基于隨機(jī)森林算法的負(fù)載預(yù)警研究及并行化
2022-11-25 03:01:12唐振坤
計算機(jī)技術(shù)與發(fā)展 2022年11期
王 誠,唐振坤
(南京郵電大學(xué) 通信與信息工程學(xué)院,江蘇 南京 210003)
0 引 言
在如今大數(shù)據(jù)的環(huán)境和背景下,如何從海量的業(yè)務(wù)數(shù)據(jù)中提取出精準(zhǔn)有效的負(fù)載預(yù)測相關(guān)數(shù)據(jù),使得負(fù)載預(yù)測工作更為準(zhǔn)確、實(shí)時,從而保障通信系統(tǒng)設(shè)備的穩(wěn)定性是當(dāng)前的研究重點(diǎn)[1-2]。
在設(shè)備故障預(yù)測領(lǐng)域,國內(nèi)外進(jìn)行了大量研究,成果顯著。例如:通過神經(jīng)網(wǎng)絡(luò)+電力系統(tǒng)進(jìn)行故障預(yù)測和安全評估;利用專家經(jīng)驗(yàn)參考系統(tǒng)對變電站的故障進(jìn)行診斷;對智能輸變電站中故障發(fā)生的動態(tài)過程,通過Petri網(wǎng)絡(luò)進(jìn)行描述分析等;以及諸多基于數(shù)理統(tǒng)計概率的方法來建立模型,從而預(yù)測故障(如蒙特卡洛仿真法)。
現(xiàn)有的負(fù)載預(yù)測方法主要分為傳統(tǒng)統(tǒng)計學(xué)方法和人工智能預(yù)測方法兩大類。傳統(tǒng)統(tǒng)計學(xué)方法包括回歸分析法[3]、時間序列法[4]、灰色模型法[5]等,統(tǒng)計學(xué)預(yù)測方法形式簡單、易于實(shí)現(xiàn),但是只能處理含有少量屬性的樣本,對樣本數(shù)據(jù)的平穩(wěn)性要求較高,且預(yù)測精度較低。而隨著人工智能技術(shù)的發(fā)展,以機(jī)器學(xué)習(xí)為基礎(chǔ)的人工智能預(yù)測方法也隨之興起。典型方法如人工神經(jīng)網(wǎng)絡(luò)(ANN)[6]和支持向量機(jī)(SVM)[7]。
憑借神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)強(qiáng)大的映射能力,人工神經(jīng)網(wǎng)絡(luò)已有很多類型(如BP網(wǎng)絡(luò)、RBF網(wǎng)絡(luò)等)被廣泛應(yīng)用于負(fù)載預(yù)測工作中。在負(fù)荷預(yù)測中,它能很好地反映歷史數(shù)據(jù)的輸入與輸出之間的關(guān)系,但是也具有預(yù)測模型泛化誤差較大,且神經(jīng)網(wǎng)絡(luò)的隱含層選取難以確定等缺點(diǎn)。作為新興的智能算法,SVM有很多優(yōu)越的性能,也克服了人工神經(jīng)網(wǎng)絡(luò)收斂速度慢、局部極小點(diǎn)等問題,但它也存在核參數(shù)和懲罰系數(shù)難以確定的缺陷。且這些模型和理論在面對準(zhǔn)確性較高的小數(shù)據(jù)集時,能較好地在單機(jī)環(huán)境下實(shí)現(xiàn),可是在面對高維度的大數(shù)據(jù)集時,就難以滿足負(fù)載預(yù)測高精度、實(shí)時性的要求。
該文提出一種基于隨機(jī)森林算法的負(fù)載預(yù)警[8]方法,并在具體實(shí)現(xiàn)上引入Spark平臺以達(dá)到并行化的改進(jìn)。通過引入公開的分布式數(shù)據(jù)集,在實(shí)驗(yàn)室搭建的分布式集群上進(jìn)行訓(xùn)練和測試,將集群預(yù)測的結(jié)果和單機(jī)模型預(yù)測結(jié)果加以比較,并逐步擴(kuò)大數(shù)據(jù)集,以驗(yàn)證模型的預(yù)測能力。
1 理論背景
1.1 隨機(jī)森林算法
美國科學(xué)院院士Leo Breiman綜合了Bagging集成、CART決策樹以及貝爾實(shí)驗(yàn)室的Tin Kam Ho等人提出的特征隨機(jī)選取思想,于2001年提出了隨機(jī)森林算法[9]。Breiman給出了與隨機(jī)森林相關(guān)的一系列數(shù)學(xué)推導(dǎo)與證明,該文可以被看作是隨機(jī)森林方法的經(jīng)典闡述。隨機(jī)森林作為一種集成算法,改變了以往分類器過擬合的問題,參數(shù)很少也使其非常容易操作,同時隨機(jī)森林也具有計算變量重要性的能力和分析所有數(shù)據(jù)之間的內(nèi)部結(jié)構(gòu)關(guān)系的能力。隨機(jī)森林算法的基本原理為:
(1)對于一個大小為N的數(shù)據(jù)集,假設(shè)隨機(jī)森林算法有k個數(shù)目,隨機(jī)森林中的每棵樹都需要從上述數(shù)據(jù)集N中通過隨機(jī)有放回的方式抽樣k個數(shù)據(jù)以作為訓(xùn)練集N0的樣本。這種方式就是Bootstrap Sample抽樣法。
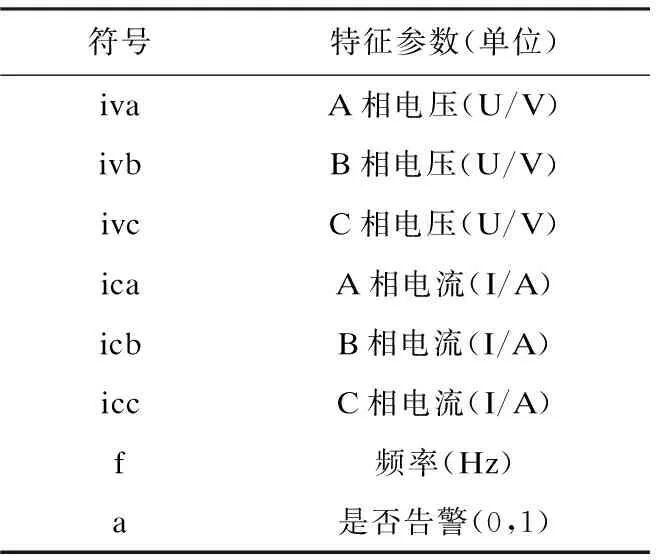
(2)記每一個輸入的數(shù)據(jù)特征維度為M,設(shè)一個常數(shù)m(要求m (3)重復(fù)執(zhí)行第2步,直到生成K棵決策樹,從而組合成隨機(jī)森林。 需要注意的是,第1步中的抽樣過程必須滿足隨機(jī)且有放回的條件,從而保證每棵樹的訓(xùn)練集是隨機(jī)且有交集的,在這個前提條件下,每棵樹的訓(xùn)練結(jié)果對最終結(jié)果才是有效的。而第3步中做不剪枝操作,是為了增加決策樹構(gòu)建的隨機(jī)性,加快決策樹的生成。 Spark[10-11]是一款基于內(nèi)存的并行分布式計算框架,相較于傳統(tǒng)的MapReduce基于磁盤進(jìn)行數(shù)據(jù)處理的計算框架,Spark將每一輪的輸出結(jié)果都緩存在內(nèi)存中,避免從HDFS中多次讀取數(shù)據(jù)導(dǎo)致的冗余資源開銷,更適合需要多次迭代的算法。 Spark的基本運(yùn)行流程是: (1)Spark在驅(qū)動節(jié)點(diǎn)Driver端運(yùn)行主函數(shù)并創(chuàng)建SparkContext以構(gòu)建Spark Application的運(yùn)行環(huán)境,創(chuàng)建完成后的SparkContext向資源管理器Cluster Manager申請所需要的CPU、內(nèi)存等資源并申請運(yùn)行多個執(zhí)行節(jié)點(diǎn)Executor,Cluster Manager分配并啟動各個Executor。 (2)SparkContext構(gòu)建有向無環(huán)圖DAG以反映彈性分布式數(shù)據(jù)集RDD之間的依賴關(guān)系,并將其分解成任務(wù)集TaskSet發(fā)送給有向無環(huán)圖調(diào)度器TaskScheduler。 (3)各Executor向SparkContext申請Task,TaskScheduler將Task分發(fā)給各個Executor,同時SparkContext將打好的程序Jar包發(fā)送給各個Executor,各Executor執(zhí)行結(jié)束后將結(jié)果收集給Driver端,最終釋放資源。 初始數(shù)據(jù)集的預(yù)處理過程是數(shù)據(jù)挖掘和分析當(dāng)中非常重要的一步。電力系統(tǒng)負(fù)荷對數(shù)據(jù)集主要是設(shè)備運(yùn)行時的一系列模擬量數(shù)據(jù),如系統(tǒng)工作頻率,A、B、C三相的相電壓,線電壓,電流,有功功率等。交流電系統(tǒng)中數(shù)據(jù)種類繁多,體量龐大,易產(chǎn)生大量的冗余數(shù)據(jù)。除此之外,在系統(tǒng)的工作過程中,由于監(jiān)測設(shè)備自身測量精度不足、通信過程中數(shù)據(jù)丟失以及運(yùn)維人員的誤操作(如拉閘斷電)等主觀或客觀因素的影響,會造成數(shù)據(jù)的缺失或異常。這部分?jǐn)?shù)據(jù)參考價值較低,如果將它們也納入預(yù)測體系會對權(quán)重產(chǎn)生較大影響,從而導(dǎo)致預(yù)測精度的下降。 (1)異常值平滑。 如上文描述,由于環(huán)境或采集系統(tǒng)自身原因的影響,會有一部分?jǐn)?shù)據(jù)和其他數(shù)據(jù)有明顯的差異,這些異常數(shù)據(jù)會對實(shí)驗(yàn)數(shù)據(jù)集產(chǎn)生負(fù)面影響,使數(shù)據(jù)集的噪聲增大,從而使預(yù)測結(jié)果出現(xiàn)偏差。因此,需要對噪聲數(shù)據(jù)進(jìn)行預(yù)處理。一種最簡單的處理方法就是直接舍棄異常值,但這樣會使數(shù)據(jù)產(chǎn)生不連貫性,因此考慮利用相近時間的正常數(shù)據(jù)作為權(quán)重進(jìn)行平滑處理,見公式(1): x(n,t)=w1x(n1,t)+w2x(n2,t) (1) 其中,x(n,t)表示第n天t時刻相應(yīng)的特征指標(biāo),w1x(n1,t)表示第n-1天t時刻對應(yīng)的特征指標(biāo),w2x(n2,t)表示第n+1天t時刻對應(yīng)的特征指標(biāo),這種方式綜合考慮了異常值附近數(shù)據(jù)的特征指標(biāo),對異常值進(jìn)行了合理的平滑。 (2)特征歸一化。 不同的特征參數(shù)的取值范圍、單位等差異較大,取值范圍較大的參數(shù)可能對取值范圍較小的參數(shù)產(chǎn)生特征覆蓋。因此,有必要對各特征參數(shù)做歸一化處理,如公式(2)所示: (2) (1)生成RDD數(shù)據(jù)集。 利用Context中的parallelize()函數(shù),將預(yù)處理后的相關(guān)數(shù)據(jù)生成RDD數(shù)據(jù)集。 (2)生成決策樹。 生成決策樹[12]是整個并行隨機(jī)森林算法的關(guān)鍵,該文采用經(jīng)典Bagging算法對RDD數(shù)據(jù)集有放回地進(jìn)行抽樣,形成k個大小一致的樣本集yi(i=1,2,…,k)。有放回地抽取說明這k個樣本集是等價的,對原始數(shù)據(jù)的特征做了均等的保留,這是并行化計算的前提。 從M個輸入特征中隨機(jī)選擇m個特征[13](m≤M)作為決策樹當(dāng)前節(jié)點(diǎn)的分裂屬性集,對m個屬性測評,如比較屬性的Gini指數(shù)(如公式(3)計算),從中選擇最優(yōu)分裂特征和切分點(diǎn),將訓(xùn)練數(shù)據(jù)集分配到兩個子節(jié)點(diǎn)中去。如此遞歸地形成決策樹,k個決策樹的形成將調(diào)用Spark進(jìn)行并行往復(fù)的迭代計算,為隨機(jī)森林模型做準(zhǔn)備。 Gini指數(shù)計算: (3) (3)生成隨機(jī)森林模型。 將所有決策樹[12]的結(jié)果整合起來,得出整個森林的結(jié)果。該文將隨機(jī)森林用作回歸,即將每個決策樹的預(yù)測結(jié)果求和取均值,這個過程由最后一個RDD來實(shí)現(xiàn),如圖1所示。 實(shí)驗(yàn)數(shù)據(jù)集選取某機(jī)房UPS部分歷史監(jiān)控數(shù)據(jù)圖,監(jiān)測主要指標(biāo)作為樣本屬性,如表1所示。選取多組容量不同的樣本(由于實(shí)驗(yàn)數(shù)據(jù)有限,將原始數(shù)據(jù)人為擴(kuò)大),如表2所示。檢驗(yàn)隨著數(shù)據(jù)量的增大,各方法的預(yù)測精度是否會受影響。 表1 數(shù)據(jù)集樣本屬性 表2 數(shù)據(jù)集樣本容量 實(shí)驗(yàn)環(huán)境是基于Spark平臺的分布式計算集群,采用一臺服務(wù)器作為driver,四臺服務(wù)器作為worker。每個節(jié)點(diǎn)的driver核數(shù)為雙核,內(nèi)存為16 G,硬盤為500 G;worker核數(shù)為單核,內(nèi)存為8 G,硬盤為200 G,Java版本為1.8.0,Scala版本為2.11.0, 使用表2中的數(shù)據(jù)集,選取典型單機(jī)負(fù)載預(yù)測算法支持向量機(jī)回歸(support vector machine,SVR)算法、分類回歸決策樹(classification and regression tree,CART)算法進(jìn)行對比。使用基尼指數(shù)最小化準(zhǔn)則進(jìn)行特征選擇,最小基尼指數(shù)值設(shè)為0.01,決策樹在生長過程中不進(jìn)行剪枝。在構(gòu)建原始隨機(jī)森林時,設(shè)定樹的個數(shù)為50,采用簡單多數(shù)投票法預(yù)測結(jié)果[14-15]。采用ROC曲線下的面積AUC指標(biāo)來評價算法預(yù)測精確度,AUC值的范圍為[0,1],其值越接近1則說明算法的預(yù)測效果越好。同時,對單機(jī)環(huán)境和并行化環(huán)境下的運(yùn)行時間進(jìn)行對比,從而判斷并行化計算是否有利于加快預(yù)測速度。 從表3可知,提出的并行隨機(jī)森林算法比CART和SVR具有更高的預(yù)測精度。這是由于算法通過 Bagging將若干個決策樹組合在一起,具備決策樹的優(yōu)點(diǎn),同時弱化其缺點(diǎn),并且對于數(shù)據(jù)做了預(yù)處理工作,降低了離群數(shù)據(jù)對于群體的干擾,保障了算法的魯棒性。此外,從表中可以看出,在數(shù)據(jù)集較小時,基于分布式集群的負(fù)荷預(yù)測方法運(yùn)行時間沒有優(yōu)勢,甚至要耗費(fèi)比單機(jī)預(yù)測算法更長的時間。這是因?yàn)榉植际郊旱娜蝿?wù)分配與調(diào)度需要消耗一定時間。為檢測并行化在大規(guī)模數(shù)據(jù)量下對算法性能的提升,將數(shù)據(jù)集進(jìn)一步擴(kuò)大,以數(shù)據(jù)集容量為變量,測試運(yùn)行時間,并在單機(jī)環(huán)境和并行集群環(huán)境下進(jìn)行對比。得到的實(shí)驗(yàn)結(jié)果如圖2所示。 表3 實(shí)驗(yàn)結(jié)果 對比可以看出,隨著數(shù)據(jù)規(guī)模達(dá)到一定程度,單機(jī)環(huán)境下的運(yùn)行時間明顯增加,而并行化環(huán)境下運(yùn)行時間增長基本保持穩(wěn)定。 在總結(jié)傳統(tǒng)單機(jī)電力負(fù)荷預(yù)測模型的基礎(chǔ)上,結(jié)合對Spark分布式計算框架的研究,實(shí)現(xiàn)了對Spark平臺下的隨機(jī)森林回歸算法的并行化,進(jìn)而借助它對電力負(fù)載做出預(yù)測,從而為負(fù)載預(yù)警提供依據(jù)和支撐,對當(dāng)前電力大數(shù)據(jù)背景下對高精度、高準(zhǔn)確的負(fù)載預(yù)測的需求提供了一定的幫助。下一步計劃將該方法在實(shí)際的數(shù)據(jù)機(jī)房中進(jìn)行驗(yàn)證,探索其實(shí)際應(yīng)用價值。1.2 Spark計算框架
2 并行化實(shí)現(xiàn)
2.1 數(shù)據(jù)預(yù)處理
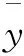
2.2 模型構(gòu)建
3 實(shí)驗(yàn)設(shè)計與結(jié)果分析
3.1 實(shí)驗(yàn)數(shù)據(jù)集

3.2 集群搭建
3.3 集群搭建

4 結(jié)束語
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
