基于BiLSTM-CNN的水稻問句相似度匹配方法研究*
2022-12-02 04:58:12劉志超王曉敏吳華瑞王郝日欽許童羽
中國農機化學報 2022年12期
劉志超,王曉敏,吳華瑞,王郝日欽,許童羽
(1. 沈陽農業大學信息與電氣工程學院,沈陽市,110866; 2. 國家農業信息化工程技術研究中心,北京市,100097;3. 北京農業信息技術研究中心,北京市,100097)
0 引言
水稻是現存的主要經濟作物之一,世界上超過一半的人口的食物來源;而不斷變化的全球氣候、植物病害的爆發,是水稻生產的主要威脅。在農業技術人員的短缺、農民自身又缺乏一定的基礎知識的背景下,在農業生產中無法有效應對此類威脅;因此,通過人工智能以及互聯網來高效地幫助農民解決此問題,對于提高水稻產量具有重要作用。在中國農技推廣信息平臺問答社區中,每天會新增關于水稻的提問語句上千百條,由于文本數據具有高維、稀疏的特點,加上漢語本身具有的復雜性,導致存在很多語義相同但表達方式不同的問句。專家在問答社區中對相同語義問句進行重復解答,會耗費大量的人力和物力,因此如何快速地檢測出語義相同問句就顯得尤為重要。文本匹配是自然語言處理(NLP)中的核心任務,常通過計算兩段文本之間的語義相似度來解決。許多NLP任務可以抽象為文本匹配問題,例如,信息檢索、問答系統和文本生成等都與文本匹配密切相關;因此,文本匹配問題具有重要的研究意義。兩個語義相似的句子會有一些相同或者相似的單詞,這意味著不同文本之間的相似性可以通過計算“詞匯共現”來衡量。基于這一原理,早期的文本匹配研究方法致力于解決詞匯層面的匹配問題,即詞匯水平上的相似性問題;該方法主要通過構建人工特征,然后利用機器學習模型對匹配程度進行評分來解決這一問題。
傳統的文本匹配技術通過特征提取算法,如TF-IDF[1]、BM25[2]、Jaccard[3]、Sim Hash[4]等算法,基于K最近鄰(K-nearest neighbor,KNN)[5],貝葉斯模型(Naive bayesian,NB)[6]和支持向量機(Support vector machine,SVM)[7]等傳統的機器學習模型用來確定文本之間的相似度。然而,此傳統方法存在一些局限性,如過于注重詞匯層面,不能解決多義問題,不能有效利用上下文信息,提取句子的高級語義特征;因此,如能有效提取句子的語義,將大大提高文本匹配精確度。近年來,基于深度學習的方法成為了國內外研究熱點,Yin等[8]提出了一種叫Bi-CNN-MI的架構,其中Bi-CNN表示兩個使用Siamese框架的CNN模型;MI表示多粒度的交互特征用于計算文本的相似度;Huang等[9]用單語義模型(Deep Semantic Similarity Model,DSSM)計算語句之間的相似度;Melamud等[10]提出一個神經網絡,使用雙向LSTM從大型語料中通過上下文表示的相似度計算;Yin等[11]使用神經網絡RNN和CNN卷積神經網絡,神經網絡通過對句子和單詞的深度分析來更好地考慮句子的語義和結構,從而預測句子的相似度;文獻[12-15]為深度學習和自然語言處理技術在農業領域文本處理方面,提供了可行性參考和依據。由于在農業領域缺乏大規模可以使用的數據集,因此農業文本相似度還鮮有涉及。而農技推廣平臺(NJTG)問答社區,面臨農業類詞匯的句法和意義較為復雜的挑戰,水稻文本中含有大量專業詞語,提取難度較大,問答文本較短,進一步增加了提取上下文信息的難度。
基于上述研究方法和現狀,針對水稻中分詞錯誤和數據稀疏等造成的問題以及提取水稻問句不同粒度的特征難度,本文采用了基于孿生網絡Siamese的雙向長短神經記憶網絡BiLSTM-CNN模型水稻問句語義層次信息的相似度匹配方法。首先使用Word2Vec訓練的字向量作為原始的句子表示,通過BiLSTM提取的字級向量組成的水稻問句的上下文特征表示,CNN捕獲關鍵部分信息特征,進行卷積和池化操作后使用對比損失函數,最后直接使用余弦相似度來衡量兩個水稻問句向量之間的相似度。以準確率、精確率、召回率和F1值為主要判斷標準,以宏平均和權重平均為輔助評價指標,對神經網絡中的參數設置進行調優,并利用水稻問答數據集構建問答評價任務中提供的數據集(NQuAD, National Question and Answering Dataset)[16]對該方法進行驗證。
1 數據與預處理
1.1 問答數據來源
本文試驗從“中國農技推廣”問答社區數據集NQuAD中導出水稻數據,共涉及水稻病蟲害、草害藥害、栽培管理常見問題等方面的2萬余對問答數據。經過人工篩選,去掉不完整信息、無效問答數據等。人工標注后,選取7 820個優質問句對存入水稻問答數據庫作為問題集和答案。共劃分6類問題,分別是栽培管理、病蟲草害、土壤肥料、市場銷售、品種選擇及其他。栽培管理1 953對、病蟲草害2 311對、土壤肥料1 697對、市場銷售651對、品種選擇246對及其他956對。
1.2 數據預處理
用戶在“中國農技推廣”問答社區水稻問答模塊發布提問,農業專家對所提問題進行解答。在此過程中,語義不精確,語言不流暢等問題,導致數據中存在字符混亂、英文字母大小不一,不利于文本匹配。通過Python正則表達式、字符格式規范化等操作,清洗和過濾無關信息,刪除非文本數據,獲得標準化的水稻數據問答庫。
1.3 水稻問句對數據集構造
針對選取的7 820個問答對,構建輸入三元組(句1,句2,標簽);具體規則如下:在水稻問句數據中,構建相似問句對,語義表達相同,記作標簽為1;語義表達不相同,其標簽為0;問句處理示例見表1。如表所示,編號1的問句對,問句1和問句2語義表達相同,標簽為1,為正樣本;編號3,問句1和問句2語義表達不相同,標簽是0,為負樣本。

表1 水稻問句數據對示例Tab. 1 example of rice question data pair
2 水稻問句相似度匹配模型構建
本節詳細描述了本文提出的混合模型結構,本研究采用結構簡單、訓練穩定的孿生網絡為基礎網絡框架,整個模型包含以下5部分,第一,利用預訓練Word2Vec構造字符級的向量,向量嵌入為每一對問句提供的向量表示。第二,使用BiLSTM神經網絡捕獲問句的上下文特征和語義關系,在此充當編碼器,從每個輸入的句子中提取隱藏特征。第三,CNN擅長捕捉序列的顯著特征。因此,在捕獲問句上下文特征的基礎上,利用卷積層進一步提取句子的局部語義特征。第四,池化層對提取后的組合進一步篩選,同時對得到的特征進行降維處理。第五,直接使用cosine距離計算并輸出余弦相似度的值,以此來衡量問句對向量的匹配程度。模型結構如圖1所示。
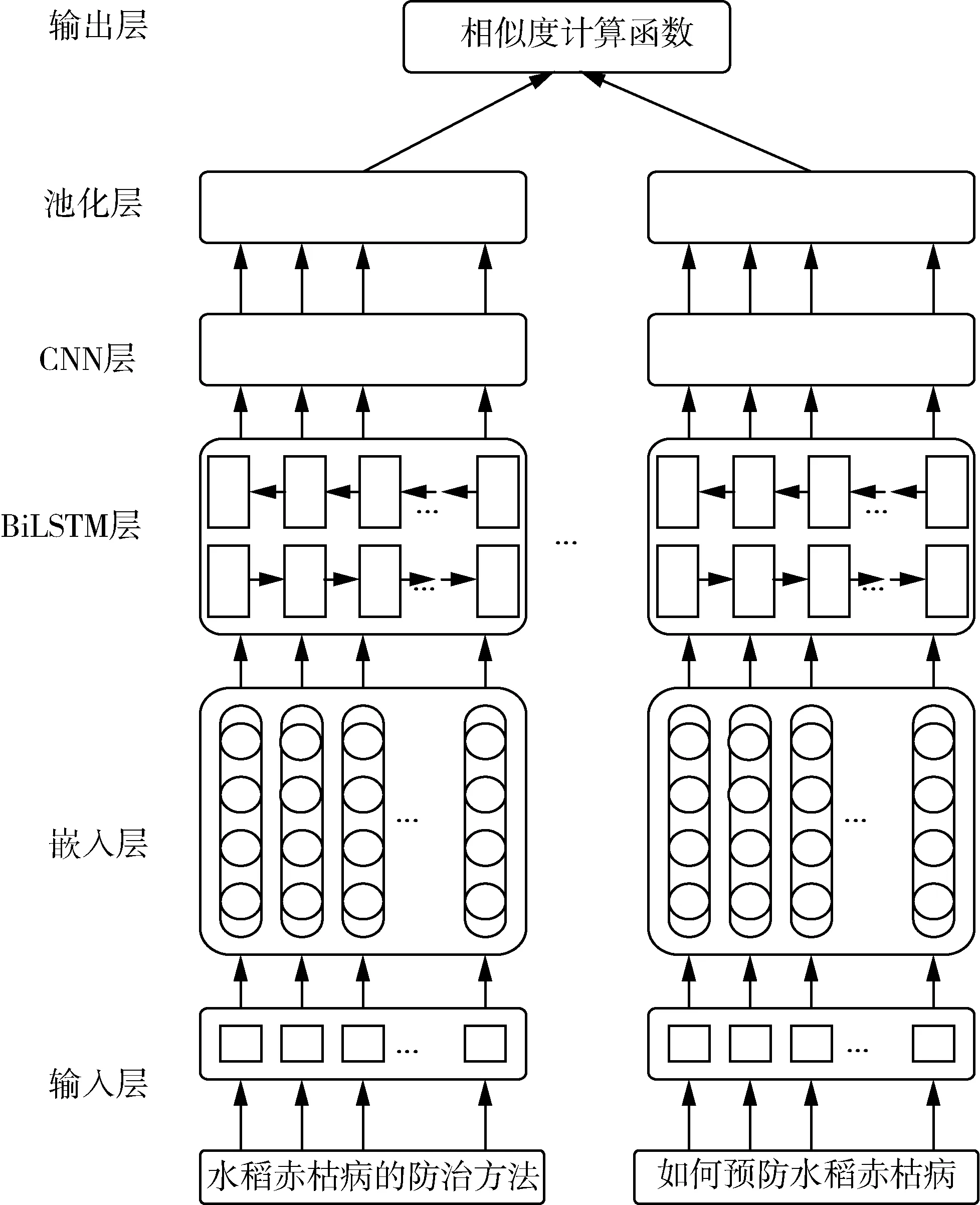
圖1 模型結構示意圖
2.1 嵌入層
為了使計算機能夠理解輸入的問題,需要對其進行向量化處理。由于農業領域的特殊性,獲取到的數據存在大量的水稻品種名稱、病蟲害類型名稱、種植技術名稱、藥劑名等專業術語,需把他們添加到農業領域詞典,使得到的農業專業術語如“水稻胡麻葉斑病”“稻縱卷葉螟”“乳苗移栽”“磷酸二氫鉀”等可以被正確化分。
近年來,農業領域專業詞匯涉獵廣泛,水稻問句對樣本較少,并且存在OOV(out-of-vocabulary)問題。在不同的問句中,同一專業詞或短語可能會存在不同分詞結果,導致訓練的詞向量組合語義信息不同。為了避免分詞對模型的影響,本文采用了字級別向量的表示方法。在自然語言處理中,一般將文本數據轉換成矩陣或向量進行表示。本研究使用預訓練的Word2Vec構造嵌入層,由預訓練得到的字向量,保留了句子最原始的信息;相對于詞向量表示,包含的語義信息更加豐富;此文本向量作為下一步BILSTM模型的輸入。本文采用CBOW模型,其根據上下文預測中心詞,并設置單詞嵌入大小為100,上下文窗口為5。水稻問句示例如圖2所示。
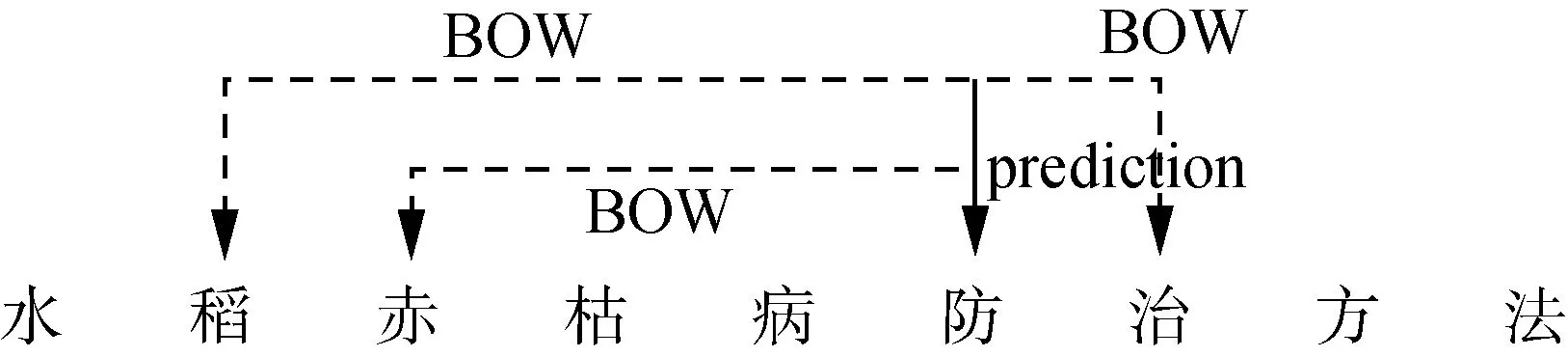
圖2 CBOW模型水稻問句可視化
2.2 BiLSTM層
遞歸神經網絡(RNNs)可以獲取一系列輸入并產生一系列輸出,輸出不僅受到像常規神經網絡一樣施加在輸入上的權重的影響,還受到基于輸入和輸出的表示學習信息的隱藏狀態向量的影響。在本文用長短期記憶(LSTM)作為雙向循環架構的循環單元,解決了循環神經網絡(RNNs)中出現的梯度消失/爆炸問題[17];此外,Graves等[18]使用雙向長短記憶網絡BiLSTM顯著提高了分類精度LSTM架構如圖3所示,其中c(t)、h(t)和x(t)分別是記憶狀態單元、t時刻的LSTM輸出和t時刻的輸入,符號Θ表示逐元素(Hadamard)乘法。tanh是雙曲正切函數,σ是對數sigmoid函數。LSTM組件值計算如下。
i(t)=σ(Wih(t-1)+Uix(t)+bi)
(1)
f(t)=σ(Wfh(t-1)+Ufx(t)+bf)
(2)
a(t)=tanh(Wch(t-1)+Ucx(t)+bc)
(3)
c(t)=c(t-1)Θft+a(t)Θi(t)
(4)
o(t)=σ(Woh(t-1)+Uox(t)+bo)
(5)
h(t)=tanh(c(t)Θo(t))
(6)
式中:i(t)——輸入門;
f(t)——忘記門;
o(t)——輸出門;
a(t)——輸入更新值;
bf、bi、bc、bo——每個門的偏差;
W——前饋權值;
U——循環權值。
該模型有兩個激活單元:輸入—更新激活和輸出激活,其中tanh函數是激活函數。
BiLSTM在三個時間步(前中后)展開的一般結構如圖4所示。雙向結構結合了循環系統的時間動態作為前饋和后向訓練的模型。BiLSTM模型結構訓練過程中,Bi-LSTM計算兩個序列:前向隱藏序列和后向隱藏序列到通過迭代從時間t=0到t=T上升的前向層和從時間t=T到t=1下降的隱藏后向層來產生輸出序列。
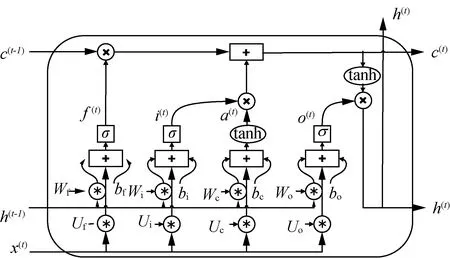
圖3 LSTM記憶單元結構

圖4 雙向LSTM模型結構
2.3 CNN層
卷積神經網絡(CNN)是由Le等[19]在1989年首次提出的,目的是利用時間序列和圖像等網格結構數據集的權重共享,通過從原始數據或少量預處理數據中提取復雜的特征表示來學習。卷積層可以提取不同大小的特征和局部語義特征,神經卷積網絡在各種應用中表現出顯著的性能改進。文本將BiLSTM提取到的文本特征作為卷積神經的輸出。
Hs(t)=[h(t),h(t+1),…,h(t+s-1)]
(7)
(8)
式中:w——過濾器權重矩陣;
s——總時間步數。
2.4 池化層
模型通過卷積層提取特征之后,使用最大池化法選取卷積提取到的n-gram特征、進行壓縮及降維,對卷積后的所有局部語義特征組合進行進一步篩選。最大池化技術方程如式(9)所示。
(9)
式中:rj——元素固定大小的向量表示;
l——輸入長度。
2.5 損失函數
經過池化操作后,得到兩個問句的抽象語義表示向量。在計算句子語義相似度的時候,都是以句子對的形式輸入到網絡中,定義了兩個網絡結構分別來表征句子對中的句子,可通過曼哈頓距離,歐式距離,余弦相似度等來度量兩個句子之間的空間相似度。
本文使用Contrastive loss Function(對比損失函數),可以有效地處理孿生神經網絡中的水稻問句對的關系。相似的樣本,在經過降維后,在特征空間中,仍舊相似;而原本不相似的樣本,依舊不相似。
DW(X1,X2)=‖X1-X2)‖2
(10)
(11)
式中:X1、X2——經過處理的文本向量;
Y——標簽,Y=1代表兩個問句相似,Y=0則代表不相似。
DW——神經網絡要學習的參數化距離函數;
m——設定的閾值。
3 試驗方法
3.1 試驗環境設置
將7 820對水稻問句對數據作為試驗數據,數據集劃分是按照7∶2∶1的比例將句子對劃分對訓練集、驗證集、測試集,訓練集共5 474條,驗證集共1 564條,測試集共782條。試驗環境設置如表2所示。

表2 環境設置Tab. 2 Environment settings
3.2 試驗參數設置
模型參數如表3所示。

表3 參數配置Tab. 3 Parameter configuration
使用TensorFlow框架對神經網絡模型迭代訓練,為避免過擬合現象,引入Dropout機制。在神經網絡槽參數設置方面,選擇Adam作為bilstm網絡的優化器,并將lstm層數設置為兩層。
3.3 評價標準
與其他的文本匹配計算方法相似,評價標準采用準確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1值,綜合考察評價指標用宏平均(Macro-averaging)和權重平均(Weight-averaging)。
(12)
(13)
(14)
式中:TP——正向類預測為正向的數量;
FP——負向類預測為正向的數量;
FN——正向類預測為負向的數量。
(15)
(16)
Weight-averaging=F0×S0+F1×S1
(17)
宏平均F值是對每一個類統計指標值,然后再對所有類求算術平均值,F0是類別為負樣本的F1值,F1是類別為正樣本的F1值。權重平均F值是正負兩類的F1加權平均,S0為負樣本在總樣本中所占的數量,S1為正樣本在總樣本中所占的數量。
3.4 對比模型
目前,在孿生網絡做文本相似度匹配的應用中,主流模型為LSTM。為了能夠驗證本文模型在文本匹配中的效果,使用文本匹配中的常用網絡模型LSTM和BiLSTM、并在BiLSTM中引入Attention機制與本文模型進行比較,同時也驗證本文提出的模型在水稻問句對數據集的有效性使用了三個對比模型進行比較。
1) LSTM:模型使用長短期神經記憶網絡LSTM模型:傳統前饋神經網絡模型的一種擴展變體,在包含一個存儲單元狀態和三個乘法門的一系列構建塊上運行,將隱藏狀態100設置為輸入參數。
本文使用的孿生網絡中的子網絡包含LSTM,本文模型和LSTM都可以處理水稻問句相似度時獲得的向量表示。對比LSTM的單網絡結構,基于孿生網絡的組合模型能夠更好捕獲全局特征和局部特征,從而提高預測準確率。
2) BiLSTM:使用雙向長期短期神經記憶網絡BiLSTM模型[20]:具有一個前向LSTM和一個后向LSTM的級聯層,雙向的LSTM提取上下文信息,隱藏狀態設置為100。
本文將孿生網絡的子網絡替換為BiLSTM,本文模型和BiLSTM都能夠很好的處理雙向數據的序列信息。而Sim-BiLSTM-CNN模型將BiLSTM適用于提取全局特征和CNN適合于提取局部特征的優勢相結合,從而擁有更高的預測精度。
3) BILSTM-Attention:使用BiLSTM和Attention機制的文本匹配模型[21]:在BiLSTM模型中引入Attention機制的文本匹配模型。Attention機制就是通過保留BiLSTM編碼器對輸入序列的中間輸出結果,再訓練一個模型來對這些輸入進行選擇性地學習并且在模型輸出時將輸出序列與之進行關聯。
相同之處是都利用BiLSTM提取文本的上下文信息和空間信息,不同之處是本模型將BiLSTM的輸出輸入到CNN層,進一步提取文本語義和空間特征,而BILSTM-Attention模型中BiLSTM隱藏層的輸出通過注意力機制分配權重。
4 試驗結果與分析
4.1 模型訓練及識別效果
圖5和圖6分別展示了5種模型在水稻問句相似對數據集上訓練的準確率和訓練誤差的趨勢圖。

圖5 訓練集準確率變化
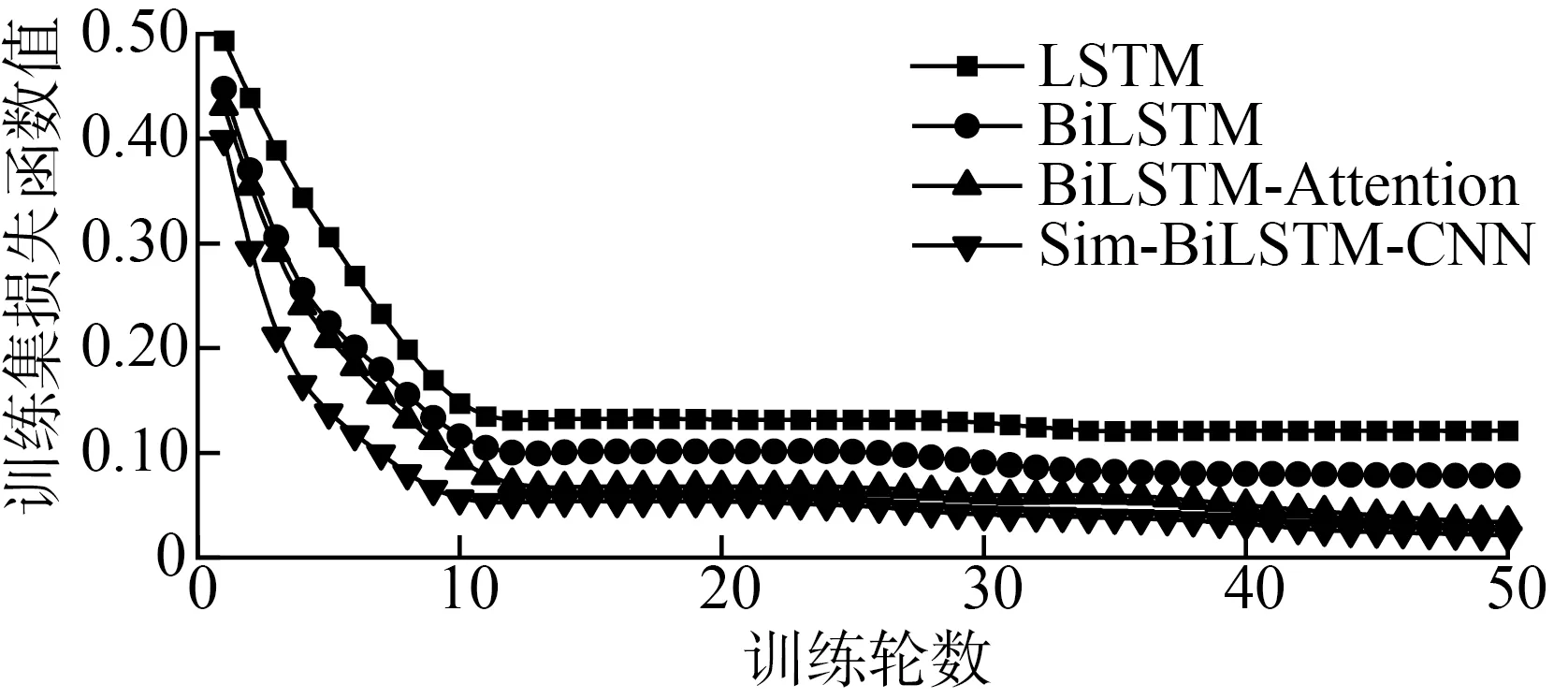
圖6 訓練集Loss變化
Sim-BiLSTM-CNN 模型相對比其他三中訓練模型,隨著模型中訓練輪數的增加,損失函數下降,精度提高,在訓練輪數達到10輪時,變化趨于穩定,準確率接近99%,損失函數值降至0.022,該模型基本達到了收斂狀態。訓練集和驗證集在輪數大于10輪之后,準確率均在95%以上,波動范圍小,模型表現效果較好。LSTM可以更好地捕獲較長距離的依賴關系,通過訓練過程可以學到記憶哪些信息和遺忘哪些信息,但無法編碼從后向前的信息而BiLSTM可以更好地捕獲雙向語義。Sim-BiLSTM-CNN模型則包含上述模型優點,參數更少,且不存在序列依賴問題。僅引入Attention機制后,在同一個樣本上根據不同位置計算Attention,忽略了不同樣本之間的聯系。Sim-BiLSTM-CNN模型loss值在10輪之前,一直處于下降趨勢,當輪數等于10時,loss值變化較小,隨著輪數的變化最終穩定在0.1以下。
4.2 不同類別樣本數量試驗對比
為驗證模型效果和節省標注數據,使用劃分好6類問句,分別是栽培管理、病蟲草害、土壤肥料、市場銷售、品種選擇及其他進行試驗。由表4可知,Sim-BiLSTM-CNN模型在各類水稻問句對數據集上準確率均具高于其他三種模型,其中市場銷售、品種選擇及其他類別中水稻問句對數據量均不足1 000對,其準確率分別達到89.3%、98.2%和98.4%,說明Sim-BiLSTM-CNN模型在數據量較少的情況下,仍能夠有效提取短文本的特征進行文本相似度計算,也說明了該模型具有很好的魯棒性。
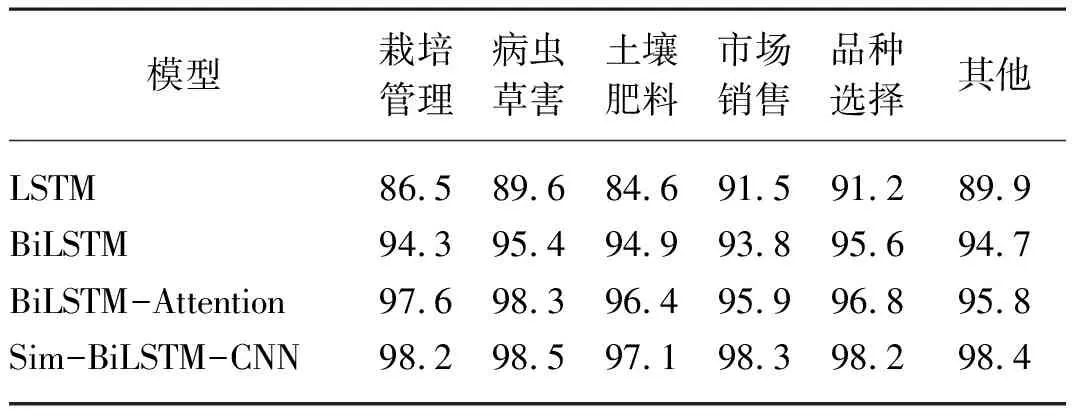
表4 本文方法與對比模型在不同類別數據集上的結果Tab. 4 Results of the method in this paper and the comparison model on different categories of data sets %
4.3 不同向量表示試驗對比
針對詞向量和字向量兩種文本向量化表示方式,本文設計了一組對比試驗,分別將詞向量和字向量作為問句相似度模型的初始輸入,對比試驗結果如表5所示。由表5可知,模型精確率為99.31%,相對于詞向量作為模型輸入,精確率、召回率、F1值分別提高了3.07個百分點、2.54個百分點、1.57個百分點。LSTM模型和BiLSTM模型在水稻問句中的P、R、F值中均低于加入注意力機制的BILSTM-Attention模型,這是由于注意力機制可以強化農業問句中關鍵詞的權重,從而提高文本匹配效果。從表5中可以得出,在四種神經網絡模型中字向量效果明顯優于詞向量,使用字符向量的好處是可以解決傳統模型不能很好地處理新詞的問題(OOV problem)。主要原因是中文分詞器往往不完善,不正確的分詞可能會降低匹配性能,分詞會導致詞義單一的詞語在不同的句子中向量表示不同。其次,在相對較大的樣本數量中,詞向量效果可能較好,本文水稻問句樣本相對較少,字向量效果更好。
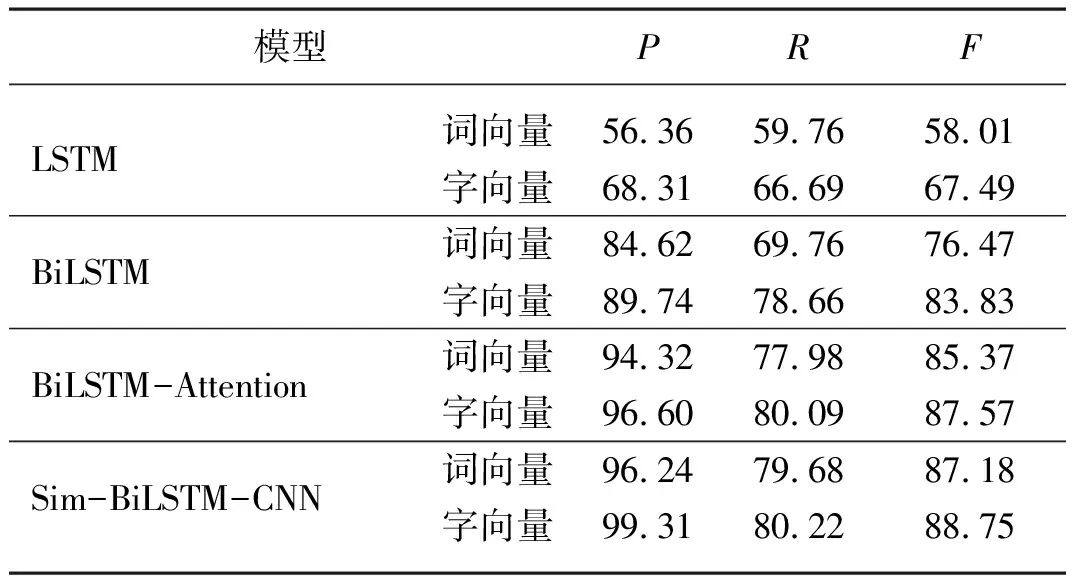
表5 不同嵌入向量(詞向量與子向量)對比試驗Tab. 5 Comparison experiments of different embedded vectors (word vector and sub vector) %
4.4 不同模型試驗結果比較
綜合考察評價指標宏平均F值和權重平均F值作為參考,如圖7所示。試驗結果對比如表6所示,顯示了各個模型在測試集的識別性能。
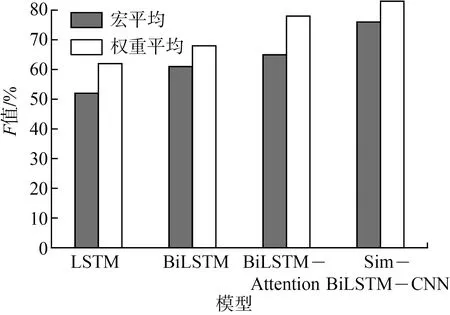
圖7 綜合考察評價指標對比
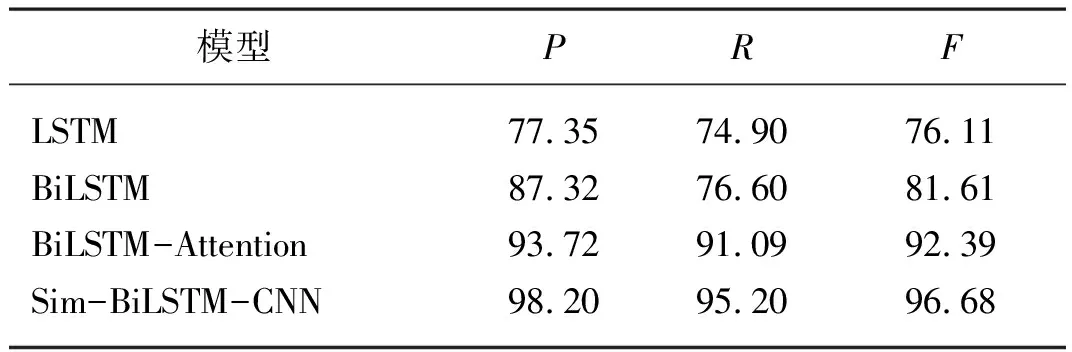
表6 不同模型的測試集結果對比Tab. 6 Comparison of test set results of different models %
由圖7和表6可知,Sim-BiLSTM-CNN模型精確率為98.20%,在綜合考察評價指標中宏平均和權重平均也明顯優于LSTM模型和BiLSTM模型,基于上下文的雙向LSTM比單向的LSTM提升了10.03%,其原因為:利用LSTM對句子進行建模存在一個問題:無法編碼從后到前的信息,而通過BiLSTM可以更好地捕捉雙向的語義依賴,與BiLSTM-Attention模型相比,較BilSTM模型綜合評價指標對比,試驗效果提升明顯。精確率高于4.48%,Attention機制可以靈活的捕捉全局和局部的聯系;與Sim-BiLSTM-CNN模型相比,宏平均和權重平均較低,是因為Attention機制不能捕捉語序順序。
應用本模型在測試集識別結果如表7所示。

表7 水稻問句數據識別結果示例Tab. 7 Example of rice question data recognition results
如果預測標簽與真實標簽一致,則正確,如編號1,2等所示;否則,屬于錯誤預測,如編號3,4,9所示。在測試結果示例中10對問句預測正確為7對,預測錯誤為3對。分析其主要導致預測標簽錯誤的原因可能是,問句1和問句2文本長短相差較大,不能更好地獲取全句語義或者是訓練集中標簽0和1數量比例不均衡等。
5 結論
為了進一步提高農戶在水稻種植過程中的工作效率和質量,減少專家重復回答農戶提出的相似問題,避免延時性。本研究使用3個詞嵌入模型對文本進行向量化表示,詞向量和字符向量在水稻問句相似度匹配模型中進行對比分析,能夠考慮到字符的輸入特征,提高模型的準確率。利用孿生網絡框架結構,應用雙向長短期記憶網絡和深度卷積循環網絡組融合對水稻問句相似度匹配的任務采取建模方式,設計了水稻問句相似度模型,與其他3種文本匹配模型進行對比分析驗證了本模型的有效性。
1) 通過使用One-hot、TF-IDF、Word2Vec以及詞向量和字符向量在水稻問句中的處理方法可以緩解農業領域的分詞錯誤造成的影響,使模型識別效果在精確率、召回率和F1值中分別提高3.07個百分點、0.54個百分點和1.57個百分點。
2) 本文所設計的水稻問句相似度匹配模型能夠對水稻問句數據進行精準匹配,三種文本相似度對比模型LSTM和BiLSTM、并在BiLSTM中引入Attention機制相比在識別結果上具體較大提高,識別的精確率、召回率和F1值分別為99.31%、80.22%和88.75%。
3) 本文使用綜合考察評價指標宏平均和權重平均作為模型參考評價標準,同其他3種模型相比,宏平均和權重平均值分別達到75%和80%以上。
4) 在下一步研究中將收集更多的訓練數據,更詳細的研究特征和架構,以及像GPT-3和BERT模型的應用,探索如何提高模型的訓練效率。
猜你喜歡
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
軍事文摘(2021年22期)2021-11-26 00:43:51
文苑(2020年6期)2020-06-22 08:41:52
開放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2019年22期)2019-12-07 05:29:00
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
