基于LightGBM-LSTM組合模型的商業建筑能耗預測
2022-12-03 01:56:36羅恒劉杭
計算機應用與軟件 2022年11期
羅 恒 劉 杭
1(蘇州科技大學電子與信息工程學院 江蘇 蘇州 215009)2(蘇州科技大學江蘇省建筑智慧節能重點實驗室 江蘇 蘇州 215009)
0 引 言
隨著智能電網對于各個大型商業建筑的普及,建筑能源的節約使用已經成為了人們的關注要點。很多大型公共建筑通過建立能源節約系統,能夠預測未來短期或中長期建筑能耗數據,起到節約資源以及節約企業成本的作用[1]。能夠影響大型商業建筑能耗的因素有很多,例如天氣影響、國家規定節假日因素等,所以能耗預測的準確度問題仍然是需要重點研究的對象。
建筑能耗預測中常用的傳統機器學習方法主要有隨機森林(Random Forest,RF)算法[2]、K-近鄰(k-Nearest Neighbor,KNN)算法[3]和支持向量回歸機(Support Vector Machine,SVM)算法[4]等。預測問題使用回歸算法較多,例如,文獻[5]提出一種基于核嶺回歸(Kernel Ridge Regression,KRR)的預測風速的方法,但預測通用性不高。很多研究人員使用決策樹的算法對時間序列數據做出簡單預測,隨機森林算法使用Bagging思想[6],將多個決策樹綜合,提升決策樹的預測效果。文獻[7]使用(Gradient Boosting Decision Tree,GBDT)算法做預測,它是基于梯度的最小化損失函數的決策樹算法。LightGBM[8]模型是GBDT模型的一種改進模型,對多特征數據處理效果較好。文獻[9-10]使用神經網絡對能耗預測,但是對于時間序列問題仍然具有局限性。針對時間序列數據,經典的自回歸移動平均模型(ARIMA)[11]和目前基于循環神經網絡(Recurrent Neural Network,RNN)[12]衍生的長短期記憶(Long Short-term Memory,LSTM)[13]網絡都是經常使用的預測模型。LSTM增加具有門控單元的記憶功能,與其他方法相比,在處理時間序列問題上更能夠捕捉時間序列項之間的依賴關系和模式。
能耗序列數據是具有長短期時間序列特性的數據,同時易受多種特征因素影響。針對能耗序列這兩種特點,依據上海某商業建筑能耗數據開展實驗,并提出一種基于LightGBM-LSTM組合模型的權重組合的預測方法。其組合方式使用文獻[14]的方差-協方差法的權重組合方法,本實驗分別使用LightGBM模型與LSTM模型對該商業建筑能耗時序數據進行建模,通過對于LightGBM模型和LSTM模型預測結果的權重組合,并將組合后的模型與KNN、RF和GBDT等模型進行實驗結果對比,本文所提出的LightGBM模型與其他單項模型相比,具有較好的預測能力。
1 研究方法與理論
1.1 LightGBM模型
LightGBM是基于決策樹基分類器的算法,它采用了幾種策略優化方式,是泛化梯度提升樹的一種模型。
決策樹算法將特征集合映射,對于輸入數據D={(x1,y1),(x2,y2),…,(xn,yn)}預生成k棵決策樹,將訓練集輸入空間遞歸劃分為兩個子區域輸出值:
計算R1、R2的域內方差:
(3)
式中:c1、c2為每個區域的輸出。找出最優切分:
計算第m棵樹子數劃分區域的局部均值:
式中:Nm為該劃分區域的數據個數。
式(5)表示對單個區域的預測結果。對于上述條件可以重復調用,獲取滿足條件的最小回歸樹。最終劃分區域空間數為M的區域集合{R1,R2,…,RM},生成決策樹為:
式中:I為指示函數,如果x∈Rm,則I為1,反之則為0。
根據平方誤差最小化原則,輸出區域內最優的值。其中對于第m棵子數的第j個預測值的損失函數定義為:
l(m,j)=L(yj,fm(xj))=(yj-(fm(xj)))2
(7)
式中:L為L2損失函數。
梯度決策提升樹是一種使用Boosting方法預測的分類回歸算法,在提升樹中使用殘差作為下一個樹的輸入,在梯度決策提升樹中使用公式:
LightGBM模型基于GBDT的策略改進,使用直方圖算法離散遍歷數據,優化最優決策樹分割點,在LightGBM模型中的決策樹使用Level-wise策略[15],控制模型復雜度。模型的創新點在于基于單邊梯度的采樣算法(GOSS)和互斥特征打包(MEF)。MEF算法如算法1所示。
算法1MEF算法流入:numData為輸入數據的大小,F為互斥特征的一組打包。
輸出:newBin,binRanges。
1. binRanges←{0},totalBin←0;
2.forfinFdo
3. totalBin+=f.numBin;
4. binRanges.append(totalBin);
5. newBin←new Bin(numData);
6.fori=1tonumDatado
7. newBin[i];
8.forj=1tolen(F)do
9.ifF[j].bin[i]≠0then
10. newBin[i]←F[j].bin[i]+binRanges[j];
1.2 LSTM模型
在使用基于時間序列的數據處理時,使用傳統的神經網絡模型無法得到前后數據的依賴關系結果。循環神經網絡(RNN)是針對這一問題而設計的深度遞歸網絡,它能夠保留前面幾個時間步的信息,但是在時間軸上會發生梯度消失或梯度爆炸,為了解決RNN梯度問題,LSTM使用門控單元來實現記憶功能,設置遺忘門(Forget Gate)、輸入門(Input Gate)、狀態更新(Status Updates)、輸出門(Output Gate)。如圖1所示,四種門控結構連接到乘法元件上,通過控制神經元細胞(Memory cell)的輸入輸出,達到提升神經元記憶能力的功能。

圖1 LSTM神經元結構
定義圖1的部件描述如下:
Input Gate:控制信息流入到記憶單元中,記為it。
Forget Gate:控制前一時刻的信息流入到當前時刻的記憶單元中,記為ft。
Output Gate:控制當前時刻的記憶單元信息流入隱藏狀態ht中,記作ot。
Cell:存儲單元,是神經元的記憶功能,有對數據保存處理的能力,記作ct。
在某一時刻t,LSTM神經網絡內部隱藏層定義運算公式為:
ft=sigmoid(wf1xt+wf2xt-1+bf)
(9)
it=sigmoid(wi1xt+wi2xt-1+bi)
(10)
ot=sigmoid(wo1xt+wo2ht-1+bo)
(12)
ht=ot×tanh(ct)
(14)
式中:w和b分別代表不同門的權重和偏差矩陣;tanh與sigmoid表示激活函數;ht代表流入當前隱藏狀態信息;xt-1、xt表示t-1時刻與t時刻數據。
LSTM在訓練過程中,將數據輸入進輸入層,經過激活函數作用后輸出,在輸出后將t-1時刻數據經過隱藏層的輸出t時刻輸入節點,由圖1和圖2對應的遺忘門、輸入門和輸出門單元處理,最后輸出到輸出層或者是下一個層計算單元,輸出層輸出的數據經過輸出層神經單元,通過反向傳播算法,更新節點權重。
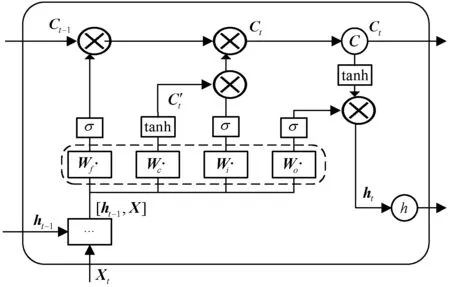
圖2 LSTM隱藏單元結構
2 LightGBM-LSTM模型構建與預測
2.1 數據預處理及特征分析
實驗采用上海市浦東新區某大型商業建筑平臺提供的歷史能耗數據,數據按照時間序列排序,包含兩年每天每小時的能耗使用情況。經過預處理,得到整點能耗數據。根據文獻[16],能耗數據受到天氣因素影響,所以從某天氣網站上獲取到了這兩年浦東新區的天氣數據進行分析,經過預處理,時間間隔為一個小時。實驗采用的日期準確范圍為2018年1月1日至2019年12月31日,共17 514條能耗數據和17 514條天氣數據。
本節主要根據歷史能耗數據以及天氣相關因素,篩選確定影響因素,從而能夠進行準確的預測。
2.1.1能耗歷史數據分析
使用文獻[16]方法,根據能耗序列歷史數據具有時間序列的關系,使用自相關系數和偏自相關系數來分析能耗歷史數據的平穩性和滯后性,如圖3所示。
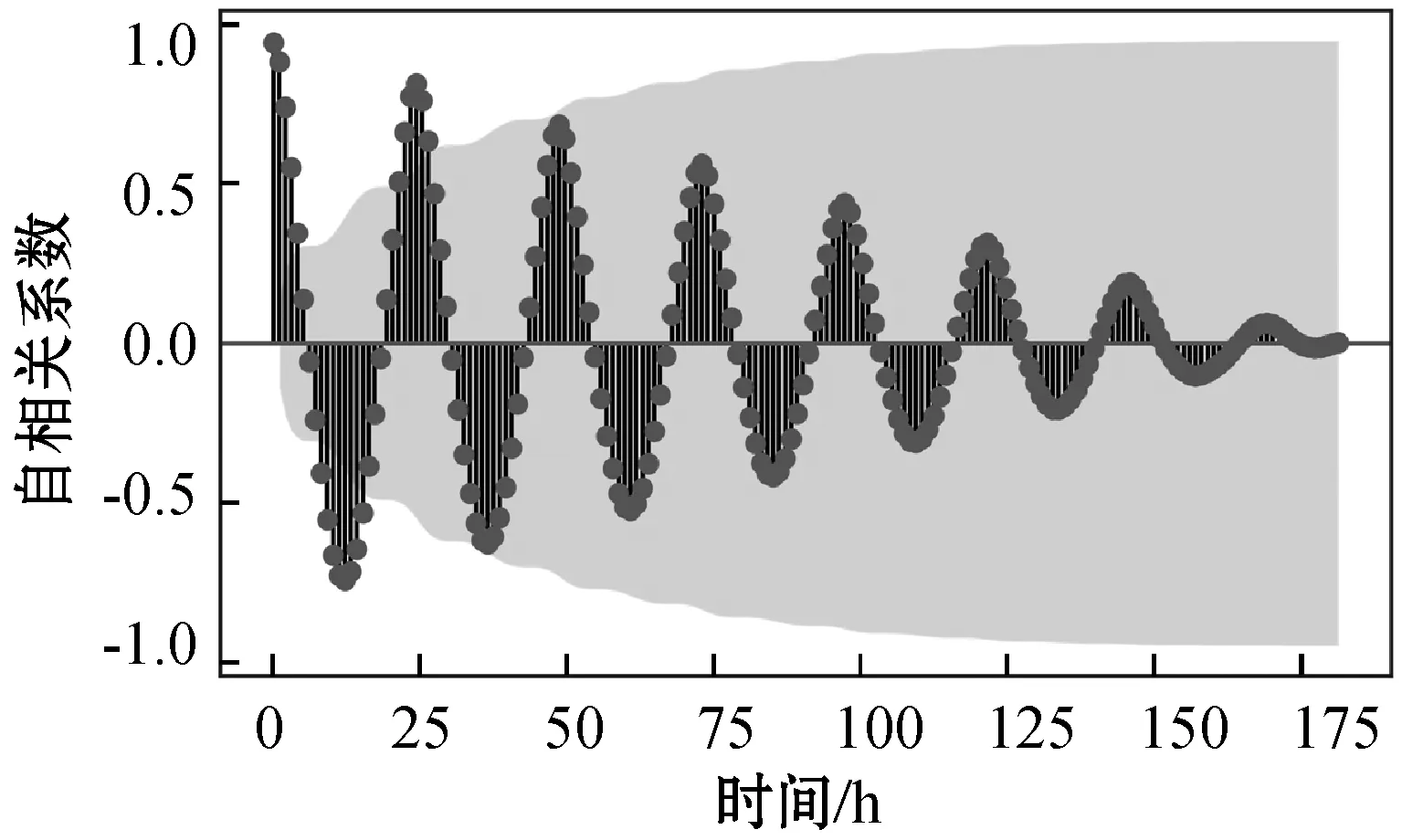
(a) 能耗數據自相關系數
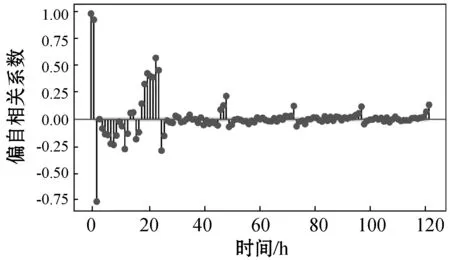
(b) 能耗偏自相關系數圖3 能耗數據相關系數
從圖3(a)中可以看出建筑能耗歷史數據隨著滯后時間增加,最終趨于平穩。通過圖3(b)可以認為歷史能耗數據具有滯后性,所以使用帶時間滯的數據作為基本實驗數據。
2.1.2特征因素
通過某天氣網站氣象應用程序接口(API)調用該地區一年的天氣情況,包括溫度、濕度、風速等。為了判定不同的因素影響程度,使用斯皮爾曼相關系數表示其相關性,篩選相關性較高的因素作為實驗影響因素。從圖4中看出風向對于建筑能耗數據的影響呈無相關性,其余三種因素呈現中相關性,因此可以將風速、濕度、溫度作為影響因素。
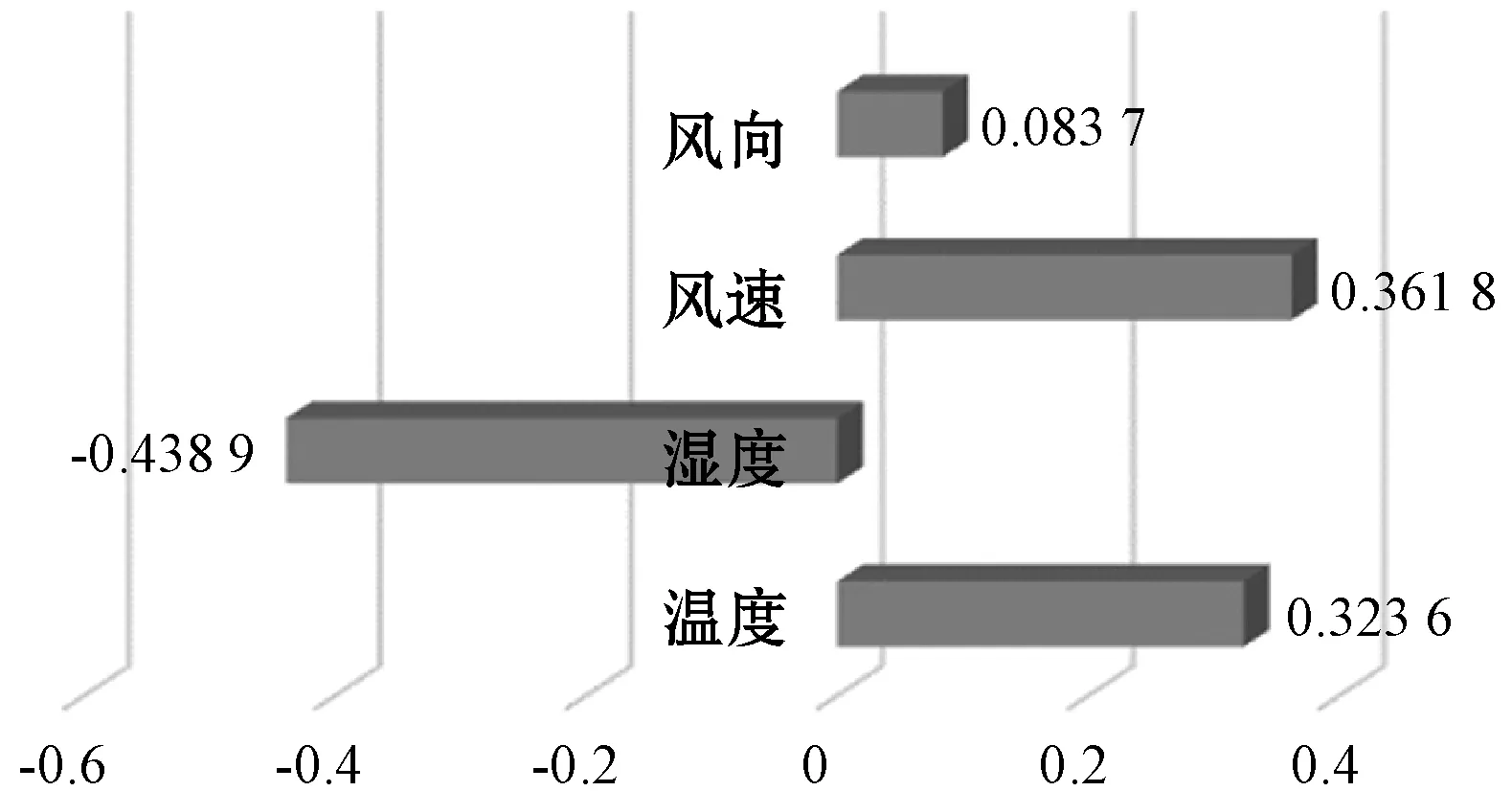
圖4 斯皮爾曼相關系數
考慮到該大型商業建筑是公共娛樂建筑,所以在節假日會比平時使用電能多。從圖5中可以觀察到,2018年和2019年的寒暑假時期,數據呈現上升的趨勢,兩年內的同一季節,數據的趨勢變化也大致相同。圖6是2018年節假期能耗、工作日能耗、全年能耗的小時均值對比圖。可以看出假期的能耗小時均值比工作日的能耗小時均值高。綜上,將工作日因素以及季節周期性因素等列為特征因素。
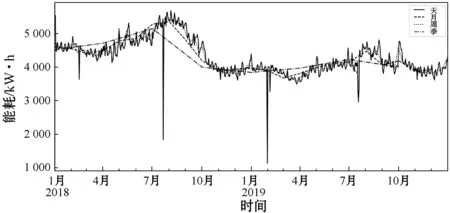
圖5 2018年-2019年能耗序列觀測
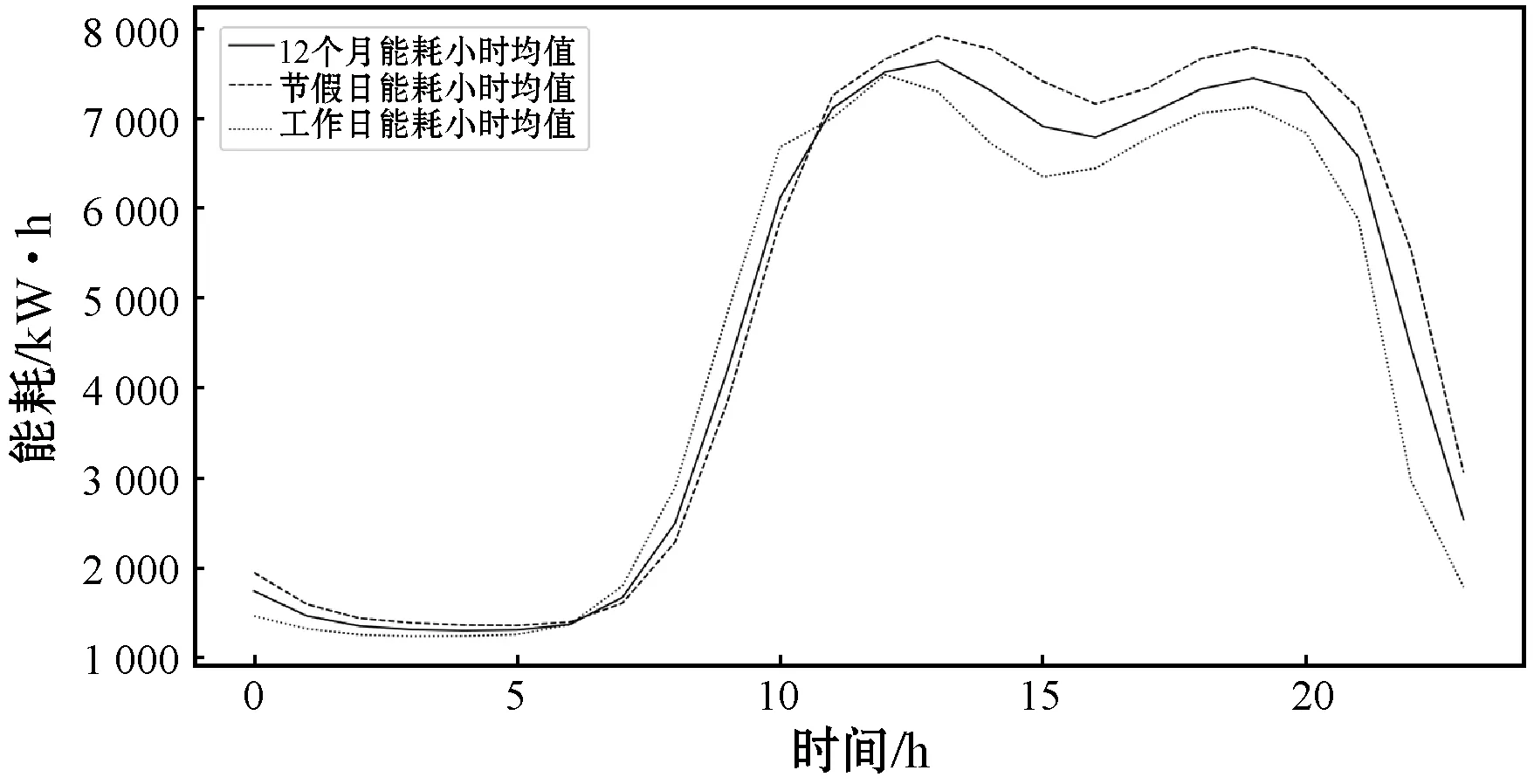
圖6 2018年節假期能耗小時均值對比
根據特征分析,可以看出序列數據在20~30之間趨于穩定,因此選取窗口為1~30進行特征重要度分析。使用決策樹被分割后的信息增益(Gain)選取得到特征值的排序,如圖7所示。
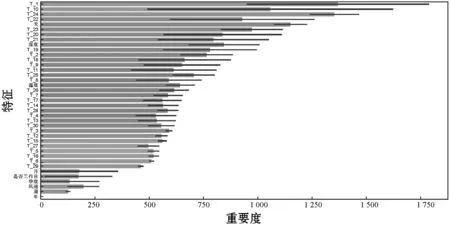
圖7 特征重要度分析
2.2 LightGBM-LSTM組合模型預測
為了充分使用LightGBM模型與LSTM模型的特點,構建使用基于LightGBM與LSTM組合模型的預測方法,使用方差-協方差方法確定兩種模型的權值,方差-協方差方法使用了誤差指標作為權重計算,首先計算對兩種模型預測結果的方差為:
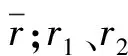
根據如上的方法得到每個預測模型的權重,其中:v1、v2分別表示兩種模型同一時間范圍內計算的方差;w1、w2為兩種模型設定的權重。將每個模型的預測結果加上權重組合,預測結果的組合公式為:
Y=w1y1(t)+w2y2(t)
(19)
式中:計算結果Y為最后組合模型權重相加的預測結果;y1(t)、y2(t)分別表示兩種模型的預測值。以上流程最終構成LightGBM-LSTM模型。圖8為組合模型的預測流程。
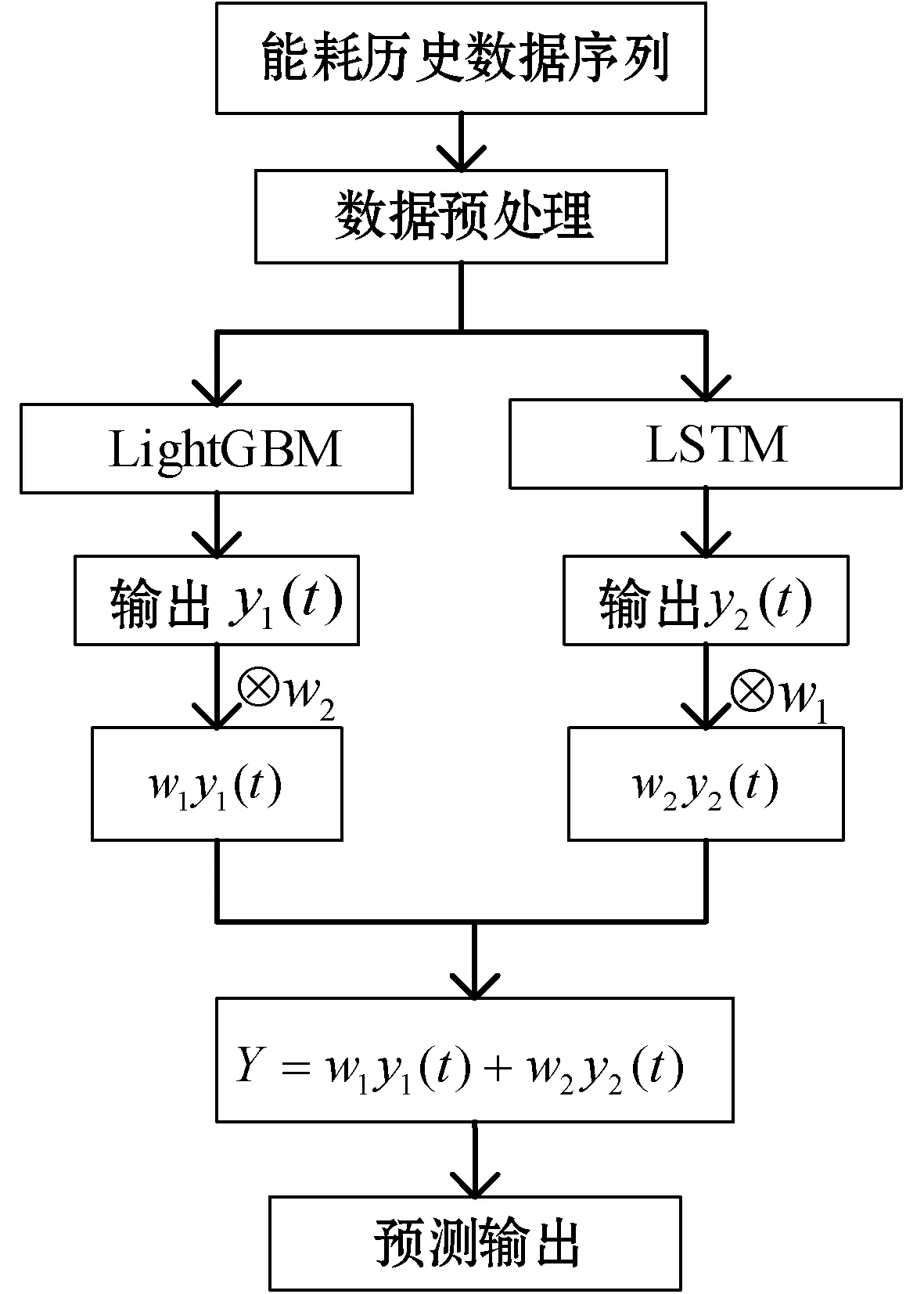
圖8 基于LightGBM-LSTM能耗時間序列預測流程
2.2.1LightGBM模型構建
將歷史序列能耗數據經過周期性變換后,使用LightGBM模型[17]構建,設計此模型的構架流程如圖9所示。
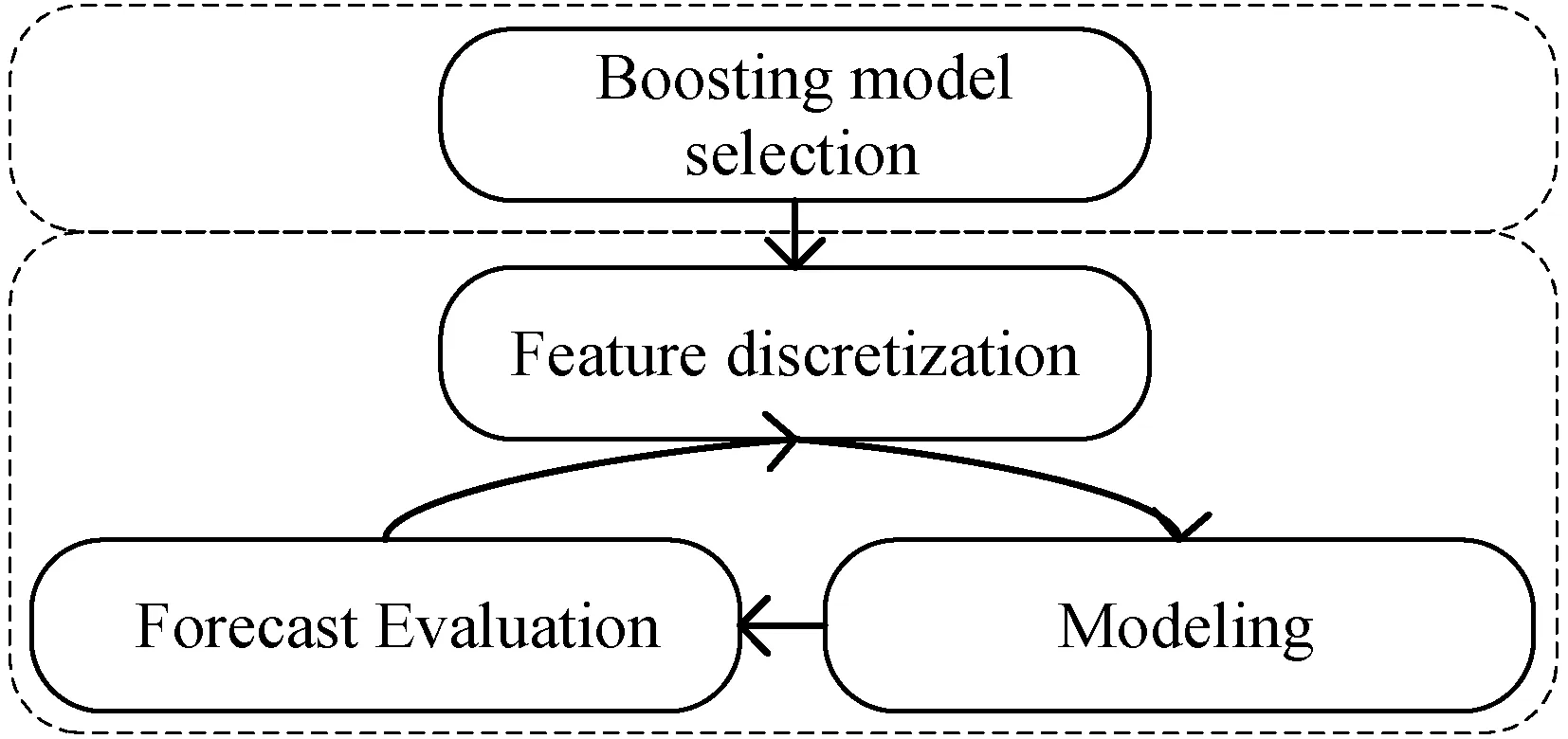
圖9 LightGBM模型構建流程
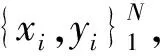
構建模型分類器:
式中:M代表類別數;h(x;αm)是GDBT的弱分類器。設置m次迭代,優化決策樹參數值,得到m次迭代值:
Fm(x)=Fm-1(x)+βmh(x;αm)
(22)
根據式(8)構造殘差作為下一個決策樹的輸入。αm和βm的計算式為:
式中:α和β為迭代中的基函數h的參數和系數。
圖10所示為構建GBDT的框架。
對特征數據遍歷,使用直方圖算法得到容器內離散數據值累積量,劃分決策樹最優分割點。能耗歷史數據中的噪聲部分會在真實數據值附近緩慢波動。使用MEF算法將關聯較少的特征綁定部分密集特征上,通過圖9循環迭代的方式訓練模型。
2.2.2LSTM模型構建
為了準確地預測歷史能耗數據,對LSTM眾多參數和網絡方法設置,包括對學習率(Learning Rate)、梯度優化控制等,使用梯度優化方法Adam算法[18]:
mt=μ×mt-1+(1-μ)×gt
(25)
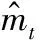
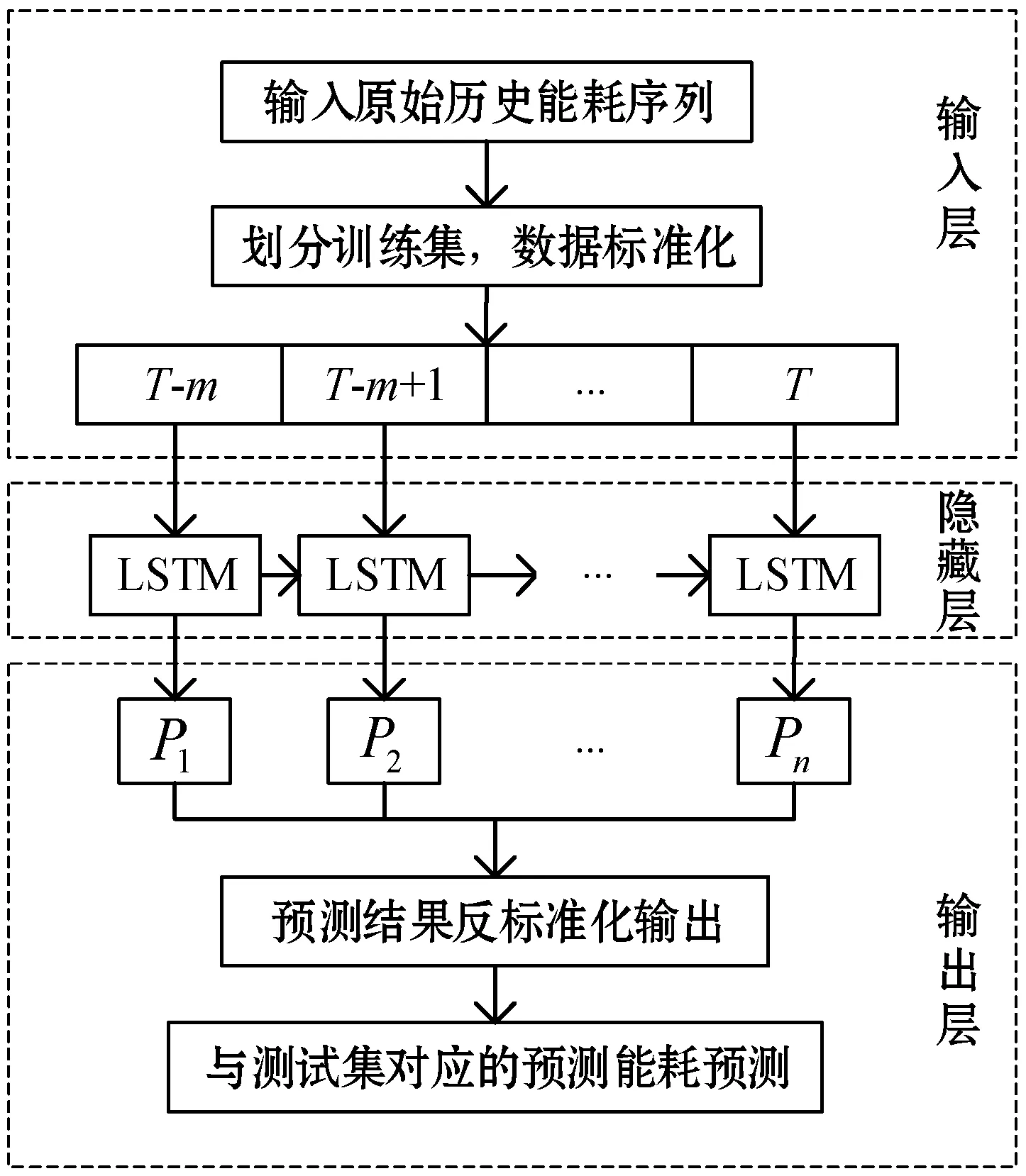
圖11 LSTM預測能耗數據框架
根據綜上所述,根據所設計的LSTM預測能耗的框架結構進行訓練,訓練過程如下:
(1) 定義能耗原始數據序列:X={x1,x2,…,xn}。
(2) 初始化數據集,為了加快訓練速度,使用min-max標準化方法對數據集進行標準化處理,在訓練結束后,對預測結果進行反標準化輸出,與原始數據比較。這里使用的min-max標準化與反標準化為:
(3) 設置LSTM模型參數,根據經驗進行初始化,設計訓練迭代次數step,迭代次數涉及從150逐漸遞增,每次遞增步長為100,多次實驗找到最優的迭代次數。
(4) 對數據集進行數據集劃分,將原始數據集序列劃分訓練集、驗證集和測試集。定義{r,m,s}為訓練集、驗證集與測試集的長度。
(5) 根據第4節特征選取,設置向前取的窗口長度L=24,模型輸入輸出為:
P=LSTMforward{Xp,Cp-1,…,Hp-1}
(32)
式中:LSTMforward表示LSTM前向傳播計算。
(6) 選取均方根誤差作為誤差計算,設定損失函數為最小化誤差。
(7) 通過不斷迭代,更新權重,得到訓練好的LSTM模型,最終應用LSTM模型對原始數據進行預測,輸出預測結果。
3 實驗與結果分析
實驗采用2018年1月1日至2019年11月30日作為訓練數據,將訓練數據自動劃分為6 ∶1比例的訓練集和驗證集,使用2019年12月1日至2019年12月31日作為預測數據。根據3.1節特征處理,得到表1所示特征統計表。
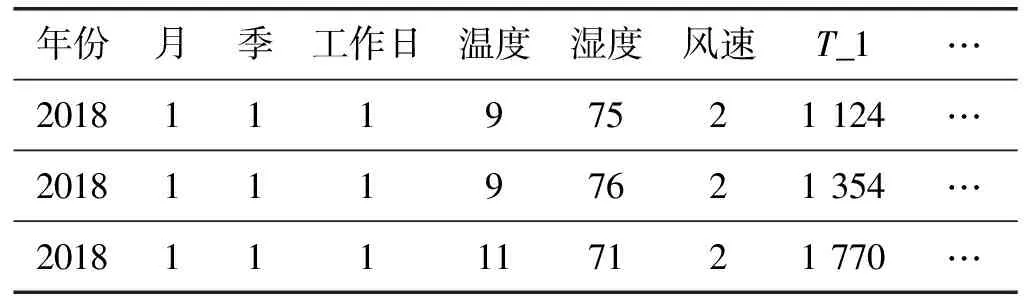
表1 某商業建筑歷史能耗特征統計
為了更好地判定預測結果準確度,根據文獻[19],選取指標函數均方根誤差(RMSE)、相對誤差(CV-RMSE)、使用平均絕對誤差(MAE)作為額外的評估指標,可以更加準確地評估組合模型預測的效果。三種評估指標的表達式為:
使用驗證集選取模型的權重系數,計算每天數據的權重系數,最終取每種權重系數的均值作為最后的權重系數,經過均值化的權重系數w1=0.5、w2=0.5。圖12是組合模型預測12月份小時均值,可以看出預測的效果符合節假日影響因素,在節假日時期,能耗的使用偏高。

圖12 組合模型預測結果的12月份小時均值
圖13展現了組合模型的預測效果,由于組合模型的真實值與預測值相差很小,所以使用了按天和周的預測數值做進一步分析,可以看出組合模型預測效果基本介于LightGBM和LSTM之間,相對有效。
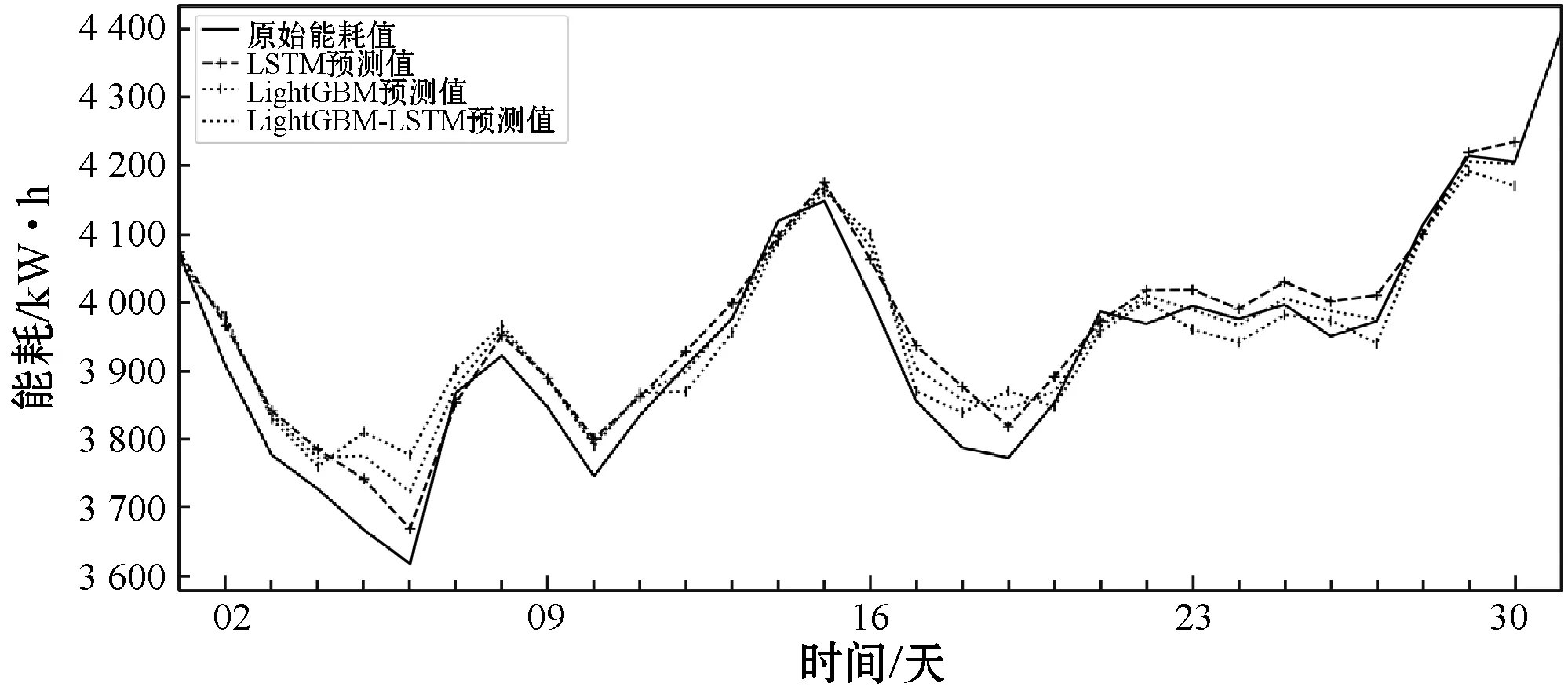
(a) 建筑能耗序列模型每天預測結果
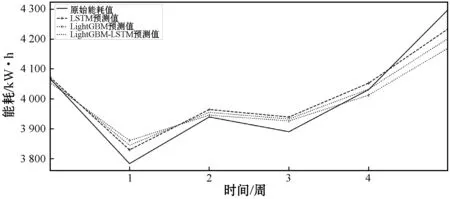
(b) 建筑能耗序列模型每周預測結果圖13 能耗預測結果
為了進一步驗證LightGBM-LSTM模型的性能,類比文獻[20],本文選取了幾種算法做對比實驗,將所選取的模型與本文設計的LightGBM-LSTM組合模型實驗結果做對比,使用24 h的滑動窗口均值擬合,如圖14所示,LigthGBM-LSTM預測效果相對較好。
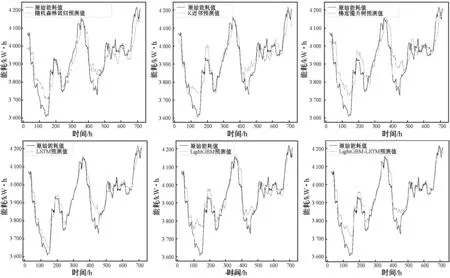
圖14 24 h滑動窗口擬合均值模型對比
指標評估結果如表2所示,可以看出,在單項模型中,LSTM與LightGBM模型預測的誤差較小。LightGBM-LSTM組合模型的CV-RMSE誤差為3.08%,與其他各種單項模型相比相對最小,MAE的誤差指數也是最小。這表明LightGBM組合模型通過權重組合的方式,對預測精度做了提升。
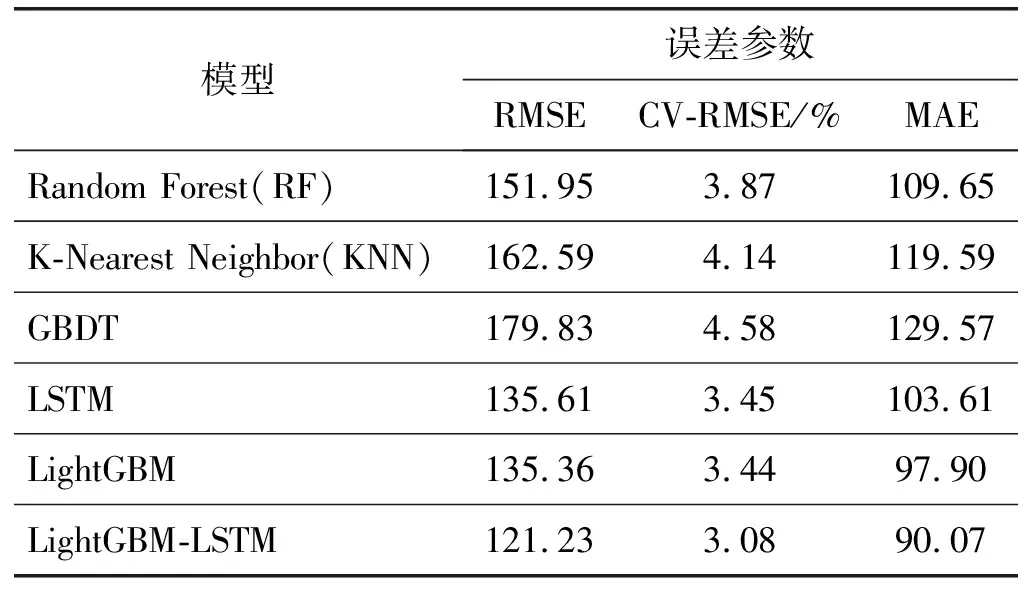
表2 模型性能對比
4 結 語
分析建筑能耗使用規律和相關特征對企業節約成本、節約資源使用有著重要作用。本文依據上海某大型商業建筑歷史能源使用序列,提出一種基于LightGBM-LSTM組合模型預測的方法,構建經LightGBM模型與LSTM模型的方差協方差方法加權預測模型,并且與組合前單項模型以及其他幾種經典的機器學習模型進行實驗對比。實驗結果表明,LightGBM模型與LSTM模型本身的單項模型的預測能力都高于其他模型的預測能力,經過組合后的模型的預測性能優于其他模型,表現了LightGBM對特征合并以及LSTM時間序列預測的優越性,總體來說,通過加權方式,充分發揮了兩種模型的優勢。
本文只設計了兩個優勢不同的模型的組合預測,針對建筑能耗短期數據做出的預測,未來可以在此基礎上設計能耗長期預測的方法。后續會繼續改進LSTM模型相關實驗,選取更多的特征因子做進一步研究,尋求更優秀的建模方式以及提升長期預測效果的方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北方建筑(2021年6期)2021-12-31 03:03:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年10期)2020-11-07 03:15:36
現代裝飾(2020年6期)2020-06-22 08:43:12
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
