一種基于勢能模型的數據流聚類算法
2022-12-03 02:02:12劉永堅唐伶俐
計算機應用與軟件 2022年11期
舒 越 解 慶 劉永堅 唐伶俐
(武漢理工大學計算機科學與技術學院 湖北 武漢 430070)
0 引 言
隨著信息技術不斷發展,信息的傳播效率不斷提高,各種信息充斥著整個世界,各種高效的智能化數據采集技術投入市場應用,使信息數據的處理能力不斷增強,而如何更加精準地從大量信息中挖掘出有價值的信息,是近些年學者們關注的重點之一[1]。隨著數據流的爆發增長,比如金融數據、Web日志數據和視頻監控數據等,數據流挖掘引起了學者們的關注[2]。數據流[3]是一個連續不斷的數字信號序列,具有以下三個特性[4]。(1) 無限性:因為數據流持續不斷地產生,因而數據點的數量是無限的,不能直接將其全部存儲到內存中。(2) 動態演變性:數據分布和特征隨時間推移而不斷變化。(3) 實時性:數據流實時產生,需要被實時處理。這些特點給數據流處理帶來了不小的挑戰[5-6]:由于數據流無法全部存儲在內存中,對數據流只能掃描一次;由于數據流的動態演變性,隨著時間的推移,數據可能發生變化,即“概念漂移”問題;需要具有處理離群點的能力。
很多旨在解決數據流聚類問題的算法已經被提出,其中大部分是基于傳統聚類算法擴展而來,如:K-means算法、DBSCAN算法和Affinity Propagation Clustering算法等,將這些傳統聚類算法改進適用于數據流聚類。除此之外,很多數據流聚類算法沿用在線/離線兩階段數據流聚類框架[7],在線階段旨在構建概要數據結構,離線階段根據這些概要數據結構使用聚類算法得到最終聚類結果。由于大部分數據流聚類算法以距離作為相似度度量標準,這造成對噪點敏感的問題,聚類效果不理想。
針對這個問題,本文提出一種基于勢能模型的層次聚類算法PHAStream,該算法結合在線/離線兩階段數據流聚類框架[7]和基于勢能模型的層次聚類算法PHA[8],在線階段采用融合勢能和距離的相似度度量標準更新微簇,判斷新到達數據點是否合并進現有微簇或新建微簇,并每隔一定時間采取剪枝策略刪除過期的微簇,調整所有微簇的類型;離線階段計算所有正常微簇的勢能,構建邊緣加權樹和樹狀圖,得到最終聚類結果。
本文的主要貢獻包括:(1) 使用一種新的概要數據結構,它不僅記錄數據點屬性的統計信息、權重信息和時間戳信息,還有微簇之間的距離信息。它可以快速構建距離矩陣,方便計算微簇的勢能,為后續基于勢能和距離的相似度度量標準和微簇聚類提供基礎。(2) 以勢能和距離為相似度度量標準,在線階段判斷新到達數據點可能合并的微簇,然后根據勢能判斷是否合并進該微簇或新建微簇。傳統以距離為相似度度量標準的方法中,新到達數據點是否合并進微簇會受到噪點的干擾,以勢能和距離為相似度度量標準,可以減少噪點的干擾。(3) 將基于勢能的層次聚類算法PHA改進適用于數據流聚類,可以減少噪點對聚類的影響,提高聚類效果。
1 相關工作
目前學術界對數據流聚類算法的研究已經取得不少成果,主要分為基于劃分的方法、基于層次的方法、基于密度的方法、基于網格的方法和基于模型的方法五種。
第一種是基于劃分的數據流聚類方法,實踐操作較為簡單,但必須在操作之前對聚類簇的數量進行設置,數據流的分布形態在初期階段很難明確,聚類簇的數量很難得到準確的評估和預測。比如,Youn等[9]提出使用滑動窗口的基于劃分的數據流聚類算法,該算法為每個窗口移動生成集群,由于在所有更改的窗口上重復進行聚類,會造成內存和計算時間方面的低效,所以此算法僅考慮窗口的插入和刪除元組。
第二種是基于層次的數據流聚類方法,在數據的劃分方面以微簇為主。如CluStream算法[7],該算法提出了在線/離線兩階段數據流聚類框架,在線階段以增量的方式更新微簇,離線階段根據用戶要求,使用K-means算法對微簇進行聚類。該算法操作簡單,但是基于距離的相似度度量使得其對噪點較為敏感。
第三種是基于密度的數據流聚類方法,能夠實現對任意形狀的數據流進行劃分,但是在計算過程中需要設置大量初始參數。如DenStream算法[10],該算法沿用在線/離線兩階段數據流聚類框架,在線階段將新到達的數據點分配給距離它最近的微簇,進行微聚類,同時提出了核心微簇、潛在核心微簇和噪點微簇來區分正常微簇數據、可能成為正常簇的微簇數據和噪點數據;離線階段使用DBSCAN算法來聚類。
第四種是基于網格的數據流聚類方法,對聚類數據的形狀沒有約束限制,但是網格粒度的大小對聚類的質量有較大影響。D-Stream算法[11]是基于網格的數據流聚類算法之一,該算法沿用在線/離線兩階段數據流聚類框架,在線階段將每個輸入的數據點映射到網格中,離線階段對這些密度網格進行聚類,并且取出稀疏的網格。張冬月等[12]提出基于網格耦合的數據流聚類算法,該算法在聚類過程中,不再片面地單獨處理網格,而是將每個網格之間的耦合關系納入考慮的范圍內,網格之間的耦合關系可以更加精準地表現數據點之間的相似度,從而提升聚類質量。
第五種是基于模型的數據流聚類方法,需要大量的學科領域知識作為輔助,在使用中需要假設模型的支持。例如,朱穎雯等[13]提出的基于歐拉核的數據流聚類算法,該算法首先采用歐拉核的方式,顯式地將數據點映射到同一維度的復數特征空間,接著在這個特征空間中使用GNG(Growing Neural Gas)模型進行聚類。
2 勢能模型
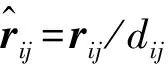
假設無窮遠處的勢能為0,那么數據點xi來自數據點xj的勢能為:
(2)
在勢能模型中,只需要關注勢能的相對值,萬有引力常數并沒有影響,所以為了方便計算,將G設置為1,并假設每個數據點的質量為1,于是式(2)可改寫為:
數據點xi的勢能,表示為來自其他所有數據點對它產生的勢能:
(4)
式中:N就是所有數據點的個數。
距離閾值ε的選取需要考慮數據點的分布,可以通過距離矩陣來進行計算:
ε=mean(MinDi)/S
(6)
式中:MinDi表示數據點xi和其他數據點之間的最短距離;S為比例因子。由文獻[14]可知,取S=10時,模型可以達到較好的平衡狀態。
在勢能模型中,通常相似的數據點之間勢能的差值也比較小,距離也更近,基于勢能和距離的聚類方法以該規律為基礎進行設計。
3 基于勢能模型的數據流聚類算法
本節詳細介紹基于勢能模型的數據流聚類算法PHAStream,該算法結合在線/離線兩階段數據流聚類框架和基于勢能模型的層次聚類算法PHA,算法的流程如圖1所示。
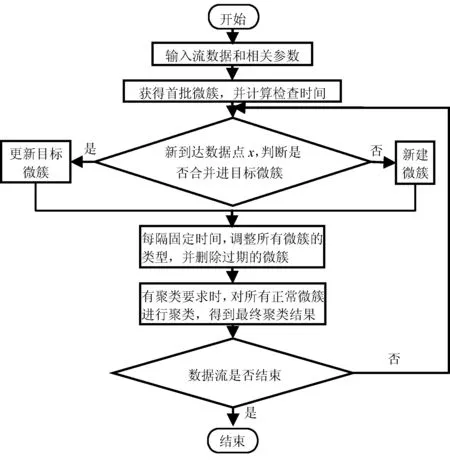
圖1 PHAStream算法流程
3.1 PHAStream算法初始化階段
數據流是一段連續不斷的序列點X={X0,X1,…,Xn,…},每個數據點到達的時間分別為T={t0,t1, …,tn,…},每個數據點在數據空間中是一個d維向量。
考慮不同到達時間的數據點的重要性,對每個數據點加權,利用一個衰減系數來確定權重與時間的關系。使用式(7)來作為衰減函數,其中λ>0,并且t表示當前時間戳tcurrent和該點到達的時間戳tarrival的差值,即t=tcurrent-tarrival。
w(t)=2-λt
(7)
在初始化階段,模型初始化參數并把時間戳t設置為0,對初始長度的數據點使用PHA進行聚類,得到首批微簇。對于每個微簇,模型定義聚類特征向量來記錄微簇的統計信息。借鑒StrDip算法[15]的聚類特征向量,本文提出一種改進的聚類特征向量,主要由帶權重的微簇統計信息、微簇的權重和微簇之間的距離信息組成。距離信息可以快速構建距離矩陣,進而快速計算勢能。聚類特征向量以這種形式定義: (CFx1,tl,weight,n,t0,dist_arr)。
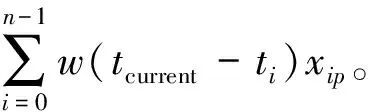
(2)tl: 微簇中最后到達點的時間戳。
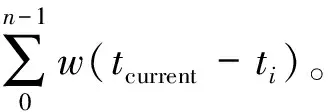
(4)n:微簇中所有數據點的個數。
(5)t0:微簇被創建的時間戳。
(6)dist_arr:當前微簇中心點和所有微簇中心點(包括自己)的距離組成的數組。
基于聚類特征向量,每個微簇的中心可以通過式(8)計算。
3.2 PHAStream算法在線階段
在線階段,對于每個新到達的數據點,尋找其可能合并的微簇,并判斷是否合并進該微簇或者新建微簇,并更新聚類特征向量,每隔固定時間采用剪枝操作,刪除過期的微簇并調整所有微簇的類型。
(1) 尋找目標微簇。當模型接收到一個新數據點的時候,需要在現有微簇中找到與之最相似的微簇,即其最可能合并進的目標微簇。
由文獻[8,16]可知,在勢能場中,距離矩陣和勢能分別反映了數據點的局部和全局分布,同時可以發現同一個簇中的數據點,勢能差值小且相互距離更近,所以這里提出一個新的相似判斷標準pd值,如式(9)所示,來找到新數據點的“目標微簇”。
pd[i]=abs(Φc-Φi)×distci
(9)
式中:Φc表示新到達數據點的勢能;Φi表示微簇i的勢能;distci表示新到達數據點和微簇i的距離,pd[i]則表示新到達數據點跟微簇i的勢能差絕對值和距離的乘積,因為同一個類中的數據點,勢能差值小且相互距離越近,所以取pd[i]最小值時,微簇i是新到達數據點的“目標微簇”。
(2) 微簇的合并準則。當找到目標微簇之后,模型需要判斷新到達點需要合并到目標微簇中,還是新建一個微簇。為此,需要設計一個合并準則來進行判斷。
由文獻[17]可知,一般情況下,由于數據集中噪點的數量是遠小于正常數據點的數量,同時噪點的分布也相對稀疏,從數據點的概率分布特點和勢能大小分析可知,噪點的勢能相對正常數據點更大,從勢能角度,這一特點正是區別正常數據點和噪點的關鍵。如圖2所示[17],是一個帶有噪點的數據集,將每個數據點的勢能按從小到大排序,如圖3所示[17],會出現一個“拐點”C,這個C點被稱為“勢能拐點”,“勢能拐點”之后的數據點被認為是噪點。
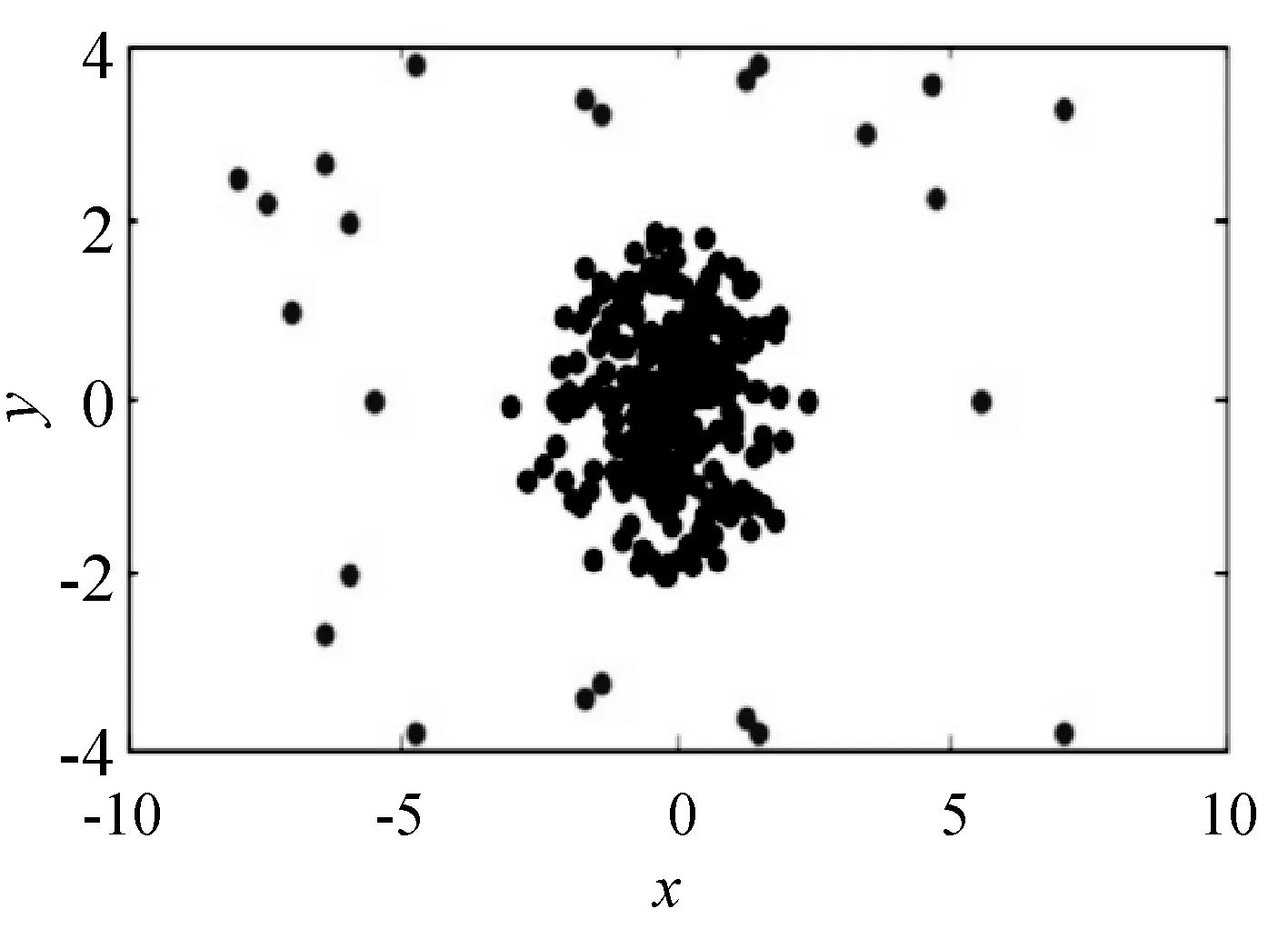
圖2 含有噪點的數據集

圖3 勢能遞增圖
將“勢能拐點”作為一個新的合并準則,來判斷新到達數據點是否合并進“目標微簇”。根據上述內容,由于此時已經可以求出每個微簇的勢能,將新到達的數據點構成的微簇和其他所有微簇的勢能按從小到大的順序排列,構成勢能遞增圖,根據式(10)找到當前勢能場下的“勢能拐點”。如果新到達數據點微簇的勢能和“目標微簇”的勢能均在“勢能拐點”之前,那么在當前勢能場下,新到達數據點微簇和 “目標微簇”均屬于正常數據點,所以將新到達數據點合并進“目標微簇”中。否則,以新到達的數據點新建一個微簇。
(Φi-Φi+1)×(Φi+1-Φi+2)≤0
(10)
(3) 更新微簇與新建微簇。根據微簇的合并準則,當新到達數據點和其目標微簇的勢能都在“勢能拐點”之前時,那么就將新到達的數據點合并進目標微簇中;否則,以新到達數據點單獨成為一個微簇,構建CF向量。
假設直到tc才有數據點x被吸收進微簇i,并且i接收上一個點的時間戳為tl,那么帶有權重的微簇統計信息將以下列方式更新[15]:
weight=weight×2-λ(tc-tl)+1
(11)
CFx1=CFx1×2-λ(tc-tl)+x
(12)
通過式(11)和式(12),可以快速地更新一個微簇新的權重weight和CFx1。
CF向量中的dist_arr屬性,記錄著當前微簇和其他微簇之間的距離信息,雖然不是以增量的方式更新,但是更新的代價并不大,因為在新的數據點到達時,要么將新到達數據點合并進某個微簇,要么以新到達的數據點新增一個微簇,如果處于檢查周期,那么就刪除過期微簇,期間這三種操作涉及個別微簇,或者只需要更新每個微簇dist_arr屬性中個別距離值。dist_arr屬性可以大大提高離線階段進行聚類的效率。
(4) 刪除微簇與調整微簇類型。微簇隨著時間推移,會根據衰退函數改變權重,微簇的權重大于等于預設的權重閾值μ,則為正常微簇,反之,則為噪點微簇。
隨著時間的推移,數據流的分布可能發生變化,一些“正常微簇”可能很長時間沒有接收新的數據點,變為“噪點微簇”,這個現象我們稱為“概念漂移”。所以需要每隔固定時間來檢查所有微簇的權重,假設一個“正常微簇”的原始權重恰好是μ,經過Tg個時間戳,這個“正常微簇”剛好變為“噪點微簇”,此時Tg就是“正常微簇”變為“噪點微簇”的最小時間間隔[10,15],即2-λTgμ+1=μ,求得:
為了節省PHAStream算法的運行時間,每隔Tg個時間戳就采用一種剪枝策略:將權重足夠小的微簇刪除。通過式(14)來判斷一個微簇的權重是否足夠小[10,15],微簇的權重下限定義如下:
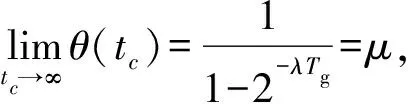
到達檢查時間時,通過式(14)判斷是否存在需要刪除的微簇,如果存在需要刪除的微簇,那么需要更新那些未刪除微簇的dist_arr屬性,將每個dist_arr屬性中與刪除微簇相關的距離信息全部刪除。
3.3 PHAStream算法離線階段
當有聚類要求時,使用改進的PHA(算法1)對所有“正常微簇”進行聚類,將每個微簇當作一個數據點,假設每個數據點的質量為1,那么每個微簇的質量等于微簇中數據點的個數。將每個微簇的dist_arr屬性組合在一起,即此刻所有微簇的距離矩陣,根據勢能模型,即可求出每個微簇的勢能。為了實現所有數據點的聚類,采用一種邊緣加權樹技術[8],基于所有數據的勢能和距離對數據點進行高效組織。將所有數據點中勢能最小的數據點當作“根節點”,記為xroot。
算法1改進的PHA
輸入:距離矩陣dist_matrix_arr, 質量數組mass, 最終聚類簇個數K。
輸出:聚類標簽clusterLabels。
1. 計算每個微簇的勢能,得到勢能數組Potential;
2. 構建邊緣加權樹,并得到父節點數組parent和權重數組weight;
3. 構建樹狀圖,依次合并最相似的微簇,直至微簇個數等于最終聚類簇個數K,得到聚類標簽clusterLabels;
4. 返回聚類標簽clusterLabels
對于每個數據點i,在所有其他數據點中勢能值小于或等于i的所有其他數據點中距i最近的數據點稱為i的父節點[7],并表示為parent[i]。
由式(15)可以找到各自數據點的父節點,其中將根節點xroot的父節點定義為它自己,邊緣加權樹中邊的權重,由數據點和其父節點之間的距離決定[7],即:
weight[i]=disti,parent[i]
(16)
其中,根節點的權重是“無限大”。
可以通過以下步驟來構建邊緣加權樹:(1) 根據勢能模型,求出所有數據點的勢能,并將所有數據點按勢能從小到大的順序排列;(2) 將所有數據點中具有勢能最低值的數據點設置為根節點xroot;(3) 根據數據點的勢能遞增順序,依次找到剩余數據點xi的父節點parent[i],并且將剩余數據點與其父節點之間的距離記錄為weight[i],然后加入到邊緣加權樹中;(4) 輸出最后構成的邊緣加權樹。
3.4 PHAStream算法及復雜度分析
算法2是PHAStream算法的整體步驟,第1-4行是初始化階段,計算檢查時間Tg,使用PHA對初始長度的數據點進行聚類,得到首批微簇并創建CF向量。第5-17行是PHAStream算法的在線階段,對于每個新到達的數據點x,如果數據點x和其目標微簇均在勢能拐點之前,那么就將這個點合并進其目標微簇中,并更新其CF向量。否則,創建一個新的微簇和CF向量。每Tg個時間戳就檢查調整所有微簇的類型,并采用剪枝策略刪除過期的微簇。第18-20行是PHAStream算法的離線階段,當有聚類要求時,根據所有正常微簇的dist_arr屬性構建距離矩陣,計算勢能,構建邊緣加權樹和樹狀圖,得到最終聚類結果。
算法2PHAStream算入:數據流dataStream, 初始長度initNumber, 初始聚類個數q, 最終聚類簇個數K, 權重μ, 衰變因數λ。
輸出:最終聚類結果。
1. 初始化時間戳timestampt= 0;
2. 計算周期檢查時間Tg;
3. 使用PHA對初始長度的數據點進行聚類,得到首批微簇;
4. 為每個微簇構建CF向量,也稱為微簇;
5. while (流數據未結束) do
6.t++;
7. for (每個新到達的數據點x) do
8. 尋找數據點x的目標微簇i;
9. if (數據點x和目標微簇i的勢能均在勢能拐點之前) then
10. 將數據點x合并進目標微簇i;
11. else
12. 新建一個微簇,并構建CF向量;
13. end if
14. end for
15. if (到達檢查時間) then
16. 采用剪枝策略,并調整微簇類型;
17. end if
18. if (當有聚類要求時) then
19. 使用改進的PHA對所有正常微簇進行聚類;
20. end if
21. end while
PHAStream算法的在線階段,計算成本主要在尋找“目標微簇”和合并準則判斷。當新到達數據點尋找“目標微簇”時,需要遍歷一遍現有的微簇,計算現有微簇和新到達數據點的距離,并將此距離更新進每個微簇的dist_arr屬性,時間復雜度為O(n)。合并準則判斷時,根據每個微簇的dist_arr屬性可以構成距離矩陣,進而計算每個微簇的勢能,將每個微簇的勢能按從小到大排序,使用快速排序即可,時間復雜度為O(nlogn)。當到達檢查時間時,遍歷每個微簇檢查其權重,是否存在需要刪除的微簇,如果有,刪除這些微簇,并將剩余未刪除微簇中的dist_arr屬性進行更新,刪除dist_arr屬性中與刪除微簇相關的距離信息,時間復雜度為O(n)。
PHAStream算法的離線階段,當有聚類要求時,根據每個微簇的dist_arr屬性可以構成距離矩陣,將距離矩陣直接傳入PHA,節約初始階段計算距離矩陣的計算成本,接著構建“邊緣加權樹”和“樹狀圖”,根據最終聚類簇個數K得到最終聚類結果,根據PHAStream算法的初始階段所述,此處的時間復雜度為O(n2)。
4 實驗與結果分析
4.1 實驗環境
不失一般性,在所有實驗中都規定每個時間戳只有1個數據點到達,并且到達的數據點經過在線階段處理后,在指定時間戳陸續執行聚類。將本文算法效果與CluStream算法[6]、DenStream算法[10]、StrAP算法[18]和TEDA算法[19]進行對比,算法實驗平臺為:操作系統Ubuntu 18.04,Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40 GHz,內存64 GB,Python版本3.7。
4.2 數據集描述
數據集采用KDD-CUP99數據集和一組真實空氣質量數據集進行測試。
KDD-CUP99數據集,一共有4 898 431個數據點,每個數據有41個維度,本實驗選取34個連續屬性,使用前1%樣本數據集進行測試,數據集總共有50 000條記錄,每隔5 000個數據點進行一次聚類測試。
真實空氣質量數據集,選取北京市過去2016年1月1日到2019年12月31日,每天24個小時的空氣質量數據,共有35 064條數據,其中無效數據有5 026條,故最終使用的有效數據為30 038條,每條數據具有7個屬性,只取PM2.5、PM10、CO、SO2、NO2、O3作為測試屬性,使用AQI作為分類標簽,如表1所示。每隔5 000個數據點進行一次聚類測試。
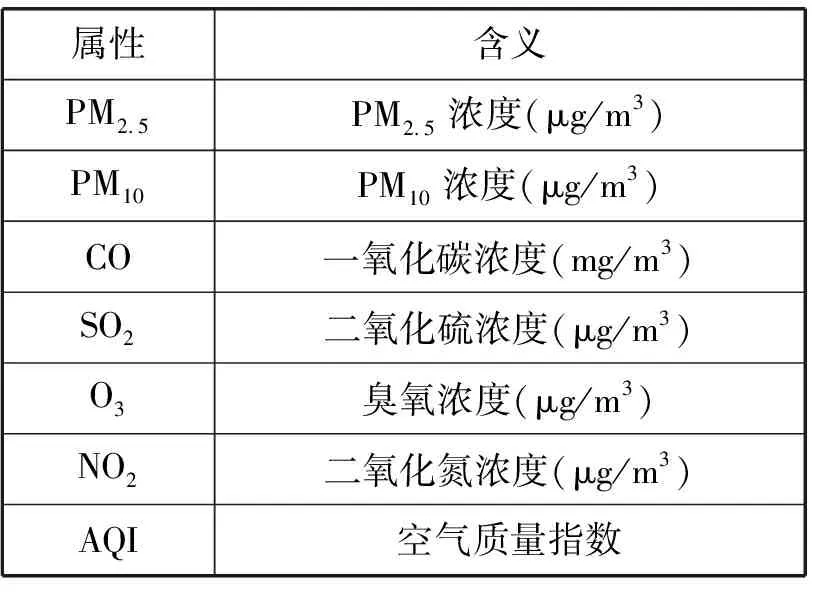
表1 空氣質量數據集屬性
4.3 度量標準
本實驗以聚類質量SSQ和聚類純度Purity作為度量標準。聚類質量SSQ的定義如下:
SSQ=∑d(pi,ci)2
(17)
式中:pi是每個數據點;ci是pi最近的聚類微簇中心。即通過計算所有點到各自聚類中心距離的平方和來衡量聚類質量SSQ,SSQ越小,說明效果越好。
聚類純度Purity的定義如下:
(18)
4.4 模型參數設置
本實驗本文中所有試驗的初始長度initNumber均為500, 通過控制變量法,來對區分正常微簇和噪點微簇的權重μ、衰變因數λ、初始聚類個數q和最終聚類簇個數K進行參數設置實驗。由4.3節聚類度量標準可知,SSQ越小越好,Purity越大越好,定義變量p來表示由SSQ和Purity總體反映的聚類效果:
故變量p的值越小,聚類效果越好,通過控制變量法,來進行參數設置實驗。
圖4至圖7分別是KDD-CUP99數據集對權重μ、衰變因數λ、初始聚類個數q和最終聚類簇個數K參數的聚類效果對比圖。根據式(19)可知,p值越小越好,所以μ值、λ值、q值和K值分別在區間[1.7, 2.0]、 [0.1,0.15]、[325,450]、[5,15]之間取值為佳。綜合實驗得出,當μ=2.0,λ=0.13,q=400,K=15時聚類效果最好。
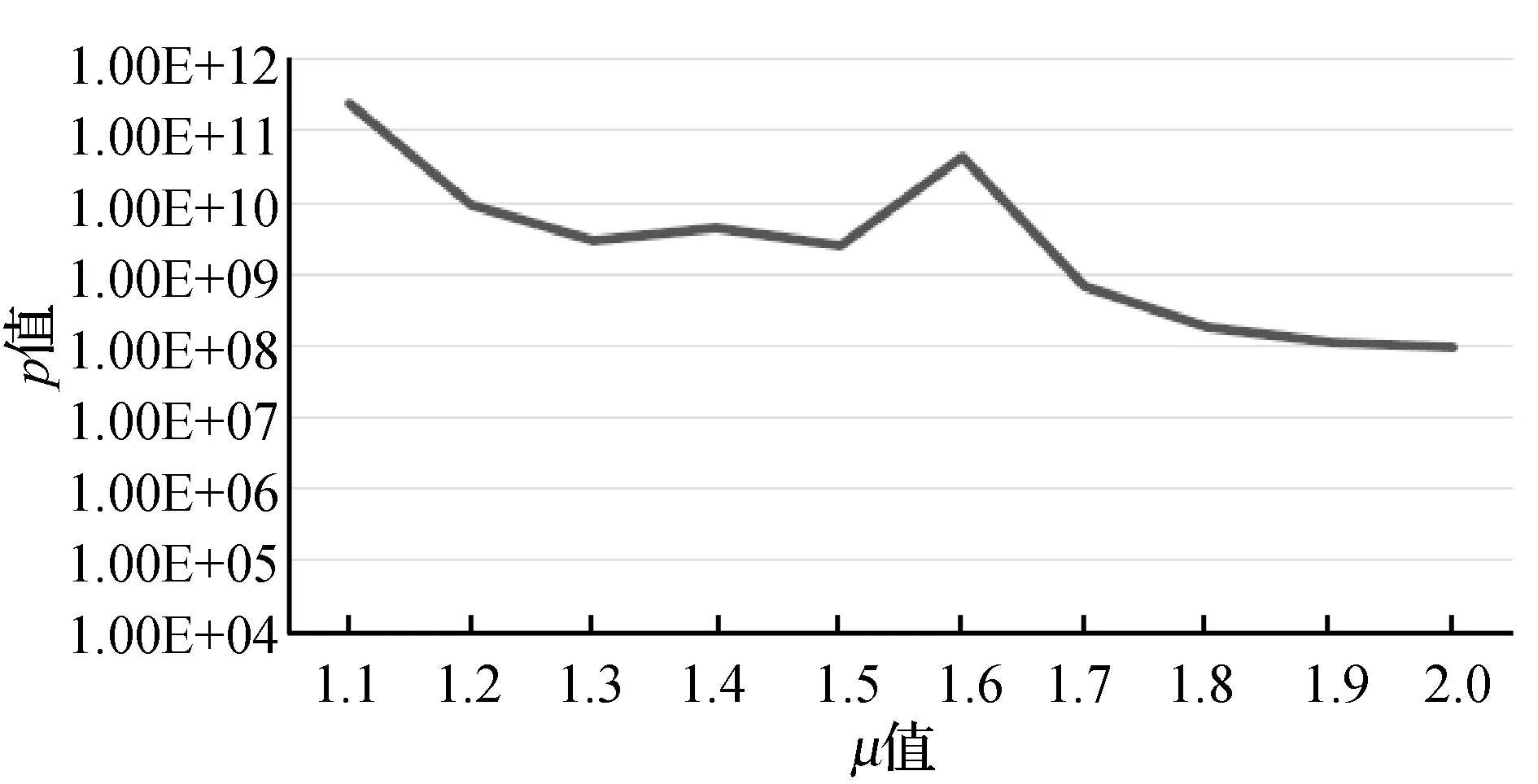
圖4 KDD-CUP99數據集不同μ值聚類效果對比圖
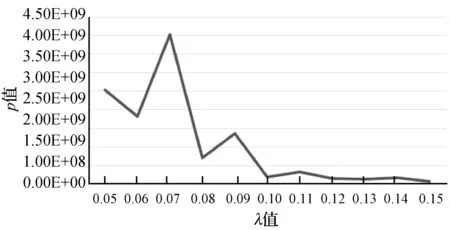
圖5 KDD-CUP99數據集不同λ值聚類效果對比圖
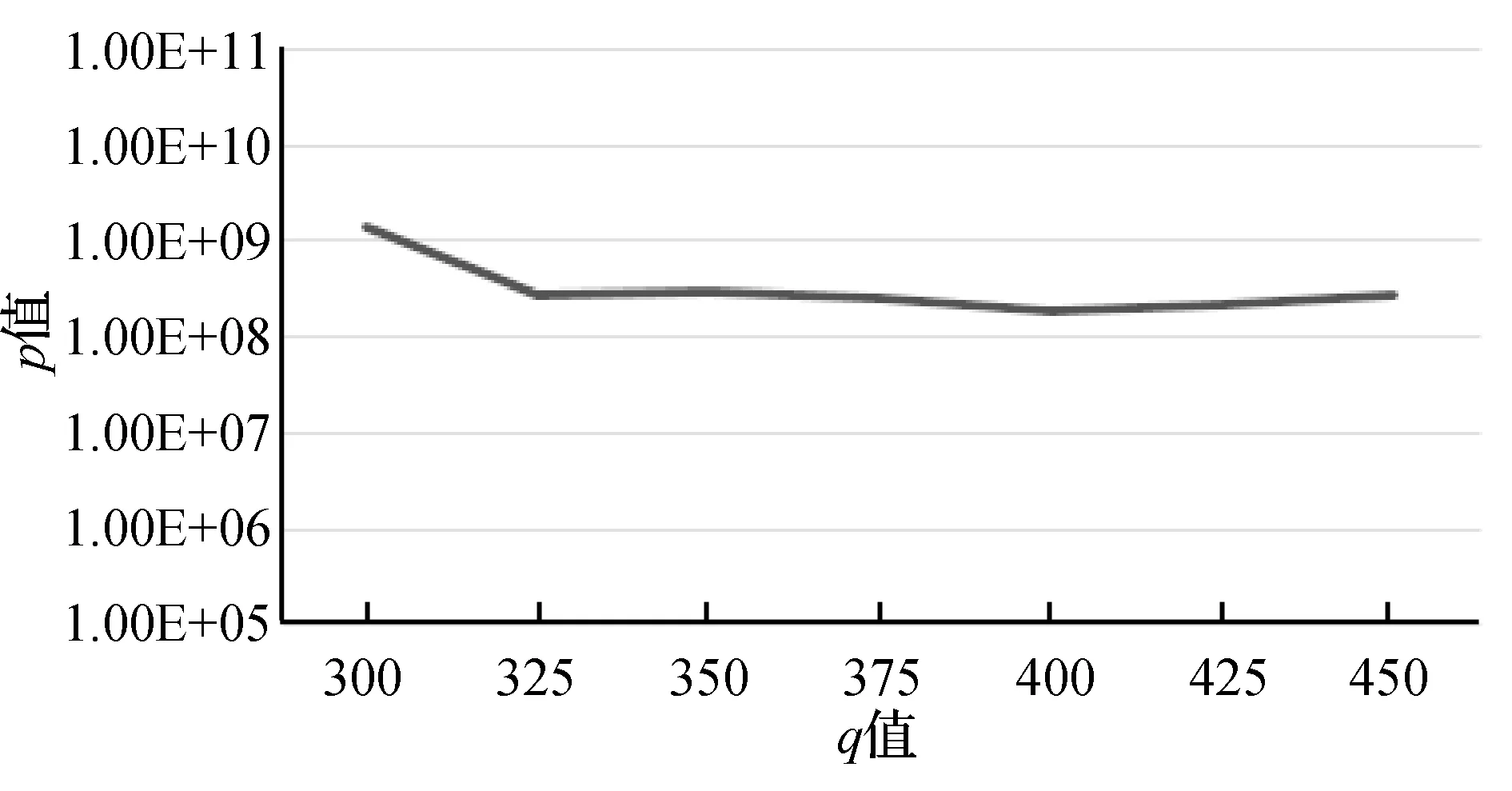
圖6 KDD-CUP99數據集不同q值聚類效果對比圖
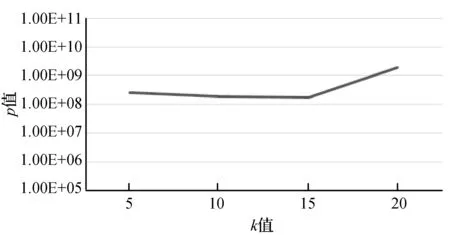
圖7 KDD-CUP99數據集不同K值聚類效果對比圖
圖8至圖11分別是空氣質量數據集對權重μ、衰變因數λ、初始聚類個數q和最終聚類簇個數K參數的聚類效果對比圖。根據式(19)可知,p值越小越好,所以μ值、λ值、K值分別在區間 [1.5, 1.9]、[0.6,0.8]、[5,9]之間取值為佳,由于q值波動較大,所以在300、350、400、450這幾個值中選擇。綜合實驗得出,當μ=1.6,λ=0.6,q=400,K=6時聚類效果最好。
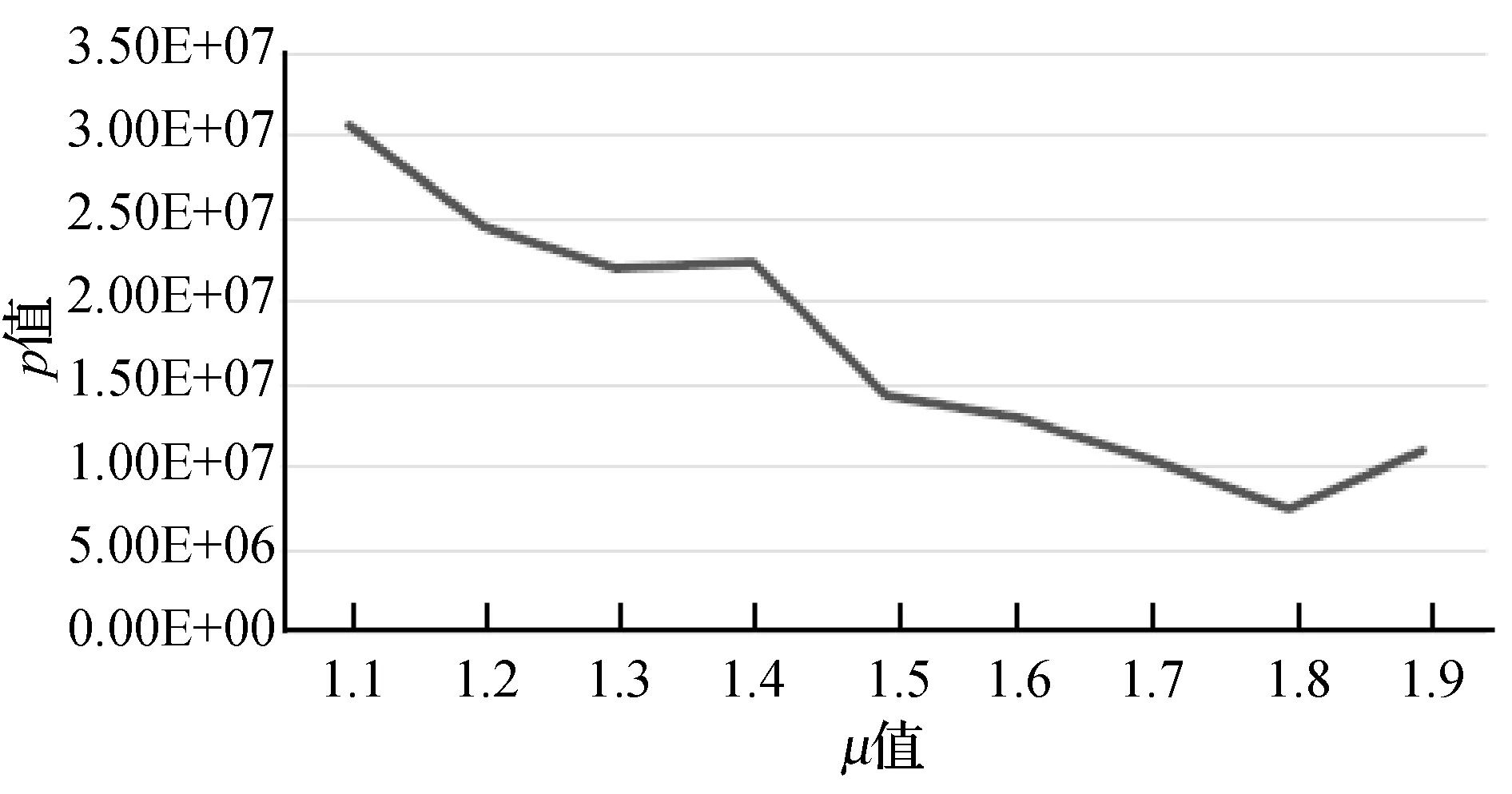
圖8 空氣質量數據集不同μ值聚類效果對比圖

圖9 空氣質量數據集不同λ值聚類效果對比圖
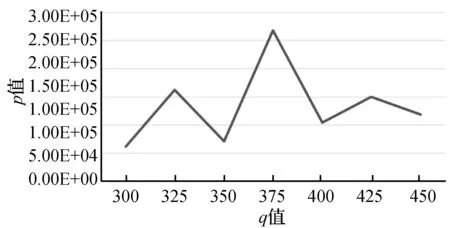
圖10 空氣質量數據集不同q值聚類效果對比圖
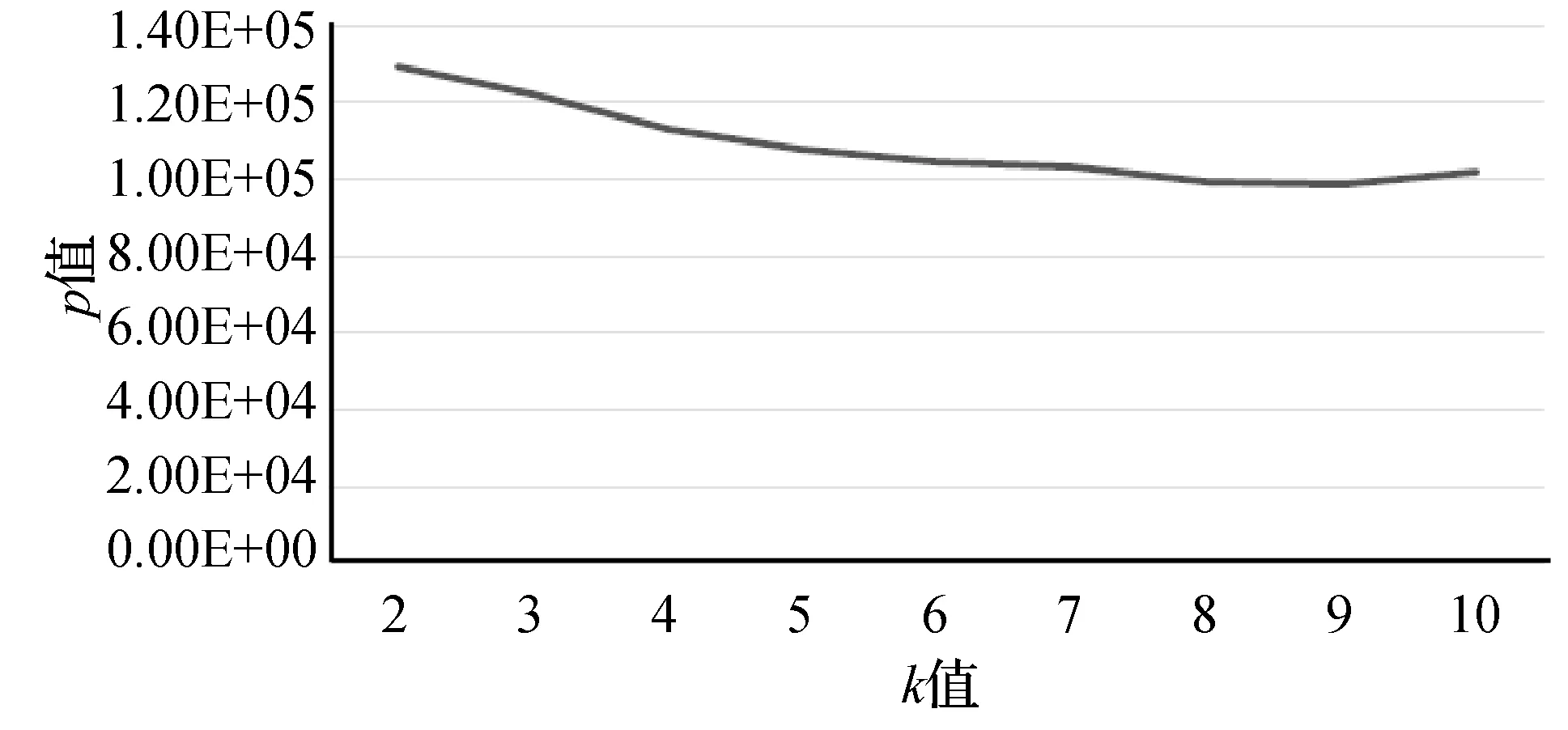
圖11 空氣質量數據集不同K值聚類效果對比圖
4.5 聚類質量驗證
圖12和圖13分別反映了五種數據流聚類算法在KDD-CUP99數據集和空氣質量數據集上的聚類質量。在KDD-CUP99數據集中,隨著數據點增多,CluStream算法和DenStream算法的SSQ值小幅度上升,StrAP算法一直保持穩定的SSQ值,TEDA算法一開始維持較低的SSQ值,后來開始上升。PHAStream算法雖然處于小幅波動,但是總體還是比其他四類算法低1~3個數量級。
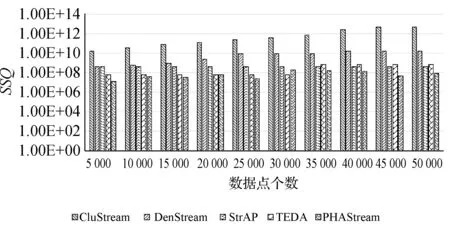
圖12 KDD-CUP99數據集聚類質量對比圖
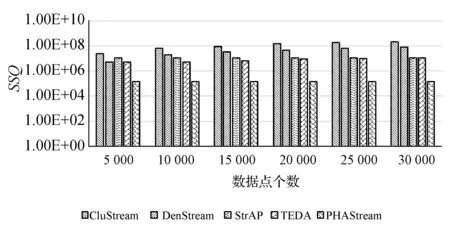
圖13 空氣質量數據集聚類質量對比圖
在空氣質量數據集中,五種算法均保持穩定的SSQ值,并且PHAStream算法一直具有更低的SSQ值。因為SSQ值越低表示聚類質量越高,所以PHAStream算法具有更高的聚類質量。
4.6 聚類純度驗證
圖14和圖15分別反映了五種數據流聚類算法在KDD-CIP99數據集和空氣質量數據集上的聚類純度。在KDD-CUP99數據集中,隨著數據點的增多,CluStream算法一開始保持較高的聚類純度,之后一直處于較低的水平,因為噪點的增多,CluStream算法是以距離為相似度度量,且對所有數據點進行聚類,故聚類純度不理想。DenStream算法和StrAP算法一直維持較高且較為穩定聚類純度,TEDA算法總體維持較高的聚類純度,PHAStream算法雖然在第20 000和第45 000個數據點時聚類純度小幅降低,但是總體具有更好的聚類純度。
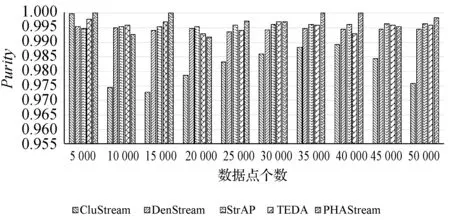
圖14 KDD-CUP99數據集聚類純度對比圖
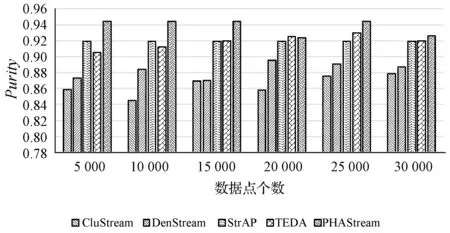
圖15 空氣質量數據集聚類純度對比圖
在空氣質量數據集中,CluStream算法和DenStream算法整個過程有小幅度波動,但是兩者總體聚類純度不高,StrAP算法聚類純度較為穩定,TEDA算法一開始聚類純度不高,但是隨著數據點的增多,聚類純度基本與StrAP算法持平,PHAStream算法相對其他四種算法一直具有更高的聚類純度,這得益于勢能場模型下,依據距離矩陣和勢能共同作為相似度度量,故PHAStream算法具有更高的聚類純度。
4.7 抗噪性驗證
為了驗證本文算法的抗噪性,將空氣質量數據集進行適當修改,改為含有5%左右噪點的數據集,各算法在此數據集上進行實驗,并求出所有統計時刻的平均值來進行前后對比。
由圖16和圖17可知,在加入5%左右的噪點后,CluStream算法在聚類質量和聚類純度上相對其他幾種算法變化較大,這是由于CluStream算法是以距離作為相似度度量標準,對噪點較為敏感,本文的PHAStream算法使用勢能和距離來作為相似度度量標準,兩者分別反映了數據點的全局與局部分布,減少噪點的干擾,具有更好的聚類效果。
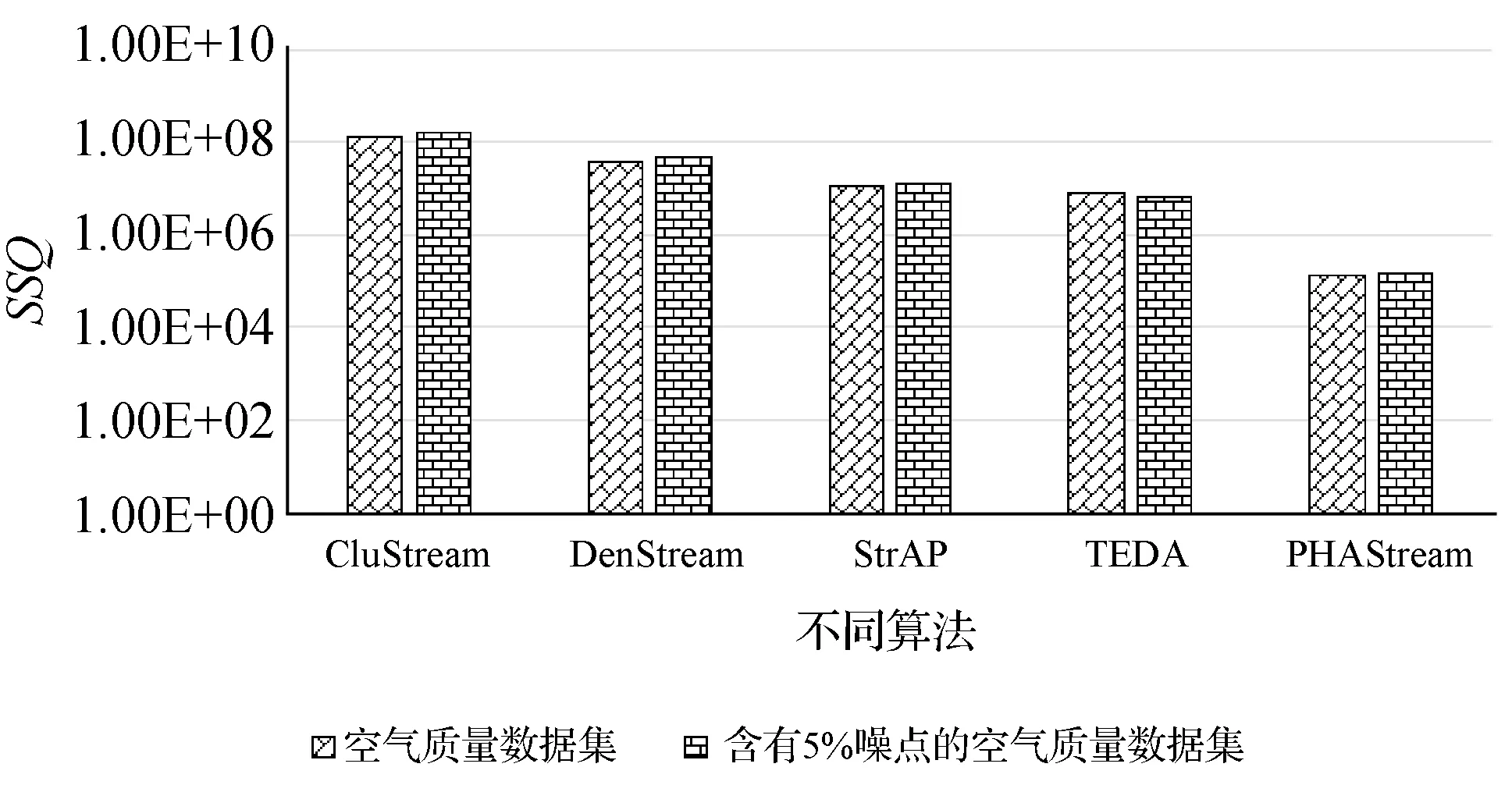
圖16 聚類質量對比圖

圖17 聚類純度對比圖
4.8 時間效率驗證
圖18和圖19分別反映了五種數據流聚類算法在KDD-CUP99數據集和空氣質量數據集的執行時間對比圖。PHAStream算法在整個階段中均保持更低的時間消耗,這得益于新的概要數據結構中的dist_arr屬性和邊緣加權樹技術,當有聚類要求時,可以快速構建距離矩陣,計算出勢能,進而得到聚類結果。
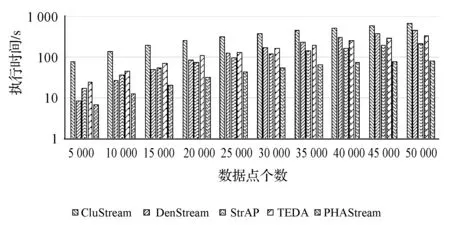
圖18 KDD-CUP99數據集時間效率對比圖
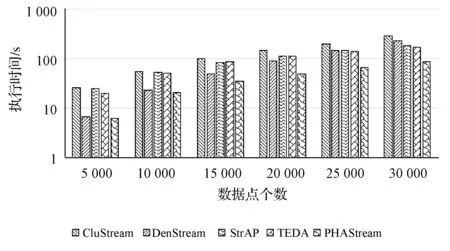
圖19 空氣質量數據集時間效率對比圖
4.9 內存消耗驗證
圖20為五種數據流聚類算法在KDD-CUP99數據集和空氣質量數據集的內存消耗對比圖。PHAStream算法相對于其他四種算法均消耗更多的內存,這主要是因為其概要數據結構中的dist_arr屬性,因為該屬性存儲了微簇之間的距離信息。PHAStream算法雖然消耗了更多的內存,但是在其他聚類效果上表現更優秀。
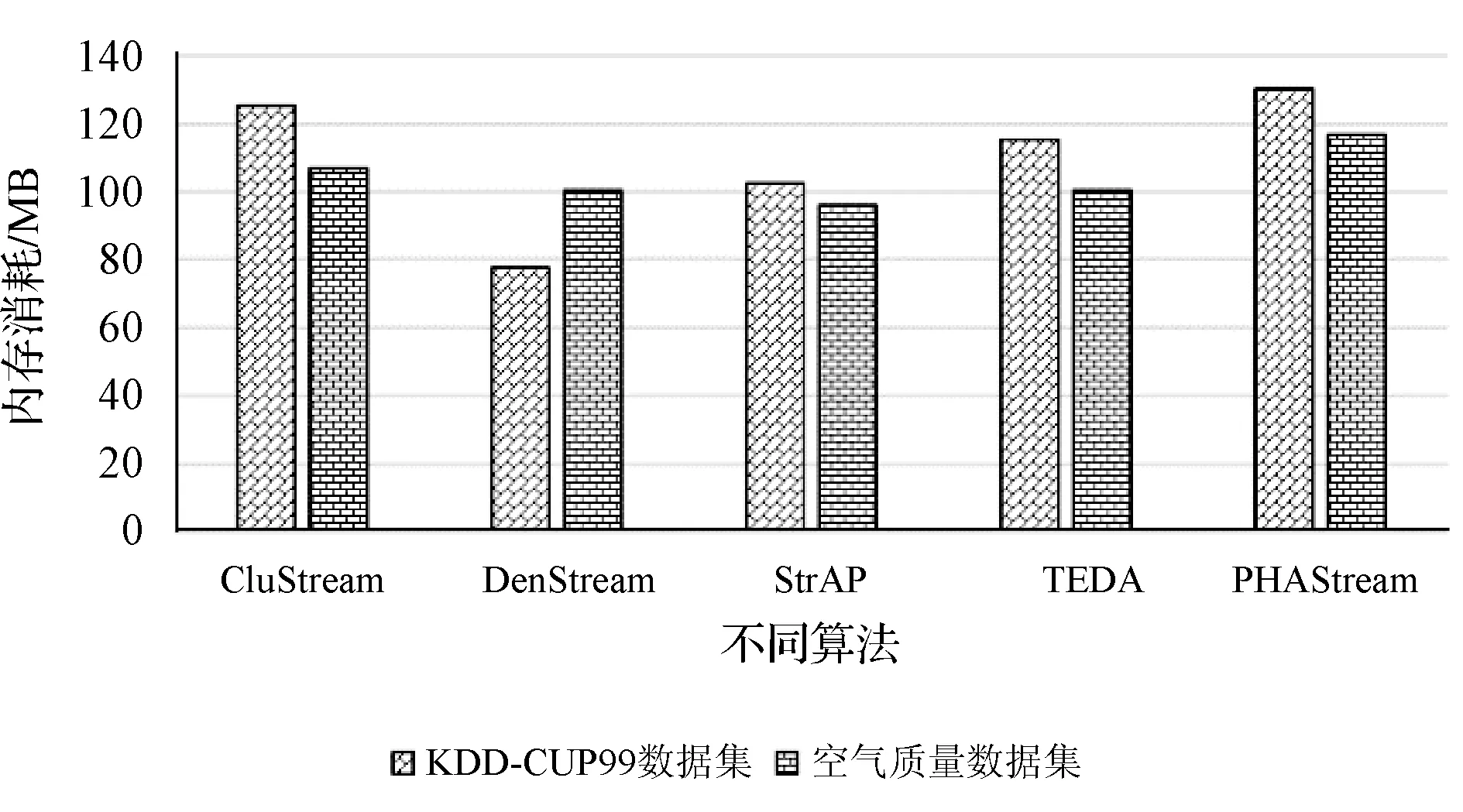
圖20 時間效率對比圖
5 結 語
本文提出一種基于勢能模型的數據流聚類算法PHAStream,將基于勢能模型的層次聚類算法PHA改造適用于數據流聚類。相對于大部分以距離為相似度度量的數據流聚類算法,本文的PHAStream算法以距離和勢能作為相似度度量,這兩者分別反映了所有數據點的局部和全局分布,減少噪點對聚類的干擾。實驗結果表明,該算法可以有效提高聚類質量、聚類純度和時間效率。
在本文的研究中,需要人工設置最終聚類簇個數。未來將考慮利用勢能自動地確定聚類簇,使得該數據流聚類算法更高效。
