基于Neo4j知識圖譜的周邊游熱點分析
——以茂名市為例*
2022-12-05 11:36:22廣州軟件學院李慧斯黃金鈺吳培超江陳發
數字技術與應用 2022年11期
廣州軟件學院 李慧斯 黃金鈺 吳培超 江陳發
在疫情防控期間,我國游客的旅游消費方式已經發生明顯的轉變,越來越多游客選擇短程旅游。大量旅游評論信息對旅游的發展產生重要的影響,然而,游客撰寫相關評論信息時,存在極強主觀臆斷性且評論內容的價值良莠不齊,大量冗余信息使得旅游企業無法分析游客旅游消費需求行為的變化。因此,周邊游需求圖譜分析對開拓旅游市場具有重要的意義。首先基于TextRank模型提取產品名稱,然后通過使用情感詞典、高頻詞,從高頻詞、情感、服務、位置、設施、衛生、價格7 個維度進行周邊游產品熱度分析,并且使用One-Hot 編碼技術對旅游產品進行關聯分析,最后用Neo4j 知識圖譜進行可視化分析。
旅游業在疫情防控期間受到嚴重影響,同時使得游客的消費方式也發生了明顯的轉變。在此背景下研究分析游客消費需求行為的變化,對于旅游企業產品供給、資源優化配置以及市場持續開拓具有長遠而積極的作用。隨著互聯網的不斷發展,文本形式的在線旅游(Online Travel Agency,OTA)和游客的用戶生成內容(User Generated Content,UGC)數據成為了解旅游市場現狀的重要信息來源[1]。OTA 和UGC 數據的內容較為分散和碎片化,要使用它們對某一特定旅游目的地進行研究時,迫切需要一種能夠從文本中抽取相關的旅游要素,并挖掘要素之間的相關性和隱含的高層概念的可視化分析工具。因此,本文將通過建立本地旅游圖譜的方式來分析疫情防控期間茂名市的周邊游發展。
1 文獻綜述
近年來,隨著旅游經濟的快速發展,游客評論成為一個待挖掘的寶藏,而大量冗余信息使得旅游企業難以分析游客旅游消費需求行為的變化,及時做出適當的調整。而知識圖譜可視化分析在旅游領域上,已經有了一定的應用。張宇飛在2020年實現了基于構建的知識圖譜,設計了一個集景點信息管理、景點信息搜索和搜索結果可視化為一體的應用系統[2]。2021年吳杰針對既有傳統旅游知識圖譜的不足,有針對性的提出了以事件為中心的旅游知識圖譜[3]。原越于2022年時進行針對現有搜索引擎提供的旅游景點信息缺乏關聯度和完整性,通過設計旅游景點本體、針對爬取語料的處理構建旅游景點知識圖譜。在此基礎上設計并實現了一個B/S 架構的旅游景點應用系統[1]。而徐春、李勝楠也在同年進行針對旅游信息呈現出散亂、無序和關聯性不強的問題,提出一種融合BERT-WWM 和指針網絡的實體關系聯合抽取模型構建旅游知識圖譜[4]。目前比較少的知識圖譜分析針對周邊游領域,而本文的研究將為其他地區使用基于知識圖譜的周邊游熱點分析提供參考。
2 研究方法及分析
2.1 數據采集
本文收集了兩個數據集,分別為2018-2019 茂名(含自媒體)數據集和2020-2021(含自媒體)數據集,數據集中包含酒店評論、景區評論、游記攻略、餐飲評論和微信公眾號新聞數據集。其中酒店評論1093 條、景區評論1203 條、游記攻略294 條、餐飲評論6984 條和微信公眾號新聞6286 條。其中主要使用微信公眾號新聞數據,該數據集中共有6286 條數據,涉及的4 個指標分別為“文章ID”“公眾號標題”“發布時間”和“正文”。
由于原始數據集中缺乏“相關性”分類標簽,因此本章在無標注的數據中隨機抽取部分數據進行人工標注。人工標注時0 代表不相關、1 代表相關。最終共得到帶有人工標注的數據4400 條。最后將數據以7∶3 的比例分為訓練集和測試集,訓練集包含4400 條數據,測試集為2286 條。
2.2 實驗步驟
在TextRank 模型[5]中將采用酒店評論、景區評論、游記攻略、餐飲評論和微信公眾號新聞數據集,具體實驗步驟如下。
(1)繁簡體轉化。通過預覽原始數據,可觀察到正文中存在“繁體字”數據,由于繁體字字符對后續分類會產生一定的影響,因此我們需要首先對評論進行繁簡體轉換。
(2)提取旅游產品。由于酒店評論、景區評論和餐飲評論數據集中有對應的旅游產品,本文只需抽取其語料ID 號及對應的旅游產品名稱,再按旅游產品名稱附加產品ID 號即可。因此,語料ID 號及產品名稱是一一對應的關系。
然而,游記攻略和微信公眾號新聞數據集中沒有對應的旅游產品,因此本文將通過TextRank 算法進行抽取。具體流程為首先對無效評論進行去除,通過使用TextRank 算法抽取每條評論的關鍵詞,每條評論可通過其內部詞語間的共現信息抽取其中的關鍵詞,最后輸出每條評論出現次數前五的關鍵詞。由于抽取的產品名稱中出現部分停用詞及不符合旅游產品的旅游名稱,因此本文根據輸出結果,自定義停用詞表,從而篩選出不規范的旅游名稱,篩選后的部分數據如表1所示。

表1 旅游產品提取部分數據集Tab.1 Part of tourism product dataset
其次將基于情感詞典擴充進行熱度分析,將采用經過預處理后的酒店評論、景區評論和餐飲評論新聞數據集,具體實驗步驟如下。
(1)根據情感詞停用詞表去除數據集中每個句子的停用詞,然后進行相應的分詞,并對句子進行切分。
(2)讀取情感詞典和程度副詞,將程度副詞乘以不同的權值,并處理情感得分防止出現負數,最終計算出單條評論語句的情感傾向總得分。
(3)產品名稱計算熱度的公式如下所示。
熱度=單條評論語句的情感傾向總得分/全部評論語句的情感總得分中的最高得分
2.2.1 關聯度的計算和量化
在前階段的數據準備和實體抽取后進行關聯模式的定義,從根據當地的經濟發展程度、地理位置等其他諸多客觀及衍生的主觀因素定義以下5 種關聯模式。從量化方法(如表2所示)中可以得知:

表2 關聯模式的量化方法Tab.2 Quantification method of correlation patterns
(1)互利關系是由產品A 對產品B、產品B 對產品A 的相對共現度加和得到,其計算的共現度可以反映當地兩兩旅游產品間聯系的緊密程度。
(2)近鄰關系是根據地理位置來計算的,而地理位置計算是根據經緯度坐標計算兩點球面距離,其中距離較近(<500m)的產品統一記作500m。
(3)散射關系是根據景區熱度、周圍同類產品密度及地理位置距離決定的,通過計算可進一步分析產品間的競爭力和變化趨勢等。
(3)競爭關系主要建立在餐飲和酒店相似度較高基礎上的研究,主要影響因素包括經濟距離和地理距離。經濟距離及地理距離越小競爭越大,經濟距離是指餐飲間的熱度差。
(5)導流關系是主要利用影響因素中的景區熱度和景區距離,即為AB 熱度之和/AB 距離。
在對5 種關聯模式進行定義和相關量化計算后,需要進行進一步的標準化,利用Z-Score 標準化方法[6]和Min-Max[7]標準化方法將指標數值局限至[0,1],其中對部分集中在較小區間的數據取立方根,最終效果的部分展示如表3所示。

表3 部分關聯度計算結果Tab.3 Partial correlation degree calculation results
2.2.2 基于Neo4j 的圖譜可視化及分析
目前知識圖譜的存儲方式主要有關系型數據庫、圖數據庫和基于RDF 結構的存儲方式[3]。Neo4j 圖數據庫以圖形結構的形式存儲信息,關聯的數據本身就是它所包含的數據,因此它可以直接顯示關聯數據特征以及數據之間的關系。首先,將旅游產品實體作為節點“Products”,并配置產品ID 和產品名稱屬性,生成旅游產品圖譜中的所有節點,再將節點創建關聯類型屬性,得到旅游圖譜,局部旅游圖譜如圖1所示。
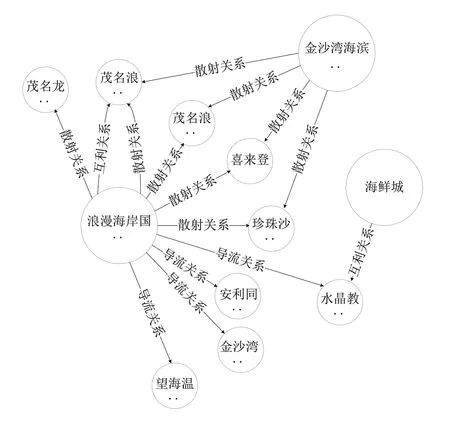
圖1 局部旅游圖譜Fig.1 Partial knowledge map of tourism
在關聯圖譜中,導流、輻射、互利關系出現頻率較高。餐飲風格相似這一模式較為集中,其中酒店的競爭關系較為明顯,例如在匯豐酒店同時與高州順得商務酒店和如家店·Neo(茂名人民路步行街中心店)存在競爭關系,較少存在其他關系。
散射關系會跨領域出現在餐飲和景區中,例如金沙灣海濱浴場和茂名浪漫海岸溫德姆酒店望海餐廳存在散射關系;或者可以跨領域出現在酒店和景區中,例如金沙灣海濱浴場和喜來登酒店存在散射關系。通過對產品關聯模式、目的地熱度進行分析,發現了餐飲業迎來了較好的發展趨勢與旅游產品的互利關系越來越明顯。
3 結語
目前,領域知識圖譜已經應用在許多領域,但是旅游領域的知識圖譜應用仍然相對匱乏,這無疑抑制了智慧旅游的發展。為了進一步應用互聯網旅游數據資源為政府提供本地周邊游發展建議,通過對本地旅游相關的評價文本進行分類挖掘,計算出關鍵詞的熱度,建立了關聯模型并進行了量化,計算出關聯度并將其輸入Neo4j 進行知識圖譜的可視化分析,完成了對周邊游熱點的分析。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
山東工業技術(2016年15期)2016-12-01 05:31:22
Coco薇(2015年1期)2015-08-13 02:23:50
數學大王·低年級(2014年7期)2014-08-11 16:36:44
海外英語(2013年8期)2013-11-22 09:16:04
玩具(2009年10期)2009-11-04 02:33:14
個人電腦(2009年9期)2009-09-14 03:18:46
舒適廣告(2008年9期)2008-09-22 10:02:48
