基于多源遙感數據和機器學習算法的冬小麥產量預測研究
2022-12-09 09:22:16李紅葉宋成陽謝永盾陶志強肖永貴孟亞雄
麥類作物學報 2022年11期
甘 甜,李 雷,李紅葉,宋成陽,謝永盾,陶志強,肖永貴,孟亞雄
(1.甘肅農業大學農學院,甘肅蘭州 730070;2.中國農業科學院作物科學研究所,北京 100081)
小麥作為世界主要糧食作物[1],在我國播種面積約2 400萬hm2,產量約1.3億t,產量約占全世界的30%[2]。然而,由于耕地減少、氣候變化和人口增加,我國小麥供求處于“緊平衡”狀態,在我國人口壓力大與耕地面積不足的大背景下,小麥產量關乎人民生活水平提高和國家糧食安全[3]。收獲前及時、準確地監測預報小麥產量對于國民經濟發展、糧食政策制定、糧食市場調節等均具有重要意義[4]。
遙感技術因其尺度大、效率高、無損傷等優點,被廣泛應用于各類精準農業研究領域[5-6]。在各尺度遙感平臺中,衛星遙感常被用于區域作物產量預測[7-8]。衛星平臺視點高、視域廣、數據采集快[9],但存在重訪周期長、影像分辨率低、混合像元和氣象條件限制等問題,對農業生產者的實際輔助效果甚微[10]。搭載各類傳感器的無人機(unmanned aerial vehicle,UAV)低空遙感平臺[11]具有快速靈活、空間分辨率高的特點,在精準農業領域受到廣泛關注[12-13],利用其能夠高通量獲取作物冠層生長信息,并及時對產量做出預測[14-15]。基于地面高光譜遙感平臺獲取的連續精細的波段反射率數據具有信息豐富且光譜分辨率高特點[16]。無人駕駛地面車輛(unmanned ground vehicle,UGV)搭載的地面高光譜設備作為全新的高通量生理表型鑒定平臺,其生理表型鑒定性能顯著優于UAV平臺[17]。采用單一平臺獲取的小麥產量相關信息往往不夠全面,目前作物估產研究也大多限于同一遙感平臺,將多個遙感平臺數據結合的研究鮮有報道。
近年來,利用各尺度遙感數據作為機器學習算法輸入特征,在建立作物性狀評估模型時表現出較高的預測精度和魯棒性[18],已廣泛用于小麥、大豆、玉米等作物產量評估[19-21]。基于單一機器學習算法對作物性狀的評估精度在不同生長環境下有所差異,而結合多種機器學習算法的集成學習有著更為穩定的預測能力[22]。Stacking是一種使用“學習法”的多模型結合策略,由Breiman于1992年提出[23]。通過次級學習器對多個初級學習器的輸出結果再次訓練,可將不同學習器解析數據的能力進行結合,并且在集成時使用多元線性回歸(multiple linear regression,MLR)作為次級學習器,具有較好的集成效果[24]。Stacking集成通常能得到比單一學習器更高的預測精度,尤其對高光譜遙感等高維度數據進行訓練時效果顯著,已廣泛應用于地理信息分類、植物光合能力評估和作物產量預測等領域[25-26]。
本研究基于冬小麥田間試驗,通過無人機遙感平臺、地面表型車平臺及手持式冠層鑒定平臺,選擇灌漿期作為最佳生育期,獲取RGB、多光譜和高光譜數據并分別構建光譜指數集,再以光譜指數集作為輸入變量,通過決策樹(decision tree,DT)、嶺回歸(ridge regression,RR)、隨機森林(random forest,RF)、支持向量機(support vector machine,SVM)4種機器學習方法與集成算法(ensemble learning,EL)分別構建基于ASD-高光譜、UGV-高光譜、UAV-多光譜、RGB-顏色指數的冬小麥產量預測模型,并探討4種遙感數據的預測精度及最優組合,以期為冬小麥產量預測提供新的思路和方法。
1 材料與方法
1.1 試驗材料與田間設計
利用中麥175/輪選987重組自交系F7代群體中70個家系為試驗材料,于2020年種植于中國農業科學院作物科學研究所昌平試驗基地(116.24°E,40.17°N)。試驗采用隨機區組設計,2次重復,行距為0.2 m,小區面積為4.2 m2(3 m×1.4 m)。出苗后對缺苗斷垅處進行移栽,確保苗全苗勻。田間管理按照北部冬麥區區域試驗標準進行,并及時進行病蟲害及雜草防控。
1.2 技術路線
按圖1所示流程獲取冬小麥冠層的光譜數據和各個小區的實際產量,并結合機器學習算法和集成算法,對小麥產量進行預測研究。
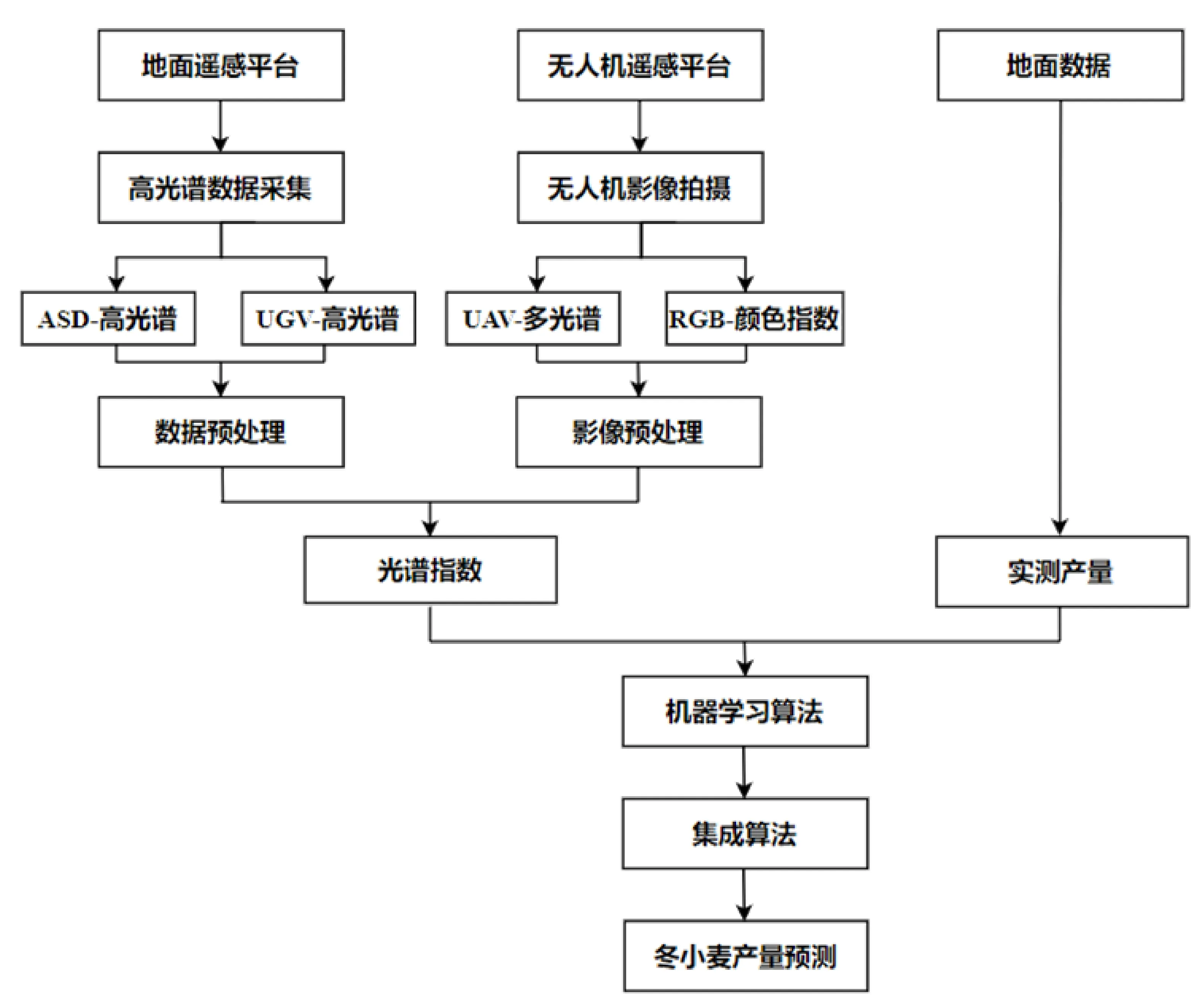
圖1 技術路線
1.3 表型數據獲取
1.3.1 無人機遙感影像獲取與處理
使用DJI精靈4無人機搭載多光譜相機和可見光相機,于小麥灌漿期(5月29日)執行飛行任務,使用軟件GS Pro2.0規劃飛行任務,規劃航線和航點任務的航向和旁向重疊率均設置為85%,無人機飛行高度設定為30 m,空間分辨率為每像素3.55 cm。獲取數據后利用Pix4D 4.5.6軟件進行影像拼接、輻射定標,結合ArcGIS軟件提取小區的冠層信息,計算多光譜的反射率和RGB的DN值。
1.3.2 ASD高光譜數據獲取與處理
采用高光譜輻射儀(Fieldspec 4,Analytical Spectral Devices ASD,Boulder,CO,United States)在小麥灌漿期測定冠層光譜。獲取光譜后,利用ViewSpecPro(ASDInc,Boulder,Colorado)軟件進行數據檢查,獲取反射率數據。
1.3.3 UGV高光譜數據獲取與處理
利用UGV獲取數據前,將單個小區的四個點進行坐標測定,將數據錄入UGV的GPS模塊中以實現對小區的自動劃分。由于UGV自帶穩定光源,在小麥灌漿期16:00-19:00采集數據。采集時車廂位于小麥冠層上方20 cm處,以0.7 m·s-1的速度進行移動測量。利用FieldExplorer分析軟件中生成的csv和bmp文件,獲得300~1 000 nm的光譜波段。
1.3.4 地面數據獲取與處理
成熟后,使用小區聯合收割機進行收獲,晾曬后籽粒含水量約為6.5%時稱重,并換算為公頃產量,共獲得144個產量數據,以4∶1的比例劃分為訓練集與測試集。
1.4 光譜指數的選取
光譜指數是由不同波段的反射率以代數形式組合成的一種參數,可降低條件背景對光譜反射率數據的干擾,比單波段具有更高的靈敏性[27]。本試驗選擇29個多光譜指數[27-40]和32個高光譜指數[41-49]。
RGB光譜指數模型中波長為650 nm(紅)、560 nm(綠)和450 nm(藍)的光譜色為三原色,在軟件的直方圖中采集葉片圖像的紅光值(R)、綠光值(G)和藍光值(B)。根據R、G、B算法組合得出33個RGB光譜指數[49-54]。
1.5 基于機器學習算法的小麥產量預測模型的構建
選取在農作物產量預測中廣泛應用的4種傳統機器學習算法[決策樹(DT)、隨機森林(RF)、支持向量機(SVM)和嶺回歸(RR)]用以構建產量預測模型[55],并使用典型的集成學習算法Stacking。交叉驗證具有簡單和通用的特點,能夠有效避免過擬合問題[56]。算法集成是在每次劃分后以SVM、RF、DT、RR為初級模型,以MLR為次級模型并使用10折交叉驗證進行訓練和測試。算法-傳感器集成是以SVM 、RF、DT、RR四種機器學習算法和RGB、ASD、UAV、UGV四個傳感器為初級模型,以MLR為次級模型并使用10折交叉驗證法進行訓練和測試。
1.6 模型驗證
以10折交叉驗證的10次驗證結果的決定系數(coefficient of determination,r2)和均方根誤差(root mean square error,RMSE)的平均值檢驗模型精度和預測能力。計算公式如下:
(1)
(2)
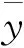
2 結果與分析
2.1 實測產量統計分析
采用SPSS軟件進行P-P圖檢驗,70個家系實測產量值呈正態分布(圖2),產量最小值為 4 131 kg·hm-2,最大值為9 798 kg·hm-2,平均值為7 204 kg·hm-2,標準差為756 kg·hm-2,變異系數為10.49%。母本中麥175的平均產量為8 539 kg·hm-2,父本輪選987的平均產量為7 500 kg·hm-2,雙親在產量性狀上有較大差異,群體平均產量低于雙親,說明該重組自交系具有豐富的遺傳變異。

圖2 小麥實測產量密度分布
2.2 光譜指數與產量的相關性
相關性分析(表1)表明,除高光譜指數DSI、PVI、MCARI外,其余指數與小麥實測產量均呈顯著或極顯著相關。RGB-顏色指數與產量多數呈極顯著負相關,其中RBDI的相關性最高(r=-0.71),ExG的相關性最低(r=0.24)。UAV-多光譜指數與產量多數呈極顯著正相關,其中NPCI和PSRI的相關性最高(r= -0.71),MNVI的相關性最低(r=0.39)。UGV-高光譜指數與產量也多數呈極顯著正相關,其中PSRI的相關性最高(r=-0.73),PVI的相關性最低(r= -0.11)。ASD-高光譜指數與產量也多數呈極顯著正相關,其中PSRI的相關性最高(r= -0.69),MCARI的相關性最低(r=-0.15)。由此可見,灌漿期各遙感平臺數據均能獲取與小麥產量相關的信息,且各平臺間差異較小。因此,建立產量預測模型時使用全部光譜指數作為各模型的輸入特征。

表1 光譜指數與冬小麥實測產量的相關性Table 1 Correlation between spectral index and measured yield of winter wheat
2.3 基于不同傳感器冬小麥產量的預測精度
將各光譜指數分別作為DT、RR、RF、SVM算法的輸入變量構建產量預測模型(表2)。結果表明,基于RGB預測產量精度最高的模型為SVM算法模型,r2為0.76,RMSE為 451.58 kg·hm-2;基于ASD預測產量精度最高的模型為RR算法模型,r2為 0.72,RMSE為501.73 kg·hm-2;基于UAV預測精度最高的模型為SVM算法模型,r2為0.75,RMSE為482.35 kg·hm-2;基于UGV預測產量精度最高的模型為RR算法模型,r2為0.72,RMSE為531.71 kg·hm-2。就傳感器而言,RGB的預測能力最為穩定,且預測精度較高,平均r2為0.74;就算法而言,RR模型預測能力較為穩定,平均r2為0.73。

表2 基于不同傳感器冬小麥產量預測精度Table 2 Estimation precision of winter wheat yield based on different sensors
2.4 基于集成算法的冬小麥產量預測精度分析
將DT、RR、RF、SVM四種初級學習器輸出的預測產量作為輸入特征建立冬小麥產量預測模型(圖3)。結果表明,基于RGB的r2由初級學習器中預測精度最高的0.76(SVM)提升至 0.77,RMSE為481.80 kg·hm-2;基于ASD的r2為0.71,雖然r2并未提升,但RMSE降為 488.16 kg·hm-2;基于UAV的r2由初級學習器中預測精度最高的0.75(SVM)提升至0.77,RMSE降至479.45 kg·hm-2;基于UGV的r2由初級學習器中預測精度最高的0.72(RR)提升至 0.73,RMSE降至519.08 kg·hm-2。這說明利用Stacking方法能提高產量預測精度,具有比單一模型更優異的泛化能力。
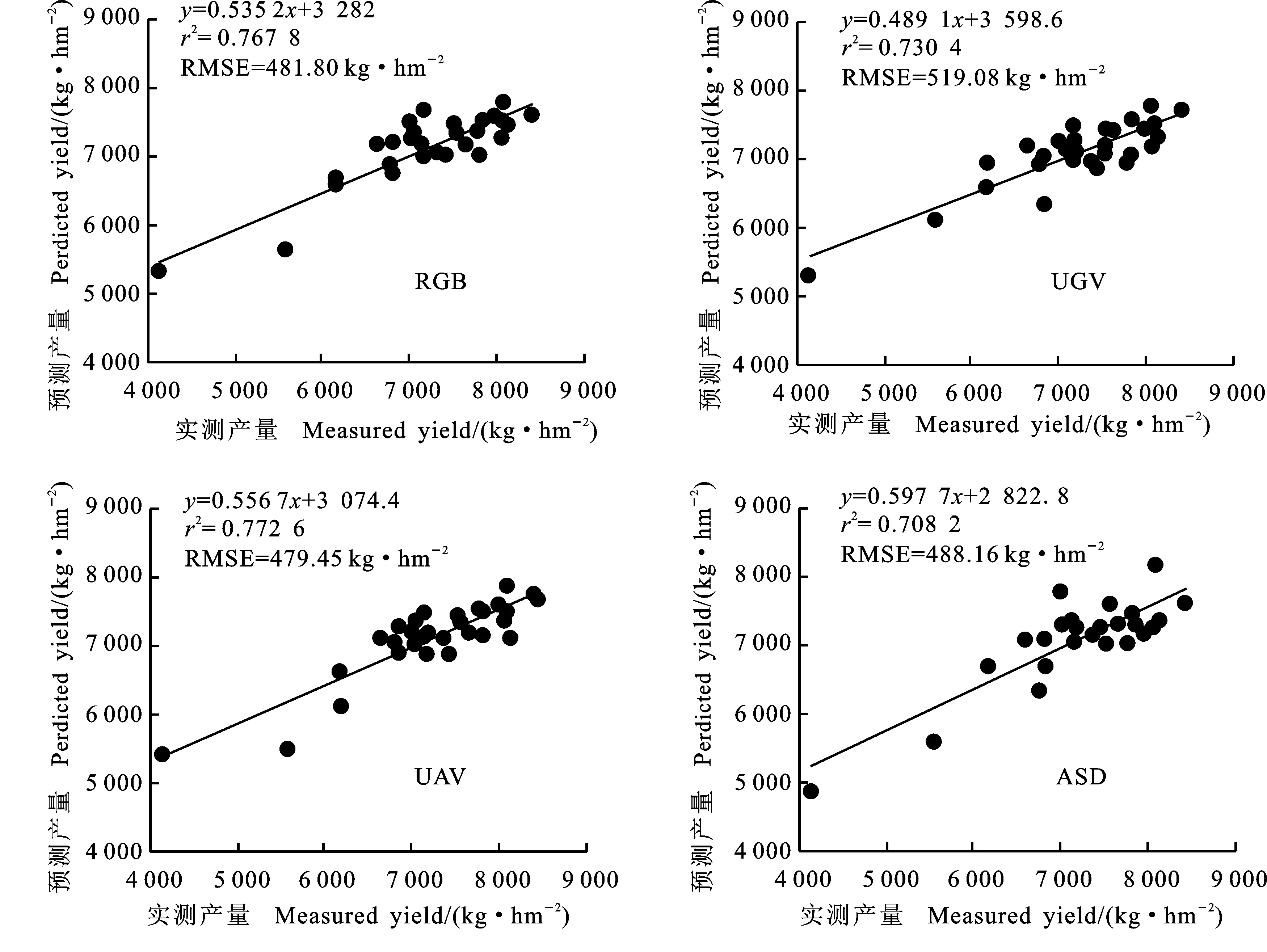
圖3 基于算法集成的小麥產量預測精度驗證
為了進一步評估集成方法的性能,通過使用DT、RR、RF、SVM四種初級學習器和RGB、ASD、UAV、UGV四個傳感器組合的集成方法來實現冬小麥產量預測。利用Stacking方法在驗證集上冬小麥產量預測結果與實測產量結果做散點圖(圖4)。算法-傳感器組合預測的r2為 0.79,RMSE為469.98 kg·hm-2,預測精度和能力大于上述的各種組合,并且RMSE也較低。用Excel軟件對產量實測值和預測值兩組數據進行t檢驗,得到P=0.64,說明兩組數據差異不顯著(P>0.05),模型集成的精度提高具有統計學 意義。

圖4 基于算法-傳感器集成的小麥產量預測精度驗證
3 討 論
小麥產量的精準預測對于提升育種工作效率具有重要意義。本研究分別獲取了基于ASD和UGV的高光譜數據,兩種傳感器計算得到的GARI、NDRSR、VREI、SRI、ARVI、RENDVI和PSRI與產量的相關性均較高(r=0.58~0.73)。上述指數波長大多位于700~800 nm,說明700 nm和800 nm組合的高光譜指數對預測產量有很好的精度。這與崔懷洋等[57]的研究結果一致。
本研究通過比較基于UGV-高光譜和ASD-高光譜兩種遙感技術建立的冬小麥產量預測模型發現,基于DT、RF、SVM、RR四種機器學習算法和集成方法建立的預測模型中,UGV預測精度均大于ASD。UGV以高光譜圖像為載體,通過結合地表作物生理圖像信息,形成了光譜與圖像的結合,具有更高的光譜分辨率能敏感捕捉不同地物在光譜維上的細微差異,進而大大提高獲取地物表型信息的能力。ASD僅得到冠層反射率,與圖像相比,包含的信息較少。相比于其他作物長勢監測平臺,UGV因價格昂貴,導致國內小規模育種公司和科研單位難以用于實際。ASD預測精度雖低于UGV,但成本較低且便于攜帶,對于多環境田間表型調查更為高效實用。本研究還發現,RR模型較其他模型能獲得較好的預測結果和穩定性,可能歸因于共線數據分析模型的偏向性和大多數性狀的綜合關系[58-60]。
利用遙感平臺可以避免估產過程中工作量大、人為干擾等不利因素[61]。將遙感數據與多個模型的優點結合起來,可以提高在各種生長條件下冬小麥產量預測的精度。集成學習方法通過組合不同的基礎機器學習算法來增加算法的多樣性,而基礎機器學習算法的更多異質性的組合提高了集成學習模型的預測能力[60-62]。本研究將4種不同原理和內部結構的機器學習算法結合在一起,在預測冬小麥產量方面具有比單一學習機器更高的精度。此外,本研究還發現將無人機遙感平臺、地面遙感平臺和地面傳統生理表型(產量)集于一體,提出近地面“天空地一體化”冬小麥產量預測模式,預測精度大于單個傳感器和單個算法,r2為0.79,RMSE為469.98 kg·hm-2,證明了該模式可提高冬小麥產量預測能力。
本研究基于多源平臺與算法的集成實現了對小麥產量的預測且效果較好,但存在一些問題需要改進:(1)研究中使用的機器學習模型均為經驗模型,其優點在于方法簡單,且可重復操作,但該類模型在更多種生長環境下實施時需要進一步地完善研究和驗證其穩定性;(2) 研究中選用的生長階段較少,缺乏對于小麥生長初期如返青期和拔節期等時期的產量預測精度研究。下一步研究內容可以包括:(1)在多種復雜生長條件下驗證與本研究結論是否一致,并探索更多影響構建模型的因素,獲得更優的機理解釋;(2)本研究僅利用一年冬小麥數據分析,未來將針對多生長季時間序列數據進行深入探討。
4 結 論
相對于高光譜和多光譜,RGB傳感器預測產量精度最高;相對于傳統機器學習算法DT、RF、SVM,RR機器學習算法預測產量精度最高。4種算法集成的模型預測精度高而且穩定,4種機器學習算法和四個傳感器構成算法-傳感器集成模型的預測精度最高,r2為0.79。這說明利用Stacking集成方法將不同算法、傳感器進行結合,能夠有效地提高產量預測精度,可為冬小麥育種工作中產量預測提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
