基于AMI數據驅動的竊電用戶識別研究
2022-12-11 02:37:06劉文浩馮玥姜東良
制造業自動化 2022年11期
劉文浩,馮玥,姜東良
(1.遼寧工程技術大學 電氣與控制工程學院,葫蘆島 125105;2.國網冀北電力有限公司遷西縣供電分公司,唐山 064300;3.遼寧工程技術大學 軟件學院,葫蘆島 125105)
0 引言
電已經成為我們生活中的必需品。電能損失可分為技術損失和非技術損失[1],通常發生在發電、輸電和配電過程中。主要的非技術損失之一是竊電。這種不當行為通常包括繞過電表、篡改電表讀數或破壞電表等[2]。在發達國家,如美國每年因竊電損失約60億美元[3]。對于發展中經濟體來說,損失的后果要糟糕得多。印度每年因竊電損失170億美元[4]。其他發展中國家損失了近50%的電力收入[5]。除了會給電力公司造成巨額收入損失外,竊電也會導致電力需求激增、電力系統負荷過重、以及對公共安全的危害(如火災和電擊)。
目前,有大量關于檢測竊電的研究。傳統的竊電檢測方法包括[6]:人工檢查有問題的電表安裝或錯誤配置,將異常電表讀數與正常電表讀數進行比較,以及檢查旁路輸電線路等。然而,這些方法極其耗時、昂貴且效率低下。智能電網的出現為解決竊電帶來了機遇。隨著高級計量設施(AMI)的大量安裝,用戶的用電大數據的收集變成了可能。相比于傳統的竊電檢測方法,數據驅動方法是更具吸引力的,因為智能電表提供了豐富的能耗數據,成本低并且能提供良好的檢測率。
文獻[5~10]使用開源的愛爾蘭能源數據集[11]對用戶竊電檢測問題進行了大量研究。但愛爾蘭數據集中所有的用戶都被認為是誠實用戶,需自定義生成竊電用戶的數據。自定義竊電用戶數據與真實竊電用戶數據之間相似性不能保證完全。文獻[12]公布出帶真實竊電標簽的用戶用電數據集,針對竊電用戶和誠實用戶每周和每月用電規律的差異性,從周用電消費趨勢和月用電消費趨勢兩個維度提取特征,搭建卷積神經網絡模型進行竊電檢測,給出了80%的AUC值。但此方法中數據預處理不夠充分,對連續缺失值的插補過多,并且僅考慮不同類型用戶自身的用電規律,缺乏不同用戶用電數據的直接對比。
考慮到誠實用戶與竊電用戶用電數據的差異是多樣的。我們對數據集中的數據進行嚴格預處理。通過分析不同類型用戶用電數據數值和消費趨勢方面的差異性,尋找其它可用于有效分類的特征,并搭配監督學習方法進行試驗。
由于時頻域參數在故障分類方面有非常多成功的經驗[13,14]。為此,我們對用戶時頻域參數在竊電分類中的研究也做了初步探索,并給出分類結果。試驗流程圖如圖1所示。

圖1 竊電檢測流程圖
1 數據處理與分析
1.1 數據預處理
源數據集[15]由中國國家電網公司提供,包括42372個用戶2014年1月1日至2016年10月31日連續1034天的日用電負荷。其中,有3615個用戶被標記為竊電用戶,其余則為誠實用戶,且數據中包含大量的缺失值。為此,使用Python語言軟件的msno模塊繪制數據分布矩陣,發現2016年1月1日之前的數據情況存在嚴重缺失。為保證數據可靠性,我們截取2016年1月1日至2016年10月31日連續304天的的數據,并將其中連續缺失數據超過6天的用戶刪除,少量缺失值我們對其進行前向插補,最后預處理后的數據情況如表1所示。

表1 預處理后數據信息表
1.2 用戶用電行為分析
為證明所提模型的合理性,在建立模型之前,我們對表1中用戶進行用電行為分析,繪制負荷圖如下。為保證分析數據的有效性,我們對誠實用戶和異常用戶進行隨機抽取。
如圖2所示,我們隨機抽取誠實用戶與竊電用戶各三名,繪制出它們連續304天的用電數據曲線,從中我們可以看出總體上,大部分竊電用戶的日用電量是低于誠實用戶的,并且誠實用戶相比竊電用戶用電規律具有更強的波動性。此外,我們隨機挑選部分用戶繪制節假日和休息日的用電數據曲線,如圖3、圖4所示。從中我們可以觀測到節假日和休息日不同類型用戶的電量差是變化的,誠實用戶的用電波動性更強。除此之外,隨機抽取竊電用戶與誠實用戶各500名,繪制出時頻域參數中的無量綱值峭度與偏斜度對比圖,如圖5所示。

圖2 竊電用戶與誠實用戶用電負荷對比圖
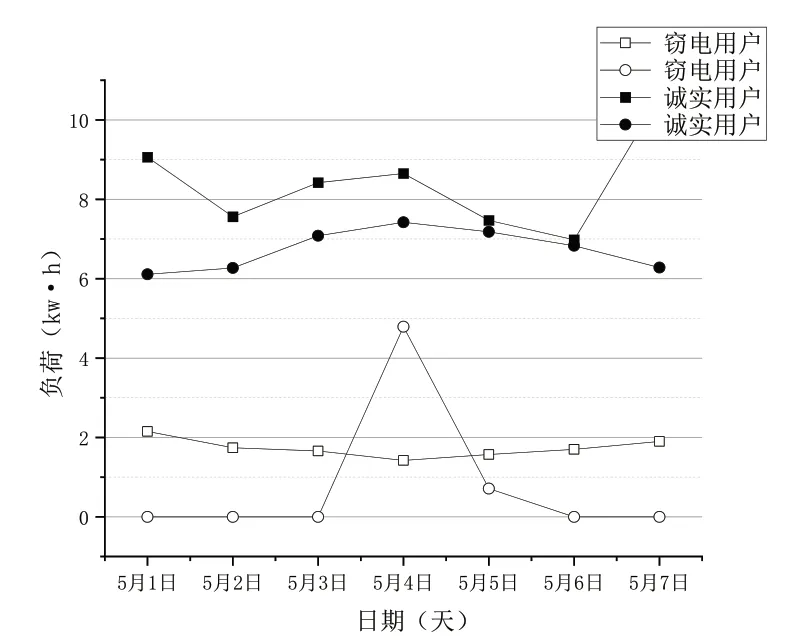
圖3 節假日用電負荷對比圖

圖4 休息日用電負荷對比圖

圖5 部分時頻域特征對比圖
基于對比圖,利用經驗和直觀負荷圖從數據中提取特征是困難的。在對竊電用戶和誠實用戶的數據分析中,我們無法看出竊電用戶與誠實用戶之間用電規律明顯的不同。但考慮用電規律的波動性,我們將用戶每天的日用電總量作為特征,利用主成分分析(PCA)保留特征中絕大部分信息,進行特征重構繼而分類。此外,針對峭度等時頻域參數對比圖,我們也挑選了部分時頻域參數作為特征進行分類。
1.3 數據集的平衡
如表1中竊電用戶與誠實用戶的數量分布情況。為解決數據類別嚴重不平衡的問題,在本文中,我們引入合成少數類過采樣技術(SMOTE)。SMOTE根據少數類樣本人工合成新樣本添加到數據集中[16]。原理如下,SMOTE對少數類中每一個樣本(x1,x2),以歐式距離為標準計算它與少數類樣本集中所有樣本的距離,得其k近鄰。根據不平衡比例設置采樣倍率N,由N從其k近鄰中隨機選擇若干樣本,假設選擇的近鄰為(x'1,x'2)。樣本點合成公式如式(1)所示:

其中Δ={(x'1-x1),(x'2-x2)},random(0,1)為0,1之間的隨機數。使用SMOTE后,正常用戶和盜竊用戶的數量幾乎相等。
2 特征提取與用戶分類
對竊電識別效果最好的PCA-RandomForest模型給出搭建原理和詳細過程,其他則在第3節中簡要介紹。
2.1 利用PCA進行特征提取
在探索提議的檢測方法之前,簡要介紹主成分分析的基本原理[17]。主成分分析是一種統計分析方法,在空間上可以理解為保持源數據集中各樣本空間位置不變的情況下,構建新坐標系,使得各樣本在這個新的坐標系上的投影具有最大的方差。這樣可以在盡可能保留源數據集信息的同時,降低給定高維數據的維數。
在我們的模型中,我們定義每個用戶為一個獨立的樣本,用戶每天的用電數據量為其用電特征。我們提取處理后的用戶用電數據(細節如表1所示)構建特征矩陣。矩陣的每一行是一個樣本的特征向量,即矩陣中有m個樣本,每個樣本有n個特征值。降維之前我們對數據X進行白化處理,保證數據各維度的方差為1,之后對數據集X應用主成分分析進行降維。
第一主成分如下所示:
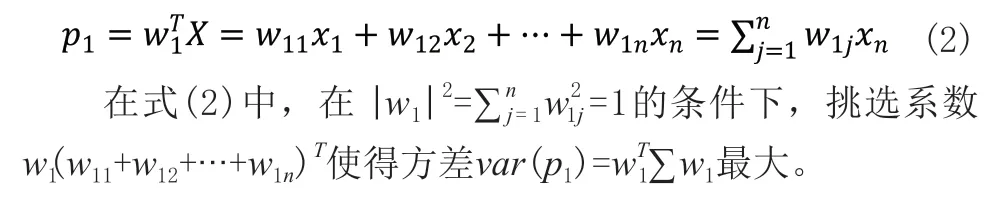
同理,第二主成分被給出為:

同樣,我們計算出其他主成分,各主成分所保留信息占比如圖6所示,我們選擇前7個主成分,重新構建特征矩陣p=[p1,p2,...,p7],這保存了源數據集99%的信息。

圖6 各主成分信息占比圖
2.2 利用隨機森林進行分類
根據PCA重建數據的特點,隨機森林算法用于分類。隨機森林算法由多個CART決策樹組成。構建每棵決策樹前,首先對全部m個樣本進行有放回的自助采樣,獲得與源數據集大小相同,但部分數據點會缺失(大約三分之一)的數據集。接下來,基于新創建的數據集建立決策樹。與普通決策樹構建不同,隨機森林中決策樹的構建選擇在每個節點處,隨機選擇特征的一個子集,并對其中一個特征尋找最佳測試。特征子集中特征個數由最大特征數(max_features)參數來控制。由于使用了自助采樣,隨機森林中構建每顆決策樹的數據集都略有不同。由于每個節點的特征選擇,每棵樹的劃分都是基于特征的不同子集。這共同保證隨機森林中所有樹都不相同。在分類過程中,采取軟投票(soft voting)策略。即每個算法做出“軟”預測,給出每個可能的輸出標簽的概率。對所有樹的預測概率取平均值,然后將概率最大的類別作為預測結果。
隨機森林算法通過Python語言軟件平臺實現,在實現過程中的一個關鍵參數是max_features,較小的max_features可以降低過擬合。我們對不同max_features進行試驗,默認的max_features=sqrt(n_features)給出了比較好的結果。
3 實驗結果與討論
以(均值,方差,最小值,最大值,峭度,偏斜度,標準差)等七個時頻域參數為特征進行分類的結果如表2所示。除此之外,PCA搭配監督學習方法的分類結果也在表2中顯示作為對比。

表2 各方法準確率對比表
為證明所提模型的穩定性,隨機抽取源數據集不同比例樣本進行分類。PCA-RandomForest(R%)指隨機抽取源數據集中R%的樣本,利用PCA-RandomForest模型進行分類。結果如表3所示。
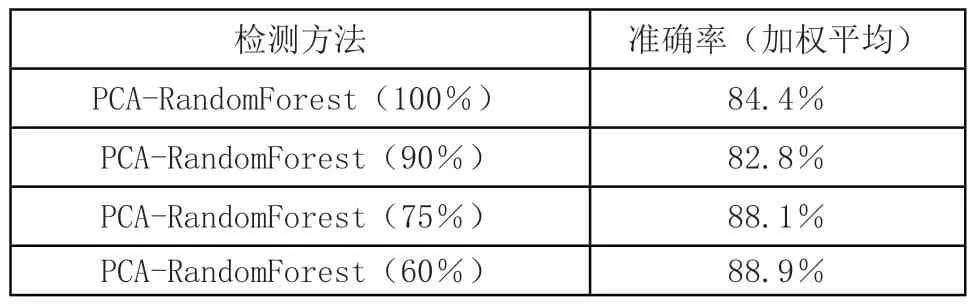
表3 不同比例源數據集準確率對比表
PCA-RandomForest(100%)竊電檢測模型的混淆矩陣如圖7所示。從中可以看出該模型非常均衡,對竊電用戶的識別率達到84%左右,同時對誠實用戶的誤診率小于15%。由此證明不同類型用戶每天的日用電量也為竊電用戶和和誠實用戶的不同特征之一,對此特征進行降維后進行竊電用戶的識別是有效的。
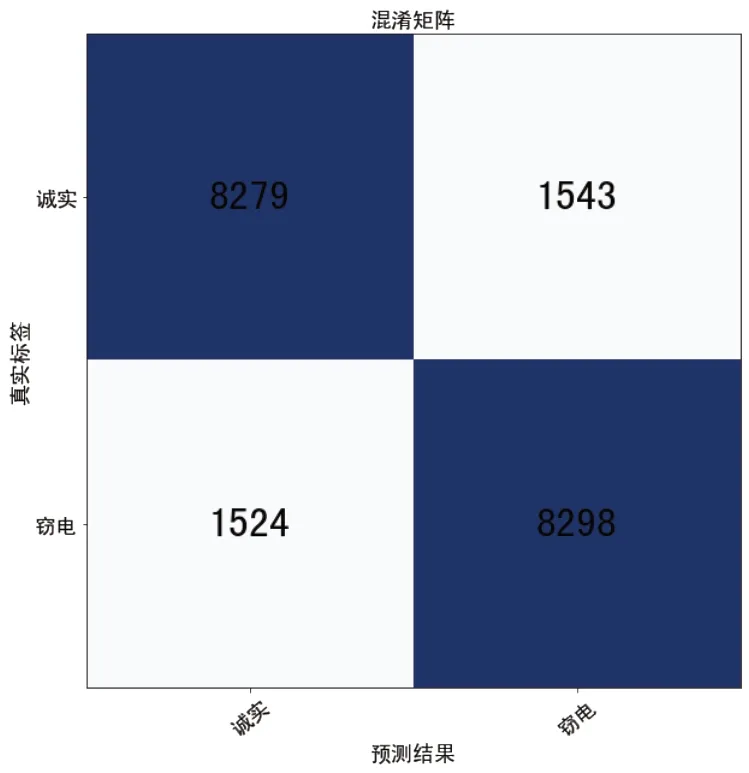
圖7 混淆矩陣圖
4 結語
本文基于由中國國家電網公司(SGCC)提供的帶竊電用戶標簽的真實數據集,對不同類型用戶用電數據進行分析,建立以用戶所有日負荷總量為特征的PCARandomForest竊電檢測模型。該模型非常均衡。利用該模型超過84%的竊電用戶被識別,而誠實用戶的誤檢率小于15%,這表明日負荷值的差異性同樣是識別不同類型用戶的有效手段之一。占比源數據集60%~90%的對比實驗證明了該模型的穩定性。事實上,由PCA-RandomForest的原理,該模型可適用于很多場景,尤其是工業應用。同時也可與其它模型共同作用,進行異常對象的識別。除此之外,我們對峭度等時頻域參數在竊電檢測領域中的效果進行了初步探索,給出對比結果,這也是我們正在嘗試的方向之一。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
