基于L8(27)改進高級醫學統計一例
2022-12-13 07:57:12俞鐘行
上海質量 2022年9期
◆俞鐘行/文
2×2×2列聯表在醫學、社會學領域應用頗廣,正交表L8(27)在質量管理領域應用普遍。說起來,2×2×2列聯表和正交表L8(27)都是處理3個因素2個水平8個數,但它們之間似乎從未有過交集。在跨界研究趨勢的引導下,本文試用L8(27)來處理2×2×2列聯表的一個較為高端的醫學問題,發現其便利、直觀、高效、精準,是一條值得嘗試的路徑。
1 .原例
《醫學統計學(第四版)》[1]中采用病例對照研究,研究避孕藥與等位基因在靜脈血栓發生中的作用。該研究共調查324人,其中病例155人、對照169人,數據記錄在表1的2×2×2列聯表中,欲對避孕藥與基因的交互作用進行分析。2×2×2列聯表有3個維度,稱為行、列、層,在表1中以X、Y、Z表示。每個維度有2個水平,不失一般性,這里以1和-1表示。應用列聯表,往往是為了挖掘和展示數據中隱藏的關聯,但有時還想對2×2×2列聯表中的數據建模,這就要應用高級統計方法——對數線性模型及SAS軟件了。
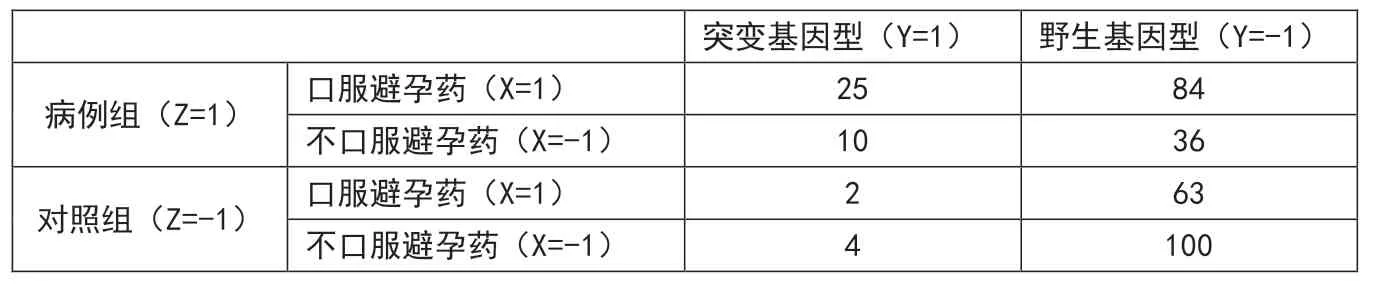
表1 基因與口服避孕藥對照研究頻數表
本例獲得的最優模型為:μijk=exp(μ+λiX+λjY+λkZ+λikXZ+λjkYZ),比全模型少了二階交互項XYZ和一階交互項XY。
得到的理論頻數如表2中相應括弧內的數字所示。

表2 基因與口服避孕藥對照研究頻數表
2 .基于L8(27)的改進
現在把基因與口服避孕藥對照研究看作L8(27)正交試驗,具體分析步驟如下。
①把表1中的8個數據填到表3最右列W的8個空格中,把它們看作是8次試驗的結果;
②作極差分析,如X列、K(+1)行對應的174,是X列取1時對應的W列4個數的和,依次類推。可以用Excel的內置函數sumif來作K(+1)和K(-1)的計算,非常方便。X的極差(R)=174-150=24,依次類推。于是得到所有因素及交互作用的極差從大到小的排序,極差越大、排序越靠前,表明此因素或交互作用越強。可以看到此項研究的關注點——是否服避孕藥(X)與不同基因類型(Y)的交互作用大小(以極差的排序表示)是最小的。
③在Excel裝上“數據分析”模塊,用其中的“回歸”對表3的上9行、右8列作分析。因為作為“Y值輸入區域”的W列只有8個數據,若把含因素的7列都放到“X值輸入區域”內,回歸會出錯。但是把極差最弱的那列XY刪去,再作回歸,就可以得到很好的結果。見圖1。

表3 基因與口服避孕藥對照研究L8(27)分析
此圖自上而下有3 個表。第一個表第1 行是復相關系數Multiple R=0.999975,標準誤差=0.707107,都很好。第二個表Significance F其實就是方程的p值=0.013295,殘差平方和/總計平方和=0.0005,都很小,說明回歸方程擬合得好。第三個表的Coefficients列給出了回歸方程的常數項、各因素及交互作用的系數,并且從P-value一列看到,沒有超過0.10的,2/3的項在0.05以下。而且各因素、交互作用的極差排序與它的P-value排序是一致的,即極差越大則P-value越小。這給了我們啟示,在數據建模時若需要刪除項,就先刪極差排序在最后的,因為它在回歸方程里也是統計最不顯著的。這相當于用“后退法”作逐步回歸。建立數據模型-回歸方程如下。
W=40.5+3X-30.25Y-1.75Z+12.75XZ+9YZ-8.5XYZ。
④把表3中8次試驗X、Y和Z取的值代入上述回歸方程,可以得到擬合值。它們和實測值相比,都是增大或減小了0.25。然而在表2中,理論值(即擬合值)和實測值的差距都超過0.25,所以,該“簡單”方法比“高級”方法的結果要更好一點。
3 .關于“效應排序原則”的討論
原例所選的最優模型中沒有二階交互項XYZ,好像很符合分析交互效應的“效應排序原則”[2]。它指出:(1)低階效應應比高階效應更重要;(2)同階效應的重要性應是相同的。但是,它同時指出:這個原則在因子效應的數目較大而不能全部進行估計時特別有效,這是一個經驗原則。本文討論的例子只有3個因子,用L8(27)進行分析時,對所有低階效應和高階效應都作了完備的分析。而且,在作L8(27)極差分析時,明顯地看到高階效應XYZ比低階效應XY、X和Z都強。同時,看到由于用基于L8(27)的方法時保留了XYZ項,所得的數學模型擬合得更好。《世界級質量管理方法》一書中有個“摩托羅拉波焊24全析因設計”的例子[3],由于16次試驗可以估計所有的主效應和各階交互作用,因此看到有個三因子交互作用就比有的二因子交互作用強,可見這種情況并非罕見。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
核科學與工程(2021年4期)2022-01-12 06:30:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
今日農業(2020年19期)2020-12-14 14:16:52
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
電子制作(2018年18期)2018-11-14 01:48:24
兒童繪本(2018年5期)2018-04-12 16:45:32
中學物理·高中(2016年12期)2017-04-22 11:53:03
山東工業技術(2016年15期)2016-12-01 05:31:22
