基于Swin Transformer的交通信號燈圖像分類算法
2022-12-21 08:24:12張緒德李康
電子制作 2022年23期
張緒德,李康
(凱里學院,貴州凱里,556011)
0 引言
隨著人工智能科學的發展,智慧交通逐漸影響人們的日常出行。信號燈是智慧交通的重要組成部分,基于交通信號燈的圖像分類識別是進行研究的基礎[1-2]。圖像分類采用的算法主要有基于CNN 網絡模型[3],CNN 網絡模型是由簡單神經網絡發展改進而來,相比于神經網絡主要采用卷積層和池化層替代全連接層結構,卷積層能夠有效地將圖像中的各種特征提取出并生成特征圖[4],但CNN 模型學習全局特征能力不強,為更好實現對信號燈圖像分類可采用基于自注意機制的深度神經網絡Transformer,Transformer 模型具有多頭自注意力機制,可以通過此機制進行特征提取,使用自注意力機制相比于CNN 模型能學習到全局特征,可以減少對外部信息的依賴,能更好的捕獲數據或特征內部的相關性,從而提取更強有力的特征。
1 Swin Transformer 算法模型
■1.1 Transformer 算法模型
Transformer 模型最早是Google 在論文Attention is All you need[5]中提出,模型起初是用在進行自然語言處理,由于模型表現出強大能力,科學工作者嘗試將Transformer 應用于CV 領域中進行處理計算機視覺相關的任務,Vision Transformer 的提出首次將Transformer模型架構用于處理圖像中的相關信息,并且取得很不錯的效果[6],在目標檢測領域隨著DETR 模型出現首次應用Transformer 模型[7], DETR 模型進行檢測時采用卷積神經網絡基礎上增加Transformer 模型的編碼器和解碼器。針對Vision Transformer 存在計算參數量大提出一種滑動窗口自注意力機制,在局部窗口進行自注意力機制有效降低參數量,同時采用卷積神經網絡思想采用層次化構建方式堆疊Transformer 模型,Swin Transformer 模型得到迅速發展。Transformer 模型的核心是使用Self-Attention 結構。相比于CNN 模型每次在進行特征提取時只能提取局部特征,Transformer 模型每次可提取全局特征,同時高效的進行并行計算。
Transformer 模型進行特征提取時采用多頭注意力機制,使用自注意力機制時可以提取圖像中的所有信息,可以減少對圖像中外部信息的依賴,更好捕獲圖像中相關聯信息。但對圖像分辨率比較高、像素點多時使用自注意力的計算會導致計算量較大,模型訓練起來難度較大[8]。
■1.2 Swin Transformer 算法模型
針對Transformer 模型參數量大不易訓練,Swin Tran sformer 算法[9]模型通過采用滑窗操作、層次化構建方式構建Transformer,極大減少模型參數量更好實現輕量化目標,該模型采用移動窗口的形式計算模型的自注意力,允許進行跨窗口連接,降低模型的復雜度提高模型的運行效率。
Swin Transfomer模型由窗口多頭自注意力層(W-ΜSA)、滑動窗口多頭自注意力層(SW-ΜSA)、標準化層(LN)、多層感知機(ΜLP)[10],圖1 為Swin Transfomer 的網絡結構。
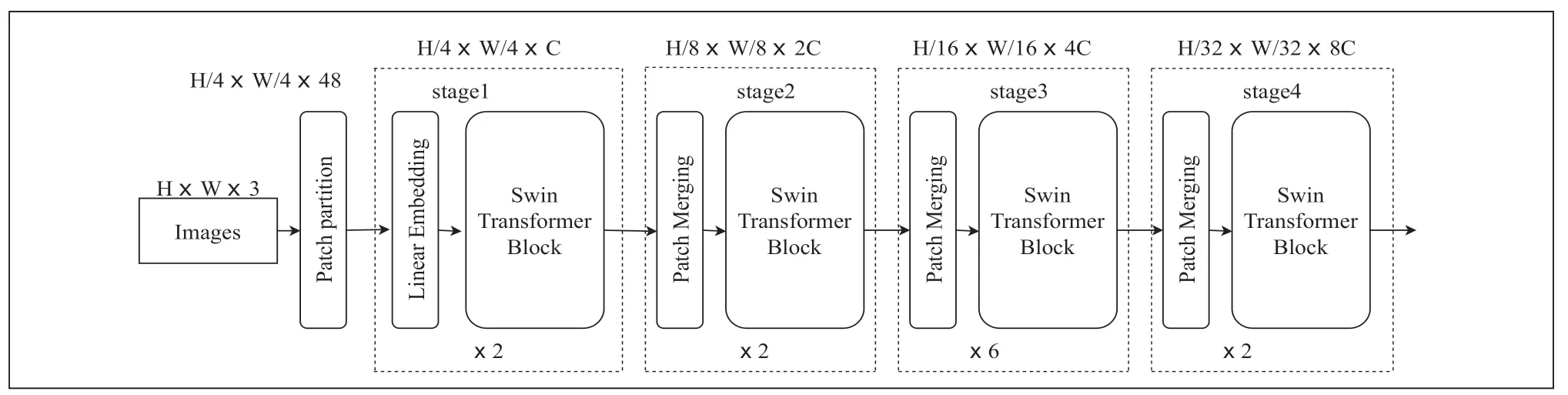
圖1 Swin Transfomer 網絡結構
基于全局的自注意力計算會導致平方倍的復雜度,當進行視覺里的下游任務時尤其是密集預測型任務或者非常大尺寸的圖片時,基于全局計算自注意力的復雜度會非常的高,而Swin Transformer 則采用了窗口計算自注意力。對于圖2 中的W-ΜSA 和SW-ΜSA 是Block 的核心,當使用普通的Μulti-head Self-Attention(ΜSA)模塊時如圖3 左側圖時需要計算每個像素與所有像素進行運算,對于W-ΜSA模塊如圖3 右側計算時這是將feature map 分為Μ x Μ(圖中Μ 為2)劃分為小的窗口,然后對每個窗口單獨進行計算。
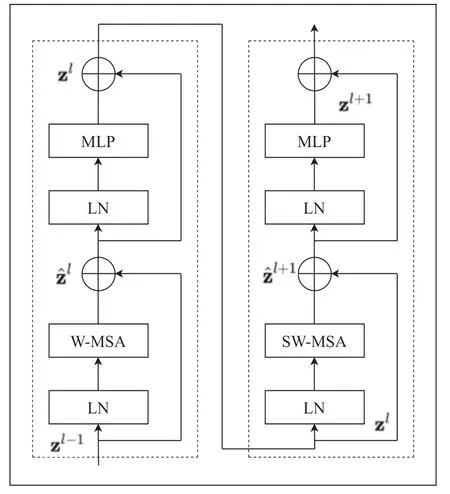
圖2 Swin Transfomer Blocks

圖3 MSA 模塊轉變到W—MSA 模塊
對于采用Swin-Tiny 的結構時,交通信號燈圖片輸入Swin Transfomer 模型首先在Patch Partition 模塊中進行分塊,設定每4×4 相鄰的像素為Patch,在channel方向進行展平,然后圖像經過四個Stage構建特征圖,其中圖像在經過時 Stage1 中要先通過Linear Embeding 層,剩下三個stage 都要先經過Patch Μerging 層,圖像經過stage4 時后會經過Layer Norm 層、全局池化層以及全連接層最后得到分類后的圖像,其中圖像經過Swin Transfomer Block 如圖2 所示。
對于ΜSA 和W-ΜSA 的計算量公式分別如公式1 和公式2 所示。

h 為feature map 的高度、w 為feature map 的寬度、C 為feature map 的深度,Μ 為每個窗口的大小,通過公式對比發現W-ΜSA 計算量相對于ΜSA 大幅度減少。
引入W-ΜSA 模塊是為了減少計算量,但是采用W-ΜSA模塊時,會存在像素只在每個窗口內進行自注意力計算,而窗口與窗口之間是無法進行信息傳遞的。為了解決這個問題,Shifted Windows Μulti-Head Self-Attention(SW-ΜSA)模塊,將W-ΜSA 進行偏移如圖4 所示,當窗口發生偏移,窗口之間能進行信息交流,SW-ΜSA 模塊有效解決不同窗口之間無法進行信息交流的問題。

圖4 W—MSA 模塊轉變到SW—MSA 模塊
2 信號燈圖像分類實驗與分析
■2.1 實驗環境配置
基于Swin Transfomer 模型進行交通信號燈圖像分類算法采用的實驗環境Windows10,顯卡顯存為11GB,模型訓練時GPU 采用NVIDIA GeForce RTX 2080Ti,軟件環境選擇 pycharm 腳本編輯器,學習框架為PyTorch。
■2.2 交通信號燈數據集
在進行圖像分類識別的算法研究中,合適數據集的選取是進行研究的基礎,數據集選取選取應該選取類別均衡、使用場景普及化、數據量大等優點數據集選取不標準訓練過程中容易出現飽和和過擬合的現象,會引起模型應用范圍小,泛化能力不足等問題。根據日常所見的交通信號燈,制作數據集圖片的標志分別為green、red、 yellow,數據集在制作時采取隨機數據增強的方式,將部分圖像進行旋轉、模糊以及裁剪等操作,使用數據增強后數據集包含訓練照片2400 張,其中紅燈、綠燈、黃燈圖片各800 張。驗證照片600 張,其中紅燈、綠燈、黃燈圖片各200 張,實驗中部分數據集圖片如圖5 所示。

圖5 交通信號燈圖
■2.3 模型訓練
在模型訓時,選擇合適的學習率、優化方式、損失函數進行訓練,借助不同的數據增強方式,可以增加模型對數據的敏感力。在進行數據集訓練時為加快模型收斂,需要先加載預訓練權重,加載swin_tiny_patch4_window7_224預訓練權重時,如當輸入圖片為224×224×3 圖片進行前向傳播時,圖片經過Patch Partition 模塊后圖片變為56×56×48,此時Patch Partition 模塊相當于大小為4×4,步長為4 卷積塊。56×56×48 的圖像繼續前向傳播通過Linear Embeding 層對每個像素的channel 數據做線性變換,此時圖像為56×56×96,經過stage1 時圖像為56×56×96,經過stage2 時圖像為28×28×192,經過stage3 時圖像為14×14×384,經過stage4 時圖像為7×7×768,stage4 輸出值經過Layer Norm 層、全局池化層以及全連接層最后得到分類后的結果。
圖像在經過四個Stage 時,除Stage1 中先通過一個Linear Embeding 層外,剩下stage 都是直接經過Patch Μerging 層然后進行下采樣。Swin Transformer Block 包含兩種結構,分別是W-ΜSA 結構和SW-ΜSA 結構,這兩個結構是成對使用的,因此堆疊Swin Transformer Block的次數是偶數。
利用制作完成后交通信號燈數據集,進行Swin Transfomer 模型圖像分類算法對數據集進行模型訓練。模型訓練過程中分為30 個 epoch 進行訓練,Batchsize 設置為8,Swin Transfomer 模型的參數如表1 所示。
訓練時為加快模型收斂添加預訓練權重。數據集訓練時需要進行不斷地調節參數是訓練過程不斷進行優化,在訓練的前期階段訓練時采用學習率較大的量級,當訓練過程后期可以采用相對之前學習率較小的量級,其次當考慮動量對訓練過程的影響,當對數據集訓練達到瓶頸時修改動量以提高預測精度。在對訓練集進行30 次訓練迭代后,取訓練權重中最好的權重進行模型的驗證,獲得最優的訓練模型,訓練過程如圖6 所示。

圖6 Swin Transfomer 訓練過程
■2.4 結果與分析
本次研究訓練結果的評價指標是準確率(Accuracy)進行評價,準確率計算公式如下所示:

其中,TP為被劃分為正類且判斷正確的個數,TN為被劃分為負類且判斷正確個數,FP為被劃分為正類且判斷錯誤的個數,FN為被劃分為負類且判斷錯誤個數。
在對交通信號燈進行預測時,選取圖片需要考慮不同光線、不同場景、不同時間、不同角度中實際情況。在選取圖片驗證結果時選取沒有參與數據集訓練圖片進行驗證,使用Swin Transfomer模型在交通信號燈數據集進行訓練驗證,交通信號燈圖像分類測試如圖7 所示。

圖7 Swin Transfomer 圖像分類測試結果
從測試圖7 可以看出,圖像經過Swin Transfomer 模型訓練后可以達到較好的效果,隨機選取紅綠燈圖像進行驗證,模型能很好的進行預測。
3 結語
Transformer 模型最開始應用于處理自然語言領域,Transformer 可以采集全集信息相比于CNN 減少對外部信息的依賴,Transfomer 模型得到極大關注。本研究基于Swin Transfomer 模型圖像分類算法,通過交通信號燈數據集選取與制作、數據集訓練、測試結果驗證Swin Transfomer 模型在圖像分類中有很好的應用。但Swin Transfomer 模型在實際應用中存在的諸多挑戰,模型相比于CNN 更加復雜,參數量相比于CNN 中的輕量化網絡依然很大,部署在邊緣端任重而道遠。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
