基于SSA-LSTM的玉米土壤含氧量預測模型
2023-01-05 03:56:04于珍珍鄒華芬于德水劉天祥張欣悅
農業機械學報 2022年11期
于珍珍 鄒華芬 于德水 汪 春, 劉天祥 張欣悅
(1.黑龍江八一農墾大學工程學院,大慶 163319;2.中國熱帶農業科學院南亞熱帶作物研究所,湛江 524003;3.華中科技大學管理學院,武漢 430074)
0 引言
土壤含氧量(Soil oxygen content,SOC)是影響作物生長發育的重要土壤環境因子,土壤中水分、氣體比例不協調是農業可持續發展的主要障礙,也是影響我國生態環境健康和農業生產發展的重要制約因素[1-2]。當SOC小于10%時,作物有氧呼吸受阻或者中斷,作物水分和養分利用效率下降,呼吸作用產生的三磷酸腺苷(ATP,高能磷酸化合物)水平下降[3-5]。植物地上部分則表現為葉片萎縮,作物鮮質量和干質量顯著下降,是農作物高產的主要限制條件[6-7],加氣灌溉技術是目前對土壤進行通氣增氧的有效措施,但是由于土壤環境復雜而不穩定,土壤氧氣含量變化具有時序性、不穩定性和非線性等特點,通氣增氧的相關參數尚未形成量化體系[8-10]。SOC容易受到氣象因子(大氣溫濕度、太陽輻射、降雨量等)及土壤環境因子(土壤溫度、土壤含水率等)的影響[11-13],各因素存在復雜的耦合關系,因此,建立SOC預測模型對于作物種植具有重要的生產意義,也為土壤通氣增氧技術的管理決策提供理論依據。
近幾年人工神經網絡迅速發展,在解決函數逼近與數據預測等問題上效果良好[14-16],但是關于土壤含氧量預測方面的研究未見報道。關于水中溶解氧(Dissolved oxygen,DO)預測取得了一定的研究成果。長短時記憶(Long and short-term memory,LSTM)神經網絡模型,對長時間序列數據層具有較好的傳遞記憶功能,可以深度挖掘長距離時序數據信息,并且能消除反向梯度消失問題,被廣泛應用于各個領域[17]。LIU等[18]利用注意機制和遞歸神經網絡通過水溫、大氣相對濕度、太陽輻射等預測DO。HUAN等[19]以pH值、水溫、大氣相對濕度等為影響因素,采用基于梯度增強決策樹(GBDT)特征選擇的LSTM模型對DO進行預測;陳英義等[20]提出了基于WT-CNN-LSTM的溶解氧含量預測模型,提高池塘溶解氧的預測精度,后期,曹守啟等[21]提出了基于K-means聚類和改進粒子群優化(Improved particle swarm optimization,IPSO)的LSTM神經網絡預測模型,該模型一定程度解決了天氣突變狀況下的數據缺失、魯棒性差等問題。
LSTM預測的準確性與其權重和閾值的設置密切相關[22-23]。生物啟發式算法是LSTM參數優化的有效方法,包括遺傳算法(Genetic algorithm,GA)[24-26]、粒子群算法(Particle swarm optimization,PSO)[27-30]、蝙蝠算法(Bat algorithm,BA)[31]、灰狼優化算法(Grey wolf optimizer,GWO)[32-34]和麻雀搜索算法(Sparrow search algorithm,SSA)[35-37]。其中,SSA基于麻雀種群的覓食和反捕食行為,解決模型輸入權值和閾值的隨機變化問題,具有高性能全局搜索能力,穩定性及收斂精度好。SSA算法具有較快的收斂速度和強大的搜索能力,采用網格搜索對LSTM神經網絡模型的初始權值和閾值進行優化,克服了傳統神經網絡模型參數選擇的盲目性和不確定性,目前,SSA被廣泛應用于非線性時間序列數據處理,如短期風速預報、降雨分析預報,在收斂速度和尋優精度等方面有著顯著優勢且結構簡單、能準確應對復雜問題。
本研究提出SSA-LSTM神經網絡模型預測土壤含氧量,基于國家土壤質量湛江觀測實驗站2021年田間獲取的氣象因子及土壤環境因子,通過皮爾遜相關系數(Pearson correlation coefficient,Pearson)及斯皮爾曼相關系數(Spearman’s rank correlation coefficient,Spearman)明確土壤含氧量變化影響因子的主次順序,基于麻雀搜索算法優化建立SSA-LSTM神經網絡預測模型,并與傳統的BP預測模型、LSTM預測模型、GA-LSTM預測模型及PSO-LSTM預測模型訓練前后的精度及預測誤差進行對比,為探究土壤含氧量變化規律及土壤通氣增氧技術整體管理措施調整及決策提供技術指導。
1 材料與方法
1.1 數據來源
研究區域位于廣東省湛江市(110°27′E,21°16′N)國家土壤質量湛江觀測實驗站,年平均日照時間為2 160 h,無霜期為350 d,年平均氣溫為23.2℃,是典型的的亞熱帶季風氣候。試驗時間為2021年8月21日—11月12日,季節性種植作物為玉米,試驗區域及定位試驗點如圖1所示。
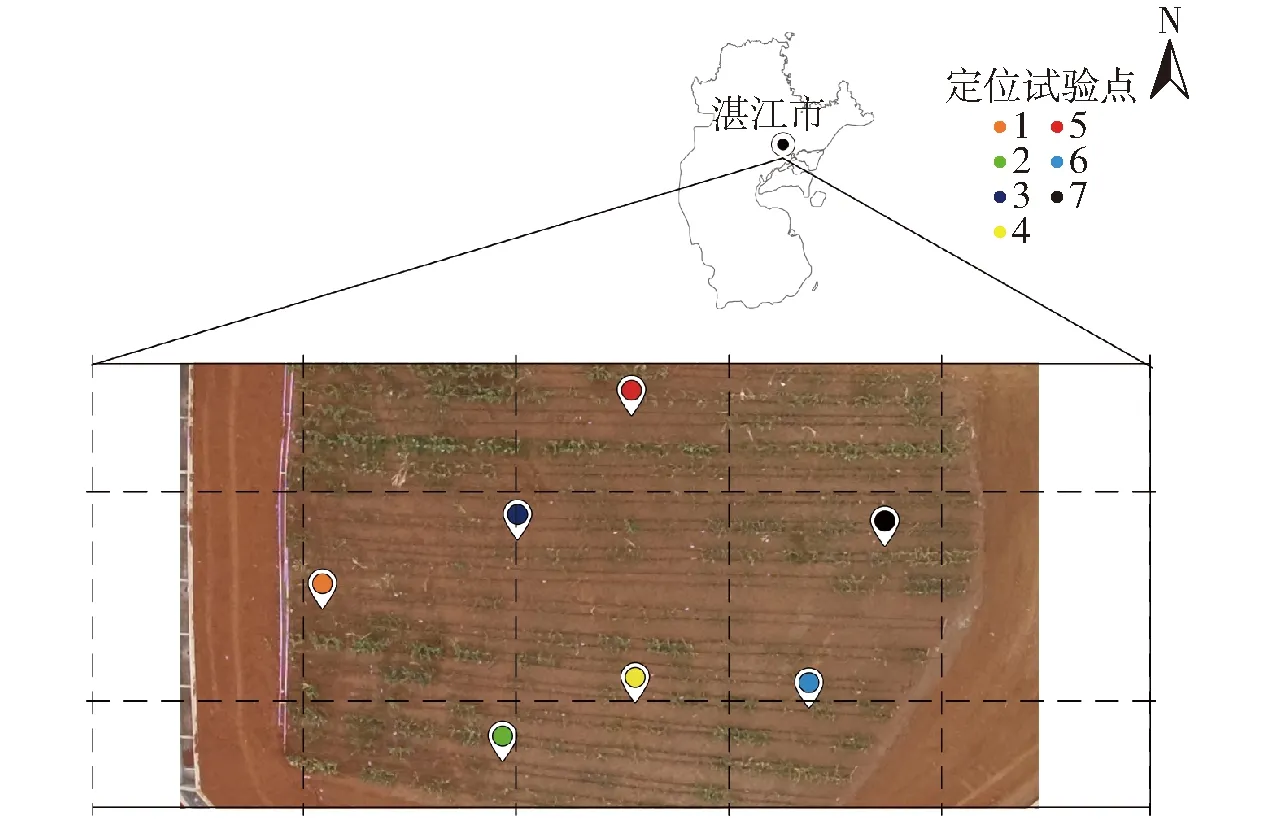
圖1 研究區域及定位試驗點示意圖
SOC主要來自土壤與大氣之間氣體交換。土壤空氣組成與大氣空氣組成近似(表1)。土壤O2濃度低于大氣,土壤和大氣之間產生O2分壓差,在分壓梯度的驅動下,O2不斷從大氣向土壤空氣擴散。土壤與大氣之間進行氣體擴散和整體交換,使得土壤中保持一定量O2(圖2a)。大氣環境主要通過影響氣體擴散進而影響SOC。大氣環境因素中,WILLEY等[10]研究表明,大氣溫度(Atmospheric temperature,Ta)變化是引起大氣與土壤氣體交換的主要因素,同時發現,隨著風速(Wind speed,SW)和大氣相對濕度(Atmospheric humidity,RH)的升高,SOC也逐漸提高。

表1 土壤空氣與大氣空氣組成成分比較
土壤中連續的充氣孔隙是作物根系-土壤-大氣之間唯一的聯系通道[30]。土壤充氣孔隙度(Air-filled porosity,AFP)充滿了空氣或水以及溶解的物質,固體為根和固定植物結構提供支持,水分滿足作物蒸騰需求,空氣為作物根系(和微生物)呼吸提供氧氣。O2以溶解氧方式通過根外水膜擴散到根系表面,最后,氧氣由根系表面擴散到根組織內,用于維持土壤中一切生物化學過程正常進行(圖2c)。田間灌溉和降雨(Rainfall,RF)會使土壤中持續存在飽和濕潤區,導致水分代替空氣存在于土壤中,進而限制了SOC的可利用性和移動性(圖2d),土壤SOC降低會導致作物根系土壤低氧脅迫,土壤呼吸(土壤中各項代謝活動)將受到限制(圖2b)。
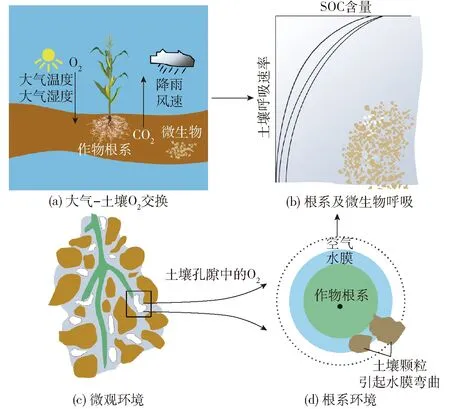
圖2 大氣-土壤-作物之間O2交換示意圖
土壤溫度(Soil temperature,Ts)以多種方式影響土壤氧氣的移動性與可利用性。首先,氧氣在水中的溶解度與溶液溫度成反比[11],其次,土壤溫度通過影響土壤呼吸(圖2d)(Soil respiration,Rs)進而影響SOC的變化[13]。土壤含水率(Soil water content,Ws)是影響SOC的關鍵因素。THONGBAI等[38]和BHATTARAI等[39]的研究均表明較高的水分變化可以調控植物體內水分的再分配和改變土壤的透氣性,從而影響植物體和微生物的代謝活動,最終導致SOC發生變化,通過進一步采用關聯系數法發現,較高的土壤水分不但阻礙大氣與土壤之間的氣體交換,直接導致SOC下降,也會抑制O2在作物根部周圍運動[11]。
因此,本研究選取Ta、RH、RF、SW、AFP、Ts、Rs及Ws共8個指標作為輸入,以SOC作為輸出構建網絡模型進行訓練和預測。
1.2 數據處理
氣象數據采用小氣候觀測儀(CAWS2000型,北京華云尚通科技有限公司),采集的氣象數據主要包括Ta、RH、RF和SW;土壤溫濕度(Ts和Ws)主要由浙江托普云農科技股份有限公司生產的TZS-PHW-4G型土壤多功能參數測定儀測定,可以自動存儲數據,土壤溫度測試范圍為-40~100℃,精度為±0.5℃,分辨率為0.1℃;土壤含水率測試范圍為0~100%,精度小于等于3%,分辨率為0.1%。
SOC采用MO-200型土壤氧氣測定儀進行定位記錄,由于土壤深度10 cm左右與大氣氣體交換較為通暢,一般不會出現缺氧現象,而作物根系大部分分布在土壤深度30~40 cm,所以本試驗選擇測定深度為30 cm。Rs采用Li-6400型土壤呼吸儀測定。AFP計算公式為
AFP=1-ρb/ρs-Ws
(1)
式中AFP——土壤充氣孔隙度,%
ρb——土壤容重,取1.32 g/cm3
ρs——土粒密度,取1.75 g/cm3
Ws——土壤含水率,%
1.3 試驗方法
相關試驗參數在每日07:00—09:00之間進行測量,相關研究表明該時段測得的土壤呼吸、充氣孔隙度等相關參數可以代表當日的平均值。人工測量時實時讀取數據,如遇強降雨天氣則推遲時間段進行測定。由于土壤含氧量的影響因素之一——土壤呼吸主要由作物根系呼吸及土壤微生物呼吸組成,因此,為了豐富數據來源,在玉米種植前9 d(2021年8月12—20日)進行裸地測量(此時,未進行玉米種植,土壤中不存在作物根系,微生物豐度也較低),玉米種植期間(2021年8月21日—11月12日)及玉米收獲后10 d(2021年11月12—21日)進行裸地測量(此時,土壤中還存在一些玉米根茬及相關土壤微生物)。因此,本研究所測的7個試驗地點共獲得682組試驗數據。其中6個試驗地點土壤含氧量為訓練樣本,以1個試驗地點數據作為驗證,分別采用BP預測模型、LSTM預測模型、PSO-LSTM預測模型、GA-LSTM預測模型以及SSA-LSTM預測模型進行預測,全文采用Matlab進行編程與模型建立。
2 預測模型構建
2.1 LSTM神經網絡模型構建
LSTM最初是傳統遞歸神經網絡的變體。在處理時間序列預測時具有較強的記憶能力,被廣泛應用于時間序列中具有長時間時間間隔和時滯的預測場景,LSTM單元的基本結構如圖3a所示。
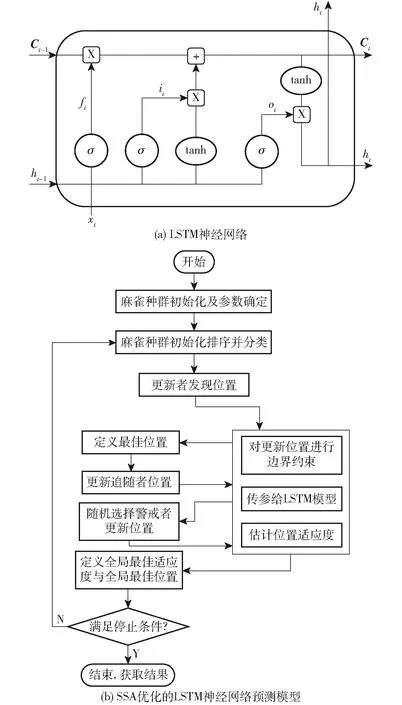
圖3 預測模型
LSTM在神經網絡的基礎上增加了更多的神經網絡層,增加了記憶單元、輸入門、輸出門和遺忘門4個具有記憶功能的模塊,有選擇地讓信息通過,每個門的功能各不相同。
遺忘門ft負責決定從記憶單元中丟棄哪些信息,更新公式為
ft=σ(wfxxt+wfhht-1+wfcCt-1+bf)
(2)
式中σ(·)——sigmoid的激活函數
xt——t時刻輸入
ht-1——t-1時刻輸出
Ct-1——t-1時刻候選向量
wfx、wfh、wfc——遺忘門權重系數
bf——遺忘門偏置
輸入門it負責決定哪些信息可以保存在記憶單元中,更新公式為
it=σ(wixxi+wihht-1+wicCt-1+bi)
(3)
(4)
(5)
式中wix、wih、wic——輸入門權重系數
bi——輸入門偏置
wcx、wch——候選向量的權重系數
bo——候選向量偏置
tanh(·)——雙曲正切激活函數
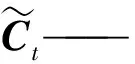
Ct——t時刻的侯選向量
輸出門決定將輸出哪些信息。除所需信息外,沒有其他信息可以通過輸出門。其表達式為
ot=σ(woxxt+wohht-1+wocCt-1+bo)
(6)
ht=ottanh(Ct)
(7)
式中ot——輸出門
wox、woh、woc——輸出門權重系數
ht——t時刻輸出
2.2 SSA優化算法
SSA是根據麻雀覓食和反捕食行為的啟發而提出的新型群體智能優化算法。SSA主要模擬了麻雀群體覓食的過程,每只麻雀都有3種可能的行為:發現者(搜索食物);加入者(跟隨發現者覓食);偵察者(警戒偵查)。其中,發現者是麻雀中找到食物較早的個體,加入者則為其他個體,同時在麻雀種群中還有一定比例的個體進行偵察預警,它們的任務是在發現危險的情況下放棄食物,選擇安全第一。
在模擬試驗中,使用虛擬麻雀來尋找實物,n只麻雀種群可以表示為
(8)
式中d——待優化變量維數
所有麻雀適應度可以表示為
(9)
式中f(x)——適應度
SSA算法中所有的生產者、具有較好適應度的發現者在搜索過程中會優先獲取食物,并負責為種群尋覓食物以及為發現者、加入者和偵察者根據各自的規則更新喂食,表達式為
(10)
式中t——當前迭代次數
rmax——最大迭代次數,常數
Xij——第i只麻雀在第j維中的位置信息,j=1,2,…,d
α——隨機數,α∈(0,1]
ST——安全值,ST∈[0.5,1]
R2——警告值,當R2≤ST時,發現者可以執行搜索操作,而當R2≥ST,表示發現者種群發出預警,迅速飛離,R2∈(0,1]
Q——服從正態分布的隨機數
L——L×d矩陣,矩陣中的每個元素均為1
對于加入者執行
(11)
式中Xbest——當前最優位置
Xworst——極差位置
β——步長控制參數
K——服從正態分布的隨機數,K∈[-1,1],其均值為0,方差為1
fi——當前麻雀的個體適應度
fg、fw——當前全局最佳適應度和最差適應度
ε——避免分母為零的最小常數
監視發現者同時隨時準備與之競爭,否則執行
(12)
式中Xp——發現者所占據的最佳位置
A——1×d矩陣,其中每個元素隨機賦值為1或者-1,且A+=AT(AAY)-1
當i>n/2,表示適應度較低的第i個加入者沒有得到食物。
預警者一般占種群數量的10%~20%,按式(12)更新站位。
SSA實現步驟如下:①初始麻雀數量并定義相關參數。②按照適應度進行順序排列,找到當前最佳適應度個體和最差適應度個體。③利用 式(10)更新麻雀(發現者)在適應度方面的位置。④使 用式(12)更新晚期麻雀(scrounger)的適應度位置。⑤使用式(11)隨機更新部分麻雀的位置。⑥獲取當前更新位置。⑦如果新的位置比舊的位置好,則更新舊的位置。⑧重復步驟④~⑧。⑨輸出最佳適應度和單個麻雀。
2.3 SSA-LSTM組合預測模型
為了提高預測精度和穩定性,本文提出了一種混合模型SSA-LSTM(圖3b),利用SSA優化LSTM的初始隱層節點數和學習率。SSA-LSTM模型的主要步驟如下:
(1)模型初始化:初始化SSA的參數,包括麻雀種群位置、參數取值上下限及最大迭代次數。初始化LSTM結構,以LSTM模型的隱層節點數和學習率作為優化目標。
(2)目標函數建立:SSA的目標函數是未經訓練的LSTM模型預測值與實際值相比的均方根誤差(RMSE)。
(3)優化:根據目標函數的結果更新麻雀的位置,當滿足初始設定的迭代次數時,LSTM的初始值達到最優。
(4)LSTM訓練:將尋優后求得的最優參數代入LSTM模型,重新進行訓練和預測,得到最終的預測模型。
2.4 模型性能評估
為了定量評估SSA-LSTM優化的神經網絡預測模型的有效性和準確性,采用均方根誤差(RMSE)、平均絕對誤差(MAE)和平均誤差(MAPE)進行模型評估。
3 結果與分析
3.1 土壤含氧量變化及影響因子相關性分析
由8個影響因子與SOC的Pearson相關系數可知,SOC與RF、Ws、Ts和AFP相關性極顯著,相關系數均高于0.8,與Ta、SW相關性顯著,與RH、Rs相關性較弱(圖4)。
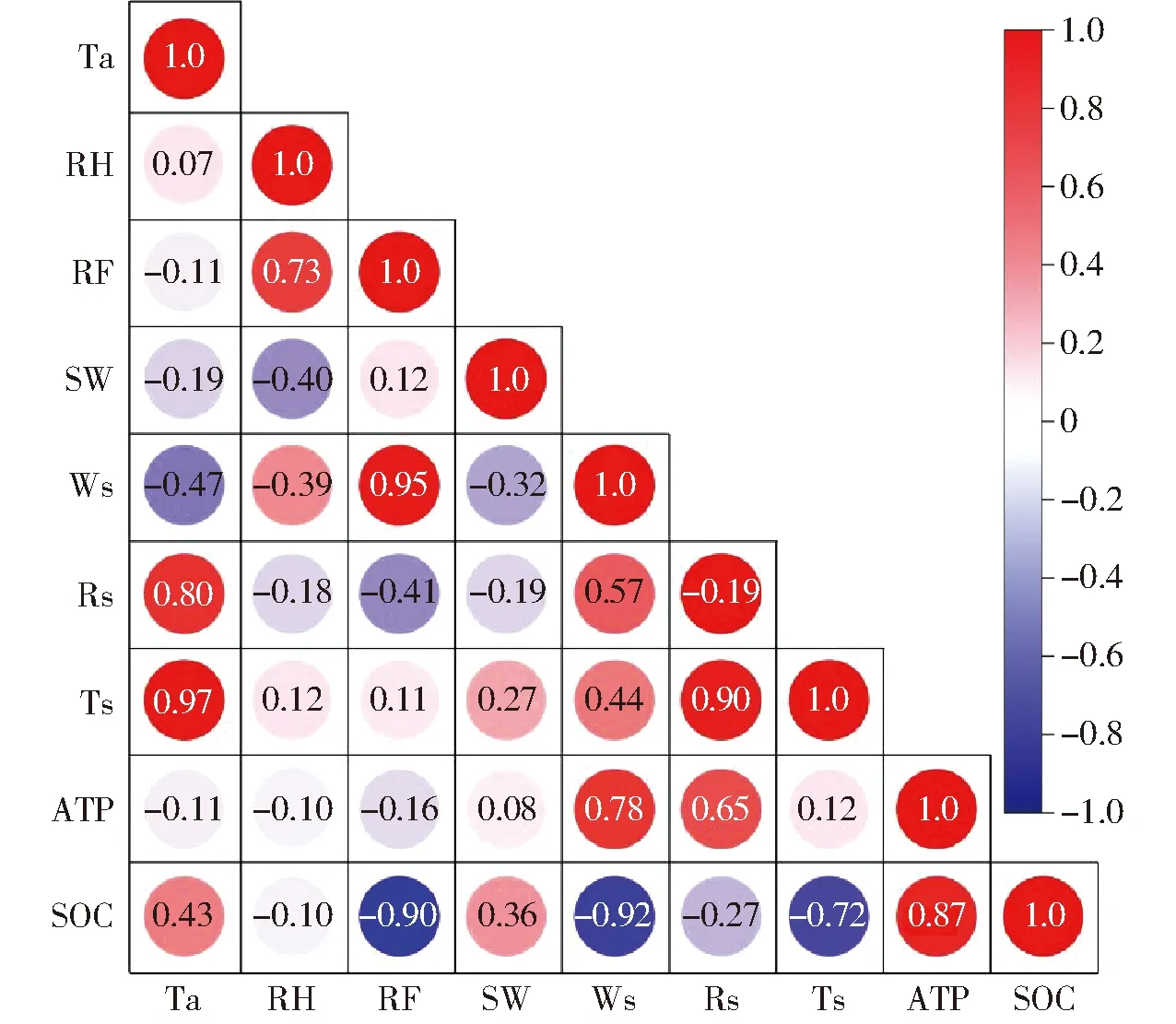
圖4 SOC與影響因子的Pearson相關系數
考慮到大氣溫度與土壤溫度對SOC的影響有一定的滯后效應,大氣溫度的變化對土壤溫度產生直接影響,土壤溫度的變化對土壤中的運動、土壤中各項生化活動產生影響,進而對SOC的變化產生影響,所以考慮滯后效應,修正后大氣溫度相關系數由0.43提升至0.51,土壤溫度相關系數由-0.72提升至-0.81。
3.2 算法參數設置
通過前期試驗,采用試湊法得到本次試驗設置的BP預測模型中相應參數:最大迭代次數為500,隱層節點數目為25,訓練精度為0.000 01,學習率設置為0.1;SSA算法優化LSTM網絡的兩個參數為隱藏神經元數和學習率,將SOC真實數據與預測數據的均方根誤差作為適應度函數。同時設置麻雀種群數量為20,迭代次數為50,神經元個數m設置范圍為[1,100],學習率為[0.000 1,0.01],經過SSA算法優化后隱藏神經元數和學習率的取值為30、0.008 5;設置GA算法的種群規模為20,交叉概率為0.3,變異概率為0.1,迭代次數為50;設置PSO算法中種群迭代次數為50,規模為20,參數c1和c2均為1.8。
3.3 模型預測對比分析
根據所測數據,構建基于BP預測模型、LSTM預測模型、GA-LSTM預測模型、PSO-LSTM預測模型、SSA-LSTM預測模型共5種預測模型,各模型對SOC預測結果如圖5所示。由圖5a、5b可以看出,BP預測模型及LSTM預測模型預測誤差較大。PSO-LSTM預測模型在土壤含氧量9.6%~12.5%的范圍內模型預測誤差較大;GA-LSTM預測模型具有良好的收斂性,當土壤含氧量高于14.2%時,會出現較大的誤差,且遺傳算法步驟復雜,運算繁瑣。SSA-LSTM預測模型具有良好的適應性和預測精度(圖5e),實測值與預測值曲線擬合更接近,說明SSA-LSTM預測模型具有更好的擬合效果和泛化能力,體現了優化算法的相對優越性。
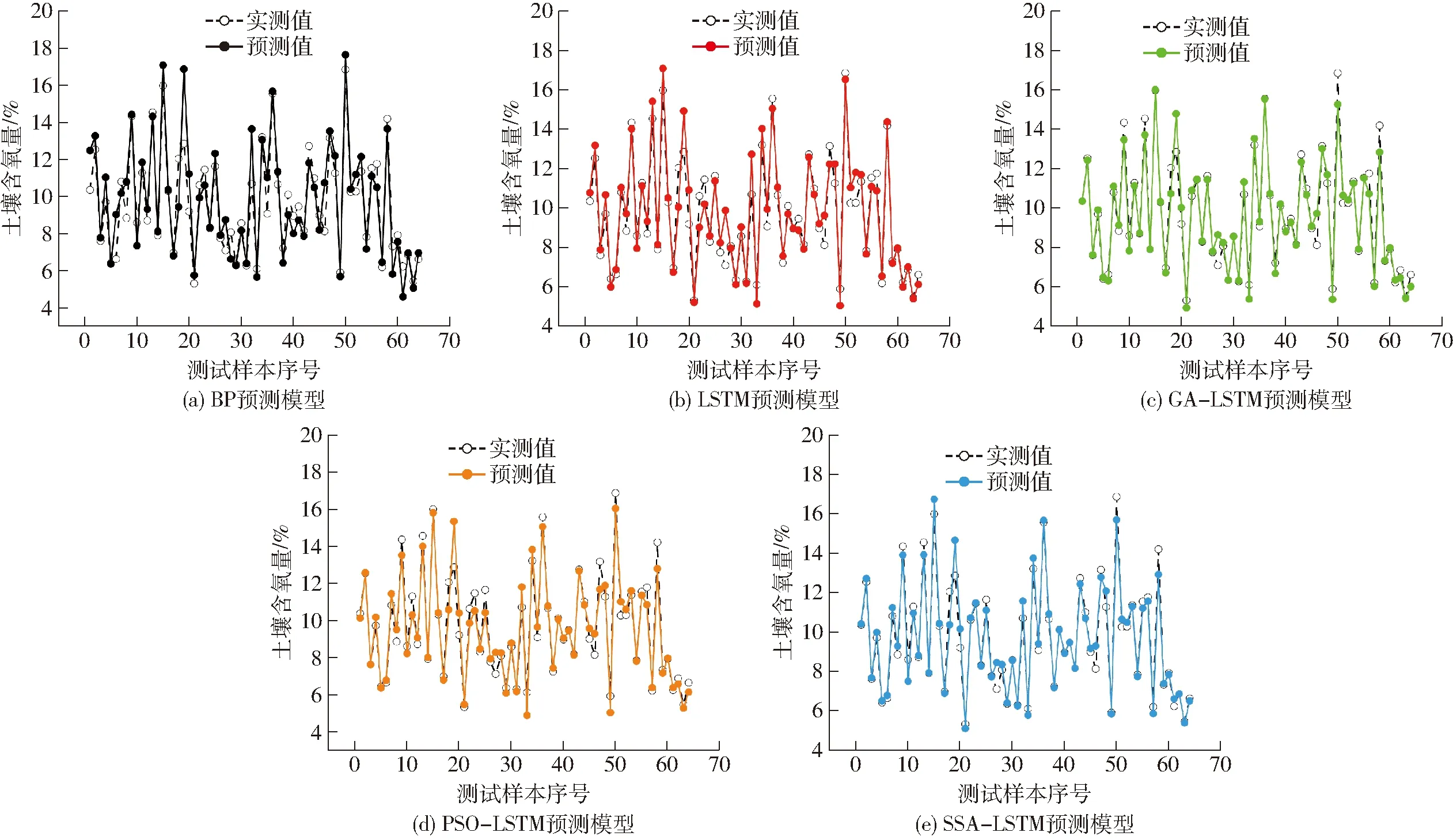
圖5 不同神經網絡模型的預測曲線
為了驗證5種模型的預測性能,驗證數據的實測值與預測值的相關系數曲線如圖6所示。不同網絡模型的擬合程度由高到低依次為SSA-LSTM預測模型、GA-LSTM預測模型、PSO-LSTM預測模型、LSTM預測模型、BP預測模型。SSA-LSTM預測模型回歸擬合較好,相關系數R增加到0.979 69,決定系數R2增加到了0.959 79,與傳統的BP預測模型、LSTM預測模型、GA-LSTM預測模型及PSO-LSTM預測模型相比,SSA-LSTM算法的R分別提高5.52%、2.30%、0.28%、1.25%,R2提高10.74%、4.55%、0.56%、2.48%。
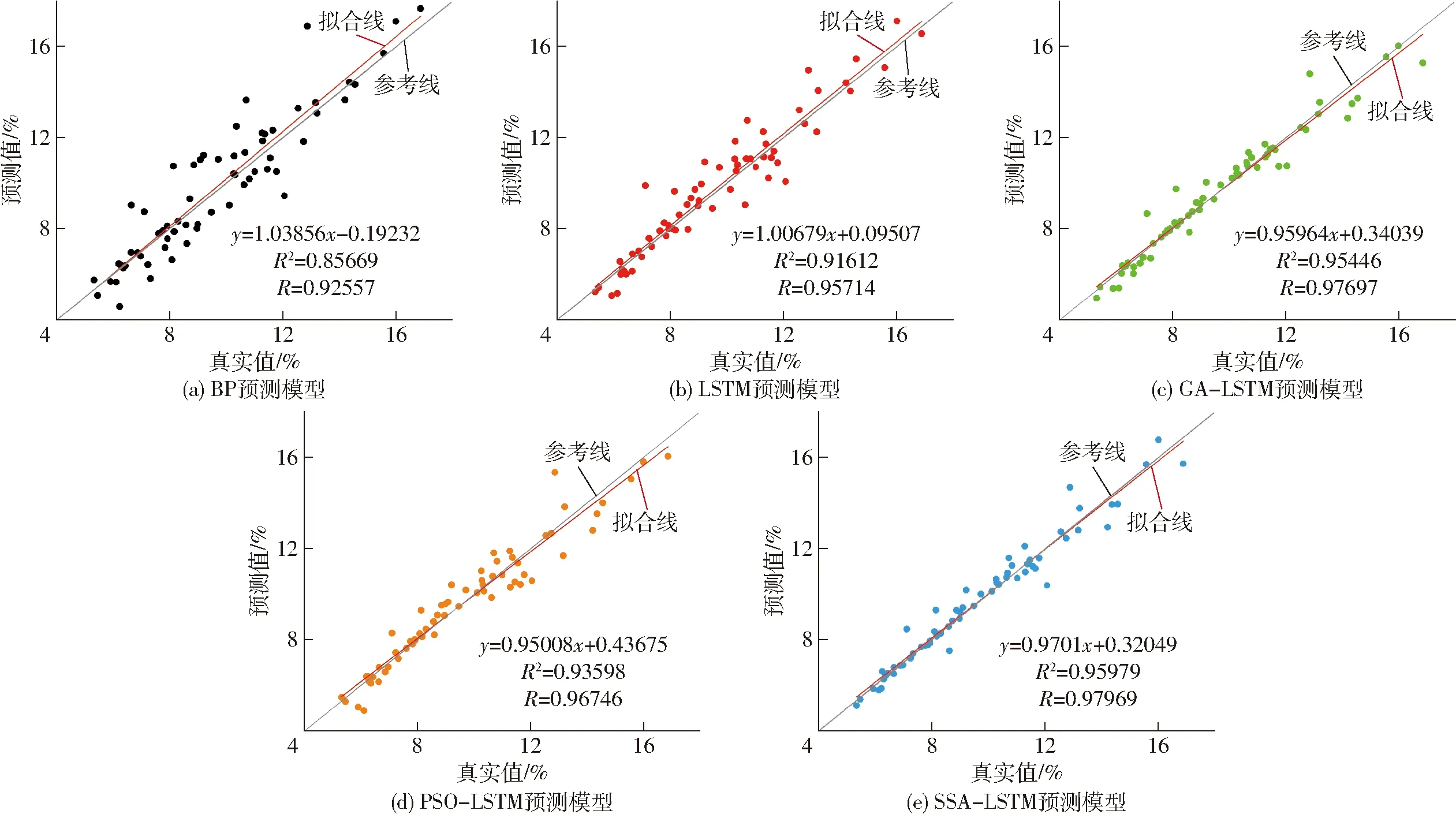
圖6 不同神經網絡模型預測值與實測值間的相關性分析
對5種預測模型的預測結果進行量化,并利用模型評價指標對模型進行對比分析(表2)。與傳統的BP預測模型、LSTM預測模型、GA-LSTM預測模型及PSO-LSTM預測模型相比,SSA-LSTM模型的RMSE分別降低58.64%、42.40%、20.04%、42.32%,MAPE分別降低59.85%、44.16%、4.02%、41.21%,MAE分別降低58.22%、43.70%、2.45%、38.26%。
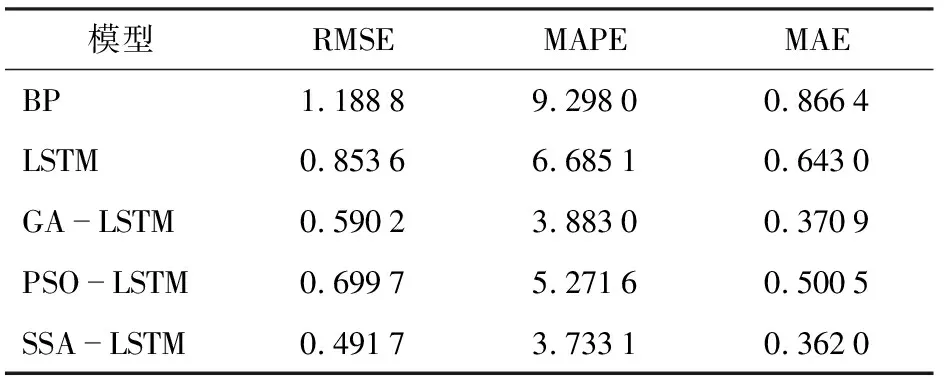
表2 BP預測模型、LSTM預測模型和SSA-LSTM預測模型性能分析
3.4 模型預測誤差分析
不同模型的預測誤差分布如圖7所示。以分布誤差為0的分界線,向兩端擴散增大,0軸表示真實值與預測值結果一致,越接近0,代表預測值與實測值的差值越小,模型的預測精度越高。從圖7可以看出,與BP、LSTM預測模型相比,GA-LSTM、PSO-LSTM及SSA-LSTM預測模型的誤差直方圖誤差接近0的個數更多且誤差更小。其中,在組合預測模型里,本文所提出的SSA-LSTM模型在零區間分布的數量更多,誤差更小,其他組合模型GA-LSTM、PSO-LSTM在零區間分布個數分別為48和38,誤差較大。
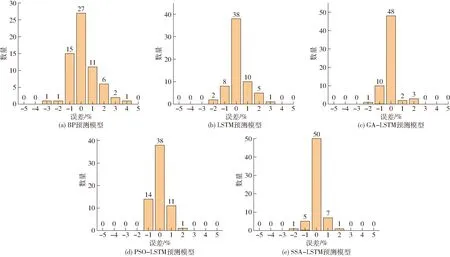
圖7 不同神經網絡模型預測誤差分布圖
4 結論
(1)利用SSA搜索算法優化后的LSTM神經網絡預測模型,采用網格搜索對LSTM神經網絡模型的隱層節點數和學習率進行優化,克服了傳統神經網絡模型參數選擇的盲目性和不確定性,提高了搜索精度、收斂速度和預測穩定性。
(2)通過對所選影響因子與SOC的Pearson相關系數分析可知,SOC與RF、Ws、Ts和AFP相關性極顯著,相關系數均高于0.8,與大氣溫度、風速相關性顯著,與大氣濕度和土壤呼吸速率相關性較弱,其中,土壤呼吸是吸收O2排出CO2的過程,呼吸強度不僅受到土壤非生物因子的影響,更多地是受到生物因子的制約,主要與土壤中的根系、微生物數量有關,因此,土壤呼吸速率與SOC的相關性較弱。
(3)將BP預測模型、LSTM預測模型、GA-LSTM預測模型、PSO-LSTM預測模型和SSA-LSTM神經網絡模型進行SOC預測分析,SSA-LSTM預測模型比其他神經網絡模型表現出更好的預測性能。經過不斷迭代訓練,SSA-LSTM網絡模型預測精度R2達到0.959 79,RMSE僅為0.491 7%,MAPE 為3.733 1%,MAE為0.362 0%,預測值與試驗值之間的擬合程度高。研究結果為土壤氧氣含量的預測提供一種新的思路和方法,為土壤通氣增氧技術提供理論依據與基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
軍事文摘(2023年10期)2023-06-09 09:15:06
空間科學學報(2021年4期)2021-08-30 08:31:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
河北書畫研究(2016年2期)2016-08-24 02:14:50
新農業(2016年18期)2016-08-16 03:28:27
核科學與工程(2015年4期)2015-09-26 11:59:03
世界知識畫報·藝術視界(2010年9期)2010-12-31 00:00:00
