模糊聚類算法對受眾性格的分類分析
2023-01-06 03:46:08鄒序焱蔣利娜
宜賓學院學報 2022年12期
鄒序焱,蔣利娜
(宜賓學院人工智能與大數據學部,四川宜賓 644000)
在日常生活與工作中可以通過個人行為習慣來了解其個性,一個人喜好的文學作品和影視作品也能反映一個人的性格特征[1],管理方即可針對不同性格群體作出不同的決策.如王紅等人[2]通過館藏圖書分類和流通數據,探索受眾與圖書流通之間的隱含規律,發現受眾特征與館藏流通之間的關聯關系,建立線性回歸模型,通過模型擬合與預測,為圖書館智慧管理提供技術與手段的支持.陶相榮[3]以圖書館現刊閱覽室的受眾和期刊種類為研究對象,對所收集的原始資料進行非條件邏輯回歸分析,得出影響期刊受眾的主要因素為高年級、男性、偏遠地區等,為圖書館的征訂工作提供了幫助.武同雁等[4]針對高校圖書館逐步向社會開放的現狀,提出通過分析社會受眾群體特征和閱讀需求來評價開放效果,從而不斷增強圖書館服務社會的能力,為社會受眾提供更加優質的服務,也為其他高校圖書館面向社會開放提供工作思路.鄭云濤等人[5]利用52萬余條有效的紙質圖書借閱記錄,分析受眾借閱圖書的內在需求,對受眾借閱行為信息進行挖掘,從而為更好服務受眾提供決策幫助.
本文通過問卷調查收集受眾的個性特征數據、受眾喜好的文學作品數據及影視作品數據,然后進行整理、分析以及量化,建立基于受眾個性特征的模糊聚類分析模型,把受眾群進行分類,并對每類受眾群的性格進行分析,提煉出每類受眾群主要的性格特點,得到每類受眾群喜歡的文學作品及影視作品.為了能夠通過每位受眾個體喜好的作品了解受眾的個性,本文將聚類分析的結果作為監督學習的標記值,建立受眾閱讀作品喜好程度的多分類SVM模型,由此判別出未知受眾群的性格種類.
1 數據收集及處理
1.1 問卷調查
為了能系統地了解各受眾的性格,除受眾的基本信息外,還從性格的四個緯度(即力量型、完美型、寬容型、自我型4類人格)設計了16個關于受眾個性的問題(即受眾性格的感性、樂觀、主動、倔強程度,謹慎、低調、注重原則、追求完美程度,冷靜、接納他人、懦弱、注重效率程度,同理心、自我、穩定、分裂程度),通過調查問卷,獲取不同年齡階段的142位調查對象的性格特征數據、所喜好的文學作品數據、受眾喜歡的角色數據以及影視作品數據.
1.2 數據收集
通過在微信、QQ發放調查問卷以及線下發放紙質問卷,共收集到142份有效數據.其中男性占54.93%,女性占45.07%,年齡段分布集中在21-30歲,如圖1、圖2所示.
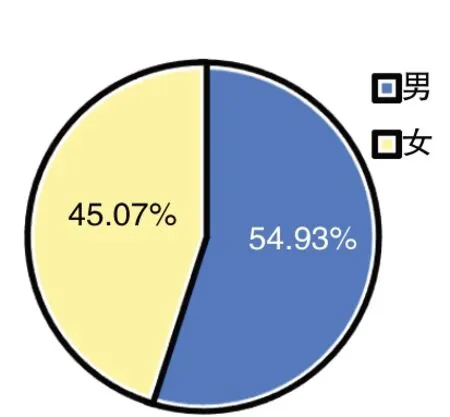
圖1 性別分布
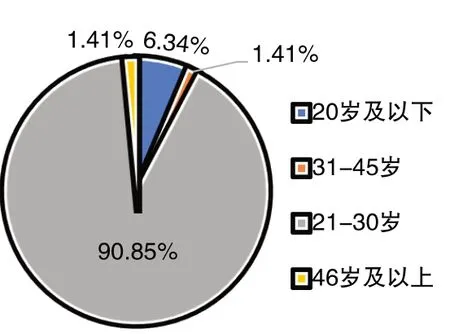
圖2 年齡階段
1.3 數據處理
關于調查對象的性格特征設置的16個問題中,每個問題的答案包含“幾乎不”“稍微”“一般”“非常”四個偏向程度指標選項,并進行量化處理,其量化標準如表1所示.

表1 受眾性格偏向程度定義
記142位受眾分別為X1,X2,...,X142,利用上述量化標準,得到142位受眾性格特征數據,結果如表2所示.

表2 受眾性格偏向程度定義表
2 模糊聚類對受眾群進行聚類
2.1 受眾群的聚類模型
本文主要采用模糊聚類算法[6-8]對受眾進行聚類.為了方便進行數值驗證,在聚類分析過程中只選擇142位調查對象中的前122個受眾數據進行計算,剩余的20個受眾數據則用于驗證算法的準確性.分析調查問卷的收集結果可得,聚類分析的樣本數據為D={X1,X2,...,X122},其中Xi=(xi1,xi2,...,xi16)代表第i個受眾,每一個受眾都是由16個不同的屬性值構成,即:xi1代表第i個受眾性格的感性程度,xi2代表第i個受眾性格的樂觀程度,xi3代表第i個受眾性格的主動程度等,具體屬性見表2.
聚類分析是利用受眾性格特征的相似度對受眾進行的聚類,也就是同一類別下的受眾性格特征相似.假設將142位調查對象中的前122個受眾分為c個簇類,即C1,C2,...,Cc.在模糊聚類中,樣本與簇的關系不再是非此即彼,而是每個樣本按照一個隸屬度屬于某個簇.設Xi屬于簇Cj的隸屬度為αij,其中αij∈[0,1]且

從而得到模糊聚類算法的優化函數為:
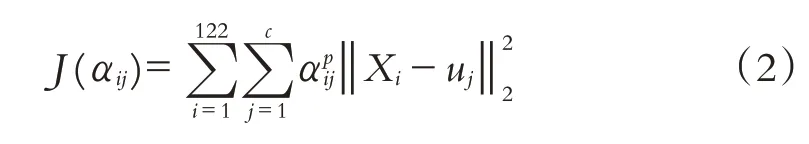
其中uj為簇Cj的聚類中心,p為控制隸屬度的影響參數,通常取2.整理得到優化模型為:
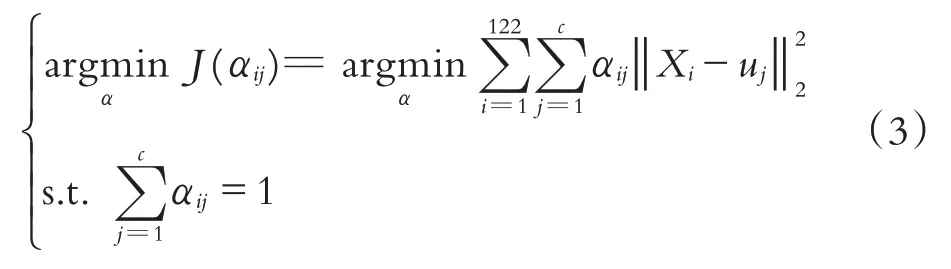
模型(3)是一個帶約束條件的優化模型,可以利用拉格朗日數乘法將約束優化問題轉化為無約束優化問題,即:

從而得到模糊聚類算法的步驟為:


2.2 受眾的聚類結果
在算法1中,設置簇數c為5,參數p為1.5,利用Python編寫程序,得到5個聚類中心為:
第一種聚類中心為:L1=(0.6258,0.7077,0.6193,0.6340,0.6819,0.6777,0.7720,0.6169,0.6336,0.7122,0.4518,0.7460,0.7473,0.3807,0.6939,0.4176),其包含17個個體.通過對樣本屬性的特征分析可知,該類為寬容型,體現在為人寬容大度,對自己和身邊的人都較為友好,接納性強,情感豐富但善于控制,自我認知清晰目標明確,這類人具有主見但不自我,原則性很強,更適于管理他人.
第二種聚類中心為:L2=(0.6206,0.6966,0.6094,0.6363,0.6740,0.6754,0.7593,0.6134,0.6279,0.7083,0.4732,0.7350,0.7364,0.4210,0.6835,0.4539),其包含4個個體.通過對樣本屬性的特征分析可知,該類為善解人意型,體現在為人同理心強,往往善解人意,更在乎他人而非自我,做事注重效率,行動力強但情感力量較為缺乏,此類人群往往需要有一個能被他們所接受的人來督促他們的進步,是需要引領的潛力股.
第三種聚類中心為:L3=(0.6314,0.7044,0.6593,0.6901,0.6901,0.7059,0.7353,0.6755,0.6757,0.7224,0.6399,0.7011,0.7310,0.6425,0.6919,0.6670),其包含51個個體.通過對樣本屬性的特征分析可知,該類為矛盾型,體現在自我認知明確,行事低調性格內斂,性格更為復雜多元,較為矛盾分裂,具有多面性且各方面較為平衡,具有一定程度的雙重性格,往往使人感到神秘.他們是現實生活中最為普遍的性格類型,感性與理性程度持平,較為樂觀勇敢,情緒穩定,無論是其自身還是身邊人往往都能受到此類人群的力量感染,因此能夠擁有較為和諧的社交關系和較強的工作執行力.
第四種聚類中心為:L4=(0.6175,0.6899,0.6033,0.6320,0.6686,0.6717,0.7558,0.6081,0.6258,0.7052,0.4772,0.7303,0.7298,0.4282,0.6794,0.4524),其包含12個個體.通過對樣本屬性的特征分析可知,該類為倔強認真型,體現在倔強認真,同時善于聽取他人意見與建議,關心他人,也關注自己,溫和但有底線,有鋒芒而不外露,思考力相對缺乏,性格溫和,較為被動,自律性相對較低.
第五種聚類中心為:L5=(0.6307,0.7253,0.6365,0.6336,0.6931,0.6846,0.7866,0.6242,0.6413,0.7186,0.4202,0.7585,0.7640,0.3341,0.7078,0.3855),其包含38個個體.通過對樣本屬性的特征分析可知,該類為助人型,體現在更具理性思維,積極樂觀行為低調,主體性不強,與人交往時往往屬于付出方,務實但做事往往更重效率不重結果.
3 多分類支持向量機對受眾性格進行歸類
3.1 受眾喜愛作品類型數據收集
本文收集受眾性格特征的同時也收集了受眾喜歡的作品類型數據,即讓每一受眾從20部書籍、20部影視劇及20個經典角色人物中按喜愛程度選擇前5部文學作品、5部影視劇作品和與5個人物角色.調查共收集了142份有效數據.根據前文對122位受眾進行的聚類分析,作為監督學習的標注值,如表3所示.
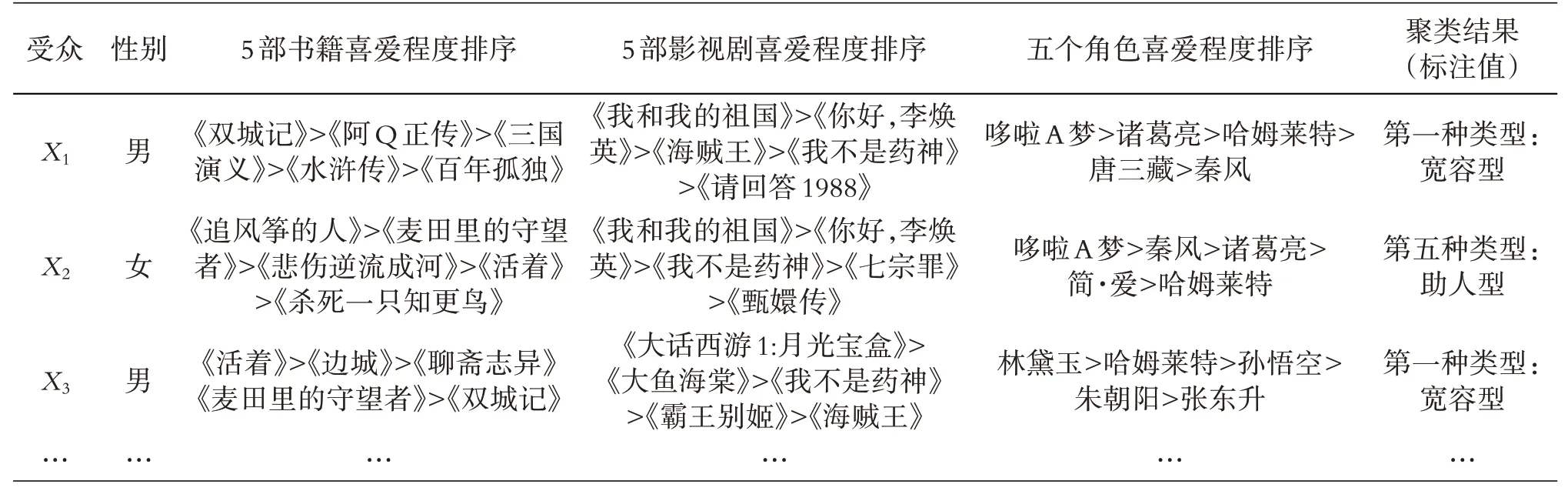
表3 受眾喜歡的作品示例表
本文需要按受眾喜歡的作品與人物類型特征對受眾進行歸類,通過分析受眾所喜愛的作品類型和人物角色提煉出各類受眾的性格特征.假設作品與人物類型的特征屬性向量為Y=(y1,y2,…,y60),其中yi代表受眾喜好某一作品或人物的程度,y1至y20依次表示受眾對《西游記》《活著》《三國演義》《平凡的世界》《聊齋志異》《水滸傳》《阿Q正傳》《簡·愛》《紅樓夢》《邊城》《悲傷逆流成河》《追風箏的人》《百年孤獨》《麥田里的守望者》《紅高粱》《人間失格》《殺死一只知更鳥》《史記》《變形記》《雙城記》這20部文學作品的喜愛程度.y21至y40依次表示受眾對《我不是藥神》《我和我的祖國》《大話西游1:月光寶盒》《你好,李煥英》《大魚海棠》《請回答1988》《甄嬛傳》《星際穿越》《釜山行》《七宗罪》《海賊王》《盜夢空間》《隱秘的角落》《我的前半生》《霸王別姬》《小敏家》《寄生蟲》《死寂》《地球最后的夜晚》《暗殺》這20部影視劇作品的喜愛程度.y41至y60依次表示受眾對孫悟空、哆啦A夢、諸葛亮、阿Q、簡·愛、哈姆萊特、豬八戒、秦風、唐三藏、沙僧、林黛玉、朱朝陽、卡西莫多、格里高爾、王熙鳳、潘金蓮、魯侍萍、張東升、康敏、賈寶玉這20個人物角色的喜愛程度.為了便于對數據進行分析,建立如下的量化標準:

3.2 利用受眾喜歡的作品類型對受眾進行歸類
為了能夠利用受眾喜歡的作品與人物類型對受眾的性格進行歸類,本文采用多分類SVM模型進行分類.SVM[9-11]為一個二分類模型[12],是處理小樣本、非線性問題的有力工具.假設數據集D={(X1,y1),(X2,y2),...,(Xn,yn)},其中yi=-1或者1,SVM就是找到一個超平面把正樣本和負樣本劃分開來[6].超平面的數學表達式[13]可表示為

式中:X為超平面上的向量,w為超平面的法向量,b為超平面的截距.求解優化問題,獲取w及b的值:
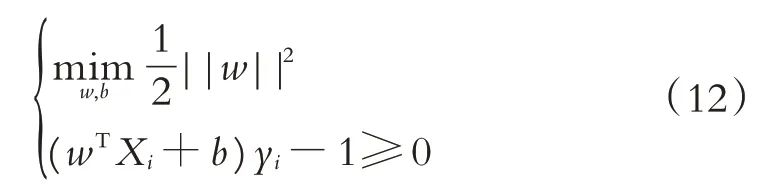
SVM最初是為處理二分類問題而設計的,實際應用中多分類問題更為普遍,所以需要對SVM進行“加工”,讓其在多分類問題中也能發揮出色的性能[14].多分類問題可以通過多個SVM的組合來解決,一般有“直接求解”法和“分類-重組”法.“分解-重組”法主要是通過組合多個二分類器來解決實際問題,常用的有一對多SVM分類、一對一SVM分類、有向無環圖SVM分類等[15].本文采用一對一SVM分類方法.
3.3 基于受眾閱讀喜好的多分類支持向量機結果
利用機器學習庫sklearn中的SVM模塊編程,對訓練集中的122個受眾數據進行訓練,訓練結果與模糊聚類結果如表4所示(表中第二列的Xi代表受眾i)

表4 受眾性格歸類
由表4的結果可知,利用多分類SVM模型可以將受眾的性格類型按他們喜歡的作品與人物類型完全區分開來,即在訓練數據集上的準確率為1.
4 誤差分析
為了驗證本文多分類SVM模型的準確度,選擇在由142位調查對象中的后20位受眾構成的測試集上進行.首先利用2.2節的聚類結果計算出該20份樣本中受眾的性格特征數據到每一個聚類中心的距離,并按距離最短原則進行歸類.對第i個樣本,其計算公式為:
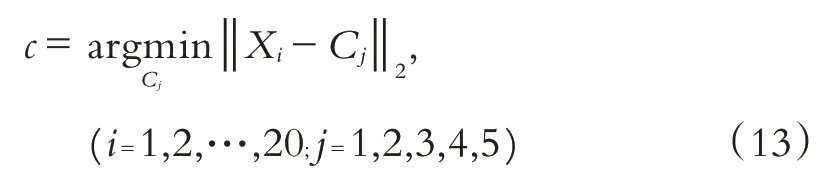
其中:c代表樣本Xi所歸類別,Cj代表聚類中心.然后利用多分類SVM模型按照受眾喜歡的作品與人物類型的數據對每一個測試集上的樣本進行分類.最后,對第i個樣本來說,如果通過受眾喜好的作品與人物類型進行的分類與聚類分析得到的歸類是相同的,則可以看作該受眾根據其喜愛的作品與人物類型來判斷其性格種類是正確的,相反則判斷錯誤,從而計算出模型的準確度,其計算公式為:其中:Nc代表測試集種樣本的個數,Nct代表測試集中判斷正確的個數,Nx代表訓練集中樣本的個數,Nxt代表訓練集中判斷正確的個數.計算得P1=0.6,P2=0.85,因此,本文所提出的個性判斷方法具有較高的準確率,即通過了解受眾的閱讀喜好可以了解到大部分人群的性格特征.
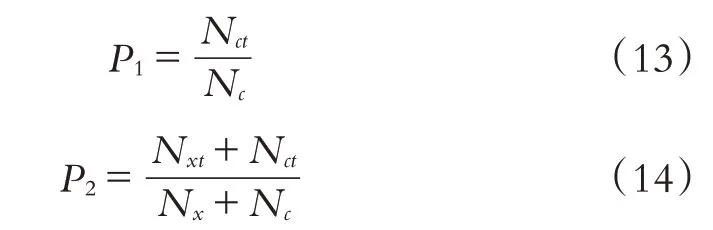
5 總結
本文重點通過受眾的閱讀喜好來了解該受眾的性格特征.首先問卷調查收集受眾的個性特征數據,其中包含了16個受眾的性格特征,如感性、樂觀、主動、倔強等;同時收集了受眾喜歡的文學作品數據、影視作品及人物角色數據.然后建立了關于人物個性特征的模糊聚類模型,從而對受眾進行分類.最后利用模糊聚類的結果,建立了關于受眾閱讀作品喜好程度的多分類SVM模型,利用多分類SVM模型可以判別未知受眾群的性格種類.通過對20名受眾的測試可知,利用受眾喜愛的作品類型來判別其性格種類的準確度為60%,在全體數據集上的準確率達到了85%.由此可知可以通過受眾喜歡的文學作品類型來了解受眾的性格特征.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
傳媒評論(2018年6期)2018-08-29 01:14:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
新聞傳播(2016年11期)2016-07-10 12:04:01
