一種基于深度學習的網絡新聞分類模型
2023-01-07 03:09:06胡豐麟朱立忠通信作者
信息記錄材料 2022年11期
胡豐麟,朱立忠(通信作者)
(沈陽理工大學自動化與電氣工程學院 遼寧 沈陽 110159)
0 引言
隨著互聯網技術的發展,新聞作為信息的重要載體呈現出爆發式的增長,深度神經網絡也正在逐步取代傳統算法和機器學習。與英語和其他語種的文本分類相比,中文文本分類由于漢字的獨特性變得更加困難。最初的文本分類是通過建立專家規則進行分類,但由于在靈活性、可擴展性和分類效果等方面存在許多不足,并未取得過多的關注。支持向量機、K 鄰近、決策樹和最大熵等機器學習算法由于對文本處理的效果較好,成為常見主流算法。當數據量非常大時,這些算法在處理時成本較高。
1 相關研究
近年來,由于深度學習模型能夠捕捉語義詞關系,在性能上優于傳統的機器學習方法,因此在文本分類中使用深度學習模型引起了廣大學者極大的興趣。使用分布式表示方法來表示單詞和短語,不僅可以獲得單詞在語言前后的關系特征,而且避免了數據的高維和稀疏問題。Liu 等[1]提出了一種可以在中文文本中提取上下文信息的模型,這種模型主要是運用LSTM 來對文本的上下文特征提取。在2013年,谷歌公司發布的Word2vec 工具可以將文本進行向量化,從而得到文本的詞向量,挖掘出更加深層的聯系,而且Word2vec 輸出詞向量可以輸入到其他的深度學習網絡模型中進一步處理,極大地提升了文本分類的準確率。由于Word2vec 模塊的完善,人們已經可以利用它對大量文字數據進行訓練,把文字表示成低維稠密的矢量空間,從而降低了大量文字數據存儲的困難度,并考慮到詞語之間的關聯,從而更好地描述了大量文字數據,這將極大地促進深度學習技術在文字分析上的發展和應用[2]。閆秘[3]對fastText 算法進行改進,通過改進特征向量的權重,以及替換數據集中主題詞來提高模型的分類效率。肖琳等[4]都將注意力機制與CNN和RNN的結合應用到了文本分類問題中。陶文靜[5]在新聞文本分類任務的研究中提出了一種改進的卷積神經網絡模型,在多個數據集中取得了不錯的效果。殷亞博等[6]將卷積神經網絡和K 鄰近算法相結合,通過卷積神經網絡對文本特征進行提取,KNN 分類器進行分類。經過測試,該模型在多個數據集都有著較好的分類效果。高云龍等[7]通過在全連接層增加稀疏編碼的方法來降低模型的復雜度。該模型經過反復實驗,具有較好的文本分類效果。胡杰等[8]提出了一種新模型,將卷積神經網絡和隨機森林算法結合,通過卷積神經網絡提出文本特征,隨機森林對文本進行分類。陳可嘉等[9]將卷積神經網絡和長短時記憶網絡相結合,通過將卷積神經網絡進行動態池化來提出更多的文本特征。經過實驗對比,該模型比其他模型擁有更高的精度。
傳統的CNN 網絡不能解決由于文本分類任務中上下文之間存在很強的依賴性和連續性,導致模型精度較低的問題。本文提出了一種卷積神經網絡(CNN)和長短期記憶網絡(LSTM)的混合文本分類模型,通過實驗,該模型與其他傳統的深度學習模型相比具有更高的準確率。
2 基于CNN-LSTM模型的方法
CNN 和LSTM 的混合模型主要是保留了各自的優點,通過Word2vec 預處理所獲得的詞向量輸入在CNN 的卷積層中,把CNN 的輸出視為LSTM 第一層的輸入,在每一層的輸出都做歸一化處理。該模型既解決了CNN 模型只能提取局部特征的問題,又能夠解決上下文的依賴關系,有效地提高了模型的準確率。
2.1 Word2vec 詞向量
由于神經網絡需要輸入的是向量,需要先對新聞文本進行預處理,將新聞文本映射成為向量,Word2vec 就是一個用來生成詞向量的工具。CBOW 和Skip-gram 是Word2vec 的兩個模型,CBOW 通過上下文預測目標詞訓練得到詞向量,并在小型語料庫上使用;Skip-gram 是用一個詞去預測它文本序列周圍的詞,適合在文本預料較多時使用。Skip-gram 模型中每個單詞在做中心詞前,都會經過K 次的檢測和微調,而這樣反復的微調就會導致單詞向量的變化比較精確。由于本文的新聞數據量較大,決定采用skip-gram 模型對文本進行預處理。
Skip-gram 模型,其訓練復雜度為:

式(1)中,C 為Word2vec 模型輸入層的窗口大小,D表示詞向量維度,V 表示訓練語料的詞典大小。
2.2 CNN-LSTM 模型
長短時記憶網絡和卷積神經網絡在處理文本分類任務上都有各自的優勢,CNN 雖然能夠保留文字的全局度量特性,并合理地挖掘文本中所有可能的語義關聯現象,但卻不能處理文本上下文的相互影響現象和上下文語義關聯現象。而由于LSTM 具備了對長期語境信息依賴的特點,可合理使用和記憶更大程度的長期上下文語義關聯,從而有效地分析文本序列的含義。因此根據二者的結構特征,在本文中建立了一個CNN-LSTM 架構,作為對信息的分析。CNN-LSTM 的網絡模型結構如圖1所示。

圖1 CNN-LSTM 網絡模型結構
卷積層:文中利用三層一維卷積,每個輸入層包含一個向量序列,并使用固定大小的濾波器進行掃描,檢測文本的不同特征。在激活函數的選擇上,比較常用的是Sigmoid 函數,但是這個函數的計算量比較大,在訓練深度網絡時容易出現梯度消失的問題,因此決定使用ReLU作為激活函數。這個函數更像一個線性函數,當神經網絡的行為是線性或接近線性時會更容易優化,也是因為此特性,在使用這個激活函數進行訓練的網絡幾乎完全避免了梯度消失的問題,訓練的速度也會比前者更快。
Batch Normalization 層:和Dropout 的作用相似,都是起到了防止模型過擬合的作用,而且相比Dropout,Batch Normalization 的調參過程也相對簡便一些,能夠有效地提高模型的學習率,提高模型的訓練速度和收斂過程,作用在每層卷積層之后。
池化層:在BN 層之后,采用max-pooling。選用最大池化層是為了捕捉最重要的特征并減少高級層中的計算。應用衰減技術來減少過擬合,衰減值為0.5,這樣做能夠保留全局的序列信息。
時序層:該層具有一定數量的單元,每個單元的輸入都是卷積層的輸出。通過LSTM 來解決在長文本中,CNN 無法捕捉上下文中存在的依賴特性關系這一問題。
輸出層:采用Softmax 分類器,使用Softmax 函數對獲得的特征T 進行分類。由于T 是一個向量,因此不可能基于T 直接確定文檔的類別。因此,Softmax 函數用于執行規范化方法,以獲得文檔屬于特定類別。公式如下:
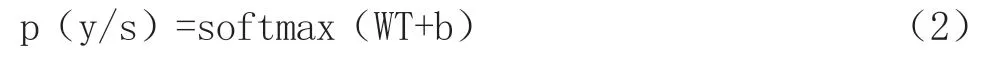
文本預測的標簽公式如下:

該模型中使用的損失函數是交叉熵損失,并引入了L2正則化。公式定義如下:
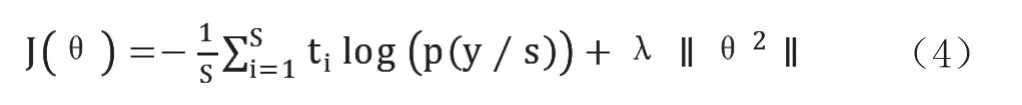
t 是文本真實標簽的概率,p(y/s)是具有Softmax函數的每個類的概率,s 是目標分類數,λ 表示模型的復雜損失占總損失的比例。經過Softmax 函數得到每個類別的概率,完成文本分類的任務得到最終的分類結果。
3 實驗結果分析
本實驗所用的資料集為清華大學自然語言處理研究室提供的中文文本分析資料集。THUCNews 數據集包括了740 000 個新聞文本,十四種新聞類型。文本采用了其中的十種類型,并選取50 000 條新聞數據作為訓練集,10 000 條新聞數據作為測試集。為了滿足深度學習對于數據量的需求,將已經標注好的網絡新聞文本中的詞語通過同義詞替換等方式來擴充數據。使用softsign 和Adam 作為Textcnn 和CNN-LSTM 的激活函數和優化函數,來測試兩種算法使用相同數據集的準確率和損失函數,結果如圖2和圖3所示。
從圖2和圖3得出,CNN-LSTM 模型比Textcnn 模型擁有更加的準確率,且損失函數下降比較平穩,說明了此模型相對其他算法模型具有良好的穩定性。

圖2 Textcnn 的accuracy 和loss 趨勢變化
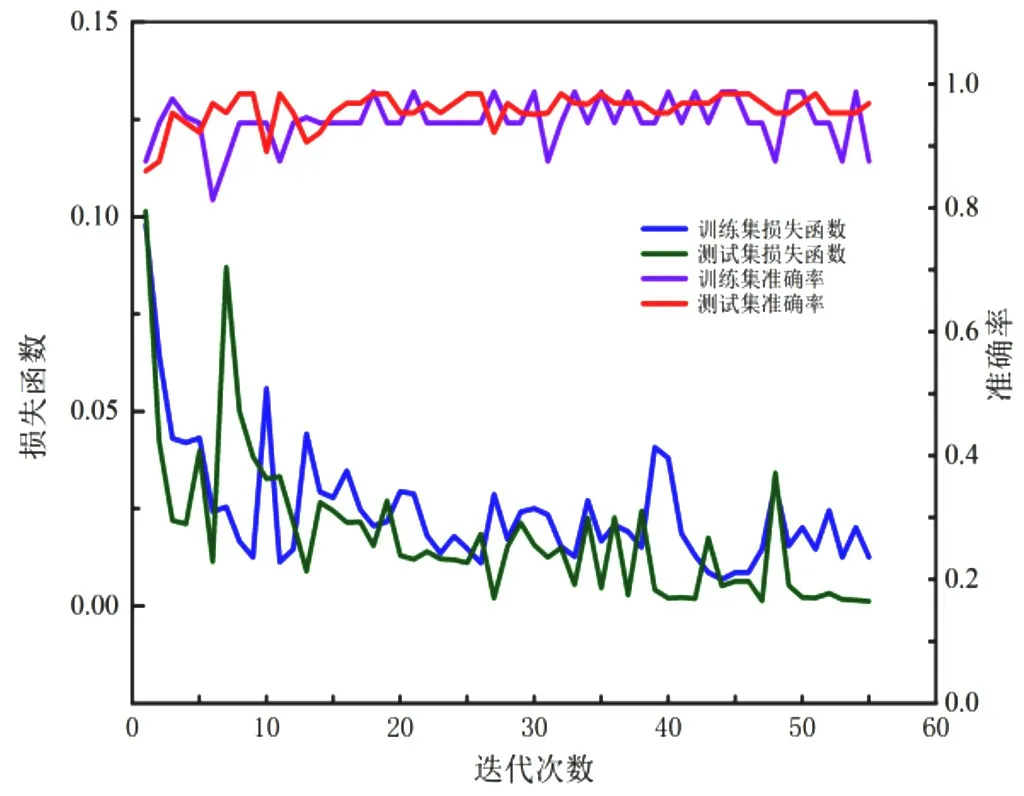
圖3 CNN-LSTM 的accuracy 和loss 趨勢變化
接著將Textcnn、LSTM 和CNN-LSTM 的準確率進行對比,如表1所示。

表1 分類準確率對比
從表1可以看出,三個模型的準確率分別為0.910、0.864 和0.962。其中CNN-LSTM 的準確率達到了0.962,比Textcnn 的準確率高出了0.052,與LSTM 相比準確率更是高出了0.98,說明了CNN-LSTM 模型能夠進行更精確地分析,有著更高的準確率,能夠有效地提高文本分類的效果。
實驗數據表明,這個結構的CNN-LSTM 模型與傳統的深度學習模型相比,具有較高的準確率,訓練效果比傳統的模型有較顯著的提升。該模型在保證每條數據結構不變的情況下,挖掘出更深層的語義結構,更好地表達數據的原始特征,有助于提高文本分類的效果。
4 總結
針對傳統的深度學習模型在文本分類任務上的準確率不高的問題,文中提出了一種將CNN 模型和LSTM 模型的優勢相結合的混合模型,將CNN 的輸出作為LSTM 的輸入,并在原始的卷積神經網絡的基礎上,采用計算速度和收斂速度更快的ReLU 函數作為模型的激活函數,將BN 層加入到卷積神經網絡中來加快網絡的收斂速度。通過實驗比較,在對海量的新聞信息進行分析時,混合模型的準確率達到了96.2%,說明混合模型比傳統的深度學習模型擁有更高的預測精度,具有更好的分類效果,因此能適用于網絡新聞的分類任務。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
