基于深度學習的水面無人艇目標檢測算法綜述
2023-01-10 03:46:56羅逸豪張鈞陶
數字海洋與水下攻防 2022年6期
羅逸豪,孫 創,邵 成,張鈞陶
(1.中國船舶集團有限公司第七一〇研究所,湖北 宜昌 443003;2.清江創新中心,湖北 武漢 430076;3.軍事科學院系統工程研究院,北京 100141)
0 引言
水面無人艇(Unmanned Surface Vehicles,USV)作為一種無人操作的水面艦艇,具有體積小、航速快、機動性強、模塊化等特點,可用于執行危險以及不適于有人船執行的任務[1]。USV可實現自主規劃與航行、環境感知、目標探測、自主避障等功能,在軍事作戰和民用領域中具備極高的應用價值[2]。其中無人艇自主目標檢測算法是支撐任務完成的核心技術[3]。目前國內 USV尚未進行大規模應用,一個重要的原因就是水面目標檢測算法性能不足。如何提高目標檢測的精度和速度,增強應對復雜場景的穩定性,以及擴充識別目標的種類,都是水面目標識別中需要解決的問題。
USV的感知模塊通常可采用以下傳感器采集信息:導航雷達、激光雷達、聲吶、紅外熱成像儀、可見光傳感器。可見光相機作為輕量級、低功耗和信息豐富的傳感器,雖然容易受到光照、天氣等環境影響,但已成為USV水面目標檢測的主流傳感設備[4]。
可見光圖像目標檢測的研究可以追溯到20世紀90年代,早期的傳統目標檢測算法基于人工設計的特征,比如十分經典的SIFT[5]、HOG[6]、Haar[7]特征。然而,它們能夠提取的特征信息往往局限于紋理、輪廓等,只適用于特定任務,并且需要大量的專業經驗和知識進行手工設計[8]。而目前各式各樣的應用環境充滿著許多復雜因素和干擾,傳統方法已經顯得無能為力。2012年,AlexNet[9]采用卷積神經網絡(Convolutional Neural Network,CNN)在 ImageNet[10]大規模圖像分類數據集上取得了突破性的效果,引發了深度學習(Deep Learning)的火熱浪潮。深度學習利用大數據對網絡模型進行訓練,克服了傳統特征的諸多缺點,已成為當下各個應用領域中目標檢測任務的主流算法。
USV水面目標檢測任務是通用目標檢測算法的一個重要應用方向。已有一些綜述文獻[11-14]對傳統或基于深度學習的目標檢測算法研究現狀進行了綜述,但它們僅采用經典的算法類型定義,并未囊括在此類型之外的最新相關工作。另一方面,文獻[15-17]對無人水面艇感知技術發展進行了調研與展望,包含了檢測、跟蹤、定位、導航等多項技術,但未對水面目標檢測進行全面深入的分析。
1 基于深度學習的目標檢測算法
目標檢測算法需要輸出給定圖像中所有物體的類別,還需用緊密的外接矩陣定位每一個目標,即分類+回歸。通俗來講,目標檢測就是解決圖像中所有物體“是什么”以及“在哪里”的問題。在2012年以前,傳統的目標檢測算法采用手工方式提取特征,其框架圖如圖1所示。
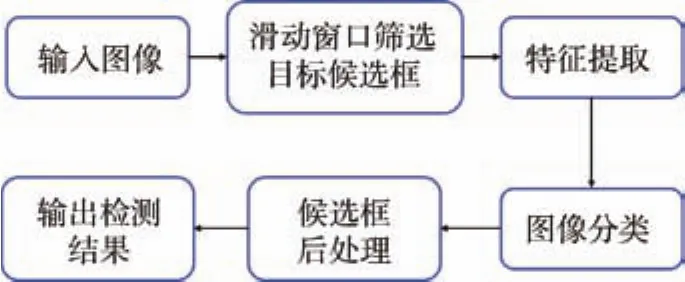
圖1 傳統目標檢測模型框架Fig.1 Framework of traditional object detection model
基于滑動窗口的篩選方法旨在枚舉出輸入圖像中所有可能的目標外接矩形框,最終得到一系列不同大小和尺寸的初始候選框(Anchor,也稱為錨框,樣本參考框)。然后從輸入圖像中截取每一個候選框中的圖像輸入特征提取算法得到圖像特征。得到的特征(比如SIFT、HOG等手工特征)被輸入到分類器(比如SVM[18]等)中以執行圖像分類。最后通過后處理步驟(比如非極大值抑制[19],Non-Maximum Suppression,NMS)根據分類得分篩選出置信度高的候選框以得到最終的檢測結果。
伴隨著 2012 年 AlexNet[9]興起的深度學習研究熱潮,深度神經網絡(Deep Neural Network,DNN)已經成為了計算機視覺領域中提取圖像特征的主流模型。在圖像分類任務中DNN取得了杰出的精度提升,因此人們自然而然地將其引入到目標檢測問題中,將傳統目標檢測框架中的各個組件由DNN進行替換,最終實現“輸入→深度學習模型→結果”的端到端模型,具體框架如圖2所示。
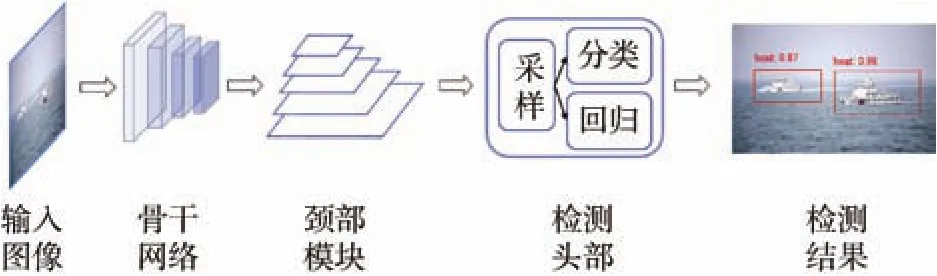
圖2 基于深度神經網絡的目標檢測模型框架Fig.2 Framework of object detection model based on DNN
不同類型的目標檢測算法具有不同的采樣策略。根據是否存在顯式的候選框提取過程,目標檢測模型可以分為兩階段(Two-stage)和一階段(One-stage)檢測方法。兩階段檢測器通過候選框提取方法首先篩選出一批感興趣區域(Region of Interest,ROI),然后再進行識別定位,整體上是一種由粗到精的檢測過程;而一階段檢測器是直接使用固定的錨框進行識別定位,屬于“一步到位”。這也是經典的目標檢測算法分類方法。
另一方面,根據是否需要顯式定義先驗錨框,目標檢測模型還可以分為基于錨框(Anchor-based)和無錨框(Anchor-free)檢測方法。基于錨框的方法需要預先定義一定數量、尺寸、長寬比例的錨框以進行采樣,而無錨框方法則不需要。大部分兩階段目標檢測模型屬于基于錨框的方法,而一階段目標檢測模型則兩者皆有。在2018年左右,無錨框檢測方法逐漸受到研究者的重視。
除此之外,Transformer[20]作為一種最早用于序列建模和機器翻譯任務的基于注意力結構,在最近兩年被廣泛應用于圖像目標檢測領域。它提供了一個新的基于目標查詢的采樣方式,將目標檢測作為一個集合預測問題。
接下來本章對上述類型的目標檢測算法分別進行闡述。
1.1 兩階段目標檢測算法
R-CNN[21]是基于深度學習的兩階段目標檢測器開山之作,在傳統檢測框架上,它采用CNN來提取圖像特征。R-CNN檢測器在第一個階段中采用選擇性搜索算法[22]生成約2 000個ROI。不同于傳統的滑動窗口,選擇性搜索算法可以排除掉一部分背景區域的干擾而盡可能篩選出目標區域。在第二階段中R-CNN將每一個ROI裁剪并縮放至同樣的大小,然后使用CNN提取圖像特征。最后將特征向量輸入到訓練好的SVM分類器和回歸器中得到分類置信度得分和目標邊界框的坐標參數。雖然R-CNN相比傳統檢測算法實現了更高的精度,但是它將每一個ROI分別輸入CNN提取特征,這導致了大量的重復計算,致使算法實時性過低,每張圖像的計算時間接近一分鐘。同時R-CNN中的各個組件是獨立的,無法以端到端的方式進行訓練和推理。
針對R-CNN的推理速度不足,SPPNet[23]直接使用CNN提取整張輸入圖像的特征,然后將特征圖輸入空間金字塔池化層得到固定長度的特征,最后進行分類和回歸。類似地,Fast R-CNN[24]采用ROI池化層處理整張特征圖以提取固定大小特征,然后輸入到由全連接層構造的分類器和回歸器中。雖然它們在一定程度上提升了檢測器的速度,但是由于候選框提取算法的限制依然無法實現端到端檢測。
為了實現快速的端到端目標檢測模型,Faster R-CNN[25]提出了一種新的候選框提取算法——區域推薦網絡(Region Proposal Network,RPN)。RPN由全卷積神經網絡[26]構成,它在輸入的特征圖中每一個坐標點設置不同比例的固定錨框,輸出帶有前景/背景二分類結果的候選框。然后,根據所提取的候選框和映射機制可以從特征圖上提取一系列ROI特征,輸入到分類層和回歸層得到檢測結果。Faster R-CNN能夠以端到端的方式進行訓練和推理,極大地提升了檢測速度和精度,并且擴展性和泛化性強,成為了經典的兩階段目標檢測器范式,被廣泛地應用于學術界和工業界。
后續的兩階段目標檢測研究主要是基于Faster R-CNN的改進工作。R-FCN[27]生成位置敏感度得分圖對每個候選框進行編碼來提取空間感知區域特征,同時用卷積層替換了分類層和回歸層中的全卷積層,實現了更快更準確的檢測。Cascade R-CNN[28]提出了一種多階段的檢測模式,通過級聯的方式結合多個R-CNN結構對回歸結果不斷地優化,實現了更精準的預測框。Dynamic R-CNN[29]采用動態訓練方法來調整訓練過程中的IoU閾值,逐步提高錨框的質量。RL-RPN[30]引入了一個順序區域建議網絡,該網絡與檢測器一起改進搜索策略,優化RPN結構。近幾年越來越多的兩階段目標檢測器被提出,比如CBNet[31]、DetNet[32]等。
1.2 一階段目標檢測算法
兩階段目標檢測器雖然檢測精度較高,但是候選區域生成模塊會帶來更大的計算消耗,降低實際場景應用中的實時性。一階段檢測器沒有用于候選框生成的單獨階段,將圖像上所有位置都視為可能存在目標,以降低檢測精度為代價來提升速度。
OverFeat[33]是第一個采用全卷積神經網絡的一階段目標檢測器,它將目標檢測看作是多區域分類,直接使用CNN來代替滑動窗口。全卷積神經網絡的優勢在于可以接受任意尺寸的圖像輸入,而全連接層的劣勢正是只支持固定尺寸的輸入。盡管OverFeat大大提升了檢測速度,其粗糙的錨框生成策略和非端到端的訓練策略使得它的檢測精度不高。
后來Redmon等人提出了YOLO[34],把輸入圖像在長寬維度上劃分為預設的N×N個網格單元。YOLO將目標檢測視為回歸問題,并規定每一個網格中都存在同一個類別的一個或者多個預測框,由框的中心點來確定目標所屬于的網格。最終每一個網格都會得到C個類別的one-hot編碼概率,B個預測框的坐標信息和其對應的置信度,輸出的特征圖尺寸(長×寬×通道)為 N×N×(5B+C)。YOLO因為其較高的準確率和極快的速度成為了最受歡迎的目標檢測模型之一。然而它也有明顯的缺點:對于小目標和聚集的物體檢測精度不高。這些問題在其后續的版本v2–v4[35-37]中陸續得到了改善。直至2022年,YOLO已經發展到了第七代[38],逐漸與無錨框方法相融合。YOLO系列模型對數據集依賴度不高,運行速度快,是工業界應用最廣泛的一階段目標檢測算法。
為了在保證實時性的同時盡可能地提高檢測精度,SSD[39]有效地借鑒了RPN,YOLO和多尺度檢測的思想,仍然將輸入圖像劃分為固定的網格單元,并設定一系列具有多個長寬比例的錨框以擴充預測框的輸出空間。每一個預設的錨框都會通過回歸器訓練得到預測框的坐標,并且由分類器得到(C+1)個類別的概率(1代表背景類別)。同時,SSD在多張不同尺寸的特征圖上執行目標檢測,以更好地發現大、中、小尺寸的目標。SSD的精度甚至超過了早期的Faster R-CNN,檢測速度比YOLO更快,因此備受推崇。基于 SSD模型的后續研究有 DSOD[40]、RefineDet[41]、MT-DSSD[42]等,它們針對原始方法的跨域預訓練、正負樣本比例失衡、特征表達能力不強等問題進行優化。
考慮到一階段探測器和兩階段探測器的精度之間的差異,普遍的觀點是認為一階段目標檢測器在訓練的過程中存在嚴重的正負樣本不平衡問題,因為未經過篩選的大量錨框只有少量才包含待檢測的目標。針對這一現象,RetinaNet[43]改進了交叉熵損失函數的表達式,提出了新的Focal Loss。它減少了訓練過程中簡單樣本(可以被輕易識別的樣本)對于梯度的貢獻,使得檢測器更加關注容易判錯的困難樣本。同時,RetinaNet引入了特征金字塔網絡[44]來進行多尺度檢測,大幅提高了檢測精度。RetinaNet部署簡單,泛化能力強,收斂速度快且易于訓練,成為了學術界一階段目標檢測器研究的基線。近幾年一階段檢測算法 ATSS[45]、GFL[46]、GFLv2[47]在損失函數上進一步優化,檢測精度已與兩階段方法沒有差距。
1.3 無錨框目標檢測算法
先前介紹的方法多是基于錨框的目標檢測算法,這也是自深度學習目標檢測研究以來的主流方法。然而,基于錨框的檢測算法十分依賴人工預先設置的錨框,需要考慮其數量、尺度、長寬比等因素。當更換數據集之后,預先設置好的錨框參數則需要重新進行設計,這帶來了巨大的工作量,使得檢測器可擴展性不高。人工設置的錨框參數并不能保證最優,可能會導致訓練樣本失衡等問題而引起精度下降。同時,生成大量密集的錨框會使得檢測器訓練和推理的速度降低。因此,近幾年無錨框檢測算法受到了越來越多研究者的關注,成為了目標檢測未來的研究方向之一。
在早期的無錨框方法研究中,UnitBox[48]率先提出了基于交并比(Intersection over Union,IoU)的回歸損失函數。交并比是指在圖像中預測框與真實框的交集和并集的面積比值,這也是評價目標檢測器精度的主要依據。而主流基于錨框的檢測器主要是采用L1損失函數,以預測框與真實框的4個頂點坐標差的絕對值來計算誤差,這與IoU不是等價的。極有可能存在具有相同L1損失值樣本的IoU值差異大。IoU損失函數使得檢測器不需要預先設置的錨框,而以像素點為單位來進行預測,開辟了一個新的回歸損失范式。
無錨框方法的另一條思路是預測目標框的關鍵點。CornerNet[49]采用CNN提取輸入圖像特征之后又續接了2個獨立的分支,上分支負責預測目標框的左上角,下分支則負責預測右下角。上下兩分支生成位置熱圖和嵌入向量,用來判定左上角和右下角是否屬于同一個目標,最終使用偏移量誤差來進行訓練,提升了模型精度。在后續研究中,CenterNet[50]又引入了物體中心點預測來提高檢測精度,ExtremeNet[51]則是采用最頂部、最左側、最底部、最右側4個極值點進行預測。
之后,FCOS[52]在結合了Focal Loss和IoU Loss的基礎上,又提出了Center-ness Loss。它將落入真實框內的坐標點視作正樣本,以坐標點到真實框四條邊的距離進行回歸,有助于抑制低質量邊界框的產生,大幅提高檢測器的整體性能。Center-ness Loss還保證了不同尺度的目標都具有足夠數量的正樣本,在一定程度上解決了正負樣本不平衡問題,成為了代表性的無錨框檢測算法配置。FSAF[53]和Foveabox[54]同樣也是采取與FCOS類似的思路:在RetinaNet檢測器上添加無錨檢測分支以優化預測框。最近ObjectBox[55]不僅泛化性良好,而且超越了以往絕大多數方法的檢測精度。
1.4 Transformer目標檢測算法
Transformer模型最早出現在自然語言處理領域,最近兩年許多研究者將其應用于計算機視覺,在檢測、分割、跟蹤等任務中均取得了優異的性能。
DETR[56]是端到端 Transformer檢測器的開山之作,它消除了手工設計的錨框和NMS后處理,并通過引入目標查詢和集合預測直接檢測所有對象,開辟了新的檢測算法框架。具體地,DETR使用編碼器-解碼器作為頸部模塊,使用前饋網絡(Feed Forward Networks,FFN)作為檢測頭部。輸入由CNN主干提取,展平成一維序列,附加位置編碼,然后輸入到編碼器。設計基于目標查詢的可學習位置編碼附加到輸入,然后并行地傳輸給解碼器。訓練過程中,在預測框和真實框之間應用二分匹配損失匹配,以識別一對一標簽分配。DETR實現了具有競爭力的檢測精度,但在小型目標上存在收斂速度慢和性能差的問題。
為了解決此問題,可變形DETR[57]提出了可學習的稀疏注意力機制,用于加速收斂,并引入了多尺度檢測結構,提升了小目標進車精度并將訓練次數減少了10倍。ACT[58]消除編碼器的冗余查詢,提出了一種自適應聚類轉換器,基于多輪精確歐幾里德局部敏感度哈希方法,ACT可以動態地將查詢聚類到不同的原型中,然后通過將每個原型廣播到相應的查詢中,使用這些原型來近似查詢關鍵注意力熱圖。與DETR相比,ACT降低15 GFLOPs的運算量,僅損失0.7%的平均精度。
DETR還可以引入空間先驗知識,與基于錨框的方法相結合。為了增強目標查詢和邊界框與經驗空間先驗的關系,SMCA[59]提出了一種基于空間交叉注意力機制的一階段檢測方法。其訓練次數比DETR少5倍。Meng等人提出了條件空間嵌入[60]方法,以空間先驗明確表示目標的極端區域,從而縮小了定位不同區域的空間范圍,使DETR收斂速度加快了8倍。Yao等人觀察到不同的初始化點總是傾向于類似地分布,提出了一種兩階段高校DETR[61],包括密集建議生成和稀疏集預測部分,將DETR訓練次數減少14倍。
Transformer結構還可以應用于目標檢測模型的骨干網絡和頸部模塊,適用于兩階段、一階段、無錨框等框架中。PVT[62-63]將 Transformer構造為一個從高到低分辨率的過程,以學習多尺度特征。基于局部增強的結構將骨干網絡構造為局部到全局的組合,以有效地提取短距離和長距離視覺相關性,并避免二次計算開銷,如Swin Transformer[64]、ViL[65]和 Focal Transformer[66]。與特征金字塔網絡[44]類似,ZHANG等人通過結合非局部特征和多尺度特征,提出了FPT[67]用于密集預測任務。在模型網絡構造過程中,Swin Transformer作為通用的視覺骨干網絡,可以廣泛應用于圖像分類、目標檢測和語義分割等任務,突破了 Transformer檢測器的應用局限性。
然而,基于Transformer的目標檢測算法通常只能在大規模數據集上實現較大的性能提升,無法在訓練數據不足的情況下進行良好的推廣[68]。可以采用遷移學習[69]的方法,從足夠的數據集中預先訓練,然后在小型和特定的下游任務中進行微調。
2 無人艇水面目標檢測技術
與傳統目標檢測算法類似,一些早期的研究工作利用人工設計的特征對水面目標檢測進行了研究。許多方法將海上物體的檢測視為顯著性估計問題[70-73]。這些方法假設目標與其所處的直接背景有很好的區別。然而,此假設在很多情況下都不成立,比如在起霧和強光的環境下,以及需要檢測視覺上接近于水的物體。經典的背景建模法和幀間差分法也不適合USV,因為起伏的海面導致USV的持續晃動,違反了靜態相機假設,導致誤報率很高[74]。RAJAN 等人[75]對基于傳統視覺的水面目標物體檢測和跟蹤做了更為全面的綜述,本文不再進行贅述。
因為現實水面環境復雜多變,USV拍攝的可見光圖像的圖像質量有所欠缺,包括天氣起霧、運動模糊、光照變化等;另外,同一類別的水面目標物也可能在尺度、形狀、紋理、大小等方面具有較大差異性。這增加了不同環境下的水面目標檢測難度,在一定程度上限制了傳統目標檢測算法的應用范圍。而深度學習目標檢測算法迅速發展,已成為目前水面目標檢測的主流技術。本章將從3個方面總結基于深度學習的水面目標檢測技術進展。
2.1 兩階段與一階段檢測方法
基于深度學習的目標檢測算法在2018年之前大多數分為兩階段或一階段檢測方法,因其技術成熟且易于實現,被廣泛應用于各個領域。而在無人艇水面目標檢測領域,應用深度學習技術起步較晚。
2017年 KUMAR 等人[76]提出了一種改進的VGG16[77]骨干網絡用于海面物體的視覺目標檢測。該工作發現由于訓練數據的缺乏,CNN規模過大可能會造成過擬合現象。為了解決此問題,LEE等人[78]采用了預訓練的方式,將通用目標數據集上訓練好的模型進行微調,以適用于海事目標。
在之后的研究工作中,經典的兩階段檢測模型Faster R-CNN被頻繁采用。FU 等人[79]使用了一種改進的 Faster R-CNN 方法用于海上目標檢測,使用層數更深、功能更強大的 ResNet[80]骨干網絡提取特征,并利用深度歸一化層、在線難樣本挖掘對模型進行優化。CHEN等人[81]將多尺度策略融合到了 ResNet的多層卷積中,并在特征圖上添加了雙線性插值進行上采樣,以增強小目標檢測的效果。Yang等人[82]提出了一個基于 CNN的水面目標檢測和跟蹤定位系統,以Faster R-CNN模型檢測目標位置,然后使用KFC算法[83]在視頻序列中連續跟蹤該目標。在后續研究中,MA等人[84]采用了混合骨干網絡架構,通過DenseNet[85]與ResNet結合的策略,再結合雙向特征金字塔網絡,進一步增強了兩階段檢測模型的精度。
基于兩階段的檢測方法傾向于算法精度,但計算復雜度相對更大;相反,一階段的目標檢測識別算法在訓練和推理過程占用內存更低,模型計算更快。在不追求更高的檢測精度時,一階段檢測方法更受偏愛。陳欣佳等人[86]使用SSD模型執行快速的無人艇目標檢測任務,并借助相關濾波(Correlation Filter)方法進行快速跟蹤。YANG 等人[87]使用YOLOv3模型實現了實時的水面無人艇檢測,然后通過卡爾曼濾波器將外觀特征與運動狀態估計相結合,實現了一種基于數據關聯的多目標跟蹤方法。無獨有偶,王飛等人[88]也基于 YOLOv3開發了海霧氣象條件下海上船只實時檢測的深度學習算法。王孟月[89]借助DenseNet改進YOLOv3的骨干網絡,以增強特征傳播效率、促進有效特征重用以及提高網絡性能。
2.2 基于語義分割的檢測方法

圖3 基于語義分割的檢測示意圖Fig.3 Schematic diagram of detection based on semantic segmentation
由于基于深度學習的語義分割網絡模型在城市與道路場景中取得了良好的效果,一些工作[90-91]將CNN分割框架用于海上圖像分割。為了改進早期方法在小障礙物上分割表現不佳以及鏡像混淆的問題,KIM 等人[92]將跳躍連接和白化層應用于E-Net[93]以改進小目標檢測,雖然精度和效率高于同期其他的分割方法,但每秒10幀的計算速度依然無法達到實時的檢測效果。
在后續的研究中,STECCANELLA等人[94]提出用深度卷積替換 U-Net[95]中的傳統卷積層以改進水線分割效果。在生成了水和非水區域的二進制掩碼后,繼續檢測水中區域的障礙物。為了進一步解決小目標檢測精度低和水反射誤報率高的問題,BOVCON等人[96]提出了一種新的深度非對稱編碼器–解碼器架構,設計了注意力機制和新的損失函數,并通過視覺和慣性信息融合提高了整體分割精度。但是基于分割的方法始終難以達到實時檢測的效果。
2.3 海事視覺感知數據集
早期有一些數據集用來評估海上監視和機器人導航的各種算法。FEFILATYEV等人[97]提出了一個數據集,該數據集包含在同一天記錄的10個序列,在同一片公海采集。然而它僅用于地平線檢測評估,不包含障礙物,限制了它們的視覺多樣性。BLOISI等人[98]采集了10種海上目標跟蹤序列。通過在一天中的不同時間進行記錄,增加視覺多樣性,并對船舶、船只和噴氣式飛機等動態障礙物進行注釋。然而,由于所有障礙物在非常明亮的水面上都是黑暗的,它們對目標檢測幾乎沒有挑戰性。MARQUES等人[99]和 RIBEIRO 等人[100]記錄了 2個視覺上不同的海上機載探測數據集。該數據集是為無人機應用而設計的,它不具有在自主船上觀察到的有利位置。
為了使數據集信息更加豐富,PATINO等人[101]提出了一個包含14個多傳感器序列的數據集,用于障礙物檢測、跟蹤和威脅識別評估。數據集包含地平線和動態障礙物的注釋,但不包含小型障礙物,如浮標。KRISTAN等人[102]構建了一個海上障礙物檢測數據集,其中包含從USV捕獲的12個不同序列,后來 BOVCON等人[103]將其擴展為與慣性測量單元同步的 28個立體攝像機序列。2個數據集都記錄在同一個場景,并包含地平線、水邊和大小動態障礙物的注釋,通過在不同天氣條件下進行記錄,保持視覺多樣性。
由于深度學習模型需要數據驅動,小型數據集會使得深度學習模型出現過擬合的問題。因此,PRASAD等人[104]提出了一個大型海上監視數據集,包含51個RGB和30個紅外光譜序列,在一天的不同時間和不同天氣條件下記錄。大多數序列是從固定的岸上觀測點記錄的,而有些是從比機器人船更高的有利位置拍攝的。由于它主要是為監視而設計的,所以場景非常靜態,幾乎沒有運動。為了使動態障礙物和地平線被很好地注釋,最近MOOSBAUER等人[105]提供了通過基于顏色的半自動方法計算的粗略實例分割標簽。GUNDOGDU等人[106]提出了一個具有400 000補丁的數據集,用于輪船分類任務,但該數據集不能用于檢測器評估,因為輪船位置沒有注釋。SOLOVIEV等人[107]最近構建了具有接近2 000張圖像的數據集,用于評估預訓練的船舶探測器,因此不標注靜態障礙物(如海岸)和動態障礙物(例如邊界)。
大多數數據集被提出用于評估目標檢測算法,只有少數數據集被設計用于訓練分割方法。STECCANELLA等人[108]提出了一個由 191幅圖像組成的逐像素注釋數據集,這些圖像在 7種海域中分別單獨記錄,用于訓練和測試分割方法。數據集包含水域和非水域 2個語義標簽,并且測試集與訓練集沒有很好地分離,視覺多樣性有限。BOVCON 等人[109]提出了目前用于海面圖像分割的最大和最詳細的數據集。數據集是在不同時間和不同天氣條件下記錄的,歷時2年,包含接近1 300張圖像,每個像素點標記水、天空或者障礙物。
5.2 推廣秸稈氣化技術,有利于秸稈資源的綜合利用,實現農業可持續發展。農民每年直接燃燒秸稈占全部秸稈總量的64%,大量的秸稈直接燃燒,不僅造成資源的嚴重浪費,也導致秸稈養畜、秸稈然掃后,還產生大量的co2氣體和煙塵,造成空氣污染,而秸稈氣化技術可以有效解決這些問題。同時秸稈燃氣比傳統的直接燃燒熱效率提高近一倍,可明顯減小秸稈和森林資源的消耗,對退耕還林、天然林保護工程、控制水土流失,起到積極地促進作用。
由于在海洋試驗現場采集數據成本高昂,許多數據集包含的圖像數量較少。在 2022年,RAZA等人[110]使用 3D仿真平臺 AILiveSim構建了一個艦船檢測仿真數據集,包含 9471張高分辨率(1920×1080)圖像,具有船舶、巖石、浮標等動態和靜態目標,并使用 YOLOv5測試了模擬數據的可行性。最近,BOVCON 等人[111]構建了目前規模最大、最具挑戰性的水面目標檢測數據集MODS,包含了超過 8萬張圖像,記錄了高度多樣化的目標,并且設計了相應的評估方法、訓練集和測試集,形成了一項新基準。這項研究工作在開源網站上進行了公開發布,系統地評估了19項兩階段、一階段、基于語義分割的目標檢測算法在該基準上的性能并進行排名,使得不同方法的跨論文比較更易實現。該工作使水面無人艇目標檢測領域取得了關鍵進展。
3 水面目標檢測關鍵問題及展望
雖然有許多研究工作將深度學習方法應用于水面目標檢測任務中,但仍有一些缺陷和關鍵問題亟需解決。本章對關鍵問題進行歸納總結,并對可行的方案以及未來發展做了進一步的展望。
3.1 關鍵問題
1)缺乏大規模數據集和統一的評價標準。
在通用目標檢測研究中,PASCAL VOC[112]數據集是 2015年以前評價檢測算法的金標準,MS COCO[113]數據集則是2015年以后的金標準,他們分別具有約2萬和16萬張圖像。由于其涵蓋類別多、場景復雜性高,被研究者們廣泛采用,不同算法工作可以輕易地進行性能橫向對比。
然而目前的許多海事數據集不能充分捕捉真實世界 USV 場景的復雜性,并且沒有標準化評估方法,這使得不同方法的跨論文比較變得困難,阻礙了相關研究的進展。
2)深度學習方法陳舊。
人臉識別[114]和行人檢測[115]也作為通用目標檢測算法的2個應用子問題,分別衍生出了各自的特異性問題和新穎的算法,在現實應用場景中取得了良好的效果。而由前文內容可知,USV水面目標檢測算法的應用相較于通用目標檢測算法研究滯后 2年左右,并且所使用的方法通常為 Faster R-CNN和YOLOv3等經典模型,未引入新的模型和針對于水面情況的算法,性能有待進一步提高。
3)現實場景圖像質量不佳。
無人艇面臨著不斷變化的外部環境和突發因素的影響,例如起霧、雨水、強光、海浪等因素的干擾,復雜的背景以及快速變化的視角,或是攝像設備的突然失焦。這均會使得采集的圖像質量不佳,極有可能導致算法誤判,在應用場景中產生嚴重后果。盡管深度學習算法比傳統算法的精度和魯棒性更強,在直接處理受損圖像時依然不能達到令人滿意的效果。
4)可見光相機信息單一。
單一的傳感器不能全面地反映復雜海況,單目可見光相機僅能獲取彩色圖像,無法獲取距離、溫度等信息。無人艇系統由各體系模塊化組成,可以搭載不同的傳感器進行感知探測。因此需要利用雷達、聲吶、紅外等多種傳感器信息進行協同、融合分析,提升系統的整體性能。
5)無法應對特定目標檢測任務。
目前水面無人艇目標檢測數據集涵蓋的目標類別通常為船舶、人、浮標、巖石等常見水面目標。然而,當某些具體的應用場景需要檢測數據集中未涵蓋的特定目標,現有的USV水面目標檢測算法難以滿足需求。比如,需要檢測海域中的冰山,搜尋水域和岸邊的瀕危兩棲動物,在海域作戰中檢測信號彈、導彈、飛機等空中目標。
3.2 展望
1)大規模數據集下的Transformer模型。
由于歸納偏差通常表示為關于數據分布或解空間的一組假設,在CNN中表現為局部性和平移不變性。局部性關注空間上緊密的元素,并將它們與遠端元素隔離,變換不變性表明在輸入的不同位置重復使用相同的匹配規則。因此CNN在處理圖像數據中更關注于局部信息,卻限制了數據集規模的上限。Transformer可以關注圖像全局信息,在大規模數據集上表現出了更優越的性能。深層Transformer骨干網絡和編碼器–解碼器結構可有效降低計算復雜度,避免深層特征過度平滑。
最新提出的 MODS大規模水面目標檢測數據集包含8萬張圖像和超過6萬個目標標注,有望成為評價水面目標檢測算法的金標準。因此,在大規模數據驅動下,可以引入 Transformer進行模型設計,進一步提升水面目標檢測算法的精度和泛化性。
2)新算法與模型的應用。
近幾年目標檢測算法在多個層面迅速發展。在骨干網絡方面,ResNext[116]和Res2Net[117]已經成為了常用的模型,可以提取表達能力更強的圖像特征,并且可變形卷積[118]也被廣泛使用。在頸部模塊方面,AugFPN[119]和 RCNet[120]聯合設計了上下文和注意力模塊大幅豐富了多尺度特征信息。在檢測頭部方面,DOOD[121]和TOOD[122]分別采用了解耦和聯合的策略,進一步提高分類和定位的精度。除此之外還有許多訓練策略[123-124]改善了正負樣本不平衡問題。對于USV水面目標檢測任務中環境復雜、小目標漏檢、背景區域大等問題,需要借鑒通用目標檢測算法,針對性的選擇和設計解決方案。
3)基于圖像重建與目標檢測的多任務模型。
為解決圖像質量不佳的問題,最直觀的方法是引入圖像重建算法對采集的圖像進行預處理。CHEN等人[125]采用偏振成像技術對強反光區域進行抑制,QIAN 等[126]結合生成對抗網絡和注意力機制對雨天采集的圖像進行去雨處理。然而他們僅針對單一的圖像受損因素進行預處理操作,適用范圍較小。設計多任務模型[127]進一步提升算法性能十分有必要。
深度學習領域中的多任務學習是指讓一個神經網絡同時學習多項任務,目的是讓每個任務之間能夠互相幫助。這有利于提高模型實時性和減少算力消耗。其主要實現方式為參數共享,多個任務之間共用網絡模型的部分參數,共同進行端到端訓練,產生隱式訓練數據增加的效果,增強模型的能力并降低過擬合的風險。多任務模型比獨立地訓練單個任務能實現更好的效果。
因此,圖像重建和目標檢測任務可以作為子任務統一至端到端模型,在大規模數據驅動下進行多任務聯合學習,提高檢測器在惡劣天氣條件下的性能。
4)多模態融合算法。
多模態學習即是從多個模態表達或感知事物[128],比如通過2種不同成像原理的相機拍攝的圖像,通過圖像、音頻、字母理解視頻。多模態學習通常具有2種方式:協作和融合。
在水面目標檢測任務中,基于協作的方法可以對相機、雷達、聲吶、紅外等多種數據的算法輸出結果執行進一步分析,采用加權等方式得到最終的檢測結果。基于融合的方法可以將多種傳感器采集的圖像進行融合,進一步探究多模態數據深層特征之間的關系,提高數據的利用率,構建魯棒的算法系統。例如,MA等人[129]提出了Fusion GAN 模型,采用生成對抗網絡實現紅外與可見光圖像融合。同時,隨著3D目標檢測[130]研究的興起,可以將彩色圖像與雷達點云數據進行配準融合[131-132]作為深度神經網絡的輸入。為提高USV感知環境的整體能力,多模態融合算法必將成為重要的發展趨勢。
5)小樣本、弱監督訓練算法。
在特定目標檢測任務中存在樣本數量少、標注缺失、類別不明確、標注錯誤等問題。可以借助深度學習小樣本學習[133]和弱監督訓練[134]的方法,針對特定的水面檢測任務充分利用已有的少量圖像數據,解決深度學習模型欠擬合和過擬合的問題,提高目標檢測算法精度。
4 結束語
水面無人艇在軍事作戰和民用領域中具備極高的應用價值,目標檢測算法是支撐任務完成的核心技術。本文首先回顧了當前基于深度學習的目標檢測算法的發展現狀,從兩階段、一階段、無錨框、Transformer 4個類別進行了全面的總結;然后從兩階段/一階段方法、基于語義分割的方法、海事視覺感知數據集 3個方面歸納無人艇水面目標檢測技術的研究現狀;最后闡述了水面目標檢測任務面臨的4個關鍵問題:缺乏大規模數據集和統一的評價標準、深度學習方法陳舊、現實場景圖像質量不佳、可見光相機信息單一、無法應對特定目標檢測任務,并對多任務、多模態、弱監督等新技術進行了可行性分析和展望。未來,高度智能化的水面無人艇將會成為海事任務的重要力量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
