基于改進MFCC和3D-CNN的變壓器鐵心松動故障聲紋識別模型
2023-01-11 01:09:20崔佳嘉馬宏忠
電機與控制學報 2022年12期
崔佳嘉,馬宏忠
(河海大學 能源與電氣學院,江蘇 南京 211100)
0 引 言
電力變壓器在運輸、使用過程中出現的碰撞、擠壓和外部短路故障等將導致鐵心松動變形,繼而造成嚴重的事故。因此對變壓器鐵心狀態進行監測,對電網的安全運行具有重要意義。
目前監測變壓器鐵心松動的方法主要是振動信號監測法[1-2]。根據已有的研究證明,存在缺陷的變壓器運行時,振動信號含有更多的高頻分量[4],高頻分量的峰度值能夠反映變壓器鐵心的壓緊程度[5]。基于振動信號的故障診斷方法已經取得了較為成熟的研究成果,但是振動傳感器的安裝通常是附著于變壓器的器身,振動信號的識別方法更依賴于傳感器的安裝位置及靈敏度。考慮到配電變壓器具有分布廣、數量多的特點,普遍采用巡檢的方式進行故障診斷,在巡檢過程中難以獲取振動信號,因此基于振動信號的故障診斷方法不適用于配電變壓器。
雖然使用振動信號對變壓器進行故障診斷存在上述缺點,但是變壓器的聲紋信號和振動信號具有相關性,因此可以利用聲信號代替振動信號對其進行監測和診斷[6]。聲紋信號的采集具有傳感器非接觸,測量便捷的優點,更適合于人工巡檢。劉云鵬等[1]提出了基于Mel時頻譜—卷積神經網絡的變壓器鐵心松動聲紋識別方法,能夠較好地識別故障;耿琪深等人[6]提出一種基于Gammatone濾波器倒譜系數和鯨魚算法優化隨機森林的變壓器故障診斷方法,能有效地識別鐵心及繞組的松動故障;華北電力大學張重遠等[7]采用盲源分離的方法針對局部放電故障進行了研究,使用2D-CNN對數據進行了深度學習,但未證明是否可用于鐵心松動的故障診斷。上海交通大學王豐華團隊[8]采用加權降維的MFCC與傳統的機器學習VQ相結合,對鐵心壓緊程度進行了診斷;已有研究存在的不足是:特征提取采用提取梅爾頻率倒譜系數(MFCC)或者線性倒譜系數(LPCC),特征向量有過高的維數,導致計算機運行的速度大大下降;目前對語音信號進行識別使用的識別模型是卷積神經網絡,主要采用的是一維或二維卷積神經網絡(2D-CNN),2D-CNN雖然可以同時提取時域和頻域的信息,但是識別準確率仍有上升的空間。三維卷積神經網絡(3D-CNN)目前已被有效地應用于動作的識別,不同于2D-CNN,其還能提取出反映時間變化上的信息。
針對上述問題,本文采用經LLE降維的MFCC作為聲紋信號的特征量,降維后的數據維度大大縮減,以降低計算的復雜度,提高計算速度;并首次使用3D-CNN識別模型對變壓器鐵心不同松動程度進行診斷,進一步提高故障識別的準確率。
1 噪聲信號特征提取
1.1 梅爾倒譜系數
1.1.1 噪聲信號預處理
噪聲信號x(t)的預處理包括分幀、加窗和離散傅里葉變換。截取一段變壓器在某工況下的噪聲信號,首先對截取的片段作分幀處理,幀長選擇太長會影響特征量的準確性,幀長選擇太短會提取不到有用的特征量。取每幀N=2 500為50 ms(采樣頻率為50 kHz),為了使幀與幀之間能平滑過渡,取重疊率為50%。其次,若是直接對分幀后的數據進行離散傅里葉變換,會出現頻譜泄露的情況,因此需要對每一幀先作加窗處理,選擇加漢明窗ω(n),使信號兩端變得平滑減少信號的失真,即
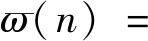
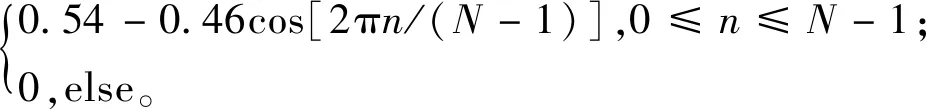
(1)
最后,根據下式再對分幀加窗后的每一幀數據作離散傅里葉變換得到能反應時頻關系的復向量Y(k),為
(2)
1.1.2 MFCC特征向量提取
在語音識別技術中,梅爾倒譜系數(MFCC)是最常見的一種語音信號特征提取方法[8]。它是基于Mel頻率域的倒譜系數,是根據人耳聽覺感知特征變換的頻率域,將線性頻譜映射到Mel頻率域中,再轉換到倒譜上。求取MFCC特征向量的步驟包括對預處理后的各幀信號Mel濾波、對數變換及逆變換(離散余弦變換)。
Mel頻率和實際頻率的轉換公式為
(3)
式中:p為實際頻率,Hz;fmel(p)為Mel頻率。
Mel濾波器是一個由m個三角形濾波器組成的濾波器組。其中心頻率為f(m),在Mel頻率刻度上,濾波器之間的距離是等寬的。該濾波器組的傳遞函數為
(4)
其中,f(m)定義為
(5)
式中:fh與fl為濾波器濾波頻率的上限與下限;fs為變壓器聲紋采樣的采樣頻率(fs=50 kHz);N為進行短時傅里葉變化時的幀長。
信號經過濾波器后可得到m個參數Mi(i=1,2,…,m)并取對數,計算公式為
(6)
將計算得到的Mi進行離散余弦變換,即可得到分幀信號的MFCC特征信號,其計算公式為
(7)
梅爾倒譜系數(MFCC),它的物理含義是語言信號的能量在不同頻率范圍的分布。特征量具體提取步驟是:
1)對聲紋信號分幀加窗。本文是將一段2 s的信號首先截取成4段,分別對每段(0.5 s)進行分幀加窗。取每幀N=2 500為50 ms(采樣頻率為50 kHz),重疊率為50%,并使用漢明窗處理使信號兩端變得平滑減少信號的失真,此時每段(0.5 s)可以得到加窗后的二維數組[19×2 500];
2)傅里葉變換。對步驟1)的每一幀作N=4 096的傅里葉變換,得到頻率特征的二維矩陣[19×2 049],并計算每一幀的能量得到能量譜E[19×2 049],將每幀的能量相加得到該幀的能量和有F[19×1];
3)計算能量特征參數的和能量總值。將步驟2)得到的能量譜E通過梅爾濾波器組,計算能量特征參數的和能量總值二維矩陣[19×26];
4)計算MFCC特征向量的基礎參數(第一組參數)。對每一行作離散傅里葉變化,由于變壓器本體噪聲的頻率集中在低頻區,因此只取每幀的前13個數據,即二維數組[19×13],對該數組作升倒譜操作,得到MFCC參數的基礎參數也是第一組參數記作feat[19×13];
5)計算MFCC特征向量的第二、三組參數。第二組參數是在已有的基礎參數(feat[19×13])下作一階微分操作得二維數組feat′[19×13],第三組參數在第二組參數下作一階微分操作得二維數組feat″[19×13],即對基礎參數導數的導數;
6)MFCC特征向量。將feat、feat′及feat″三個二維數組拼湊得到MFCC最終的特征向量數組[19×39]。
1.2 改進的MFCC特征向量
使用上述方法提取的MFCC特征向量在高維度的情況下,能有效地提取到噪聲信號中的信息,但是過高維度的數據會耗費大量的時間,并且增加計算的復雜性,因此考慮使用局部線性嵌入(locally linear embedding,LLE)算法對提取到的高維度的MFCC特征向量進行降維,且保證能保留變壓器噪聲信號的有效信息。
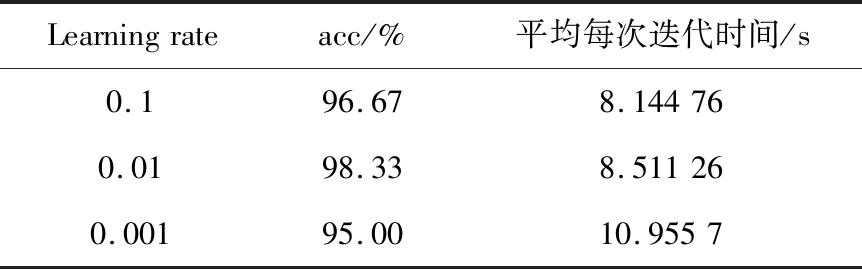
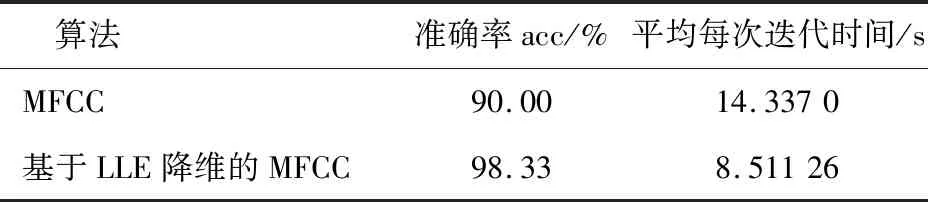
LLE算法的主要思想是高維的數據樣本點可以利用局部領域的點進行線性表示,并保持局部領域權值不變,且在低維空間中利用修改權值重新構造原來的數據點,并使得重構誤差達到最小[9]。對于數據X={x1,x2,…,xN}∈RD×N是高維歐式空間RD的數據集,通過LLE降維算法可將高維數據(D維)X降維到低維數據(d維)Y={y1,y2,…,yN}∈Rd×N,d 1)尋找數據樣本點xi(i=1,2,…,N)的k(k (8) 2)計算重構權值矩陣。構造誤差函數ε(W),并使得誤差最小,定義為 (9) 式中:xij表示為xi的第j個近鄰點(j=1,2,…,k),wij為xi和xij之間的權值,同時滿足 (10) 綜合式(9)和式(10),即有最小誤差函數 (11) 3)將樣本點從高維空間映射到低維空間。在低維空間中應滿足: (12) 式中:yi為xi映射在低維空間的輸出向量;yij表示為yi的第j個近鄰點(j=1,2,…,k),同時滿足 (13) (14) 則映射在低維空間的輸出向量Y=(y1,y2,…,yN),可以用下式求解: Y(I-W)(I-W)TYT=YMYT。 (15) 式中:Ii為N×N單位矩陣的第i列;Wi為矩陣W的第i列。 4)求解輸出向量Y。由推導公式可知,Y應由矩陣M的從小到大排列的d個非零特征值的特征向量構成的矩陣。考慮到最小的非零特征值無限趨近于0,因此選擇第2至第d+1個特征值對應的特征向量作為LLE降維算法的輸出向量Y。 卷積神經網絡是一種前饋神經網絡,具有局部連接特性和權值共享特性,能夠自動對原始數據進行局部空間特征提取,因此被廣泛應用于圖像識別等領域[10]。研究表明,卷積神經網絡可以學習到人工難以提取的深層次的特征,使用CNN有助于提高模型的判別能力和泛化能力。它通常是由多個卷積層、池化層和全連接層組成,每一層網絡輸入輸出的數據均是二維數據,由多個獨立神經元組成,有較高的識別精確度。 對于傳統的2D-CNN,只能提取二維圖像的特征信息,而3D-CNN適用于更高維度的圖像數據,在處理過程中增加了時間維度的信息(連續幀),可以同時提取出時間與空間的信息。相比于二維卷積,三維卷積更能捕捉到時序上的特征。3D-CNN的卷積公式為 (16) 將采集的2 s原始數據分為4幀數據,用上述方法生成4組MFCC特征向量,此時數據大小為[4×19×39×1],再將每一組數據經過LLE算法降維,則數據大小縮小為[4×19×39×1],其中4表示數據深度;19表示時間分量;18表示特征維度,1表示輸入網絡的通道。則三維卷積神經網絡的輸入數據集制作如圖1所示。 本文根據CNN網絡輸入數據的大小和特點,設計了用于識別變壓器鐵心松動故障的聲紋特征的網絡結構,該網絡能避免訓練過程中出現的過擬合和梯度爆炸現象,且能有較高的識別率。 在搭建CNN結構時,采用激活函數ReLU,它能極大地提高網絡的訓練速度;為了防止發生過擬合,使之在訓練集上訓練良好卻在測試集上準確率低的現象,因此選擇在全連接層進行了dropout操作,它是通過概率隨機丟棄部分神經元,使得訓練樣本在保持輸入和輸出神經元數量不發生變化的情況下進行參數的迭代;另外,為了防止發生梯度消失,又能夠加快學習收斂的速度,采用批規范操作,提高網絡的性能。 圖1 數據集制作過程Fig.1 Dataset production process 本文使用的3D-CNN是由兩層卷積層、兩層池化層及兩層全連接層組成,均采用“SAME”補零方式。其中,卷積層后接有激活層,激活層選擇的是線性整流函數(ReLu),dropout是一種非常有效的提高泛化能力,降低過擬合的方法,因此選擇在每一個全連接層后設置dropout層,速率均設置為0.5。由于本文作四分類問題,將最后一層設置為4節點,用softmax函數激活作分類。網絡的詳細結構如表1所示(batch size表示批尺寸:一次輸入網絡訓練的樣本數量)。 表1 3D-CNN網絡結構Table 1 3D-CNN network structure 給每一段音頻生成經過LLE降維后的MFCC特征向量標記,送入3D-CNN模型中分別訓練,用損失值loss和準確率acc來評判模型的優劣,損失值loss用來描述預測值與實際值之間的差距,acc表示正確分類的數量占總預測樣本的比例。loss值越小,acc值越大,則判定該模型越適合變壓器鐵心松動故障的識別。其中,損失函數選擇的是傳統的交叉熵損失函數(softmax loss)。softmax loss是由softmax和cross-entropy loss 組合而成的損失函數,其損失函數的表達式為 (17) 鐵心的噪聲能代表變壓器運行時的狀態信息,在不同的運行工況下或者發生故障情況下,它的噪聲信號在時域、頻域會出現不同程度的變化,但是這種狀態信息的變化非常復雜,難以直接通過某一個數值的變化辨別,因此構造由LLE改進的MFCC-CNN的變壓器聲紋識別模型,用于變壓器鐵心松動故障的診斷。 通過第1節的噪聲MFCC特征的提取并通過LLE的降維,將預處理后的特征向量作為CNN網絡的輸入量進行深度學習,形成基于LLE降維的MFCC-CNN識別模型,從而實現變壓器的鐵心在不同程度松動下的聲紋特征的提取與故障的識別。基于LLE降維的MFCC-CNN識別模型實現的具體步驟為: 1)搭建變壓器鐵心松動故障試驗模擬平臺,采集鐵心在松動不同程度下的變壓器噪聲信號; 2)給采集的噪聲數據規范為統一的數據長度并添加數據標簽; 3)提取每一段信號的MFCC特征并使用LLE算法對其降維并制作成輸入網絡的數據集; 4)搭建3D-CNN網絡結構,將步驟3)制作的數據集輸入網絡進行訓練,并調整網絡參數至最佳; 5)使用測試集測試訓練好的模型。 為了驗證基于LLE降維的MFCC-CNN識別模型的變壓器鐵心松動故障的識別效果,搭建了變壓器鐵心松動故障試驗平臺,采集鐵心在不同松動程度下的噪聲信號。 試驗對象為一臺S13-M-200/10變壓器,根據國標GB/T 1094.10—2003對該變壓器噪聲測量的標準和要求,采用電容式麥克風作為聲傳感器對變壓器鐵心不同松動情況下的噪聲進行測量,采樣頻率為50 kHz,頻率響應為20 Hz~20 kHz。試驗在變壓器廠廠房中進行,廠房空間較為空曠,幾乎不存在聲波反射的情況。試驗環境如圖2所示。 圖2 試驗環境Fig.2 Test environment 在設置鐵心不同松緊程度時,將變壓器油抽出后吊心,鐵心的壓緊程度是通過改變螺栓的預緊力來確定的,首先使用扭力扳手確定鐵心的額定預緊力,再通過調整不同的預緊力達到模擬鐵心不同松緊程度的目的,模擬過程如圖3所示。在低壓側加400 V電壓,對變壓器做空載運行如圖4所示,分別采集變壓器鐵心未松動、松動40%、松動80%、松動100%時若干個聲紋信號。 圖3 模擬鐵心松動故障Fig.3 Simulated core looseness fault 圖4 空載運行控制圖Fig.4 No load operation control diagram 分別采集鐵心在未松動情況下的樣本82個,松動40%時的樣本129個,松動80%時的樣本129個,松動100%時的樣本140個(每個樣本的截取時間為2 s)。將變壓器鐵心在同一種松動程度下的數據歸為一類,并統一添加標簽,使用卷積神經網絡進行無參特征量的訓練學習。為了驗證模型的泛化能力,隨機在樣本中抽取80%作為訓練集,剩余20%則作為測試集。同時,在每一次訓練卷積神經網絡時,都將樣本數據重新打亂排序,以保證模型的有效性。 限于篇幅,本文以圖2中②號傳感器采集的聲紋信號測試結果為例進行計算分析。圖為試驗變壓器在鐵心未松動、松動40%、松動80%及松動100%時的聲紋信號的頻率分布圖。由圖可見,在鐵心處于不同松動程度時,變壓器的聲紋信號的頻譜特征各不相同。 從圖5可以看出,鐵心在未松動時(正常狀態下),聲紋信號的頻率主要集中在100、200、300 Hz等偶次諧波,并伴隨少量奇次諧波的存在;在鐵心發生松動時,聲音信號的能量在不同頻率范圍的分布發生了改變,具體表現為:各頻率分量的幅值均發生改變,且明顯出現了500、600、800、1 000 Hz等分量。對不同松動程度的聲紋信號作3層小波包分解,分解出0~2 500 Hz的8個頻率帶,其各個頻段能量所占的比例分布圖如圖6所示。從圖6中可以明顯看出,隨著松動程度的不同,各個頻率帶的能量比例會發生不同程度的變化,這為聲紋識別提供了可能。 且變壓器聲紋能量集中在低頻部分,從梅爾頻率的定義可以看出,梅爾濾波器加強了低頻部分,削弱了高頻部分,所以將變壓器聲紋信號映射到梅爾頻率域上,可以突出變壓器聲紋信號中富含信息的低頻部分,有助于對聲紋信號中有用信息的提取。 圖5 鐵心不同松動程度的聲紋頻率分布Fig.5 Distribution of voiceprint frequency of iron core with different looseness 將變壓器噪聲信號通過3.1采集并制作成數據集后,分別提取信號的MFCC特征量,再對特征向量LLE降維。采集變壓器各種狀態下的穩定聲紋信號2 s并截取成4段(每段0.5 s),對每段作相同處理:取每幀長為50 ms,重疊率為50%。由此提取到的MFCC特征向量的每一幀的時間幀數為19,每一幀頻率的維數為39,此時數據的大小為[4×19×39×1] ,4代表的是將1個樣本數據分成4段,[19×39]代表每一幀數據的大小,1代表通道數。 將上述的特征向量使用LLE降維,降維后的每一個樣本的數據大小為[4×19×18×1],選擇降維后的維度是18的原因是,當維度低于18時,降維后的數據將提取不到有效的特征量,導致后續的3D-CNN計算不收斂,泛化性極低,因此選擇將數據降到18維。取某一幀數據提取MFCC后降維前后的計算結果如圖7所示,數據尺寸被大大縮小。 圖6 不同松動程度聲紋的各個頻段能量所占比例分布圖Fig.6 Distribution of energy proportion of each frequency band of voiceprint with different looseness 在模型訓練過程中,卷積神經網絡超參數的選擇會直接影響網絡的訓練結果。本文選擇調整的超參數為批尺寸(batch size)和學習率(learning rate)。 4.2.1 批尺寸優化 不同的batch size直接影響的是完成一次完整樣本的訓練所需要的次數,batch size值越大,處理一次完整樣本的速度就越快,則當需要達到相同精度時其需要迭代的次數也越多。在這個過程中,會存在一個最優的數值,此時模型的訓練結果最佳。本文選取batch size分別等于10、20、30、60,訓練結果如圖8、圖9所示。 圖7 特征量將為前后對比Fig.7 Comparison before and after dimensionality reduction of feature quantity 圖8 不同批尺寸下的準確率曲線Fig.8 Accuracy curve under different batch sizes 從圖8可以明顯看出,當batch size=10、20、30時,訓練過程中準確率波動很大,且在圖7的loss曲線中,沒有呈現穩定下降趨勢,因此當批尺寸選擇10、20或30時,可能會導致模型最終不能收斂。而當batch size=60時,在訓練過程中,當迭代次數達到43以后,準確率已穩定在1,且loss值在迭代過程中總體呈現出穩定下降的趨勢。不同批尺寸最終訓練模型在測試集上的表現效果如表2所示,當batch size=60時,準確率最高達到96.88%;對于每個模型都選擇迭代100次,從表2中平均每次迭代所需時間可以看出,批尺寸的選擇對計算時間影響不大。因此根據準確率與損失函數曲線選擇batch size=60。 圖9 不同批尺寸下的損失函數曲線Fig.9 Loss function curve under different batch sizes 表2 不同批尺寸的訓練結果Table 2 Training results of different batch sizes 4.2.2 學習率優化 學習率(Learning rate)作為監督學習以及深度學習中重要的超參數,其決定著目標函數能否收斂到局部最小值以及何時收斂到最小值。合適的學習率能夠使目標函數在合適的時間內收斂到局部最小值。本文選取Learning rate分別等于1,0.1,0.01,0.001,訓練結果如圖10、圖11所示。 如圖10所示,當learning rate=1時,訓練過程中準確率在0.2以下浮動,且呈現不收斂趨勢;learning rate=0.1時,隨著迭代次數的增加,準確率和損失值還存在大幅度的波動,使得模型訓練不穩定;而對于learning rate=0.01和0.001,當learning rate=0.001時,迭代次數在25次以后,訓練集的準確率維持在1,而learning rate=0.01雖然在迭代次數36以后準確率維持在1,但是在圖9損失函數曲線中,可以觀察到learning rate=0.01的曲線在learning rate=0.001的下方,且在測試集中,模型采用學習率為0.01的準確率為98.33%,而模型采用學習率為0.001的準確率為95.00%,且在表3中平均每次迭代的時間也達到近11 s.因此為該卷積神經網絡選擇的學習率為0.01。 圖10 不同學習率下的準確率曲線Fig.10 Accuracy curve under different learning rates 圖11 不同學習率下的損失函數曲線Fig.11 Loss function curve under different learning rates 表3 不同學習率的訓練結果Table 3 Training results of different learning rates 將上述調參后的3D-CNN使用MFCC直接進行卷積神經網絡計算和基于LLE降維的MFCC進行訓練的結果如表4所示。直接使用MFCC提取的特征量維數是39,而經過LLE降維的MFCC的特征量維數是18,因此在網絡訓練過程中計算量將大量下降,就會縮短每次迭代所需要的平均時間。從表4中可以看出采用改進后的基于LLE降維的MFCC的特征量并使用調參后的3D-CNN訓練的準確率可以從90%提高到98.33%,且平均每次迭代的時間大大縮短。 表4 改進算法前后對比Table 4 Comparison before and after the improved algorithm 使用2D-CNN作為識別模型進行變壓器鐵心故障診斷時,并不采用“連續幀”來制作數據集,而是將每個2 s的數據樣本直接提取MFCC特征向量,再使用LLE對其進行降維。為了驗證3D-CNN識別模型比2D-CNN識別模型的優越性,采用與表1相同數量的卷積層和池化層。計算結果表明,采用2D-CNN模型同樣能收斂,但最終在測試集上的準確率為93.33%,平均每次迭代時間為9.153 81 s,相較于表中顯示的基于LLE降維的MFCC提取的特征量并使用3D-CNN模型的識別效果準確率達到98.33%,平均迭代時間只有8.511 26 s,那么隨著樣本數量的增加,2D-CNN訓練所需要的時間要比3D-CNN大幅度增加,因此采用3D-CNN更有優勢。 1)采用LLE算法降維后的MFCC作為變壓器聲紋信號的特征向量,能夠完整地保留其主要特征信息,并大幅降低模型的計算量,從而提高模型的識別速率,將平均每次迭代時間從14.337 0 s降至8.511 26 s; 2)使用經LLE降維的MFCC作為特征量,消除MFCC的特征向量中不能反應運行狀況的冗余的特征向量,較直接使用MFCC作為特征量的準確率從90.00%提高到98.33%。 3)構建了相同網絡結構的2D-CNN和3D-CNN,并使其訓練同一批數據集,計算顯示在準確率和識別速率上,3D-CNN更具優勢。
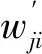
2 基于三維卷積神經網絡的模式識別
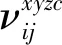
2.1 數據集制作
2.2 網絡結構及性能指標

2.3 LLE改進的MFCC-CNN的模式識別
3 試驗描述
3.1 試驗平臺搭建



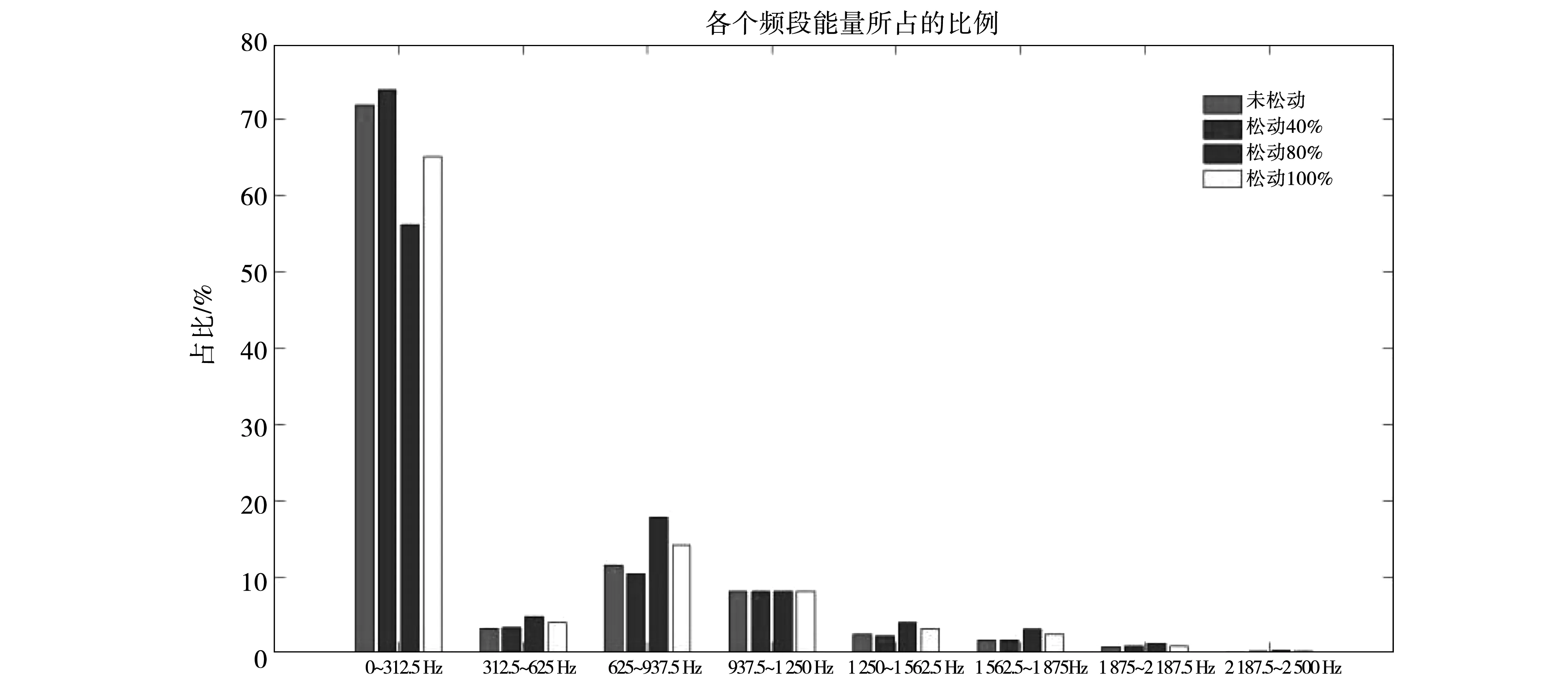
3.2 聲紋數據分析
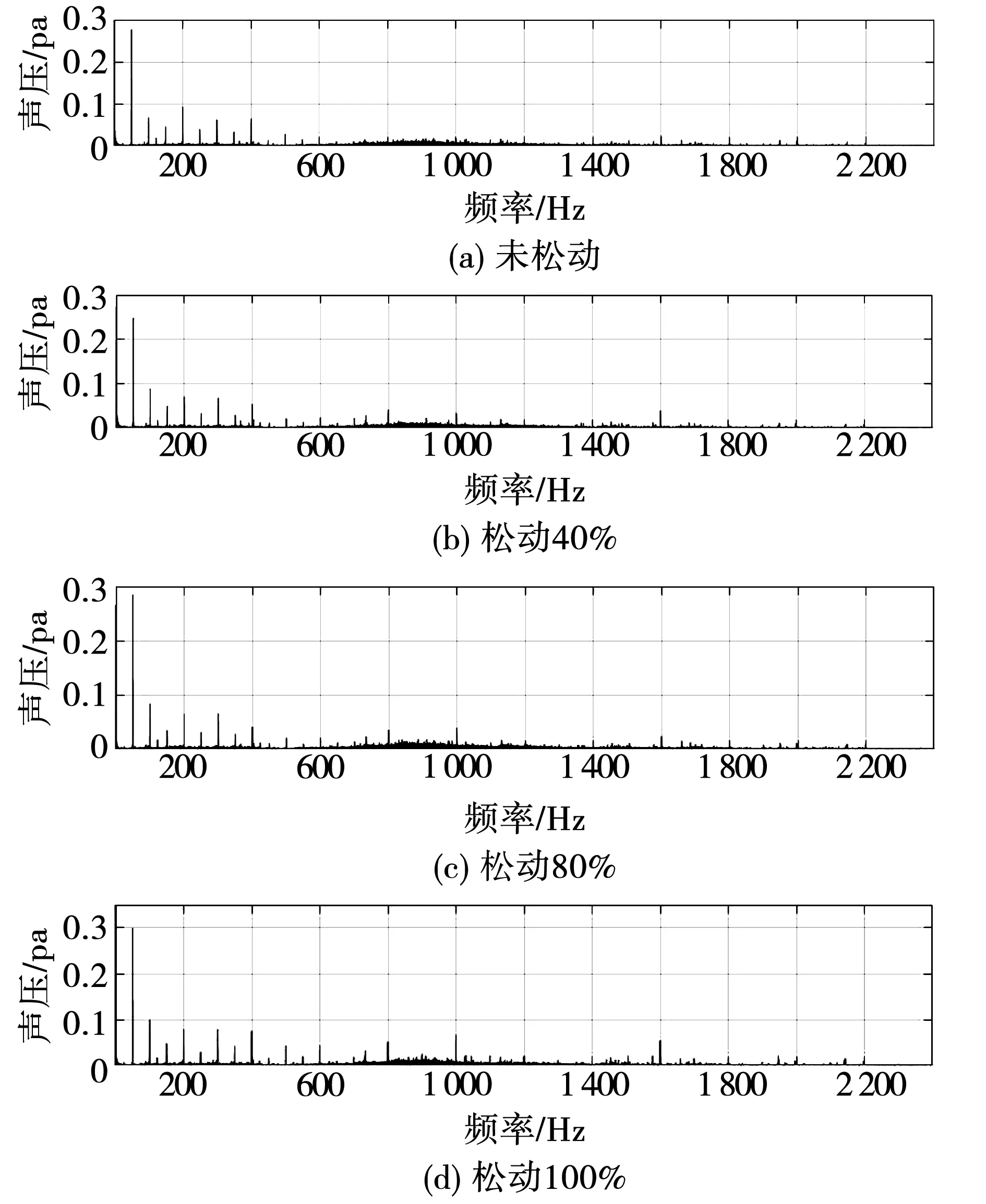
4 結果分析
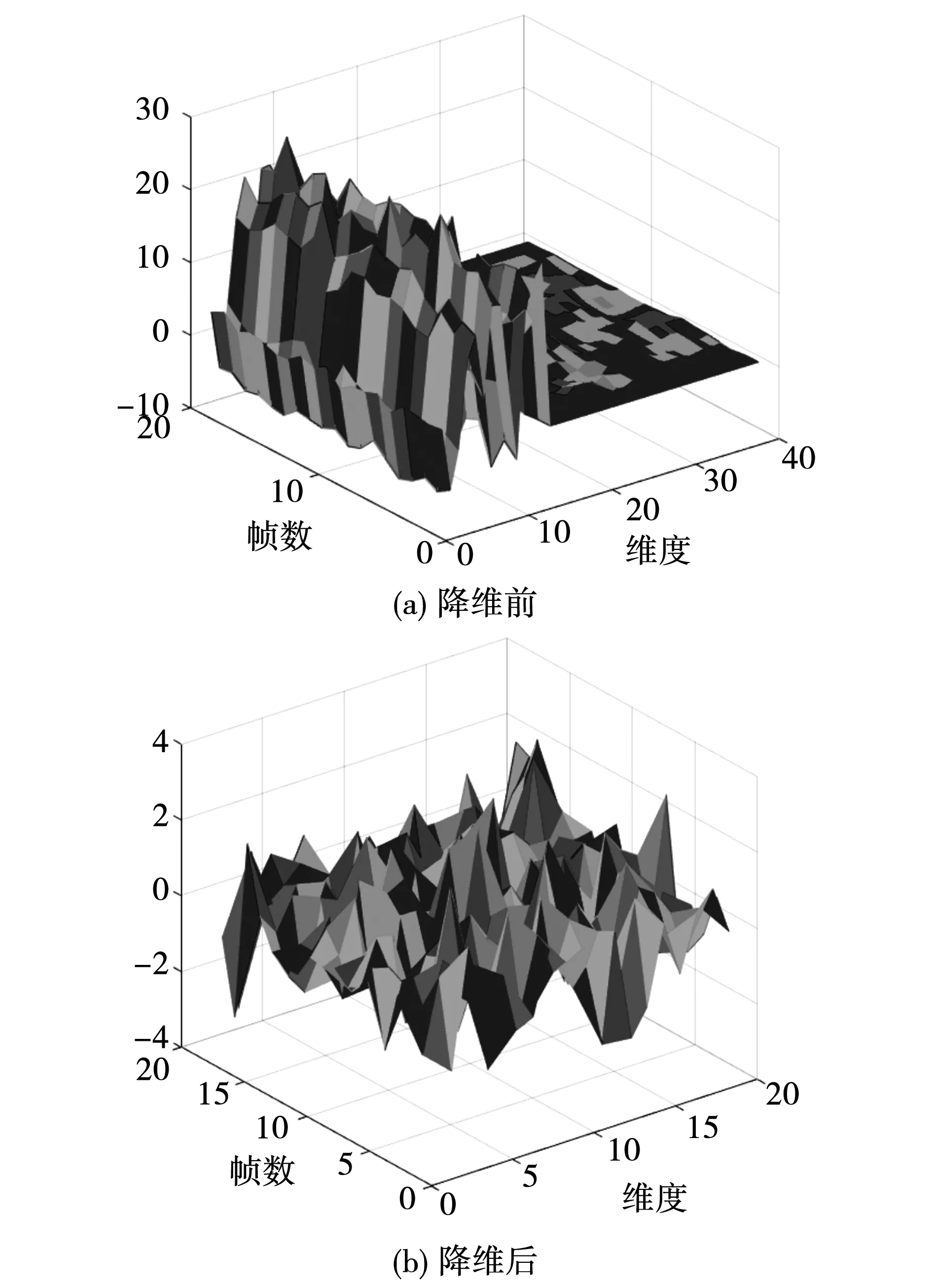
4.1 基于LLE降維的MFCC特征提取
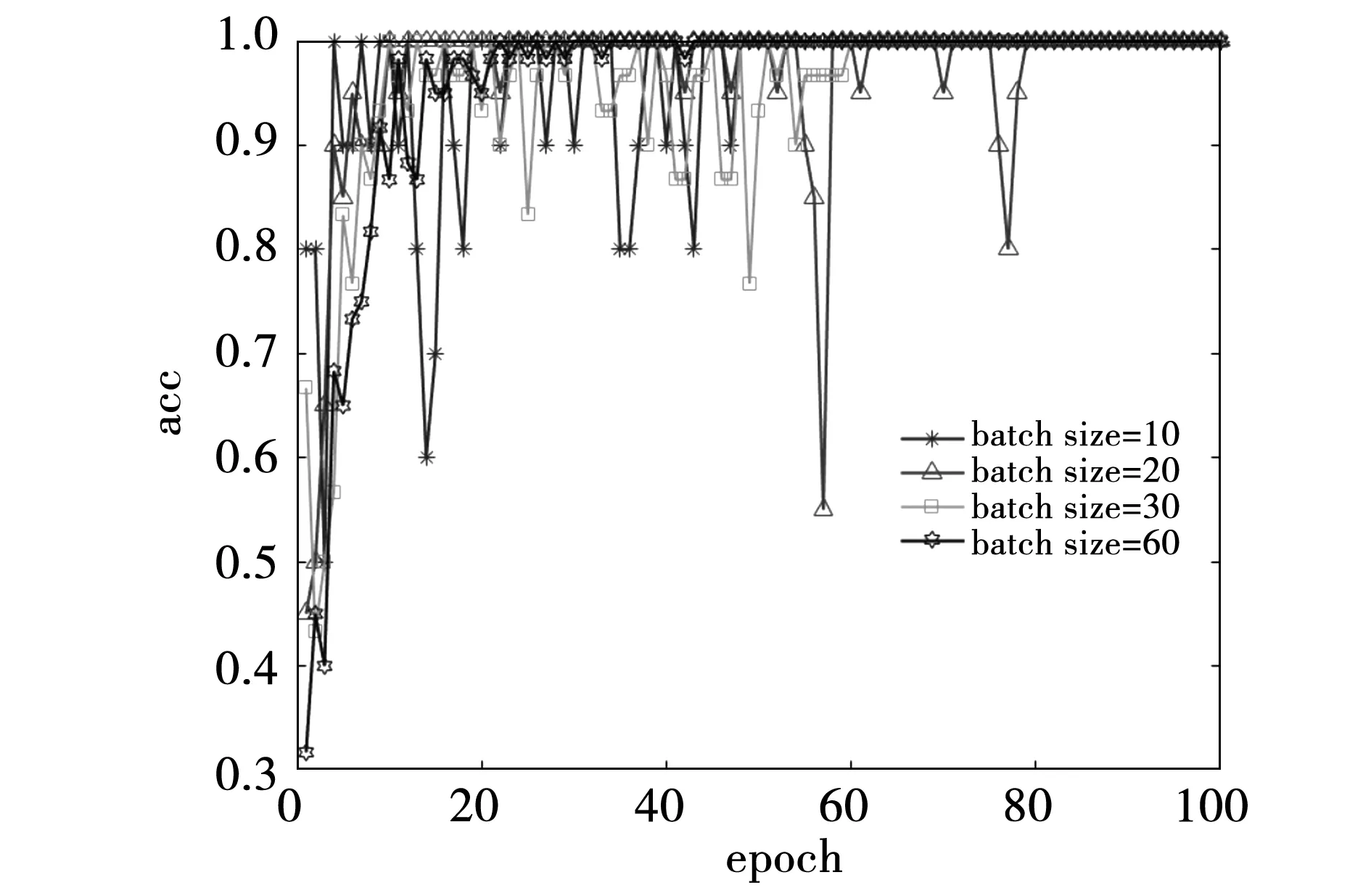
4.2 超參數優化
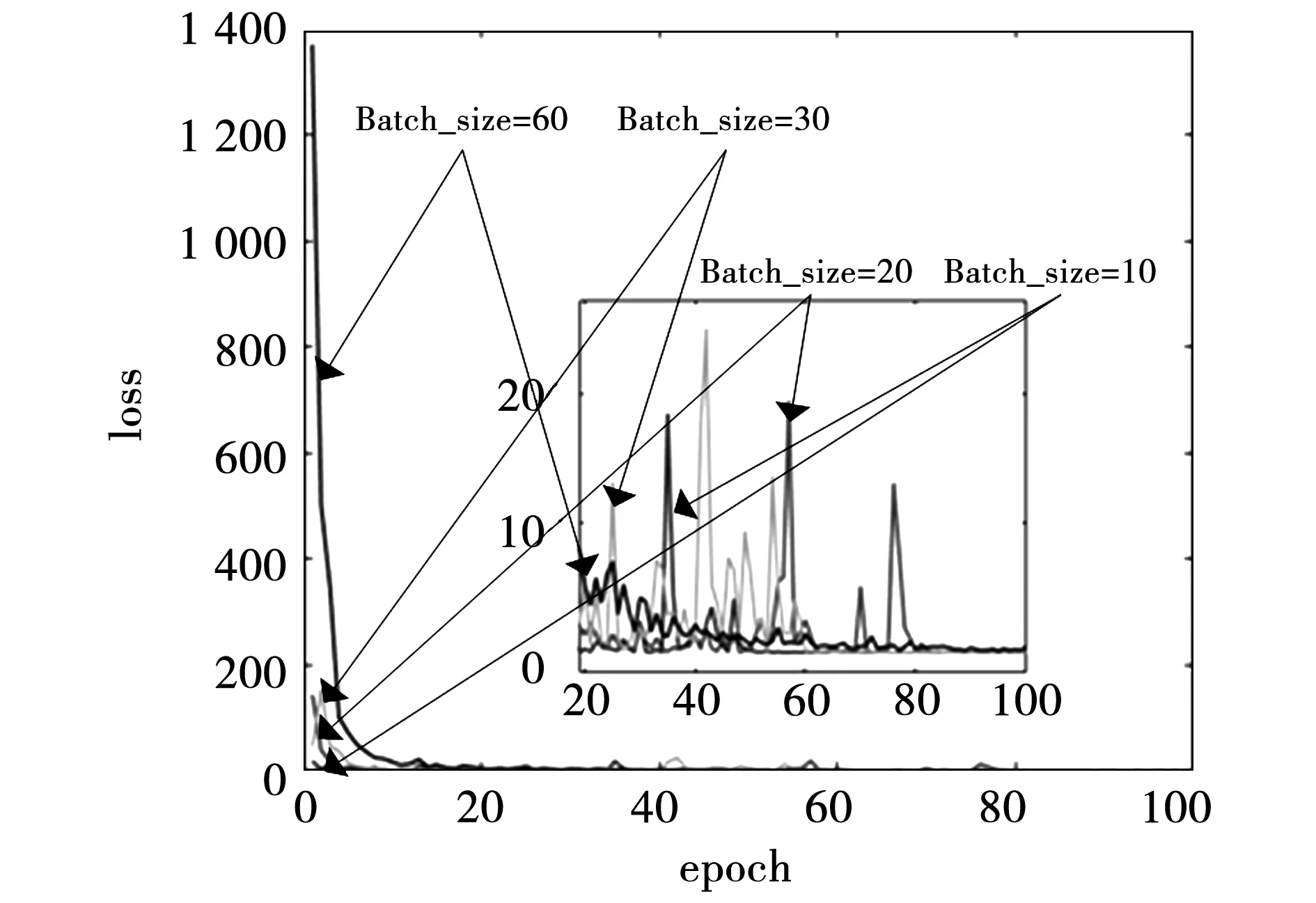
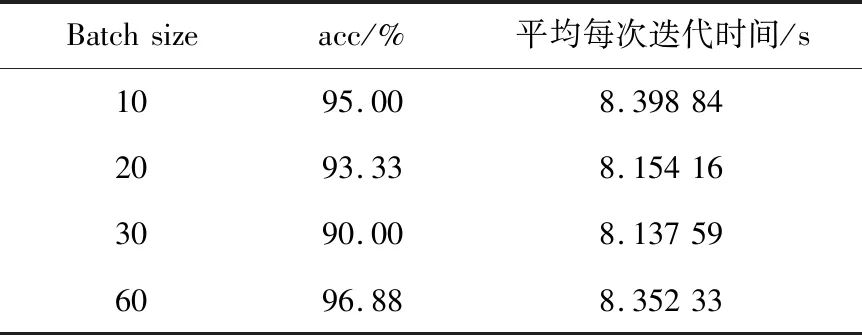
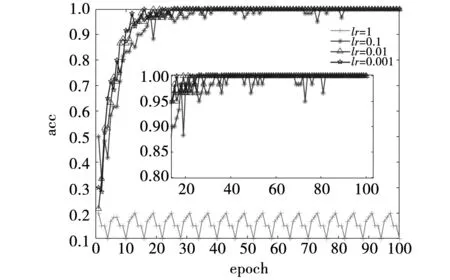
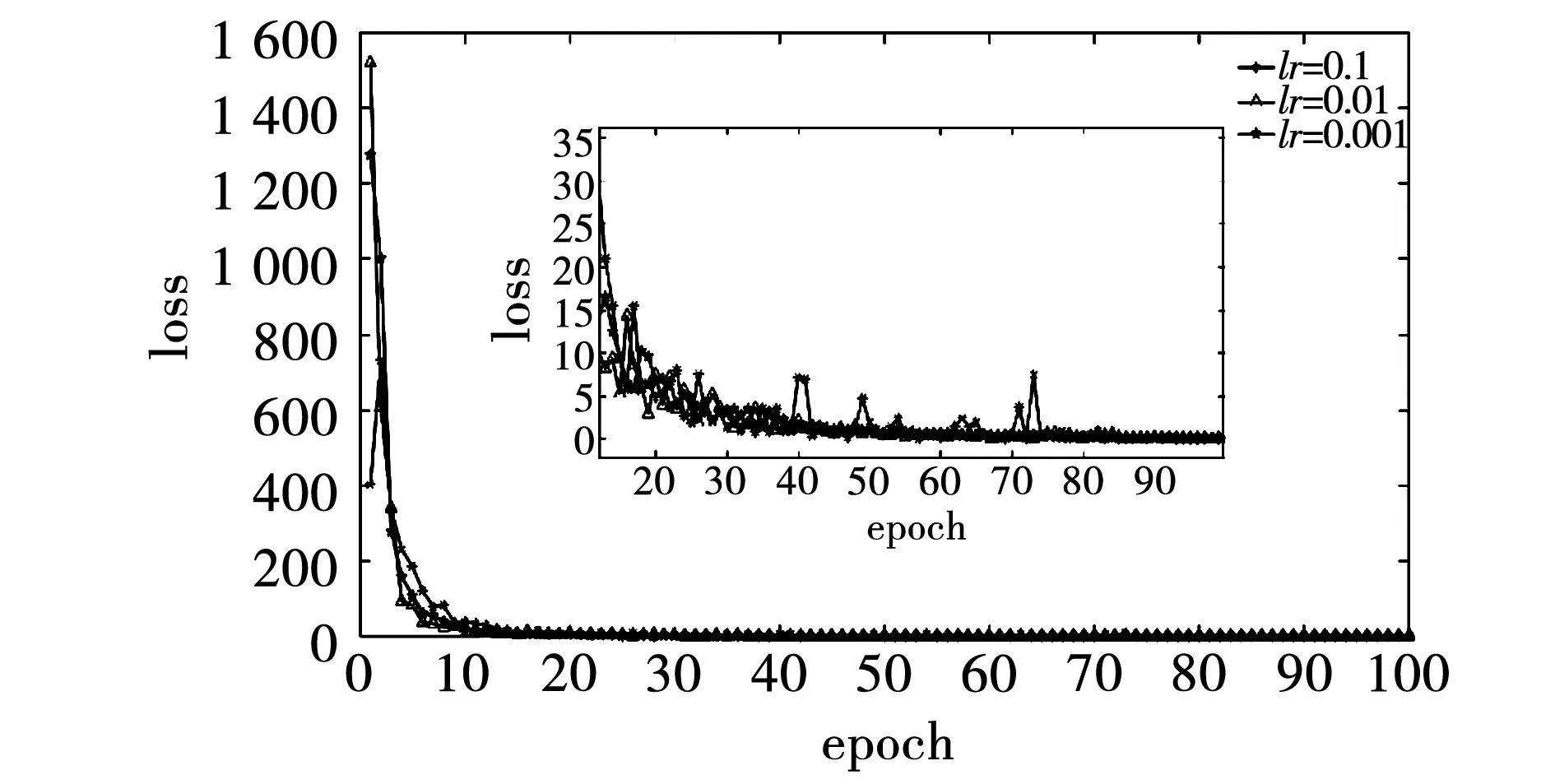
4.3 3D-CNN識別結果
4.4 與2D-CNN比較
5 結 論
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08考試與評價·高一版(2020年6期)2020-11-02 02:45:24中國生殖健康(2019年3期)2019-02-01 06:12:26通信電源技術(2018年3期)2018-06-26 06:33:30現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38通信電源技術(2016年3期)2016-03-26 07:13:46鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25海軍航空大學學報(2015年3期)2015-11-11 17:20:00電測與儀表(2014年12期)2014-04-04 12:10:16
