嵌入注意力機制的多尺度深度可分離表情識別
2023-01-12 11:48:02宋玉琴高師杰曾賀東熊高強
北京航空航天大學學報 2022年12期
宋玉琴, 高師杰, 曾賀東, 熊高強
(西安工程大學 電子信息學院, 西安 710600)
面部表情識別作為人機智能交互系統的關鍵技術,是當前人工智能的重要研究課題。 傳統的表情識別主要是應用機器學習方法人為設計特征,最后用分類算法判定表情。 提取特征的方法主要有局部二值模式(local binary pattern, LBP)[1]、主成分分析法(principal component analysis, PCA)[2]、Gabor 小波變換[3]、尺度不變的特征變換(scale invariant feature transform, SIFT)[4]、灰度共生矩陣(gray-level co-occurrence matrix, GLCM)[5]等。常用的分類算法有支持向量機(support vector machine, SVM)[6]、K 近鄰算法(K-nearest neighbor,KNN)[7]等。 上述方法特征提取與表情分類是2 個分開的過程,效率較低,且其特征提取受到人為因素影響,容易丟失部分表情特征,特征提取的不完備使得最終分類效果一般。
基于深度學習的表情識別,其特征提取與表情分類可同時進行。 李勇等[8]基于LeNet-5 優化網絡模型,將網絡中提取的低層特征與高層特征相結合,在CK +數據集上取得了83.74%的識別率。 Mollahosseini 等[9]將AlexNet 與GoogleNet 網絡融合,增加了網絡的深度和寬度,在CK + 數據集上取得了93. 20% 的識別率。 Jung 等[10]通過輸入人臉外貌特征與人臉關鍵點聯合訓練網絡,增強了特征提取的多樣性,在CK +數據集上取得了97.25%的識別率。
研究表明,更深更寬的卷積神經網絡能夠有效提高表情識別率,但隨著網絡深度的增加,會出現梯度爆炸和梯度彌散的現象,導致模型訓練難以收斂。 對此,何凱明等[11]提出了深度殘差網絡(ResNet),有效緩解了網絡性能退化和梯度爆炸等問題。 受此啟發,本文構建了殘差網絡嵌入CBAM[12](convolutiona block attention module)的多尺度深度可分離表情識別網絡。 通過疊加多層深度可分離卷積層來代替5 ×5、7 ×7、9 ×9 等大卷積核,提取不同深度的特征信息,降低網絡運算參數,采用CBAM 注意力機制提高網絡模型對關鍵表情特征的敏感度,提升網絡中面部表情特征權重,剔除無關的冗余特征,提升網絡的魯棒性。同時,通過恒等映射有效緩解了網絡中的梯度問題,提高網絡收斂速度。
1 表情識別網絡模型
1.1 CBAM 注意力機制
注意力機制是模仿人類在瀏覽時專注自己感興趣的事物而忽視無關事物的特性。 CBAM 注意力機制由通道注意力與空間注意力串聯組合而成。 其中,通道注意力關注的是有意義的輸入特征,空間注意力關注的是最具信息量的特征部分。
假設輸入特征F大小為H×W×C,H、W和C分別為特征的長、寬和通道數。 通道注意力如圖1所示。 首先,特征F分別進行最大池化(Maxpool)和平均池化(Avgpool)后,特征變化為1 ×1 ×C,再分別輸入共享權值的多層感知器(multi-layer perception, MLP),其中隱藏層為降低參數運算設置C/r個神經元,r為縮減倍數,激活函數為ReLU。 然后,將經MLP 運算后并相加的特征采用Sigmoid 激活函數完成映射,得到權重系數MC。 最后,將輸入特征與MC相乘,得到完成通道注意力的新特征。

圖1 通道注意力模塊Fig.1 Channel attention module
空間注意力如圖2 所示。 首先,特征F分別經最大池化和平均池化后,并在通道上完成拼接,得到H×W×2 的特征。 然后,將其輸入到卷積核為7 ×7、Sigmoid 激活函數的卷積層,得到最終的權重系數MS。 最后,F與MS相乘便可得到完成空間注意力的新特征。
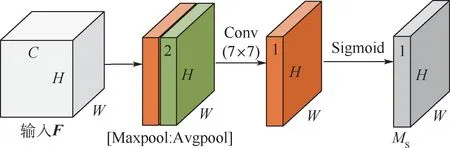
圖2 空間注意力模塊Fig.2 Spatial attention module
1.2 嵌入CBAM 的多尺度深度可分離卷積殘差塊
本文提出的嵌入CBAM 的多尺度深度可分離卷積殘差塊如圖3 所示,其中,深度可分離卷積由點卷積(pointwise convolution, PW)和深度卷積(depthwise convolution, DW) 組成,如圖中A_Conv2d 和B_Conv2d 所示。 假設輸入F′特征類型為H×W×C。 以本文采用的卷積核為例,F′特征經N個點卷積,其參數量為H×W×C×N,通過卷積核為3 ×3 ×1 的深度卷積,參數量為H×W×C×3 ×3,因此,深度可分離卷積的計算量為H×W×C×3 ×3 +H×W×C×N。 特征F′經卷積核為3 ×3 ×N標準卷積運算,其參數量為H×W×C×3 ×3 ×N。 深度可分離卷積與標準卷積參數運算量對比如式(1)所示。 采用深度可分離卷積神經網絡替代標準卷積使得網絡模型的參數減少1/8 ~1/9,從而輕量化網絡模型。

圖3 嵌入CBAM 的多尺度深度可分離卷積殘差塊(基礎塊)Fig.3 Multi-scale depthwise separable convolution residuals embedded in CBAM(Basic Block)

A_Conv2d 和B_Conv2d 均由卷積層、批歸一化層(batch normalization)、ReLU 激活層組成。 其中,批歸一化層通過歸一化每批數據,緩解深層神經網絡中梯度消失的問題,提升網絡模型的非線性表達。 ReLU 激活函數能有效改善梯度的彌散問題,增強網絡模型的收斂效率。 本文利用2 層A_Conv2d 和B_Conv2d 的疊加代替一個5 ×5 的卷積核,利用3 層A_Conv2d 和B_Conv2d 的疊加代替一個7 ×7 的卷積核,使用4 層A_Conv2d 和B_Conv2d 的疊加代替一個9 ×9 的卷積核,從而豐富網絡提取特征的多樣性,在每個通道后嵌入CBAM,并對不同通道進行特征融合。 CBAM 能提高網絡表情相關特征的權重,剔除冗余特征,提升特征的有效性。 通過恒等映射緩解深層網絡梯度彌散和梯度爆炸的問題,提高網絡訓練的收斂速度,輸入X在經過卷積激活等圖中運算輸出為F(X)。 若輸入X與輸出F(X)的特征維度相同,則直接加和。 若維度不同,則與輸出F(X)維度一致,最終輸出H(X) =X+F(X)。
1.3 表情識別網絡總體模型
本文提出的殘差網絡嵌入CBAM 的多尺度深度可分離表情識別網絡如圖4 所示,由1 個卷積核為3 ×3 ×64 的卷積層、8 個Basic Block、全局平均池化層(Golbal Average Pooling)和全連接層(FC)等構成。 其中,Basic Block 的卷積核的個數依次為64、64、128、128、256、256、512、512。 全局平均池化層能生成與分類類別相對應特征圖,增強特征圖與類別的一致性,對每個特征圖求和取均值,最終輸入到Softmax 分類層。 此外,全局平均池化可看做對模型的網絡結構整體進行正則化,從而提高模型的泛化性能。
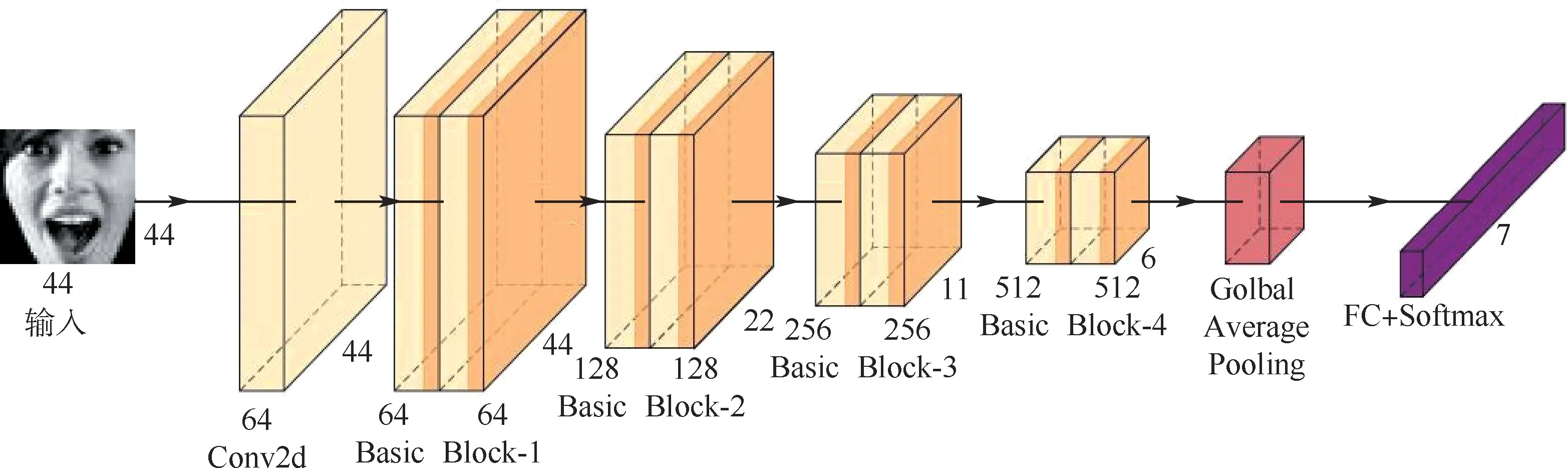
圖4 基于殘差網絡的嵌入CBAM 的多尺度深度可分離表情識別網絡結構Fig.4 Structure of multi-scale depthwise separable facial expression recognition network embedded in CBAM based on residual network
網絡損失函數選用交叉熵(cross-entropy)損失函數, 其能度量預測的概率與真實的差異情況,交叉熵損失越小,則模型預測的準確率越高。交叉熵損失函數表示為

式中:g(xi)為模型輸出預測值;yi為輸入xi真實值;C為樣本數;L為計算后的交叉熵損失值。
如圖4 所示,向模型輸入預處理過后的44 ×44 ×3 的圖像,經過第1 個卷積處理后特征格式為44 ×44 × 64,經過8 個Basic Block 特征圖為6 ×6 ×512,最終送入到全連接層和Softmax 分類層得出表情類別。 網絡模型的特征變化如表1所示。
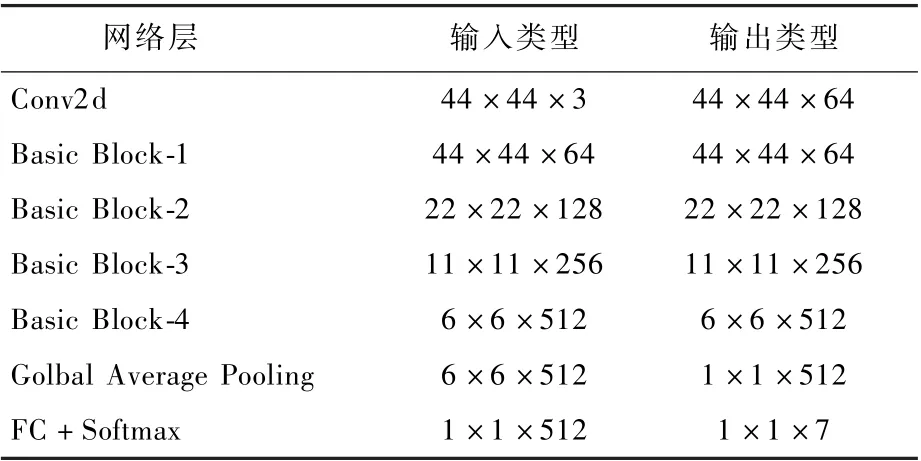
表1 表情識別網絡特征參數Table 1 Feature parameters of expression recognition network
2 實驗環境與結果
本文設計的網絡在Ubuntu18.04 LTS 系統下使用Pytorch 深度學習框架完成搭建,實驗硬件平臺如下:CPU 為AMD Ryzen 5 3600X,主頻為3.8 GHz,內存為32 GB,GPU 為顯存11 GB 的NVIDIA GTX 1080TI,選用Fer-2013 和CK +公開表情數據集進行表情識別網絡模型的訓練與測試。
2.1 數據集選擇與處理
Fer-2013 數據集[13]是Kaggle 面部表情識別比賽提供的一個數據集,包括訓練集圖像28 709 張,公共驗證集與私有驗證集均3 589 張圖像,圖像的像素都為48 ×48。 該數據集包含憤怒(4 953 張)、厭惡(547 張)、恐懼(5 121 張)、快樂(8 989 張)、悲傷(6 077 張)、驚喜(4 002 張)和中立(6 198 張)7 類表情,各類表情如圖5 所示,每列為一類表情,其同類表情的面部姿態、年齡、表情強度、膚色有明顯的差異,并且很多人臉有被眼鏡、帽子、手等物體遮擋,這樣更符合真實場景下的人臉表情,使用該數據集更能說明算法模型的泛化性能。

圖5 Fer-2013 數據集的表情示例Fig.5 Sample expression diagram of Fer-2013 dataset
CK +數據集[14]是面部表情識別的代表性數據集之一,其在實驗室條件下采集,較為嚴謹可靠。 數據集包括123 人的593 個圖像序列,展示了表情從平靜狀態到峰值的過程,其中327 個為帶有標簽表情序列。 本文實驗選取除中立表情外的其他7 種表情,提取表情序列中最后3 幀,并將其處理為48 ×48 像素的圖像,如圖6 所示。 這7 種表情共有981 張圖像,包含憤怒(135 張)、厭惡(177 張)、恐懼(75 張)、快樂(207 張)、悲傷(84 張)、驚喜(249 張)和藐視(54 張)。

圖6 CK +數據集的表情示例Fig.6 Sample expression diagram of CK + dataset
為提高網絡的泛化性能,實驗對Fer-2103 數據集和CK +數據集進行了數據增強。 如圖7(a)所示,在訓練網絡模型時,將訓練集的圖像隨機裁剪為44 ×44 大小,其中隨機裁剪掉的為紫色部分,并進行水平翻轉,將數據集擴充數據為原來的2 倍后輸入網絡進行訓練。 如圖7(b)所示,為提高網絡模型的魯棒性能,在進行測試集驗證時,將輸入圖像分別在左上角、左下角、四邊、右上角和右下角進行裁剪,裁剪部分如圖7(b)中紫色部分所示,得到5 張44 ×44 大小的圖像,并水平翻轉,得到10 倍數據,將處理后的圖像輸入模型得到類別概率求和并取均值,其最大概率分類為最終表情類別。

圖7 Fer-2013 訓練集與測試集的數據增強示例Fig.7 Sample figure of data enhancement of Fer-2013 training set and test set
2.2 實驗過程與結果
在Fer-2013 數據集上訓練時,網絡超參數如下:實驗共迭代300 次,初始學習率設為0.01,批量大小設為32,50 次迭代后,每8 輪迭代學習率衰減為之前的0.8 倍。 在公共驗證集上測試優化網絡權值,在私有驗證集上測試模型,評估模型性能。 混淆矩陣如圖8 所示。 本文算法在Fer-2013數據集得到73.89%的準確度,快樂(91%)、驚喜(84%)、中立(74%)等表情因相對其他表情具有明顯的面部特征從而獲得較高的識別率,而厭惡(69%)、憤怒(64%)、悲傷(64%)和恐懼(58%)4 種表情之間誤判率相對較高,其主要原因是:這些表情本身就有較高的相似性,人類也難以辨認陌生人的這4 類表情。
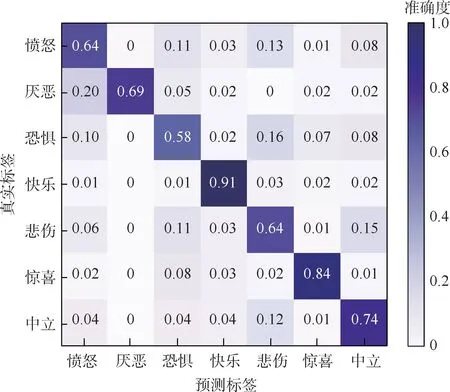
圖8 Fer-2013 私有驗證集表情分類的混淆矩陣Fig.8 Confusion matrix of expression classification in Fer-2013 private validation set
此外,這些表情圖像數據相對其他表情較少,類別數據的不均衡導致網絡訓練不充分,也是影響其識別率的重要因素。
在CK + 數據集上訓練時,因其數據較少,故采用十折交叉驗證,實驗以9 ∶1 的比例將數據集分為訓練集和測試集,訓練集882 張圖像,測試集99 張圖像。 實驗共迭代200 次。 訓練批量大小設為64,前50 次迭代其學習率為0. 01,之后每8 輪迭代,學習率衰減為之前的0. 7 倍。 其測試集混淆矩陣如圖9 所示。 本文算法在CK + 數據集得到97. 47% 的準確度,快樂(100%)、驚喜(99%)、厭惡(98%)、憤怒(97%)等均有較高的識別率。 恐懼(95%)、藐視(93%)、悲傷(92%)等表情因受類別數據不均衡和本身易混淆的影響,識別率相對較低。

圖9 CK +測試集表情分類的混淆矩陣Fig.9 Confusion matrix of expression classification in CK + test set
為驗證本文算法的先進性,在Fer-2013 和CK +公開表情數據集上,與近年其他表情識別算法進行對比,對比結果如表2 所示,本文構建的網絡模型具有更強的泛化性能。 此外,因為Fer-2013 數據集存在較多的受遮擋面部圖像,且存在部分表情標簽誤分的問題,模型在Fer-2013 數據集準確度整體相對CK +數據集較低。
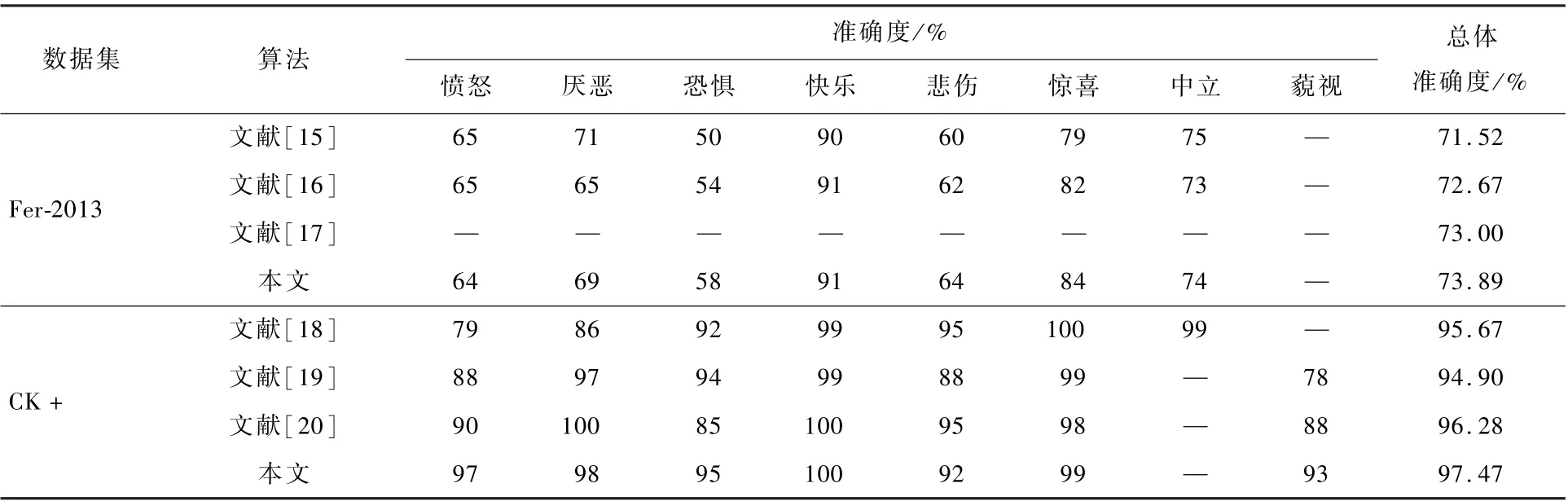
表2 本文算法與其他表情識別算法的準確度對比Table 2 Comparison of recognition rates between proposed algorithm and other expression recognition algorithms
2.3 消融實驗
為進一步驗證CBAM 注意力機制與多尺度卷積結構特征提取的有效性,實驗通過增刪Basic Block 中不同通道的卷積結構與注意力機制進行實驗驗證。 實驗在Fer-2013 和CK + 數據集上訓練時,網絡中的超參數與2.2 節中一致。 消融實驗結果如表3 所示,表3 中的A、B、C、D 分別表示不同尺度的卷積模塊,如圖3 所示,此外ACBAM、B-CBAM、C-CBAM、D-CBAM 分別對應A、B、C、D 卷積模塊后添加CBAM 注意力機制。 由表3 分析可知,隨著Basic Block 中通道由A 增加到ABCD 通道,2 個數據集上表情識別率均有明顯提升,驗證了通過提取多尺度的表情特征能有效提升表情的識別率。 此外,隨著Basic Block 各各個通道依次增加CBAM 注意力機制,數據集上的表情識別率穩步提升。 驗證了嵌入CBAM 注意力機制能有效提升網絡中表情特征的表達,削弱了網絡中無關特征的權重。

表3 消融實驗Table 3 Ablation experiments
3 結 論
本文設計的嵌入CBAM 多尺度深度可分離殘差表情識別網絡,通多層小卷積層的疊加來代替大卷積核,在豐富了特征信息同時,有效縮減了網絡訓練參數,通過注意力機制進行特征的篩選,提升有效特征的表達權重,有效提高了表情識別率,網絡模型具有較高的泛化性。
后續將通過生成式對抗網絡進行數據增強,豐富面部表情樣本的多樣性,從而提高表情識別網絡的訓練效率。 對因表情數據類別數據不均衡,導致網絡無法均衡訓練部分參數的現象展開研究,進而提升網絡模型的泛化性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
