基于GF-6WFV影像提取玉米水稻種植信息
2023-01-12 05:58:22郭玉超李榮平任鴻瑞
山東農業大學學報(自然科學版) 2022年5期
郭玉超,李榮平,任鴻瑞*
基于GF-6WFV影像提取玉米水稻種植信息
郭玉超1,李榮平2,任鴻瑞1*
1. 太原理工大學測繪科學與技術系, 山西 太原 030024 中國氣象局沈陽大氣環境研究所, 遼寧 沈陽 110166
玉米、水稻是我國重要的糧食作物,利用遙感技術高效獲取其種植分布信息具有重要作用。GF-6 WFV遙感數據光譜波段較為豐富,空間分辨率較高,能夠為作物遙感分類提供多種類型特征。然而多特征參與分類容易產生數據冗余、降低處理效率。如何優選GF-6 WFV數據豐富的特征信息對于提高分類精度具有重要意義。本文利用GF-6 WFV影像提取光譜特征、無紅邊指數、紅邊指數及紋理特征共26個特征變量,基于所有特征進行優選并采用不同分類方法及不同特征組合識別黑山縣及北鎮市玉米、水稻分布信息。結果表明:采用平均不純度減少與相關系數雙重指標共優選出14個特征,其中紅邊信息占比最大。基于優選特征采用隨機森林法識別玉米、水稻精度最高,其總體精度為94.01%、Kappa系數為0.90,相比優選前分別提高1.14%、0.02。多源特征相對于單一特征能夠改善作物分類效果,提高分類精度。該研究能夠剔除非農田像元影響以高效高精度地提取玉米、水稻,具有可行性、有效性,能夠為國產高分數據在作物遙感識別應用方面提供參考。
高分六號; 農作物; 影像提取
玉米、水稻以其重要的食用價值、飼用價值以及工業用途,在世界上廣泛分布。我國玉米、水稻種植范圍廣、規模大,是國內種植面積分列第一、第二的糧食作物,其生產布局對農業發展及經濟運行具有重要影響。利用遙感資料有效、及時監測玉米、水稻種植分布信息有助于進行產量預測、農業決策,對優化國家作物綜合管理與確保糧食安全具有重大意義。
在遙感影像數據源方面,目前作物提取研究中多采用MODIS[1]、Landsat[2]等中低分辨率數據,中低分辨率的遙感數據覆蓋范圍廣,獲取來源較多,但易存在混合像元以及“同譜異物”或“異物同譜”現象。GF-1 WFV影像數據空間分辨率為16 m,相對于Landsat等數據更適合作物精細分類[3],然而該數據僅包含傳統可見光以及近紅外波段,波段信息具有一定局限性。GF-6衛星于2018年6月發射,是我國首顆具備紅邊波段用于農業觀測的高分衛星,且打破了對國外衛星紅邊遙感影像依賴的局面,在農作物分類方面應用前景廣闊[4]。劉佳等通過對比紅邊與無紅邊條件下玉米、大豆及其他作物分類效果,發現引入紅邊波段能夠改善農作物分類效果[5]。濮毅涵等基于Sentinel-2A紅邊斜率對植被群落進行分類,研究結果表明,光譜紅邊斜率對植被分類應用能力較佳[6]。梁繼等通過提取松嫩平原玉米、大豆、水稻,發現在作物識別中紅邊特征表現優越[7]。已有研究表明,紅邊信息能夠增加不同作物可分性,提高農作物分類精度[5,7]。目前遙感識別研究中,特征類型較為單一,多采用可見光等傳統波段及以NDVI為代表的傳統植被指數,紅邊信息相對較少。
豐富的遙感特征能夠改善地物識別效果,對于提高地物分類精度具有重要應用[8]。然而不同特征間存在相關性,若所有特征參與分類容易產生數據冗余、降低處理效率,故數據降維具有重要意義。但若僅考慮到特征間相關性篩選特征,容易遺漏對農作物分類重要程度高的特征。隨機森林法具有特征重要性評估能力,其自帶的平均不純度減少法能夠計算得到特征重要性[9]。鑒于此本研究擬用一種平均不純度減少與相關系數雙重指標進行特征優選的方法,以優先選擇重要程度較高且冗余信息較少的特征。
為驗證該特征優選法的有效性,本研究基于GF-6 WFV影像構建光譜特征、無紅邊指數、紅邊指數及紋理特征,并對所有剔除非農田像元后的特征進行優選,采用隨機森林法對比優選前與優選后玉米、水稻分類精度。同時為挖掘不同分類方法及不同特征組合對玉米、水稻提取精度影響,基于優選特征共采用3種分類方法及8種特征組合進行對比分析。
1 材料與方法
1.1 研究區概況
本文選擇遼寧省黑山縣及北鎮市作為研究區,該區屬暖溫帶半濕潤氣候,地物復雜多樣,地勢西北高,東南低,自西北向東南依次形成丘陵區、平原區及低洼區。黑山縣耕地面積13.7萬hm2,是全國重點產糧縣;北鎮市耕地面積7.3萬hm2,是全國著名糧食生產基地,玉米、水稻為研究區內主要糧食作物。
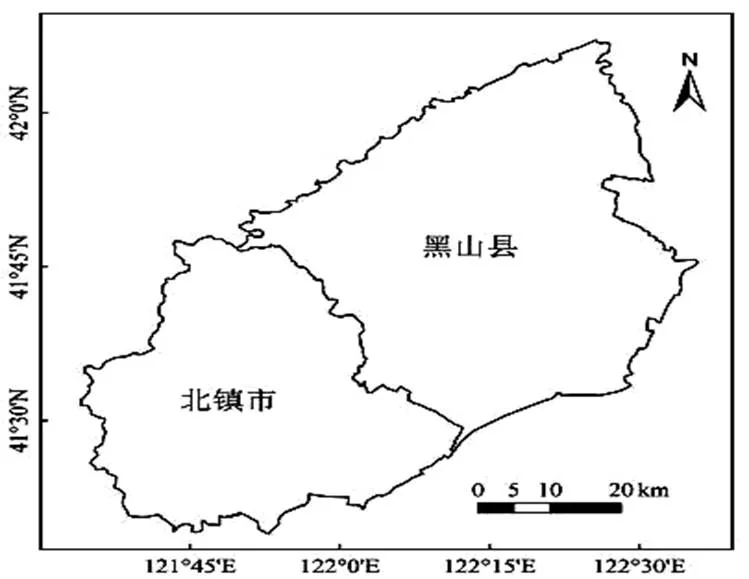
圖1 研究區位置示意圖
1.2 數據獲取及預處理
GF-6 WFV空間分辨率為16 m,共含有8個波段,除藍波段(B1)、綠波段(B2)、紅波段(B3)、近紅外波段(B4)4個傳統波段外,還添加紅邊Ⅰ(B5)、紅邊Ⅱ(B6)兩個紅邊波段及紫波段(B7)、黃波段(B8)。參考研究區作物物候信息及影像質量,選取2020年8月14日2景影像,該時期植被生長旺盛,與非植被光譜差異明顯,各類作物生長穩定、光譜信息豐富,利于不同作物類型提取。對獲取的遙感影像依次進行預處理,包括輻射定標、大氣校正、正射校正、拼接裁剪。
樣本選取參考2017~2019年東北10 m農作物分布產品[10],結合研究區作物物候期與類別特征,分為玉米、水稻、其他作物3類,所需樣本通過借助此產品與Google earth高分辨率影像對遙感影像進行目視解譯,采集樣點時須使選取像元與周圍像元特征一致,以此確保樣本點準確性。經過反復目視糾正最終得到樣本點玉米1249個,水稻431個、其他作物1829個,各類以7:3分別作為訓練與驗證樣本點。
1.3 特征變量計算
本研究提取8個光譜特征、5個無紅邊指數、5個紅邊指數及8個紋理特征共26個特征(表1)。為提高數據利用率,對所有波段進行主成分變換(PCA),對第一主成分通過灰度共生矩陣法(GLCM)提取紋理特征[11]。為清晰反映地物紋理信息,將窗口大小設置為3×3,步長為1,同時為消除不同角度影響,取0°、45°、90°和 135°共4個方向特征平均值作為紋理特征。
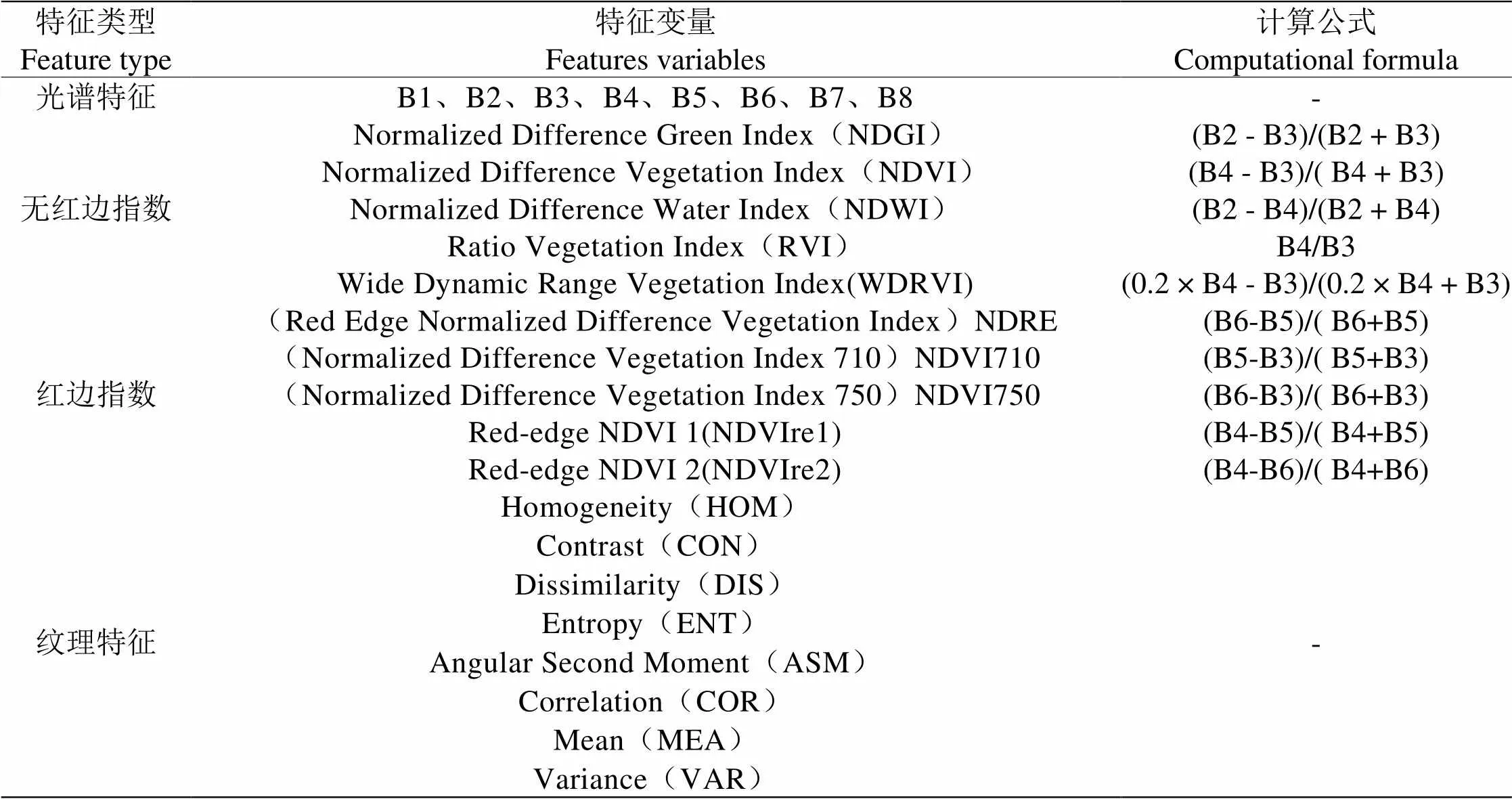
表1 特征變量
1.4 特征優選及分類
對所有特征采用隨機森林算法自帶的平均不純度減少(MDI)指標進行評估[9],在訓練決策樹時能夠得到每個特征基尼不純度減少量,隨機森林通過計算每棵決策樹不純度減少量的平均值作為特征重要性得分。
若樣本集合為,共含有個類別,則基尼指數公式如下:
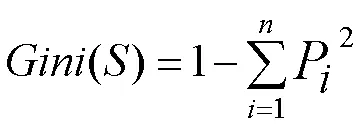
式中:P為中隨機選擇的樣本屬于第類的概率。
若根據某特征結點分裂后,被劃分為1和2,在該特征條件下,結點劃分后基尼指數公式:
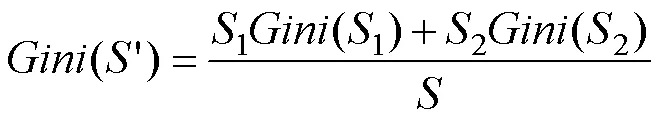
平均不純度減少公式為:
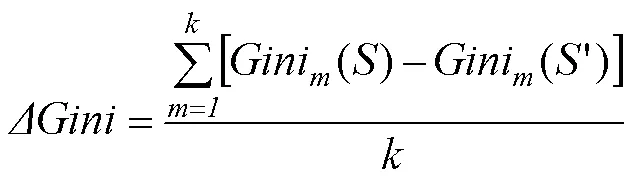
上式中,是決策樹個數,Gini()代表第棵決策樹結點劃分前的基尼指數,Gini()則代表結點劃分后的基尼指數。某特征劃分后平均不純度減少程度越大,則該特征重要性程度越高,在分類時此特征發揮作用越強。
對所有特征進行相關性分析,特征之間相關系數越高,則重復信息越多。通過統計特征間相關系數,以選擇相關性低的特征變量。
結合特征重要性得分及相關系數篩選特征集參與后續農作物分類,分類方法有隨機森林法[9]、支持向量機法[12]、最大似然法。其中隨機森林法設置決策樹個數為100,特征數量為總特征個數的算術平方根。支持向量機法設置核函數為徑向基核函數,Gamma為輸入影像波段數的倒數,懲罰參數為100。
1.5 精度評價
基于驗證樣本對分類結果進行精度評價得到混淆矩陣,根據混淆矩陣計算總體精度、Kappa系數、制圖精度、用戶精度4個指標用以精度分析,確定分類結果準確性。
2 結果與分析
2.1 農田區提取
本研究采用分層提取策略,首先借助2020年10 m全球土地覆蓋數據(ESA WorldCover)構造決策樹規則,該數據耕地編碼為40。另外利用黃波段(B8)篩除部分道路像元以進一步確保農田區域準確性,具體規則如圖2。
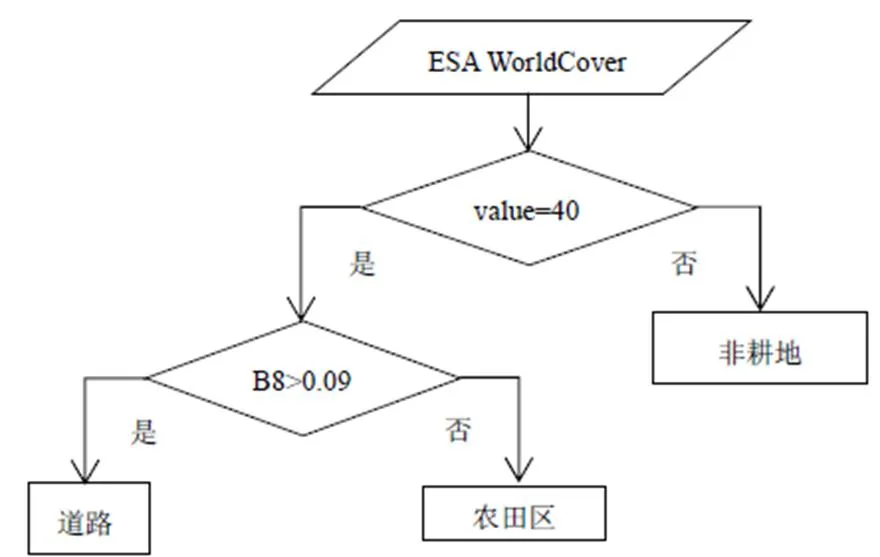
圖2 農田像元提取
2.2 特征優選結果
對所有基于農田區掩膜后的特征變量進行重要性評估(圖3),發現4種特征類型中,紅邊指數重要程度最高,依次為無紅邊指數、光譜特征、紋理特征。
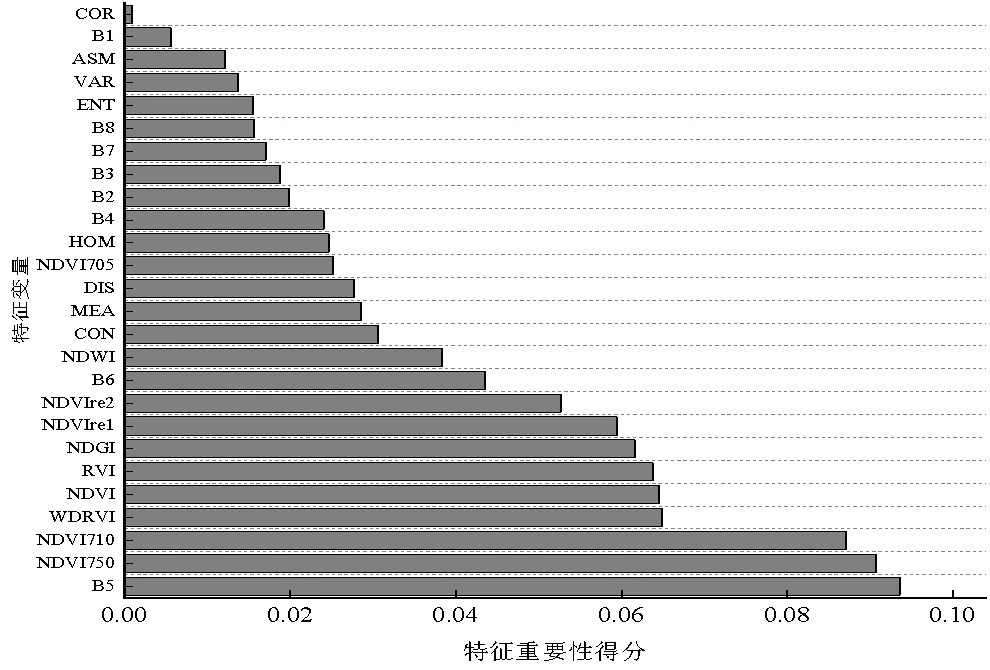
圖3 特征重要性得分
由于影像選取時間位于植被生長中后期,此時玉米與水稻處于穗期,生長旺盛,具有葉片寬厚濃綠、莖桿粗壯等特點。紅邊波段是指示植被生長狀況的敏感波段,與葉綠素含量、葉面積指數等生長參數具有很好的相關性[13,14],故紅邊波段重要程度高。該期植被葉綠素濃度較高,紅波段吸收易飽和,歸一化植被指數差異主要取決于近紅外波段反射率。相對于近紅外波段,紅邊波段完全處于植被反射率急劇變化的區域,對葉綠素含量更為敏感,因而更能反映出不同植被間光譜細微差別,故基于紅邊波段構建的NDVI750、NDVI710重要性得分更高。該期NDVI等指數易發生飽和,而WDRVI波段構造能夠改善飽和現象,故WDRVI得分較高。研究區內不同作物植被覆蓋分布不均,RVI適用于不同程度植被覆蓋情況[15],且與作物生長參數相關性緊密,故該指數重要性排名靠前。此時各作物生長較為穩定,在空間分布上表現出一定規則性與密集性,相同類內紋理特征較為均勻,不同類別間紋理則表現出一定差異性,故紋理特征中能夠體現圖像差異性的CON重要性得分較高。
通過相關性分析得到相關系數圖(圖4),結合重要性得分依次從高到低篩選特征。B5、NDVI750、NDVI710得分占比前27.15%,且相關系數均低于0.9,故保留。WDRVI、NDVI、NDVIre1、NDWI、NDVI705與NDVI750相關系數均大于0.9,故均剔除。RVI、NDGI、NDVIre2、B6在重要性排序中位列前10,且與其它特征相關性偏低,故均保留。其余紋理特征中,MEA與B6相關系數高達0.98,故舍棄MEA;DIS與HOM相關性偏高,而DIS重要性得分高于HOM,故僅保留DIS;ENT與ASM相關性偏高,而ASM重要性得分偏低,故剔除ASM;CON、VAR、COR與其它特征相關系數均低于0.9,故全部保留。剩余光譜特征中,B4與B6相關系數高達0.97,故剔除B4;B2重要性得分高于B3、B7、B8、B1,而B3、B8、B1與B2相關系數均在0.9以上,故保留B2、B7。最終優選特征為:B5、NDVI750、NDVI710、RVI、NDGI、NDVIre2、B6、CON、DIS、B2、B7、ENT、VAR、COR。
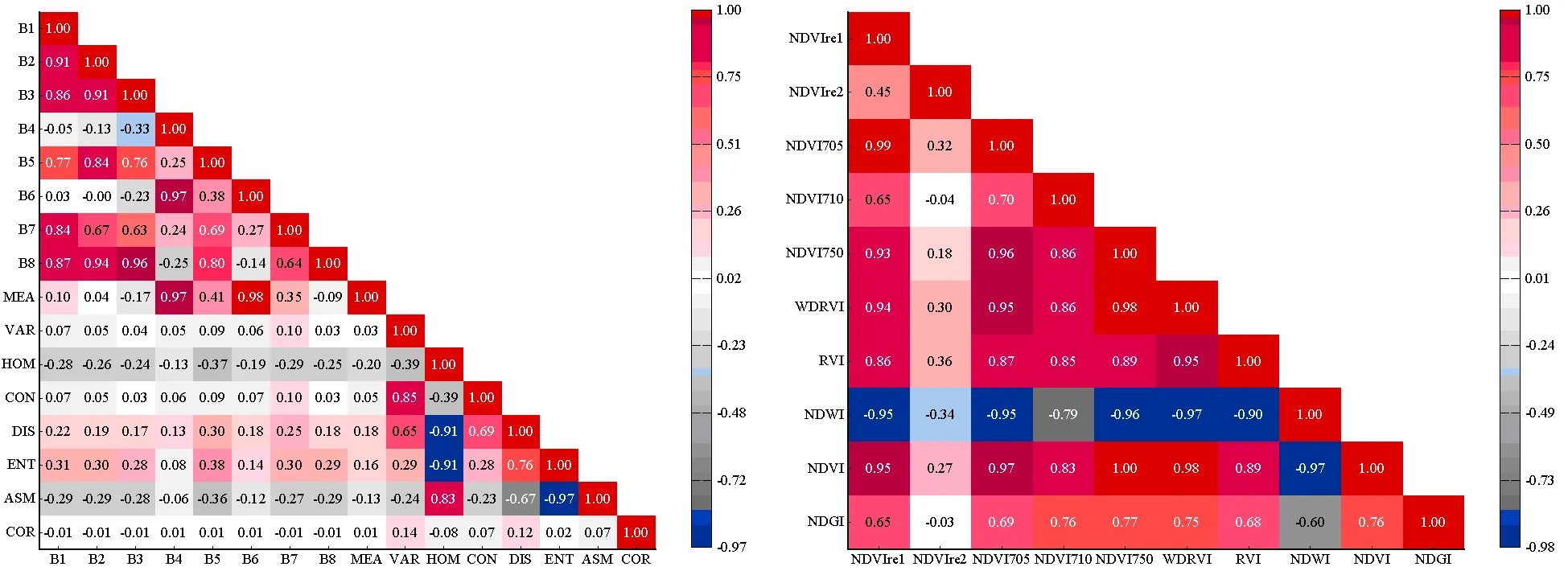
圖4 特征相關系數圖
2.3 不同分類方法結果對比
利用14個優選特征采用不同分類法進行作物提取,并采用驗證樣本進行精度檢驗(表2)。由表2可知,隨機森林法提取作物總體精度與Kappa系數最高,分別達到94.01%、0.90。相較于支持向量機與最大似然法,其總體精度分別提高1.34%、2.69%,Kappa系數分別提高0.02、0.05。同時利用隨機森林法基于優選前特征進行分類,發現優選后較未優選總體精度提高1.14%,Kappa系數提高0.02。
對比優選特征下不同方法分類結果(圖5),可以看出,隨機森林法提取玉米、水稻效果最好,該法玉米圖斑椒鹽現象較少,水稻圖斑更為規則、完整,作物錯分漏分現象少。支持向量機提取的水稻地塊完整度低,且存在將其他作物錯分為玉米現象。最大似然法作物圖斑更為破碎,錯分現象嚴重。不同算法識別作物原理不同,導致提取精度存在一定差異。隨機森林法采用多決策樹的投票結果作為最終結果,能夠保證較高精度;支持向量機利用有限的樣本信息進行分類,在部分作物光譜混淆區域存在錯分現象;最大似然法需假定樣本數據符合正態分布,然而實際應用中數據不一定服從正態分布,從而導致分類結果有所偏差,不能滿足作圖精細化需求。由圖5可知,黑山縣玉米種植范圍較廣,主要分布于無梁殿鎮、薛屯鄉等中部區,水稻種植集中分布于二道鄉,另外新興鎮等地區也有少量種植;北鎮市玉米種植較少,主要分布于柳家鄉等東部地區,水稻則主要分布于新立鄉、青堆子鎮、窟窿臺鎮等東南部地區。

表2 不同分類方法精度評價表
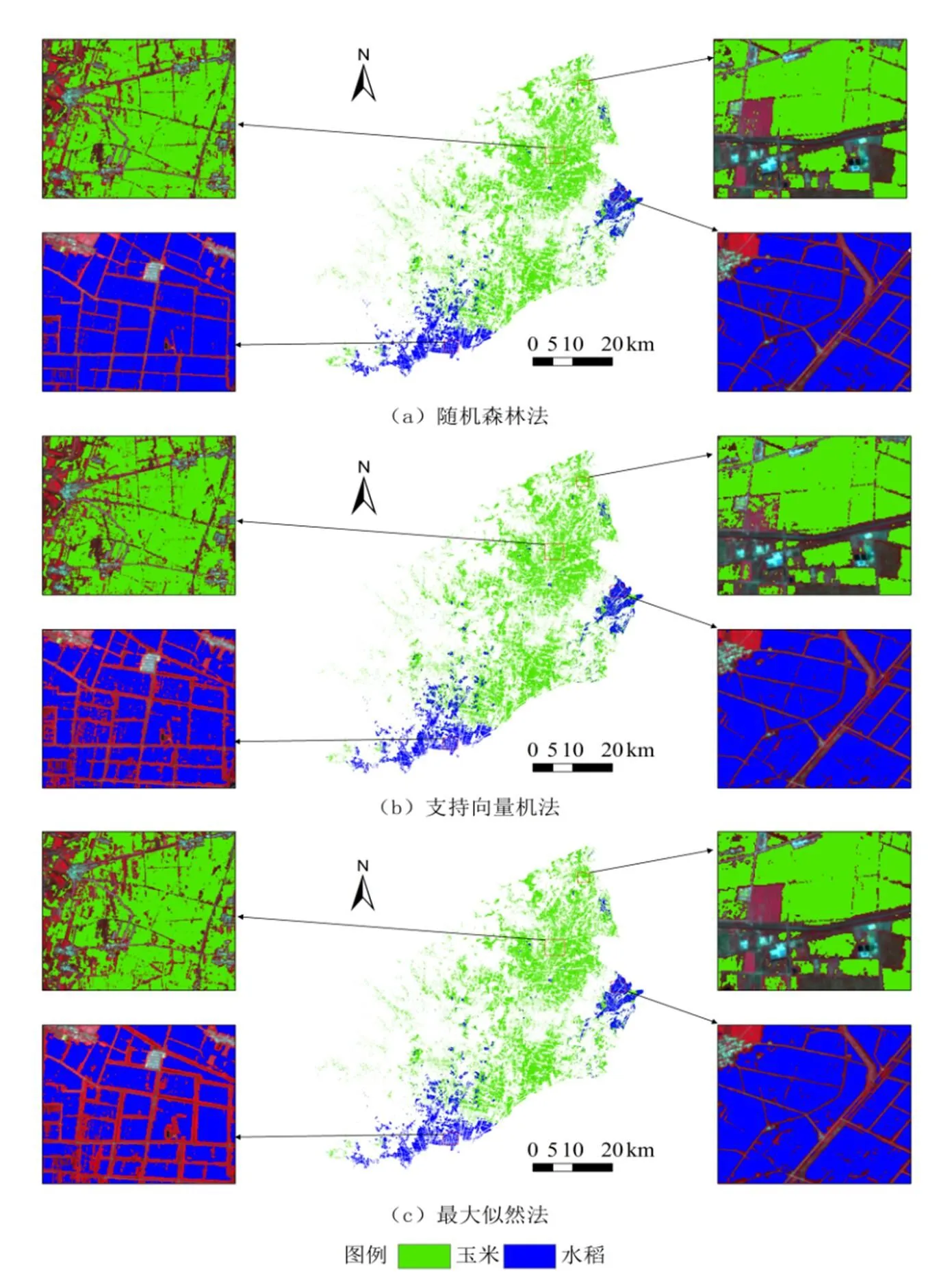
圖5 不同分類方法作物局部識別效果對比圖
2.4 不同特征組合分類結果對比
為深入挖掘各特征對作物分類精度影響,基于14個優選特征共構建8種組合并使用隨機森林法進行分類,根據精度評定表(表3)可知,僅使用光譜特征作物分類總體精度與Kappa系數在所有方案中最低。當在光譜特征上單獨或同時添加無紅邊指數、紅邊指數、紋理特征時,發現總體精度均在91%以上,Kappa系數均達到0.86。這表明GF-6 WFV多源特征相對于單特征能夠提供更為豐富的特征信息,極大程度地改善作物分類精度。
根據不同特征組合分類結果圖(圖6),發現僅利用光譜特征提取玉米、水稻椒鹽現象較為明顯,且不能很好地識別田塊,識別作物結果多為大片連續區域。添加紋理特征后,對作物田塊間田埂的識別能力提高,但接近田埂的田塊作物像元易產生錯分。指數特征引入能夠有效減少作物錯分漏分現象,使得田塊更為規則、完整,且紅邊指數區分各作物能力相比于無紅邊指數更強,能夠更為準確地識別出玉米、水稻。故所有特征組合提取玉米、水稻精度達到最高,既能區分出田埂,又可保證作物田塊較為完整。
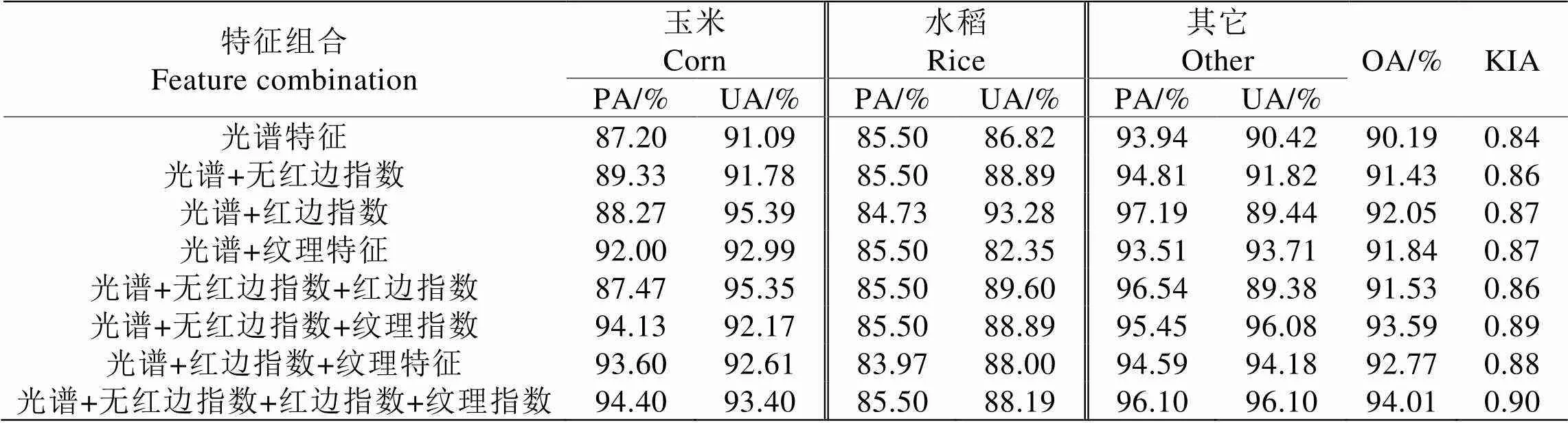
表3 不同特征組合分類精度表
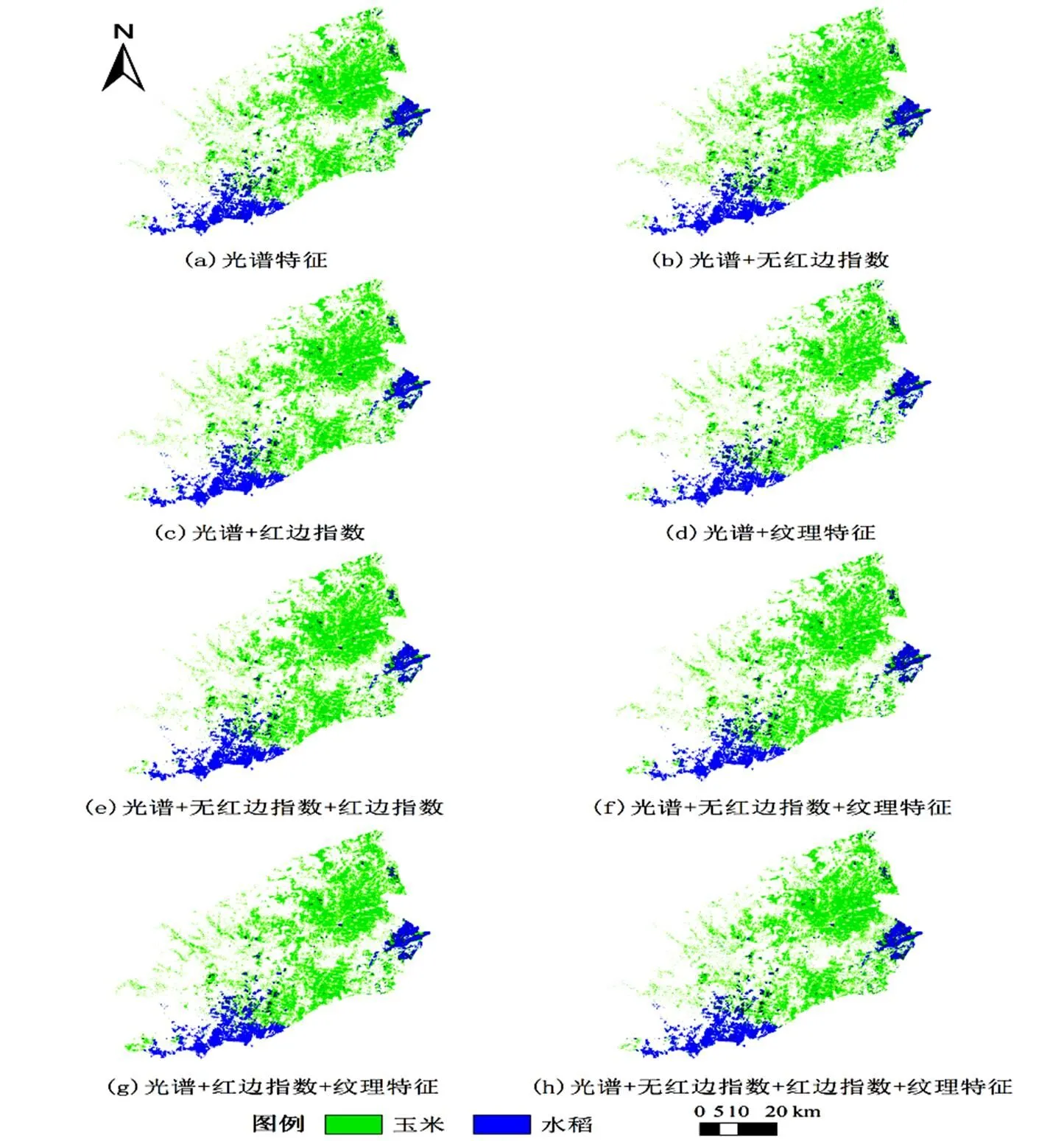
圖6 不同特征組合分類結果圖
3 結論
本文以黑山縣及北鎮市作為研究區,基于GF-6 WFV遙感影像提取黑山縣與北鎮市玉米、水稻種植區,結論如下:
(1)構建決策樹規則提取農田像元時,新增黃波段在區分植被與建設用地方面表現良好,2020年ESA WorldCover數據有助于非農田像元剔除且能夠保證農田區域完整性;
(2)對于玉米、水稻提取,特征貢獻程度從高到低依次為紅邊指數、無紅邊指數、光譜特征、紋理特征,其中B5、NDVI750、NDVI710位列前3;
(3)相對于無紅邊指數與紅邊指數,光譜、紋理特征間冗余信息較少,而紋理特征MEA與光譜特征B4、RE2相關性較高;
(4)采用平均不純度減少與相關系數雙重指標共篩選出14個特征:B5、NDVI750、NDVI710、RVI、NDGI、NDVIre2、B6、CON、DIS、B2、B7、ENT、VAR、COR,發現紅邊信息占比最大;
(5)基于優選特征采用隨機森林法的作物分類精度最高,總體精度為94.01%,相對于優選前總體精度提高1.14%。相較于支持向量機、最大似然法,其總體精度分別提高1.34%、2.69%;
(6)GF-6 WFV紋理特征在一定程度上有助于區分田埂與田塊。紅邊指數則在保證作物田塊完整性,有效識別玉米、水稻方面突出。光譜特征、紅邊指數、無紅邊指數、紋理特征結合相對于單特征能夠有效減少作物錯分漏分現象,提高分類精度。
[1] 朱彤,張學霞,王士遠,等.基于物候特征和混合光譜信息的春玉米種植面積提取[J].沈陽農業大學學報,2017,48(3):328-337
[2] 李曉慧,王宏,李曉兵,等.基于多時相Landsat 8 OLI影像的農作物遙感分類研究[J].遙感技術與應用,2019,34(2):389-397
[3] 黃健熙,侯矞焯,蘇偉,等.基于GF-1 WFV數據的玉米與大豆種植面積提取方法[J].農業工程學報,2017,33(7):164-170
[4] 張悅琦,李榮平,穆西晗,等.基于多時相GF-6遙感影像的水稻種植面積提取[J].農業工程學報,2021,37(17):189-196
[5] 劉佳,王利民,滕飛,等.RapidEye衛星紅邊波段對農作物面積提取精度的影響[J].農業工程學報,2016,32(13):140-148
[6] 濮毅涵,張棟,徐丹丹,等.Sentinel-2A紅邊波段對湖濱帶植被分類能力的評估[J].林業資源管理,2021(2):131-139
[7] 梁繼,鄭鎮煒,夏詩婷,等.高分六號紅邊特征的農作物識別與評估[J].遙感學報,2020,24(10):1168-1179
[8] 劉通,任鴻瑞.GEE平臺下利用物候特征進行面向對象的水稻種植分布提取[J].農業工程學報,2022,38(12):189-196
[9] Breiman L. Random Forests [J]. Machine Learning, 2001,45(1):5-32
[10] You NS, Dong JW, Huang JX,The 10-m crop type maps in Northeast China during 2017–2019 [J]. Scientific Data, 2021,8:41
[11] Haralick RM, Shanmugam K, Dinstein IH. Textural features for image classification [J]. IEEE Transactions on Systems, Man, and Cybernetics, 1973,3(6):610-621
[12] Vapnik V. The Nature of Statistical Learning Theory [M]. Springer, 1999
[13] Ren HR, Zhou GS. Estimating above ground green biomass in desert steppe using band depth indices [J]. Biosystems Engineering, 2014,127:67-78
[14] 蘇偉,侯寧,李琪,等.基于Sentinel-2遙感影像的玉米冠層葉面積指數反演[J].農業機械學報,2018,49(1):151-156
[15] 王李娟,孔鈺如,楊小冬,等.基于特征優選隨機森林算法的農耕區土地利用分類[J].農業工程學報,2020,36(4):244-250
Extraction Planting Information of Corn and Rice Based on GF-6 WFV Image
GUO Yu-chao1, LI Rong-ping2, REN Hong-rui1*
1.0300242.110166
Corn and rice are important grain crops in China, and it is important to use remote sensing technology to obtain planting distribution information efficiently. The spectral bands of GF-6 WFV data are relatively abundant and have high spatial resolution, which can provide multiple types of features for crop remote sensing classification. However, multi-feature classification tends to produce data redundancy and reduce processing efficiency. How to optimize the feature information of GF-6 WFV data is of great significance to improve the classification accuracy. In this study, GF-6 WFV data were used to extract 26 features, including spectral features, non-red edge index, red edge index and texture features. Based on all features, different classification methods and feature combinations were used to identify the distribution information of corn and rice in heishan County and Beizhen city. The results showed that: 14 features were optimized by using the double metrics of mean decrease impurity and correlation coefficient, among which the red edge information accounted for the largest proportion. Based on the optimized features, the random forest method had the highest accuracy in identifying corn and rice, the overall accuracy was 94.01% and kappa coefficient was 0.90, which were 1.14% and 0.02 higher than before optimization, respectively. Compared with single feature, multi-source features can improve the accuracy of crop classification. This study can eliminate the influence of non-farmland pixels to efficiently and accurately extract corn and rice, which is feasible and effective, and can provide a reference for Chinese satellite in the application of crop remote sensing recognition.
GF-6; crop; image extraction
TP79/S127
A
1000-2324(2022)05-0685-08
2022-03-10
2022-04-02
山西省省籌資金資助回國留學人員科研項目(2022-055);中國氣象局沈陽大氣環境研究所聯合開放基金課題資助(2021SYIAEKFMS39)
郭玉超(1999-),女,碩士研究生,主要研究方向為植被遙感. E-mail:guoyc98@163.com
通訊作者:Author for correspondence. E-mail:renhongrui@tyut.edu.cn
猜你喜歡
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
軍事文摘(2021年22期)2021-11-26 00:43:51
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
文苑(2020年6期)2020-06-22 08:41:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
文苑(2019年22期)2019-12-07 05:29:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
