基于流模型的缺失數據生成方法在剩余壽命預測中的應用
2023-01-16 07:36:28張博瑋鄭建飛胡昌華
自動化學報 2023年1期
關鍵詞:模型
張博瑋 鄭建飛 胡昌華 裴 洪 董 青
對于鋰電池、軸承、航空發動機和陀螺儀等復雜關鍵設備,由于受到內部應力或外界環境的影響,其設備的健康狀態會不可避免的出現退化,最終引發設備及所在系統的失效,甚至導致人員和財產的損失[1-2].為切實掌握設備的健康性能,保障設備安全可靠運行,預測與健康管理 (Prognostics and health management,PHM) 技術[3-4]近年來受到了廣泛關注.作為PHM 技術的關鍵環節,剩余壽命(Remaining useful life,RUL) 預測旨在通過分析狀態監測收集的退化數據,來預測設備的剩余壽命.隨著先進傳感、物聯網技術的進步和監測工藝的發展,當代設備復雜化、自動化以及智能化水平不斷提升,推動數據驅動的剩余壽命預測技術進入了 “大數據”時代.
在工程實際中,由于機器故障 (如測量傳感器故障) 或人為因素 (如未記錄) 不可避免地導致部分數據缺失[5-7].若利用這類不完整數據預測設備剩余壽命,將面臨難以準確描述設備退化規律的現實問題,進而將影響設備的健康管理和維修決策.因此,針對缺失數據統計特性的多樣性隨機退化設備剩余壽命預測問題得到了大量學者的關注.
隨著深度神經網絡在計算機視覺、密度估計、自然語言和語音識別等領域的興起[8],深度生成模型[9]開始應用于時間序列的生成,其基本思路是通過捕捉時間序列的分布特征,對時序數據進行再生成,從而填補數據.Yoon 等[10]首次提出了一種基于生成式對抗網絡 (Generative adversarial network,GAN) 框架的缺失數據輸入方法獲得了較好的填充效果.張晟斐等[11]基于柯爾莫可洛夫—斯米洛夫檢驗 (Kolmogorov-Smirnov test,K-S test) 檢驗的思想,改進卷積生成對抗網絡 (Deep convolutional generative adversarial network,DCGAN),獲得了更高精度的生成結果,但是存在生成器和判別器模式崩潰、難以訓練的風險.Nazabal 等[12]融合基本的變分自編碼器 (Variational autoencoder,VAE)和高斯過程,利用變分推斷在多維時間序列填充問題上得到了更理想效果.在基于深度學習的框架下,現有研究集中在GAN和VAE 的改進和優化方面.根據處理極大似然函數方法的不同,GAN 采用網絡對抗和訓練交替的方式,避免優化似然函數,雖然生成精度高但是訓練過程困難,VAE 采用似然函數的變分下界代替真實的數據分布,只能得到真實數據的近似分布.因此,亟需研究一種既能保證模型精度又容易訓練的深度生成模型.
近年來,為了克服模型精度和訓練速度方面的局限性,可逆網絡構造似然函數的流模型 (Flowbased model,Flow) 及改進模型[13-16]被應用于圖像、音頻生成領域效果顯著.其中,非線性獨立成分估計(Non-linear independent component estimation,NICE) 是首個基于Flow 模型的變體[13].針對完整的一維時序數據生成問題,Ge 等[17]提出了一種基于NICE 框架的生成網絡來模擬配電網絡的一維日常負載曲線.相比于GAN 與VAE,NICE 的生成效果能夠更好地捕捉日常負載曲線的時空相關性.薛陽等[18]提出了基于NICE 框架的生成網絡來增強分布式光伏竊電數據曲線,通過對比GAN 與VAE的生成效果,NICE 具有準確的似然估計,生成的樣本更接近真實數據曲線.盡管NICE 面向完整時序數據時表現出良好的生成效果,但應用于缺失時序數據情形下的數據生成則鮮見報道.因此,如何利用NICE 挖掘出缺失數據的演變規律,以克服傳統GAN和VAE 所面臨的模型精度較低以及訓練速度過慢的難題,是有待進一步研究的重要問題.同時,訓練過程中如何優化NICE 模型參數是影響生成效果的關鍵因素,需予以重點考慮.
本文依靠NICE 網絡的生成優勢,提出了一種改進NICE 網絡的缺失數據生成方法.該方法充分利用NICE 強大的分布學習能力,通過粒子群優化(Particle swarm optimization,PSO) 算法,將生成序列與真實序列之間的分布偏差融入NICE 采樣生成樣本的退火參數中,在提升訓練速度的同時保證生成序列與真實序列的一致性.在此基礎上,本文利用融合注意力機制的雙向長短期記憶網絡 (Bidirectional long short term memory with attention,Bi-LSTM-Att),建立了設備退化趨勢預測模型進行剩余壽命預測.最后,通過鋰電池的退化數據,對所提方法生成數據和預測數據的可靠性進行實例驗證.
1 基于PSO-NICE 的數據生成
1.1 流模型
流模型的基本思路是:復雜數據分布一定可以由一系列的轉換函數映射為簡單數據分布,如果這些轉換函數是可逆的并且容易求得,那么簡單分布和可逆轉換函數的逆函數便構成一個深度生成模型.
具體地,流模型假設原始數據分布為PX(x),先驗隱變量分布為PZ(z) (一般為標準正態分布),可逆轉換函數為f(x) (z=f(x)),生成轉換函數為g(x)(g(x)=f-1(x)),基于概率分布密度函數的變量代換法可得:
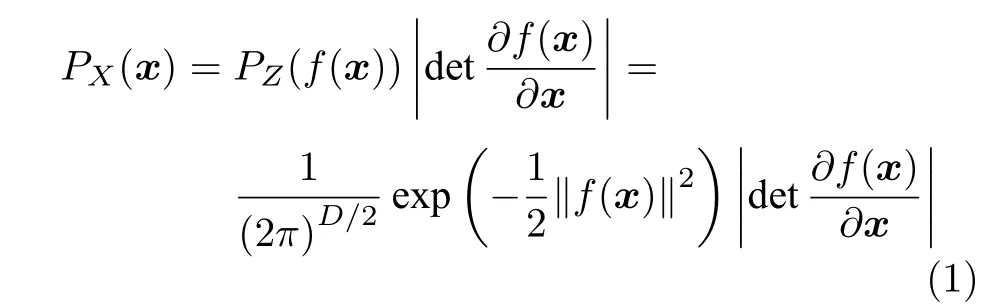
其中,D是原始數據的維度,是可逆轉換函數f(x) 在x處的雅可比行列式 (Jacobian),而更高維度的監測數據會增加Jacobian 的計算復雜度,導致模型擬合的負擔多于求解可逆函數的反函數的過程.因此,流模型除了轉換函數f(x) 可逆易求外,還需確保其Jacobian 易于計算.基于最大對數似然原理,流模型的訓練優化目標為:

當流模型訓練過程結束時,通過采樣概率分布Z~PZ(z)得到隨機數,其中采樣分布一般為標準正態分布,然后通過可逆轉換函數的反函數g(z)=f-1(z)生成新的數據分布.從生成模型的出發點來看,流模型可以提供精確的估計,能夠生成高質量的樣本.
NICE 是首個基于流模型的無監督深度神經網絡生成模型[13].其優勢在于能夠得到精確的對數似然估計,易于訓練,且基于可逆操作無需單獨構建生成網絡,它與訓練網絡共享同一套參數,最后從標準正態分布中采樣隨機數來生成樣本.然而,實際上對于訓練好的NICE 模型,采樣標準差并不一定是1,因為更小的方差可以通過犧牲樣本多樣性增加樣本真實性,所以理想的采樣標準差一般比1稍小.最終采樣的正態分布標準差,被稱為退火參數[19].因此,當NICE 深度生成模型處理時間序列樣本時,選擇合適的退火參數是決定生成樣本精度高的關鍵性因素.
1.2 PSO-NICE 模型
為了降低NICE 模型生成分布與原始分布的偏差,利用粒子群優化 (PSO) 算法快速迭代找到退火參數全局最優解,從而改進NICE 反向生成模型.
具體地,PSO-NICE 網絡結構如圖1 所示.NICE 由多個分塊加性耦合層 (交錯混合方式)和一個尺度壓縮層組成,每一個分塊加性耦合層模擬一個可逆變換函數f(x),通過交錯混合來連接兩個相鄰的分塊加性耦合層.如圖1 所示,按照向右箭頭的方向為正向訓練過程,向左箭頭的方向為反向生成過程.NICE 作為一類無監督向量變換模型,能夠確保將輸入數據的分布轉化為標準正態分布,在反向生成時,從標準正態分布中采樣隨機數來生成樣本,采用PSO 來對退火參數進行優化,提升NICE模型的反向生成能力.
以圖1 為例,分別介紹分塊加性耦合層、交錯混合和尺度壓縮層的結構和參數.

圖1 PSO-NICE 網絡框架圖Fig.1 PSO-NICE network frame diagram
NICE 通過分塊加性耦合層來擬合可逆變換函數f(x). 具體地,將維度為D的原始數據輸入樣本劃分為兩部分x1和x2,不失一般性,將x的各個維度打亂后重新排列,選取x1=x1:d為前d維元素組成的向量,x2=xd+1:D為后 (D-d) 維元素組成的向量,并作如下變換:


其中,Id和Id+1:D分別表示d維單位矩陣和(D-d)維單位矩陣,根據分塊矩陣的結構,由式 (5) 可以得到J(f(x)) 是一個下三角矩陣形式,并且對角線元素全部為1.分塊加性耦合層巧妙的設計不僅使得變換函數的逆函數易于求解,而且它的Jacobian 結果固定為1.
NICE 通過交叉耦合來連接兩個相鄰的分塊加性耦合層,將分塊加性耦合層1 輸出的兩部分直接交換作為分塊加性耦合層2 的輸入:

由式 (6) 知,分塊加性耦合層的耦合操作只作用在第二部分,第一部分是恒等的變換.交錯混合的操作簡單,即前一個分塊加性耦合層等價變換的向量可以在下一個分塊加性耦合層進行非等價變換,可使信息充分融合.

其中,s各元素是要訓練優化的非負參數向量,可識別維度的重要程度 (其大小決定了維度的重要程度),起到壓縮流形的作用.代入上一節流模型的優化目標式 (2),NICE 模型的訓練優化目標為:
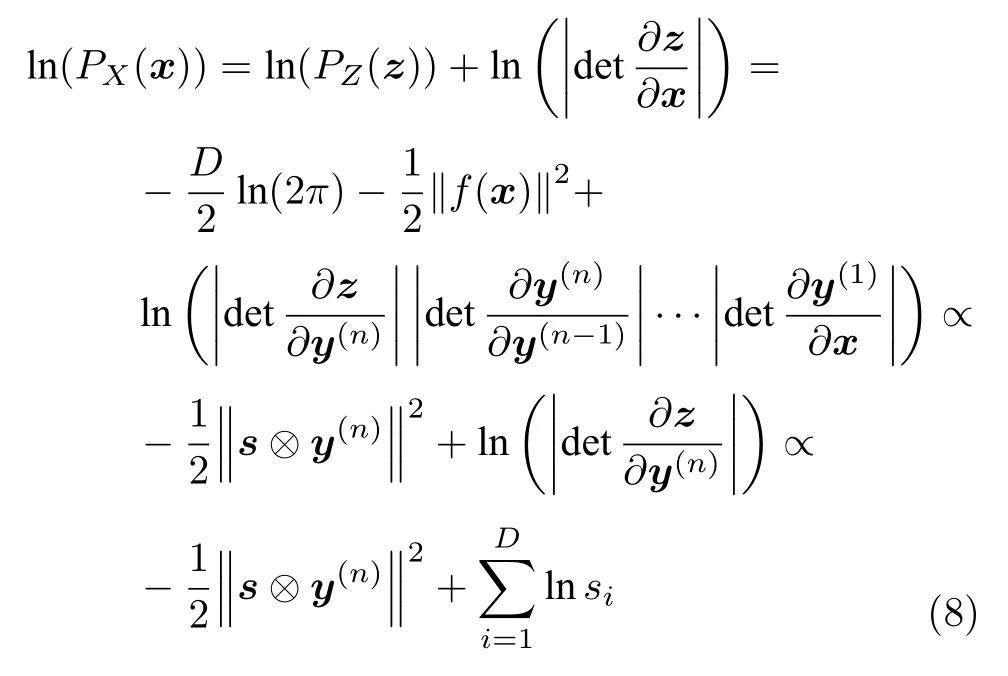
上述優化目標即為NICE 模型訓練的損失函數,經過堆疊多個分塊加性耦合層和一個尺度壓縮層,在流模型的框架下,降低了可逆函數的反函數和Jacobian 的計算復雜度,NICE 完成了網絡構建.
在NICE 網絡基礎上,PSO 首先初始化一群隨機粒子 (隨機解),每個粒子的維度與原始樣本保持一致,退火參數初始化為1,然后通過迭代找到最優解.在每一次的迭代中,粒子通過跟蹤兩個 “極值”(個體最優值pbest,群體最優值gbest) 實現更新.PSO 的標準形式如下:

其中,i=1,2,···,N,N是粒子群中粒子的總數,vi是粒子的速度,rand() 是介于 ( 0,1) 之間的隨機數.vi是粒子當前的速度,xi是粒子當前的位置,c1和c2是學習因子,一般c1=c2.vi的最大值為vmax(通常大于0),如果vi大于vmax,則vi=vmax.
PSO 的優化目標選擇生成分布與原始分布的推土機 (Earth-mover,EM) 距離,又稱Wasserstein 距離.EM 距離相對KL 散度與JS 散度的優勢在于平滑性更好,即使對兩個分布很遠幾乎無重疊的情況,仍能反映兩個分布的遠近.該優點可保證PSO 迭代過程的初始階段能夠快速收斂.EM 距離越小,表明生成分布與原始分布越接近.EM 距離可表示為:

其中,Π (P1,P2) 是P1和P2分布組合起來的所有可能的聯合分布的集合.對于每一種可能的聯合分布γ,可從中采樣 (x,y)~γ得到一個樣本x和y,并計算出該對樣本的距離‖x-y‖,進而可計算該聯合分布γ下,樣本對距離的期望值 E(x,y)-γ[‖x-y‖].在所有可能的聯合分布中能夠對這個期望值取到的下界即為EM 距離.
綜上,在NICE 反向生成過程引入PSO,優化采樣分布的退火參數,可以充分利用流模型的可逆生成模型,增加對生成結果的反饋,提升網絡模型的生成效果.
2 基于Attention 的Bi-LSTM 的RUL預測
雙向長短期記憶網絡 (Bi-LSTM) 通過堆疊前向LSTM 層和后向LSTM 層,來提取序列的深度特征.與單個LSTM 層相比,能夠充分利用監測數據過去與未來的潛在信息.反映設備退化信息的長時間序列在輸入Bi-LSTM 網絡時會通過滑動時間窗處理劃分為時間步Xi對應的短序列,而不同時間步的短序列所蘊含的設備退化特征往往不同.
為了捕捉對預測結果貢獻度較高的特征,引入注意力機制 (Attention) 層,將對預測結果貢獻度高的特征賦予更高的權重,貢獻度低的特征賦予較低的權重,對Bi-LSTM 的提取后的特征進行再次融合.
具體地,融合注意力機制的雙向長短期記憶網絡Bi-LSTM-Att 結構如圖2 所示,X1,X2,X3,···,Xn為一組輸入隨機退化的監測數據經過滑動時間窗處理后的短時間序列,前向LSTM 層和后向LSTM 層對輸入的短時間序列進行前向和后向的特征提取得到隱藏狀態yi=[y1,y2,y3,···,yn],Attention 層對提取的特征分配不同的權重ai=[a1,a2,a3,···,an],最后連接一個全連接層,得到預測結果y.Attention 層的計算過程如下:
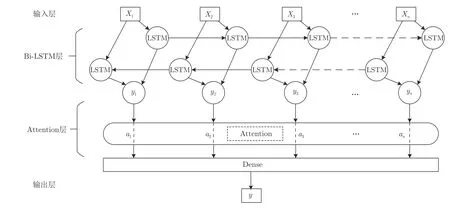
圖2 Bi-LSTM-Att 網絡框架圖Fig.2 Bi-LSTM-Att network frame diagram

其中,t anh(·) 為非線性激活函數,其范圍為 (-1,1),Wi和bi分別為隱藏狀態yi=[y1,y2,y3,···,yn] 的權值矩陣和偏置矩陣,ai為Attention 層分給不同隱藏狀態的權重,y為對所有隱藏狀態加權求和后得到的綜合特征.
綜上,在Bi-LSTM 層后引入Attention 層,對不同的退化特征有不同的側重,可以充分利用每個時間步的隱藏狀態,提取有用信息,提升網絡模型的預測效果.
3 基于PSO-NICE 缺失數據生成的RUL預測
基于PSO-NICE和Bi-LSTM-Att 的監測缺失數據生成和RUL 預測方法流程如圖3 所示,具體的步驟為:

圖3 缺失數據生成和RUL 預測流程圖Fig.3 Missing data generation and RUL prediction flowchart
1) 樣本各維度歸一化:為了后期深度學習模型能夠高效訓練、挖掘深層次特征,需要對訓練的原始數據進行必要的預處理操作,將含有缺失數據的監測原始退化監測數據每個樣本的各個維度分別線性歸一化到 ( 0,1) 區間,得到PSO-NICE 模型的訓練樣本,反歸一化是歸一化的逆操作,歸一化與反歸一化公式如下:
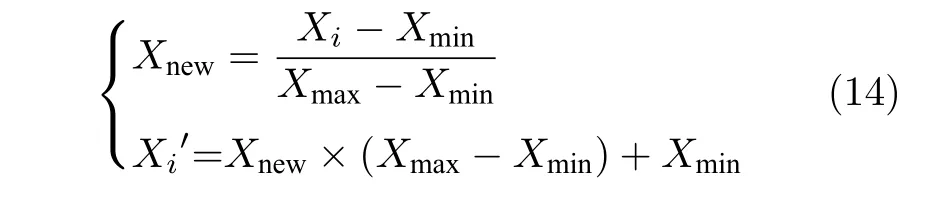
其中,Xmax和Xmin為某個維度樣本的極值 (最大值和最小值),i為樣本個數.
2) 搭建NICE 網絡模型:根據樣本量的大小,配置NICE 正向訓練過程參數.將歸一化后的訓練樣本作為模型的輸入,進行深度無監督學習.
其中,NICE 網絡結構模型參數主要是對分塊加性耦合層的處理,包括分塊加性耦合層的層數,耦合層的數量及其每一層的神經元數量.一般地,以4 個分塊加性耦合層為基礎建立模型,耦合層一般選擇全連接層.隨著輸入數據分布的復雜度提高,由于交叉耦合的處理方式,分塊加性耦合層的數量需要以偶數倍增加.同時,也可以加深耦合層的數量和增加每層神經元的數量來擬合復雜數據的分布.
3) 搭建PSO 迭代模型:引入一群與訓練樣本維度相同的粒子群,對NICE 反向生成過程模型的生成分布效果進行迭代優化,得到NICE 反向生成過程模型最優的退火參數.
其中,粒子的維度即為樣本維度,粒子群的大小應不少于2,初始化的位置和最大速度可以根據優化目標的經驗值設置參數,否則需要更多的迭代次數.最后,通過實驗觀察迭代效果,優化目標趨于穩定時停止訓練,選擇保證訓練效果的最低迭代次數.
4) 缺失數據填補:選擇最優退火參數下正態分布的隨機數,作為NICE 反向生成過程模型的輸入,將模型生成的全部樣本反歸一化到原始樣本的變化區間,將與缺失數據的時間維度最接近的樣本數據作為填補值,與原始數據一起組成完整的退化時間序列樣本.
5) 構建Bi-LSTM-Att 預測模型:將填補后的數據與歷史數據再次線性歸一化,按照Bi-LSTM的輸入格式,進行時間滑動窗口處理,作為Bi-LSTMAtt 的輸入.訓練調整Bi-LSTM-Att 預測模型的結構參數和訓練參數,最后通過迭代預測得到RUL的預測值.
4 實驗與分析
為了驗證本文提出的基于PSO 改進NICE 的缺失數據生成方法和基于Attention 改進Bi-LSTM的RUL 預測方法,本文采用美國馬里蘭大學先進壽命周期工程中心 (Center for Advanced Life Cycle Engineering,Calce) 提供的CS2 類型電池容量退化數據集[6],共包含四塊電池退化數據:CS2_35,CS2_36,CS2_37,CS2_38.這四組電池容量退化的完整曲線如圖4 所示.
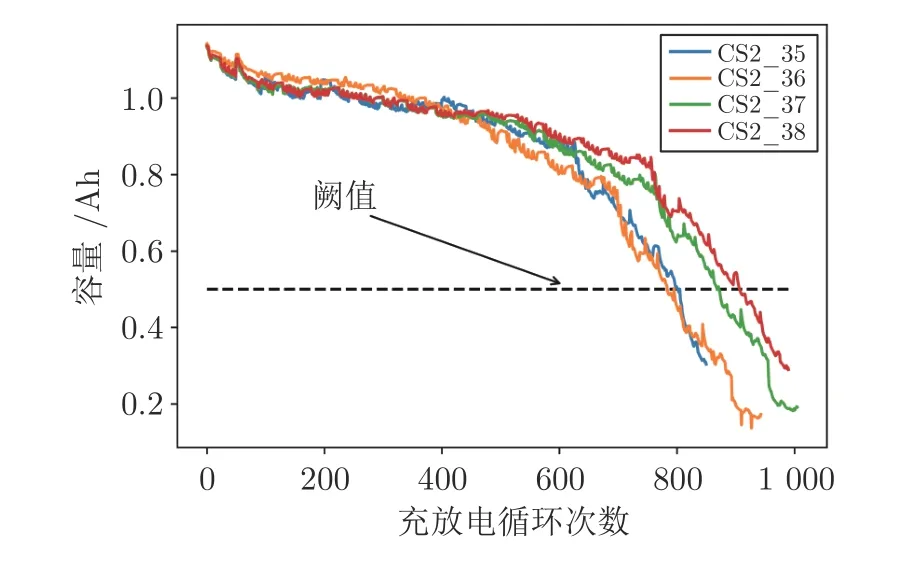
圖4 CS2 電池組容量退化軌跡Fig.4 CS2 battery pack capacity degradation trajectory
圖4 中,電池容量可以有效反映電池健康狀況,實際應用中通常采用在一定充放電條件下電池容量衰減到失效閾值時所經歷的充放電周期次數來描述電池的RUL,因此選擇該指標進行鋰電池RUL 預測.其中,失效閾值選擇0.5 Ah.鋰離子電池的RUL指從當前時刻開始至鋰離子電池容量不能維持設備正常工作所經歷的充放電周期次數.
為確保對比的公正性,本文采用文獻[11] 中DCGAN-KS 模型的缺失數據設置模式.主要體現在缺失機制與缺失率兩個方面,缺失機制設定為完全隨機缺失 (Missing completely at random,MCAR),即數據的缺失概率與缺失變量以及非缺失變量均不相關[20].不同于MCAR,隨機缺失 (Missing at random,MAR) 指的是數據的缺失不是完全隨機的,即該類數據的缺失依賴于其他完全變量.在實際生產過程中,由于設備復雜和環境惡劣,大多缺失類型屬于MCAR.不失個體差異性,生成數據實驗以CS_37 電池為例.缺失率是在CS2_37數據的前850 個充放電循環基礎上,分別選擇10%、30%、50%和70% 四種模式.本文通過調用python 的random 庫,選擇缺失率分別為10%,30%,50%和70% 的sample 函數,用于產生生成模型的訓練數據.由CS2_37 構造的原始數據和訓練數據如表1 所示.
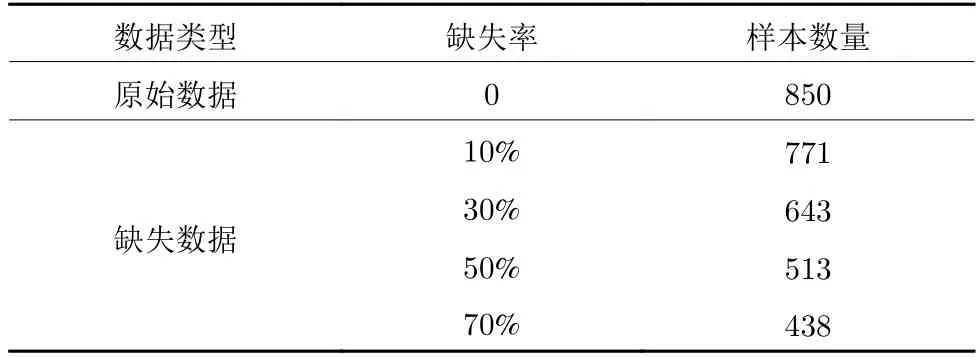
表1 CS2_37 構造的原始數據和不同缺失率下的訓練數據Table 1 Original data constructed by CS2_37 and training data with different missing rates
進一步,根據生成數據設置預測所需的數據集模式,將編號為CS2_35、CS2_36、CS2_38 電池的完整數據和CS2_37 截止到600 個循環周期的容量數據作為訓練樣本,將CS2_37 的600 個循環周期之后的406 個循環周期作為驗證樣本來評估預測性能.由CS2 電池構造RUL 預測的訓練樣本和驗證樣本如表2 所示.

表2 CS2 數據集構造RUL 預測的訓練樣本和驗證樣本Table 2 CS2 dataset constructs training samples and validation samples for RUL prediction
根據本文第3 部分所提方法步驟進行數據生成.將訓練數據歸一化處理后,依次搭建NICE 網絡模型和PSO 迭代模型.其中,隨著缺失率的提高,可以適當減少 (偶數個) 分塊加性耦合層的數量和降低NICE 模型的訓練批處理量.粒子的維度為2(充放電循環維度和容量維度),粒子群大小可以設置為2,通過多次生成實驗選擇保證訓練效果的最低迭代次數為15.表3 給出了不同缺失率下的PSONICE 模型參數.其中,第二、三、四列為NICE 模型的結構參數,第五、六列為NICE 模型的訓練參數,第七、八列為PSO 的訓練參數.

表3 不同缺失率下的PSO-NICE 模型參數Table 3 PSO-NICE model parameters with different missing rates
圖5 展示了70% 缺失率下VAE 模型、GAN模型、NICE 模型和PSO-NICE 模型的生成效果圖.通過對比不難發現,VAE和PSO-NICE 模型生成數據相較于GAN和NICE 模型更平滑,而在數據分布上,NICE和PSO-NICE 模型對原始數據的擬合度更高.總體上,NICE和PSO-NICE 模型兩種方法都可以很好地覆蓋鋰電池容量整個數據的退化趨勢和分布特性,且PSO-NICE 模型生成的數據更接近真實分布.
為研究PSO 算法隨機性優化的效果,圖6 繪制了不同缺失率下PSO 迭代次數的變化.
從圖6 中可以得到,70%和10% 缺失率下的PSO 迭代的優化目標較快穩定,表明缺失率較小或者較大時數據的分布屬性較簡單,PSO 的優化目標更容易收斂.最終,根據缺失率的大小,PSO-NICE模型生成的數據分布與原始數據的分布誤差 (EM距離) 均不同程度穩定在0.02 以下.
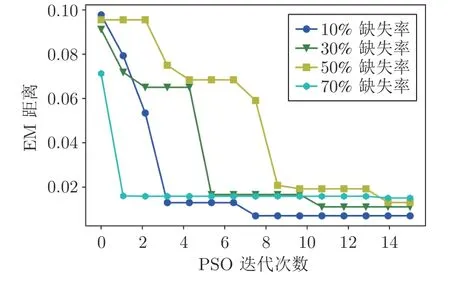
圖6 不同缺失率下PSO 迭代優化過程Fig.6 Iterative optimization process of PSO under different missing rates
進一步,為了與VAE、GAN 及DCGAN[11]的生成效果對比,表4 通過EM 距離量化不同缺失率下各方法生成樣本與完整樣本的誤差.由表4 可見,在不同缺失率下,本文所提方法得到的EM 距離均小于其它方法.并且隨著缺失率的增大,PSO-NICE模型EM 距離的增幅相對較小,表明其生成分布更接近原始分布.

表4 不同缺失率下各方法生成樣本與完整樣本的EM 距離Table 4 The EM distance between generation sample and the complete sample under different missing rates
根據PSO-NICE 模型生成的樣本數據,選擇與缺失值的時間維度最接近的值作為填充值對缺失數據填補,圖7 分別繪制不同缺失率下的填補效果.
由圖7 可見,在10%和30% 低缺失率的情況下,PSO-NICE 模型對缺失數據填補的精確性較高.在50%和70% 高缺失率的情況下,PSO-NICE 模型對缺失數據填補的精確性較低,某些結果與缺失數據有較大差距.總體上,不論缺失率高低,PSONICE 模型的填補效果均可以保持與原始數據分布的一致性.
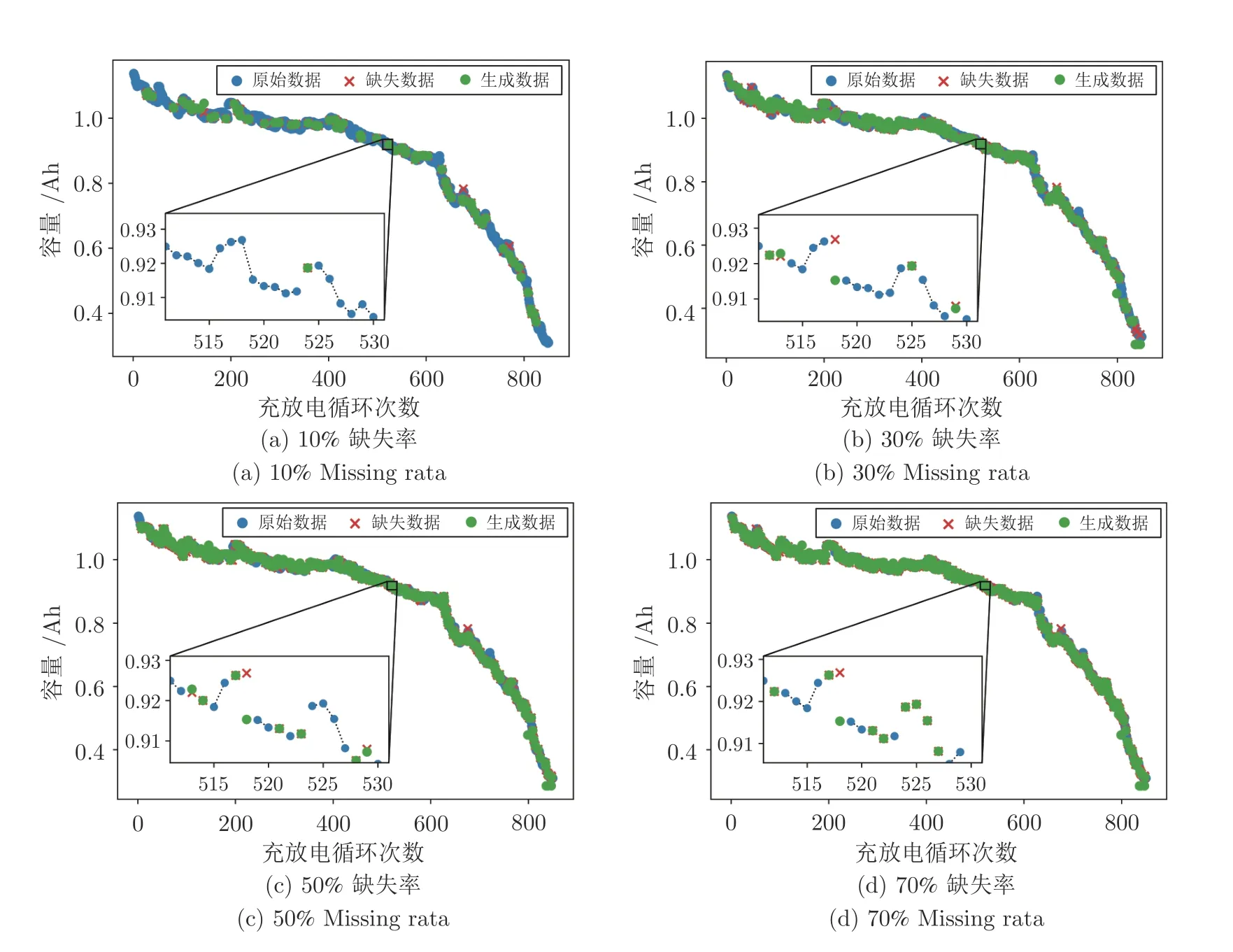
圖7 不同缺失率下的填補效果Fig.7 Generation effect under different missing rate
為驗證預測效果,將PSO-NICE 模型填補后的時序數據按照表2 構造樣本,并且全部時序數據要經過滑動時間窗處理.具體地,滑動時間窗統一設置為200,預測步長為1.針對現有常用預測網絡(RNN、GRU、LSTM、Bi-LSTM和Bi-LSTMAtt 等),損失函數選擇均方誤差 (Mean squared error,MSE),優化器選擇Adam,調整網絡結構和訓練參數使各個方法達到最優,相關結果如圖5 所示.
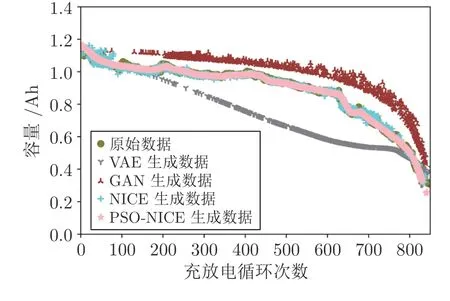
圖5 70%缺失率下不同方法的生成效果Fig.5 The generation effect of different methods under 70% missing rate
表5 分別展示了RNN、GRU、LSTM、Bi-LSTM和Bi-LSTM-Att 等現有常用預測網絡的參數.需要注意地是,每次預測實驗均設置了隨機種子,固定預測結果.訓練好各類網絡后,首先在0%缺失率 (即不缺失) 情況下,從預測起始點迭代預測406 次.預測效果如圖8 所示.
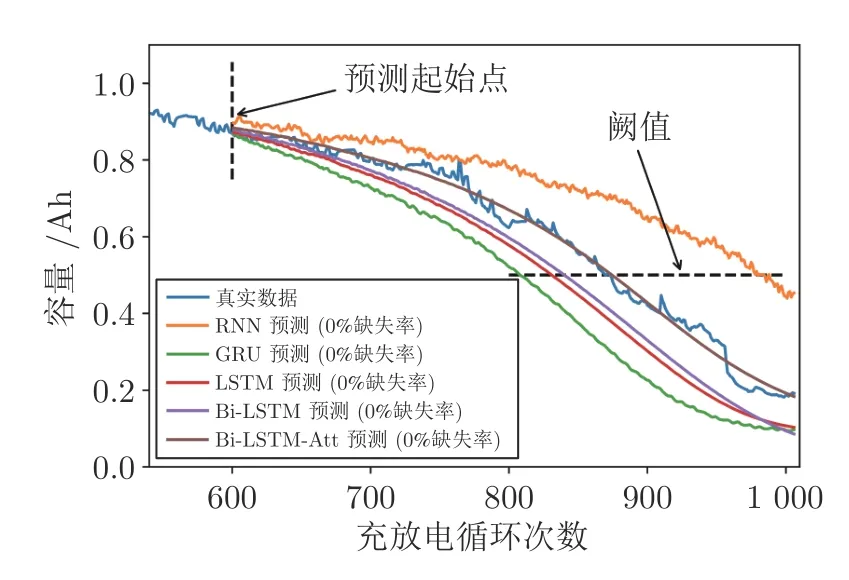
圖8 0%缺失率下現有常用方法的預測效果Fig.8 Prediction effect of existing common methods under 0% missing rate

表5 現有常用預測網絡的參數Table 5 Parameters of existing common prediction networks
由圖8 可見,在0% 缺失率下,對比真實數據,RNN 網絡的退化趨勢差距較大,并且預測結果滯后,GRU、LSTM和Bi-LSTM 網絡的預測退化趨勢較好,但預測結果均提前,Bi-LSTM-Att 的預測結果最接近原始數據,且預測趨勢更吻合.預測對比實驗說明RNN 網絡無法捕獲長距離的信息,而LSTM-based 方法具有長記憶性,能夠獲得比GRU更好的預測效果,增添Attention 層后使得整個預測網絡關注影響退化趨勢的部分重要數據,增加了預測網絡可解釋性.因此,選擇Bi-LSTM-Att 網絡來進行剩余壽命預測.
為研究不同缺失率下的填補效果對剩余壽命預測的影響,以10%、30%、50%和70% 四種缺失率為例,圖9 展示了同一Bi-LSTM-Att 網絡的預測效果.
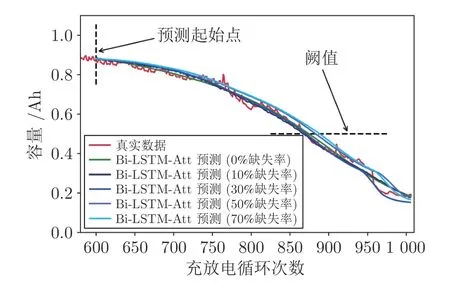
圖9 不同缺失率填補后Bi-LSTM-Att 的預測效果Fig.9 The prediction effect of Bi-LSTM-Att after filling with different missing rates
為了更清晰地量化預測效果,采用均方根誤差(Root mean square error,RMSE)和決定系數 (Rsquared,R2) 兩個指標衡量預測的準確性,并將結果繪制于表6.RMSE是逆向指標,該值越小越好,而R2是正向指標,該值越大越好,范圍為 ( 0,1).計算公式如下:其中,yi是各個時刻的真實值,是各個時刻的預測值,是各個時刻的均值.
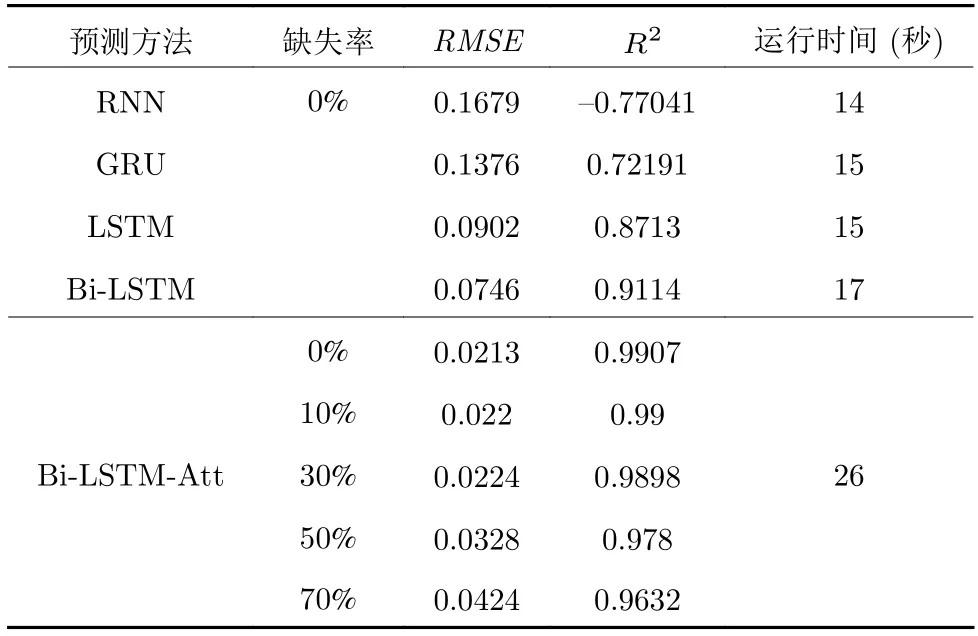
表6 不同預測方法的效果評估Table 6 Effectiveness evaluation of different forecasting methods
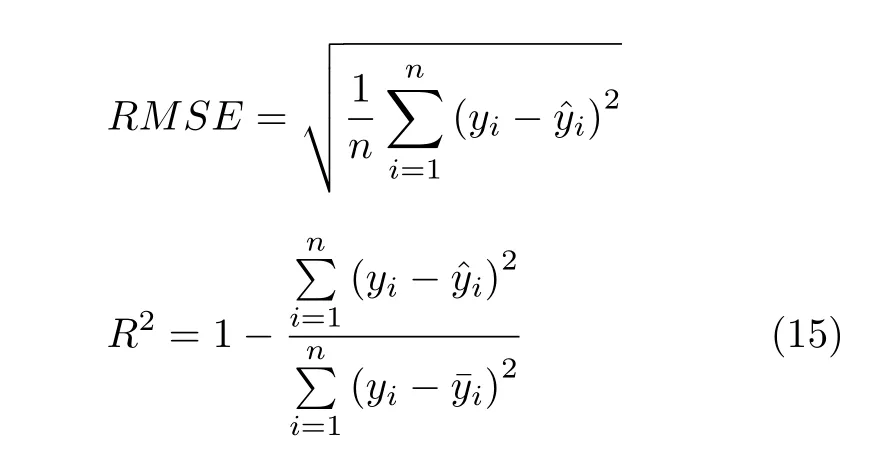
由表6 不難看出,Bi-LSTM-Att 模型的RMSE和R2均小于其他方法,但是運行時間較長.此外,隨著缺失率的增加,Bi-LSTM-Att 預測精度增大幅度較小,再一次表明所提缺失數據生成方法能夠高效捕捉時間序列的退化信息的優越性.
進一步,考慮到樣本的完全隨機缺失機制,需要討論其對預測結果影響的穩定性分析,檢驗模型的魯棒性.具體地,仍然以10%、30%、50%和70%四種缺失率為例,僅僅改變真實數據的缺失位置,再通過PSO-NICE 網絡和Bi-LSTM-Att 網絡進行缺失數據生成填補、剩余壽命預測任務,重復試驗,得到預測相關效果如圖10 所示.
同時,為了量化預測效果,采用RMSE衡量預測的準確性,相關量化結果如表7 所示.

表7 不同缺失率填補后Bi-LSTM-Att 重復預測量化結果Table 7 Quantification results of Bi-LSTM-Att repeated prediction after imputation with different missing rates
通過對比觀察圖10 不難看出,四種缺失率下,Bi-LSTM-Att 模型重復實驗95% 的預測置信區間均能夠很好地覆蓋真實數據,且預測均值與真實數據擬合程度較高,表明PSO-NICE 模型對缺失數據生成的穩定性和魯棒性較好.
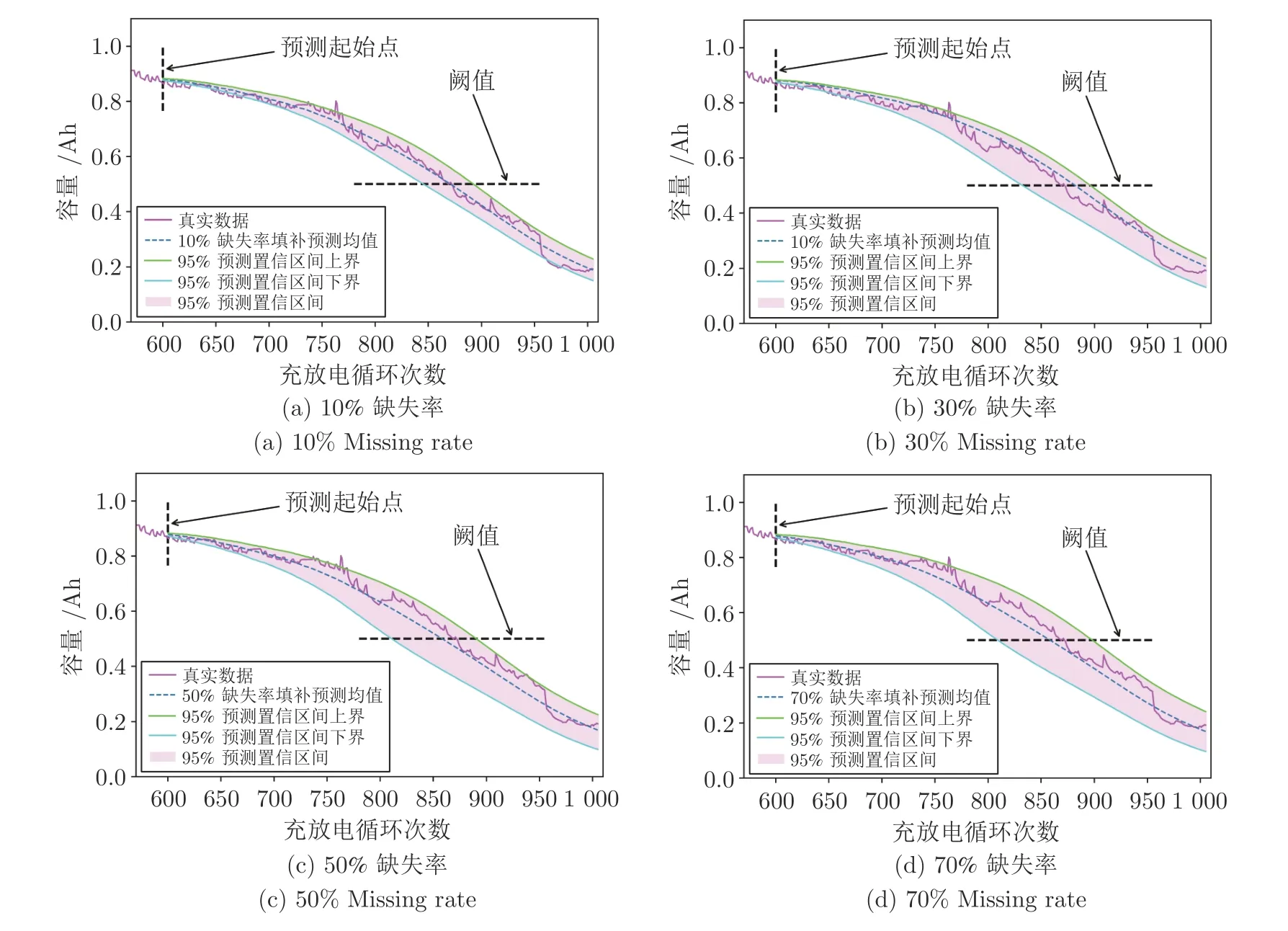
圖10 四種缺失率填補后Bi-LSTM-Att 重復預測效果Fig.10 Bi-LSTM-Att repeated prediction effect after four missing rates imputation
5 結論
針對缺失數據生成模型精度低和訓練速度慢的問題,提出一種基于流模型框架的缺失數據生成方法,可以獲得較好的生成效果,最后通過鋰電池實例進行驗證.工作的主要創新如下:
1) 基于流模型框架,將一維時序缺失數據輸入NICE 深度生成模型,通過無監督方式學習缺失數據背后的真實分布,進而對缺失數據進行充分填補,得到完整意義下的時間序列數據.
2) 基于NICE 深度生成模型,在NICE 反向生成階段,通過引入PSO 算法,迭代優化其退火參數,將深度生成模型由無監督變成有監督,能夠更精準地學習缺失數據背后的真實分布,提升對缺失數據填補的精度,得到更完整意義下的時間序列數據.
本文基于流模型框架,通過建立NICE 模型和PSO-NICE 模型,實現了對一維時間監測序列完全隨機缺失下系統缺失數據的生成及剩余壽命預測的應用.在未來的研究中,將進一步考慮現場實際環境的復雜關系,對不同缺失機制、多維度時間監測序列的缺失數據生成和RUL 預測問題進行更深層次的探索和研究.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
