融合結構和特征的圖層次化池化模型
2023-01-17 09:31:56馬涪元李麗娜汪洪吉
計算機與生活 2023年1期
馬涪元,王 英,李麗娜,汪洪吉
1.吉林大學計算機科學與技術學院,長春130012
2.符號計算與知識工程教育部重點實驗室(吉林大學),長春130012
3.吉林大學人工智能學院,長春130012
為了定義圖卷積操作,研究者們定義了基于譜域和基于空間的圖卷積方法,這些方法都涉及沿著圖中的邊轉換、傳遞和聚合圖中的節點信息,在學習節點表示的任務中取得了良好效果。然而,在面對圖分類任務時,考慮到圖中不同位置和不同狀態的節點有著不同的作用,以及圖中還可能存在著一些具有特定功能的子結構,僅通過圖卷積操作無法利用這些信息。例如,在一個蛋白質圖中,分子(圖的節點)通過鍵(圖的邊)連接,一些由特定分子以及連接它們的鍵組成的子結構具有特定的功能。這些具有特定功能的局部結構對整個圖的表示也十分重要。因此,受卷積神經網絡啟發,利用圖的局部和全局結構獲取圖表示的層次化池化應運而生。
目前,圖的層次化池化研究已有一定成果,主要有兩種策略對圖進行池化:(1)聚類策略,通過應用聚類算法將當前層的節點分配給若干個聚類,每個聚類將作為池化后下一層的一個節點,池化后節點的表示通過對聚類內部的節點特征進行聚合獲得,節點間的連接關系則通過聚合聚類間節點的連接關系獲得。(2)采樣策略,通過設計一種重要性標準為當前層每一個節點計算一個重要性得分,根據得分選擇top-k節點作為池化后下一層的節點,池化后節點的表示為原節點表示與節點得分的一個點積,考慮到拋棄的節點中仍含有大量信息,Zhang 等人[1]提出對被選擇的節點進行一次信息傳遞,將其鄰居信息匯聚以獲取新節點表示,池化后節點的連接關系為原節點間的連接關系。考慮到被拋棄的大量結構信息以及出現孤立節點的可能性,Zhang 等人[2]提出應用結構學習機制為節點學習新的鏈接關系。以這兩種策略構建層次池化模型取得了較好的效果。
考慮對圖數據池化的兩種實現策略,聚類策略一般隱式地利用結構信息和節點特征信息,使得其可能產生不合理的分配矩陣,而采樣策略在池化節點時僅利用結構信息或是節點特征,節點的重要性僅被從一個方面考慮,沒有充分利用圖數據中蘊含的信息。因此,本文結合節點特征和圖結構提出結構和特征融合池化(structure and feature fusion pooling,SAFPool)。主要貢獻如下:
(1)基于聚類策略,分別捕獲圖結構信息和節點特征信息學習聚類分配,并結合得到最終的聚類分配結果。
(2)SAFPool 模型顯式利用圖結構信息和節點特征信息為圖生成聚類分配矩陣,依照聚類對節點信息進行聚合得到粗化圖實現池化。
(3)在相同的模型結構和數據集下,與其他方法相比,SAFPool取得了較好的效果。
1 相關性研究
1.1 圖卷積神經網絡
圖卷積神經網絡由于其在處理圖結構數據上優異的表現正受到越來越多的關注,目前也已經有了豐富的成果,基于譜域的圖卷積神經網絡有著堅實的理論基礎,其從信號處理的角度看待圖數據。Bruna等人[3]將圖信號從節點域變換到譜域后根據卷積定理通過點積實現卷積操作,譜域卷積依賴對拉普拉斯矩陣的特征分解,需要耗費大量算力且沒有局部化,每次卷積將對所有的節點進行聚合;Defferrard 等人[4]利用切比雪夫多項式,將聚合范圍縮減到節點的k階鄰域,同時利用k階多項式避免了對拉普拉斯矩陣的特征分解,減少了運算復雜度;隨著Kipf 等人[5]進一步的簡化,將k階鄰域變為僅聚合一階鄰域信息,在效率和效果上取得了極好的效果,基于譜域的圖卷積神經網絡變得有效實用。基于空間的方法學習卷積神經網絡,利用圖空間結構即節點間的連接關系對鄰域信息進行聚合(例如,消息傳遞神經網絡(message passing neural networks,MPNNs)[6]、Graph-Sage[7]、GAT(graph attention network)[8]、GIN(graph isomorphism network)[9])。由于圖數據不同于圖像數據,節點不具有固定的鄰域結構,如此便不能如同卷積神經網絡一樣共享濾波器中的加權參數,其聚合函數只能選擇使用不受節點排列順序影響的函數。不論是基于譜域還是基于空間的圖卷積神經網絡,其操作都可概括為根據圖結構對節點特征信息轉換、傳遞和聚合。
1.2 圖層次池化模型
層次化池化模型通過層次結構利用圖的全局和局部結構信息得到更有效的圖表示,為了利用圖的局部結構信息,其在每一個池化層通過聚類或采樣策略縮減節點的規模得到一個粗化圖。
基于聚類的方法通過利用圖中節點和結構信息對節點聚類,將每一個聚類作為池化后的粗化圖中的一個節點,通過聚合局部聚類的信息利用圖的局部結構。DiffPool[10]在池化層通過圖神經網絡模塊為節點學習聚類分配矩陣,通過聚類分配矩陣聚合同一聚類下的節點特征和聚類間的拓撲結構。EigenPool[11]直接通過譜聚類獲得節點分配矩陣,并基于譜域理論通過上采樣為聚類學習新的表示。StructPool[12]在獲取聚類分配矩陣時,著重考慮節點的鄰域節點對其聚類分配的影響,利用條件隨機場從結構上考慮節點的鄰域節點的聚類分配對節點聚類分配的影響。
基于采樣的策略通過為節點計算重要性得分,保留最重要的前k個節點以及它們間的連接關系生成粗化圖實現池化。gPool[13]通過計算節點表示在一個與節點表示等長的可訓練權重上投影計算節點重要性。SAGPool[14]通過GCN(graph convolutional networks)為節點計算重要性得分,GCN 利用結構信息的同時也隱式利用了節點的特征信息。HGP-SL(hierarchical graph pooling with structure learning)[2]則考慮節點與鄰域的信息差異,將與鄰域信息差異越大的節點作為越重要的節點。
以上基于聚類的策略在生成聚類分配矩陣時都從圖結構信息入手。DiffPool 通過GCN 利用圖結構信息,譜聚類則是通過圖最小切思想對圖進行聚類劃分,StructPool 則考慮鄰域信息的聚類分配對當前節點的影響。考慮到采樣策略中許多模型利用圖節點特征信息進行采樣并獲得了良好的效果,為提升基于聚類策略的模型的效果,本文模型SAFPool在為節點生成聚類分配矩陣時,同時考慮利用圖中的結構信息和節點信息,以使模型在分類任務中更加客觀和準確。
2 層次化池化模型
為了獲得圖的表示,全局池化策略利用圖卷積神經網絡獲得節點表示,通過加和、讀出、神經網絡等方法將圖中所有節點的特征聚合得到圖的表示。考慮到全局池化沒有利用圖中豐富的結構信息,所有節點不論位置、屬性為形成圖的表示發揮同樣的作用,本質上十分“平坦”。因此,通過學習卷積神經網絡的層次池化模型提出圖層次化池化模型,針對圖結構數據設計池化操作,以利用圖的全局和局部結構信息獲取更有效的圖表示。為了逐層地捕獲圖的局部結構,針對圖數據的池化操作主要有兩種策略:基于聚類策略和基于采樣策略。
2.1 基于聚類的層次化模型
由于圖數據的結構復雜性,對數據的池化難以直接學習卷積神經網絡中的對網格狀數據進行池化操作。同時,不同的圖擁有不同的節點數和邊數,為池化操作的設計帶來了更大挑戰。為了解決這些問題,Ying 等人[10]開創性地使用聚類方法實現池化,提出DiffPool 模型,在圖數據上引入了層次池化操作用以生成圖的分層表示,其能夠以端到端的方式堆疊圖神經網絡結構實現與各種圖神經網絡結構的結合。
給定一個圖神經網絡模型的輸出Z=GNN(A,X)和圖的鄰接矩陣A∈Rn×n,X∈Rn×d表示節點特征矩陣,其中d是節點特征的維度。池化操作需要定義一種策略輸出一張粗化圖,該粗化圖將包含m<n個節點,節點間具有帶權鄰接矩陣A′∈Rm×m和節點嵌入表示Z′∈Rm×d,使得該新粗化圖可以用于輸入另一個圖神經網絡層。通過重復該粗化圖的過程L次可以構建出一個L層圖神經網絡的模型,該模型可以輸出關于輸入圖的一系列越來越粗化的圖。因此,池化操作需要學習如何利用圖神經網絡層的輸出對節點進行聚類或者池化,如此才能將粗化圖作為圖神經網絡的輸入。相較于傳統圖粗化任務,針對圖分類的層次化池化模型面對著更大的挑戰,不同于在一張圖上進行粗化,圖分類任務需要對一組圖進行處理,而不同的圖具有不同的節點數目、邊數目和結構信息,因此,池化操作在實現時必須能夠涵蓋不同的圖且適應不同圖結構。
為了利用圖神經網絡的輸出實現聚類,池化操作的關鍵是在L層的模型中,利用上一層生成的節點表示為當前層學習一個聚類分配矩陣。因此,需要每一層同時提取對圖分類有用的節點表示和對層次池化有用的節點表示,并使用圖神經網絡模塊構建對一組圖都有效的一般的池化策略。池化操作由兩部分構成:(1)根據聚類分配矩陣實現池化;(2)使用圖神經網絡結構生成分配矩陣。
在得到一層節點到聚類的分配矩陣Sl后,DiffPool 的池化操作根據分配矩陣Sl對這些節點表示進行聚合得到對應聚類的表示,依據l層的鄰接矩陣Al,根據不同聚類內包含的節點間的連接關系生成表示每對聚類間連接強度的粗化鄰接矩陣。DiffPool 通過將該層節點信息聚合到聚類實現對輸入圖的粗化。
為了獲取在l層進行池化所需要的分配矩陣Sl和嵌入表示矩陣Zl,DiffPool利用兩個獨立的圖卷積神經網絡分別生成這兩個矩陣,兩個圖卷積神經網絡的輸入相同,是從前一層輸入l層的節點特征Xl和節點鄰接矩陣Al。在l層生成節點嵌入表示的是一個標準圖神經網絡模塊:

該模塊將l層中的聚類節點的節點表示傳入一個圖神經網絡模塊,進而學習一個關于聚類節點的新的表示Zl。另一方面,在l層生成分配矩陣的是帶有Softmax 的另一個圖神經網絡模塊:

其中,Softmax 函數以行方式作用在圖神經網絡的輸出上,GNNl,pool(·)的輸出維度是預定義參數,其決定對l層節點分配到多少個聚類(也即l+1 層的節點數),是模型中的超參數。DiffPool 池化層中的兩個圖神經網絡模塊接受相同的輸入,但各自有著不同的參數且發揮著不同的作用,GNNl,embed(·)用于在l層為l層的節點生成新的表示,GNNl,pool(·)用于在l層為l層節點生成分配矩陣。在第0 層時,池化模型的輸入為原始圖數據,在l-1 層時,該層生成的分配矩陣維度應設置為1,如此在最后一層將前一層中的所有信息聚合在一起生成最終的圖表示。
2.2 基于采樣的層次化模型
為了在池化層縮減節點規模,另一種策略是對節點采樣,池化層不斷地尋找重要節點,卷積層則對這些重要節點的信息進行局部匯聚,最終通過這些采樣獲取重要節點信息對整張圖進行表示。Lee 等人[14]提出SAGPool 使用圖神經網絡模塊計算一個自注意力分數作為選擇標準。注意力機制[15]在深度學習模型中廣泛使用,這樣的機制可以使得模型更多關注重要的特征而較少關注不重要的特征。具體而言,自注意力[16]也被稱為內部注意力,其允許輸入特征作為自身的注意力要素。SAGPool 通過圖卷積神經網絡獲取自注意力分數,其可以利用不同的圖卷積神經網絡層,例如使用前文所述的1stChebNet,其自注意力分數的計算可通過如下公式進行:
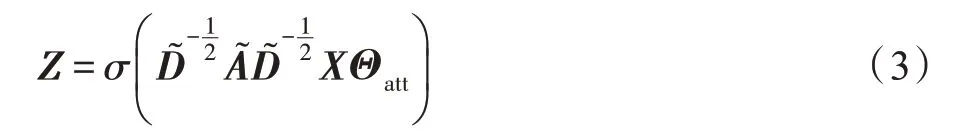
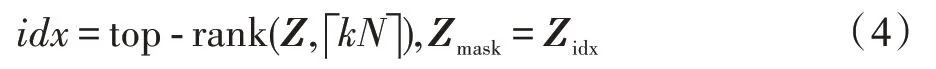

其中,Xidx,:是對節點特征矩陣的行索引,即僅保留節點特征矩陣中被idx 作為索引選擇的節點;Aidx,idx是一個包含行和列的索引,即僅保留鄰接矩陣中兩個端點都是被idx 作為索引選擇的節點的邊。Xout和Aout分別作為經過池化的新圖的節點表示矩陣和鄰接矩陣。SAGPool 通過舍棄所有未被選擇的節點的相關信息,僅保留通過自注意力分數選擇的節點信息進行池化操作。
3 結構和特征融合池化
本文提出結構和特征融合池化(SAFPool),考慮顯式地利用圖結構信息和圖節點特征信息實現聚類策略。池化層模型主要包含兩部分:聚類學習和聚類池化。
3.1 聚類學習
聚類學習是SAFPool 模型的關鍵,SAFPool 模型同時顯式地利用圖的結構信息和圖中節點特征為節點學習聚類劃分,其包含三個組成部分:基于結構的聚類學習(structure-based cluster learning,SBCL)、基于特征的聚類學習(feature-based cluster learning,FBCL)和結構-特征聚類學習(structure feature cluster learning,SFCL)。池化層進行聚類學習過程如圖1所示。
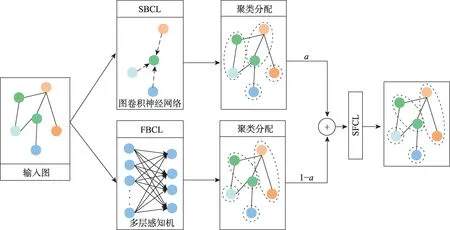
圖1 池化層聚類學習Fig.1 Cluster learning in pooling layer
池化層進行聚類學習首先需要通過基于結構信息的聚類學習模塊和基于節點特征信息的聚類學習模塊,基于結構的聚類學習利用圖卷積神經網絡通過圖結構為節點學習聚類分配,基于特征的聚類學習則利用多層感知機通過節點特征為節點學習聚類分配,結構-特征聚類學習則融合二者學習到的聚類表示生成最終的聚類分配。
基于結構的聚類學習:一般來說,一張圖中包含著大量的節點和邊,蘊含著豐富的結構信息,因此在學習節點的聚類分配時就要考慮充分利用這些信息,圖卷積神經網絡模塊沿著圖中的邊利用節點的鄰域信息對節點表示進行更新,這個過程中通過利用鄰域信息,即節點的鄰居構成和鄰居屬性實現對結構信息的利用。因此本文使用圖神經網絡模塊利用圖中結構信息為節點學習聚類分配,利用結構信息進行聚類學習可以表示為:

基于特征的聚類學習:在圖數據中,節點也往往包含著特征信息,這些特征信息能在很大程度上對節點進行表示,因此直接利用節點的特征信息學習聚類分配也有其必要性。本文通過應用多層感知機來通過節點特征學習聚類分配,公式如下:

結構-特征聚類學習:圖卷積神經網絡能夠高效地利用圖結構信息,多層感知機則專注于節點特征信息,為了同時利用這兩種方法學習到的聚類分配矩陣,使結果更加客觀且具有更好的魯棒性,在獲取從圖結構和節點特征信息學習到的聚類分配矩陣后,將兩個聚類分配矩陣融合在一起:

其中,權重a是一個預定義的超參數。
3.2 聚類池化
在獲取最終的聚類分配矩陣后,將根據聚類分配矩陣實現池化。將層次模型中l層的分配矩陣表示為Sl∈Rnl×nl+1,Sl中每一行對應著l層的nl個節點(或是聚類),每一列則對應著l+1 層的nl+1個聚類,Sl中每一個值對應著該行的l層節點屬于該列對應的l+1 層聚類的概率。直觀上,分配矩陣Sl為l層的所有節點提供了分配給l+1 層各個聚類的概率。
假設已獲取l層的分配矩陣Sl,并將該層的節點鄰接矩陣表示為Al,該層的節點嵌入表示用Zl進行表示。給定這些輸入,聚類池化將依照分配矩陣將屬于各個聚類的節點特征聚合作為聚類表示,將各個聚類包含的節點到其他聚類包含的節點的連接強度聚合作為聚類間的連接強度,以此得到池化后的粗化圖。該粗化圖的鄰接矩陣和嵌入表示分別使用Al+1和Xl+1表示,即(Al+1,Xl+1)=Pool(Al,Zl)。具體而言,其使用以下兩個公式進行池化:

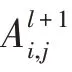
整個層次化池化模型是通過將圖卷積神經網絡模塊和池化模塊依次堆疊起來建立的,如圖2 所示。通過將卷積層和池化層交替堆疊在一起,可以不斷地匯聚整張圖的信息直到得到整張圖的表示,每經過一次池化模型就會在輸入的基礎上對更高層的局部結構信息進行匯聚,通過讀出操作在每一次池化后都將池化結果作為圖表示的一部分,可以極好地保留整張圖在各個層次上表現出的特征,從而實現同時捕獲局部和全局結構得到圖的表示。
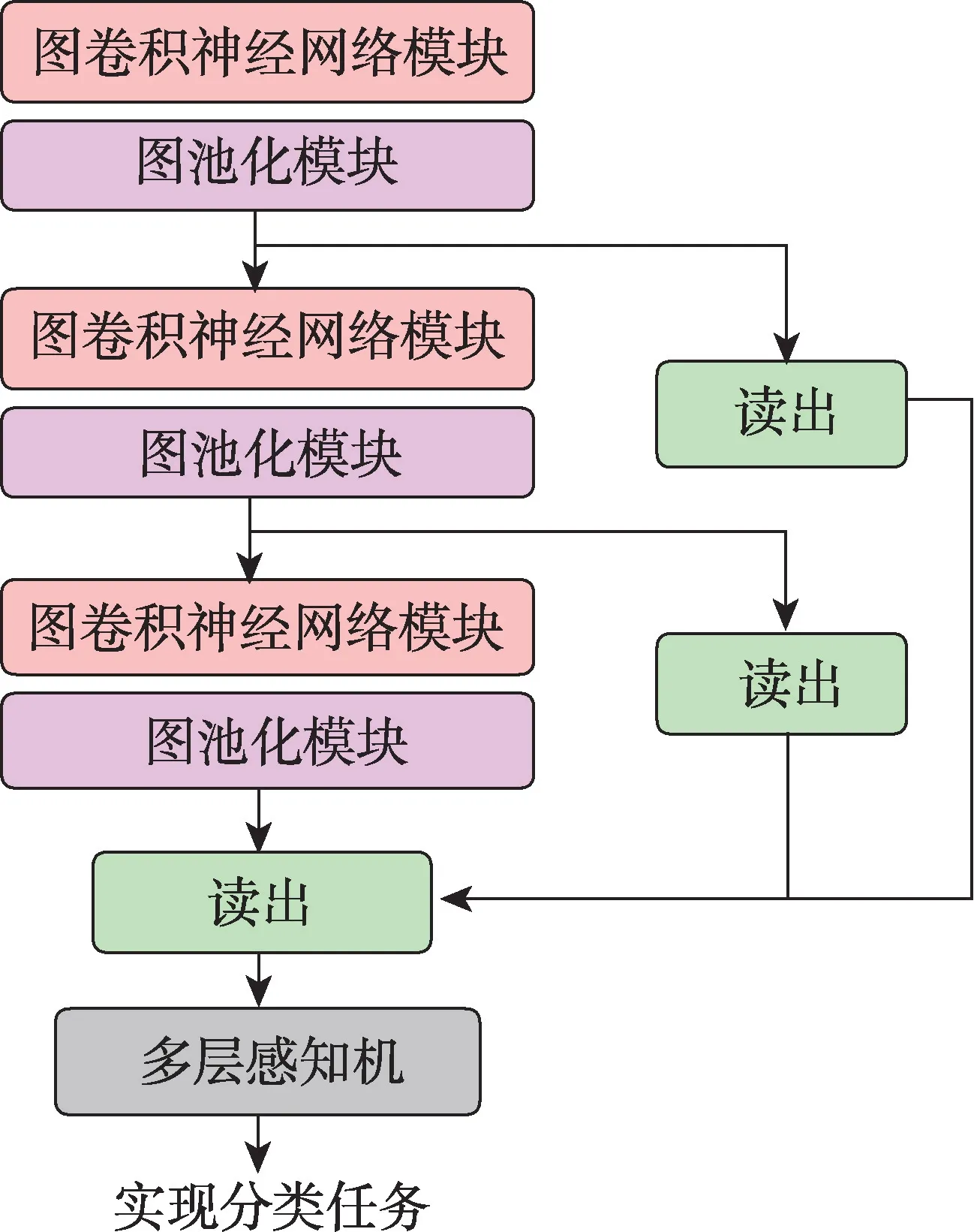
圖2 層次化池化模型結構Fig.2 Illustration of hierarchical pooling model architecture
4 實驗
4.1 數據集
為了驗證SAFPool模型的有效性,本文使用三個生物信息相關的圖分類數據集,選擇三個時下較新的層次化池化模型進行對比。
PROTEINS[17]是一個蛋白質圖數據集,每張圖中的節點表示一個氨基酸,若兩個氨基酸之間的距離小于6 埃,則認定代表這兩個氨基酸的節點間存在一條邊,圖的標簽則指示該蛋白質是否為蛋白酶。NCI1 和NCI109[18]是抗癌活性分類的兩個生物學數據集,其中每張圖都表示一個化合物,圖的節點和邊分別代表原子和化學鍵。這三個數據集的基本信息如表1 所示。
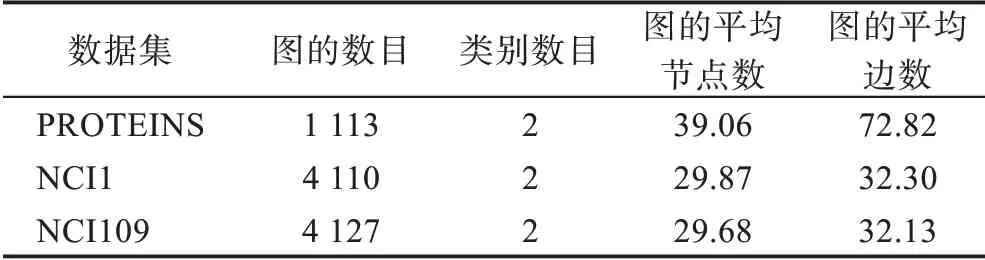
表1 數據集信息表Table 1 Dataset information table
將數據集按照8∶1∶1 的比例劃分為訓練集、驗證集和測試集,在相同的模型結構和參數設置下運行SAFPool以及當前較新的三個模型。通過對比不同模型的效果對模型的有效性進行驗證,同時通過對不同聚類學習模塊的學習結果進行可視化,觀察模型的創新點即引入的基于特征的聚類學習模塊的效果。
4.2 基線方法與實驗設置
為了對模型的性能進行檢驗,本文選擇了兩個近期工作提出的模型:HGP-SL(hierarchical graph pooling with structure learning)[2]和GSAPool(graph selfadaptive pooling)[1]。由于這兩種模型都是基于采樣策略實現的,本文又選擇了基于聚類策略的Diffpool[10]模型,同時若將本文提出的模型SAFPool中池化層的FBCL 模塊移除即可被視為一個Diffpool模型。
HGP-SL 模型通過將三個卷積層與兩個池化層交替堆疊構建層次化模型學習圖表示,圖表示亦通過讀出操作聚合各個池化層的局部結構信息獲得,卷積層的輸出節點表示維度為128。由于HGP-SL 模型使用采樣策略實現聚類,其不必執行矩陣乘法操作,可以使用將批次中的圖以分塊對角矩陣組織在一張圖中的形式構建批數據,此時可以依照池化率在池化時為每張圖保留不同數目的節點,這里模型設置的池化率為0.5。GSAPool模型同樣使用采樣策略,由三個卷積層和三個池化層交替堆疊而成,其池化率亦設為0.5。Diffpool 模型使用的聚類策略,同本文模型SAFPool一樣由三個卷積層和三個池化層交替堆疊而成,其池化參數也與本文模型SAFPool相同,三個池化層學習的聚類數分別為14、7、1。模型在訓練時都采用相同的訓練策略,即迭代的epoch數為1 000,并且當模型在驗證集上的損失連續50個epoch都不再變得更小時也停止訓練,認為得到了最好的模型,激活函數為ReLU函數,參數初始化方法為Glorot Uniform。
4.3 實驗結果與分析
本文模型與三個對比基線方法的對比如表2所示。
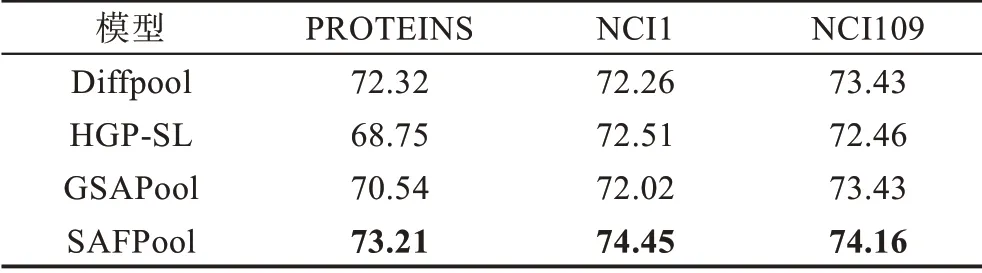
表2 圖分類模型在不同數據集上的對比實驗結果Table 2 Comparative experimental results of graph classification models on different datasets 單位:%
表2 中,各個數據集中的最優效果加粗顯示,可以看到本文模型SAFPool 在三個數據集上都取得了最優表現。尤其與Diffpool 的對比效果說明在為節點生成聚類分配矩陣時,通過圖卷積神經網絡利用圖結構信息,同時引入多層感知機處理圖節點表示信息,為節點生成聚類分配矩陣進行池化可以提升模型效果,證明了池化操作在通過圖卷積神經網絡利用圖結構信息外引入節點特征信息的有效性。
為了更加直觀地研究基于特征的聚類學習模塊的引入的效果,說明基于節點特征的聚類學習的必要性,本文對基于結構的聚類學習模塊、基于特征的聚類學習模塊以及結構-特征聚類學習模塊在一張圖上同一池化層得到的聚類分別進行可視化展示,可視化效果見表3。

表3 SAFPool模型不同模塊的聚類分配結果Table 3 Cluster assignment results of different modules of SAFPool
為了對節點的聚類分配可視化顯示,本文對節點分配矩陣進行了一定處理,雖然在執行池化操作時一個節點可能屬于多個聚類,依照其屬于該聚類的概率發揮不同程度的作用,可視化時為了醒目而令節點僅屬于分配概率最大的聚類,表3 中展示的圖片中節點的顏色就表示節點所屬的聚類。從表中可以看出基于結構的聚類學習模塊和基于特征的聚類學習模塊學習的聚類分配矩陣存在著明顯的差別,二者結合得到的聚類分配也與它們的原本分配概率存在較大差別,說明模型引入特征信息生成聚類確實能夠帶來新的信息,同時對最終的池化結果帶來較大的影響。
5 結束語
本文在圖卷積之外顯式地補充節點特征用于池化,通過實驗說明了這種方法的有效性。同時顯式利用圖結構信息和圖中的節點信息生成節點分配矩陣實現聚類策略相較于基線模型取得了較好的效果,尤其與利用圖卷積神經網絡隱式利用圖結構和節點特征信息實現聚類策略的Diffpool 模型對比,充分說明了圖中的節點包含的信息對表達圖特征具有重要作用。
現實的圖數據中含有大量富有意義的局部結構信息,層次化池化模型正是為了利用這些局部結構而提出的。在當前方法中,局部結構的獲取是通過端到端的訓練獲得的,并沒有對應上現實數據中具有特定作用的局部結構,是否能將現實數據中的局部結構引入池化操作過程中以提高模型的有效性和可解釋性也是十分值得研究的方向。
同時,在訓練模型時也可以考慮與一些智能算法[19-20],如MBO(monarch butterfly optimization)[21]、EWA(earthworm optimization algorithm)[22]、MS(moth search)[23]結合以提高模型的表現。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
鐵道通信信號(2020年9期)2020-02-06 09:15:22
中華詩詞(2019年7期)2019-11-25 01:43:04
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中華手工(2017年2期)2017-06-06 23:00:31
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
