基于深度神經網絡和聯邦學習的網絡入侵檢測
2023-01-27 08:27:26劉金碩詹岱依鄧娟王麗娜
計算機工程 2023年1期
劉金碩,詹岱依,鄧娟,王麗娜
(武漢大學國家網絡安全學院空天信息安全與可信計算教育部重點實驗室,武漢 430072)
0 概述
在高速網絡環境下,網絡安全問題層出不窮,網絡入侵檢測作為監控網絡潛在攻擊的重要措施[1],需要在海量數據環境下快速且準確地識別攻擊事件。因此,提高網絡入侵檢測技術的準確率與檢測速度具有十分重要的現實意義。
近年來,機器學習與深度學習算法在圖像和文本識別、語言翻譯等方面都取得了較大突破,于是很多研究人員也將其運用于網絡入侵檢測領域。MA等[2]提出一種基于生成對抗網絡和雙向長短期記憶(Bidirectional Long Short-Term Memory,Bi-LSTM)網絡的方法,該方法解決了數據集冗余的問題。LI等[3]提出基于卷積神經網絡的入侵檢測系統,該系統將文本數據處理轉換為圖像數據處理,準確率達到79.14%,雖然其效果不如其他深度學習算法,但是為入侵檢測方法設計提供了一種新思路。此外,ZARAI 等[4]利用長短期記憶(Long Short-Term Memory,LSTM)網絡來緩解循環神經網絡(Recurrent Neural Network,RNN)的梯度消失問題,從而改進入侵檢測系統的特征選擇,實驗結果表明,3 層LSTM 架構的入侵檢測模型對異常攻擊檢測更有效。SUWANNALAI 等[5]提出基于強化學習的網絡入侵檢測系統,與遞歸神經網絡相比,該系統在數據集中某些類型的攻擊上有優異表現。ZHAO 等[6]提出一種基于輕量級深度神經網絡(Deep Neural Network,DNN)的網絡入侵檢測方法,該方法能有效減輕入侵檢測時所面臨的內存負擔。
雖然深度學習[7]與機器學習算法在網絡入侵檢測領域取得了較好的效果[8-10],但是仍然存在如下問題:1)數據安全與數據隱私,在大數據時代,數據安全與數據隱私[11]一直是網絡入侵檢測所面臨的一大難題,且在模型訓練以及數據傳輸過程中往往存在許多隱私泄露等安全問題;2)準確率與效率,在處理海量數據時,較高的準確率往往伴隨著較大的時間成本,如何同時提高數據處理效率[12]與模型準確率也是目前的研究重點。
聯邦學習[13]是2016 年谷歌公司提出的一種分布式機器學習框架,它在服務器之間通信時可以實現數據安全,很好地保障了參與方的終端數據隱私。同時,還可以使用各種不同的通用模型在多個參與方之間開展高效率的特征提取與學習。FRIHA 等[14]結合聯邦學習提出一種物聯網入侵檢測系統,該系統利用混合集成的方法結合聯邦學習來執行局部訓練并只聚合模型參數,實現了較高的召回率。CIREGAN 等[15]使用基于GPU 的加速訓練深度神經網絡算法進行圖像分類和字符識別,結果表明,深度神經網絡的并行計算能力能夠大幅減少訓練所需時間。
本文基于深度神經網絡和聯邦學習建立一種網絡入侵檢測模型DFC-NID。該模型融合聯邦學習框架,通過基于自動編碼器優化的深度神經網絡算法對多個子服務器節點的網絡入侵數據進行模型訓練。最后通過實驗驗證DFC-NID 模型在耗時和數據安全保障方面的性能。
1 相關理論
1.1 KDDCup99 與NSL-KDD數據集
網絡入侵檢測數據集包括部分自制數據集和一些常用的公測數據集。目前,大多數入侵檢測研究使用的標準公共數據集為KDDCup99[16-17]和NSLKDD[18-20]。
NSL-KDD 數據集是KDDCup99 數據集的改進版 本。2009 年,TAVALLAEE 等[21]對KDDCup99 數據集進行統計分析,發現該數據集中存在大量冗余記錄,其中,訓練數據集中就有高達78%的冗余數據,測試數據集中有75%的冗余數據,如此大量的重復記錄會導致分類器偏向于學習更頻繁出現的記錄,從而造成評估結果偏差。TAVALLAEE 等[21]刪除了原始KDDCup99 數據集中的這些冗余記錄,創建了一個更簡潔高效的入侵檢測數據集NSL-KDD。NSL-KDD 數據集包含41 個正常或特定攻擊類型的特征,表1 匯總了NSL-KDD 數據集中的數據類型以及屬于該特定數據類型的數據集中的特征編號。
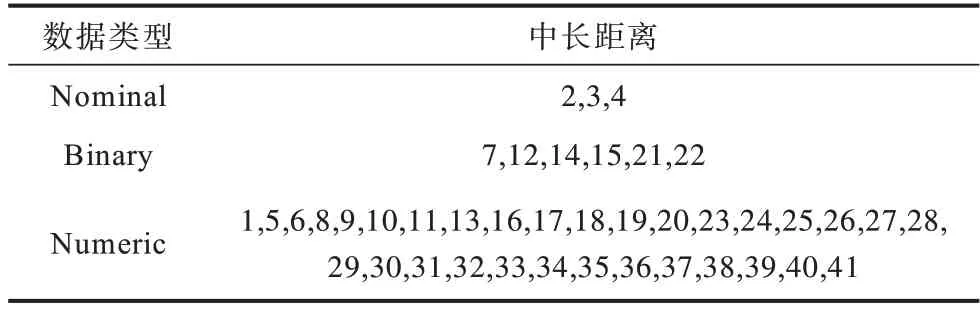
表1 NSL-KDD 數據集的數據類型及特征編號Table 1 Data type and feature number of NSL-KDD dataset
表2 歸納了NSL-KDD 數據集中4 種不同攻擊類型的屬性值,分別為DoS(Denial of Service)、Probe、R2L(Root to Local)、U2R(Unauthorized to Root):

表2 NSL-KDD 數據集的攻擊類型屬性值Table 2 Attack type attribute value of NSL-KDD dataset
1)DoS。拒絕服務攻擊,攻擊者通過使計算內存資源變得過于繁忙或拒絕合法用戶訪問,使其暫時或無限期地對用戶不可用。
2)Probe。攻擊者通過掃描計算機(主機)的網絡,收集有關Web 應用程序、操作系統、數據庫、網絡以及與其連接的設備的信息,從而找到威脅或漏洞并加以利用。
3)R2L。攻擊者從遠程設備到本地設備進行未授權訪問,通過利用一些漏洞來向設備發送數據包。
4)U2R。攻擊者可以訪問攻擊目標中的user,且攻擊者在訪問計算機時可以獲得root 權限的攻擊,如木馬、勒索軟件等。
上述4 種攻擊類別中共包含22 種不同的子類,這22 個子類加上normal 共同組成了KDDCup99 中的23 個標簽。在KDDCup99 的41 個特征中,有38 個數字特征和3 個字符特征,3 個字符特征分別為protocol_type、service 和flag。
1.2 深度神經網絡
深度神經網絡在處理NSL-KDD、KDDCup99 等規模龐大數據集時具有較好的并行計算能力。如圖1 所示,用于入侵檢測數據處理的DNN 由輸入層、隱藏層、輸出層組成[22],各個層之間的神經元完全連通。圖1 的輸入層使用來自NSL-KDD 數據集的所有41 個特征作為神經元,經過多個隱藏層之后對攻擊數據和正常數據進行分類。
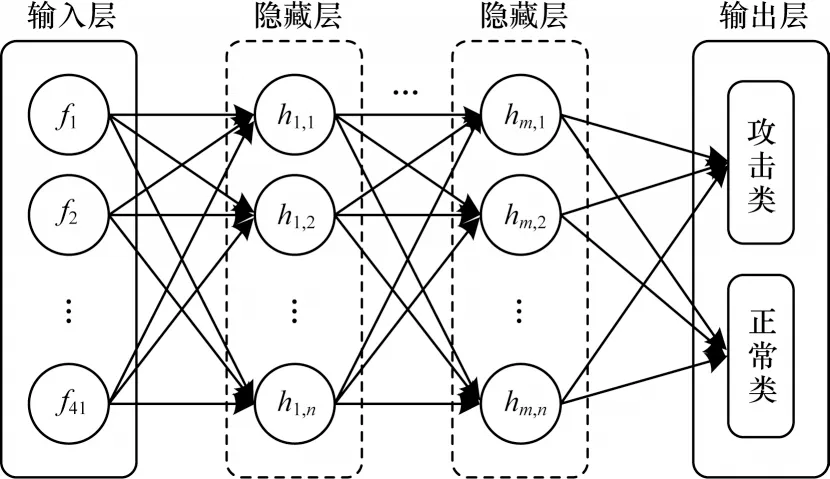
圖1 深度神經網絡結構Fig.1 Deep neural network structure
1.3 聯邦學習
聯邦學習的核心思想是基于分布在多個設備上的數據集建立機器學習模型,同時防止數據泄露[23]。在聯邦學習框架下,每個設備不發送原始數據進行處理,僅發送更新后的模型參數進行聚合,其參數聚合原理類似于分布式機器學習[24]。
如圖2 所示,在聯邦學習框架中,每個服務器之間相對獨立、互不干預,對本地數據的處理權限不受中心服務器控制。每個子服務器通過下載通用模型來對本地數據進行獨立訓練與測試,然后通過上傳將本地參數更新傳輸至中心服務器。每個數據擁有方都可以在不給出己方數據的條件下進行訓練,從而有效保障數據所有者的數據安全。在聯邦學習機制下,多個子服務器能夠共同維持一個最新的全局模型,這個全局模型是聯邦學習框架中最重要的組成模塊,本文DFC-NID 模型中聯邦學習框架所使用的通用模型是DNN。
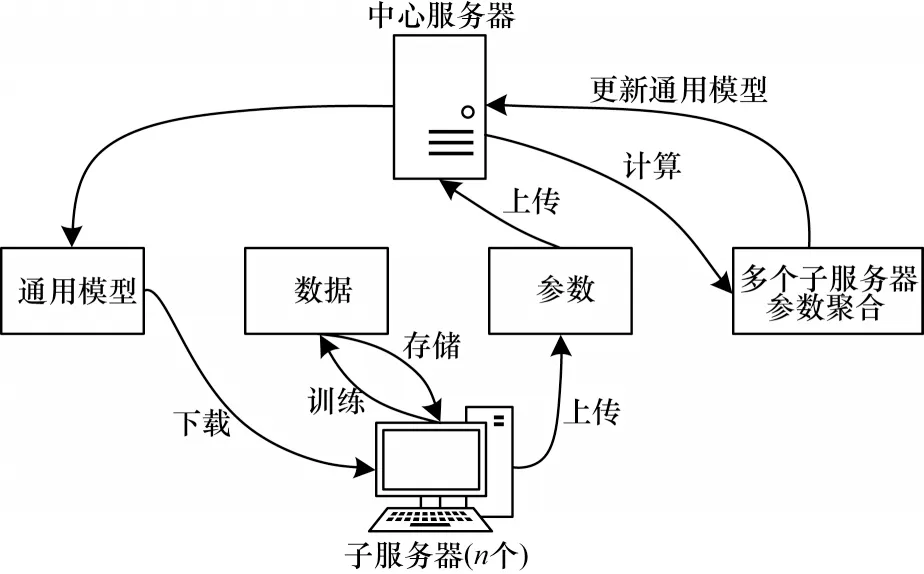
圖2 聯邦學習框架Fig.2 Federated learning framework
2 DFC-NID 模型
本文所提網絡入侵檢測模型DFC-NID 的總體流程如圖3 所示。

圖3 DFC-NID 流程Fig.3 The procedure of DFC-NID
DFC-NID 總體架構分為數據預處理、DNN 通用模型搭建、聯邦學習框架建立3 個部分。對于輸入的數據集,首先進行符號預處理以及數據歸一化;然后建立DNN 通用模型模塊,利用其對數據集進行特征學習;接著搭建聯邦學習框架,使得多個服務器協作并不斷迭代優化參數;最后通過Softmax 層輸出分類預測結果。
2.1 數據預處理
由于在使用DNN 進行分類時數據只能用數值來訓練和測試,而NSL-KDD 與KDDCup99 數據集包含許多不同的數據類型,因此需要對初始數據進行預處理。預處理過程主要分為以下2 個步驟:
1)符號數據預處理,即將非數值數據轉換成數值數據。在數據集中通常存在非數值數據,如表1中的特征2、3 和4(TCP、UDP 和ICMP)。給每個變量分配特定的值(如TCP=1、UDP=2、ICMP=3),可以將訓練數據集和測試數據集中的這些特征轉換為數值類型。在預處理時,將數據集的攻擊類與正常類轉換為數字類,如將1、2、3、4分別分配給DoS、Probe、R2L、U2R,將5 分配給normal。
2)數據歸一化。NSL-KDD 數據集的特征是離散值或連續值,如果特征值的范圍不同,則它們之間將無法直接進行比較。通過使用最小-最大歸一化[25]對這些特征進行處理,將每個特征的所有不同值都映射到[0,1]范圍。
2.2 深度神經網絡通用模型建立
通用模型是基于聯邦學習的入侵檢測框架的核心模塊,DFC-NID 選擇深度神經網絡作為該框架的通用模型。
如圖4 所示,輸入層使用來自NSL-KDD 數據集的所有41 個特征作為神經元。第一隱藏層是一個包含20 個神經元的自動編碼器,其從輸入數據的41 個特征中選擇20 個特征;第二隱藏層是一個包含10 個神經元的自動編碼器;第三隱藏層是Softmax層,通過Softmax 層后可以將數據分為正常類與4 種不同的攻擊類。
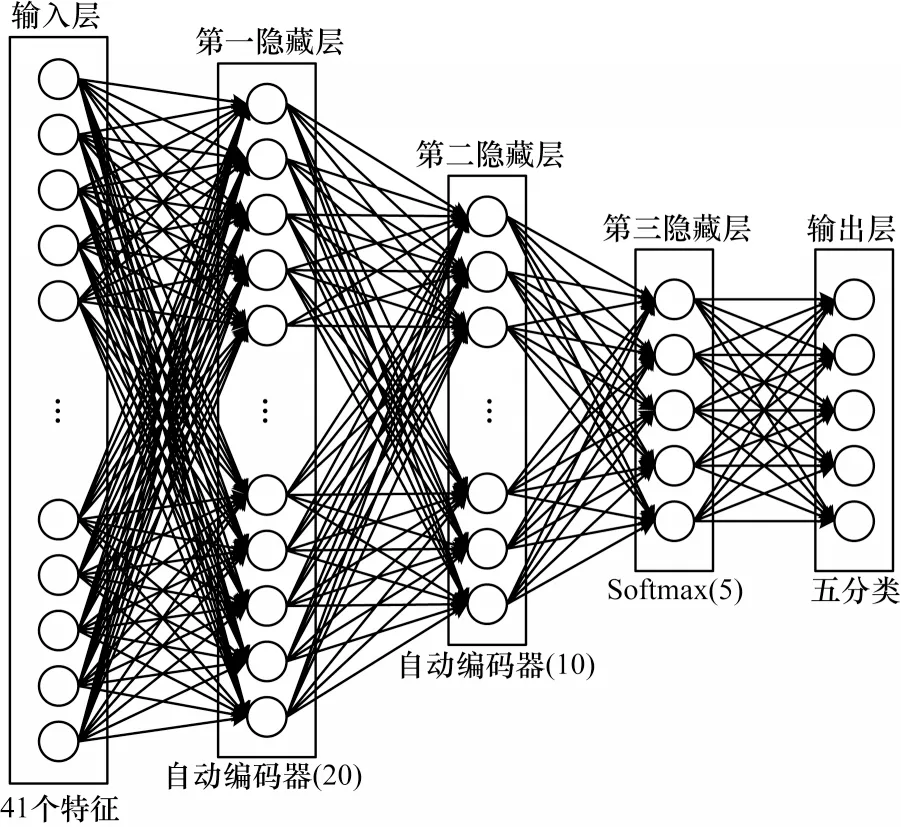
圖4 深度神經網絡通用模型Fig.4 General model of deep neural network
2.2.1 自動編碼器
自動編碼器[26]是一種可以用于特征降維[27]的無監督神經網絡模型,DFC-NID 采用自動編碼器作為“預訓練”DNN 的一種方式。自動編碼器結構如圖5所示。
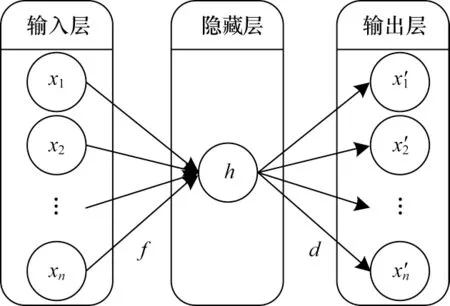
圖5 自動編碼器結構Fig.5 Auto-encoder structure
自動編碼器在對訓練數據進行預訓練的過程中不使用標簽,且自動編碼器在輸出處復制其輸入。在通常情況下,x的數量與x′相同,當隱藏層中的神經元數量h小于x的數量時,自動編碼器會學習x的壓縮表示,下一個自動編碼器再使用這些從訓練數據中提取生成的特征集進行訓練。綜上所述,首先通過無監督學習技術對自動編碼器進行訓練,然后利用訓練后的自動編碼器提取特征。
2.2.2 訓練方式
為了使訓練過程更加有效,模型一次訓練一層DNN,即通過自動編碼器來對每個隱藏層進行訓練與微調。
在第一個自動編碼器訓練后,再對第二個自動編碼器進行訓練。與訓練第一個自動編碼器不同的是,第二個自動編碼器使用的是從第一個自動編碼器中提取的特征,而不是訓練集。在這一層中,20 個特征被進一步壓縮為10 個特征集。經過訓練后,再從第二個自動編碼器中提取特征。
2.3 入侵檢測聯邦學習框架建立
聯邦學習能夠在保持高效率通信的情況下很好地保護數據隱私。本文DFC-NID 模型構建的入侵檢測聯邦學習框架如圖6 所示。由于同步加載的通信方式具有更高的預測精度且使模型收斂更穩定,因此本文聯邦學習中心服務器與子服務器的通信過程選用同步加載的調度方式。對于圖6 中的N個子服務器,每個服務器都有自己的數據集Di,每間隔時間t展開一輪通信,每一輪通信包括以下4 個步驟:1)發送通用模型;2)訓練子服務器;3)上傳子服務器模型參數;4)模型聚合,生成新的通用模型。
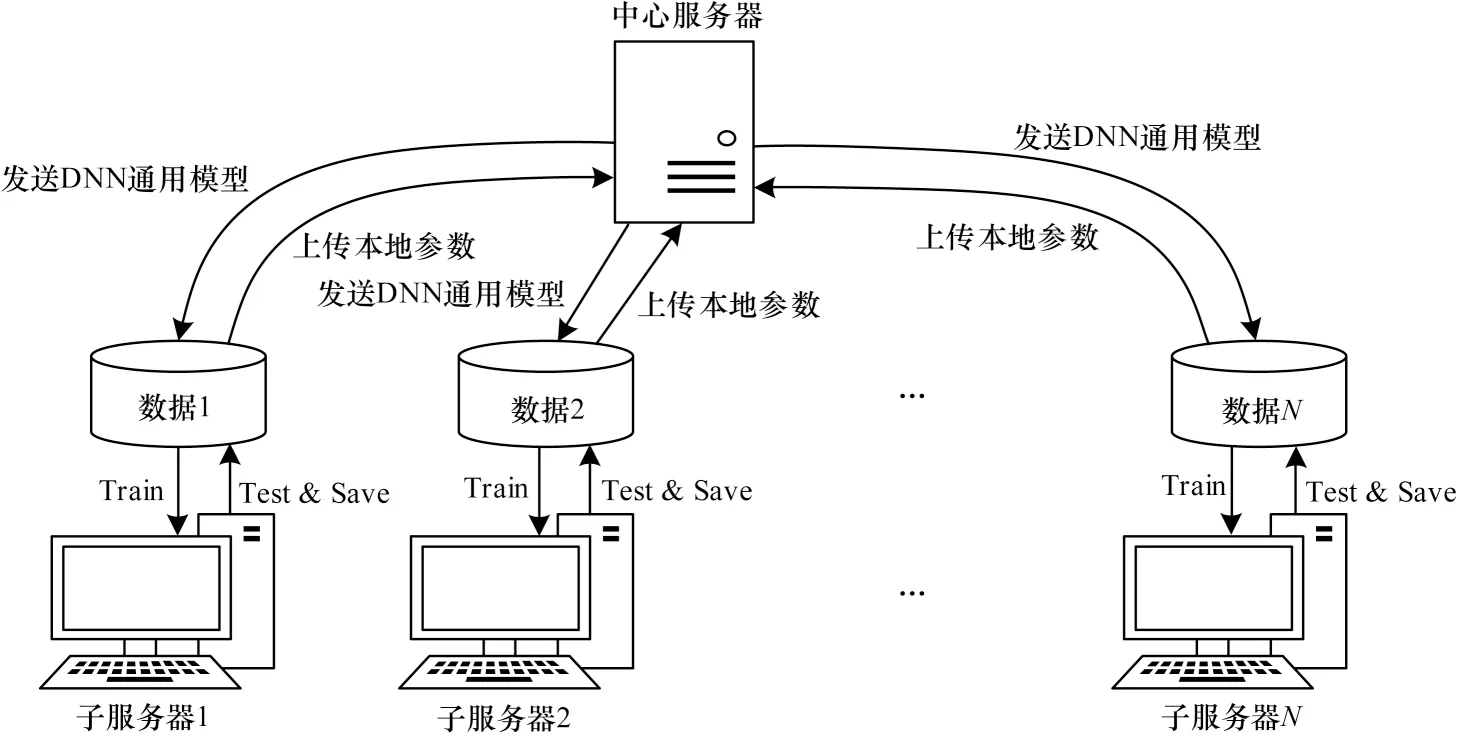
圖6 DFC-NID 模型的聯邦學習框架Fig.6 Federated learning framework for DFC-NID model
中心服務器將DNN 通用模型發送到每個子服務器,子服務器使用各自本地的數據集進行訓練,訓練完畢后再將得到的訓練參數上傳。在通信時間t期間,中心服務器獲得了各個子服務器的訓練參數,通過式(1)更新模型權重并進行模型聚合:

其中:ni為每個子服務器數據集的大小;n為所有子服務器數據集ni之和。隨著W值的不斷更新,可以得到一個新的DNN 通用模型文件Mt+1。最后,將新的DNN 通用模型立即重新分配到每個子服務器上,并進行迭代處理直到模型收斂,結束訓練。算法1為入侵檢測系統聯邦學習過程的完整偽代碼。
算法1入侵檢測系統的聯邦學習算法

DFC-NID 在第一輪通信時使用一個小規模的測試集對訓練后的子服務器進行性能測試,若測試結果小于設定的閾值,則該服務器本輪通信停止上傳參數,從而增強通用模型的聚合效果。除此之外,DFC-NID 還在聚合算法中設置啟動閾值,當中心服務器接收到的參數個數大于閾值時,模型聚合開始,從而有效提高聯邦學習模型的聚合效率。
3 實驗結果與分析
3.1 數據集
本文實驗使用NSL-KDD 與10%的KDDCup99作為數據集,其中,619 994 條數據作為訓練集,311 094 條數據作為測試集。各個特征類別所對應的訓練集與測試集數據量如表3 所示。
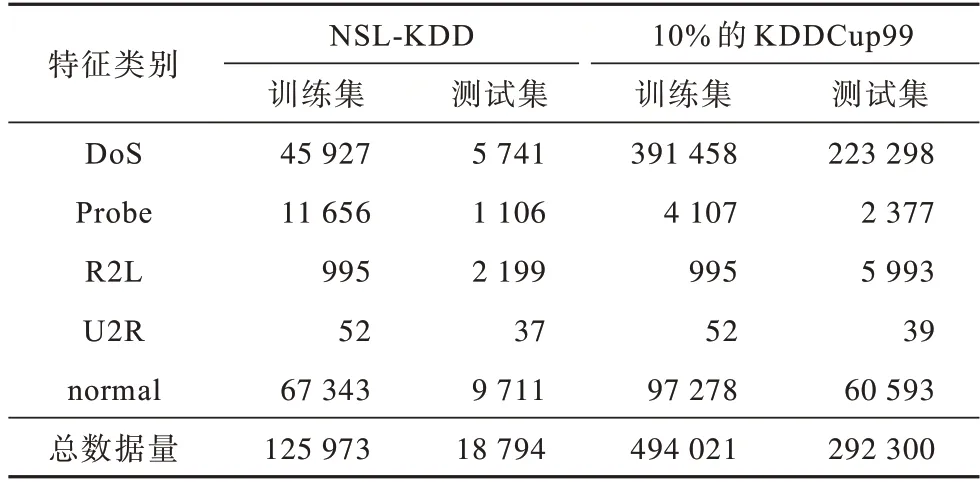
表3 實驗數據集信息Table 3 Experimental dataset information
3.2 實驗評價指標
實驗使用如下指標對DFC-NID 進行入侵檢測性能評估:
1)準確率,計算公式如下:
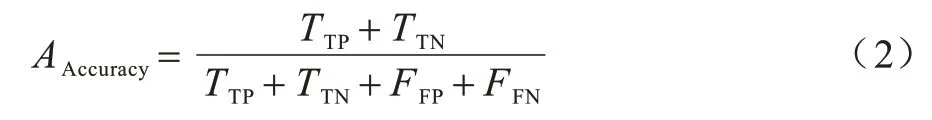
2)精確率,計算公式如下:

3)召回率,計算公式如下:

4)F1 分數,計算公式如下:

3.3 結果分析
3.3.1 先進性與有效性實驗
表4 比較了本文DFC-NID 與眾多常用的深度學習模型在檢測性能上的表現。從表4 可以看出,DFC-NID 在準確率和F1 分數上均優于其他模型,其中,準確率平均提升了3.1%。
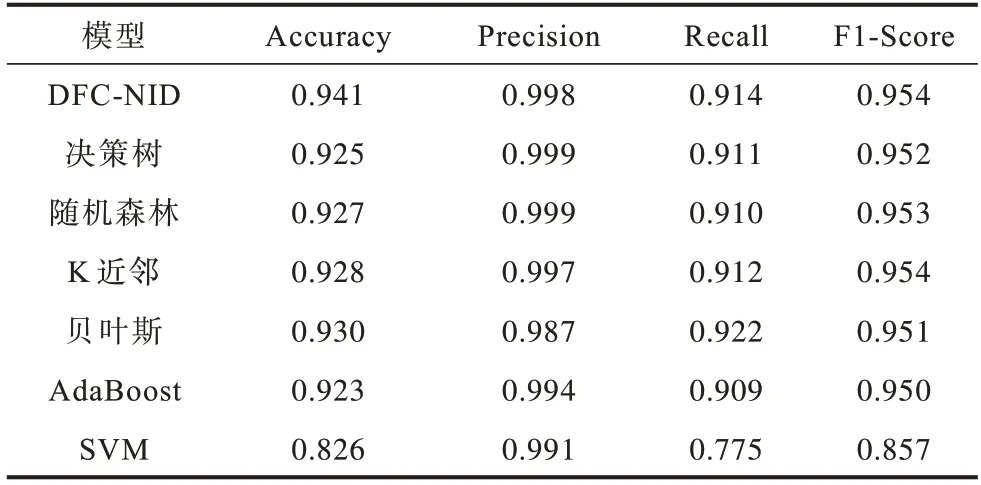
表4 不同模型的實驗結果對比Table 4 Comparison of experimental results of different models
表5 對比了DFC-NID 與近兩年提出的網絡入侵檢測模型[28-30]的準確率。從表5 可以看出,與現有模型相比,本文DFC-NID 模型在入侵檢測中取得了更高的準確率。
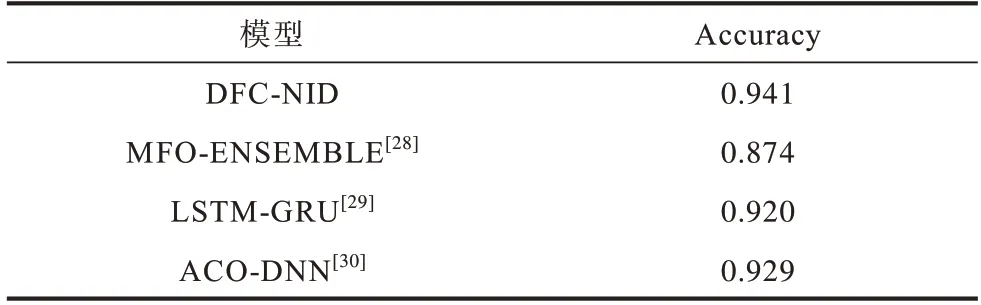
表5 網絡入侵檢測模型準確率對比Table 5 Comparison of accuracy of network intrusion detection models
結合表4 與表5 可以得出,本文所提DFC-NID模型在網絡入侵檢測中具有先進性和有效性。
3.3.2 模型魯棒性實驗
為了驗證DFC-NID 的魯棒性,實驗針對不同的攻擊類別對不同數據集進行多分類實驗,其中包括正常類與DoS、Probe、U2R、R2L 這4 個攻擊類。實驗結果如表6、表7 所示,從中可以看出,在NSLKDD 數據集上DoS、Probe 與正常類的準確率均在0.946~0.977范圍內,在KDDCup99數據集上DoS、Probe 與正常類的準確率均在0.987~0.998 范圍內,即在不同數據集上DFC-NID 對于DoS、Probe 與正常類的檢測都有較高的準確率,證明DFC-NID 具有良好的魯棒性。
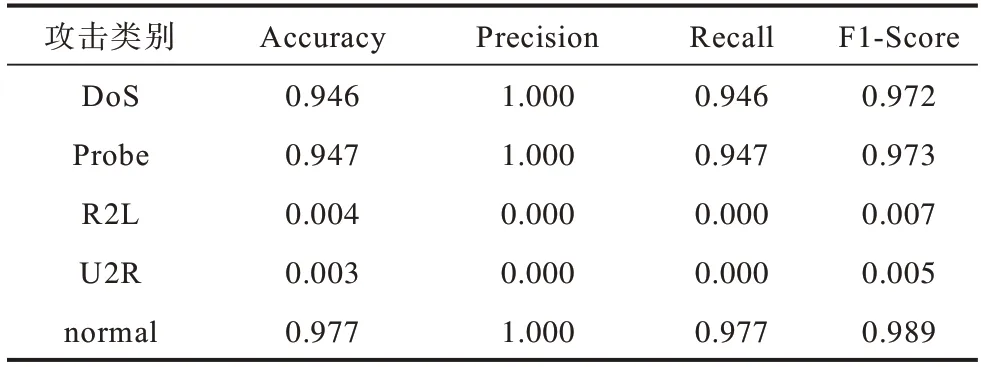
表6 NSL-KDD 數據集的五分類結果Table 6 Five classification results of NSL-KDD dataset
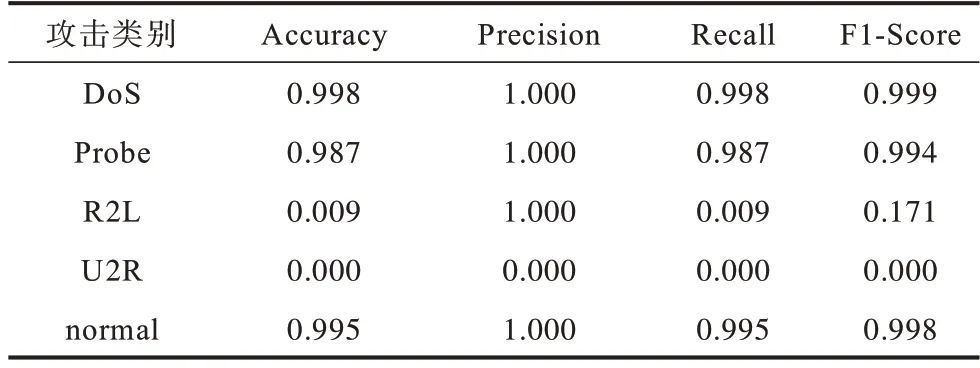
表7 KDDCup99 數據集的五分類結果Table 7 Five classification results of KDDCup99 dataset
從表6、表7 中還可以看出,當只考慮2 類(正常類和攻擊類)時,檢測精確率較高。由于R2L 和U2R可供訓練的樣本有限(如表3 所示,R2L 和U2R 的數據量都太過稀疏),因此在實驗中取得的結果不太穩定。盡管如此,從實驗結果中還是可以明顯看出,DFC-NID 模型對于數據量大的攻擊類別能夠取得很高的準確率、精確率、召回率和F1 分數。
3.3.3 聯邦學習對比實驗
為了驗證DFC-NID 所使用的聯邦學習框架在網絡入侵檢測中的優越性,實驗將DFC-NID 與不使用聯邦學習框架而只使用DNN 通用模型的情況(稱為NO-FC 模型)進行對比。其中,DFC-NID 中設置5 個子服務器作為參與方,并將數據集隨機分為5 個部分分別發送給子服務器用于各自的本地訓練。在網絡入侵檢測模型評估中,時間效率也是體現模型性能的一個重要因素,因此,實驗還測量了DFC-NID模型與對比模型所需的訓練時間,實驗結果如表8所示。

表8 聯邦學習對比實驗結果Table 8 Comparative experimental results of federated learning
由表8 可以看出,相比不使用聯邦學習框架的NO-FC 模型,DFC-NID 模型在測試集上的準確率與召回率有所提升,且DFC-NID 減少了83.9%的訓練時間。因此,DFC-NID 模型可以在保持高準確率的同時大幅縮短訓練時間。另外,由于DFC-NID 模型在訓練時只需要傳輸模型參數,數據集僅在子服務器上進行訓練,因此DFC-NID 模型能更好地保障數據的安全性。
4 結束語
為在復雜網絡環境中對多樣化的網絡入侵方式進行快速準確的檢測,本文提出一種基于深度神經網絡和聯邦學習的入侵檢測模型DFC-NID。利用聯邦學習框架使多服務器協作參與,在縮短訓練時間的同時確保數據的安全性。使用DNN 作為通用模型自動提取并高效學習數據特征,最后通過Softmax分類器得到預測結果。實驗結果表明,DFC-NID 的準確率達到94.1%,高于MFO-ENSEMBLE、LSTM-GRU等分類模型,在攻擊類DoS與Probe上,DFC-NID 的準確率最高達到99.8%與98.7%,取得了很好的檢測效果。與此同時,相較不使用聯邦學習的對照模型,DFC-NID 減少了83.9%的訓練時間并能保持較高的準確率與召回率。在聯邦學習機制下,每個參與方之間數據不互通,因此,DFC-NID 能夠很好地保證數據的安全與隱私。下一步將對小樣本入侵檢測問題進行研究,提升針對稀疏數據的攻擊類別檢測效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
