基于蟻群參數優化的LightGBM輻射源個體識別*
2023-02-08 02:31:16顧楚梅曹建軍王保衛徐雨芯
計算機工程與科學 2023年1期
顧楚梅,曹建軍,王保衛,徐雨芯
(1.國防科技大學第六十三研究所,江蘇 南京 210007;2.南京信息工程大學計算機學院網絡空間安全學院,江蘇 南京 210044)
1 引言
無線通信領域中,輻射源發出的信號不僅包含了所需的信號信息還承載了輻射源內部器件的固有硬件信息,通過提取這部分信息特征來識別不同輻射源個體的過程稱為輻射源個體識別SEI(Specific Emitter Identification)[1]。SEI一般由3個步驟組成:對接收到的原始輻射源信號進行預處理;從預處理后的信號中提取輻射源物理層本質細微特征,即射頻指紋RFF(Radio Frequency Fingerprint)特征;使用分類器識別信號,以確定發射此信號的輻射源個體[2]。由于射頻指紋的可測性、唯一性和不可篡改性,SEI被廣泛應用于軍事通信、情報偵察、電子對抗、無線網絡安全和設備診斷等軍用和民用領域[3]。但是,輻射源信號數據量大、提取到的射頻指紋特征維數高等問題增加了輻射源個體分類識別的難度,如何在降低特征維數的同時提高輻射源個體識別正確率是一個至關重要的問題。
通常使用特征選擇FS(Feature Selection)方法來解決上述問題。特征選擇旨在根據某種評價標準從原始特征空間中消除不相關和冗余特征,選出高相關性特征組成特征子集,以獲得比使用所有特征更好的性能[4]。特征選擇方法通常分為3類:過濾式、封裝式和嵌入式。過濾式方法通過評估每一特征的鑒別能力過濾掉鑒別能力差的特征。該方法運算時間短、獨立于學習算法且具有高泛化性,但依賴具體的度量標準。典型的過濾式特征選擇方法有方差分析、互信息和卡方檢驗等[5]。封裝式方法由搜索策略和學習算法組成,將特征選擇封裝到學習算法中,通過學習算法的預測結果進行評估,并使用搜索策略調整特征子集。該方法所選擇的特征子集性能高且考慮了特征間的相互關系,但計算復雜度高。典型的封裝式方法有遞歸特征消除等[6]。嵌入式方法將特征選擇嵌入到學習算法中,學習算法結束的同時也得到了特征的重要性值。該方法效率較高、特征分辨力好,但依賴于指定學習算法。典型的嵌入式方法有:基于懲罰項的方法,例如Lasso等;基于樹模型的方法,包括決策樹DT(Decision Tree)、隨機森林RF(Random Forest)、梯度提升決策樹GBDT(Gradient Boosting Decision Tree)、極端梯度提升XGBoost(eXtreme Gradient Boosting)和輕量級梯度提升LightGBM(Light Gradient Boosting Machine)等[7]。
嵌入式特征選擇方法解決了過濾式方法結果中冗余度較高及封裝式方法計算復雜度較大等問題,逐漸成為了特征選擇的研究熱點。文獻[8]為改進現有的網絡入侵檢測多分類方法,提出了一種融合RF和GBDT的入侵檢測模型,首先使用GBDT對特征進行重要性排序,并使用遞歸特征消除法進行特征選擇,然后使用RF進行特征變換,分類器選用GBDT,最后驗證了該方法的優越性。文獻[9]提出了一種基于XGBoost和RF特征選擇的堆疊模型,計算XGBoost模型和RF模型特征重要性值的調和平均數,并將得到的調和平均數作為新的重要性值進行特征選擇。相比于XGBoost和RF等特征選擇方法,該模型的F1值有所提升。文獻[10]提出了一種基于XGBoost和RF相結合的物聯網入侵檢測方法,使用XGBoost對特征進行重要性評分并選出最優特征組成特征子集,使用改進的RF算法進行分類,該模型能有效進行特征選擇并合理分類。文獻[11]針對從傳感器中提取的特征數較多導致在學習過程中可能出現的過擬合問題,使用LightGBM特征選擇方法來減少特征集的維數,實驗結果表明LightGBM方法可以產生比現有Boosting算法更好的結果。文獻[12]設計了一種基于LightGBM的特征選擇方法來加快入侵檢測系統的訓練和測試,根據特征重要性值對特征進行排序,依次選取前h(h∈N*)個特征重要性值大的特征查驗訓練精度直到不再改善,根據實驗結果選取了前12個特征重要性值大的特征構成最優特征子集并輸入到分類器中,不僅有效縮減了特征維度還優化了精度。
上述幾種基于樹的嵌入式特征選擇方法在各自研究背景和數據集上均能得到較優的特征子集。在輻射源個體識別領域,為進一步提高分類識別的正確率和運算效率,本文提出了一種基于蟻群參數優化的LightGBM輻射源個體識別方法ACO-LightGBM(Ant Colony Optimization_Light Gradient Boosting Machine)。該方法結合了提升小波包變換、蟻群算法、LightGBM方法和特征選擇思想,主要過程如下:
(1) 選取12個統計特征參數和標準化相對能量,結合提升小波包分解與重構方法提取特征并構建特征參數體系。
(2) 使用蟻群ACO(Ant Colony Optimization)算法優化LightGBM參數,包括最小葉子節點數據量(χ)、決策樹的數量(δ)、學習率(ε)、L1正則化項的權重(γ)、L2正則化項的權重(λ)和最小葉子節點樣本權重和(η)。參數的取值將影響特征選擇和最終的分類結果。
(3) 使用優化后的LightGBM獲得每個特征重要性值并進行排序,使用序列后向搜索策略進行特征選擇,比較搜索過程中各個特征子集的分類正確率,最后得到最優特征子集。
(4) 采用不同信噪比下的電臺數據集,對比GBDT、XGBoost和LightGBM特征選擇方法,綜合考慮分類正確率和特征個數等評估指標,實驗結果表明本文所提方法性能更優。
2 LightGBM模型描述
針對GBDT方法在處理大數據或高維特征時效率低和擴展性差的問題,研究人員對GBDT算法進行優化,提出了LightGBM。LightGBM中的直方圖(Histogram)、基于梯度的單側采樣GOSS(Gradient-based One-Side Sampling)等算法的提出解決了上述問題[13],且提供了度量標準來衡量模型中特征的重要性。
2.1 直方圖算法構建決策樹
每個樣本信息包含了樣本的特征取值、一階梯度值和二階梯度值。直方圖算法將連續的浮點特征值離散化為k個整數,即將數據劃分為k個區域,每個區域構成一個bin,并構造一個寬度為k的直方圖,如圖1所示,每個bin中所包含的信息為樣本個數、一階梯度之和及二階梯度之和。離散化后的值作為索引在直方圖中累積統計量,遍歷一次數據后,直方圖累積了所有需要的統計量;然后將每一個bin對應的直方圖作為分裂點計算分裂增益,候選分裂點個數為bin個數減1,遍歷尋找最優分裂點。直方圖算法優化了GBDT等算法按照樣本不同取值進行分裂的方法,需要遍歷的分裂點個數更少,且使用整數代替原始數據的浮點值,減少了計算量和內存消耗[14]。

Figure 1 Construction process of histogram圖1 直方圖構建過程
在直方圖基礎上,LightGBM使用了帶有最大深度限制的按葉子生長(leaf-wise)策略代替GBDT中按層生長(level-wise)的決策樹生長策略。2種生長策略的對比如圖2所示。level-wise策略通過分裂每一層的葉子節點來構建樹,不加區分地處理同一層葉子將消耗大量資源來分裂信息增益較低的節點。而leaf-wise策略從當前所有葉子節點中找到分裂增益最大的葉子進行分裂。相比于傳統方法,leaf-wise在分裂次數相同的情況下不僅避免了大量計算還降低了誤差。為避免leaf-wise方法生長出深度較大的決策樹而引起過擬合問題,通過增加最大深度限制進行約束[15]。
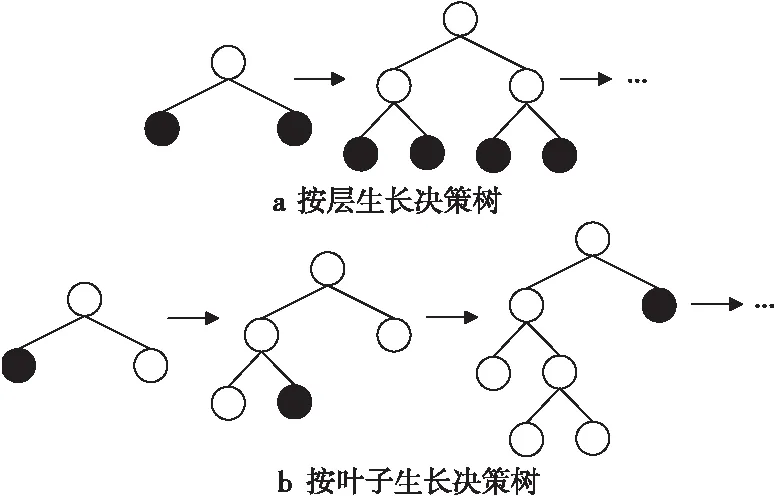
Figure 2 Comparison of decision tree growth strategies圖2 決策樹生長策略對比
LightGBM中的決策樹基于給定的訓練數據集通過多次迭代進行構建,在每一次迭代中使用損失函數的一階和二階梯度信息計算當前樹的殘差并根據殘差值來擬合一棵新樹加入到當前迭代樹中。迭代樹是由Z輪迭代生成的Z棵決策樹疊加而成[16]。
2.2 GOSS算法
GOSS算法的主要思想是排除權重較小的數據,用權重大的數據計算信息增益。GBDT中每個數據雖然沒有原始數據權重,但都有不同的梯度值。根據信息增益的定義可知,梯度較小的數據在計算增益時發揮的作用較小,故可以剔除這些數據而留下梯度較大的數據,但剔除數據通常會改變數據集的分布。
使用決策樹來學習一個從輸入空間Xc到梯度空間G的映射函數,數據集{x1,x2,…,xi,…,xn}的數據個數為n,xi是空間Xc中維度為c的向量。每一次梯度提升迭代中,在當前模型中損失函數負梯度輸出的值表示為{g1,g2,…,gi,…,gn}。GOSS算法首先將數據按照梯度的絕對值從大到小進行排序,然后保留前a個梯度絕對值較大的數據記為特征子集A,從剩余小梯度數據中隨機選取b個記為特征子集B,在集合A∪B上計算特征j在分裂點d的信息增益Vj(d)[17],如式(1)所示:
(1)
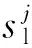
2.3 特征重要性
LightGBM提供了2個度量標準來衡量模型中特征的重要性:split—每個特征在所有決策樹中被分割的總次數;gain—特征在所有決策樹中作為分裂點所得到的信息增益。一個特征在所有決策樹中被分裂的次數越多或得到的信息增益值越大,此特征就越重要,對預測結果的影響越大[18]。
對于特征j,決策樹選擇最優分裂點dj*=arg maxdVj(d)并計算得到最大信息增益Vj(dj*),然后在點dj*處將數據分成左右孩子節點。特征j在單棵決策樹中節點d的重要性計算如式(2)所示:
IMPim=wd·ΔV
(2)
其中,wd表示節點d的數據量與總數據量的比值,ΔV表示節點d分裂后左右葉子節點相比分裂前原節點的信息增益值。將每棵決策樹中特征j的重要性相加得到特征j基于模型LightGBM的特征重要性評分,評分越高,該特征對預測結果越有效[19]。
3 基于提升小波包變換的特征提取
特征提取是輻射源個體識別的關鍵步驟,提取到的特征直接影響到特征選擇和分類器的性能。原始輻射源信號數據量往往很大,輻射源個體識別的關鍵不在于使用所有數據對輻射源進行描述,而在于使用其中有效特征來識別輻射源個體。特征提取旨在通過變換提取到有效的識別特征,使原始信號從高維數據空間轉化到低維特征空間[20]。
輻射源個體識別中特征提取的方法通常有雙譜法、提升小波包分析法、Wigner-Ville和經驗模態分解法等[21]。基于提升小波包分析法有較好的時頻分辨能力和較高的運算效率,本文采用此方法,通過其分解與重構可以獲得更多特征信息,擴大了有效識別特征集合[22]。
本文選取了12個統計特征參數:均值、平均幅值、方根幅值、標準差、有效值、峰-峰值,波形指標、脈沖指標、峰值指標、偏斜度、峭度和峪度指標,并使用標準化相對能量。依據統計特征參數和標準化相對能量,結合提升小波包分解與重構,給出了特征參數體系。對于輻射源發出的信號,首先使用先序分解后序搜索算法[23]對數據進行最優基分解,得到最佳小波包樹;然后,通過分解與重構將最佳小波包樹調整為一棵兩層的滿二叉樹,滿二叉樹的葉子節點分別記作(2,0),(2,1),(2,2)和(2,3),計算4個頻帶內系數的統計特征值和標準化相對能量;接著,分別對每一頻帶內系數進行單支重構,并分別提取相應的統計特征;最后,對原信號重構并提取重構原信號的統計特征。
將重構原信號的12個統計特征參數(標號為1~12)、小波包分解的第2層4個節點系數的各12個統計特征參數(標號為13~60)、4個單支重構信號的12個統計特征參數(標號為61~108)及小波包分解的第2層4個節點系數的標準化相對能量(標號為109~112),共112個特征依次編號。為全面描述輻射源信號信息,在幅值信號、I路信號和Q路信號上分別提取這112個特征并構建特征集set={vi|vi=v1,v2,…,vn},n=336。
4 LightGBM參數優化和特征選擇
為提升輻射源個體識別的正確率,可以對LightGBM的參數進行優化,并使用LightGBM算法獲取特征重要性值進而進行特征選擇,以達到提高算法正確率和運算效率的目的。
輻射源個體識別問題的本質為分類問題。分類器的參數設置和特征子集的選擇會直接影響到最終的分類性能,故使用分類器的分類正確率和所選子集中的特征個數作為目標函數。為提升輻射源個體識別正確率和運算效率,根據目標函數,所求問題可以描述為:(1)LightGBM的6個參數為:最小葉子節點數據量(χ)、決策樹的數量(δ)、學習率(ε)、L1正則化項的權重(γ)、L2正則化項的權重(λ)和最小葉子節點樣本權重和(η),各參數在給定取值范圍內取值;(2)從原始特征集合中選擇基數為q的一個特征子集subsetq;(3)將各參數取值和特征子集subsetq輸入分類器,得到的分類正確率A最大且特征個數q最小。具體數學模型如式(3)~式(5)所示:
maxA(χ;δ;ε;γ;λ;η;subsetq)
(3)
minq
(4)
s.t.|subsetq|=q,1≤q≤n
(5)
其中,A為分類正確率,計算公式如式(6)所示:
(6)
數據輸入測試集前,已知正類(Positive)數據和負類(Negative)數據,模型預測的數據也分為正負2類。可以得出4個指標:樣本真實類別為正類,模型識別結果也為正類TP(True Positive);樣本真實類別為正類,但模型識別結果為負類FN(False Negative);樣本真實類別為負類,但模型識別結果為正類FP(False Positive);樣本真實類別為負類,模型識別結果也為負類TN(True Negative)。
5 求解模型的算法設計
基于蟻群參數優化的LightGBM輻射源個體識別方法框架如圖3所示。首先,對原始輻射源信號使用提升小波包進行特征提取,并使用Z-score標準化對得到的特征數據集進行處理,采用蟻群算法優化LightGBM的6個參數;然后,根據優化后的LightGBM計算得到每個特征的重要性值,在此基礎上使用序列后向搜索策略進行特征選擇,得到最優特征子集;最后,將最優特征子集輸入到分類器中識別輻射源個體。

Figure 3 Framework of specific emitter identification of LightGBM based on ant colony parameters optimization圖3 基于蟻群參數優化的LightGBM輻射源個體識別框架圖
5.1 蟻群算法優化LightGBM參數
為提升輻射源個體識別的正確率,需要對LightGBM的一些參數進行優化。由于蟻群算法具有信息正反饋、采用并行分布式計算和魯棒性較強等優點,本文采用ACO算法優化LightGBM的6個參數。
ACO基于螞蟻覓食行為,設置多只螞蟻分頭并行進行搜索,是一種群智能優化算法。每只螞蟻會在行進的路徑上釋放信息素,信息素量與解的質量成正比。螞蟻路徑的選擇依據信息素濃度大小(初始信息素濃度相同)和啟發式信息,采用隨機局部搜索策略,使當前最優解上的信息素濃度較大,后續螞蟻選擇該解的概率也較大。通過禁忌表來控制合法解,所有螞蟻搜索完一次即迭代一次,每迭代一次需更新信息素,舍棄原螞蟻,新螞蟻進行新一輪迭代[24]。
以輻射源個體識別最大分類正確率作為參數優化的目標,引用文獻[23]中基于圖的螞蟻系統算法求解,根據優化參數問題構造有向圖,如圖4所示。

Figure 4 Construction digraph of parameters optimization圖4 參數優化問題構造圖的有向圖
圖4中,需要優化的參數個數為6,包括2個離散型參數(最小葉子節點數據量(χ)和決策樹的數量(δ))和4個連續型參數(學習率(ε)、L1正則化項的權重(γ)、L2正則化項的權重(λ)和最小葉子節點樣本權重和(η)),共設置7個節點,各參數搜索空間大小為n(n=1001),其中參數χ和參數δ的取值為x1,x2∈{x|1≤x≤1001,x∈Z},參數ε的取值為x3∈{x|0.001≤x≤1.001},參數γ和參數λ的取值為x4,x5∈{x|0.00≤x≤10.00},參數η的取值為x6∈{x|0.01≤x≤10.01},x3取小數千分位,x4、x5和x6取小數百分位。有向圖的邊表示參數的備選取值,路徑映射為一個求得的參數組合。eu1表示參數最小葉子節點數據量(χ)的備選取值集中第u(1≤u≤n)個取值。在節點d1處人為設定螞蟻總數K,每只螞蟻根據有向圖邊上的信息素量和啟發式信息隨機獨立地向下一節點移動,構造可行解,直到所有螞蟻均完成一次行走過程,一次迭代結束,迭代結束后按照一定規則對信息素進行更新。
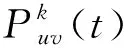
(7)
其中,K表示螞蟻總數量,k=1,2,…,K;τuv(t)為t(t=1,2,…)時刻邊euv上的信息素濃度值;α表示信息素的相對重要程度;ηu為啟發式因子,表示選擇第u個元素的期望程度;β表示啟發式因子的相對重要程度,LightGBM參數優化問題中設定選擇每個候選值的期望程度相同,故暫不考慮ηu,設置β=0;tabuk為螞蟻k的禁忌表,記錄螞蟻走過的邊。
信息素量隨迭代次數動態變化。當一次迭代完成后,按照一定規則對信息素進行更新,如式(8)所示:
τuv(t)=(1-ρ)τuv(t-1)+Qφ′(tabut)
(8)
其中,ρ(0<ρ<1)為信息素揮發系數;tabut為t時刻選擇的參數路徑;φ′(tabut)為要進行信息素增強路徑的目標函數值,為信息素增量公式;Q為常數,用于調節信息素增量的大小。
ACO算法優化LightGBM參數流程圖如圖5所示。在ACO算法優化LightGBM參數的過程中,首先初始化ACO的參數:螞蟻k和螞蟻總數量K、當前迭代次數Nc和迭代總次數N、初始信息素濃度τuv(0)、信息素相對重要程度α、信息素揮發系數ρ(0<ρ<1)、信息素強度常數Q,并設定LightGBM各個參數的取值范圍,其中使用離散化來處理連續型參數。依據路徑選擇概率公式(式(7))構建某個可行解,并根據目標函數來判斷當前解是否為最優解,若是最優值則替換原參數值,若不是則保留原參數值。所有螞蟻搜索完即迭代一次后更新信息素值(式(8))并記錄當前迭代的最優解。算法終止條件為達到設定的迭代次數,算法終止后輸出迭代過程中保留的最優參數組合和最大分類正確率。
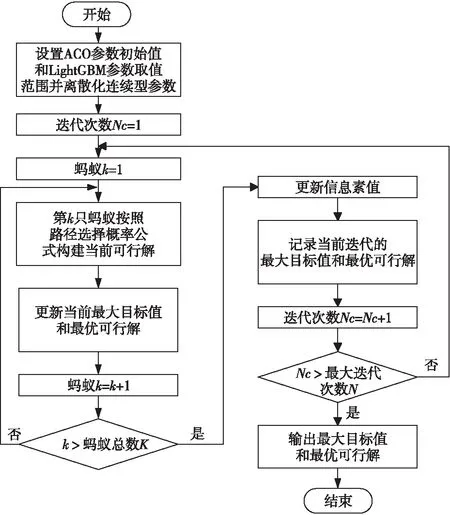
Figure 5 Flow chat of using ACO to optimize the parameters of LightGBM圖5 ACO優化LightGBM參數流程圖
5.2 特征選擇
采用LightGBM構建迭代樹的過程來計算樣本的特征重要性值,并使用序列后向搜索策略[25]進行特征選擇,把分類正確率最高且特征個數最小的特征子集作為特征選擇的結果。
此處特征選擇問題可以分為2個階段:評估特征和搜索特征子集。評估特征時,構造迭代樹模型并利用樹結構對每個特征進行評價。具體過程為:首先使用直方圖算法構建決策樹;然后,根據一階梯度值和二階梯度值來確定分割點,每次都選取具有最大信息增益的特征進行分割,并在每層分裂時使用貪心方法選取最佳分割點。一個特征可能被分割多次,特征被分割的次數越多,整棵樹的信息增益就越多,在特征選擇過程中優先考慮選取這些特征。在搜索特征子集階段,首先將評估特征階段得到的重要性值進行排序;然后采用基于LightGBM特征重要性值的序列后向搜索策略進行特征選擇,即對于按照重要性排序后的特征全集,每次剔除一個重要性最低的特征得到一個特征子集,綜合考慮基于該特征子集的分類正確率和子集中特征的個數來確定最優特征子集。
6 實驗與結果分析
6.1 數據準備
實驗在1臺i7-4770 3.40 GHz 4核處理器、24 GB內存的電腦上運行,開發環境為Python 3.8。
實驗數據來源于2個相同型號的電臺輻射源,采集環境為無噪聲環境,2個電臺發出的信號在10種不同的采集狀態下獲得,10種采集狀態下的信號具體參數如表1所示。

Table 1 Signal parameters
原始數據在無噪聲環境中采集得到。為驗證所提方法在噪聲數據上的效果,添加高斯白噪聲將信噪比分別調整為10 dB和5 dB,并分別進行特征提取得到相應特征集合set10dB={vi|vi=v1,v2,…,vn}和set5dB={vi|vi=v1,v2,…,vn},n=336。
6.2 特征值標準化
為統一數據樣本的數量級、增加可比性及加快算法的收斂速度,對特征值進行Z-score標準化處理[26],如式(9)所示:
(9)

Z-score標準化將數據轉換到某個范圍,且不會改變原始數據的排列順序。標準化后,不同數量級的特征在數值上進行了統一,尋優過程更為平緩,更容易正確地收斂到最優解。
6.3 基于LightGBM重要性度量的特征選擇
對于無噪聲特征集合setoriginal={vi|vi=v1,v2,…,vn},n=336,根據式(1)和式(2)計算每個特征的重要性值,圖6繪制出了前20個最重要特征的特征標號-特征重要性值柱狀圖[27]。
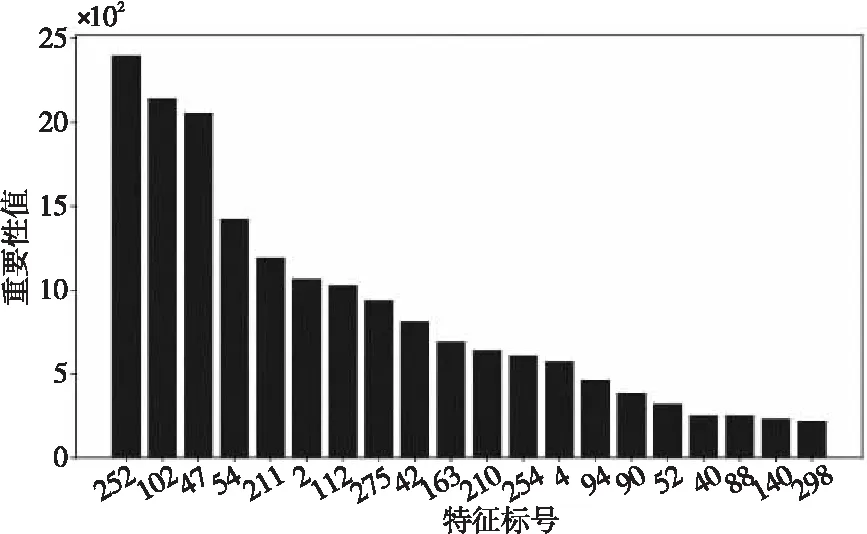
Figure 6 Ranking of features according their importance圖6 特征重要性排序
為獲得最優特征子集,將計算得到的特征重要性值從小到大進行排序,并使用序列后向搜索策略進行特征選擇。每次將重要性值最低的特征刪除得到相應的特征子集,并計算基于該特征子集的分類正確率,綜合考慮該分類正確率和特征子集的大小選出最優特征子集。特征選擇的結果如表2所示。

Table 2 Results of feature selection
表2中,當特征重要性值為0時,表示將所有特征輸入到分類器的分類正確率為98.0%;剔除重要性低的特征可以有效提高分類性能,當選擇前28個重要性值大的特征,并將這28個特征組成的特征子集輸入到分類器中時得到最高正確率98.8%。由此可見:高維特征集中包含的不相關或冗余特征會影響模型性能,使用特征選擇方法不僅提高了輻射源個體識別的分類正確率,同時特征維數的減少也提高了運算效率。
6.4 蟻群算法優化LightGBM參數
為提高輻射源個體識別的分類正確率,使用蟻群算法來優化LightGBM參數。待優化的參數信息如表3所示。

Table 3 Parameters of LightGBM to be optimized
首先初始化蟻群算法的參數:螞蟻總數量K=100,迭代總次數N=100,初始信息素濃度τuv(0)=1,信息素相對重要程度α=1,信息素揮發系數ρ=0.8,信息素強度常數Q=1。基于噪聲信號數據集,利用蟻群算法對LightGBM模型參數進行優化后,輻射源個體識別正確率隨蟻群算法迭代次數的變化趨勢如圖7所示。

Figure 7 Curve of accuracy of SEI changing with the iteration times of ACO圖7 輻射源個體識別正確率隨ACO迭代次數變化曲線
從圖7可以看出,利用ACO優化后的LightGBM模型可以獲得比未優化模型(98.0%)更高的分類正確率。隨著迭代次數的增加,分類正確率逐漸增加,在迭代次數為80時達到收斂,此時搜索到LightGBM模型的最優參數組合,最高分類正確率為98.9%。采用ACO優化后得到的LightGBM參數取值如表3所示。
6.5 特征選擇方法對比分析
對比方法使用基于樹模型的嵌入式特征選擇方法:GBDT、XGBoost和LightGBM。GBDT是集成算法Boosting的一種,每次訓練的目的是找到一個能夠減少擬合殘差的函數,在獲得訓練結果的同時可以得到每個特征的重要性值;XGBoost是GBDT的改進方法,具有速度快和支持自定義損失函數等優點;LightGBM是GBDT的改進方法,在不降低預測正確率的同時,大大加快了預測速度并降低了內存消耗。
使用上述3種對比方法與本文方法ACO_LightGBM在無噪聲信號數據集上進行特征選擇,各方法所得的分類正確率與特征子集中特征個數q(特征個數最大取值為336,該值較大,故還取q=21,41,61,81,101,121,141,161,181,201,221,241,261,281,301,321進行實驗驗證)的關系如圖8所示。
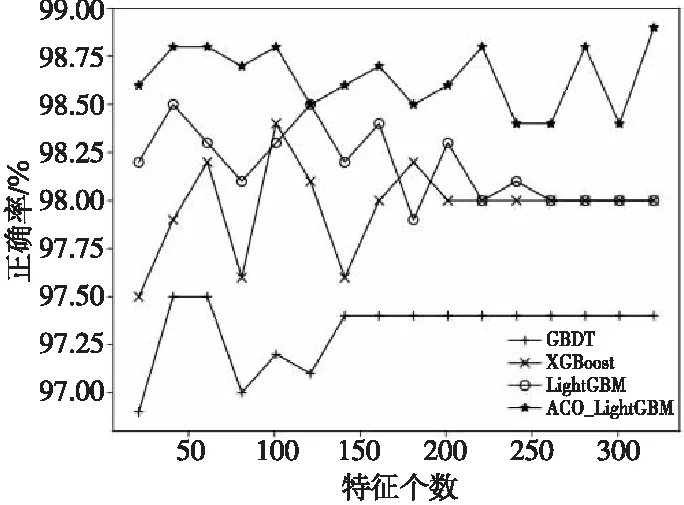
Figure 8 Accuracy comparison of classification using different feature selection methods圖8 特征選擇分類正確率對比
從圖8可以看出,當特征個數q相同時,相比于GBDT、XGBoost和LightGBM,使用ACO_LightGBM特征選擇方法選出的特征子集輸入到分類器中可以得到最高正確率,使用GBDT方法得到的正確率最低。這說明使用ACO_LightGBM方法選出的特征子集更能表示電臺的本質特性,從而能區分2個電臺,進而分析電臺的危險等級,在現代數字化信息戰場取得優勢。隨著特征個數q的增加,使用各特征選擇方法的分類正確率總體上呈現先增后減或先增后趨于平緩的趨勢,這也滿足了特征選擇的目標,即在剔除不相關和冗余特征的同時提高分類正確率。
在3個數據集setoriginal、set10dB和set5dB上分別進行蟻群算法優化LightGBM參數和特征選擇等實驗,并分別使用對比方法和本文ACO_LightGBM方法得到最優特征子集,實驗結果如表4所示。
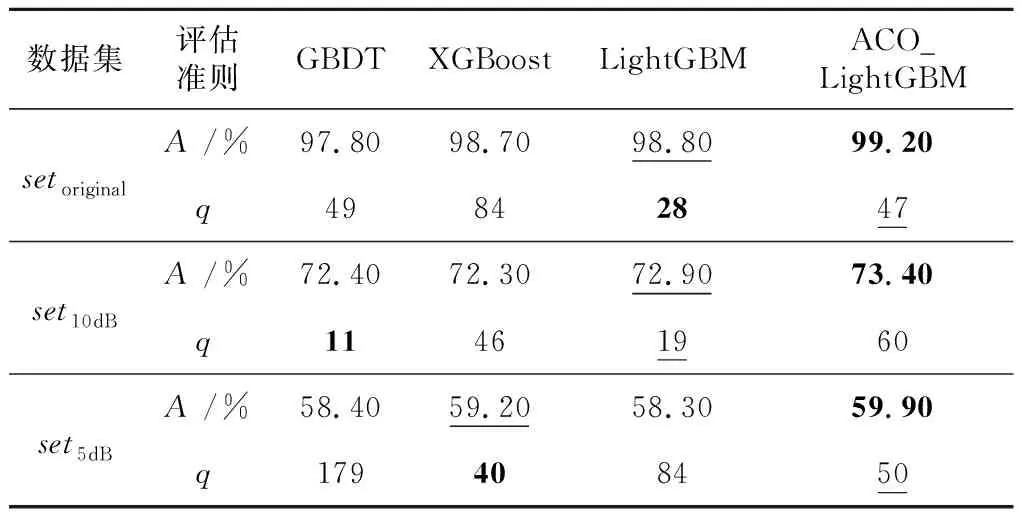
Table 4 Performance comparison of classification using different feature selection methods
表4中,加粗值為最優值,下劃線值為次優值。可以看出,ACO_LightGBM方法所得的最優特征子集的分類正確率在3個數據集上均優于對比方法的,最優特征子集的特征個數也為一個相對較小的值。對于數據集setoriginal,ACO_LightGBM方法得到的分類正確率相比于GBDT、XGBoost和LightGBM方法的分別提高了1.40%,0.50%和0.40%,特征個數為次優值;對于數據集set10dB,ACO_LightGBM方法得到的分類正確率分別提高了1.00%,1.10%和0.50%,但特征個數最多;對于數據集set5dB,ACO_LightGBM方法得到的分類正確率分別提高了1.50%,0.70%和1.60%,特征個數為次優值。結合圖8和表4可知,當特征個數q取4種方法的最優值時,ACO_LightGBM方法得到的分類正確率仍最大,綜合考慮分類正確率和特征個數,ACO_LightGBM方法的性能最優。
7 結束語
為提升輻射源個體識別的正確率和運算效率,提出了一種基于蟻群參數優化的LightGBM輻射源個體識別方法,該方法有以下2點貢獻。
(1) 使用提升小波包變換提取特征并對特征值進行標準化,以最大分類正確率和最小特征子集規模為目標函數,建立了使用LightGBM參數優化和特征選擇的數學模型。
(2) 使用蟻群算法,基于參數優化問題的構造圖,采用路徑選擇概率公式進行路徑搜索,利用信息素更新公式,求解了LightGBM參數優化問題;使用基于LightGBM特征重要性值的序列后向搜索策略求解了特征選擇問題。
實驗結果表明,相比于GBDT、XGBoost和LightGBM方法,本文提出的基于蟻群參數優化的LightGBM輻射源個體識別方法選出的特征子集分類正確率最高,同時特征個數也相對較少,為提高輻射源個體識別正確率和運算效率提供了新思路。
未來的工作主要包括:在嵌入式特征選擇方法的基礎上,如何在保證分類正確率的同時進一步縮減特征子集規模;為進一步提升輻射源個體識別的正確率,考慮其他特征選擇方法,如封裝式方法和混合式方法等;對比信號數據集在不同分類器上得到的分類結果,以確定最適合信號數據集的分類器。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
