基于深度學習的公路裂縫病害自動識別技術研究
2023-02-15 13:19:38隆星
工程建設與設計 2023年2期
隆星
(1.中國鐵建投資集團有限公司,廣東 珠海 519031;2.西安交通大學人居環境與建筑工程學院,西安 710049)
1 引言
截至2021年年末,我國路網總里程已達到528.07萬km,高速公路達到16.91萬km[1],居于世界前列。密集的公路網極大地便利了區域間的信息交流和資源分配,從而促進了經濟社會的快速發展[2-3]。然而,在車輛和周圍環境等因素的綜合作用下,高速公路在使用過程中會不可避免地出現裂縫、車轍、坑槽等病害,這些病害會對路面壽命、公路運營產生嚴重影響,甚至會造成交通事故,因此,對公路路面病害的檢測和養護成為管理部門的任務和日常工作。采用傳統的人工視覺檢測路面病害流程復雜、效率低,并且伴隨著大量的人工成本。在計算機視覺和圖像處理技術發展初期,研究者多通過直方圖估計、局部二值模式、Gabor濾波、形態學特征、支持向量機(Support Vector Machine,SVM)等方法檢測路面病害,取得了不錯的精度。但這些方法存在一些共性的弊端,就是對圖像的質量要求較高,對外界的抗干擾能力較差,模型的結果受光照、背景和裂縫的對比度、非裂縫等其他類別像素等的影響較大,極大地限制了路面病害的檢測準確度和效率。
近年來,深度學習方法因其在非線性、模糊系統中的突出表現成為解決復雜預測、分類問題的一項重要工具。在目標檢測、語義分割、圖像分類、逐幀視頻分類、文本處理、時間序列分析等領域都得到了廣泛的應用。卷積神經網絡被定義為前饋神經網絡的一個子類,具有池運算和卷積層的特殊性,在捕獲局部和全局特征以進行項目抽象和表示方面具備良好的性能,可以較好地抑制噪聲的影響,從而被廣泛應用于公路裂縫的識別中。封筠等[4]提出了一種多級卷積神經網絡的路面裂縫檢測模型,通過網絡級聯的方法在保證裂縫圖像全部召回的前提下,取得了更優的檢測結果,為路面裂縫圖像漏篩的問題提供了解決思路。晏班夫等[5]引入了一種目標檢測中的快速區域卷積神經網絡算法來快速識別病害種類、位置和面積,該方法使路面表觀病害檢測的效率和精度都得到了極大的提高。侯越等[6]提出了卷積自編碼預訓練深度聚類算法,利用傳統圖片幾何變換和CAE網絡重構增強圖片兩種方法對小樣本路面圖片數據集進行擴充,提高了DCEC深度聚類方法的準確率。曹錦綱等將注意力機制引入編碼器-解碼器(Encoder-Decoder)框架中,提高了裂縫檢測模型的效率和裂縫識別定位的準確性[7]。
以上研究雖然對裂縫識別有著較高的識別精度和較快的速度,但模型的抗干擾能力以及對裂縫邊緣分割的準確率有待提高。本文基于VGG網絡和SegNet網絡提出一種裂縫分割算法模型(DeepCrack),在保證裂縫識別和定位準確度的同時具備較好的魯棒性。可為新疆及干旱地區高速公路的建設和路面養護提供有價值的建議和理論性的指導。
2 研究區概況和數據預處理
2.1 研究區概況
新疆深處內陸,氣候干旱,地形封閉,屬于典型的大陸性干旱氣候,冷暖季和晝夜溫差極大,呈現出極端性大溫差特征,該區域長、短時溫變極易引起路基路面病害。極端的自然條件對新疆地域的公路建設與維養提出了更高的要求和標準。
本文通過道路綜合檢測車對G30連霍高速與G7連接的S303線K40~K77段以及G312線哈密段[見圖1(a)]進行路面病害樣本的采集,共采集3 000余個樣本數據,主要包括裂縫、坑槽、車轍、龜裂等病害。對采集到的樣本進行統計,其中大多為裂縫病害。裂縫根據其延伸方向與道路行車方向是否垂直可以分為橫向裂縫和縱向裂縫,隨著使用年限的增加和車輛的碾壓,會逐漸形成網狀裂縫[見圖1(b)~(d)]。裂縫的統計學特征經常被作為評估路面健康狀況的指標,實現公路裂縫的高效、智能檢測對道路養護具有重要意義。
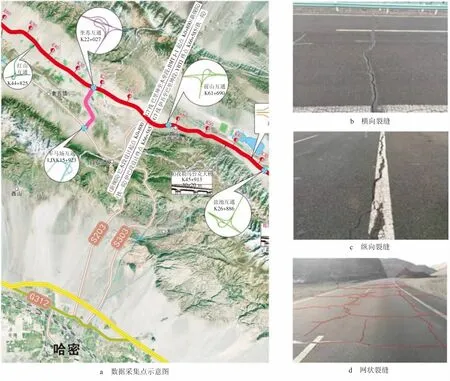
圖1 裂縫數據采集位置及裂縫分類
2.2 數據預處理
采集到的裂縫數據通過預處理步驟轉換為符合模型輸入要求的圖片。首先將樣本分辨率統一為31 361 933像素。通過光照變換和多角度變換對樣本數據進行擴充,盡量減弱光照、拍攝角度等因素對樣本質量的影響。然后通過分割和重采樣的方法(見圖2)將樣本統一為512 512像素大小的圖片,分割時盡量確保裂縫在整張圖像中占更多的比例,避免裂縫像素和非裂縫像素比過于不均衡。最后使用OpenCV將圖像轉換為單通道灰度圖(0~255)。這里將樣本劃分為1 799個訓練數據,100個驗證數據和100個測試數據。

圖2 所采集裂縫原始圖像預處理分割
3 基于深度學習的路面裂縫識別
本論文提出的裂縫識別深度學習模型基于VGG網絡中塊的設計思路和SegNet網絡中編譯碼器(Encoder-Decoder)思想進行設計,最后通過多尺度誤差函數對模型識別精度進行量化評價。
VGG網絡中塊的設計思路將圖像信息的識別和提取逐級抽象化,將特定卷基層和池化層組成可重復的單元塊。圖像在該單元塊時,信息抽象化程度逐級提高,形成一系列不同尺度的中間處理結果。這些中間處理結果保留了裂縫等缺陷圖像對噪聲敏感但邊界清晰的低尺度信息和對噪聲魯棒性強但邊界模糊的高尺度信息。
這些中間處理結果根據通過Encoder-Decoder還原成與輸入圖像同大小的數據以進行該尺度下的誤差分析,由此可以得到裂縫圖像不同尺度下的誤差。通過將這些多尺度下的誤差圖進行巧妙融合,組成新的誤差函數,網絡每次訓練以減少該多尺度誤差為目標。由于模型同時考慮了裂縫的具象信息(邊界信息)和抽象信息(是否為裂縫),對于裂縫的識別準確率和定位準確率有明顯提升。
3.1 模型結構
如圖3所示,經過圖像預處理后的輸入數據會首先經過5個由3個卷基層和1個池化層組成的編碼器(Encoder)網絡塊,從而得到裂縫圖像在5個不同尺度下的信息。每經過一層編碼操作,裂縫信息的抽象化程度會更高,其抗干擾能力逐級增強,但是裂縫位置、寬度等信息會逐級丟失。該過程可以看作是對圖像進行多層Encoder的過程,目的是增強裂縫識別的準確率。
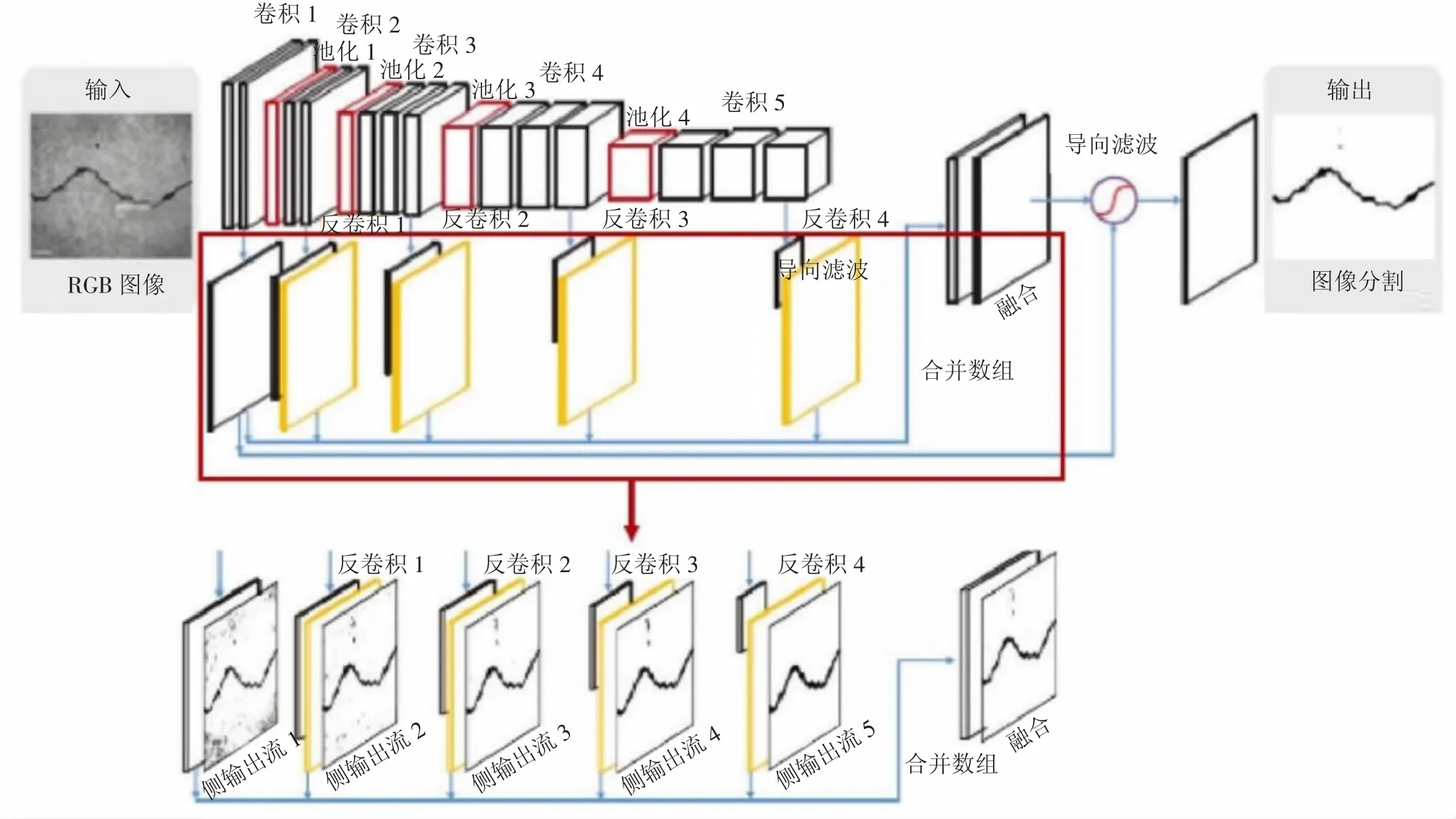
圖3 裂縫圖像處理過程
隨后,經過編碼后的圖像信息會通過與Encoder對稱的解碼器(Decoder)網絡。圖像信息的中間輸出結果由通過Decoder網絡恢復成與輸入數據同尺寸大小的圖像。可以逐級增強裂縫的位置、寬度等具體信息,提高識別分割結果的邊界準確度。由于經過Decoder網絡得到的裂縫圖像中輸出結果尺寸與原始圖一致,從而可以得到該尺度下的裂縫識別誤差圖。
在每次卷積操作后,會對特征圖進行小批量標準化操作,從而得到5張特征圖,分別為裂縫圖像在5個尺度下的誤差信息。通過將這5張誤差特征圖進行融合,可以有效提升線狀目標的檢測準確率。為了將不同尺度下的誤差特征圖融合,采用的卷積層調整特征圖的尺寸和通道數。經過上述操作可以得到同一尺寸的不同尺度的下的裂縫預測特征圖。將每個尺度下得到的誤差圖進行融合和導向濾波,最終得到模型的整體預測誤差函數,通過最小化誤差函數對網絡模型進行訓練,得到最終的預測模型。生成結果是表示裂縫位置的二值圖,裂縫與非裂縫像素值分別為1和0。
3.2 損失函數
給定包含N張圖像的訓練數據集S={(Xn,Yn),n=1,…,N},其 中代 表 原 始 輸 入 圖 像表示與Xn相對應的真實裂縫標簽圖,I表示每張圖像中的像素數目。目標是訓練網絡從而產生能達到真實結果的預測圖。在編譯碼器(Encoder-Decoder)結構中,K表示卷積級數,故在階段生成的特征圖可以表示為F(k)=其中k=1,…,K。由多尺度融合得到的特征圖可以被表示成
裂縫檢測是一個二分類問題,因此,采用交叉熵損失函數來定量預測誤差。由于裂縫與非裂縫像素數量分布不平衡,在網絡結構中給裂縫像素增加更多的權重。從而定義像素級別的預測誤差為:
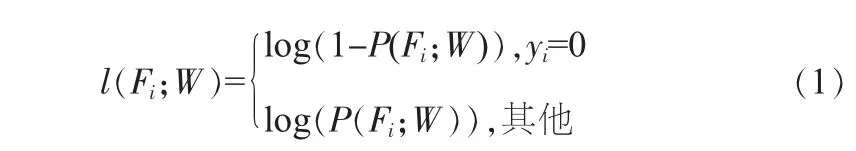
式中,Fi為網絡特征圖中像素點i的輸出;W為網絡層中標準參數的集合;P(F)為標準sigmoid函數,用于將特征圖轉換成概率密度圖。綜上,總誤差可以表示成:

4 結果分析
本論文的實驗環境為CPU:Intel(R)Core(TM)i9-10900KF CPU@3.70 GHz,RAM:32G。每次預測過程中,一次循環需要大約2.4 s,可通過多線程并行。
4.1 評價指標
根據樣本真實類別和模型預測結果,將樣本分為TP(True Positives)、FP (False Positives)、TN (True Negatives)和FN(False Negatives)。TP和FP表示對裂縫像素的預測是否正確,TN和FN表示對非裂縫像素的預測是否正確。并基于此計算精確度(Precision)、召回率(Recall)作為評估模型準確性的指標,公式為:

精確度-召回率(P-R)曲線是分別以精確度和召回率作為縱坐標和橫坐標繪制的曲線。平均準確率(Average Precision,AP)是對P-R曲線的積分。
4.2 對比實驗
對比實驗選取兩個數據集CRKWH100和CrackL315作為測試集,分別包括100張和315張路面圖片。將本文提出的方法與HED,RCF等6種深度學習網絡在兩個數據集上進行實驗,結果見圖4。結果表明:經典邊緣檢測網絡HED和RCF利用VGG16作為特征提取網絡,并在不同尺度下完成特征融合。兩個模型在CRKWH100數據集上的AP值為0.909 6和0.907 9,性能上相差不大,而在CrackLS315數據集上HED為所有網絡中性能指標最低。U-Net與SegNet網絡通過特征壓縮與復原實現像素級別的類別標注。在CRKWH100數據集上,U-Net比SegNet的AP值高出5.25%。裂縫分割算法模型(DeepCrack)通過實現SegNet編解碼端的特征融合與多重損失的監督訓練達到了更好的效果,但融合特征并沒有進行有效篩取。本文提出的單尺度多層次特征融合模塊和三重注意力模塊的改進策略,使新的DeepCrack在CRKWH100數據集上AP平均準確率達到0.9408,優于當前最佳的結果。此外,在CrackLS315數據集上較原先的DeepCrack在AP值提升了0.71%,獲得了最佳效果,進而證明本文提出的模型具有更好的泛化性。

圖4 CRKWH100數據集和Cr ackLS315數據集上測試結果的P-R曲線
將該網絡模型對采集到的隧道裂縫圖像進行識別,識別結果如圖5所示。

圖5 裂縫識別效果圖
5 結論
本論文使用在京新高速(G7)沿線的高速公路上采集的公路裂縫影像制作了公路裂縫的標準數據集,并提出了一個深度學習模型用于裂縫的識別。該神經學習網絡模型基于VGG塊設計思想和編譯碼器提取多尺度抽象信息為基礎,可以實現裂縫的像素級識別定位。在CRKWH100和CrackL315兩個標準測試數據集中的準確率、召回率,F-measure結果均要優于目前其他幾個主流模型。說明該方法可以滿足工程實際檢測的需求,同樣的,該方法在橋梁裂縫檢測、建筑物表面裂縫檢測等方向也具有很好的應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
