基于深度學習的多模態AIGC動畫探究
2023-02-19 05:40:30歐陽春雪
現代電影技術 2023年1期
歐陽春雪
四川美術學院,重慶 401331
1 引言
人工智能 (Artificial Intelligence,AI)是使計算機或機器模擬人類的智慧、能力的一項技術,其作為二十一世紀的尖端技術之一,近三十年取得了迅速發展,早已成為人類現代生活中不可或缺的一部分。
學習能力是人類智慧的核心能力,如表1所示,機器學習(Machine Learning,ML)是一種使計算機具有學習技能的技術,也是使計算機具有人類“智能”的關鍵。
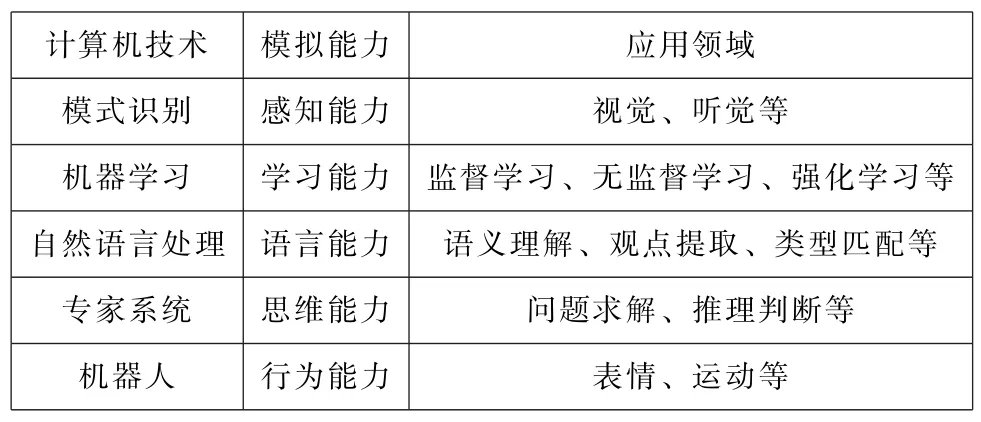
表1 計算機技術與模擬能力[1]
為了真正模擬人腦學習的復雜神經網絡,從機器學習概念中延展出了 “深度學習 (Deep Learning,DL)”。在解決實際問題時,深度學習技術通常與其他技術融會貫通,為AI賦予了更趨自主、更全面的能力。
AI的深度發展與數字內容供給需求的增長使得各個行業的內容生成方式由傳統的專業生產內容(Professionally-generated Content,PGC)、用戶生成內容(User-generated Content,UGC)轉向了人工智能生成內容 (AI-generated Content,AIGC)[2]。
百度創始人兼董事長李彥宏認為:AIGC 已不是單純用于輔助人類進行內容生產的助手,目前AIGC正處于“協作階段”,與人類相互配合完成內容生產;在未來,AIGC將步入 “原創階段”,能夠獨立完成內容創作。[3]
2022年8 月,一幅主要使用文本描述生成的AI畫作 《太空歌劇院》 (Théatre D'opéra Spatial)奪得美國科羅拉多州博覽會大賽數字藝術類別冠軍[4],引起群眾對AIGC藝術創作的思考。
而早在2022年7月的戛納短片電影節(Cannes Short Film Festival),就出現了使用AIGC的動畫短片《烏鴉》(TheCrow),將真人舞蹈作品PAINTED 基于 “文本-圖像-視頻”的多模態轉換,以“世界末日中起舞的烏鴉”形象再創作,獲得最佳短片獎。
據《AIGC深度產業報告》顯示,AIGC未來發展更趨向多模態生成方式,且至2030年,AIGC 市場規模將超萬億人民幣。[5]動畫作為一門具綜合性、商業性的藝術,隨著深度學習與多模態AIGC 的引入,傳統動畫生產方式勢必會面臨沖擊,并迎來新的機遇。
2 技術原理
2.1 NLP預訓練模型
計算機語言是以 “0”與 “1”組成的二進制,計算機要完成與人進行交互的任務必須通過自然語言處理 (Natural Language Processing,NLP)技術。
Transformer的提出最開始用于機器翻譯任務,其基本架構如圖 1 所示,Transformer模型的核心自注意力機制 (Self-attention)使得其相對于RNN①和CNN②等傳統深度學習網絡更擅長處理不同類型的數據,具有更好的并行性與全局性。[6]
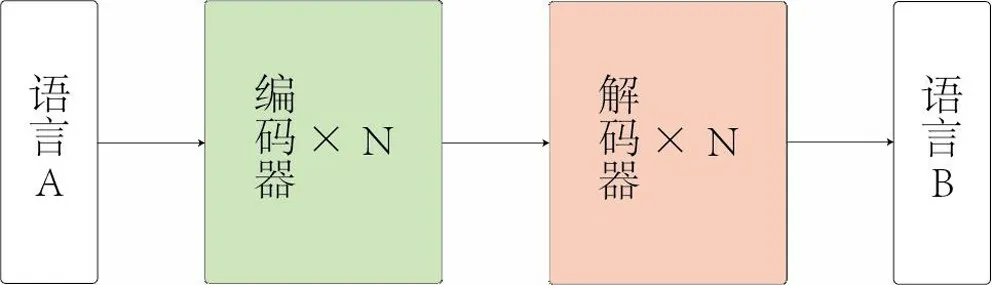
圖1 Transformer模型架構
NLP的核心是語義理解,為保證計算機能夠高效地學習,需要提前建立語義聯系,即預訓練。通過大量含標簽的訓練集對文本語句進行向量化表示[7],在下游的具體應用中再對模型進行參數調優,使得模型能更好地匹配任務[8]。
BERT 是典型的一種預訓練模型,類似于完形填空,隨機遮蓋掉部分文本建上下文語義間的聯系[9]。
2.2 多模態模型
2019年谷歌發布的VideoBERT 將Transformer拓展到“文本-視頻”領域,驗證了Transformer預訓練用于多模態學習的可行性[10]。
2021年Open AI提出的CLIP 模型基于Transformer進行預訓練,分別提取文本與圖像的特征并進行對比,得到“文本-圖像”的相似度,使得兩種不同模態的數據得到關聯。[11]
2.3 生成模型
生成模型用于對數據的建模,生成文本、圖像、視頻等內容,主流的生成模型有生成對抗網絡(Generative Adversarial Networks,GAN)和擴散模型(Diffusion Model)。
2.3.1 生成對抗網絡
GAN 的框架中含兩個模塊:生成器 (Generator)和判別器 (Discriminator)。[12]生成器的任務是將輸入的初始噪聲偽造成一個與真實內容相似的新內容,再由判別器來檢驗偽造內容的真假,當經過數次對峙訓練后,生成內容能夠以最大概率“騙”過判別器時,模型則能夠生成一張足夠“以假亂真”的最優圖像。GAN 的基本原理如圖 2 所示。
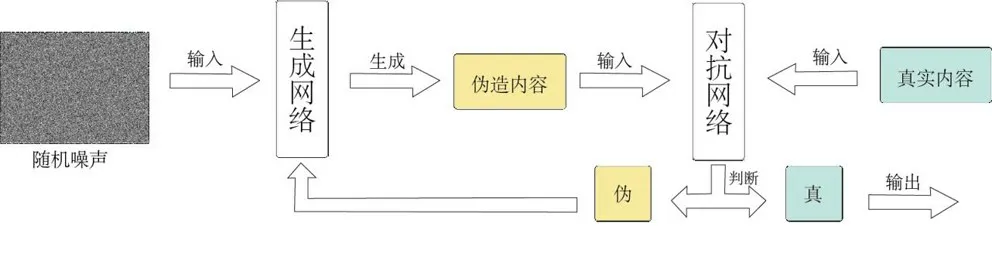
圖2 GAN 原理圖
2.3.2 擴散模型
擴散模型正向是不斷加噪的過程,逆向是根據不同程度的噪聲生成新內容的過程,其原理如圖3,擴散模型試圖學習噪聲分布,其在圖片生成任務中的表現超越了GAN[13]。

圖3 擴散模型對圖形加噪、去噪原理
3 多模態AIGC動畫生成模式與局限
3.1 圖像到動畫的生成
視頻是連續的圖像序列,而動畫是以逐格方式拍攝的畫面連續播放形成的活動影像。“圖像-視頻”的跨模態AIGC視頻與動畫的原理相似,可看作是基于圖像的邏輯組合。
由單個圖像生成關聯圖像后進行插幀或者使用擴散模型補充幀數,但在生成動畫方面效果存在以下問題:
(1)AI 難以把握無邏輯、主觀性語言
由于動畫的視覺語言與創作者的主觀感受息息相關,根據故事想要傳達的內容有不同的表現方式,這樣具主觀性、非規律性的信息難以對計算機進行學習、訓練。
(2)二維圖像難以進行三維空間映射
二維動畫相對于三維動畫更難以讓計算機把控攝像機與對象的空間關系,遮擋、透視變換、角度變換會造成 AI 計算錯誤而導致畫面割裂、變形、拖影等[14]。且由于鏡頭、場景變化多,要得到高準確率的映射需要耗費大量的算力。
(3)運動規律復雜多變
對象的屬性、速度影響變形程度,幀數也會影響運動表現的力度,例如表現力度大的動作時會刻意省略幀數,故不是所有運動都適合高幀數的表現方式。
除由圖像生成連續畫面的視頻外,AIGC 還涉及基于二維圖像生成三維模型以輔助三維動畫創作:
一款用于二次元手繪設定稿動畫化的神經渲染器Co NR (Collaborative Neural Rendering)可實現用較少數量的手繪圖片映射到A-Pose③下的灰模,導入動作序列即可完成手繪角色模型的三維動畫[15]。
谷歌發布的一種端到端的可訓練深度神經網絡PHORHUM 能夠基于單張圖像生成三維模型[16],目前尚未開源。新型2D-3D 算法的提出,為三維動畫建模提供了便利。
雖然二維圖像生成三維模型的技術日益進步,但缺少對動作內容的處理,尚且無法達到依靠硬件設備進行動作捕捉的精度。
3.2 文本到圖像的生成
視頻內容是圖像在時間維度上的疊加,圖片生成算法為動畫內容的生成奠定了基礎。
文本生成圖像的熱門模型有Midjourney、Disco Diffusion、Stable Diffusion、Dall·E 2等。
其基本原理 (以主流模型為例):CLIP 基于Transformer進行無監督預訓練后,會根據擴散模型去噪過程中的圖像評估與文本的匹配度,引導擴散模型生成最符合文本的圖像。
為提高生成圖像的準確度,模型往往支持文本描述與圖片參考共同作為生成圖像的標準 (即 “文本+圖像→圖像”),圖4、圖5、圖6為使用Midjourney模型生成圖像的實例。

圖4 文本描述為:“一位美麗的舞者,身穿舞裙,在莫高窟壁畫前跳舞。”

圖5 文本描述為:“三只劍齒虎,遠處是高山,近處是寸草不生的地,地面有堆積的動物骸骨,背光,夕陽下沉,氛圍凄涼。”

圖6 在圖5基礎上增加了參考圖 (上)生成的4幅圖像 (下)
通過在開源模型試驗后,總結出AIGC 由文本生成圖像的局限性:
(1)AI 生成場景效果普遍優于生成人物
AI 可以模擬細致的顏色、紋理,且場景的排布較人物限制較少,尤其是在遠景時,不用考慮過多透視問題。人物在高透視、多遮擋條件下難以生成符合要求的圖像,其中正確生成手的拓撲結構是AIGC的難題(圖7)。

圖7 Novel AI在生成角色時手與身體結構出現偏差
(2)AI 對訓練樣本少的語義理解不佳
深度學習是建立在大量數據訓練基礎上的,必然涉及無樣本或樣本稀缺的類型,無法建立起文本與圖像的語義聯系。例如,圖4-圖6中的 “莫高窟”“劍齒虎” “寸草不生”“骸骨”等描述被忽略。而對于“佛跳墻 (Buddha Jumps Over the Wall)”“過橋米線 (Crossing-the-bridge Noodles)”等詞在轉換為英文時,AI易僅從字面上理解。
(3)需要參考圖的輔助才能使得AIGC 更加準確
文本單模態的語義限制不夠,越多的描述詞延伸的語義也會越多,對于計算機可學習的樣本也越多;相較于描述詞限定以外的內容由計算機隨機生成來講,圖像可提取的大量特征給了計算機更接近預期的參考。
(4)用戶需要經過長時間的熟悉、學習、嘗試
基于不同模型的底層代碼,用戶的操作方式、表述語言都會有所差異。用戶使用新模型時需要進行詞匯庫的積累和學習,了解其工作原理并掌握更加精準的描述詞;由于AIGC 的隨機性,每次生成均呈現隨機結果,即便使用同樣的描述詞也會呈現不同的最終圖像,需要多次生成嘗試后用戶自主選擇最符合目標的內容;對于有創作專業基礎的用戶來說,獲得理想圖像所消耗的時間成本不一定小于自主創作的時間成本。
3.3 文本到動畫的生成
Disco Diffusion在文本跨模態生成多幅圖像時,支持將不同描述的圖像連接成視頻。雖然AIGC 視頻內容對畫面的銜接平滑流暢,但由于視頻生成技術尚不成熟,只能完成推拉、旋轉等單一的鏡頭切換效果,且動畫內容會有明顯的抖動、變形。
清華大學與智源實驗室聯合發布的Cog Video是首個開源的文本生成視頻模型 (只支持中文輸入),直接采用“文本-低幀視頻對”來對計算機進行訓練,能夠生成較為流暢的短視頻,其生成案例見圖8 。

圖8 Cog Video生成的 “文字-視頻”案例[17]
谷歌團隊連續發布了在視頻分辨率、3D 圖像生成具有優勢的Imagen Video和擅長生成長鏡頭(長達2分鐘以上)講故事的Phenaki,后者在空間透視關系與合理性方面取得了巨大提升 (圖9),但兩者尚未開源。

圖9 Phenaki在講述故事時考慮到了反射、交互、遮擋以及場景過渡[18]
雖然基于文本或 “文本+視頻”生成視頻的AIGC技術在分辨率、流暢性、合理性、故事性各方面都取得了迅速突破,但相較于傳統方式拍攝的視頻/動畫效果還有一定差距。
4 多模態AIGC動畫的前景
4.1 技術層面
(1)構建更廣的語義網絡,應對不同場景的語義偏差
增加AIGC對于上下文及全局的聯系,根據語義推斷最匹配的理解方式,從而使得AI更易掌握動畫視覺語言規律,針對特定事件、背景作出更準確的判斷。
(2)以更少的訓練樣本達成更好的學習效果
提高AI學習效率及遷移運用的能力,減少對監督學習的依賴,降低對訓練樣本較少的內容的誤判率。尤其在“文本-視頻”訓練樣本有限的情況下,高效運用標記信息是AIGC視頻的有利支撐。
(3)二維圖像到三維模型的映射更加精準
對于空間、深度的映射更為準確,為三維動畫模型建模、二維動畫攝像機定位創造基礎,改善動畫主體、鏡頭運動造成的生成內容變形。
(4)提升系統的抗干擾能力及魯棒性
增加AIGC對于空間、角度、遮擋、變形的判斷力,增加對噪聲的抵御力,使得生成內容更趨平滑穩定。
(5)補充常識、邏輯信息
在訓練集中引入常識,篩選有效經驗作為相關參考,權衡龐大額外數據帶來的 “運算效率降低”與“結果邏輯增強”兩者的關系。
4.2 內容層面
(1)作為提供創新思路的參考素材
AIGC動畫擁有基于大數據樣本的優勢,生成內容具有各異性、多樣性、跳躍性,且數字信息具有便于調整的優勢,可輔助創作者尋找創新思路。
(2)作為抽象藝術內容象征
AIGC 動畫系統穩定性不足導致畫面出現非邏輯性的抖動、變換;而這樣的抽象藝術恰好符合用于刻畫意識與夢這樣光怪陸離的表現手法,可利用這種性質作為抽象藝術的體現。
(3)作為動畫序列幀的初始版本
將AIGC圖像作為關鍵幀,或視頻分割為動畫序列幀,手動修改不合理、與目標不匹配的部分,保留并提取可借鑒部分,在此基礎上進行二次創作。
4.3 市場層面
(1)引入動畫制作流程
對于生成文本而言,可服務于編劇;對于生成圖像而言,可服務于概念設計;對于生成動畫而言,可服務于原畫師、動畫師。AIGC 技術趨于成熟后,有望正式作為動畫制作流程的一部分,或增加基于AI 訓練、AI 描述的額外崗位。
(2)改變市場供給關系
需求者與創作者身份會相互流通:部分原本不具供給實力的需求方利用 AIGC 轉變為內容的提供方,對于部分創作者不善使用AIGC 又渴望嘗試,會流向需求一方。
(3)增加崗位對綜合性人才的粘性
動畫的綜合性特征由于人工智能的飛速進步而得到顯現,對于崗位人才的能力需求不再是單一能力,而更趨向于綜合性方向。
4.4 倫理層面
(1)版權問題
AIGC模型進行學習、訓練的樣本庫來自網絡大量的數據信息,生成內容是基于樣本信息的再創作。雖然部分模型官方以付費方式出售生成內容的使用版權,但對于樣本的原作者是否構成侵權卻無法界定。如將AIGC 投入動畫生產,需在生成內容上調整修改,不直接套用。
目前國內缺少明文條例用以說明AIGC 的版權問題,依照其快速發展的趨勢,可期望于未來完善體制,保障原創者的權益。
(2)安全問題
AIGC追求還原真實性,若被不法分子利用生成違法信息、宣傳虛假內容會造成嚴重后果,模型供應方需對文本敏感詞匯進行屏蔽,產出數據需要第三方合理監管、跟蹤。
4.5 總結
AIGC的跨模態生成、多模態轉換算法真正融入動畫產業生產還需克服一定的困難,但隨著技術與體制的完善,借助AIGC 賦能動畫藝術創作未來可期。
注釋
①循環神經網絡RNN:全稱為Recurrent Neural Network,是一類以序列數據為輸入,按鏈式連接的遞歸神經網絡。
②卷積神經網絡CNN:全稱為Convolutional Neural Networks,是一類包含卷積計算且具有深度結構的前饋神經網絡。
③A-pose:指人物直立,大臂向下30 度的一種標準角色姿勢。
猜你喜歡
小哥白尼(趣味科學)(2021年12期)2021-03-16 05:40:38
小學科學(學生版)(2020年10期)2020-10-28 07:52:18
開放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2019年22期)2019-12-07 05:28:56
現代語文(2016年21期)2016-05-25 13:13:44
學生天地(2016年9期)2016-05-17 05:45:06
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
