融合多尺度殘差注意力的圖像修復算法
2023-02-21 12:53:56錢冠宇鄧紅霞劉健虎李海芳
計算機工程與設計 2023年2期
錢冠宇,鄧紅霞,劉健虎,李海芳
(太原理工大學 信息與計算機學院,山西 晉中 030600)
0 引 言
傳統(tǒng)的圖像修復方法主要有兩種,一種是使用偏微分方程修復的方法,采用擴散的思路,將信息缺失部分附近的信息擴散到待修復部分[1-3]。但這種修復方法僅適用于缺失面積較小的情況。之后學者提出另外一種塊匹配方法[4,5]。從圖像中未缺失的部分進行檢索匹配出與缺失部分相似的區(qū)域,然后再進行對修補缺失部分,能夠達到較好的修復效果。但這類修復方法比較依賴待修復圖像中存在的信息,如果不能匹配到與缺失部分相似的信息塊,那么它修復缺失區(qū)域的效果則不會很好。
針對傳統(tǒng)方法的局限性,提出神經網絡[6-15]的方法來提高圖像修復的質量。李等[16]提出了一種多尺度生成對抗網絡圖像修復算法,提高了圖像修復的精確度,但在某些情況下修復圖像會看起來很不自然,出現(xiàn)這種情況的原因可能是由于網絡在卷積過程中提取了一些無效像素的特征。肖等[17]提出了結合感知注意力機制的生成對抗網絡圖像修復算法,得到更合理語義信息的修復效果;然而,該方法無法修復不規(guī)則破損區(qū)域的圖像。針對以上的問題,本文采用生成對抗模型來修復圖像,引入殘差注意力模塊提取缺失區(qū)域的有效信息以及通過多尺度判別器對全局和局部信息的一致性約束,最終實現(xiàn)缺失圖片的修復。通過實驗的對比,進一步探討本文算法的性能。
1 生成對抗網絡
生成對抗網絡(generative adversarial network,GAN)是Goodfellow等[18]提出的一種新理念深度學習模型,它是在相互博弈中達到平衡的一種網絡模型。原始的GAN模型將一個隨機的噪聲向量Z輸入到生成網絡中,然后輸出一張生成的假圖片,與真實的圖片一起送入判別網絡中判定圖片真假的概率,并將判別的結果反饋給生成網絡。原始GAN模型由于模型易崩塌的缺點,只能生成低分辨率圖像,生成的圖像較為模糊。GAN網絡問世以來,大多數(shù)學者開始研究一系列變種GAN網絡,例如把條件控制信息加入到GAN網絡的訓練中,以控制輸出的結果屬性。Arjovsk等[19]提出的一種新的截斷損失函數(shù)可以極大提高GAN網絡訓練的穩(wěn)定性,避免模型崩塌,能夠合成質量更好的樣本。之后引起了一系列GAN網絡的研究及應用,以及能夠生成高分辨率圖像的GAN網絡被提出,例如DCGAN,CycleGAN等網絡。隨著這些變種GAN網絡的出現(xiàn),GAN網絡的各種應用研究也因此極大增加。例如在低質量數(shù)據(jù)的提升上有超分辨率重建,圖像的去雨去霧和去除模糊,圖像的修復這些方面GAN網絡都有一定的效果,通過改進GAN網絡的結構和約束范式可以進一步提高這些低質量數(shù)據(jù)方法的提升效果。
2 融合多尺度殘差注意力的修復方法
MRS-Net(multiscale residual squeeze-and-excitation networks)模型與生成對抗網絡相似,整體網絡框架分為一個修復網絡和D1、D2兩個不同尺度的判別器網絡以及一個預訓練的Vgg16網絡。MRS-Net模型整體框架如圖1所示。

圖1 MRS-Net框架
修復模型結構如圖2所示,將256*256修復模型圖片通過編碼器進行4次下采樣,下采樣后會增大感受野,但會造成部分特征丟失,因此采用24塊殘差序列注意力塊來強化重要通道的特征,弱化非重要通道的特征,進行更好的特征提取,提高模型計算能力,最后通過解碼器進行4次上采樣輸出256*256修復后的圖片,同時在下采樣和上采樣之間使用跳躍連接層可以更好地利用圖像原始信息,能夠更好推測出缺失部分信息。將修復的結果進行重構損失、感知損失、風格損失、全變分損失、多尺度聯(lián)合判斷修復圖像與真實圖像的相似程度,判斷修復結果的好壞,并將結果反向傳播給修復模型,網絡依據(jù)反饋結果進行梯度下降尋找最優(yōu)模型參數(shù),可以讓修復的圖片在完成修復的情況下近似于真實圖片,能夠“騙過”判別器,以達到較好的修復效果,同時可以提高模型的魯棒性。

圖2 修復模型結構
多尺度判別器網絡結構如圖3所示,使用了兩個較為淺層的網絡作為判別器,通過使用二進制的交叉熵損失來反饋給判別網絡,判別網絡依據(jù)反饋結果進行梯度下降尋找最優(yōu)模型參數(shù),可以更好地判別修復結果。經過兩個網絡的相互迭代博弈使模型達到最優(yōu)修復的效果。

圖3 多尺度判別器網絡結構
算法整體流程是在修復模型輸入添加不同形狀掩碼后生成的256*256缺損圖像,經過修復模型的修復,然后輸出256*256修復圖像,計算修復后圖像的重構損失,全變分損失,通過一個預訓練的Vgg16模型來提取圖像的淺層和深層特征來計算感知損失,風格損失,并且將修復后的圖像下采樣為128*128的圖像,指導其修復圖像,同時可以避免生成器在博弈過程中產生過擬合現(xiàn)象,提高模型的泛化能力。兩個判別器模型對圖像的修復會有不同的約束,大尺度的判別器增強了圖像全局結構的完整性,小尺度的判別器增強了圖像的紋理細節(jié),增強了修復后圖像的真實感。將修復模型修復后的圖像和原始完整圖像輸入第一個判別器網絡,下采樣的修復圖像和下采樣的原始完整圖像輸入第二個判別器網絡,然后聯(lián)合兩個判別器網絡輸出的結果進行計算。通過加權融合多種損失結果來反向傳播給修復模型。
2.1 殘差注意力模塊
在計算機視覺中,注意力的目的是讓神經網絡在學習過程中能夠忽視無用信息并且重點關注有用信息。SE注意力[20]可以加強重要的通道信息,弱化不重要的通道信息,加強了子通道信息之間相關性。它通過全局平均池化、全連接層讓特征映射提高全局感受野,能夠利用圖像的全局信息進行預測修復。本文提出的殘差注意力模塊結構如圖4所示,輸入模塊中的是512*16*16的特征圖。圖像缺損區(qū)域的信息通常不僅和同一子通道的上下文像素點有緊密聯(lián)系,在不同子通道之間也會有密切聯(lián)系。因此,將SE注意力[20]模塊嵌入到殘差結構中,可以增加特征圖中通道之間的聯(lián)系。通常加深網絡層數(shù)會在學習過程中提高網絡的計算能力,但是會發(fā)生過擬合現(xiàn)象,梯度傳播困難,同時造成資源浪費。而殘差機制能使網絡層次不斷加深并且可以有效防止梯度消失以更好的提取圖像缺失部分特征,確保前面層的特征被再利用,從而避免過深的計算造成的信息損失。因此殘差注意力模塊能幫助提取圖像缺損區(qū)域的有效信息,盡管整個網絡會稍微增加了一點計算量,但是能夠達到比較好效果。

圖4 殘差注意力結構
2.2 多尺度判別器
多尺度判別器是兩個網絡結構相同,尺度不同的判別器,它對生成256*256的圖像以及下采樣后128*128的圖像進行鑒別,輸出一個到0,1之間的分數(shù)。不同尺度的判別器往往具有不同的感受范圍。因為修復后的圖像往往產生模糊以及高頻信息的丟失,因此,結合圖像全局和局部信息提高修復結果能夠反饋給生網。
2.3 損失函數(shù)的構建
2.3.1 重構損失
在圖像轉換問題中,重構損失是一種基于輸出圖像與真實圖像之間的差值方法,計算兩幅圖片中所有對應位置的像素點之間的均方差,最小化差值就會使兩幅圖像更相似

(1)
其中,1代表“1范式”。注意,N是使用缺失面積調整懲罰的分母。它意味著如果一個面被一個小的遮擋所干擾修復的結果應該非常接近實際情況,如果缺損程度較大,只要結構和一致性是合理的,則可以重新限制。
2.3.2 感知損失
通過最小化重構損失,來優(yōu)化輸出圖像的數(shù)據(jù),最終輸出高質量的圖像。但該方法的弊端是效率低下,實時性差。感知損失在度量圖像相似性方面比重構損失更具魯棒性。感知損失函數(shù)是兩幅圖像輸入Vgg16網絡后所提取特征之間的歐式距離,i表示修復后圖像與原始圖像在網絡第i層特征圖的歐氏距離
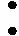
(2)
2.3.3 風格損失
風格損失函數(shù)是兩幅圖像輸入Vgg16網絡后所提取特征之間的格拉姆矩陣的歐氏距離。j表示修復后圖像與原始圖像在網絡第j層特征圖格拉姆矩陣的歐氏距離
(3)
2.3.4 總變分損失
總變分損失在低質量圖像數(shù)據(jù)提升中經常應用于圖像的去噪處理和修復處理。通常像素信息缺失圖像的總變分和完整圖像的總變分相比會有顯著性差異。總變分是計算圖像數(shù)據(jù)梯度幅值的積分。限制了總變分就會使圖像變得更為平滑
(4)

2.3.5 生成對抗損失
修復網絡將對抗損失最小化來反向傳播更新網絡,兩個尺度的判別器網絡將對抗損失最大化來反向傳播更新網絡。Pdate(Igt) 代表真實圖像的分布,Pmiss(I) 代表輸入圖像的分布,D(.) 是判別器網絡對于輸入的圖像是修復圖像和真實圖像的概率預測

(5)
2.3.6 聯(lián)合損失
通過加權融合多種損失結果來判斷修復圖像與真實圖像的相似程度,并將結果通過反向傳播給修復模型,網絡依據(jù)反饋結果進行梯度下降尋找最優(yōu)模型參數(shù)
l=αladv+βlpixel+δlprec+εlstyle+ωltv
(6)
3 實驗和結果分析
3.1 實驗數(shù)據(jù)集
實驗采用數(shù)據(jù)集CelebA和數(shù)據(jù)集Oxford Buildings,CelebA數(shù)據(jù)集是包含20萬張人臉數(shù)據(jù)的公共數(shù)據(jù)集。實驗選取48 100張圖片,劃分為訓練數(shù)據(jù)集和測試數(shù)據(jù)集,訓練數(shù)據(jù)集包括44 100張圖片,測試數(shù)據(jù)集包括4000張圖片。數(shù)據(jù)集Oxford Buildings包含上百萬張各式建筑物圖片,實驗選取20 000張圖片,使用19 800張為訓練數(shù)據(jù)集,200張為測試數(shù)據(jù)集。在數(shù)據(jù)處理部分,對于每張圖片檢測人臉并裁剪成256*256大小的圖片。實驗數(shù)據(jù)使用的是成對的數(shù)據(jù),完整圖片相對的缺失數(shù)據(jù)較少且不容易收集,所以實驗設計了中心矩形掩碼,隨機矩形掩碼,隨機數(shù)量的不同形狀掩碼,由已有完整圖片添加缺失掩碼生成缺失圖片,從而產生成對的數(shù)據(jù)集。
3.2 實驗設置
實驗使用現(xiàn)較流行的深度學習框架Pytorch框架,實驗軟件配置為python3.6,硬件配置為i7+Nvida2080Ti,使用Linux操作系統(tǒng)。實驗中Batch_size設置為1,使用Adam優(yōu)化算法來優(yōu)化模型,學習率設置為0.0002,beta1為0.5。實驗設置30個epoch。
3.3 評價方法
實驗中使用了SSIM(結構相似性)與PSNR(峰值信噪比)兩種評價指標來測評修復后圖像與真實的圖像的差異性和相似性。這兩種評價方法經常用來作為低質量的圖像數(shù)據(jù)提升為高質量的圖像數(shù)據(jù)的評價指標。SSIM的原理是從兩幅圖像的3個方面(亮度l、對比度c、結構s)來評測兩幅圖像的相似性。它的取值的范圍為[0,1],數(shù)值接近1就代表著兩幅圖像越相似
SSIM(X,Y)=l(X,Y)*c(X,Y)*s(X,Y)
(7)
PSNR的原理是計算兩幅圖像對應的像素點之間的差異性,公式中MSE代表兩幅圖像的均方誤差,較大的PSNR數(shù)值就代表著圖像失真的程度較小
(8)
3.4 實驗結果
本節(jié)針對不同的實驗結果分為3部分進行討論分析與總結,第一部分是與不同模型的方法在公共數(shù)據(jù)集上的性能指標對比,以及與不同模型方法中修復后的可視化結果對比。第二部分是消融實驗,同時討論了殘差注意力塊層數(shù)和使用的不同損失函數(shù)對于MRS-Net的影響。第三部分是與不同模型方法在不同缺失面積的修復結果之間的比較,以及與不同模型方法在大面積的缺失的修復結果之間的比較。
3.4.1 對比實驗
將MRS-Net與CE、GL、PIC-Net、Shift-Net等在圖像修復方面具有代表性的算法進行比較。在圖5的結果對比中可以看出CE算法無法推測出圖像中合理的缺失信息;GL算法可以計算出圖像中較為合理的缺失信息,但是在一些地方有較明顯的差異性;PIC-Net算法可以使圖像的修復結果較為合理,但和真實的圖片有些差距,同時修復局部地區(qū)存在一些偽影;Shift-Net算法能夠計算出圖像中合理的缺失信息,并達到較好的效果,但是在圖像的細節(jié)不具有較好的一致性;MRS-Net修復圖像的結果相比于其它幾個模型有進一步提高,同時具有更加精細的紋理細節(jié),修復的結果有更好的一致性。圖6可視化了不同修復算法在4種缺失類型的圖片,從圖6的結果可以看出MRS-Net在4種缺失類型可以較好完成修復任務。在較大面積缺失時其它的算法對于修復效果有一定的偏差,而MRS-Net可以較好彌補這些缺陷,合理修復缺失部位;在局部細節(jié)信息缺失時,對比的算法對于像眼睛、眉毛等部位的缺失達達不到較好的修復水平,而MRS-Net的修復結果對于局部精細部分有更好的修復效果。

圖5 不同算法對比結果

圖6 不規(guī)則破損圖算法對比結果
為了驗證MRS-Net具有較好的修復性能,使用PSNR和SSIM兩個圖像評價指標來對比經典修復算法與MRS-Net在測試集上的修復效果。從表1的對比實驗結果可看出,MRS-Net在SSIM指標上相比于其它幾個算法能提高2%~5%左右,在PSNR指標上能提高1~3左右。由于人臉圖像的結構大體輪廓有一定的相似性,而Oxford Buil-dings數(shù)據(jù)集圖片復雜度較高,相似性較低,所以對于建筑物圖像修復的任務具有一定的挑戰(zhàn)性,圖5的第五行到第八行對在Oxford Buildings數(shù)據(jù)集上的修復結果進行了可視化,對于建筑物圖片的修復任務,其它幾個算法的修復結果不是很理想,而由于MRS-Net的方法可以較好推斷出建筑物圖像缺失信息并且提高修復圖像的清晰程度,因此可以達到較好的修復效果。同時,從表1的結果中可以看出,MRS-Net在SSIM指標上比其它3個模型能提高2%~7%左右,在PSNR指標上能提高1~4左右。

表1 評價指標不同算法對比結果(PSNR/SSIM)
3.4.2 消融實驗
為了驗證MRS-Net改進的效果,進行了消融實驗。在消融實驗中算法使用相同的損失函數(shù),從表2中可以看出,在修復缺失圖像上MRS-Net的方法在SSIM指標上比其它4個消融模型提高1%~5%左右,在PSNR指標上能提高1~3左右。第一行是基礎的編碼器解碼器網絡的修復結果存在修復后圖像質量差,相似度低的問題。第二行M是使用多尺度判別器和第三行是使用殘差注意力上修復結果的指標均低于MRS-Net的指標,從而可以看出MRS-Net改進的有效性。第四行M3是使用3個判別器和殘差注意力的時候,模型的性能反而會降低,推測可能是因為判別器的性能過于強大,從而打破了博弈的平衡性,在博弈中修復模型處于劣勢,造成修復模型性能的降低。

表2 在CelebA數(shù)據(jù)集評價指標消融結果(PSNR/SSIM)
不同的殘差注意力塊層數(shù)對于修復結果的影響,在深度學習中更深的網絡往往可以學習到更好的預期結果,但過深的網絡也會導致不良的結果,因此探索階段選擇使用12層、24層、36層不同的層數(shù)進行實驗驗證,圖7的結果中表明12層殘差注意力塊可以較好修復缺失圖片,但在眼睛和眉毛部分會存在些許模糊;24層殘差注意力塊能夠較好地推測出缺失部分的語義信息;36層殘差注意力塊的修復結果會出現(xiàn)大范圍的模糊偽影。所以實驗中最終選取加入24層殘差注意力模塊的改進模型作為算法的修復網絡。之后探索了在MRS-Net上使用不同損失函數(shù)對于修復結果的影響。如圖8的結果顯示,列1使用了生成對抗損失之后,修復的結果比較模糊,修復的部分會有偽影,達不到預期的修復效果,所以需要加入重構損失來消除修復后模糊現(xiàn)象。列2加入重構損失后可以提高圖像的清晰度,但是在眼睛部位存在些許偽影,而在列3加入了全變分損失后,可以較好地消除眼部偽影,但修復后額頭部位有不平滑的修復現(xiàn)象,列4中加入了Vgg16提取圖像高層特征計算感知損失使得圖像結構近似于原圖內容,但是與原圖內容相比在圖像風格方面過于暗淡,在列5中加入了Vgg16提取圖像低層特征風格損失后,提高了圖像與原圖風格的相似度,同時提高修復圖像清晰度,達到預期想要的結果。

圖7 在CelebA數(shù)據(jù)集不同殘差注意力塊數(shù)結果

圖8 在CelebA數(shù)據(jù)集不同損失消融結果
3.4.3 模型魯棒性實驗
為了驗證模型的魯棒性,實驗對比了不同算法在缺失面積占比為5%~10%、11%~20%、21%~30%、31%~40%、41%~50%時的性能表現(xiàn),見表3和表4。MRS-Net在不同面積的缺失圖像上修補均有最高的峰值信噪比和結構相似性指標數(shù)值。此外,隨著圖像缺失面積的增大,兩個指標的下降幅度比較低,在圖9的結果中使用不同形狀和不同數(shù)量的特大面積缺失的圖像進行修復,GL算法在圖像修復效果都很不理想,對于特大面積缺失的圖像不能進行較好的修復;PIC-Net算法對于前三行的圖像修復效果相比于GL算法有些許提高,可以合理修復缺失部位,在第四行與第五行的圖像修復效果相比于GL算法降低了,幾乎沒有修復圖像的缺失部位;Shift-Net算法可能是由于泛化能力不足導致圖像的修復結果不理想;相比于其它算法,MRS-Net有較好的圖像修復效果,可以體現(xiàn)MRS-Net具有較好的魯棒性。

圖9 不規(guī)則特大面積缺失結果

表3 在CelebA數(shù)據(jù)集不同面積峰值信噪比對比結果(PSNR)

表4 在CelebA數(shù)據(jù)集不同面積結構相似性對比結果(SSIM)
MRS-Net對于普通的圖像修復效果較好,但對于色彩過于復雜或者形狀奇特的圖像修復效果不可觀,如圖10所示,后續(xù)會尋找相應的解決辦法。

圖10 復雜形狀修復結果
4 結束語
本文提出一種融合多尺度殘差注意力的修復缺失圖像模型。使用融合的殘差序列提取注意力,提高圖像中缺損區(qū)域特征圖子通道之間的相關性,使得提取的圖像特征預測圖像結構和語義信息是缺損區(qū)域的有效信息,多尺度判別器來約束修復的內容。實驗結果表明,與先前的算法相比,MRS-Net在修復多種形狀缺失塊圖像和大面積缺失塊圖像的清晰度與相似性取得了較好的效果,圖像修復的結果與真實的圖像有較好的一致性。MRS-Net可以應用在人臉去遮擋修復和建筑物的修復。最終會得到修復質量較好的圖像。
但是本文所提方法也存在一定不足,對于特大面積缺失和缺失部分圖案復雜的圖像修復效果會有部分降低,下一階段將對特大面積的缺失和缺失部分圖案復雜的圖像修復進行研究,提高模型對于特大面積缺失圖像的修復能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
