基于DeepLabV3s的曳引輪磨損測量研究*
2023-03-11 07:56:42劉士興汪一丹王金博
機電工程 2023年2期
劉士興,汪一丹,王 野,王金博
(1.合肥工業大學 微電子學院,安徽 合肥 230009;2.安徽省特種設備檢測院,安徽 合肥 230041)
0 引 言
隨著我國經濟社會的快速發展和城鎮化速度的加快,高層建筑中必不可少的電梯的數量快速增加。2020年我國電梯產量達到了105萬臺,在電梯領域已經成為產能最大、配套最完善、出口最多的國家[1]。
曳引系統是電梯中重要的組成部分,用于提供動力、驅動轎廂的正常運行[2]。在電梯的運行過程中,曳引輪與鋼絲繩反復摩擦,導致繩槽面產生磨損[3]。如果其過度磨損,可能引發鋼絲繩斷裂、轎廂振動、沖頂等事故[4],對電梯的安全運行具有重大影響。
根據調查,使用年限較久的電梯都存在曳引輪磨損嚴重、曳引力不符合要求的情況,部分電梯的繩槽出現缺損和裂紋[5],存在比較嚴重的安全隱患。因此,按時檢測曳引輪的磨損情況對于電梯的安全運行意義重大。
曳引輪磨損量傳統測量法包括目視法、角尺與塞尺結合法、橡皮泥或塑性膠法等[6]。陳本瑤等人[7]提出了一種規塞式工裝測量法,該方法可以同時測量繩槽寬度、深度以及切口上寬度等多個信息,測試精度高;但其通用性不強。
非接觸式測量有利于提高測量的自動化水平,降低人工成本[8]。謝曉娟等人[9]提出了一種基于圖像處理的曳引輪磨損識別方法,該方法不僅簡單有效,還可以降低檢測的成本;但該方法不適用于繩槽磨損均勻的檢測情況[10]。陳建勛等人[11]將激光三角法應用于曳引輪磨損的非接觸測量中,該方法具有檢測精度高、自動化程度高等特點;但其無法實現便捷檢測,且實時檢測的可操作性差。林永森等人[12]提出了一種基于線激光位移法的磨損檢測法,該方法測量精度高,與其他方法相比效率也有所提升;但其有效測試區域長度有限。劉士興等人[13]研制了一種基于單目視覺的曳引輪磨損檢測系統,完成了對曳引輪磨損的非接觸測量,且與傳統方法比,其測量的精度更高。
為了提高計算效率,研究人員進一步提出了一種基于機器視覺的曳引輪磨損檢測方法[14]。該方法解決了弱光環境下測量不準確的問題;但其測量過程中需要人工選取測量點,因此,其自動化程度還有待于提高。
為了提高電梯曳引輪磨損測量的精度和自動化程度,筆者提出一種電梯曳引輪磨損自動測量算法。
通過改進后的模型DeepLabV3s,筆者對制作好的數據集進行訓練,將曳引輪與鋼絲繩區域劃分,并采用融合曳引輪特征的圖像處理算法,實現邊緣快速提取、目標區域截取以及磨損點定位的目標;最后,在實驗平臺進行測量,以驗證該算法的精度與可行性。
同時,根據國家相關標準,筆者建立曳引輪磨損物理模型,以在不同光照環境下可以對磨損進行精準測量。
1 曳引輪磨損自動測量系統
1.1 曳引輪繩槽磨損模型
電梯曳引輪繩槽分為凹型槽、半圓槽、V形槽等[15]。筆者以帶切口的V形槽為研究對象,使用工業相機對V形槽磨損量進行非接觸測量。
曳引輪磨損測量系統示意圖如圖1所示。
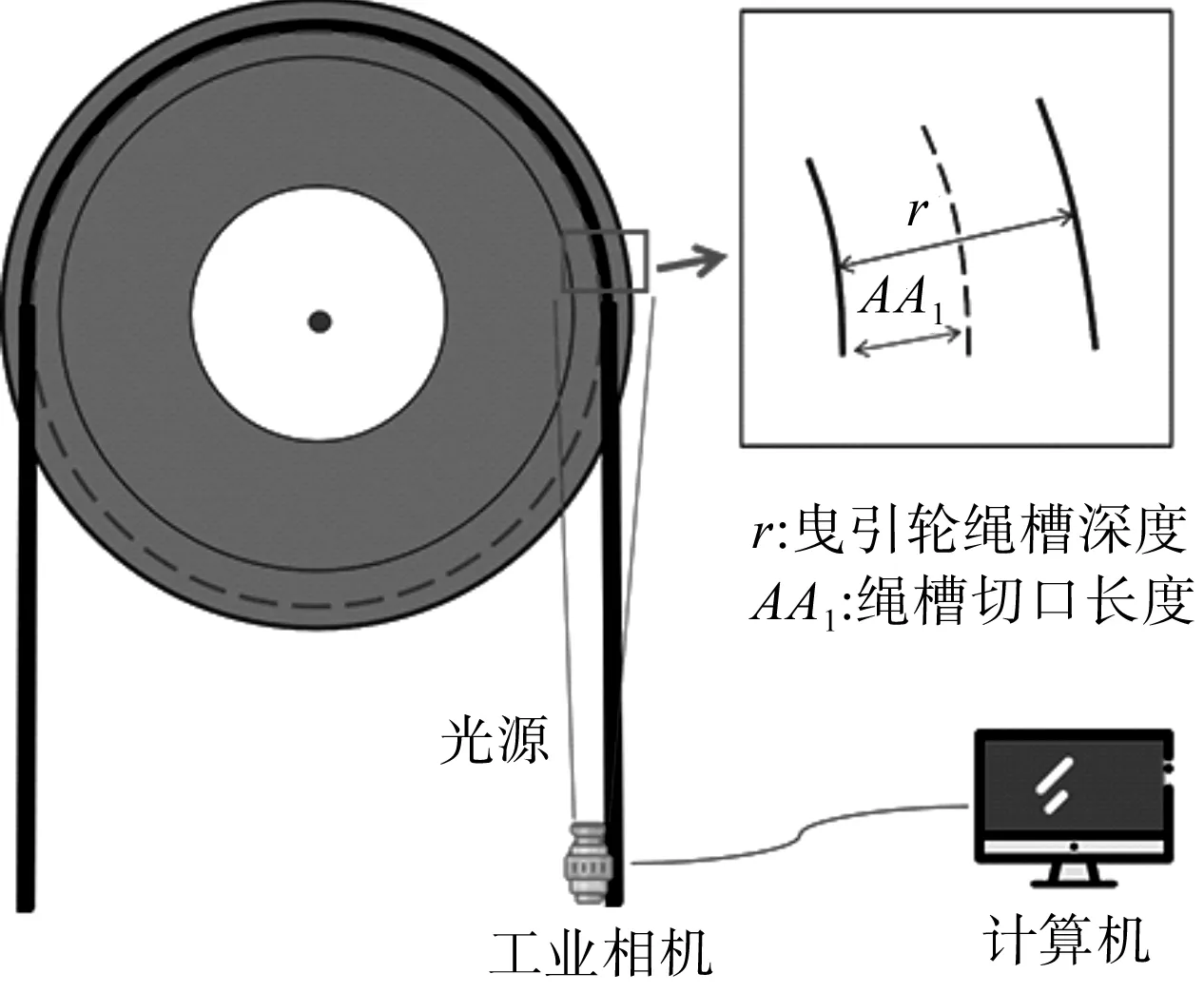
圖1 曳引輪磨損測量系統示意圖
磨損主要是壓力和運動摩擦的產物[16]。根據曳引輪檢測國家標準,在未磨損情況下,曳引輪繩槽底部到鋼絲繩外緣最大間距為6 mm,當間距小于3 mm時,需嚴密監測。
假設曳引輪繩槽兩側磨損均勻,曳引輪繩槽的磨損量即為鋼絲繩的下沉量。為實現下沉量的計算,筆者基于曳引輪實際特征構建V形槽截面的物理模型。
曳引輪磨損物理模型如圖2所示。
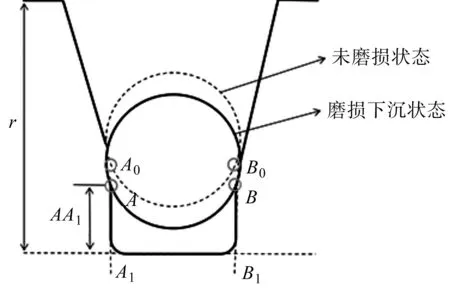
圖2 曳引輪磨損物理模型r—曳引輪繩槽深度;AA1—繩槽切口長度
由圖2得:當曳引輪未磨損時,A0為鋼絲繩與繩槽的左側接觸點,B0為右側接觸點。從A0、B0兩點垂直于繩槽底部構建兩條直線,與繩槽底部延長線交于A1、B1。忽略鋼絲繩的磨損,當曳引輪發生磨損后,鋼絲繩豎直下沉,A0、B0移動至A、B兩點,A、B即為磨損點。
1.2 算法流程
基于曳引輪磨損物理模型,筆者提出一種基于改進DeepLabV3的磨損自動測量算法。該算法基于PyCharm平臺,使用python語言開發,分為語義分割和圖像處理兩個模塊。
曳引輪磨損自動測量算法流程如圖3所示。
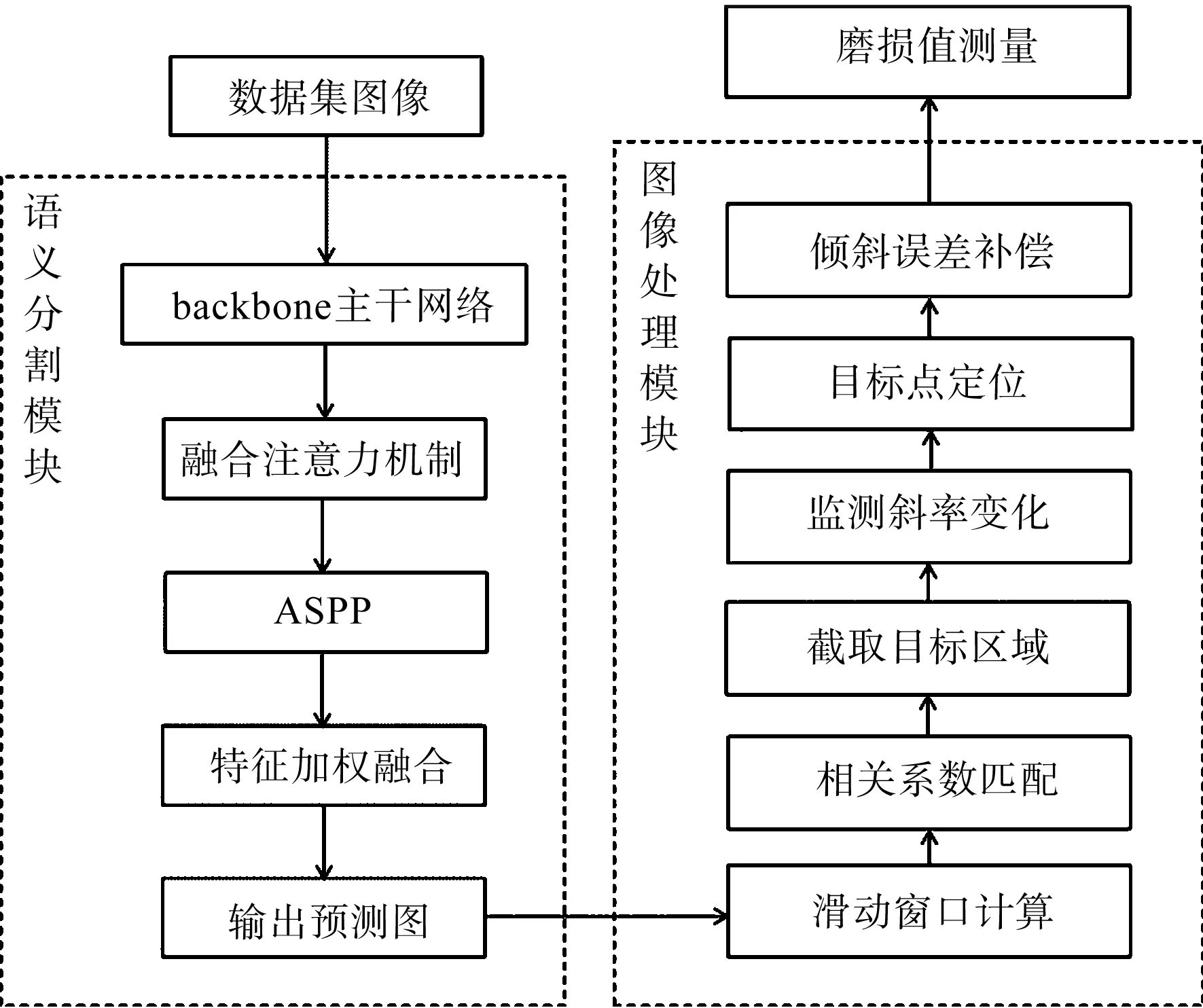
圖3 曳引輪磨損自動測量算法流程
由圖3可知:語義分割模塊主要用于解決原圖像紋理復雜、輪廓不清晰、干擾性特征點過多、受光照影響大等問題,通過深度卷積神經網絡對制作好的數據集進行訓練,實現對鋼絲繩和曳引輪的圖像分割;
圖像處理模塊主要用于解決傳統目標區域匹配方法限制物距的問題,以及測量的實時性和準確性較差等問題,以實現實時、自動化且不受相機物距限制的磨損值測量的目的。
2 DeepLabV3模型
2.1 模型性能對比
在工業領域中,采用機器視覺和非接觸式測量的方式,可以減少人為干預,提高響應速度[17]。目前,融合深度學習的非接觸式測量方式在工業中得到了廣泛應用。其中,語義分割通過神經網絡進行數據處理,在提升特征提取能力的同時,也在特征提取過程中去除了人工的干預,實現了特征提取自動化和端到端學習的目的,有利于系統的自動化。
筆者使用fully convolutional networks(FCN)、DeepLabv3、Unet、DeepLabV3+這4個網絡模型,對曳引輪數據集進行訓練測試。測量目標為帶切口的V形槽。
為收集足夠的訓練樣本進行訓練,需建立曳引輪磨損數據集。筆者使用工業相機采集不同光照、角度下的曳引輪圖片,用標注軟件LabelMe對采集到的圖像進行標注,利用數據增強方法提高深度學習模型精度與泛化能力[18],最終得到完整的數據集(圖片共3 055張,其中訓練集2 138張,測試集917張)。
筆者采用相同損失函數、學習率、學習率衰減函數優化器,分別對數據集訓練相同的epoch,針對訓練后的模型進行預測效果評價;采用平均交并比(mean intersection over union,MIoU)和準確率(accuracy,Acc)作為評價指標。
MIoU計算方法如下式所示:
(1)
式中:i—曳引輪圖像實際值;j—預測值;k+1—類別個數(包括背景);pij—將i預測為j的個數;pji—將j預測為i的個數;pii—將i預測為i的個數。
模型性能比較如表1所示。

表1 模型性能比較
由表1可得:除FCN模型表現較差外,其余模型相差不大,DeepLabV3表現較好。
由于曳引輪繩槽邊緣預測的準確性對測量結果影響最大,而DeepLabV3在繩槽區域表現最佳,經綜合考慮,筆者最終選用DeepLabV3為訓練模型。
2.2 DeepLabV3網絡
DeepLab網絡由CHEN L C等人[19]在2014年提出,是語義分割領域較為先進、優秀的算法。相比于其他網絡,DeepLabV3網絡舍棄了全連接層,主干網絡Backbone使用Resnet101,并對空間金字塔池化進行了改進,解決了分辨率下降、多尺度信息等問題。
為解決輸出圖像分辨率過低的問題,DeepLabV3中使用空洞卷積。空洞卷積中的膨脹率可以擴展濾波器的感受野,膨脹率越大,其感受野也越大。
當使用空洞卷積,則卷積輸出和輸入關系的表達式如下式所示:
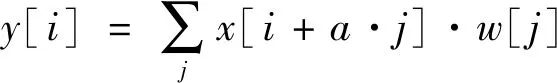
(2)
式中:x[i]—輸入;y[i]—輸出;a—膨脹率;w[j]—卷積核。
當膨脹率設為2,空洞卷積結構如圖4所示。
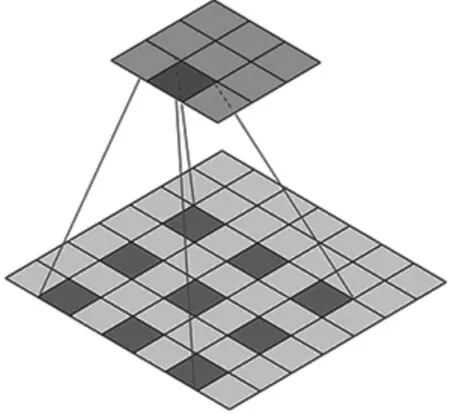
圖4 空洞卷積結構
由圖4可得:大小為3×3的卷積核可以覆蓋5×5的區域。以此類推,當膨脹率設為3,則卷積核可以覆蓋7×7的區域。
在光照較強或圖片模糊狀態下,采用DeepLabV3網絡進行圖片分割時,會導致誤判,對后續圖像處理產生干擾,影響最終的測量結果。因此,需要對其做適當的改進處理。
2.3 改進的DeepLabV3網絡
光照對曳引輪圖像的分割存在一定影響。預測圖像不可避免地會出現誤判區域,對后續圖像處理、磨損值測量影響較大。為了解決這個問題,筆者提出一種融合SEnet和ECAnet雙注意力機制的DeepLabV3網絡—DeepLabV3s。
融合雙注意力機制的DeepLabv3s網絡結構如圖5所示。
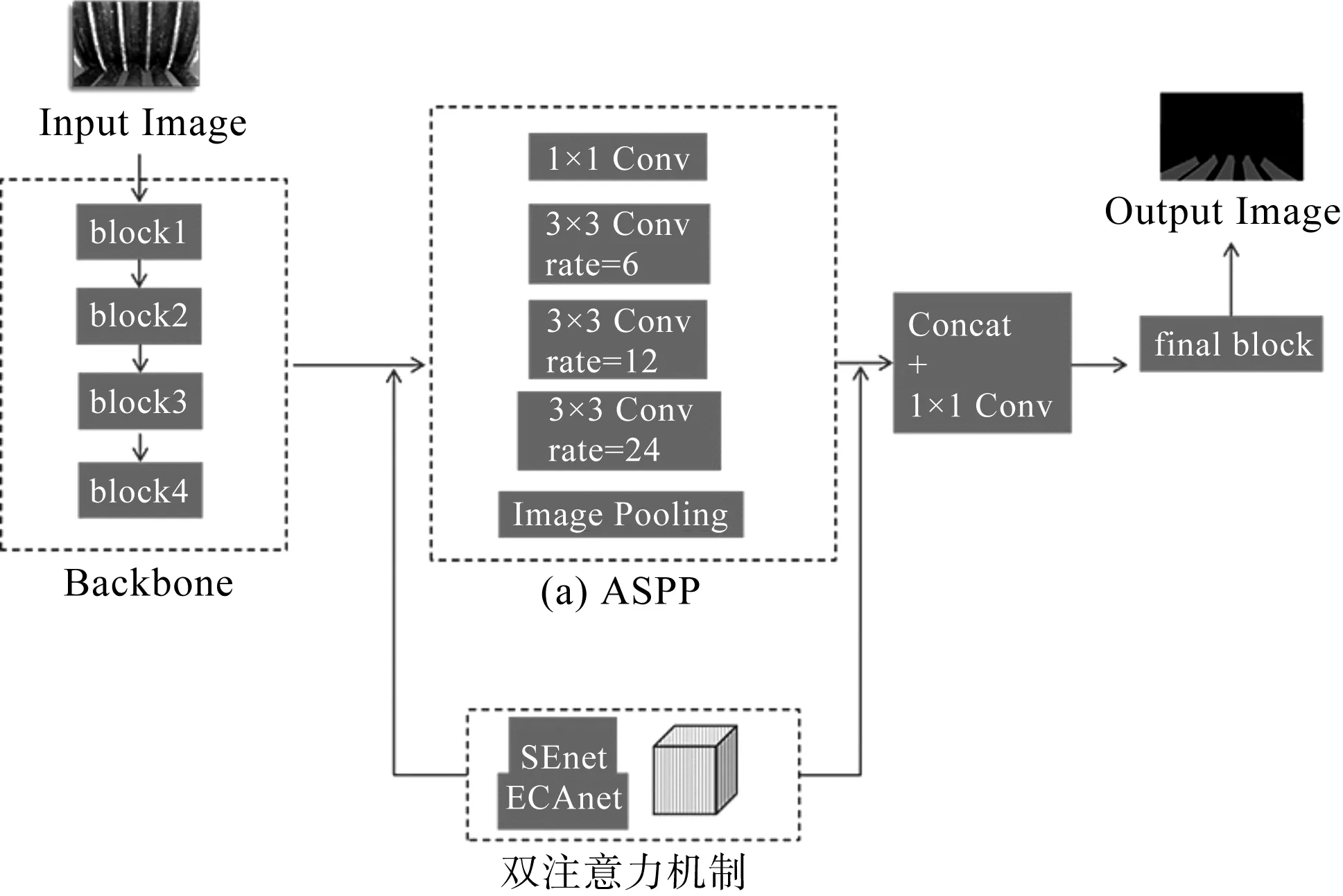
圖5 融合雙注意力機制的DeepLabv3s網絡結構
SEnet(即通道注意力機制)通過分配給每個通道權重,以此來平衡不同通道的作用力,解決因不同通道所占權重不同而導致的損失問題。
最終的特征值為:
ω=σ(f{w1,w2}(g(χ)))
(3)
式中:σ—Sigmoid函數。
f(w1,w2)(y)表達式為:
f(w1,w2)(y)=w2·ReLu(W1y)
(4)
全局平均池化函數g(χ)表達式為:
(5)
SEnet通過提取圖像特征,得到特征圖的維度[C,H,W],在平均池化后,將通道[H,W]壓縮至[1,1],再經過兩個全連接層,增強通道間的相關性,得到每個通道的權重,然后作用于特征圖,使得每個通道各自乘以對應的權重。
ECAnet是一種輕量級的通道注意力機制,通過自適應函數改變卷積核大小,實現跨通道的信息交互。
自適應函數如下:
(6)
其中:γ=2,b=1。
將SEnet和ECAnet注意力機制融合在DeepLabV3的網絡結構中,減輕了SEnet帶來的維度縮減,同時可以有效地增強多維度信息交互。
2.4 改進后的模型性能分析
預測圖對比如圖6所示。

圖6 預測圖對比
由圖6可得:由于不同類別的訓練權重不平衡,使用無注意力機制的DeepLabV3時,其預測結果常常會出現誤判區域,對后續的圖像處理造成較大影響,使測量結果不穩定。
筆者提出的改進模型解決了因通道權重不平衡而導致的損失問題,更專注于所需類別,有效地降低了其誤判幾率。
模型性能對比如圖7所示。
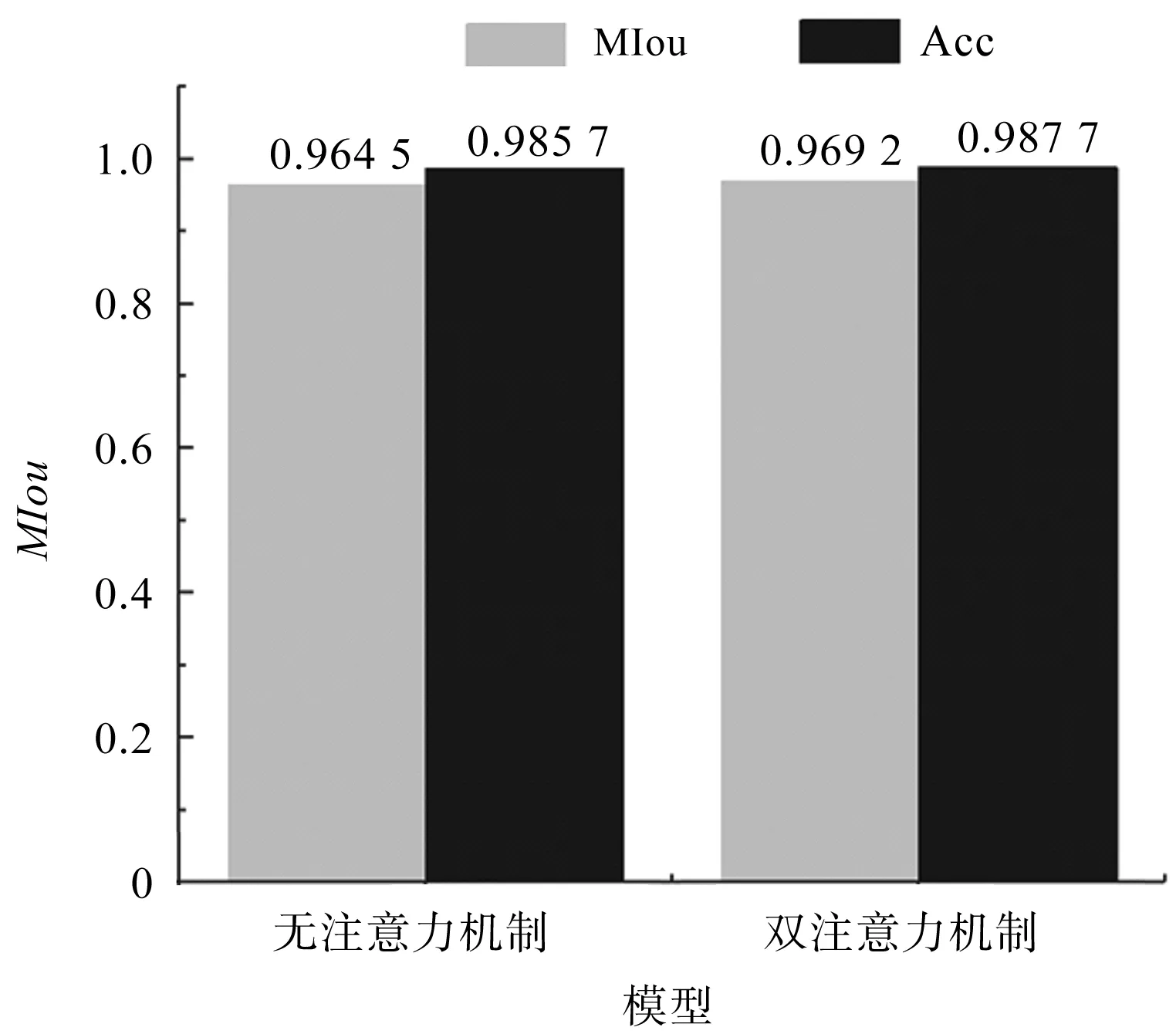
圖7 模型性能對比
由圖7可得:DeepLabV3在曳引輪數據集中表現良好;MIoU可達0.964 5,改進后的模型對MIoU的提高比較有限,但是對于類別的判斷能力有很大提升。
Loss值對比如圖8所示。
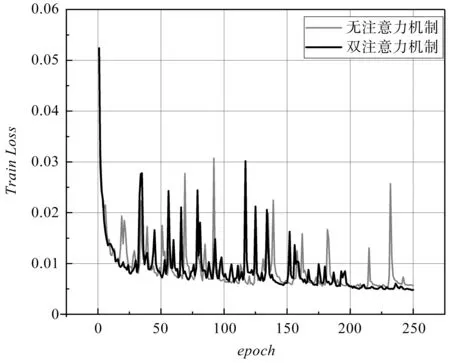
圖8 Loss值對比
由圖8可得:融合雙注意力機制的DeepLabV3模型Loss值下降速度相對較快,收斂效果更好。
該結果表明:改進后的算法精度有一定的提升,有效消除了圖像中的預測偏差,明顯減輕了光照對語義分割效果的影響,使其對光線魯棒性更強,有利于后續圖像的處理和磨損測量精度的提升。
3 曳引輪磨損測量算法
3.1 基于預測圖像的目標匹配
為了實現對目標繩槽的精準提取,并為后續目標點的提取做準備,筆者采用相關匹配法進行模板匹配。
模板匹配即是在圖像中用滑動窗口遍歷像素,判斷其是否與模板相似,計算模板與窗口區域的相關系數,當相關系數足夠高時,則認定為要尋找的目標;若匹配到了多個區域,則通過設置閾值得到目標的最佳匹配。
相關系數的計算如下式所示:
(7)
式中:T(m,n)—模板圖像;S(w,h)—搜索圖像;w,h—模板的高度和寬度;Sij—模板與搜索圖重合的子圖;i,j—子圖在被搜索圖中的左上角坐標。
為了加快匹配速度,當目前子圖的相關系數小于一定閾值時,搜索步長加大。在相關匹配法中,由于亮度變化對相似度的計算影響較小,滿足曳引輪在不同光照條件下測量的需求。
目標匹配如圖9所示。

圖9 目標匹配
由圖9可得:該算法對目標繩槽匹配的效果較為精準(其中,方框表示匹配到的目標區域)。
3.2 磨損點定位
為了計算出曳引輪的磨損量,需要監測磨損點的變化,以精確定位磨損點。
由圖2所示物理模型可知:AA1、BB1幾乎垂直于繩槽底部,水平方向變化較小,而A、B兩點磨損處水平、垂直方向變化較大。以拍攝圖片左上角為坐標原點,豎直向下為y軸正方向,水平向右為x軸正方向。
像素點的斜率變化監測如圖10所示。
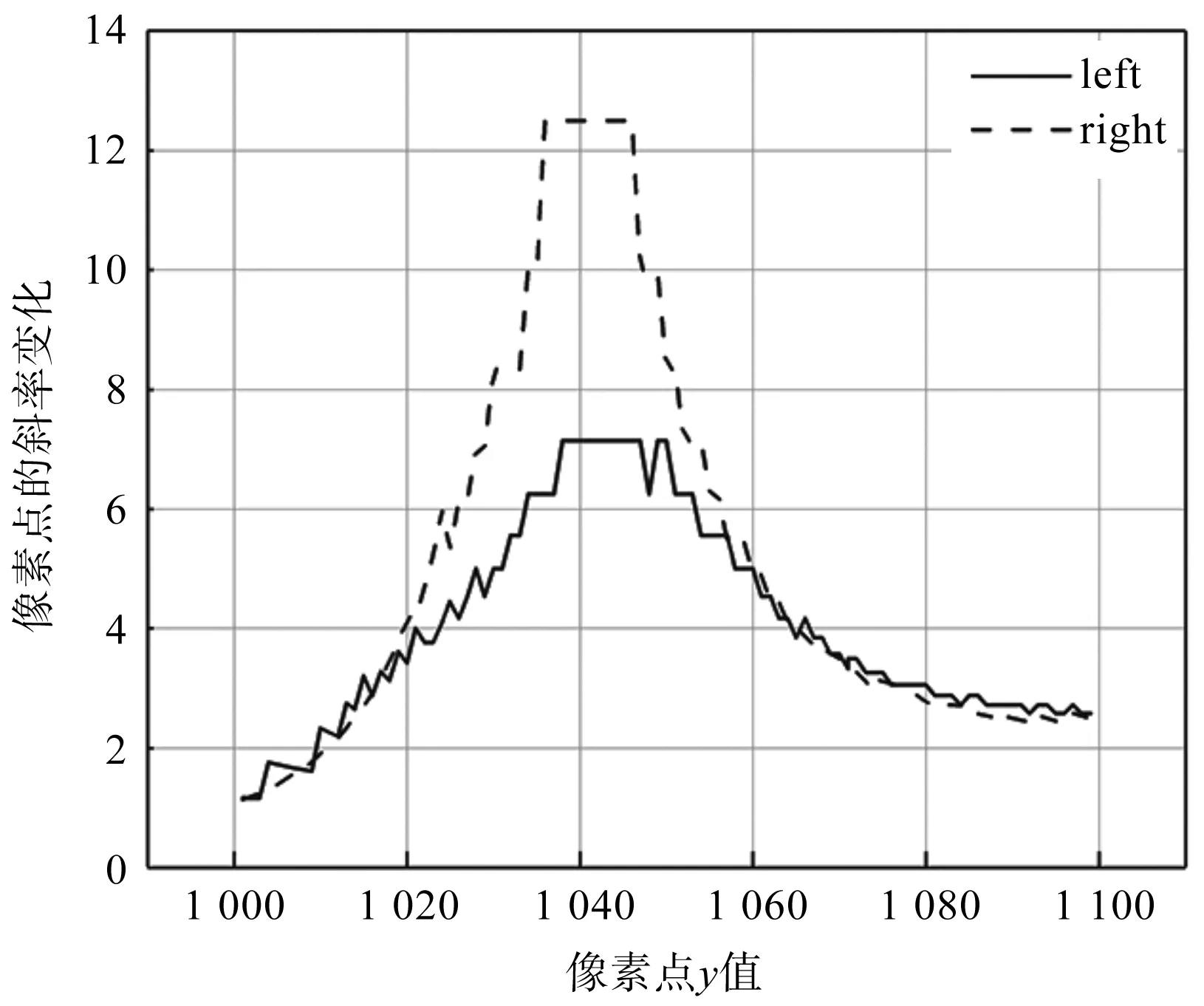
圖10 像素點的斜率變化監測
由圖10可得:像素點y值為目標繩槽邊緣在坐標中的y軸坐標,磨損處的像素點y值處于[1 050,1 080]區間內,AA1則處于斜率幾乎不變的[1 035,1 050]。當斜率變化從幾乎不變的區間滑動至變化較大的區間,即可定位至磨損點。由于相機水平位置的偏差,繩槽左側和右側斜率存在不可避免的誤差,但其變化趨勢與實際值一致。
磨損點檢測圖如圖11所示。

圖11 磨損點檢測圖
圖11中標注的兩個點表示檢測到的磨損點A、B。
實驗結果表明:曳引輪磨損檢測系統目標區域提取準確,目標點檢測較為精準,對環境要求不高,在實際應用中具有優勢;與傳統方法相比,該檢測系統對設備的要求較低,其測量方法簡便,對相機測量物距的要求較為寬松,可以取得較高的自動化程度。
3.3 磨損量測量
定位到磨損點A、B后,可由像素點差值計算磨損后切口投影至圖像中的長度。
繩槽的磨損量A0A為:
A0A=a0-a1
(8)
式中:a0—未磨損的繩槽切口實際長度,即A0A1;a1—磨損后的切口實際長度,即AA1。
根據相機的成像原理,實際長度與投影至二維圖片中對應長度的比值為比例系數α。
由下式可得a1:
(9)
式中:a2—繩槽切口長度投影在圖片中的尺寸;r—繩槽實際深度;r1—繩槽深度投影在圖片中的尺寸。
其中:a0、r可由出廠標準得到(其中,a0=3.31 mm,r=10.65 mm);a2、r1可由像素點坐標計算得到。
為了消除不可避免的相機傾斜誤差,筆者使用B點做加權傾斜補償。
傾斜補償后的繩槽切口長度a2為:
a2=AA1+β·BB1
(10)
式中:AA1,BB1—圖像中繩槽兩側切口長度;β—補償因子。
4 實驗與結果分析
4.1 魯棒性驗證
實驗環境為Ubuntu操作系統,其中,GPU為NVIDIA RTX3060,開發環境為CUDA11.5,采用PyTorch網絡框架。筆者采用DeepLabV3s為網絡模型;ResNet101為預訓練模型;初始學習率設置為0.007;批處理大小(batch size)設置為5。
測量實驗平臺如圖12所示。

圖12 測量實驗平臺
筆者使用MIoU和Acc來評價訓練效果。MIoU最終可達到0.969 2,Acc可達0.987 7。
不同情況下曳引輪繩槽預測圖如圖13所示。
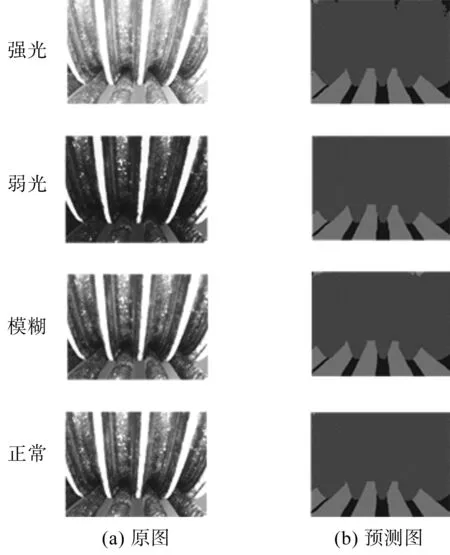
圖13 不同情況下曳引輪繩槽預測圖
由圖13可知:目標區域幾乎沒有區別,在弱光、強光環境下和畫面模糊狀態下的預測效果良好;
該方法對清晰度要求不高,對光照的魯棒性很強,有利于在電梯弱光環境中進行測量。
筆者對4種不同情況下的圖片進行磨損量測量。已知測量標準值為3.31 mm,不同情況下基于DeepLabV3的磨損量測量值,如表2所示。
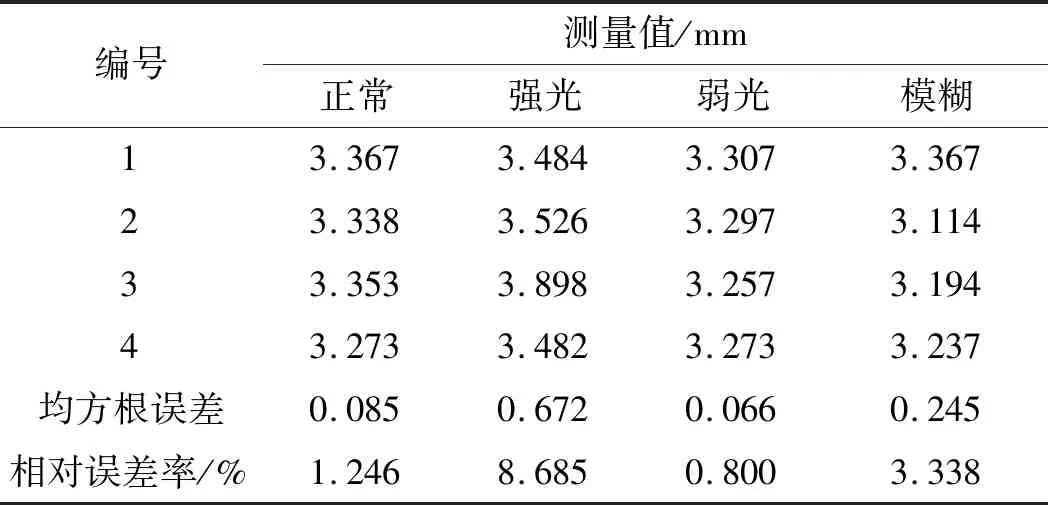
表2 不同情況下基于DeepLabV3的磨損量測量值
不同情況下基于DeepLabV3s的磨損量測量值如表3所示。
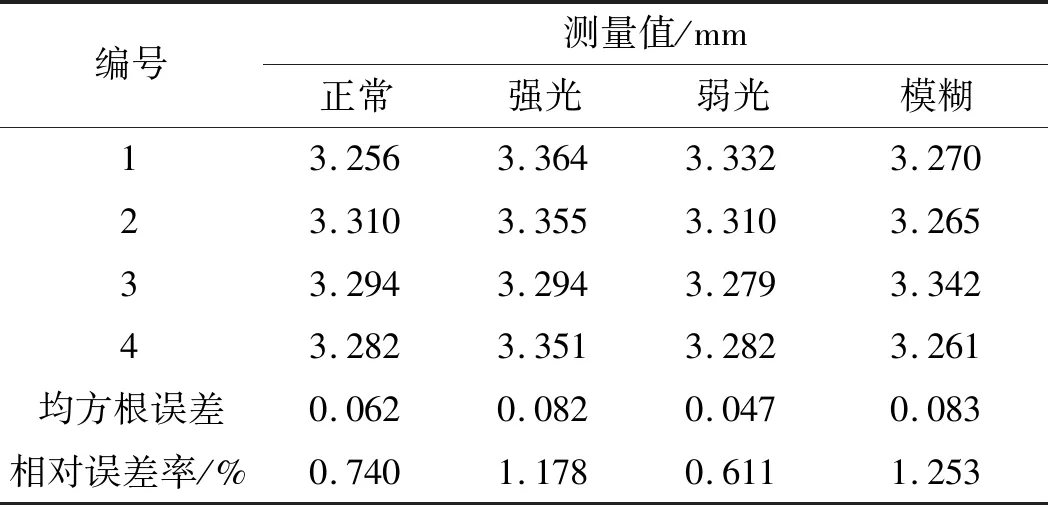
表3 不同情況下基于DeepLabV3s的磨損量測量值
對比表2、表3中4種不同情況的測量值和誤差可得:強光會導致邊緣細節丟失,測量結果總體偏大,誤差值最大;弱光卻能在一定程度上保留更多的暗部紋理細節,測量值最接近標準值,誤差值最小;輕微的模糊對測量結果影響較小。
綜上所述,在測量時應盡可能避免強光環境,而電梯實際測量環境較暗,有利于該算法的測量;在光線環境較為極端的情況下,基于改進后模型的測量值誤差下降明顯,強光環境下的均方根誤差從0.672下降到0.082,相對誤差率從8.686%下降到1.178%,驗證了DeepLabV3s模型改進的有效性。
4.2 精度與誤差
為了驗證上述自動測量算法的精度與效率,筆者選擇12張未經處理的原圖像作為測量對象(包括模糊、正常、強光、弱光狀態,保證測量的普適性與真實性),并以絕對誤差、相對誤差和均方根誤差為評價標準。
測量實驗結果如表4所示。
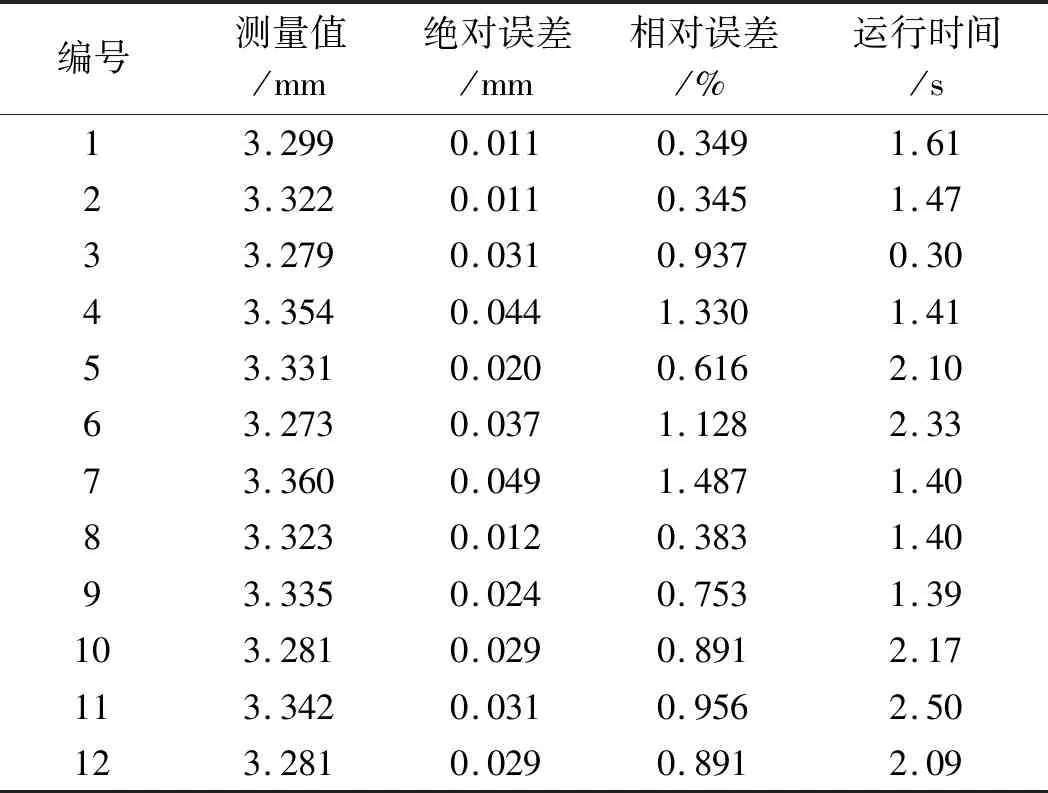
表4 測量實驗結果
由表4可得:針對不同的圖片,該算法表現較為穩定,其中,編號3相機物距較小,圖像中僅需處理兩個繩槽,故運行時間較短,而編號11相機物距較遠,背景、繩槽邊緣復雜,因此處理時間相對更長;
測量值的均方根誤差為0.044 mm,絕對誤差值范圍為0.011 mm~0.049 mm,相對誤差率最大不超過1.487%,滿足曳引輪磨損測量的精度需求;
運行時間控制在2.50 s內,初步實現了曳引輪磨損的實時測量。
與其他算法相比,該算法最大均方根誤差從0.05 mm降低到0.044 mm,且無需限制相機的物距,實現了曳引輪磨損測量自動化的目的,同時提高了測量的精度,這對于電梯安全運行有重要的意義。
5 結束語
筆者采用融合注意力機制的語義分割網絡,將曳引輪繩槽和鋼絲繩進行圖像邊緣分割,設計了一種融合曳引輪圖像特征的圖像處理算法,并通過測量實驗對算法性能進行了驗證,解決了不同光照環境下的曳引輪磨損非接觸式測量問題。
研究結果表明:
(1)與傳統邊緣提取算法相比,基于語義分割的邊緣提取效果更好,并解決了在強光環境下測量誤差大的問題;
(2)算法實現了目標區域截取、磨損點定位、磨損量測量自動化的目標,同時縮短了運行的時間,提高了操作的便捷性;
(3)曳引輪磨損自動測量系統絕對誤差小于0.049 mm,相對誤差率小于1.487%,均方根誤差為0.044 mm,可滿足曳引輪磨損測量的各項要求;同時,驗證了基于DeepLabV3s的曳引輪測量方法在不同光照條件下的魯棒性及測量的精確性。
該方法具有在實際工業場景下應用的潛力。在后續的工作中,筆者將進一步收集足夠數量的實驗數據,改進深度卷積網絡框架,建立更完善的數學模型,以期能夠預測電梯曳引輪的壽命,拓展該系統的功能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
小學生學習指導(低年級)(2018年3期)2018-01-31 02:18:58
光學精密工程(2016年6期)2016-11-07 09:07:19
小學生時代·綜合版(2016年7期)2016-05-14 17:53:49
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
