基于Dim env-YOLO 算法的昏暗場景車輛多目標檢測
2023-03-16 10:21:38郭克友王蘇東
計算機工程 2023年3期
郭克友,王蘇東,李 雪,張 沫
(1.北京工商大學 人工智能學院,北京 100048;2.交通運輸部公路科學研究院,北京 100088)
0 概述
據調查顯示,截止2020 年末,中國汽車保有量已經達到28 087 萬輛,超過美國成為全球汽車總量最大的國家[1]。汽車的普及能夠方便出行,但是同時也導致交通擁堵問題,提高了交通壓力。近年來,計算機技術不斷進步,人工智能發展迅速,智能識別技術在交通行業的應用也越來越廣泛,其中的車輛目標智能檢測引起了研究人員的關注。
車輛目標檢測是一個計算機視覺領域的經典任務,在輔助駕駛、交通監控等方面具有巨大的研究價值和應用前景,在自動無人駕駛領域更是不可或缺[2]。夜間車況復雜、照度急劇下降、駕駛員視線變差、不規范使用的遠光燈等都成為車輛行駛的巨大干擾。因此,在昏暗的場景下對車輛進行識別檢測具有實際應用價值。白天室外平均照度大約為500 lx(lx 為勒克斯,是照度單位)[3],陰天照度一般低于100 lx,昏暗場景一般為照度低于50 lx 的道路環境。人眼在照度低于50 lx 時對周邊事物的判別感知能力明顯下降,相較于白天的自然光,駕駛員對車燈、路燈等輔助照明的適應性也明顯不足。我國一般城市道路夜間照度平均為17.5 lx,本文針對該照度條件下的車輛目標檢測展開研究。
智能檢測技術可以減少城市智慧交通中的人力成本,降低因駕駛員反應不及時或誤操作等因素導致的交通事故發生概率,進一步保障出行安全。對于道路目標的識別,通常分為傳統檢測方法和深度學習檢測方法。傳統檢測方法須隨道路場景和背景不斷變化從而提取不同特征,精度較低,魯棒性也較差[4]。基于深度學習的目標檢測算法可分為兩類:一類是以R-CNN[5]、Faster R-CNN[6]等為代表的兩階段檢測算法,它們使用區域候選網絡來提取候選目標信息;另一類是以YOLO[7]、SSD[8]等為代表的端到端的一階段目標檢測算法。兩階段算法的區域建議模塊計算機內存消耗很大,而一階段算法從學習輸入圖像直接到目標位置和類別的輸出,由于沒有區域候選過程,目標檢測被視為回歸問題,因此提升了檢測速度。其中,YOLOv4 算法以其檢測速度較快、精度較高的特性而受到廣泛的青睞[9]。
本文在YOLOv4 的基礎上提出一種Dim env-YOLO 改進算法。利用MobileNetV3[10]網絡替換YOLOv4 的主干網絡,并在特征金字塔部分引入注意力機制,進一步降低參數量。由于現有公開車輛數據集夜間場景樣本有限,因此本文自制昏暗道路場景下的車輛數據集,在此數據集上對改進網絡進行訓練及測試。為驗證極端照度條件下算法的有效性,設計不同照度實驗場景探索環境照度邊界值,同時為驗證模型的魯棒性,在高斯噪聲、模糊處理、雨霧夜晚等干擾下進行實驗分析。
1 算法原理
1.1 YOLOv4 模型結構
YOLOv4 是YOLOv3 的改進版,其在YOLOv3的基礎上大幅提高了精度和速度[11]。YOLOv4 的主干網絡CSPDarknet53 在Darknet53 網絡的基礎上加入CSP(Cross Stage Partial),特征金字塔部分使用SPP 結構和PANet 結構[12],如圖1 所示。
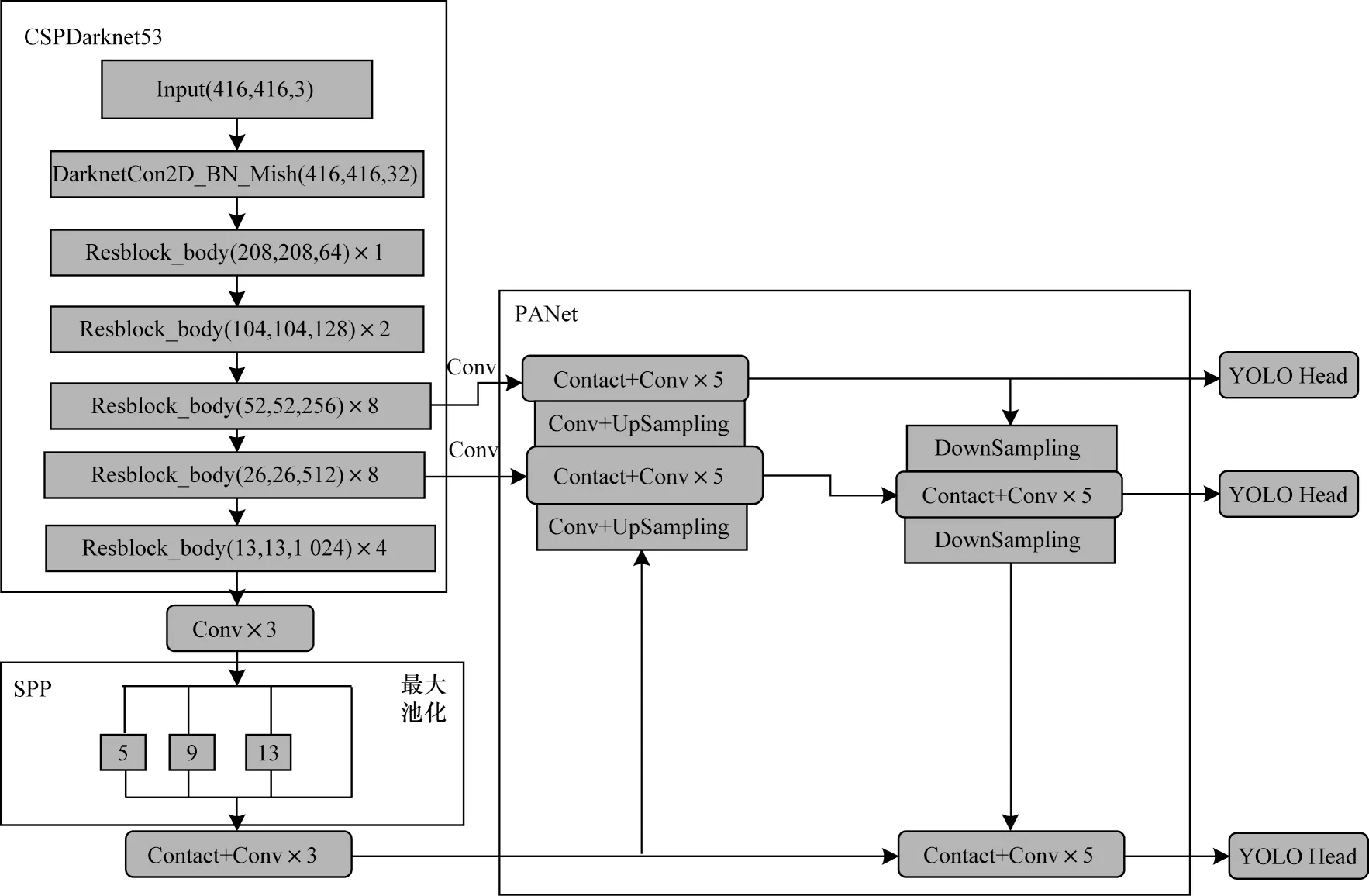
圖1 YOLOv4 結構Fig.1 Structure of YOLOv4
Darknet 網絡采用Mish 激活函數,如圖2 所示。Mish 激活函數是對Leaky-ReLU 的折點小修正,平滑的激活函數允許更好的信息深入神經網絡,從而得到更好的準確性和泛化能力[13]。Mish 函數如式(1)所示:
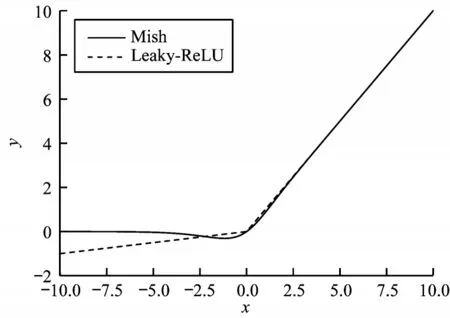
圖2 函數圖像Fig.2 Function images
Darknet53 存在一系列殘差模塊,它們由一次下采樣和多次殘差結構堆疊構成。CSP Net 即為跨階段局部網絡,在原有Darknet53 的殘差模塊中加入了交叉分通道卷積[14]。交叉分通道卷積雖然可以增強CNN 的學習能力,在輕量化和低內存訪問成本的同時增強梯度融合,減小計算瓶頸,但是由于YOLOv4原網絡結構中存在較多的卷積過程,這些卷積模塊計算冗長,導致模型參數過多,計算量仍然較大。
1.2 MobileNet 網絡
神經網絡中的數據在卷積層最耗費時間,輕量化網絡模型一直是研究熱點,因此,深度可分離卷積塊DW 應運而出[15],利用DW 卷積替換傳統的卷積,可以減小參數量,提升檢測速度。DW 卷積分為逐通道卷積和逐點卷積,逐通道卷積過程中一個通道只被分配一個卷積核,兩者一一對應[16],逐點卷積核尺寸為1×1×Cout。對于深度可分離卷積,設輸入特征圖通道數為Cin,shape 為H×W,卷積核尺寸是Ksize,輸出特征圖通道數為Cout,大小為H×W,則:
其中:FLOPsdw指深度可分離卷積計算量;FLOPsconv指傳統卷積計算量。在一般情況下,假定采用3×3的卷積核,那么當Cout相對較大時可以降低近90%的計算量[17]。
此外,MobileNetV3 結合了 MobileNetV1、MobileNetV2 的一系列特點,并使用h-swish 代替swish作為激活函數,減少了運算量,提高了檢測性能。h‐swish函數表達式如式(5)所示:
MobileNetV3 結構詳解如表1 所示。

表1 MobileNetV3 結構參數Table 1 Structural parameters of MobileNetV3
在表1 中,HS 和RE 分別代表h-swish 激活函數和ReLU 激活函數,步距表示每次block 結構所用的步長[18]。由表1 可知,每個特征層經過bneck 模塊,輸入的特征層尺度均多次發生相應的變化,其中又在5、6、7、12~16 層加入了注意力機制。
1.3 損失函數
在YOLO 網絡中,每一張完整圖片都被有效特征層分成S×S的網格,隨后在網格中心建立先驗框的局部坐標,再通過網絡預測的坐標偏移量、物體置信度和種類置信度[19]三項指標,與每一個先驗框分別比較損失以進行擬合,最后根據得分排序和非極大值抑制篩選得出預測結果。本文模型采用二分類交叉熵的方法計算損失函數[20],將多分類目標問題轉化為二分類問題,類別劃分轉為此目標物體是否屬于該分類類別,損失函數如式(6)所示:
其中:Lxywh為真實框的坐標軸偏移量和長寬差值;λcoord為坐標系數;Lconfi為目標置信度誤差,分為有無目標兩項,λobj和λnobj分別表示是否有目標的置信度系數;Lclasses為物體種類的分類損失;表示第i個網格第j個先驗框的擬合情況。
IoU[21]是目標檢測中經典的評價指標,它反映了預測邊框與真實邊框的重疊程度,即預測框與真實框交集與并集之間的比值,計算方式如圖3 所示,其中,A、B分別表示預測框和真實框的面積。
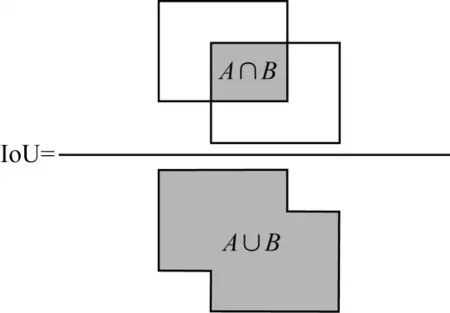
圖3 IoU 定義Fig.3 The definition of IoU
但是,僅僅依靠IoU 進行評價會存在一些問題[22],若真實框和預測框并無相交,則IoU 為0,此時無法體現兩者的距離(重合度)。同時,因為損失LLoss=0,梯度不回向傳播,所以無法進行學習訓練。此外,IoU 僅依靠預測框和真實框的重合面積,忽略了位置關系,如圖4 所示,3 種情況下IoU 均相等,為0.33,然而真實框和預測框的重合程度存在差異,回歸效果從左至右依次遞減。
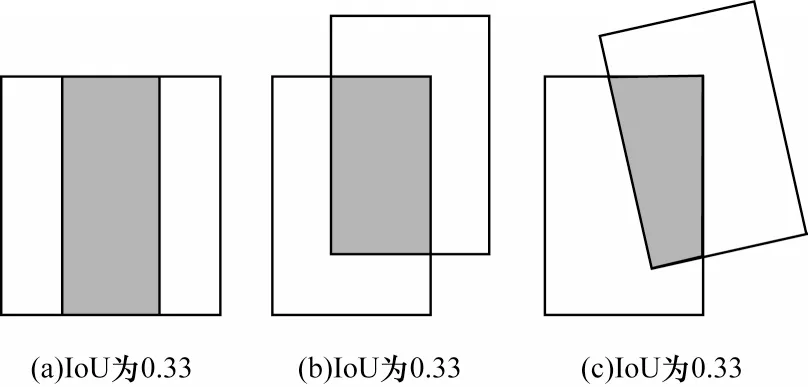
圖4 3 種IoU 均相同的情況Fig.4 Three cases that IoUs are the same
針對上述問題,本文引入CIoU 代替IoU 作為邊框回歸損失函數評價指標[23]。CIoU 將預測框和真實框之間的關鍵幾何因素,即重疊面積、中心點距離和長寬比列入邊框回歸損失,使得邊框回歸更加穩定,收斂精度更高。CIoU 損失函數如式(7)所示:
其中:b和bgt分別表示預測框與真實框的中心點;ρ(·)表示歐氏距離;c表示預測框與真實框重疊多邊形的最小外接矩形對角線長度;α和v為懲罰因子,它們擬合了預測框和真實框的長寬比,α是協調比例參數,v是用來衡量長寬比一致性的參數。α與v的計算公式分別如式(8)和式(9)所示:
2 Dim env-YOLO 網絡
2.1 框架改進
由于環境昏暗,使得目標檢測精度有所下降,為了在低光照的條件下增強圖像的色彩對比度,凸顯目標信息,可以引入圖像暗光增強技術。傳統的暗光圖像處理法有直方圖處理、伽馬均衡等方法[24]。近年來,隨著計算機技術的發展,研究人員嘗試利用深度學習的方法處理暗光圖像,如MSR-net 算法、Ret-Net 模型、K.D++算法等[25]。
本文選擇一種輕量化HDR 暗光圖像增強方法,如圖5 所示。該方法僅對缺失光照部分進行補光增強,對于光照充足的區域,不會產生較大的影響,從而避免已有一些方法在暗光增強的同時造成圖片過度曝光從而影響檢測處理效果的問題。

圖5 HDR 圖像增強效果Fig.5 HDR image enhancement effect
針對昏暗環境的車輛目標檢測,本文在YOLOv4的基礎上結合HDR 圖像暗光增強技術,設計一種Dim env-YOLO 道路車輛檢測網絡,其結構如圖6 所示。網絡輸入是經暗光增強預處理后的數據圖片,主干網絡由CSPDarknet 替換成MobileNetV3 網絡,將主干網絡中用到的普通卷積替換成深度可分離卷積,并在隨后有效特征層和加強特征網絡以及上采樣后的結果中引入注意力機制模塊,進一步減少模型的參數量[26]。
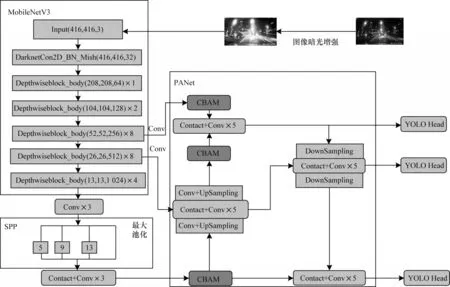
圖6 Dim env-YOLO 網絡結構Fig.6 Dim env-YOLO network structure
2.2 算法優化
神經網絡的學習率是比較重要的超參數,其值大小與模型性能密切相關[27],如何設置學習率一直是個難題,同時,訓練過程中的損失通常只對參數空間的某些特定方向敏感。為進一步提高算法的檢測效率,研究人員提出一系列算法優化方法。為避免引入過多的新參數,致使參數量增加,本文采用優化效果較好、魯棒性較高的Adam 自適應學習率算法,其描述如下:
3 實驗結果與分析
3.1 實驗描述
本文采集北京市某區域一帶道路的數據自制數據集,對于昏暗城市道路,主要目標類別分為轎車、公交車和卡車,如圖7 所示。數據集包含2 000 張圖片,約11 000 個車輛目標,使用LableImg 對車輛進行標注,制作成VOC 數據集,標注情況如圖8 所示。

圖7 車輛類別Fig.7 Classes of vehicle

圖8 數據集示例Fig.8 Dataset example
本文實驗在Ubuntu18.0 操作系統上運行,GPU 為NVIDIA 1080Ti,內存為16 GB。深度學習框架為PyTorch1.2.0,CUDA 版本為11.4,Python 版本為3.7.0。
實驗采用凍結訓練的方式以提高訓練速度,節省GPU 顯存[28]。由于主干特征提取網絡所提取的特征通用,因此引入遷移學習的思想,依次進行凍結、解凍訓練,由此提高訓練效率并防止權值被破壞。網絡參數設置如表2 所示。

表2 網絡參數設置Table 2 Network parameters setting
網絡的最終性能不僅取決于模型本身的結構和參數,還依賴于硬件平臺的配置,檢測結果影響因素如圖9 所示。
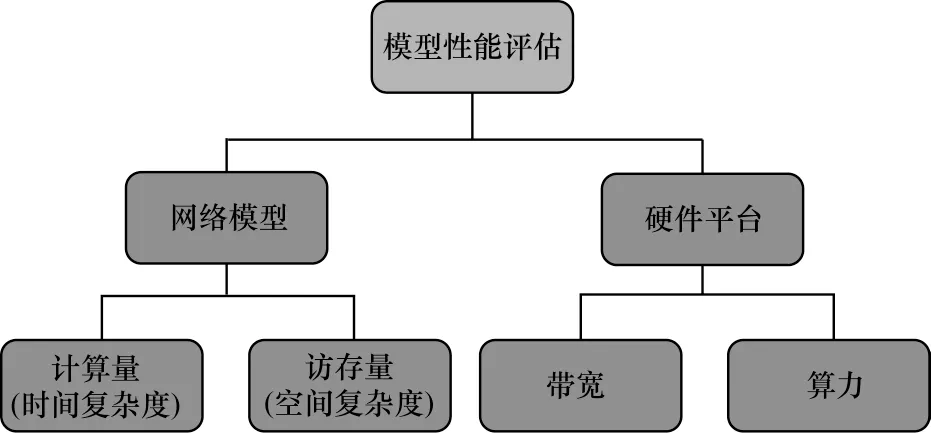
圖9 網絡模型的影響因素Fig.9 Influence factors of network model
計算機的計算能力用算力和帶寬來評估[29],算力即FLOPs(Floating-point Operations Per Second),表示計算機每秒執行的浮點運算次數;計算機的帶寬指計算機內存交換能力,用Byte/s 表示。算力和帶寬之比則為計算機的計算強度上限Imax,單位是FLOPs/Byte,表示每單位內存交換中完成的浮點運算量,公式表達如式(10)所示,計算強度上限數值越大,表示計算機內存使用效率越高。
網絡模型的計算能力是指模型的計算量和訪存量,分別是模型浮點計算次數和模型一次迭代(iteration)前后傳播的內存交換量,即時間復雜度和空間復雜度。模型的時間復雜度表示為:
其中:D表示模型卷積層數;Cl-1表示l層輸入通道數;Cl表示輸出通道數;K為卷積核邊長;M是輸出特征圖的大小。時間復雜度決定訓練的時長,訓練耗時過多的模型結構較為復雜。
模型的空間復雜度表示為:
空間復雜度是網絡的各層參數權重和輸出特征圖所占的內存,訪存量越大表示網絡參數越多。
3.2 實驗數據分析
本文進行實驗驗證所提模型的效果,如圖10 所示,設置凍結階段迭代次數為50 次,由于模型主干被凍結,特征提取網絡不發生改變,占用顯存較少,因此網絡僅發生微調。
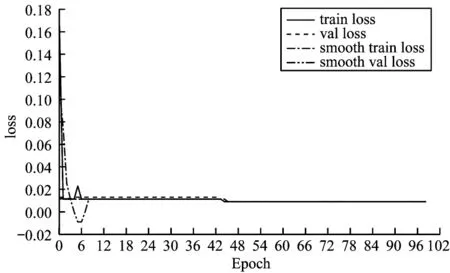
圖10 Dim env-YOLO 訓練過程中loss 的變化情況Fig.10 Changes of loss during Dim env-YOLO training
在凍結階段,改進的網絡loss 值不斷下降并收斂。在解凍階段,占用顯存變大,主干網絡參數發生變動,但是訓練效果提升,損失值進一步下降,由此可以看出網絡模型具有良好的收斂能力。
圖11 所示為本文算法在簡單場景下的檢測效果,可以看出,該算法可成功檢測出昏暗環境下的近距離車輛目標。

圖11 簡單場景下的檢測效果Fig.11 Detection effect in simple scenes
如圖12 所示,對于昏暗道路常見的小汽車、SUV 中型車和大巴客車,本文算法的檢測AP 值分別為93%、91%和87%,檢測mAP 值達到90.49%。
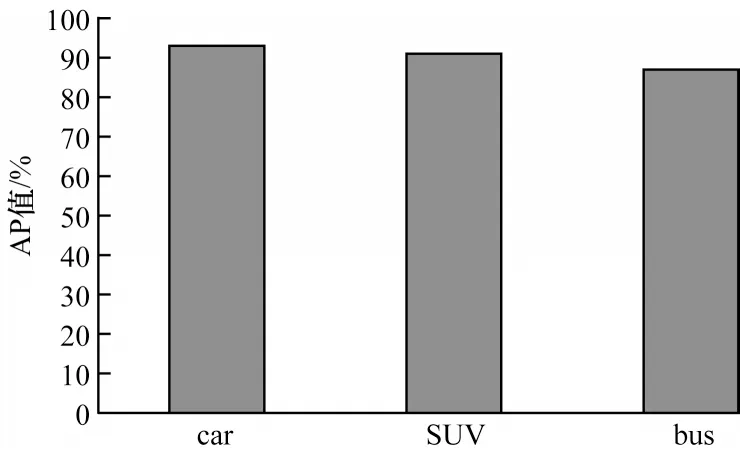
圖12 本文算法的AP 值Fig.12 AP values of this algorithm
3.3 復雜場景對比實驗
為了進一步驗證復雜道路情況下的車輛目標檢測效果,擴充已有數據集,新增包括擁擠路口場景下的車輛目標、遠距離車輛目標以及重疊的車輛目標。制作數據集時要訓練樣本的多樣性,同時減少數據冗余和訓練體量。隔幀抽取所拍攝的車流視頻能夠保證不同密度,從而獲得較優的數據樣本,如圖13 所示。

圖13 復雜路口數據樣本Fig.13 Complex intersection data sample
夜間環境照度不足、車燈刺眼干擾、明暗對比強烈,嚴重影響駕駛員對道路情況的判斷,使得暗光條件下路口阻塞車流檢測難度提升。如圖14 所示,對于昏暗復雜的路口,Dim env-YOLO 檢測效果優異,證明其在低照度的復雜場景下具有有效性,可以為夜間智能出行提供一定技術支持。

圖14 復雜場景下的檢測效果Fig.14 Detection effect in complex scenes
3.4 算法魯棒性驗證和最低照度研究
按照國家相關規定,一般城市主干道路路燈照明要求為30 lx,次路約為10 lx。為了進一步探究更低照度的道路車輛識別效果,測試微弱路燈光的城市次干道(照度僅為3~5 lx)和支路以及幾乎黑暗(照度為0.05 lx)的居民巷等路況下的車輛目標識別效果,實驗結果如圖15 所示。從圖15 可以看出,當車燈直射車輛和在照度極低的暗處角落,車輛依舊可以被準確檢測出,即對于光照不均勻、光斑混照等復雜情況,本文算法識別效果依然良好。

圖15 城市支路檢測效果(照度為5 lx)Fig.15 Detection effect of urban branch road(illumination is 5 lx)
對于照度低于0.5 lx 的黑暗道路場景,實驗結果如圖16 所示。從圖16 可以看出,對于汽車燈光照射的區域,可檢測出車輛目標,而無車燈照射區域,車輛目前無法被識別,純黑暗區域可以通過閃光燈補光來提升識別率。

圖16 黑暗道路檢測效果(照度為0.5 lx)Fig.16 Detection effect of dark road(illumination is 0.5 lx)
綜上,在照度不低于5 lx 的道路環境,本文算法識別準確率較好。為了進一步驗證模型的魯棒性,隨機選取夜間道路車輛并加入高斯噪聲、模糊、雨霧夜晚等擾動,路況如圖17 所示,檢測結果如圖18 所示,實驗定量結果如表3 所示。
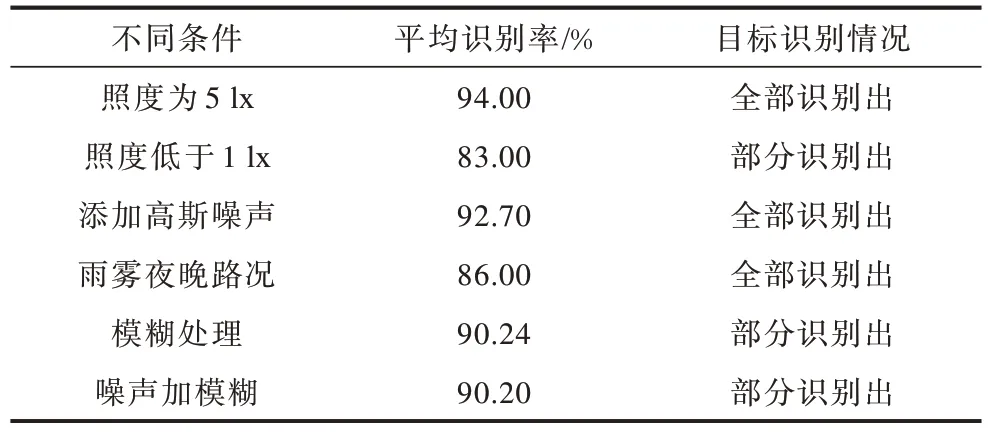
表3 不同照度條件及干擾下的目標識別情況Table 3 Target recognition under different illumination conditions and interference

圖17 擾動下的4 種路況Fig.17 Four road conditions under disturbance

圖18 不同路況下的檢測結果Fig.18 Detection results under different road conditions
從圖18 和表3 中的數據可以看出,即使在低照度、復雜噪聲下,實驗結果也未隨擾動而大幅退化,平均識別率能達到86.00%以上。在極黑暗的環境中,車燈照射區域識別準確率良好,對于模糊擾動敏感度稍有降低,對于高斯噪聲具有更好的魯棒性,尤其在雨夜體現出良好的泛化性能,使得本文算法具有廣闊的應用前景。
3.5 與經典模型的對比
為了驗證本文Dim env-YOLO 模型相較其他經典網絡的優勢,選取3 種常用的目標檢測模型與本文Dim env-YOLO 進行性能對比分析,用于對比的檢測模型包括Faster-RCNN、YOLOv3 以及原始YOLOv4。在實驗驗證過程中,用4 類檢測器分別訓練相同的數據集,訓練結果如表4 所示。
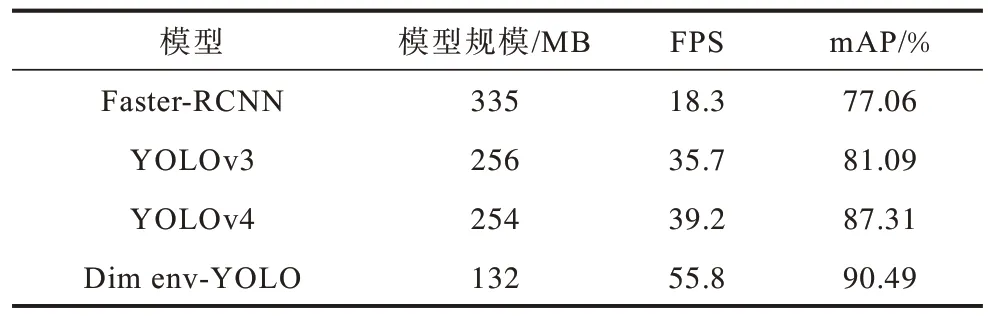
表4 不同模型的效果對比Table 4 Effect comparison of different models
從表4 可以看出,在昏暗場景下,本文算法的mAP值比原始YOLOv4 提高了3.18 個百分點,優于同等情況下的其他網絡模型,且通過對比可知,本文模型的體量約為Faster-RCNN 的40%,約為YOLOv3 和YOLOv4的50%。
4 結束語
本文基于YOLOv4 提出一種昏暗條件下面向道路車輛目標檢測的Dim env-YOLO 算法,以改善原始YOLOv4 網絡夜間檢測精度和速度較低的問題。對夜間圖片進行暗光增強處理,使用MobileNetV3替換CSPDarknet 主干特征提取網絡,引入注意力機制選擇重要信息,利用深度可分離卷積減少模型參數,從而提升檢測效果。實驗結果表明,Dim env-YOLO 對于夜間小汽車的檢測AP 值達到96%以上,且在各種噪聲干擾下依然具有良好的魯棒性,優于同類型模型在昏暗光照條件下的檢測效果,本文算法可以為夜間場景下的車輛目標檢測提供一種新的思路。
Dim env-YOLO 算法可以滿足夜間智慧交通的實時性要求,為識別道路車輛、分析夜間道路路況和路口阻塞情況等提供技術支持。但是模型同時也存在一些問題,如數據集采集角度單一化。下一步將豐富訓練集,采用俯角拍攝道路車輛,增加卡車、公共汽車等大型車輛的樣本集,以及使用更多不同的目標場景數據集等,從而實現更復雜場景下的高效車輛目標檢測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
