基于RoBERTa的多標簽作業許可文本分類方法
2023-03-16 10:24:54長慶油田公司許斌張亮陳喆
數字技術與應用 2023年2期
長慶油田公司 許斌 張亮 陳喆
作業許可的本質與核心是風險管理,作業前危害辨識與風險分析是一項費時費力的工作,過于依賴人的專業經驗。隨著信息化的發展,大量作業許可風險數據被保存下來,但這些數據多以文本形式存在,難以提取有用信息實現共享和復用。針對此問題,本文提出一種基于RoBert的多標簽作業許可文本分類模型,可實現對高危作業的作業類型、危害因素、安全措施等信息的多標簽自動分類和提取。最后在中石油某企業近10萬條作業許可數據集上進行模型訓練與測試,實驗結果表明,該多標簽分類模型在測試數據集上的平均F1值達到86%,可有效提取高危作業風險信息。
作業許可是指在從事高風險作業及在生產或施工作業區域內工作規程未涵蓋到的非常規作業(簡稱高危作業)等之前,為保證作業安全,必須取得授權許可方可實施作業的一種制度[1],是開展危害識別和作業前風險分析的前提和保障,是減少和避免事故發生的重要措施之一[2]。
高危作業實行作業許可制度的核心和靈魂是風險辨識與評估,然而風險辨識與評估是一個專業、費時且以人為中心的分析過程,其本質上是主觀的,依賴于專業經驗與能力。當前作業許可的管理過程中,存在許多走過場的現象,如在危害因素辨識時,大多是簡單標注一下許可證上羅列的有關風險,沒有真正開展危害因素辨識和風險評估工作,所制定的措施也多是抽象型內容,不具可操作性[3]。隨著網絡技術的迅速發展,國內大多數石油化工企業建立了作業許可管理信息系統,積累了大量作業許可證數據,但這些數據大多處于靜態數據庫中,且大量數據以文本形式保存,無法實現共享和復用[4]。
通過研發基于RoBert的多標簽作業許可文本分類模型,挖掘現有作業許可風險數據,提煉和聚合大量風險評估專家的知識和經驗,實現對高危作業的作業類型、危害因素、安全措施等信息的多標簽自動分類和提取,解決作業許可風險辨識不全面、安全措施不具體的問題,從而提升作業許可管理水平。
1 相關研究
目前主流的多標簽文本分類模型為端到端的模型,模型結構分為文本特征提取器和分類器。其中對性能影響最大的是文本特征提取器部分,目前主流的文本特征提取器有卷積神經網絡、循環神經網絡與預訓練語言模型。
1.1 卷積神經網絡
卷積神經網絡(Convolutional Neural Network)簡稱為CNN,與普通的全連接神經網絡相比,卷積神經網絡的結構有很大不同,可以看成是一種對全連接神經網絡的改進,通過添加一種被稱為卷積核的特殊結構來提取圖像的局部特征。卷積核相當于一個濾波器,卷積操作就相當于對圖像使用濾波器進行濾波,得到該濾波器對應的特征圖。在傳統的圖像處理中,濾波器也就是卷積核都是經過特殊設計的,而在卷積神經網絡中每一個卷積核只需要進行隨機初始化,卷積核的參數會在訓練過程中自動優化。
一般來講,圖像的特征向量的維度等于該圖像所包含的像素的數量,一張100×100的三通道圖像的像素點有30000個,該圖像的特征向量有30000維,若使用全連接神經網絡則網絡的參數量會特別龐大,不僅會大大提高訓練的難度還會導致過擬合,并且真實場景中的圖像大小會遠遠超過100×100。卷積神經網絡使用了參數共享機制來解決這一問題,同一個卷積核所做的卷積操作本質上就是使用同一套參數在整張圖像滑動做內積,以此達到參數共享的目的,這大大減少了模型的參數量。這一操作的依據為圖像數據具有一種叫做局部感知野的特性,即在圖像中距離近的像素往往關系并具有相同的語義特征。
卷積神經網絡同樣可以應用于自然語言處理中[5],因為人類語言同樣具備一定的局部感知野,在一句話中往往鄰近的漢字之間具有更加緊密的關系。在自然語言處理中,每一個漢字或詞語都對應一個N維的字向量或者詞向量,一個包含M個字或詞的句子可以表示為一個MxN的矩陣,可以進行卷積操作。不同的是對于圖像的卷積是二維卷積,卷積核可以在整張圖片的X軸和Y軸上移動,而對詞向量矩陣的卷積是一維卷積,這是因為卷積核必須有一個維度與詞向量的維度相同,即卷積核只能在代表句子長度的維度上做卷積運算,以確保句子中每一個詞語的信息不丟失。如圖1所示是用于作業許可數據文本分類的卷積神經網絡模型,其中Embedding層為雙通道,兩個通道都使用了CNPC詞向量進行映射,不同的是其中一個通道的數值隨著模型的訓練一起更新,而另一個通道的參數保持不變。卷積層使用了3個不同長度的一維卷積核來提取文本數據的N-Gram特征,最后將三個不同的卷積核提取的特征拼接起來接入一個線性分類器進行分類。本章節中的基于卷積神經網絡的文本分類模型參考了TextCNN的模型結構。
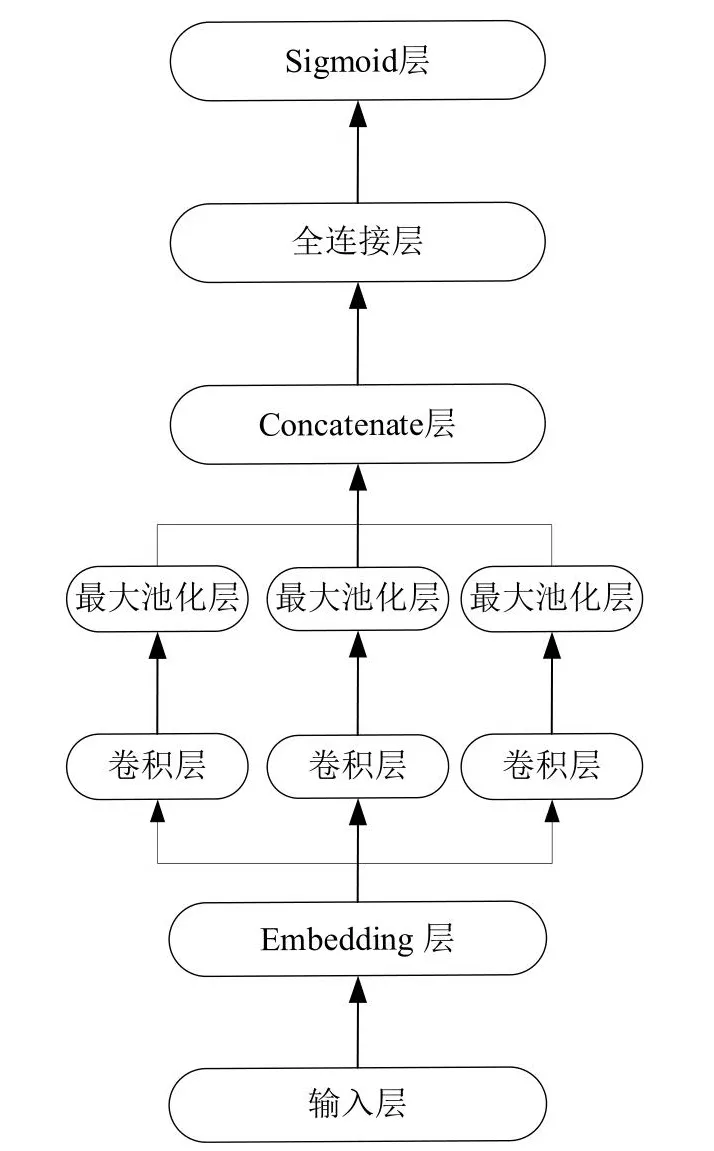
圖1 CNN文本分類模型Fig.1 CNN text classification model
1.2 循環神經網絡
循環神經網絡(Recurrent Neural Network)簡稱為RNN。不同于卷積神經網絡和全連接神經網絡,循環神經網絡主要用于處理序列數據,即在時間或空間上有先后順序的數據,例如人類的語言文字、股票的走勢等。卷積神經網絡和全連接神經網絡并不適合處理這類序列數據,因為這類網絡無法捕捉到序列數據在時間和空間上的關系,模型在處理某一個序列的某一個時間點上的數據時只會關注該時間點上的數據,這意味著該數據會被孤立。循環神經網絡能夠回顧序列中當前時間點之前的數據來產生當前時間點的輸出,通過回顧可以了解所有之前的輸入。但從實際操作中看,它只能回顧最后幾步。如圖2所示為本論文設計的用于作業許可數據文本分類的循環神經網絡模型。RNN同樣可以用于文本分類任務[6],本論文使用Bi-LSTM來提取作業許可文本的上下文特征,最后接入全連接層與Softmax層進行分類并輸出分類結果。該基于循環神經網絡的文本分類模型參考了TextRNN的模型結構。
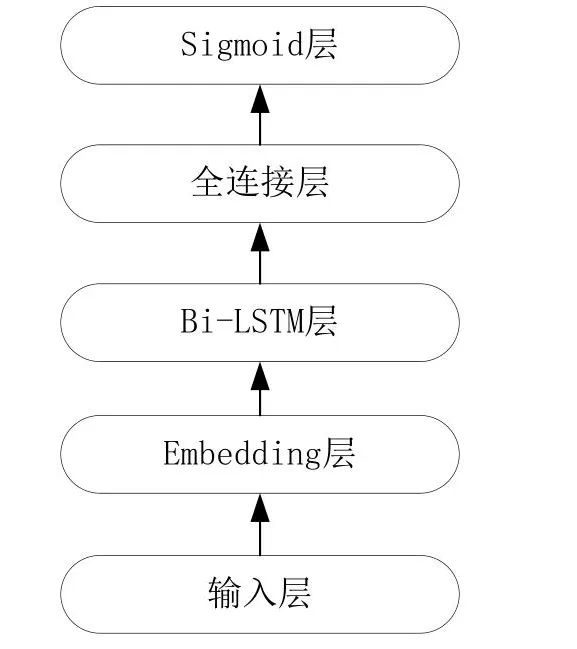
圖2 RNN文本分類模型Fig.2 RNN text classification model
1.3 預訓練語言模型
深度學習技術在NLP任務中已有廣泛應用,基于人工神經網絡的NLP方法正在逐步取代傳統的NLP方法。傳統的NLP文本分類方法需要人工設計文本特征,人工設計特征效率低下且分類效果并不理想,而基于神經網絡的NLP方法能夠從大量的訓練樣本中自動提取文本特征,相比于傳統NLP方法,基于人工神經網絡的NLP方法更加高效且分類準確率更高,人工神經網絡技術大大簡化了各類NLP系統的開發難度。盡管已經能夠將神經網絡模型應用于NLP任務中,但由于缺少像ImageNet那樣的大規模的經過人工標注的數據集,與計算機視覺領域相比,神經網絡模型為NLP任務帶來的性能改進并不顯著。而且深度神經網絡通常具有大量的參數,使得它們在這些小的訓練數據上過于擬合,在實際應用中不能很好地推廣,所以早期NLP任務的模型結構相對簡單(淺層神經網絡)。本論文所研究的作業許可文本分類任務同樣是一個有監督的學習任務且訓練樣本較少、獲取成本較高,本論文使用的前3種網絡均為淺層神經網絡。
目前機器在自然語言閱讀理解上的表現甚至已經超越了人類的表現,這都歸功于新的模型結構的提出,那就是基于Self-attention機制的Transformer模型[7]。Transformer是由谷歌公司提出的一種Seq2Seq模型,在原始論文中用于語言翻譯任務。Transformer相對于LSTM來說最大的不同點就是LSTM是迭代計算的,即計算得出前一個字符的隱狀態后才能計算下一個字符的隱狀態。而Transformer是并行計算的,即能夠同時計算整個序列中所有字符的隱狀態,本質上就是能夠轉化為張量運算。這一特征使得Transformer能夠很好地利用GPU進行加速,從而使得訓練大型模型成為可能。目前在自然語言處理領域的各項任務中表現最好的模型都是基于Transformer模型結構在大規模語料數據上訓練得到的,如BERT、XLNet、RoBERTa 等。
Transformer相較于LSTM的另一個明顯優勢就是Transformer能夠解決長期依賴問題,盡管LSTM相較于經典RNN模型在長期依賴方面有所改善,但依然不能完全解決長期依賴問題。Transformer中使用的自注意力機制能夠使序列中每一個字符的隱狀態都包含序列中其他字符的信息,無論該字符與序列中其他字符距離多遠都能夠等價編碼。Transformer有編碼器和解碼器兩部分組成,而基于Transformer的預訓練語言模型僅使用了其編碼器部分。下面對Transformer模型的編碼器進行詳細介紹。
如圖3所示為Transformer編碼器的模型結構。其中“位置信息”節點代表的操作是為對輸入向量添加位置編碼,因為對于Transformer來說一個序列中的所有字符在位置上都是等價的,但對于自然語言來說字符的位置信息至關重要,包含相同漢字的兩段中文其含義可能截然不同。所以要為輸入字符向量添加位置編碼,一般使用正弦函數進行位置編碼。“多頭自注意力”節點所代表的操作為對輸入向量進行Self-attention操作,這是Transformer模型的核心操作,通過該操作使得每個字符的隱狀態包含有該句子中其他所有字符的信息。“Add&Norm”節點所代表的操作為Layer Nomalization和殘差連接。在反向傳播的過程中,殘差連接梯度可以直接傳到初始層。Layer Nomalization的作用是將隱狀態歸一為標準正態分布。通過添加這兩個特殊的層,能夠加快訓練過程中模型的收斂速度。下面為各個步驟的主要數學表示:
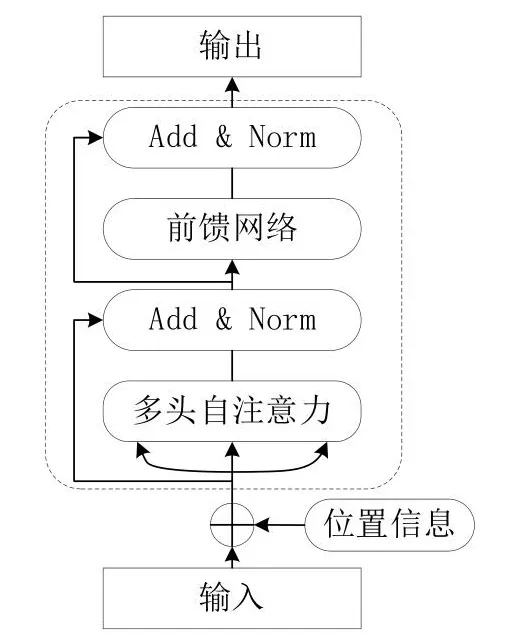
圖3 Transformer編碼器模型結構Fig.3 Transformer encoder architecture
(1)字向量與位置編碼
(2)自注意力機制
(3)殘差連接與Layer Normalization
(4)Feed Forward
圖3為一個處理單元,Transformer的編碼器由多個這樣的單元組成,通過增加層數來增加參數量,提高模型特征提取能力和泛化能力。
BERT[8]是最具代表性的一種預訓練語言模型,其模型架構本質上就是Transformer的編碼器部分。BERT首先在大規模公開語料上進行預訓練,學習語言的通用特征,然后再將該預訓練模型在具體的下游任務中進行微調。BERT的預訓練過程是無監督的,即無需人工標注的訓練數據,這意味著能夠充分利用互聯網上的各種文本數據。
預訓練語言模型有上下文相關模型和上下文無關模型兩種。上下文無關模型為詞典中的每一個詞都生成一個向量表示,即詞向量。但上下文無關模型會存在一詞多義的問題,即同一個詞向量編碼了多種語義,Word2Vec和GloVe是最具有代表性的上下文無關模型。與上下文相關語言模型不同,上下文相關的預訓練語言模型能夠根據句子的上下文來為詞語生成詞向量,BERT是最具有代表性的上下相關模型。
BERT的模型架構與Transformer的編碼器部分基本一致。該模型使用了兩種特殊的訓練方式,第一種是將輸入序列中15%的單詞(中文以漢字為單位)屏蔽掉,然后使用一個深層的Transformer編碼器來預測被屏蔽掉的單詞;第二種是判斷兩個隨機抽取的句子是否存在上下文關系。
1.4 二元交叉熵損失
二元交叉熵損失簡稱為BCELoss(Binary Cross Entropy Loss),主要用于作為多標簽文本分類的損失函數。單標簽文本分類的目標是根據輸入序列,找出概率最高的一個標簽。多標簽文本分類的目標是根據輸入序列找出所有與輸入序列相關的標簽。在模型構造層面的區別是,單標簽分類模型使用Softmax函數將神經網絡最后一層的輸出映射到和為1的0~1區間上,并使用CELoss(Cross Entropy Loss)作為損失函數。與單標簽分類不同,多標簽分類使用Sigmoid將神經網絡最后一層每一個神經元的輸出獨立的映射到0~1區間,使用BCELoss(Binary Cross Entropy Loss)作為損失函數,單獨計算一每個標簽的二分類損失并求均值,BCELoss的計算公式如式(9)所示:
2 基于RoBERTa的多標簽分類模型
由于作業許可數據中所涉及的與審核主題相關的要素較多,并且作業許可數據大多記錄不規范,存在大量的噪聲數據,所以淺層的神經網絡模型較難取得理想的分類效果。為盡可能提高作業許可數據分類的準確率,本論文使用由Brightmart開源的Large版本的中文RoBERTa預訓練模型[9,10],該模型在多個中文文本分類數據集上取得了state-of-the-art的成績。RoBERTa的模型結構與BERT基本一致,與谷歌的原版BERT模型相比在如下幾個方面做出了改進:
(1)改進訓練數據的生成方式和預訓練任務:使用全詞遮蓋來代替字符遮蓋。首先將訓練語料進行分詞,然后隨機選取10%的詞進行遮蓋操作,除進行全詞遮蓋之外還取消了句子預測任務。
(2)使用豐富的訓練語料:訓練語料涵蓋了多個領域共計超過30G中文文本數據。
(3)訓練更久:總共訓練了近20萬個Epoch,總計約近16億個訓練樣本。
(4)增大預訓練Bach Size:使用8k的Batch Size進行預訓練。
在此基礎上,本論文對該預訓練語言模型做出了如下改進[11]:
在RoBERTa模型中,越靠近輸入層就能夠提取越底層的通用的語義和語法信息。基于此,在微調過程中凍結前3層的參數且后續的層不再使用固定的學習率,而是對于較低的層次使用較小的學習率,較高的層次使用較大的學習率,即使用線性衰減學習率。通過實驗得出當初始學習率設為2e-5,衰減系數設為0.9時可以獲得較好的效果。
如圖4所示為基于RoBERTa的多標簽作業許可文本分類模型,在該模型中RoBERTa可以看做輸入文本的上下文特征提取器,該特征提取器可以用來獲得整個輸入句子的特征。
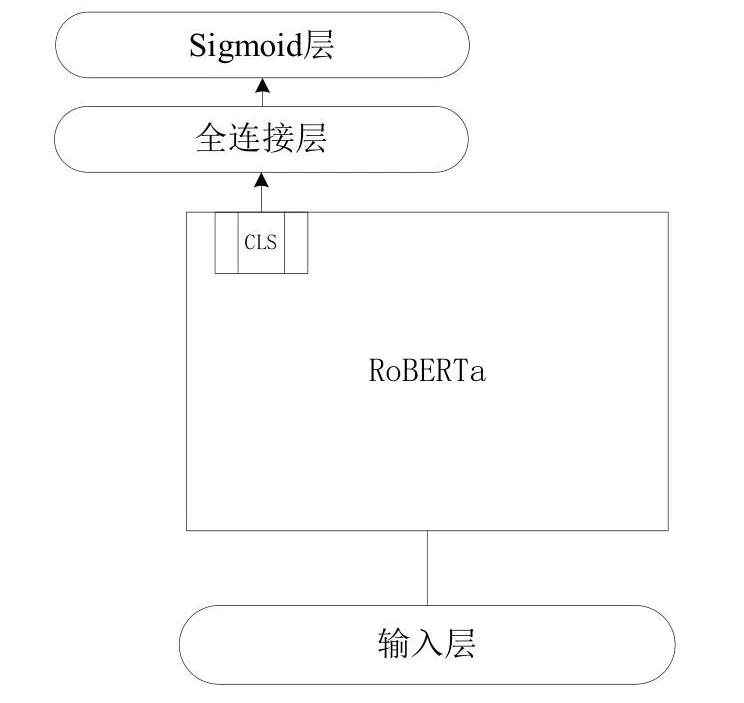
圖4 多標簽RoBERTa文本分類模型Fig.4 Multi-label RoBERTa text classification model
RoBERTa模型在使用時需要預先指定輸入序列的最大長度,超過最大長度需要進行截斷處理,不足則補0,若最大長度設置過大會導致顯存溢出,無法進行訓練。本論文通過計算得出作業許可數據的平均文本長度為231,結合實驗中使用的GPU的顯存大小,本論文設置輸入序列的最大長度為256。
RoBERTa在輸出句子每個字符對應的上下文相關詞向量的同時還會輸出一個特殊標記CLS對應的向量。CLS中包含有整個輸入文本的文本特征,可以將CLS視為整個句子的特征向量。使用模型進行多標簽預測時只要將CLS向量接入一個線性分類器(即一個全連接層與一個Sigmoid層的組合)獲得模型在各個標簽上的預測得分,將得分大于0.5的標簽作為最終預測結果。
3 實驗結果及分析
3.1 實驗數據
實驗選取中石油某企業2019—2021年10萬條作業許可證數據集,每一條作業許可數據樣本均為人工填報,已被標注為多個類別標簽,是典型的多標簽多分類任務。數據包括工作內容文本描述和每條文本對應的工作類型、危害識別、安全措施多個主題類別,數據具體形式如表1所示。

表1 作業許可證數據形式Tab.1 Data forms of operation permits
多標簽分類就是要將作業許可證工作內容描述標記為臨時用電、高處作業等7類工作類型的一種或多種;觸電、墜落等15類危害因素的一種或多種;絕緣服、安全帶等29類安全措施的一種或多種;共計51個標簽。每類標簽的樣本數統計如表2、表3和表4所示。

表2 各類工作類型樣本數統計Tab.2 Statistics of samples of various types of jobs
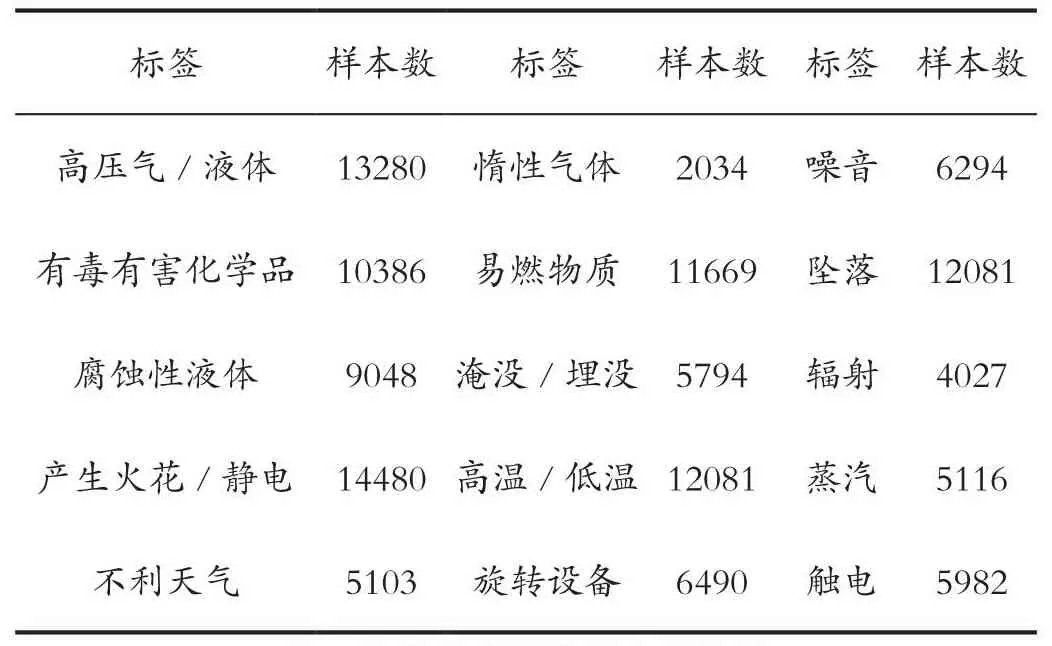
表3 各類危害因素樣本數統計Tab.3 Sample number statistics of various hazard factors
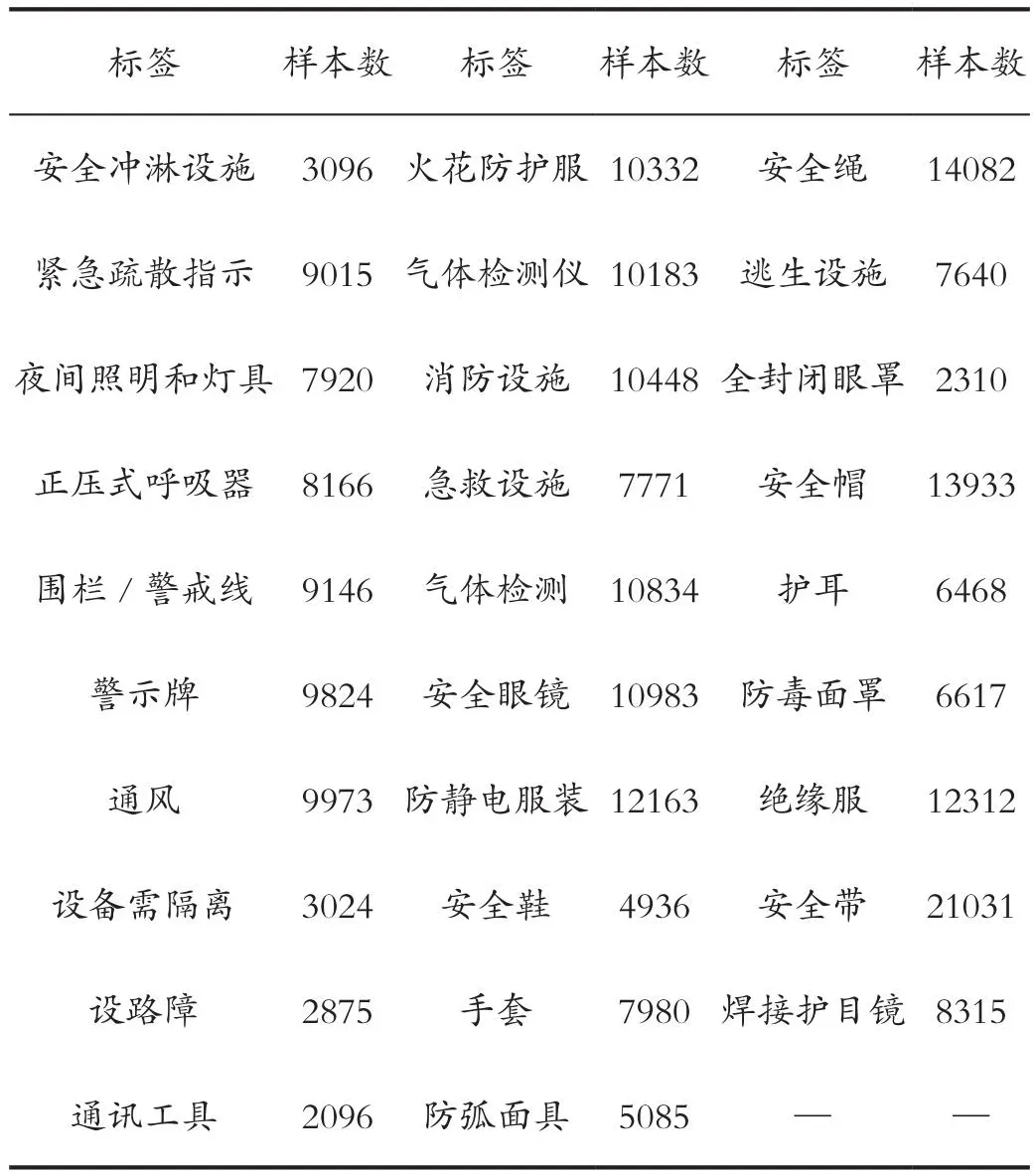
表4 各類安全措施樣本數統計Tab.4 Statistics on samples of various security measures
3.2 模型參數
本文選取全連接神經網絡、卷積神經網絡、循環神經網絡與本文提出的基于RoBERTa的多標簽分類模型進行對比實驗。在模型訓練過程中,4種模型均使用AdamW算法作為優化算法更新模型權重。除此之外,在模型調優過程中使用貝葉斯優化算法與十折交叉驗證選取最優的超參數組合,相比于網格搜索與隨機搜索,基于高斯過程貝葉斯優化算法可以從概率上找到一個“很可能”更好的超參數。
3.3 評估指標
多標簽分類可以看作多個單標簽二分類問題,二分類問題最常使用的評價指標為F1值。因此,本論文使用平均F1值(macro F1)作為多標簽文本分類的評價指標。原始的F1值只針對二分類問題,包括2個指標:精確率(precision)和召回率(recall)。如式(10)、式(11)、式(12)所示分別為精確率、召回率和F1值的數學表達式。
其中TP和FP分別代表真陽性和假陽性的預測結果數目,FN代表真陰性和假陰性的預測結果數目。宏平均F1值為各個類別的F1值的平均值,宏平均F1值的數學表達式如式(13)所示,其中N為類別總數。
3.4 實驗結果分析
本論文在多標簽作業許可文本分類任務上分別嘗試了全連接神經網絡(FCNN)、卷積神經網絡(CNN)、循環神經網絡(RNN)和預訓練語言模型。如表5所示展示了不同的模型在測試集上的實驗結果,其中各個模型的超參數均為經過貝葉斯優化與十折交叉驗證所獲得的超參數組合,在本小節中將這些通過該種方法得到的超參數組合稱為最優超參數組合。
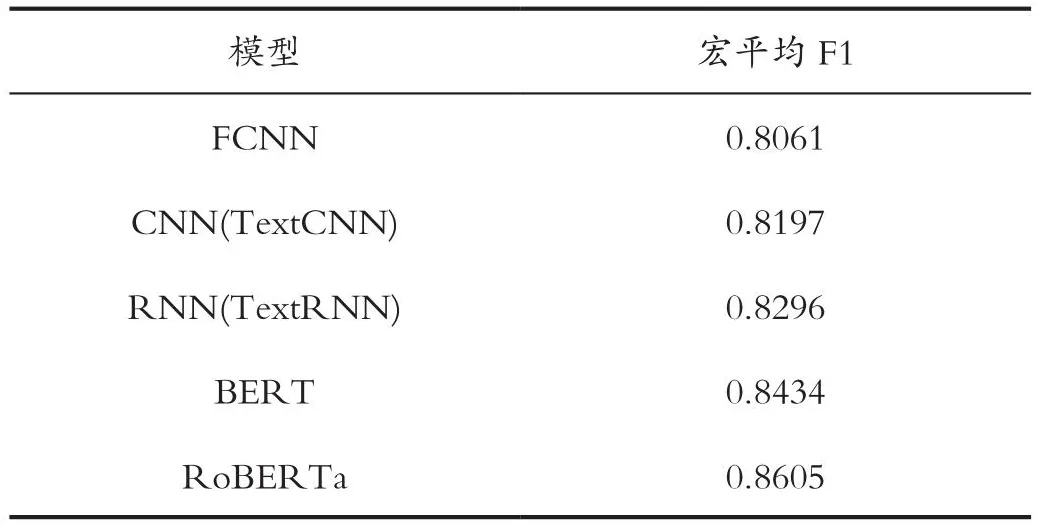
表5 多標簽文本分類實驗結果Tab.5 Multi-label text classification experiment results
其中RoBERTa為由Brightmart開源的中文RoBERTa模型,從實驗結果可以明顯看出,預訓練語言模型都具有顯著優勢。其中一個重要的原因是RoBERTa預訓練語言模型含有更多的參數。已有研究表明,模型的參數量越大,其擬合能力越強,也越容易發生過擬合。在訓練樣本較少的情況下,全連接神經網絡、卷積神經網絡與循環神經網絡采用深層結構會造成較為嚴重的過擬合,故而只能采用淺層網絡結構。本實驗中使用的RoBERTa模型的參數量遠大于其他3個模型,且RoBERTa在大量的公開語料上進行過預訓練,在下游任務微調的過程中能夠有效地防止過擬合。在體系審核數據文本分類任務中,由于訓練樣本獲取成本較高、可使用的訓練樣本較少,使用RoBERTa預訓練模型能夠獲得明顯超過全連接神經網絡、卷積神經網絡和循環神經網絡的分類效果。
在本次實驗中,RoBERTa模型的分類效果最佳,平均F1值達到0.8605,超過了未經過專業培訓人員人工分類的加權F1值(0.72),并且接近經過專業培訓人員的分類的加權F1值(0.88)。
4 總結
本文主要針對多標簽作業許可文本分類問題進行了研究,在給定許可工作內容描述時能夠對該數據所屬的類別進行預測。分別使用了全連接神經網絡、卷積神經網絡、循環神經網絡、BERT與RoBERTa進行多標簽文本分類,并且針對RoBERTa做出了進一步優化。與其他模型相比,優化后的RoBERTa模型的宏平均F1值最高。實驗結果表明本文提出的方法是可行的,在節省人力和時間上做出了巨大貢獻。目前自然語言處理還在發展階段,作業安全問題卻不容小覷,因此將深度學習技術和作業安全問題相結合是時代發展的需求,為進一步降低人力成本,減少作業現場事故的發生,我們還需要做出更進一步的研究。
引用
[1]劉沖,范偉,姜春豐,等.基于風險控制的作業許可管理系統開發與應用[J].云南化工,2018,45(2):226-229.
[2]胡月亭.正確使用作業許可有效防范高危作業事故發生[J].工業安全與環保,2014,40(1):96-98.
[3]尚鴻志,劉玉東.國內外作業許可制度建立與實施的初步探討[J].中國安全生產科學技術,2012,8(S2):140-143.
[4]于菲菲,王廷春,蔡寶華,等.煉化企業作業許可體系探析[J].中國安全生產科學技術,2012,8(07):194-199.
[5]RAKHLIN A.Convolutional Neural Networks for Sentence Classification[J].GitHub,2016.
[6]LAI S,XU L,LIU K,et al.Recurrent convolutional Neural Networks for Text Classification[C].Proceedings of the AAAI Conference on Artificial Intelligence,2015.
[7]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all You Need[J].ArXiv preprint ArXiv:1706.03762,2017.
[8]DEVLIN J,CHANG M W,LEE K,et al.Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding[J].ArXiv Preprint ArXiv:1810.04805,2018.
[9]CUI Y,CHE W,LIU T,et al.Pre-training with Whole Word Masking for Chinese Bert[J].ArXiv Preprint ArXiv:1906.08101,2019.
[10]LIU Y,OTT M,GOYAL N,et al.Roberta:A Robustly Optimized Bert Pretraining Approach[J].ArXiv Preprint ArXiv:1907.11692,2019.
[11]SUN C,QIU X,XU Y,et al.How to Fine-tune BERT for Text Classification?[C]//China National Conference on Chinese Computational Linguistics,2019:194-206.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
故事大王(2016年7期)2016-09-22 17:30:08
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
