基于航空影像的建筑信息遙感提取
2023-03-21 08:57:34姚磊
資源導刊(信息化測繪) 2023年1期
姚磊
(山東省地質測繪院,山東 濟南 250000)
1 引言
建筑是地表覆蓋相對較多的類型,是人類活動的產物。如何準確獲取地表建筑信息對于自然資源監管起著重要作用[1,2]。隨著遙感技術的發展,基于中高分辨率衛星影像的分類提取已成為應用最多的建筑信息獲取手段,該方法可較快獲取建筑信息。通過大量應用,遙感分類手段有了更深層次的研究與提升。吳巧玲等基于多源多時相遙感影像和地形數據,綜合利用非監督分類等知識建立分類決策規則,有效提取了城鎮建筑用地信息,準確度不低于90%,并且滿足城鎮建筑用地動態變化分析的精度要求[3]。曾濤等在傳統的面向對象基礎上提出了面向對象的高空間分辨率遙感影像建筑物信息提取方法。該方法首先通過影像分割將影像劃分為互不相交的影像對象,然后根據影像對象的特征(如光譜、紋理、形狀和上下文等信息)進行分類,從而快速有效地提取建筑信息[4]。馬海榮等基于高景1 號衛星影像,構建建筑物遙感特征指數,并采用面向對象分類提取農村建筑物信息,經過多輪次分割與解譯,有效提取了農村建筑物信息[5]。
基于此,本研究以無人機航空影像作為數據源,分別選用KNN 聚類、最大似然法、隨機森林三種分類算法開展基于航空影像的建筑信息遙感提取,對比分析不同算法在建筑信息提取中的適用性。
2 數據及原理
2.1 數據介紹
本研究選用的無人機平臺為深圳市大疆公司生產的精靈4pro,該飛機具有起降靈活、攜帶方便、操作簡單等優勢,可實現定點懸停、低速飛行、多樣載荷等特點。搭載于無人機平臺的鏡頭拍攝獲取的影像為4 波段多光譜影像,涵蓋了可見光近紅外光譜范圍,空間分辨率為5cm,具體成像效果如圖1 所示。

圖1 航空影像區
2.2 原理介紹
本研究主要采用KNN 均值聚類、最大似然法分類以及隨機森林分類三種方法進行基于航空影像的建筑信息遙感提取[6-8]。三種分類原理如下:
(1)聚類分析原理
k 均值聚類算法是一種迭代求解的聚類算法,首先將影像數據分為N 組,然后隨機選取N 個像元對象作為影像信息的初始聚類中心,其次計算每個像元與臨近各個初始聚類中心之間的距離,把每個像元均分配給距離它最近的中心,并計算最優距離。KNN 均值聚類方法在無樣本以及地表紋理信息明顯的狀態下,可快速獲取高精度的地物提取結果,該算法通過臨近像元分析及權重附加,對像元進行聚合與分離,可較快獲取分類成果。
(2)最大似然法原理
最大似然法相對于其他監督分類方法,在樣本集計算與優化時具有一定的優勢,是用統計的方法根據最大似然比貝葉斯判別準則法建立非線性判別函數集而進行分類的一種圖像分類方法。該方法可對各樣本類型進行相似分析與正態分布分析,將不符合樣本特征的錯誤信息剔除,最終得到具有較高精度的樣本模型,以此進行遙感分類。
(3)隨機森林原理
隨機森林(Random Forest)是指用隨機抽樣方法建立一個森林。隨機是指隨機采樣來建立模型;森林是指包含很多獨立的決策樹。隨機森林基本原理如下:
①從原始數據中以有放回的方式隨機取樣得到n個訓練數據集。②從每個訓練數據集中隨機選擇K 個特征(K 小于原始數據總共的特征)。③反復根據這K個特征建立起m 棵決策樹。 ④應用每個決策樹預測結果,且保存所有預測結果。⑤對分類模型進行投票,計算每個預測結果的得票數,選擇得票最高的模型作為最終決策。該方法可通過平均決策樹,降低過擬合風險。
3 結果分析
3.1 樣本選擇
本研究采用在影像上勾畫樣本的方式采集建筑、水體、植被、裸地、道路5 大類。各類采集的樣本數量保持1∶1左右,各地類樣本采集數量均為30個左右。對采集的樣本進行篩選,挑選出20%的樣本作為預留的精度驗證樣本,80%的樣本作為訓練樣本進行分類。樣本選擇如圖2 所示。

圖2 樣本選擇
3.2 遙感解譯
3.2.1 KNN 聚類分類
KNN 均值聚類分類效果如圖3 所示:由圖可知,各地類分布情況均已識別出來,但存在部分同物異譜現象,如水體中存在部分道路、裸地誤識別現象。但K 均值對連片分布的地類識別效果較好,如植被的識別,本研究選擇的影像有大量植被分布,通過聚類分析,較好識別出了植被的分布情況。

圖3 KNN分類成果
3.2.2 最大似然法分類
最大似然法分類效果如圖4 所示:由圖可知,最大似然法分類成果整體較KNN 均值聚類分類成果更精細,尤其是建筑信息的識別,較多的獨棟建筑也完整識別出來,水體的邊緣淺灘也能準確識別。

圖4 最大似然法分類成果
3.2.3 隨機森林分類
隨機森林分類效果如圖5 所示:由圖可知,隨機森林分類成果整體精細度優于KNN算法與最大似然法。如圖5 中裸地信息的識別,無論是連續分布的大塊裸地,還是零星分布的裸地,均較好地識別出來,并且在道路識別中也較少出現斷頭路現象。

圖5 隨機森林分類成果
3.3 建筑信息提取
3.3.1 KNN 算法提取
KNN 算法提取建筑物的效果如圖6 所示 :由圖可知,建筑物信息大致都識別出來,但仍存在誤識別現象,如將部分水體邊緣的河灘地、部分細小裸地識別成建筑等。但建筑與道路等硬化地表的區分度較好。

圖6 KNN算法建筑提取成果
3.3.2 最大似然算法提取
最大似然算法提取建筑物的效果如圖7 所示:由圖可知,最大似然法的識別成果中河灘地不存在誤識別現象,且細小裸地圖斑的誤識別也較少。但硬化地表的誤識別較多,均識別成了建筑。
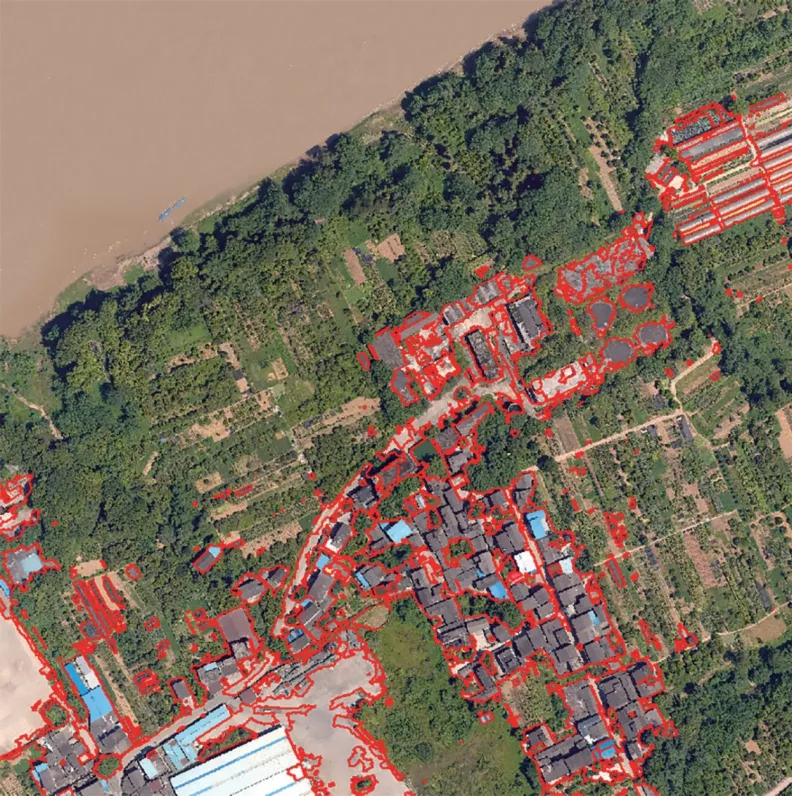
圖7 最大似然算法建筑提取成果
3.3.3 隨機森林算法提取
隨機森林算法提取建筑物的效果如圖8 所示:由圖可知,隨機森林的建筑識別效果整體優于KNN 算法與最大似然法。建筑信息完整識別出來,并且嚴格按照屋頂邊緣提取,硬化地表道路等均未參與到建筑識別中。

圖8 隨機森林算法建筑提取成果
3.4 精度驗證

表1 分類精度驗證
本研究采用預留的20%樣本對三種分類方法的分類成果進行混淆矩陣精度驗證,最終結果如表1 所示:整體來說,分類精度最高的是隨機森林算法,其次是最大似然法,分類精度最低的為KNN 聚類方法;建筑信息識別精度最高的是隨機森林算法,識別精度達到了89%。
4 結論與展望
本研究利用無人機航空影像,采用KNN 均值聚類、最大似然法、隨機森林三種算法提取建筑信息,以此研究不同分類算法對建筑提取的適用性,為后期相關工作的開展提供一種更便捷、更高效的工作途徑。通過試驗,得出以下結論:
(1)大疆精靈4pro 無人機獲取的多光譜影像具有較高的成像質量,地物信息表達清晰。
(2)三種算法均較好地識別出了各地物的空間分布情況,其中KNN 算法識別植被效果較好,最大似然法識別淺灘及獨棟建筑效果較好,隨機森林在分類成果上更加精細,避免了細小圖斑的混淆。
(3)通過對比三種分類算法對建筑的識別精度得出,建筑識別最好的算法為隨機森林,提取的圖斑嚴格按照建筑邊緣走向,識別精度達到了89%。
本研究雖然取得了較好成果,但仍存在一定的問題,研究選用的試驗區植被分布較多、硬化地表與廠房占比較大,建筑屋頂多為灰色,代表性較差。在后期研究中將著重豐富建筑物的樣本信息,以此提升識別精度。
猜你喜歡
北方建筑(2021年6期)2021-12-31 03:03:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
文苑(2020年10期)2020-11-07 03:15:36
現代裝飾(2020年6期)2020-06-22 08:43:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
少兒科學周刊·兒童版(2015年6期)2015-11-24 03:49:38
中外會展(2014年4期)2014-11-27 07:46:46
