基于YOLOv5的咖啡瑕疵豆檢測方法
2023-03-21 13:08:42張成堯張艷誠張宇乾趙玉清
食品與機械 2023年2期
張成堯 張艷誠,2 張宇乾 趙玉清,2
(1. 云南農業大學機電工程學院,云南 昆明 650201;2. 云南省作物生產與智慧農業重點實驗室,云南 昆明 650201)
咖啡瑕疵豆嚴重影響烘焙過程中咖啡的風味與品質,直接影響咖啡的出售價格。傳統的咖啡瑕疵豆檢測方法是通過人工目測篩選,勞動強度大、效率低、主觀性大、評判標準不統一,難以保證咖啡品質[1-5]。隨著圖像技術的發展,將計算機視覺應用于咖啡瑕疵豆的檢測成為了可能[6-7]。早期的計算機視覺研究大多基于機器學習方法,主要采用人工提取形狀、顏色、紋理等特征,通過K近鄰分類方法、支持向量機(SVM)和BP神經網絡進行特征分類,實現咖啡瑕疵豆的檢測[8]。Akbar等[9]利用隨機森林和KNN方法,結合顏色和紋理視覺特征實現了阿拉比卡咖啡的品質分級。Pinto等[10]利用CNN模型對咖啡瑕疵豆進行分類,平均識別正確率為80%。目前深度學習已被應用于農業生產的各個方面[11-16]。宋懷波等[17]通過改進YOLOv5s中的卷積塊并引入SE注意力機制模塊實現了對重度黏連的小麥籽粒的檢測。奉志強等[18]通過設計改進YOLOv5的特征提取模塊并在主干網絡中引入Transformer,提高了復雜背景下小目標的識別能力。胡根生等[19]基于改進YOLOv5網絡實現了復雜背景圖像中茶尺蠖的識別,識別準確率為92.89%。
綜上,改進的YOLOv5算法在小目標檢測、復雜背景等方面具有良好的表現,因此研究擬針對傳統計算機視覺中,咖啡瑕疵豆檢測網絡模型深度不夠導致精度不高,特征提取耗時耗力,以及咖啡瑕疵豆目標小、檢測環境復雜等問題,結合深度學習在模型深度、小目標檢測與復雜背景識別精度高等特點,提出一種以YOLOv5s為基線網絡并嵌入CBAM注意力機制模塊與Hardswish激活函數的咖啡瑕疵豆檢測算法,旨在提高咖啡瑕疵豆識別準確率,以及在保證咖啡瑕疵豆檢測準確率的基礎上提高模型的檢測速度,使模型更加輕量化,為后續基于深度學習的咖啡豆瑕疵檢測算法部署到嵌入式設備提供依據。
1 材料與方法
1.1 試驗數據制作
選用云南阿拉比卡小粒種咖啡生豆作為研究對象,使用佳能EOS 200DⅡ單反相機拍攝,拍攝時相機鏡頭距離咖啡豆60 cm,分別拍攝破損豆、霉菌豆、帶殼豆(見圖1)640像素×640像素尺寸各200張,采集的圖片包含了單粒和多粒并記錄各種豆子數量保證3種瑕疵豆總的數量相同,并對采集的數據集進行圖像增強,擴充至2 400張圖片,按照9∶1將各瑕疵豆隨機分成訓練集與驗證集,同時檢驗訓練集與驗證集的瑕疵豆數量的比例是否接近9∶1,最后使用LabelLmg軟件標注目標類別與目標位置,生成txt文件格式。

圖1 缺陷豆種類Figure 1 Defective soybean species
1.2 數據增強
利用OpenCV相關庫的圖像處理操作對原始圖像數據集進行處理,以提高訓練模型的泛化能力。該過程通過圖像鏡像翻轉、圖像噪聲增大、圖像模糊等(圖2),以達到提高網絡的檢測性能和魯棒性。
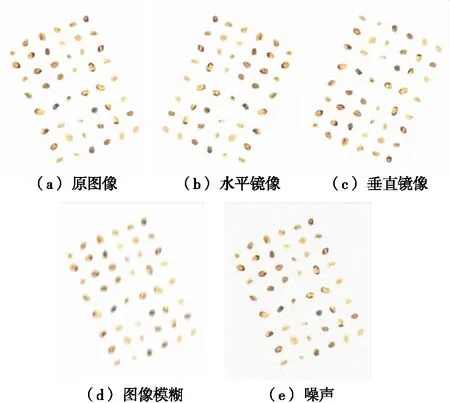
圖2 圖像增強Figure 2 Image enhancement
1.3 YOLOv5網絡結構
YOLO系列[20-21]的檢測網絡是典型的one-stage網絡,研究使用YOLOv5s檢測模型。YOLOv5的主要網絡結構包括輸入端(input)、Backbone、Neck和輸出端。
主干網絡Backbone主要由Focus結構與CSP結構組成。Focus模塊是將輸入特征圖像進行切片操作,使640×640×3的圖像先變為320×320×12的特征圖,再經過一次卷積操作變為320×320×32的特征圖,該操作通過增加一點計算量來保證圖像特征信息不會丟失,將 W、H的信息集中到通道上,使得特征提取得更加充分。CBL模塊由Conv+BatchNormal+LeakyRelu組成。在YOLOV5中Backbone和Neck分別使用兩種不同的CSP1_X和CSP2_X結構,在Backbone中使用帶有殘差結構CSP1_X源于Backbone網絡結構較深,殘差結構會加強梯度值在反向傳播過程中,有效防止網絡結構加深時所引起的梯度消失,得到更加豐富特征信息。通過設置不同的CSP模塊中的寬度與深度,可以得到YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x不同的型號模型。SPP結構在Backbone的尾部,主要目的是增大感受野,增強網絡的線性表達能力。
Neck網絡是一系列混合圖像特征的聚合層,采用FPN+PAN的結構。FPN 是通過上采樣的方法傳遞和融合信息,從而獲得預測的特征圖。由于該網絡的特征提取采用自上而下的特征金字塔網絡,因此能夠提高低層特征的傳輸,增強對不同尺度目標的檢測,可以精確地識別不同尺寸和比例的目標對象。Neck中CSP2_X主干網絡中的兩個分支的輸出進行拼接,加強網絡特征融合能力。
輸出端采用CIOU函數作為邊界框的損失函數,在目標檢測后處理過程中,使用NMS、非極大值抑制來對多目標框進行篩選,增強多目標和遮擋目標的檢測能力。具體網絡結構如圖3所示。
1.4 網絡結構優化
1.4.1 嵌入CBAM注意力機制 注意力機制通過模仿人腦處理視覺信息的方式,模仿人類迅速觀察圖像的全局信息,找出需要重點關注的候選區域,并將主要注意力放在此區域,從而提取更多的細節信息。因此,在深度學習,尤其是在深層次高性能網絡中得到了廣泛應用。
為了獲取咖啡瑕疵豆更加豐富的特征信息,減少背景與復雜環境的干擾,引入CBAM(Convolutional Blaock Attention Module)模塊[22]。CBAM模塊是由空間與通道的注意力機制模塊組成,其中通道注意力模塊與空間注意力模塊可以并行排列和順序排列,此處采取順序排列。
輸入的特征圖為C×H×W∈F,其中C為特征圖的通道數。F進入通道注意力模塊,通過平均池化和最大池化得到每個通道的信息,并將得到的參數通過多層感知器進行疊加,再經過sigmoid函數激活,從而得到通道注意力特征:
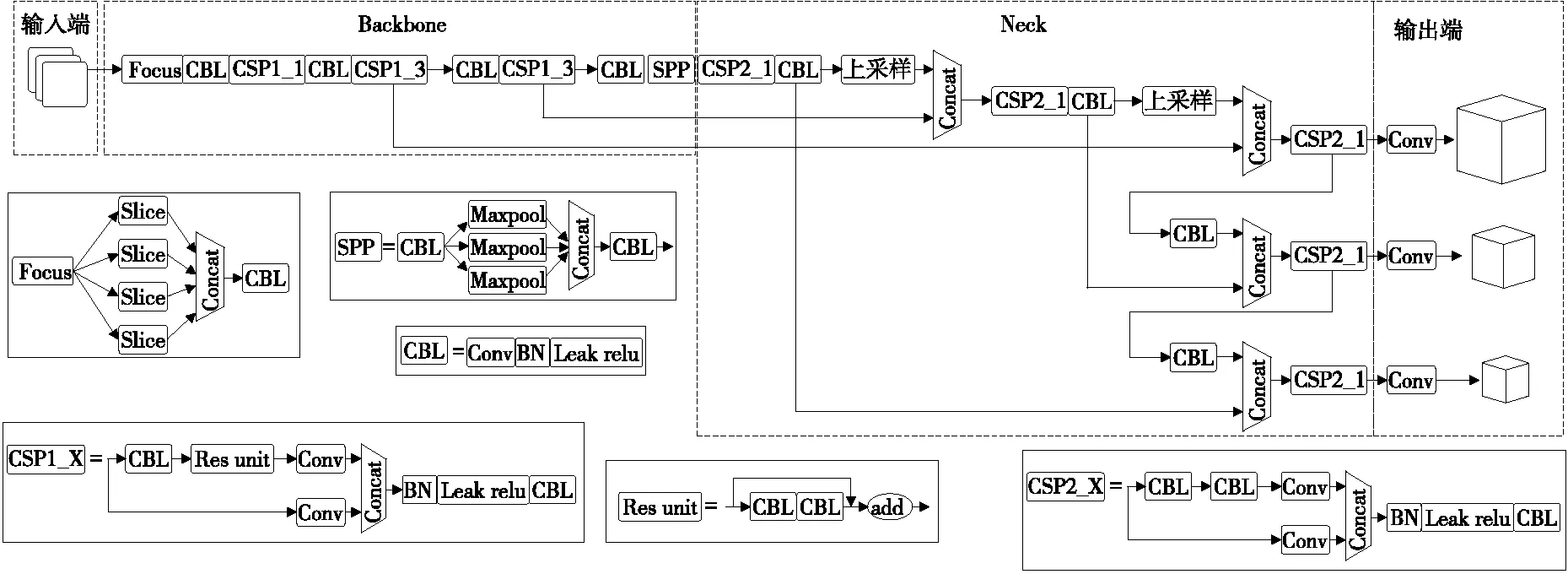
圖3 YOLOv5網絡結構Figure 3 YOLOv5 network structure
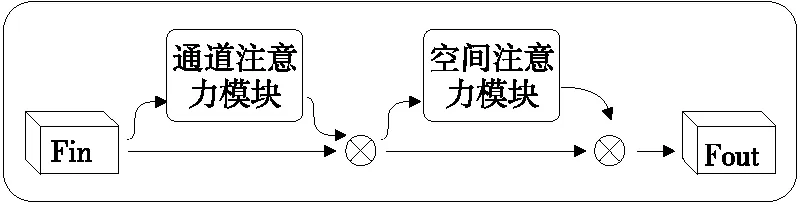
圖4 CBAM模塊結構Figure 4 CBAM module structure
(1)
式中:
Cm——通道注意力機制;
σ——sigmoid函數;
MLP——多層感知器;
AvgPool、MaxPool——對模塊特征圖空間信息進行平均池化和最大池化;
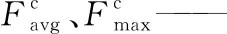
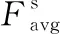
(2)
式中:
Sm——空間注意力機制。
1.4.2 激活函數 引入非線性函數作為激活函數,有利于加大深層神經網絡表達能力,實現權值模型的輕量化,使模型具備捕獲復雜的視覺布局能力,從而提高模型的綜合性能,使咖啡瑕疵豆識別更加精確。選用Hardswish函數[23]作為激活函數,選擇Hardswish將YOLOv5s特征提取網絡骨干部分(Convolution、Batch normal、LeakReLU、CBL)模塊中的激活函數進行替換:
(3)
1.4.3 損失函數 YOLOv5s的損失函數由3個部分組成,分別是定位損失、置信度損失和類別損失,其中置信度損失和類別損失采用二元交叉熵計算,在YOLOv5s原始網絡中采用GIOU作為定位損失計算式。
(4)
(5)
式中:
C——兩個框中的最小外接矩形;
B∪Bgt——預測框與真實框的并集。
雖然GIOU解決了IOU中兩個框無交集時,導致梯度消失的情況,但并未改善預測框與真實框相互包含時損失函數退化成IOU,從而不能清楚描述預測框的回歸問題,無法預測評估預測框和真實框的相對位置,影響定位精度的準確性,導致定位框失去收斂方向。選擇CIOU[24]作為損失函數,其計算式為:
(6)
(7)
(8)
式中:
b、bgt——預測框與真實框的中心點;
ρ(·)——歐式距離;
C——兩個框的最小外接矩的對角線距離;
ν——真實邊框與預測邊框的寬高比損失;
α——寬高比損失系數;
αν——CIOU寬高比懲罰項(防止當真實框與預測框中心點重合時CIOU損失退化成IOU,進而能在中心點重合時CIOU仍有寬高比損失懲罰,能進一步調整寬高比例)。
CIOU綜合考慮了真實框與預測框之間的重疊率損失、中心點偏移損失和自身寬高比損失3種度量優點,使得在模型學習與訓練中具有更好、更穩定的收斂精度與收斂效果。
2 結果與分析
2.1 模型及評價指標
為了評價模型性能,采用準確率(P)、召回率(R)、平均準確率(AP)、瑕疵豆平均準確率均值(mAP)以及檢測速度FPS作為評價指標。
(9)
(10)
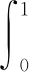
(11)
(12)
(13)
式中:
TP——判斷為正類的正類;
FN——判斷為負類的正類;
FP——判斷為正類的負類。
2.2 訓練結果
模型訓練軟件環境為Windows 10操作系統,使用pytorch深度學習框架,CUDA11.1。硬件環境為GeForce RTX2060顯卡,AMD的R7-4800H處理器,16 GB運行內存。
模型訓練以YOLOv5s初始參數設置為基礎,迭代周期為200;Batchsize為16;動量因子為0.937;權重衰減系數0.000 5,采用余弦退火策略。
由圖5可知,經過200輪次的訓練,損失函數的最小值出現在155輪為0.03,召回率最大值出現在158輪為0.991,mAP(0.5)的最大值在154輪為98.8%,準確率與mAP(0.5∶0.95)的最大值均出現在196輪,分別為99.5% 和71.9%,選擇196輪作為最終的測試權重文件。
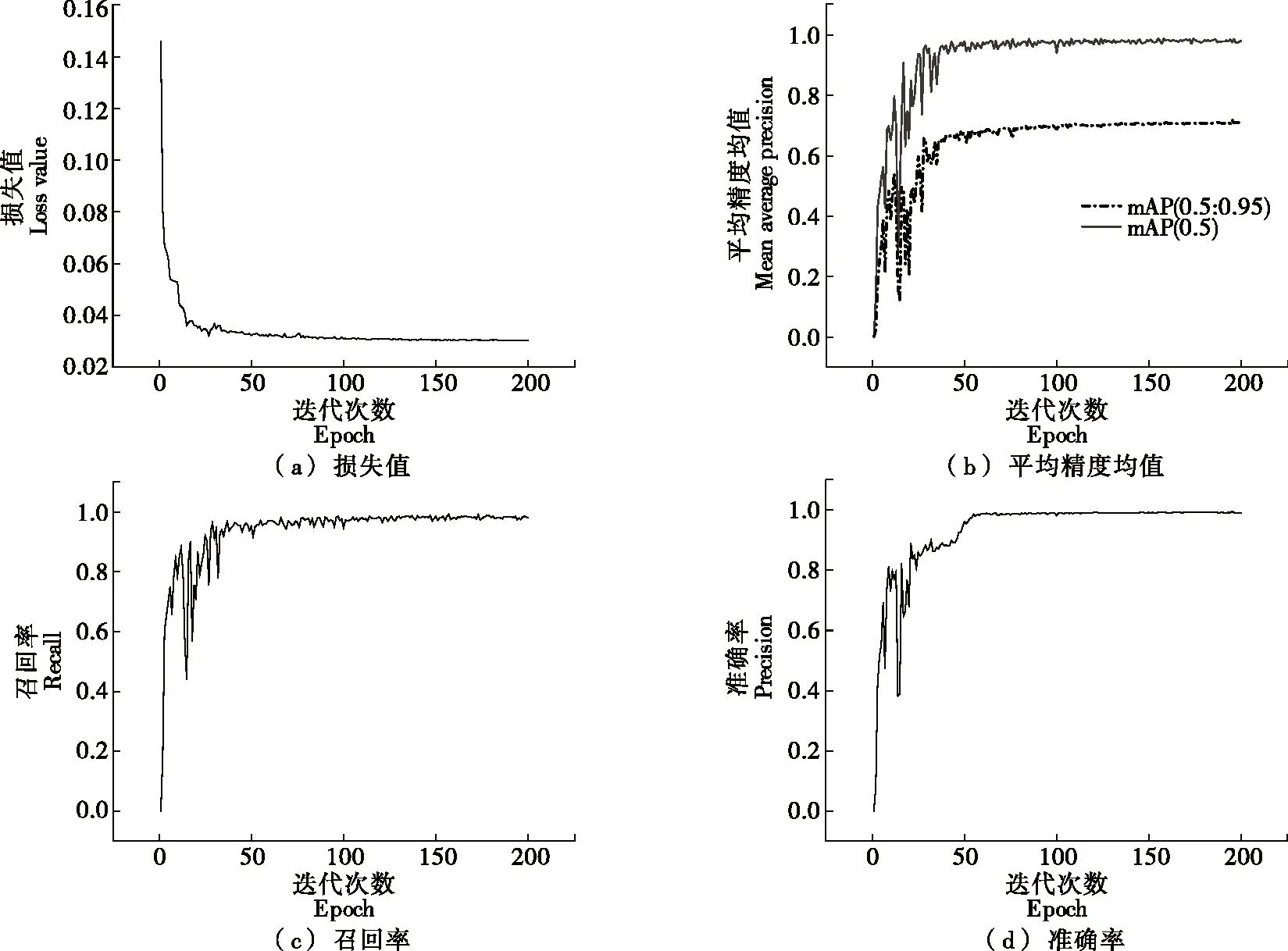
圖5 各項指標變化曲線Figure 5 Change curves of various indicators
2.3 不同注意力機制分析
在主干網絡Backbone中分別使用現有的注意力機制CBAM、SE、CA、ECA等模塊[25-27]。分別加在表1序號2、4、6、9的4個BottleneckCSP模塊后記作A;單獨加在序號9的BottleneckCSP模塊后記作B;單獨增加一層加在序號8與序號9之間記作C,結果如圖6所示。由圖6 可知,CBAM加在B處的效果最好,相比基線網絡,mAP (0.5∶0.95)提高了2.9%。
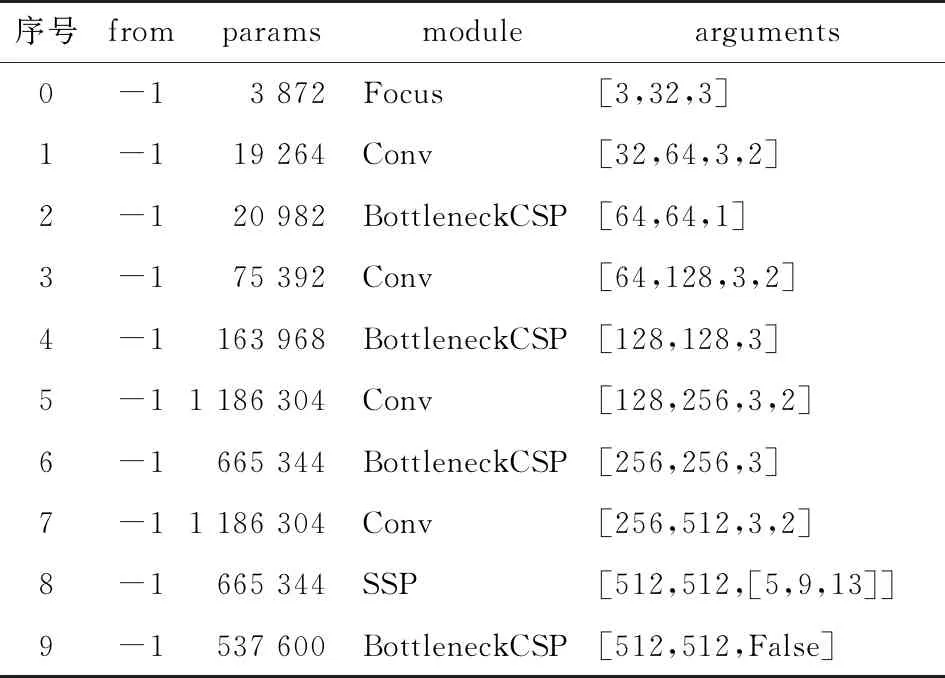
表1 YOLOv5s的Backbone部分網絡結構圖
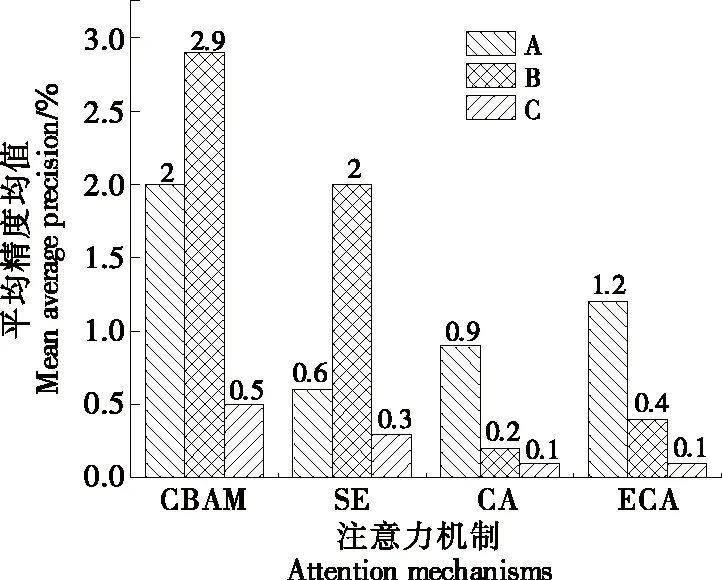
圖6 不同注意力機制比較Figure 6 Comparison of different attention mechanisms
2.4 不同激活函數對比
通常,在線性捕獲卷積層中的空間相關性后,激活層立即充當標量非線性變換。目前已提出了許多有效的激活函數,如SILU、Hardswish和FReLU[28]。以YOLOv5s網絡為基線,模型默認的激活函數為LeakReLU,以模型在mAP(0.5∶0.95)為評價指標,選擇一款在該數據集上模型的泛化性能更好的激活函數。由圖7可知,Hardswish更有效,在咖啡瑕疵豆的檢測任務上表現更好。
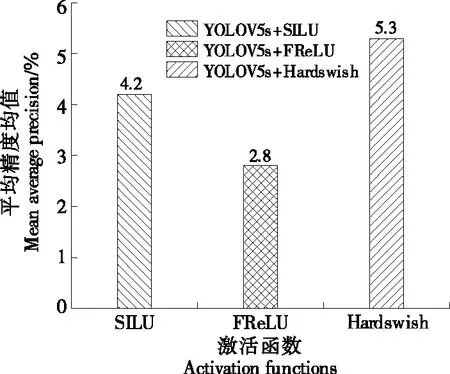
圖7 不同激活函數比較Figure 7 Comparison of different activation functions
2.5 檢測網絡對咖啡瑕疵豆的識別
由表2可知,YOLO系列算法在召回率、準確率、mAP上均大于Faster-RCNN和SSD;試驗算法的mAP比Faster-RCNN、SSD、YOLOv3、YOLOv4、YOLOv5分別高20.4%,13.2%,7.3%,4.1%,3.1%。在模型檢測速度方面,試驗算法識別速率為64幅/s,相比上述模型差值為+48,+9,+18,+24,-2。在模型大小方面,試驗算法、SSD、YOLOv5s明顯優于Fast-R-RCNN、YOLOv3和YOLOv4。綜上,改進后的算法在識別準確率與召回率上明顯提升,可大幅提高咖啡豆的品質檢測。在工程應用中,將檢測速率與模型可移植性作為評價指標,輕量級模型在模型的可移植性方面更好,鑒于試驗改進算法在檢測時間與模型大小的優勢,改進后的YOLOv5算法更加適用咖啡豆檢測系統的部署應用。
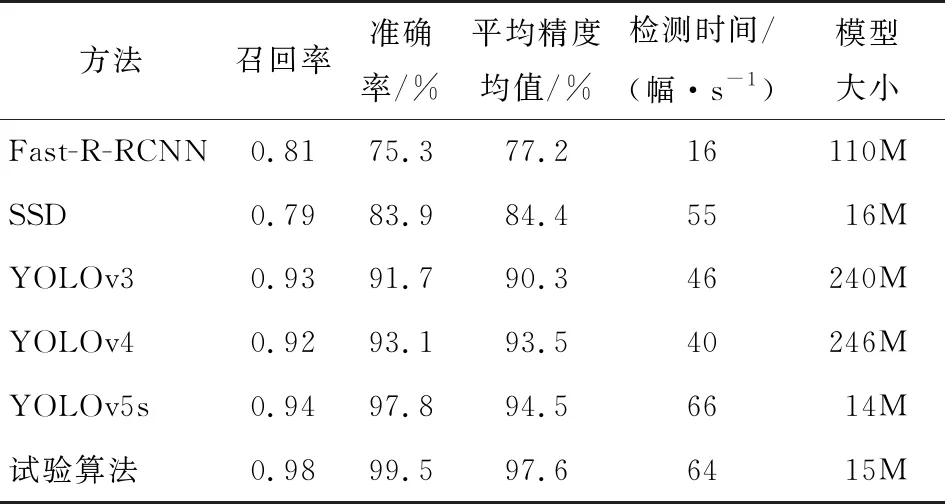
表2 算法對咖啡瑕疵豆的識別結果
2.6 咖啡瑕疵豆的識別效果
2.6.1 單粒識別效果 測試了3種瑕疵豆各30張,其中破損豆與霉菌豆各出現一個錯誤識別,整體的檢測置信度均在90%以上,識別準確率為98%(見圖8)。

圖8 單粒識別效果Figure 8 Effects of single particle recognition effect
2.6.2 多粒識別效果 由圖9可知,試驗算法在粒數為8的圖像中全部識別正確,整體置信度在92%以上;在粒數為30的圖像中,有一個將破損豆識別為霉菌豆,識別正確率為96.7%,其中霉菌豆目標檢測置信度最小為82%,最大為88%,均值為84.7%,破損豆目標檢測置信度最小為74%,最大為87%,均值為81.7%,帶殼豆目標檢測置信度最小為84%,最大為90%,平均值為87.6%;單幅60粒的圖像中識別錯誤有7個豆,分別是2個破損豆、2個帶殼豆和3個霉菌豆,其中有4個識別錯誤豆是檢測框出現類別重復。破損豆、帶殼豆和霉菌豆正確率分別為90%,90%,85%。破損豆目標檢測置信度最小值、最大值、平均值分別為76%,88%,83%;帶殼豆目標檢測置信度最小值、最大值、平均值分別為83%,90%,87.1%;霉菌豆目標檢測置信度最小值、最大值、平均值分別為74%,87%,83.7%。綜上,試驗算法的總體識別正確率在85%以上,目標檢測置信度在74%以上。隨著粒數的上升,模型精度會有所下滑,總體來說模型在多粒識別方面均有不錯的效果。

圖9 多粒識別效果Figure 9 Effects of multiple grains recognition
2.6.3 黏連識別效果 采用單幅30粒的圖片分別設置3種黏連程度,由圖10可知,3種黏連程度的準確率分別為100%,100%,86%,其中重度黏連中出現2個破損豆識別錯誤,2個帶殼豆識別錯誤。輕度、中度、重度黏連的目標檢測置信度均值分別為88.1%,81.5%,85.3%。綜上,模型精度受黏連程度的影響,但模型總體識別效果較好。

圖10 黏連識別效果Figure 10 Effects of adhesion recognition
2.6.4 不同光照背景 測試了3種光照條件下的單幅9粒圖片,由圖11可知,在過度曝光情況下識別準確率為100%,目標檢測置信度均值為82.7%,在弱光環境下識別準確率為100%,目標檢測置信度均值為84.4%,在昏暗環境下準確率為66.7%,其中帶殼豆與霉菌豆識別準確率為100%,由于昏暗環境導致破損豆與霉菌豆顯示無差別,導致模型將破損豆全部識別為霉菌豆,目標檢測置信度均值為83.6%。綜上,模型在相對穩定的環境下識別效果較好,當環境影響較大時,在帶殼豆與霉菌豆檢測方面也具有較高的準確率。

圖11 不同光照識別效果Figure 11 Effects of recognition in different illumination
3 結論
針對瑕疵豆引起咖啡生豆的品質問題,提出了一種改進的YOLOv5s咖啡瑕疵豆的檢測算法。結果表明,試驗算法比YOLOv5s基線網絡模型的準確率、平均精度均值和召回率分別提高了1.7%,3.1%和4%,同時也優于SSD、Fast-R-RCNN、YOLOv3、YOLOv4等模型;模型對單粒識別效果最好,識別準確率為99%,在多粒與黏連環境下識別效果下降,但整體識別準確率>85%;過度曝光與弱光環境下模型識別正常,但在昏暗條件下,模型易將破損豆識別為霉菌豆,導致破損豆識別準確率下降。針對破損豆的識別率不高,如何利用在計算能力有限的嵌入式設備上,實現高性能的實時咖啡瑕疵豆檢測任務等問題,后續可以從數據集制作,在主干特征提取網絡中增加小目標檢測層,進一步提高破損豆在昏暗環境的檢測效果,以及對改進后的算法進行輕量化研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
