基于深度學習的沈陽市春節期間PM2.5濃度預測研究
2023-03-25 06:31:10劉思洋曹馨元劉照李曉妍
當代化工研究 2023年4期
*劉思洋 曹馨元* 劉照 李曉妍
(1.沈陽航空航天大學能源與環境學院 遼寧 110136 2.中國科學院東北地理與農業生態研究所 吉林 130102)
春節是我國歷史最為悠久的傳統節日,春節期間燃放煙花爆竹已然成為了人民的一項重要的娛樂性活動。但是,在短時間內燃放大量煙花爆竹,不但會導致意外傷亡的事故增加,而且會釋放出大量污染物。目前,對于煙花爆竹燃放的研究大多利用地面監測數據及采樣數據分析污染物成分及其危害。趙素平等[1]以蘭州市為例研究了春節期間顆粒物濃度及其體積濃度譜分布特征,結果表明煙花燃放排放顆粒物體積中位徑最大比例在0.93,5.50μm左右。金軍等[2]研究發現,煙花爆竹的燃放會導致污染物濃度劇烈增加,監測點PM10最高濃度超過800μg/m3,不僅導致能見度下降,還會造成大氣消光作用。煙花排放顆粒物水溶性離子、重金屬濃度也會在短期內急劇上升,K+質量濃度最高達到115.6μg/m3,Ba質量濃度最高達到5.168μg/m[3]。洪也等[4]進一步對煙花爆竹燃放排放細顆粒元素進行了分析,結果指出Ba、Sr、K等污染元素濃度在沈陽城區中有明顯上升,特別富集在PM1中。大量的污染物不但會導致空氣質量的惡化,而且會對人體的健康造成危害[5]。出于環保以及安全的角度考慮,沈陽市人民政府發布了關于春節期間禁止銷售和燃放煙花爆竹的通告,因此2020年春節成為沈陽市三環以內城區準許銷售和燃放煙花爆竹的最后一年[6]。因此,準確預測煙花爆竹排放顆粒物濃度對于控制節日期間短期急增大氣污染至關重要。
目前,顆粒物濃度預測的方法主要包括大氣數值模式預測、統計模型預測以及機器學習模型預測[7]。其中大氣數值模式預測是通過對PM2.5的擴散方程進行數值求解,統計模型預測包括多元線性回歸模型,灰色預測模型,以及時間序列常用的ARIMA模型等。近年來,國內外學者通過構建機器學習模型,提高了預測PM2.5濃度的預測精度。梁錫冠等[8]通過比較幾種常見的基于樹的集成學習模型預測PM2.5濃度,得到的結論是LightGBM模型預測濃度更優,其次是XGBoost模型,RF模型最差。Kumar等[9]通過改進的AdaBoost算法預測了德爾黑PM2.5濃度,與XGBoost模型相比預測效果更佳。
本研究基于2016年—2022年沈陽市春節期間正月初一前后各15d的逐小時空氣質量監測歷史數據集,結合相應的氣象數據以及時間編碼數據對沈陽市春節期間PM2.5濃度進行預測,并且通過4種錯誤度量標準得出最優模型,為沈陽市煙花爆竹燃放政策的完善以及春節期間空氣污染控制提供預報預警作用以及參考,并為沈陽市環境管理部門科學決策提供數據支持。
1.實驗部分
(1)數據來源
①觀測數據
本研究的觀測數據主要來自全國空氣質量歷史數據庫網站(http://beijingair.sinaapp.com/#messy),該網站的數據主要來自中國環境監測總站的全國城市空氣質量實時發布的數據。本文所采用的監測數據為2016年—2022年正月初一前后各15d的沈陽市包括皇姑區、大東區、沈河區、和平區、于洪區、渾南區、鐵西區、沈北新區在內的主城區的9個站點的空氣質量指數(AQI)和各常規污染物(PM2.5、PM10、CO、NO2、SO2、O3)質量濃度的逐時監測數據,這些站點包括主要區域、交通干道等類型,所有監測站點均經過GPS定位[10]。
②氣象數據
本研究主要通過中國氣象數據網(http://data.cma.cn/site/index.html)和rp5.ru天氣(https://rp5.ru.com)獲得沈陽市2016年—2022年溫度(℃),表面大氣壓(mmHg)、平均海平面大氣壓(mmHg)、相對濕度(%)、平均風速(m/s)、露點溫度(℃)[11]。
(2)研究方法
為了更加合理、準確地評價模型的性能,本研究采用均方誤差MSE、平均絕對誤差MAE、平均絕對百分比誤差MAPE、決定系數R2四種錯誤度量標準對模型進行評估[12-13]。其中MSE作為回歸問題最常用的指標之一,其優點可以非常直觀地反映預測值與真值之間的偏差,MAE則能更好的地反映出預測值誤差的實際狀況,MAPE以百分比表示,可用于比較不同比例的預測,R2度量了因變量中可以被自變量解釋的比重,R2越接近1,模型的擬合效果越好。
2.結果與討論
(1)特征工程處理
PM2.5濃度與時間特征存在一定的相關性,在創建機器學習模型訓練的過程中,為了使模型輸出的結果能夠更準確、更靈活,時間特征也應該被輸入到模型中[8]。除進行時間周期性編碼外,時間特征還可被當作為離散值進行處理,本研究采用OneHotEncoder對時間特征進行編碼并代入模型[14-15]。進行時間變量編碼后的結果與PM2.5濃度的相關系數如表1所示。實驗表明,沈陽市9個站點年份特征編碼對于PM2.5濃度有很強的一致性,其中r-2020均得到了大幅提高,說明沈陽市春節期間的濃度在2020年劇烈增加,而2021年—2022年Pearson相關系數均與PM2.5濃度呈現一定的負相關性。
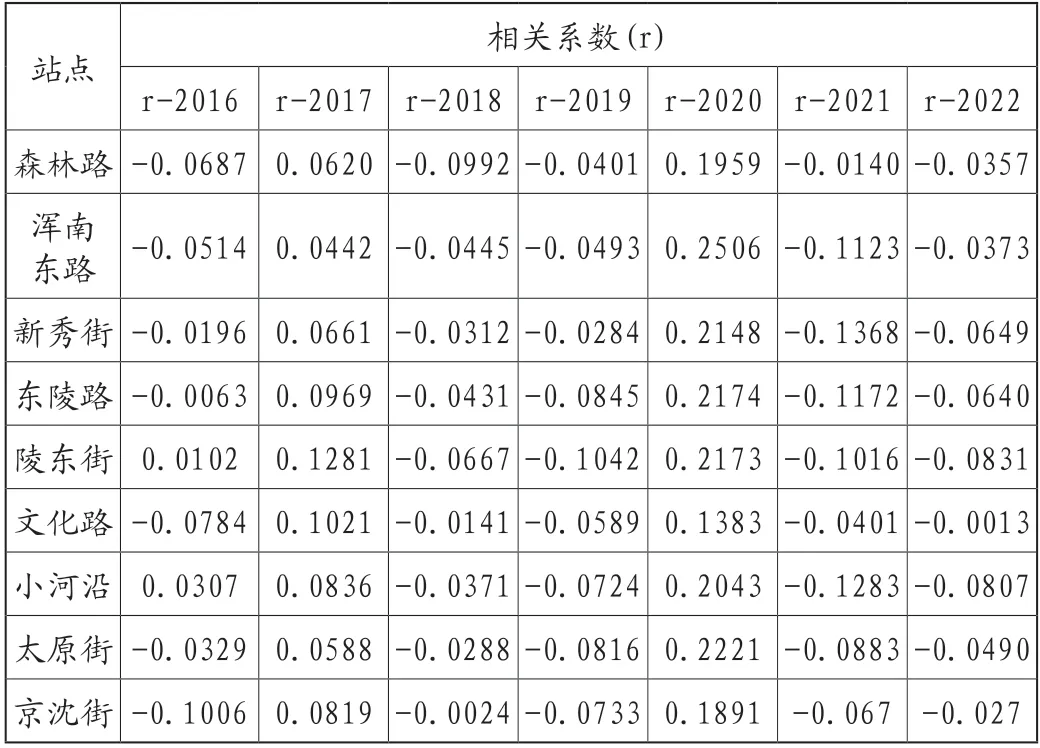
表1 年份時間編碼與PM2.5濃度的相關系數
(2)預測結果分析
對于數據量較大的數據集,為了防止過擬合,通常要進行K-fold交叉驗證,但是由于傳統的K-fold交叉驗證是隨機打亂數據集作為訓練集的部分,對于時間序列類與時間變量存在極大的相關性數據,會導致時間性關系喪失,從而導致模型的錯誤。因此,本研究利用了sklearn庫中的TimeSeriesSplit類,其中n_splits參數設置為5,意為創建5個不同的時間窗口,其中時間窗口中的數據集為連續的時間序列數據,tiest_size參數取值為300,意為測試集的樣本數為300個。同時,為了防止不同的時間窗口中訓練集與測試集數據產生交叉,本研究將gap參數設置為48,意為訓練集與測試集的數據需要間隔48h。這樣K-fold的交叉驗證能夠直觀地判斷出模型在不同的數據集上的過擬合情況,以便后續的調參過程處理。
本研究以陵東街站點為例,對六種模型的預測值與真值進行分析,其中4種錯誤度量標準為進行交叉驗證后取得平均值的結果。
從圖1中真實值與預測值得結果可以看出,LSTM、GRU模型擬合效果最好,當PM2.5濃度為20~70μg/m3時,各個模型的預測精度都很高,但當PM2.5濃度大于70μg/m3時4種集成學習模型的預測精度開始下降,而深度學習模型的預測精度仍很高,當PM2.5濃度持續增加到大于125μg/m3后,深度學習模型的預測精度開始緩慢下降。由表2可知,LSTM、GRU深度學習模型的4種錯誤度量標準均小于4種集成學習模型。在4種集成學習模型中LGBM的MSE最小,預測精度最高,RF、XGBOOST其次、GBDT效果相對最差。總體上來講,六種模型的R2均大于0.9,MAPE均小于20%,MAE均小于0.7,所有模型的精度均為很高水平。從整體上看,深度學習模型比樹集成學習模型模擬效果好很多,MSE平均降低了大約44%,其余錯誤度量標準也均小于樹集成學習模型。GRU、LSTM與主流的機器學習模型預測濃度以及相較于傳統的空氣質量模型預測PM2.5濃度也有明顯的優勢,并且預測速度更快。
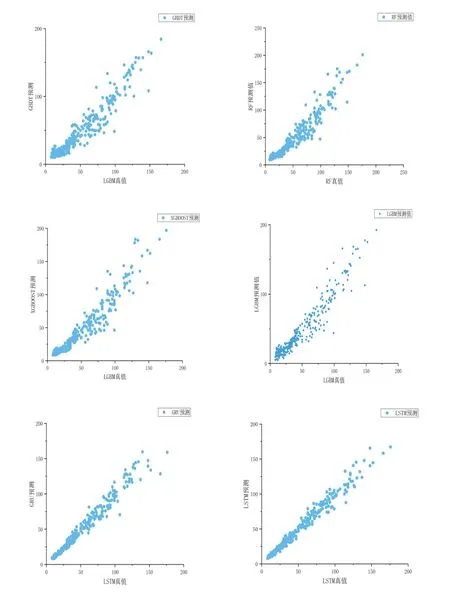
圖1 種模型預測值與真實值得對比
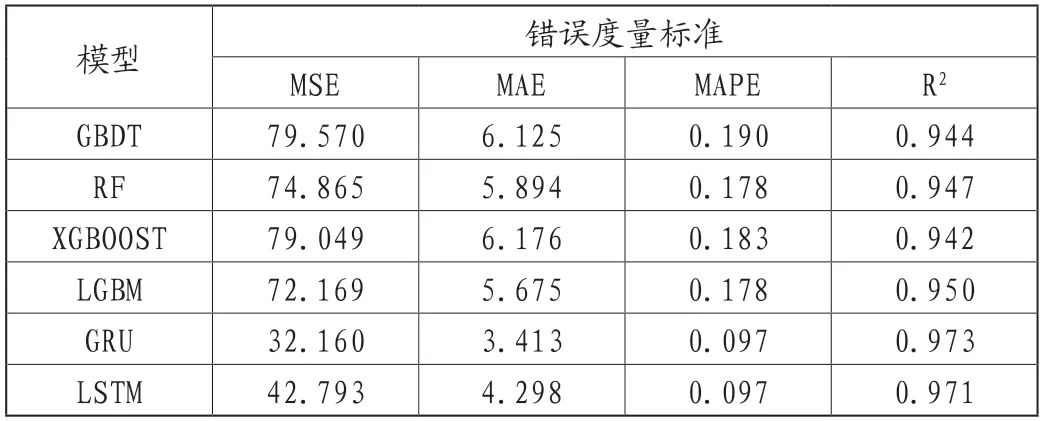
表2 陵東街站點6種模型的錯誤度量標準
3.結論
(1)通過對比6種機器學習模型的預測情況,得到的結論是GRU模型預測PM2.5濃度的效果最好,其次為LSTM模型,GBDT模型預測PM2.5濃度的效果最差。
(2)GRU模型在沈陽市PM2.5濃度預測中其準確率要高于其他模型,其MSE、MAE、MAPE以及R2分別為32.160、3.413、0.097、0.973。
(3)建立的GRU模型以及LSTM模型其MSE、MAE、MAPE均小于樹集成學習模型,R2均大于樹集成學習模型LGBM、XGBOOST、RF以及GBDT,表明在預測PM2.5濃度的實驗中,深度學習模型要優于常見的樹集成學習模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
環境保護與循環經濟(2017年2期)2017-09-26 11:52:22
環境科技(2016年1期)2016-11-08 12:17:48
光學精密工程(2016年6期)2016-11-07 09:07:19
化工進展(2015年3期)2015-11-11 09:18:15
核科學與工程(2015年4期)2015-09-26 11:59:03
浙江大學學報(工學版)(2015年1期)2015-03-01 01:17:28
環境與可持續發展(2013年6期)2013-03-11 16:21:48
