一種基于集群負載均衡的Kubernetes資源調度算法
2023-04-06 15:55:00黃志成
電腦知識與技術 2023年5期
黃志成

關鍵詞: Kubernetes; 資源調度; 負載均衡; 容器技術; 資源監控
當前Kubernetes調度策略是一個比較熱門的研究方向,我們的應用向Kubernetes請求資源之后,Kuber?netes會進行容器調度,現有的Kubernetes調度器是根據用戶請求的資源去分配節點的,沒有考慮到用戶可能申請了很多資源但是實際使用資源很少的情況,這時Kubernetes不會去做資源的重新分配,會造成很大的資源浪費[1]。另外調度器在選擇節點的時候是根據用戶請求的CPU和內存數量去分配節點的,沒有考慮節點自身的負載情況,將Pod調度到本身已經高負載的節點上會造成集群中某些節點資源利用率很高,出現性能不穩定的情況[2]。針對Kubernetes默認調度器的不足,對其進行優化是本文的研究方向。
1 相關工作
國內外學者對于資源調度也有非常多的研究,Menouer等人[3]提出了一種新的Kubernetes容器調度策略,簡稱為KCSS。這個策略考慮了六個關鍵因素,分別是每個節點CPU利用率、每個節點的內存利用率、每個節點的磁盤利用率、每個節點的功耗、每個節點中運行的容器數以及用戶傳輸鏡像到容器的時間。然后通過TOPSIS 算法選擇排名最高的節點來運行Pod。Mao等人[4]提出了一種推測性容器調度器,通過將速度緩慢節點上的資源遷移到其它節點上來提升系統性能,主要包含以下三個步驟,確定速度緩慢的節點、選擇合適的新節點、遷移重新平衡節點。浙江大學的楊鵬飛[5]基于ARIMA和神經網絡兩種模型組合的方案,提出一種資源動態調度算法,每一輪調度都由一個動態資源管理器去計算所有的節點實例,然后根據用戶的資源請求數量去分配一個節點。該方法沒有考慮集群節點本身的負載情況,每一輪調度都要遍歷所有節點去計算資源情況,時間復雜度過大。華南理工大學的魏飴[6]提出一種基于節點CPU和磁盤I/O 均衡的動態調度算法,該方法通過監控節點的CPU和磁盤IO使用情況為節點進行打分,能夠解決默認調度器只考慮用戶請求的CPU和資源情況。但是該方法沒有考慮內存影響的因素,并且使用Sched?uler Extender實現的調度方法會有性能問題。電子科技大學的唐瑞[7]提出了一種基于Pod優先級的搶占策略,在集群資源不足的情況下,選擇將一部分低優先級的Pod資源回收。但是該特性在v1.14版本的Ku?bernetes中就已經支持了。
2 基于集群負載均衡的Kubernetes資源調度算法
2.1 資源監控設計
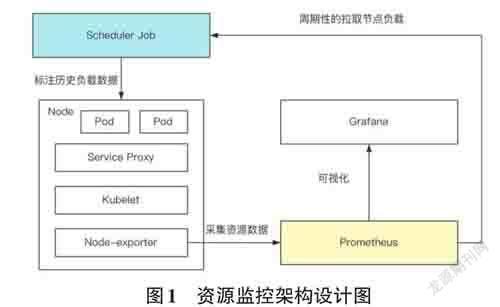
為了改進Kubernetes的默認資源調度算法,本文需要額外采集CPU、內存和磁盤的歷史負載情況,用于調度策略的優化,本文采用Node-exporter + Pro?metheus + Grafana的技術對指標進行采集、存儲與展示。如圖1 所示,主要實現兩個組件,分別是Pro?metheus 和Scheduler Job。在Prometheus 中實現一個自定義指標采集策略,對歷史負載情況進行采集和存儲。具體實現方式為在配置規則文件中編寫采集指標的PromQL語句,然后通過Node-exporter 定期采集期望獲得的數據并進行存儲。在Scheduler Job中周期性地拉取各個節點的負載數據,計算其歷史負載情況,并以注解的方式標注在節點上。在后續的資源調度算法需要獲取節點自定義負載數據時,調度器無需請求Metrics Server API,只需要直接查詢節點上的注解信息,就能獲取到節點最近的負載情況,這樣可以減少HTTP請求所花費的時間,極大提高調度器的調度性能。
2.2 資源模型
本文提出一種基于集群節點負載均衡的調度方法,通過監控節點近期CPU、內存、磁盤的情況,周期性的將這些指標以注解的方式標注在節點中,在調度器的預選和優選階段根據監控到的指標數據對節點進行過濾和打分。本方法主要關注以下指標:1) CPU最近5分鐘的平均利用率。2) CPU最近1小時的最大利用率。3) 內存最近5分鐘的平均利用率。4) 內存最近1小時的最大利用率。5) 磁盤最近5分鐘的平均利用率。6) 磁盤最近1小時的最大利用率。
2.3 調度算法
本文通過Scheduler Framework 實現一個自定義的調度器,在Filter 和Score 這兩個擴展點進行擴展實現,同時保持其余擴展點的Kubernetes 默認策略不變。
在調度的Filter 階段,從候選節點的注解中讀取歷史負載數據,并根據這些數據對負載較高的節點進行過濾。如圖2所示,步驟如下:
1) 判斷需要調度的Pod類型,如果是Daemonset類型,說明所有的節點都需要運行這個Pod,不過濾該節點,直接結束流程。如果不是Daemonset類型,將繼續進行第2步。
2) 遍歷該節點上的所有注解。每一個注解都代表一項自定義指標數據。
3) 對于每個注解,將其與配置文件中初始定義的閾值進行比較。只要有一項指標的實際利用率超過其對應的閾值,那么這個節點將被過濾,代表該Pod無法調度到該節點上,結束流程。如果所有指標的實際利用率都小于或等于設定的閾值,那么這個節點在預選階段篩選通過,不過濾該節點,結束流程。
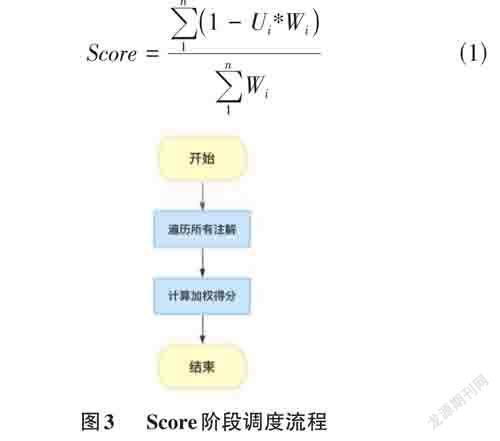
在調度的Score階段,基于節點注解上的指標數據進行打分,最終得分是這些指標值的加權和。如圖3所示,步驟如下:
1) 遍歷節點上的注解,得到歷史負載指標數據。
2) 計算節點的加權得分。假設節點中的資源負載指標集合為Usage = {U1,U2,U3, ... ,Un },資源負載指標對應的權重集合為Weight = {W1,W2,W3, ... ,Wn }。根據式(1)計算節點的分數。
3) 每一個節點計算完成之后,最終得分返回給調度器,由調度器挑選得分最高的節點部署Pod。
3 實驗分析
3.1 實驗設計
本實驗在4臺安裝了Centos7.9的虛擬機上部署Kubernetes集群,其中Master節點1臺,Node節點3臺,其中Master節點和兩個Node節點CPU為2核,內存為2G,另一個Node節點CPU為4核,內存為4G,安裝的Kubernetes版本號為v1.23.10。
本次實驗分為兩組,分別為實驗組與對照組,實驗組使用本文實現的調度器,對照組使用Kubernetes默認的調度器,各種指標的采集頻率、閾值與權重如表1所示。
整體實驗分為以下幾個步驟:
1) 先使用Kubernetes默認調度器,使用kubectl客戶端向Master節點的API Server發起創建Pod的命令,每次創建10個Pod,每隔6小時創建一次,一共創建50個Pod。
2) 記錄各節點資源使用情況,在初始時記錄一次,然后在每次創建完Pod后30分鐘記錄一次,頻率也為6小時一次。
3) 所有Pod創建完成之后,計算集群的負載均衡度stdScore,計算公式如式(2) ~式(4),Scorei 代表第i個節點的得分,Ucpu 代表當前節點的CPU利用率,Umem代表當前節點的內存利用率,Udisk 代表當前節點的磁盤利用率。Wcpu、Wmem、Wdisk 分別為各指標的權重,本實驗設置為50、40、10。
3.2 實驗結果與分析
整體實驗過程中Pod分布情況如表2所示,從測試結果可以看出,在剛開始的時候,兩次實驗每個節點上分布的Pod數量基本一致,由于剛開始每個節點的負載都較小,調度器會平均分配Pod對象。在實驗中后期,實驗組會傾向于把Pod分配給node3節點,因為此節點的CPU和內存更大,這樣可以盡可能的保證集群之間的負載均衡。相比之下,默認的調度算法只考慮了節點當前的CPU和內存的利用率情況,沒有考慮歷史的負載情況以及磁盤利用率情況。
各個階段Pod部署完成之后集群的負載均衡度如圖4所示,可以看出實驗組的負載均衡度要低于對照組的負載均衡度,因此使用本文所提出的資源調度方法后,Kubernetes集群整體的負載情況要優于使用默認的調度方法。
4 結束語
本文設計了一種資源監控的架構,該架構借助開源框架Prometheus將集群中節點的負載情況記錄下來。并提出了一種基于集群負載均衡的資源調度方法,該方法考慮節點自身的負載情況,并使用最新的Scheduler Framework技術實現了該方法,從而實現集群之間的負載均衡。最后搭建實驗環境,設計實驗步驟并進行實驗,對本文提出的資源調度方法與Kuber?netes默認資源調度進行了對比和分析,通過分析可以得出本文所提出的基于集群負載均衡的資源調度方法相比默認調度方法更有優勢。但是本文的資源調度算法只考慮了CPU、內存、磁盤的利用率情況,后續還可以考慮網絡I/O、磁盤I/O的影響。另外由于成本問題,本文的測試集群只有四臺主機,測試用例也比較有限,在條件允許的情況下,后期可將資源調度算法在大規模集群上進行測試。
