社區老年衰弱風險預測模型系統評價
2023-04-08 03:39:28程俊寧劉金旭莊一渝勞月文
中國現代醫生 2023年6期
程俊寧,劉金旭,莊一渝,勞月文
1.浙江中醫藥大學護理學院,浙江杭州 310053;2.浙江大學醫學院附屬邵逸夫醫院護理部,浙江杭州 310016
衰弱是指個體脆弱性增加及保持自我內在平衡能力下降的臨床綜合征,其特征是多個系統的生理功能下降,從而導致機體對壓力源的敏感性增加[1-7]。衰弱會使老年人群面臨更高的不良后果的風險,包括跌倒、住院、殘疾和死亡等,嚴重影響其生活質量,還會導致家庭負擔的加重和社會醫療費用的增加[8,10],但衰弱在一定程度上是可逆的,特別是在早期階段[1]。
因此,早期識別衰弱高危人群是優化衰弱管理的重點。風險預測模型支持疾病風險的計算,可在不良事件發生之前識別高風險的個體,劃分不同的風險層次,進而實現精準預防,提高醫療的質量和效率[11]。目前國內外已有多項研究開發、驗證社區老年衰弱預測模型,但文獻質量不一。因此,本研究系統地分析、評價社區老年衰弱風險預測模型的研究,以期為公共衛生從業者和衛生保健人員選擇合適的風險預測模型預防患者發生衰弱提供參考。
1 資料與方法
1.1 文獻納入和排除標準
①納入標準:a.研究類型為隊列研究、病例-對照研究和橫斷面研究;b.研究對象為年齡≥60 周歲的社區老年人,其種族、國籍、病程不限;c.研究內容為采用多變量設計的衰弱風險預測模型,但不包括預后和進展模型。②排除標準:a.僅涉及衰弱危險因素,未構建衰弱風險模型的研究;b.會議摘要、綜述、述評或基于系統評價、Meta 分析建立模型的研究;c.沒有使用經過信效度檢驗的工具評估結局指標;d.無法獲取全文或信息不完整;e.非中英文文獻。
1.2 搜索策略
計算機檢索PubMed、EMbase、Web of Science、The Cochrane Library、CBM、VIP、WanFang Data和CNKI 數據庫,搜索關于社區老年人衰弱風險預測模型的研究。檢索時限均為建庫至2022 年8 月20日。此外,追溯納入文獻的參考文獻,以補充獲取相關文獻。英文檢索詞包括:frailty、frailty syndrome、frail elderly、frailty index、asthenia、prediction model、prognostic model、risk stratification model、model、risk factor、predictor、aged、elderly、geriatrics、gerontology、communit、community dwelling、community-based participatory research、community participation、community involvement;中文檢索詞包括:衰弱、虛弱、衰弱綜合征、衰弱指數、預測模型、模型、危險因素、預測因子、老年人、老人、老年、老年醫學、社區、社區醫學。
1.3 文獻篩選和資料提取
由2 名研究人員獨立篩選文獻、提取資料并交叉核對。如有分歧,則通過討論或與第三方協商解決。文獻篩選時首先閱讀文題,在排除明顯不相關的文獻后,進一步閱讀摘要和全文以確定是否納入研究。確定納入文獻后,本研究基于預測模型研究系統評價的關鍵評估和數據提取清單(critical appraisal and data extraction for systematic reviews of prediction modelling studies,CHARMS)[12],制訂了標準化表格用于數據提取。資料提取內容包括第一作者、發表年份、研究地區、研究設計類型、研究對象、隨訪時間、預測結果、候選變量、樣本量、缺失數據、建立模型的方法、最終包含的預測因子、模型呈現形式、模型的性能和驗證方法等。
1.4 偏倚風險和適用性評價
由2 名研究員獨立評價納入研究的偏倚風險和適用性,并交叉核對結果。偏倚風險和臨床適用性使用預測模型研究的偏倚風險評估工具(prediction model risk of bias assessment tool,PROBAST)[13]進行評估。偏倚風險的評估涵蓋了4 個領域:研究對象、預測因子、結果和分析,適用性評估涵蓋3 個領域:研究對象、預測因子和結果。
2 結果
2.1 文獻篩選流程和結果
初篩共獲得相關文獻篇,經逐層篩選,最終納入文獻10 篇[14-23],包括8 篇[14-18,21-23]為模型的開發研究,2 篇[19-20]為模型開發及驗證研究。文獻的篩選流程及結果見圖1。納入文獻的基本特征及預測結局見表1。
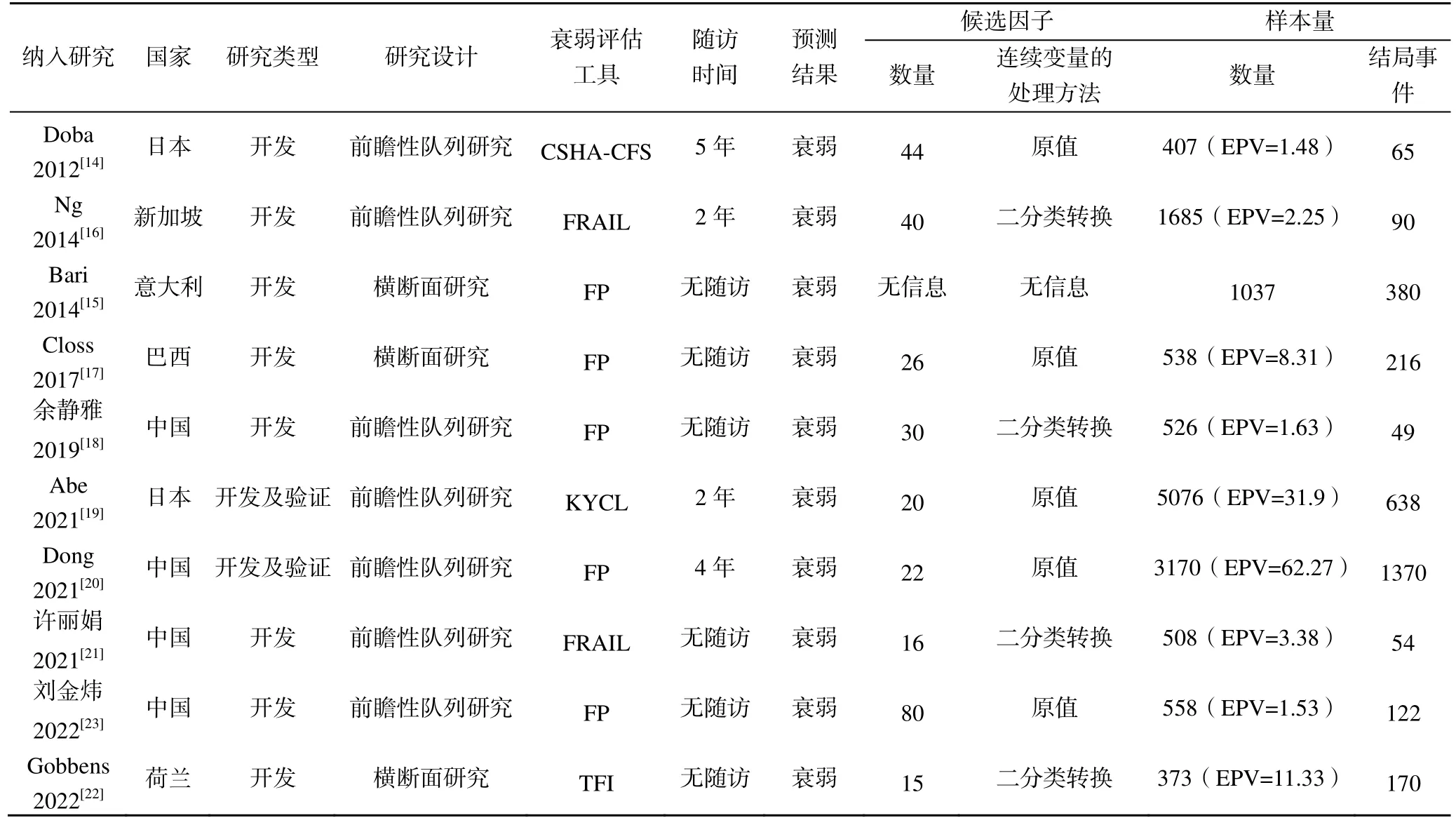
表1 納入研究的基本特征

圖1 文獻篩選流程及結果
2.2 納入模型的一般情況
共納入10 個社區老年人衰弱預測模型,其中7個[14-17,19,20,22]為英文研究,3 個[18,21,23]為中文研究。研究設計類型方面,7 個[14,16,18-21,23]研究為前瞻性隊列研究,3 個[15,17,22]為橫斷面研究。最早的模型[14]發表于2012 年,近3 年共發表5 個研究[19-23]。樣本總量為373~5076 例,結果事件數為49~1370 例。5個[15,17,18,20,23]研究采用衰弱表型量表(frailty phenotype,FP),2 個[16,21]研究采用衰弱量表,1 個[22]研究采用蒂爾堡衰弱指標,1 個[14]研究采用日文版臨床衰弱水平量表,1 個[19]研究采用KY 檢查表。
2.3 模型構建情況
10個模型研究中,候選因子數量為15~80個。2個[19-20]研究的結果事件數與協變量個數比(number of events per variable,EPV)超過20,1個[15]研究未報告協變量個數,6個[14,16-18,21,23]研究小于10,還有1個研究[22]介于10~20。10個研究中有8個[15-16,18-23]統計分析時納入了所有對象,其中僅1個研究[19]報告了缺失數據的樣本量及處理方式,1個研究[20]對缺失數據進行了多重插補,但未報告缺失數據的數量,6項研究[15,16,18,21-23]未報告缺失數據。7個[14,16,18-22]研究采用了Logistic回歸分析,1個[15]研究未報告建模方法,1個[17]研究應用了Logistic回歸模型與神經網絡模型,1個[23]研究采用了Logistic回歸模型并與隨機森林、支持向量機、梯度提升算法4種方法進行比較,見表2。
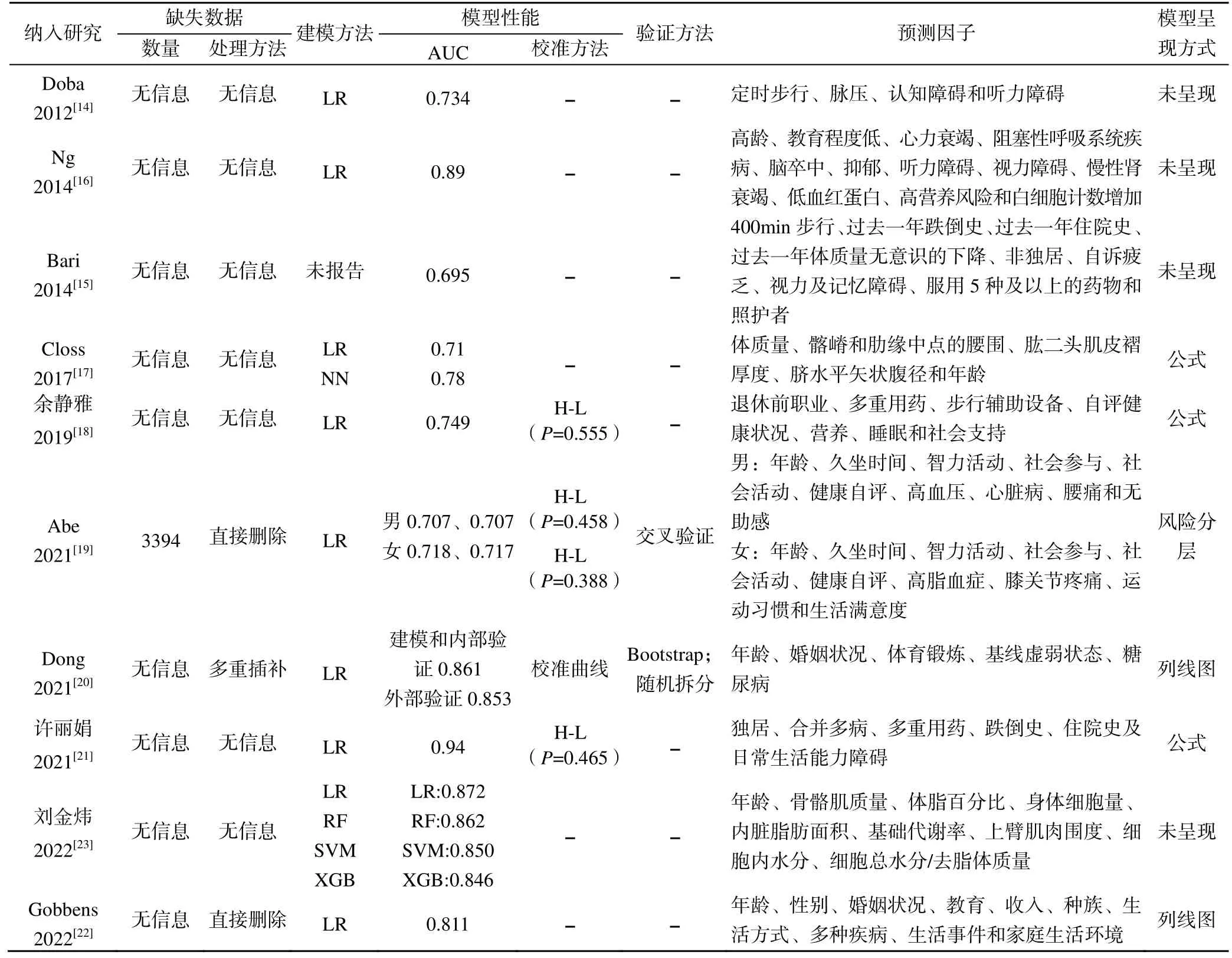
表2 納入模型的性能和預測因子
2.4 模型性能與結果
納入研究主要是通過受試者工作特征曲線下面積(area under the curve,AUC)及Hosmer-Lemeshow檢驗(P>0.05)對模型性能進行評價,10 個[14-23]研究均報道了模型的區分度(AUC 為0.695~0.940),除了Di Bari 等[15]的研究外,其他模型AUC 均>0.7,預測效能較好。4 個[18-21]研究對模型的校準度進行了評價,其中 3 個[18-19,21]模型均采用了 Hosmer-Lemeshow 檢驗(H-L),1 個[20]研究應用了校準曲線評價模型的校準度。2 個研究[19,20]進行了模型的內部驗證,其中Abe 等[19]采用了5 折交叉驗證的方法,得到的AUC 值與之前模型接近;Dong 等[20]應用Bootstrap 方法,重復抽樣1000 次,得到的AUC 值與之前模型一致,2 個模型的可重復性較強。在外部驗證方面,1 個[20]研究采用了隨機拆分驗證,外部驗證的模型表現出的較好的區分度(AUC=0.853),校準曲線在原先模型和驗證模型中顯示出良好的一致性。1 個[20]研究報道了臨床決策曲線(decision curve analysis,DCA),但文中未展示DCA。6 個[17-22]研究報告了模型的呈現方式,其中2 個[20,22]為列線圖,1個[19]為風險分層,3 個[17-18,21]為預測公式。
2.5 納入研究的偏倚風險與適用性評價
納入的10 個[14-23]預測模型中,研究對象偏倚風險均處于較低水平,且均對預測因子的測量方法進行了詳細描述,偏倚風險較低。9 個[14-20,22,23]模型的結果部分偏倚風險較低。但在分析領域中,除了Dong等[20]的模型外,其余[14-19,21-23]模型均處于高偏倚風險,通常是因為樣本量的大小和缺失數據領域偏倚風險較高。大多模型的樣本量不足,用于開發模型的數據集中的EPV<10。4 個研究將連續型變量轉換為>2 個類別的變量,導致預測模型不夠準確,偏倚風險較高。在缺失數據方面,9 個[14-18,20-23]研究均未對缺失數據的數量進行報道,1 個[19]研究報道了缺失值,但并未遵循PROBAST 的建議對缺失值進行多重插補,而是直接刪除,另外1 個[20]研究采用了多重插補,但未報告缺失數據的數量。此外,1 個[15]研究未報告變量篩選的統計方法,6 個[14-17,22-23]研究未對校準度進行評價,8 個[14-18,21-23]研究未采用內部驗證,9 個[14-19,21-23]研究未采用外部驗證,這也是分析領域偏倚風險高的重要原因。在適用性上,所有模型的適用性均較高。從總體來看,9 個[14-19,21-23]研究均不符合PROBAST 標準,1 個[20]研究達到標準。
3 討論
近年來,關于社區衰弱預測模型逐漸增多,但研究質量有待評估。本研究納入的10 個[14-23]研究中,除了Dong 等[20]的模型外,其余研究偏倚風險均偏高,主要原因在于分析領域,如樣本量較少、缺失數據的報告、對連續和分類變量的處理,以及缺乏內部或外部驗證等。
每個自變量的事件數(events per variable,EPV)是用結局變量中較少組的數量除以自變量的個數,即衰弱發生的人數除以自變量,而此變量并非是最終模型包含的預測變量的數值,而是預測模型構建階段所考慮變量的總數,即候選變量[24]。除了1 個[15]研究未報告候選變量導致無法計算EPV外,只有2 個[19-20]研究EPV>20,其余6 個[14,16-18,21,23]研究均<10,1 個[22]研究介于10~20。EPV 的經驗準則是至少為10,低于10 的研究可能存在過度擬合或擬合不足,導致偏倚風險增高,但Van 等[25]研究表明該閾值沒有科學依據,建議EPV 至少為20,從而避免模型的過度擬合,與PROBAST 條目類似,而對于采用機器學習技術開發的預測模型通常需要更多的EPV(>200)以最大程度減少過度擬合。劉金煒等[23]研究采用多個機器學習方法,但EPV 僅1.525,導致分析領域高偏倚風險。
許多研究[14-18,21-23]沒有描述缺失數據的信息,也沒有說明是否對缺失數據進行統計學處理。缺失數據會影響到數據分析的質量和模型的準確性,因而對缺失數據的預處理較為重要。本次納入的10個研究中,僅Dong 等[20]的研究對缺失數據進行了多重插補。雖然Abe 等[19]研究完整地報告了缺失數據的數量及處理方式,但其采取方法是直接刪除缺失值,可能會影響預測變量與結局變量之間的關聯,導致構建的模型性能存在偏差。在PROBAST的條目中,強調對于缺失數據不應排除,應進行多重插補[13]。
納入的10 個模型中,除了Di Bari 等[15]未報告模型的構建方法,其余均采用Logistic 回歸分析的方法。Closs 等[17]應用NN 和Logistic 回歸分析兩種建模方法,并對比預測能力,發現區分度均>0.7,預測效能較好。NN 是指通過計算機模擬人的神經元傳遞及處理信息的方式而構建的一種數學模型,其建模的優越性已在多個研究中得到證實[26-27]。劉金煒等[23]采用了Logistic 回歸分析、隨機森林、支持向量機、梯度提升算法4 種方法進行建模,并比較四者之間的預測性能,結果顯示Logistic 回歸分析模型的預測能力最強,但文中未對其他3 種建模方式進行詳細描述,預測能力僅局限于AUC 值比較,未比較模型校準度、內部外部驗證之間的差異,尚不能判斷四者之間的優劣。
預測模型的常用的評價指標包括區分度和校準度[28]。區分度可通過ROC 曲線計算AUC 或C 指數進行評價,AUC 值越接近于1 說明模型區分度越好;校準度常用的方法是Hosmer-Lemeshow 擬合優度檢驗或校準圖[29]。10 個[14-23]模型均報告AUC 值,除了1 個[15]研究為0.695,其余[14,16-23]均>0.7,說明多數模型均能較準確地預測患者是否發生衰弱,但僅4 個研究對模型的校準度進行評價,6 個模型未評價,將難以判斷6 個模型預測的概率與現實概率之間的差異。10 個研究中僅2 個[19-20]模型進行了內部驗證,僅Dong 等[20]的模型進行了外部驗證。建議學者在后期研究開發或驗證預測模型時,參照模型的報告規范——個體預后或診斷的多變量預測模型透明報告[28],同時參考PROBAST,盡可能減少模型的偏倚風險。
研究者盡可能展示出模型的公式,以便于其他地區或國家的研究人員利用公式對模型進行外部驗證、校準模型和實際應用。10 個[14-23]模型的候選變量15~80 個,預測因子5~13 個,出現頻率最高的是年齡,應對社區中高齡患者給予高度關注,可考慮定期評估,其余因子差異較大,與許多研究選擇的候選變量相關。部分[17,23]研究僅關注身體測量指標,限制了模型的泛用性,可能忽視部分處于衰弱高風險的老年人群。納入的10 個模型適用性均較強,較易在社區找到研究對象,在社區實踐中極易得到應用,預測因子和結果也符合該系統評價的主題。
綜上所述,納入的10 個研究中大部分模型偏倚風險較高,分析領域存在較多問題。Dong 等[20]的研究是目前社區老年衰弱模型中在分析領域中最為完善的模型,樣本量適當(EPV>20)、報告了缺失數據的處理方式、模型的區分度、校準度,采用了內部外部驗證,模型的預測能力較好。后續研究根據當地的實際情況,選擇適當的模型進行衰弱風險的預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
石油瀝青(2021年4期)2021-10-14 08:50:44
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
