ChatGPT來了,我們離AI生成電影還有多遠?
2023-04-11 12:19:38張雪
現代電影技術 2023年3期
如果你還沒有和ChatGPT (Chat Generative Pre-trained Transformer)對話,都不好意思聊人工智能(AI)。
Chat GPT 是美國人工智能實驗室Open AI發布的一種生成式大型語言模型,采用Transformer深度神經網絡架構,基于人類反饋的監督學習和強化學習,在GPT-3.5模型之上進行訓練微調形成,能夠通過學習人類語言和理解上下文來實現對話互動,敢于質疑與承認錯誤,大幅提升了對用戶意圖的理解能力。
ChatGPT 上線2個月,月活躍用戶就已成功過億,并于近日宣布開放API,允許第三方開發者將其集成至應用程序和服務中。
那么,“神通廣大”的Chat-GPT可以生成一部電影嗎?
1 ChatGPT生成劇本
菲律賓28 Squared工作室和Moon Ventures工作室運用Chat GPT幫助劇本創作,7天制作完成6 分半短片 《安全地帶》(The Safe Zone)。團隊首先使用ChatGPT 篩選出大量故事創意,并挑選前五名,讓ChatGPT為這五個創意生成劇本。但在這一過程中,團隊發現ChatGPT 會很快偏離關鍵主題,為此制片人只能不斷提醒其注意情節的發展邏輯。最后,團隊通過主動要求ChatGPT 對故事的某些部分提供更多細節來充實劇本。劇本生成后,ChatGPT 可以根據劇本內容設計具體的鏡頭清單,還可以回答機位、演員位置、燈光位置、角色情緒、服裝道具等完整細節,以輔助分鏡設計。
2 AI生成電影
采用Chat GPT 生成劇本已完成了電影制作的第一步,后續電影制作仍能由AI完成嗎?Chat GPT認為“如果結合多個AI模型,可能可以實現一些電影制作方面的任務。”下面讓我們看看在電影制作過程中,AI都能完成哪些制作任務。
電影主要由圖像和聲音兩大要素組成,在圖像和聲音生成領域近年來發展形成了較多國內外AI模型,從圖1可以窺見一斑。它們 “可能可以”接力ChatGPT 生成的劇本,完成相應的電影制作。
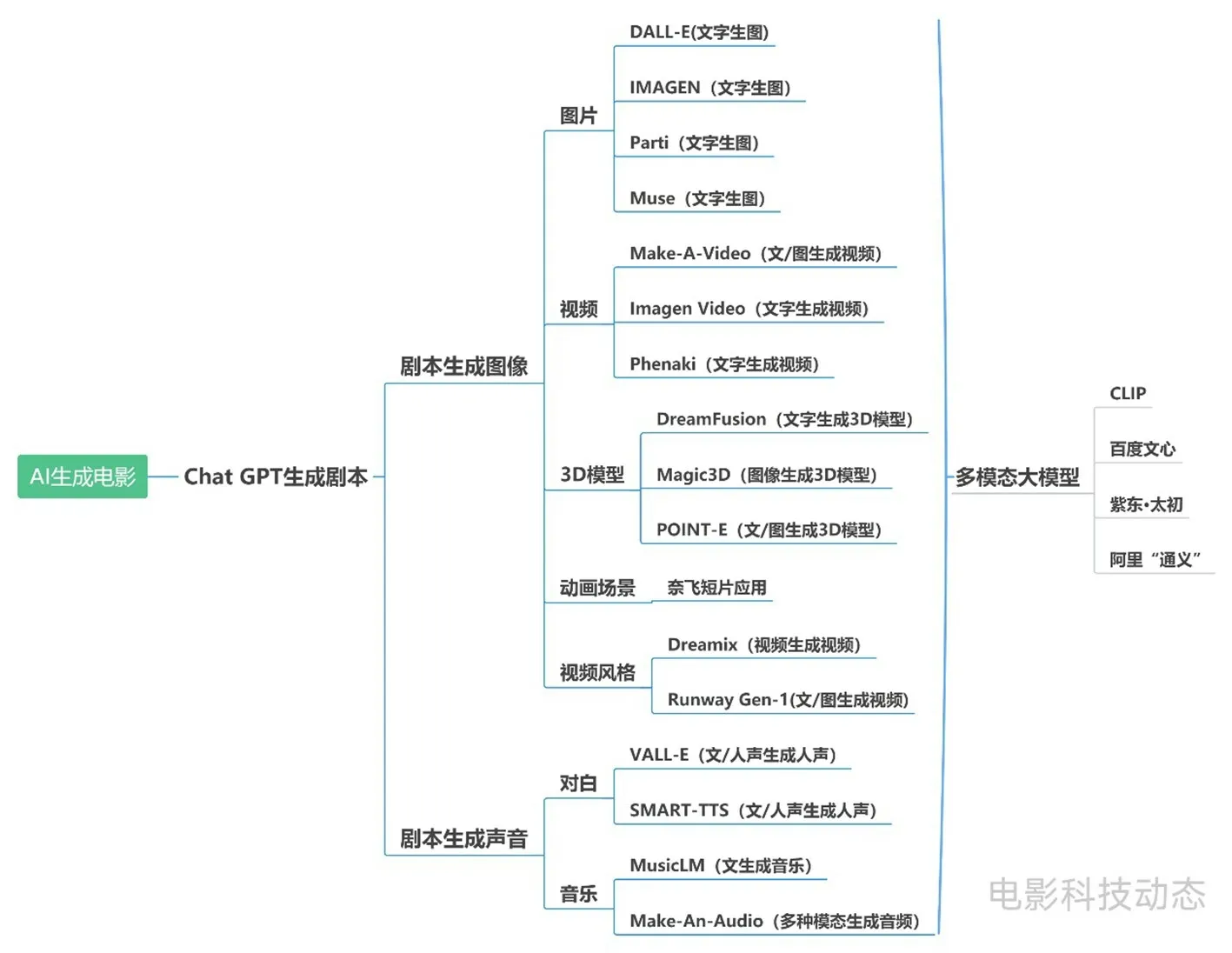
圖1 電影制作過程中AI能夠完成的制作任務
3 圖像生成
目前各類圖像AIGC (人工智能生成內容)模型發展迅速,如文字生圖片、文字生視頻、3D 模型生成、動畫場景生成、視頻風格遷移等。
3.1 圖片生成
當前文字生圖片AI模型發展較快,其中較為常見的大模型包括Open AI的DALL-E 2和谷歌的IMAGEN、Parti、Muse。
DALL-E 2雖能生成較為逼真的圖片,但無法辨識上下左右等方位信息,當文本中存在對物體顏色或場景內文字的描述時會出現錯誤,生成復雜場景時還會出現嚴重的細節缺失。IMAGEN 使用大量純文本語料訓練,得益于強大的編碼器,IMAGEN在為物體分配顏色和生成場景內文字時更加準確。Parti具有可擴展的模型規模,最高可擴展至200億參數,參數越多、模型規模越大,生成圖像的細節越豐富,錯誤信息也明顯降低。Muse在給輸入圖片加入掩碼進行重構學習的基礎上,利用動態遮蔽率實現推理階段的迭代并行編碼,在不損失圖片生成效果的同時,極大地提高了模型推理效率。
3.2 視頻生成
視頻可以認為是多張 “圖片”有邏輯、連貫的組成,AI生成視頻是AI生成圖片的深度延伸。現有AI生成視頻模型可一定程度滿足提升效率與契合腳本內容的需求,但由于模型本身能力和訓練素材質量的限制,此類模型目前處于非常初級的階段,存在動作過渡不自然、理解角度詭異、視頻分辨率不高等問題,所生成的視頻還不夠完善。
Meta的“Make-A-Video”AI影片生成工具可通過文字和圖片識別,生成一段時長5秒、16FPS的無聲片段,分辨率為768×768。除文本輸入外,還可根據其他視頻或圖片制作新視頻,或是生成連接圖像的關鍵幀,讓靜態圖片動起來。
谷歌的Imagen Video與Phenaki,前者主打視頻品質,后者主要挑戰視頻長度。其中Imagen Video可根據文本提示以24FPS生成分辨率為1280×768的視頻,長度不超過5 秒;Phenaki可根據200 詞左右的提示語生成2分鐘以上長鏡頭,且具備相對完整的故事情節。
3.3 3D 模型生成
若需要制作更為復雜的3D 模型,也有相應的AI生成模型,但渲染環節暫無專門的AI模型支持。谷歌DreamFusion可由文本生成具有密度和顏色的3D 模型,還可進一步導出為網格體,以便進一步加工。英偉達Magic3D 使用兩階段生成法,首先使用低分辨率擴散先驗獲得模型的粗略表示,并使用稀疏3D 哈希網格結構進行加速;再以粗略表示作為初始,進一步優化具有紋理的3D 網格模型。Open AI的POINT-E由文本-圖像模型和圖像-3D模型組成,其首先根據文本生成2D 圖像,再將2D圖像依次轉換為包含1024個點的粗略點云,最后在粗略點云的基礎上生成包含4096個點的精細點云。
3.4 動畫場景生成
AI在動畫場景繪制方面已有短片應用。此前奈飛(Netflix)與微軟小冰、WIT STUDIO 共同創作首支AIGC動畫短片《犬與少年》,其中部分動畫場景由AI輔助生成。其采用類似Stable Diffusion中以圖生圖的方式,由制作人提供設計圖,AI生成細節并優化,形成一張完成度較高的場景圖,制作方只需對這張圖進行適當修改,即可直接使用。
3.5 視頻風格遷移
如果對現有視頻風格不滿意,還可使用AI工具生成其他定制風格的新視頻。谷歌Dreamix可通過應用特定的風格從現有視頻中創建新的視頻。曾在2022年創建“文本-圖像”模型Stable Diffusion的技術公司Runway推出模型Gen-1,可通過文本提示或參考圖像指定的任何風格,將現有視頻轉換為全新風格、時長更長的視頻。
4 聲音生成
聲音作為電影的另一項要素,主要包括對白、音效、音樂,共同起著情節推進、氛圍營造和情感共鳴等重要作用。目前也有不少AI模型可以完成相關內容的生成制作。
4.1 對白
微軟的語音合成AI模型VALL-E 經過6萬小時英語語音數據的訓練,使用特定語音的3秒剪輯來生成內容,可復制說話者的情緒和語氣,即使說話者本人從未說過的單詞也可以模仿。
科大訊飛的多風格多情感合成系統SMARTTTS充分利用文本和語音的無監督預訓練,實現了從文本到聲學特征,再到語音的端到端建模,可提供11 種情感、每種情感20 檔強弱度的調節能力,也可根據自己喜好調節停頓、重音、語速等。
4.2 音樂
谷歌的Music LM 可從文本描述中生成頻率為24k Hz的高保真音樂,還可以基于已有旋律轉換為其他樂器,甚至可以設置AI“音樂家”的經驗水平,系統可以根據地點、時代或音樂風格 (例如鍛煉的勵志音樂)進行創作。
浙江大學與北京大學聯合火山語音提出的文本到音頻的生成系統Make-An-Audio,可將自然語言描述作為輸入,而且是任意模態(例如文本、音頻、圖像、視頻等)均可,同時輸出符合描述的音頻音效,具有強可控性、泛化性。
4.3 多模態大模型
多模態大模型能夠在計算機視覺 (CV)、自然語言處理(NLP)、語音識別等不同的模態間構建關聯,單個模型可支持,以音生圖、以文生圖、以圖生音以及聲音轉文字等功能。OpenAI的CLIP、國內百度文心、紫東·太初、阿里“通義”等多模態大模型近年來持續發展,在電影制作領域也具備一定的潛在應用價值。
5 結語
在上述各類模型的共同參與下,AI生成電影的基本鏈條已具雛形。但正如ChatGPT 所言,目前AI技術仍然存在一些局限:
第一,AI模型仍然需要人工干預,語言類模型給出的文本指導需經過專業技術人員的審核確認才能實際應用;
第二,用于生成視頻和音頻的AI模型由于訓練數據的限制,生成結果較為簡單,質量還遠遠達不到電影要求;
第三,由于AI生成內容是由機器使用現有數據和內容產生,AI生成作品的版權問題仍存在較大爭議,法律對AI生成內容的版權保護仍處于“缺位”狀態。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
