基于知識圖譜的多輪對話技術研究綜述
2023-04-21 13:10:26盛勝利奚雪峰
計算機技術與發展 2023年4期
關鍵詞:模型
楊 陽,盛勝利,奚雪峰
(1.蘇州科技大學 電子與信息工程學院,江蘇 蘇州 215009;2.蘇州市虛擬現實智能交互及應用重點實驗室(蘇州科技大學),江蘇 蘇州 215009;3.數據分析實驗室(德州理工大學),德克薩斯州 拉伯克市 79409)
0 引 言
近年來,隨著自然語言處理技術和人工智能的蓬勃發展,從備受關注的人機對戰到貫穿人們日常生活的無人駕駛、智能家居等,人工智能正在逐漸地改變人們的日常生活[1]。例如,通過WIFI等接入方式與一些智能家居設備相連并進行控制操作[2-3]。得益于深度學習技術的不斷完善與發展,加上使用海量的大數據和云計算的不斷普及,自然語言處理技術和語音識別技術的判斷準確率得到了明顯的提高。
對話系統得益于自然語言技術的不斷成熟,其意在能夠精準猜測出用戶的意圖,并且快速準確地回答問題。當然對話不可能只是一問一答,現實中對話一定是多問多答,并且是連貫的、合乎邏輯的。然而目前多輪對話仍然存在諸多問題,例如缺乏相對應的知識推理能力,多輪對話的能力。在實際的人機對話過程中,必須進行多方考慮,目前部分機器學習的實際應用案例以及相關的技術研究還僅僅處在一個“低級智能”階段,為了使機器的回復更精準、更高效、更有趣,從“低級智能”向“高級智能”階段進一步發展,因此許多研究人員努力將知識圖譜技術應用到多輪對話中。基于知識圖譜的多輪對話是結合實體和實體間的關系,將知識三元組和原始對話上下文數據融合在一起,更好地實現多輪對話。
1 問題定義
根據當前的應用場景(包括開放域和特定域),目前的對話系統主要分為單輪對話系統和多輪對話系統。
單輪對話的定義公式為:γ=g(q);
多輪對話的定義公式為:γ=g(q|c)。
以上公式中,q表示查詢語句;γ表示答復語句;c表示歷史上下文對話信息;g(*)表示從查詢語句中對應答復的數據庫中經過篩選匹配后給出最合適數據的結果。
2 多輪對話中使用的相關技術
隨著自然語言處理技術的不斷成熟與發展,當前對自然語言處理的研究側重點已經轉移到深度學習,深度學習是加深了層的深度神經網絡,是研究人員模仿人類大腦的工作運轉模式,通過計算模擬出人工神經元以此來組成人工神經網絡,解決一系列復雜問題。多輪對話中的主要技術有詞向量技術、知識圖譜等。
2.1 詞向量技術
詞向量技術為人類自然語言和計算機語言處理提供了一座橋梁,讓原本零散的、孤立的、稀疏的詞序列演變成為密集的語義向量,為人工神經網絡更好地理解人類自然語言提供了有力的保障。現實中自然語言符號往往采用高維度向量表示,為了方便計算機讀取和處理數據,需要采用相對應的技術手段將這些零散的文字進行向量化,即轉為詞向量。目前采用的方法主要有One-Hot編碼和詞的分布式表達法。
One-Hot編碼主要采用的是將文章中所有出現的詞匯融合成一個字典,其目的是為每一個字典中出現的詞設定一定的維度并確定為詞向量。該向量的要求為詞對應的位置上為“1”,即每一個詞在指定的并相同的部分為1,其他部分均為0。例如,在一個包含10 000個詞的詞典,該詞典里包含了所有的交通工具,例如“高鐵”“地鐵”,那么這兩個詞可以表示為:“高鐵”:[0,0,0,0,0,0,0,1,0,0],“地鐵”:[0,0,0,1,0,0,0,0,0,0]。但由于自然語言字詞符號等數量龐大,因此相應的詞表也會非常大,從而造成了資源的極大浪費。
鑒于One-Hot編碼的缺點及其發展的局限性,研究人員在表示詞向量的維度上做出了很多改進。詞的分布式表達法是目前廣泛用于自然語言處理(Natural Language Processing,NLP)任務中的一種新范式。該方法最初在1986年由David E Rumelhart、Geoffrey E Hintont、Ronald J Williams提出,它克服了One-Hot編碼的缺點,并具有很多優勢。其旨在以固定長度、連續和密集的特征向量來表示單詞。此外,Mikolov等人[4-5]提出了一種使用神經網絡學習分布式詞向量表示(Word2Vec)的模型架構,這種技術目前主要用于自然語言技術中捕捉語義和語法之間的關系。其他的分布式單詞表示法有語義分析法[6]和潛在Dirichlet分配法[7]。
2.2 知識圖譜技術
由于在多輪對話過程中,多輪對話需要深度結合歷史對話信息,確保對話上下文具有連貫性,針對提問者提出來的問題,從答復語料庫中選取匹配相似度最相關的回復。為了解決開放域多輪對話中存在的問題,研究人員建議將有關對話的先驗信息表示為圖,旨在建立更加連貫的對話。基于知識圖譜[8]的多輪對話是給定與當前對話相關的知識三元組,以當前用戶語句和對話歷史信息作為輸入,以合適的回答作為輸出。
在基于知識圖譜的多輪對話中,其主要采用的是End-to-end[9]的生成模型來構建系統模型。在系統建模時,主要工作為對知識圖譜、歷史對話和用戶當前語句進行建模,與此同時針對這三個部分的建模信息進行相對應的解碼,以產生相對應的回復。
知識圖譜的技術架構如圖1所示。
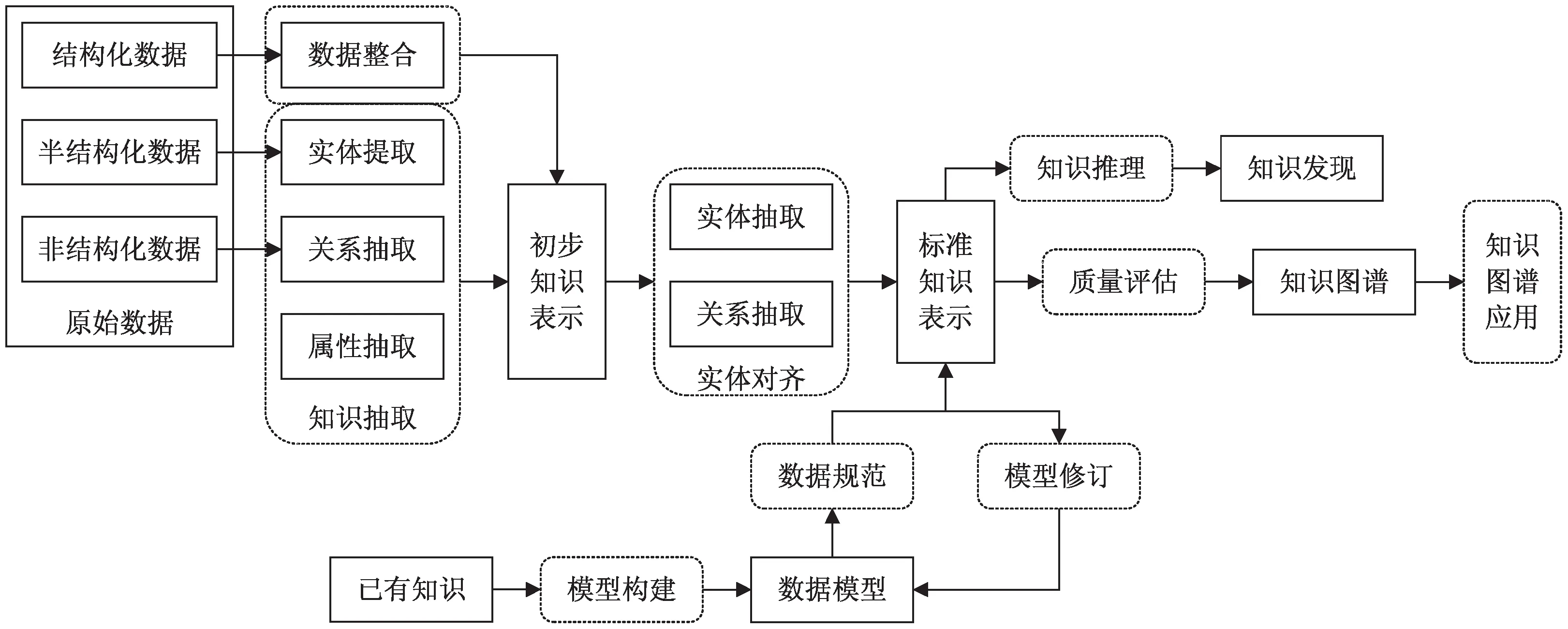
圖1 知識圖譜的技術架構
3 基于知識圖譜的多輪對話模型
3.1 預訓練模型
深度上下文語言模型(Deep Context Model,DCM)被證明在語言表達方面是有效的,在一系列的自然語言處理模型中取得了最先進的結果。例如語言模型嵌入[10]、廣義自回歸預訓練[11]、魯棒優化伯特預訓練方法[12]和AL-BERT[13]。通過提供細粒度的上下文信息,這些預訓練的模型既可以作為編碼器輕松應用于下游模型,也可以用于微調,這些DCM在表示特定領域語料庫中的上下文化信息方面仍然受到限制,因為它們通常在通用的語料庫中進行訓練[14-15]。
3.2 多輪對話建模
開發對話系統意味著訓練機器使用自然語言與人類對話。目前已經設計了許多對話系統,主要分為兩種類型的架構:一種連接所有上下文語句[16-18],另一種分離并聚合上下文語句[19-24]。
3.3 基線模型
3.3.1 基于后驗生成的模型
Liu等人[25]在2017年提出了采用先驗分布來逼近后驗分布的方法,其原理為從候選的知識圖譜庫中選擇出最合適的知識三元組,生成相對應的回復語句。先驗分布是根據用戶的提問來選擇知識,后驗概率主要是根據回復和用戶輸入選擇知識。模型由四個部分組成,包含上下文編碼器、知識編碼器、知識管理器和解碼器。上下文編碼器是將用戶當前語句和歷史對話信息作為輸入,記為I,輸出的為上下文向量,記為i。知識編碼器是與當前產生的所有對話產生的知識圖譜和產生的回復作為輸入,最終輸出結果為每一個知識的三元組向量和回復向量。知識管理器是以上下文編碼器和知識編碼器的輸出結果作為輸入,輸出經過大量篩選后的知識向量。同理,解碼器是以上下文編碼器和知識管理器的輸出結果作為輸入,最后生成回復。
3.3.2 基于注意力機制的后驗生成的模型
Bahdanau等人[26]在2014年在機器翻譯任務中引入注意力機制,大幅度地提升了機器翻譯的性能。于是后期研究人員將注意力機制廣泛應用于自然語言處理的各個領域。在基于序列到序列的生成任務中,可以根據當前解碼狀態去選擇最相關的原始端信息,來提升解碼效果,同時該方法也符合人類思考的思維習慣:關注重點信息,選擇性忽視不重要的信息。可以將注意力機制分為三個部分,分別為查詢語句q,鍵項k={k1,k2,…,kn},值項v={v1,v2,…,vn},注意力機制的計算公式如公式1~公式3所示。
ei=score(q,ki)
(1)
(2)
(3)
目前注意力機制采取的得分函數有若干種計算方式。Luong等[27]研究人員提出了三種注意力機制計算方法,如公式4所示。
(4)
其中,dot計算公式中要求有相同維度的q和ki,而general計算公式主要通過可變參數Wa使得q和ki的維度保持不同,concat的計算方式主要采用的是將q和ki拼接聯系起來,通過使用一個單層感知機和可變參數Va計算得出最后的分數。Vaswani等[28]研究人員提出一種新的計算手段-放縮點積,計算公式如公式5所示。
(5)

可以清楚地發現:基于后驗生成的模型和基于注意力機制的后驗生成的模型無明顯差別,其唯一存在的區別就是在解碼時加入注意力機制這一手段。使用解碼時上一時刻狀態st-1以及上下文編碼器中的hi使用注意力機制可以得到的結果為ct,然后根據ct以及知識管理器的輸出k和st-1,結果產生下一時刻的解碼狀態st,最后判斷當前時刻解碼狀態st以及上下文向量x輸出當前時刻解碼單詞,計算過程如公式6~公式10所示。
(6)
(7)
(8)
(9)
Yt=softmax(st,x)
(10)
3.4 層次上下文建模的后驗生成模型
3.4.1 基于層次上下文建模的后驗生成模型
上述討論的基于后驗生成基線模型中,將歷史對話上下文信息拼接成一句話,最后對拼接的句子建模。但是存在的問題是:上下文信息不可能是單獨的一句話,一般是由多句話組成。并且拼接的句子語句長度較長,這種建模方式會產生歷史上下文對話中最前面的幾句話被忽略,導致上下文信息缺失,向量信息不充分。為了解決此問題,研究人員采用了層次上下文建模方式。其主要原理為:先使用一個編碼器建模上下文中每一句話的信息,再使用另一個編碼器建模所有的句子信息,最后生成上下文信息。可以發現:基于層次上下文建模的后驗生成的模型和基于后驗生成的模型無明顯差別,各模塊基本相同,其唯一存在的區別就是編碼器不同。一個雙向的門控循環單元(Gate Recurrent Unit,GRU)和一個單向的GRU組合構成基于層次上下文建模的后驗生成的模型的編碼器。例如給定上下文X={u1,u2,…,un},其中ui表示上下文X中的第i句話;Ui={wi1,wi2,…,win},其中win表示Ui中的第j個詞。Utterance Encoder是一個雙向GRU,主要功能是將歷史對話上下文中每一句話{u1,u2,…,un}編碼形成句子向量{u1,u2,…,un}。Context Encoder是一個GRU,主要功能是將句子向量編碼成上下文向量x,計算步驟如公式11~公式12所示。
(11)
x=sn=GRU(un,sn-1)
(12)
3.4.2 融合層次上下文建模和注意力機制的后驗生成模型
在多輪對話系統中,解碼需要充分考慮上下文信息。即解碼每一個詞時,需要提前判斷歷史對話中哪些話需要考慮進來,并且是重要的。其次,需要充分考慮歷史對話中哪些詞對解碼的意義至關重要。融合層次上下文建模和注意力機制的后驗生成模型和基于層次上下文建模的后驗生成模型無明顯差別,其唯一存在的區別在于上下文編碼器和注意力使用機制有所不同。
上下文編碼器主要采用層次上下文方法進行建模,其模型結構和基于層次上下文建模的后驗生成模型的上下文編碼器大體相同。需要注意的是,模型中不僅將注意力機制用于Utterance Encoder的輸出,而且也將該技術運用于Context Encoder的輸出。Utterance Encoder的輸出表示為輸出每個詞的狀態,將其定義為詞級別的注意力機制(Word Attention)。Context Encoder的輸出表示為上下文中每句話的狀態,將其定義為句子級別的注意力機制(Sentence Attention)。在使用中需要注意詞級別的注意力機制和句子級別的注意力機制的相同之處以及不同之處,并做好區分。例如,給定上下文X={u1,u2,…,un},Utterance Encoder的功能是將歷史對話中每一句話Ui編碼生成詞向量Hi={hi1,hi2,…,hin}和對應句子向量ui,ui計算公式如公式11所示。Context Encoder的功能是將句子向量C={c1,c2,…,cn}編碼生成{s1,s2,…,sn}。在解碼時使用上一時刻狀態st-1并分別對所有的詞向量和句子向量使用注意力機制,最后得到的結果為ct,計算步驟如公式13~公式15所示。
ct1=Attention(st,H)
(13)
ct2=Attention(st,C)
(14)
ct=MLP([ct1;ct2])
(15)

3.5 基于TransD后驗生成模型
在基于知識圖譜的多輪對話中,需要將知識圖譜建模并且融入到多輪對話系統中。基于注意力機制的后驗生成的模型的主要原理為將歷史對話中與當前對話相關的知識三元組相互連接組成一句話,然后將連接后的知識圖譜使用雙向GRU進行建模。該建模方式存在的缺點為沒有充分利用實體間的關系,導致知識圖譜的建模信息不完整。為了解決該問題,研究人員引入知識表示學習,在知識圖譜量化時,也充分考慮了各個實體和關系之間的語義關系。
知識圖譜主要包含實體及其對應關系的圖結構網絡,圖中的每一條邊都表示為一個知識三元組,即頭實體、關系和尾實體。兩個實體之間通過特定的關系相連,每個實體可以和若干個實體相連,每個關系也可以出現在若干個不同的三元組中。Bordes等人[29]最早提出了TransE模型,其主要采用的方法是將實體和關系映射到向量空間。同時研究人員借鑒word2vec的平移不變性的特性,可以將知識圖譜中的關系看作是實體間的某種平移不變量。即針對一個已經建立好的知識圖譜三元組(h,r,t),其中h表示頭實體,r表示關系,(h,r,t)表示尾實體,TransE的作用原理主要是將每個三元組(h,r,t)映射到向量空間,使得h+r的值和t盡可能靠近,如圖2所示。
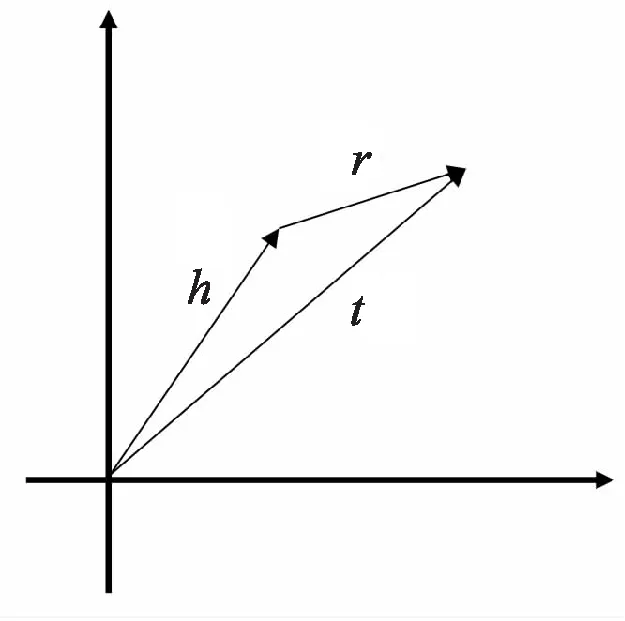
圖2 TransE模型
同時在TransE模型訓練過程中,可以構造出大量的負樣本,要求負樣本中的h'+r'和t'盡可能背離。具體損失函數公式如公式16所示:
(16)
TransE模型中參數較少,計算復雜程度低,可以很好解決一對一的問題,但是無法解決一對多和多對一的問題。為了解決該問題,Wang等人[30]提出TransH模型,TransH主要原理為針對每一組關系都定義一個超平面Wr和關系向量dr,主要采用的方法為將頭實體和尾實體通過超平面映射到關系平面上,這樣可以將關系平面中頭實體向量加關系向量接近于尾實體向量,如公式17所示。
(17)
TransH使得不同的實體在不同的關系中可以用不同的向量來表示,同時也可以使得不同的實體在同一關系中,使用關系向量的映射,得到不同的向量表示,如圖3所示。因此TransH相對于TransE,可以很好地解決一對多和多對一的情況。
TransE和TransH的應用場景均為假設實體和關系運用于同一向量空間中,但是實體和關系表示為不同的對象,可能運用于不同的向量空間中,這就會導致在不同的向量空間中無法表示的可能性。為了解決該問題,Lin等人[31]提出TransR模型。TransR主要原理為一個實體可以包含多種屬性,不同的關系需要考慮實體屬性也不同,因此不同的關系對應映射到不同的語義空間。在TransR模型中,實體和關系均有不同的向量維度,針對每一個關系都定義一個語義空間Mr,它采用的是將實體映射到關系空間。然后在關系空間內,使頭實體加關系盡可能接近尾實體,如公式18~公式19所示。
hr≡hMr,tr≡tMr
(18)
fr(h,t)≡hr+r-tr
(19)
在TransE、TransH和TransR模型中,都是假設每種模型中每種關系僅有一層含義,但是同一種關系可能存在多層含義。例如,relationship可以表示人和某個團體之間的關系,也可以表示人和某個國家之間的關系。在TransR模型(見圖4)中,針對同一個關系,頭實體和尾實體可共享同一投影矩陣,但頭實體和尾實體所包含的對應屬性可能存在明顯的差異。為了解決該問題,Ji等人[32]提出TransD模型,TransD主要原理基于動態矩陣生成,對應的生成映射矩陣由實體向量和關系向量兩部分組成。這樣生成的優勢為在同一種關系下在不同的頭實體和尾實體所對應的映射矩陣完全獨立且都不相同,如公式20~公式22所示。對于每一個三元組(h,r,t)都分別對應于兩個向量,即h,hp,r,rp,t,tp,一個可以用來表示它們的具體含義,另一個用于構造出相對應的映射矩陣,I表示單位矩陣。TransD模型中映射矩陣包含實體向量和關系向量,因此大幅度提高了TransD計算復雜度,并遠小于TransR。

圖4 TransR模型
(20)
h⊥=Mrhh,t⊥=Mrtt
(21)
fr(h,t)=h⊥-t⊥
(22)
與TransE、TransH和TransR相比,TransD(見圖5)計算復雜度小,模型優化效果明顯。基于TransD后驗生成模型與基于注意力機制的后驗生成模型相比,其主要區別在于知識編碼器不同以及編碼器數量有所不同。

圖5 TransD模型
使用TransD模型將所有的知識圖譜向量化,即針對每一個知識三元組Ki={hi,ri,ti},將頭實體向量hi、關系向量ri和尾實體向量ti進行相連,最后經過全連接層生成ki,其計算公式如公式23所示。
ki=FUN([hi,ri,ti])
(23)
4 數據集及評價指標
4.1 數據集介紹
DuConv數據集于2019年由Wu等人[33]在ACL2019[34]首次公開,主要涵蓋內容為基于知識圖譜的多輪對話數據集。Ubuntu數據集在2015年由Lowe等人首次公開,主要涵蓋內容為一個大規模開放域下對話生成的數據集,其廣泛用于對話生成任務中[35-36]。Cui等人[37]于ACL2020發表了多輪對話與推理的數據集MuTual, 針對性強地用于評價模型在多輪對話過程中的邏輯與推理能力。
4.2 評價標準
針對基于知識圖譜的多輪對話的實驗結果,研究者主要采用以下兩個客觀指標進行評價。
(1)平均對話輪數。對話輪數指的是從語句輸入到最終對話結束一共持續的對話輪數。當對話中出現類似于“嗯嗯”“好的”等這些人為實現定義的回復或者對話一直是重復的無效的,系統則默認對話過程已經結束。
(2)多樣性。采用統計方法模擬在對話過程中產生出來的各種互相不重疊關系的一元文法(unigram)和二元文法(bigram)之間所約占比例的百分比,以進一步反映對話結果產生的復雜性。一元文法與二元文法都是語言模型理論中重要的概念,這種指標通常可以用來判斷表示出其最終的輸出結果的語言模型豐富程度的程度。由于多輪對話回答問題的特殊性,其回答結果也不存在絕對唯一性,故也可以同時出現一個問題或出現多個回答。因此,傳統的BLUE等傳統評價方式也不適用于針對多輪值對話結果進行的評價。
5 結束語
對話系統是自然語言處理以及人工智能領域研究的一個重要領域,并且得到了廣泛的商用。基于知識圖譜的多輪對話技術是結合實體和實體間的關系,將知識三元組和原始對話上下文數據融合在一起,更好地實現多輪對話。研究人員多次運用并證明了將知識圖譜融入到多輪對話中對多輪對話技術的發展是有幫助的并且效果是非常顯著的。然而目前的研究進展存在諸多挑戰,例如針對開放域的信息抽取,主要包括實體抽取、關系抽取以及屬性抽取這三個問題。其中,多種語言文本信息、開放域下非結構化純文本信息抽取等問題是當前面臨的重要挑戰之一。知識圖譜的重要性不僅是一項技術,更加推動了自然語言處理和深度學習的發展。文章希望更多的研究者能夠參與并且投入到這份研究工作中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
