一個基于金融混合數據的智能問答模型
2023-04-29 00:44:03章皓洲胡兵馮端宇
四川大學學報(自然科學版) 2023年1期
章皓洲 胡兵 馮端宇


智能問答系統(Question Answering System, QAS)是一種讓人類通過自然語言與機器進行問答來獲取信息的人機交互系統,是自然語言處理的一個集綜合性與廣泛性于一體的應用.現有的智能問答系統模型研究主要考慮單一型數據.然而,現實生活中結合表格和文本的混合型數據十分普遍,如金融領域的財務報表.本文對已有的財務報表智能問答模型進行改進并提出了一個新模型,該模型有更好的效果.
自然語言處理; 智能問答; 混合數據
O241.82A2023.011004
收稿日期: 2022-04-15
基金項目: 國家重點研發計劃(2018YFC0830303)
作者簡介: 章皓洲(1996-), 男, 四川德陽人, 碩士研究生, 主要研究方向為計算金融學.
通訊作者: 胡兵.E-mail: hubingscu@scu.edu.cn
A question answering model based on hybrid data in finance domain
ZHANG Hao-Zhou,? HU Bing, FENG Duan-Yu
(School of Mathematics,? Sichuan University,? Chengdu 610064, China)
Question answering? system (QAS) allows humans to discass questions with machine through natural language and thus is? a comprehensive and extensive application of natural language processing.Many QAS are based on single-structured data and can not suitable for? the mixed data combining both table and text, such as the financial statements.This paper proposes a new QA model to deal with such question based on the mixed data in financial field automatically and improve the known models.
Natural language processing; Question answering; Mixed data
1 引 言
作為一種人工智能系統,智能問答系統(Qusetion Answering System, QAS)能接受并回答用戶的自然語言形式的提問.早在1961年,Green等[1]便提出了一個簡單的問答系統,主要用于回答用戶關于MLB賽事的相關問題,如比賽時間、地點和球隊名稱等.智能問答系統利用機器智能實現人機信息交互,并用自然語言給用戶提供答案.不同于搜索引擎僅僅返回用戶需求的相關信息片段,智能問答系統更加智能化.
近年來,隨著深度學習技術的進步[2-3],機器智能閱讀理解(Machine Reading Comprehension,MRC)技術也得到了極大發展[4],隨之智能問答模型的基本模式逐漸演化為當前的“檢索器-閱讀器”(retrieve-reader)結構.檢索器根據問題語句的語義檢索出相關文檔,閱讀器則從檢索出來的文檔中推理出最終答案.其中的閱讀器就依托于深度學習技術,通常是一個神經網絡MRC模型.
根據答案來源的信息源類型,現有的智能問答研究主要可分為文本智能問答[5](Textual QA,TQA)和知識庫智能問答[6](Knowledge Based QA, KB-QA)兩大方向.值得注意的是,現有的智能問答模型研究主要基于單一的數據形式,對包含非結構化文本、結構化知識庫或半結構化表格數據類型的研究還十分罕見.另一方面,現實生活中表格和文本結合的混合型數據十分普遍,如財務報表、科研論文、醫療報告等,尤其在金融領域中.因此,關于財務報表的智能問答對財務分析等工作很有幫助.
章皓洲, 等: 一個基于金融混合數據的智能問答模型
相較于傳統的智能問答系統,金融領域的智能問答系統的設計研究存在諸多挑戰.首先,金融財報中存在多種數據類型的處理問題,而不僅是單一形式的閱讀理解問題.在我們的數據集中,根據答案類型的不同可以分為四種類型的問題:單句、多句、計數和數學類型問題.單句類型的答案對應于連續的單個句段,多句類型的答案包含多個分散的句段,計數類型需要對取得的句段進行計數,數學類型問題答案則需要相關數字進行數理推理后得到.為了應對多類型的問題,我們從transformer模型[7]中獲得啟發,設計了一個多頭(muti-head)結構的模型,將不同的問題交給不同的頭去解決.其次,金融財報的問答中還存在許多需要數理推斷的數學問題,比如:
-Q:"What is the change in Other in 2019 from 2018?"
-A:"-12.6"
-derivation:"44.1-56.7".
這些問題需要利用表格或者文本中的相關數字(num1:44.1, num2:56.7),根據具體問題進行對應的數學推理(num1-num2)以后得到最終結果(-12.6).針對這一類問題,我們對模型結構進行改進和實驗,將一種基于目標導向機制的樹模型序列建模思路[8]應用在模型中,取得了不錯的效果.這部分問題解決效果的提升也成為整體效果提升的重要部分.
2 模型預處理
2.1 預訓練
由于要在自然語言上進行計算,我們需要獲得詞對應的可計算表示.一種樸素的想法是將詞進行one-hot編碼.由于編碼導致的正交性,這種思路并不能反映出詞之間的相互聯系,由此誕生了詞向量的預訓練類型的生成方式.
預訓練是一種遷移學習的方法,最早起源于word2vec模型[9],在自然語言處理領域是一種有效的方法.它基于語言模型將模型在大文本上進行大規模的預訓練,得到預訓練模型的參數估計,然后再在實際任務中進行微調手法以獲取詞的向量表示[10].
在transformer模型[7]中,作者使用了多頭注意力機制,利用向量內積模擬詞之間的相關性,取得了很好的效果.注意力機制主要將詞由相鄰詞匯進行表示:
attention(Q,K,V)=softmaxQKT dkV(1)
其中Q,K,V都是詞的向量表示;dk是向量的維度.注意力機制不僅加快了算法的速度,也提升了模型的效果,所以現有的預訓練模型基本都使用了注意力機制.
對于Bert模型[10],它不同于之前的語言模型,采用MLM進行模型訓練,在訓練過程中以15%的概率用特定的符號([MASK])在原數據的文本中進行替換.這種思想類似嶺回歸的懲罰項,使得模型在大語料庫中避免了過擬合.其次,Bert模型同時作用于NSP任務,在對應開頭位置的特殊標記位置做一個二分類的任務,先將一半數據順序打亂,模型需要預測出傳入的數據是否被打亂.
由于注意力機制使用內積運算,雖然加快了運算速率,但是因為語言是一種序列,具有先后順序,對于位置和順序敏感,所以Bert在做詞向量表示時還引入了位置嵌入(possiton embbeding)
PEpos,2i=sinpos100002i/dmodel
PEpos,2i+1=cospos100002i/dmodel(2)
利用正余弦函數性質,使得詞在不同位置和不同維度由不同的正弦余弦函數表示,如圖1所示.
Bert在大語料上進行訓練,然后在下游任務上進行微調.這種模式使得模型具有很強的泛化性,也彌補了下游任務數據不足的缺陷.后續也有越來越多的預訓練模型被提出,比如XLnet[11]和Roberta[12]等.
Roberta模型相較于Bert模型在預訓練階段使用更大量更豐富的數據作為訓練語料,同時增大模型參數的維度及每次訓練數據的批次.Bert模型基于mask的語言模型,在數據處理階段就對句子進行mask處理,由此導致模型每次都接受到的是同樣的mask位置的數據.Roberta模型改進了這一點,使用一種在輸入時不斷調整的動態mask方式.
實驗發現,更為魯棒的Roberta模型在我們的任務中表現更好,因而最終我們使用了Roberta模型作為我們的預訓練模型.
圖2 線性條件隨機場
Fig.2 Linear conditional random fields
2.2 序列模型
自然語言處理中的句子可以看作以詞為單位的序列.同樣,計算式(例如$44.1-56.7=-12.6$)也可以看作以數字和計算符號為單位的序列.隱馬爾科夫模型(Hidden Markov Model,HMM)是一種常見的序列模型,是條件隨機場(Conditional Random Fields, CRF)的一種特殊情形[13],如圖2所示.它滿足齊次馬爾科夫假設
Pit|it-1,ot-1,…,i1,o1=Pit|it-1(3)
這個假設表示t時刻的狀態只與t-1時刻的狀態有關.
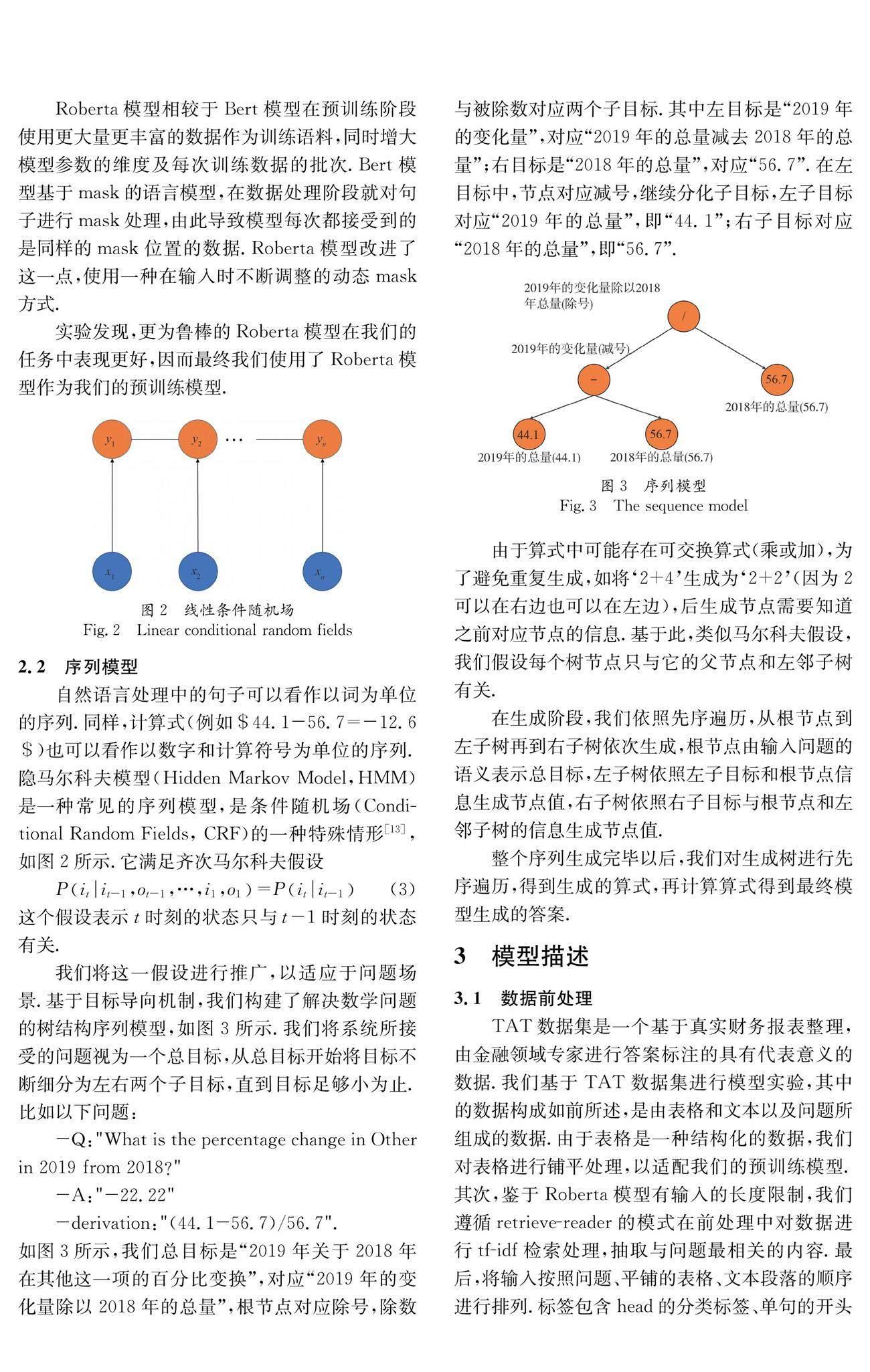
我們將這一假設進行推廣,以適應于問題場景.基于目標導向機制,我們構建了解決數學問題的樹結構序列模型,如圖3所示.我們將系統所接受的問題視為一個總目標,從總目標開始將目標不斷細分為左右兩個子目標,直到目標足夠小為止.比如以下問題:
-Q:"What is the percentage change in Other in 2019 from 2018?"
-A:"-22.22"
-derivation:"(44.1-56.7)/56.7".
如圖3所示,我們總目標是“2019年關于2018年在其他這一項的百分比變換”,對應“2019年的變化量除以2018年的總量”,根節點對應除號,除數與被除數對應兩個子目標.其中左目標是“2019年的變化量”,對應“2019年的總量減去2018年的總量”;右目標是“2018年的總量”,對應“56.7”.在左目標中,節點對應減號,繼續分化子目標,左子目標對應“2019年的總量”,即“44.1”;右子目標對應“2018年的總量”,即“56.7”.
由于算式中可能存在可交換算式(乘或加),為了避免重復生成,如將‘2+4生成為‘2+2(因為2可以在右邊也可以在左邊),后生成節點需要知道之前對應節點的信息.基于此,類似馬爾科夫假設,我們假設每個樹節點只與它的父節點和左鄰子樹有關.
在生成階段,我們依照先序遍歷,從根節點到左子樹再到右子樹依次生成,根節點由輸入問題的語義表示總目標,左子樹依照左子目標和根節點信息生成節點值,右子樹依照右子目標與根節點和左鄰子樹的信息生成節點值.
整個序列生成完畢以后,我們對生成樹進行先序遍歷,得到生成的算式,再計算算式得到最終模型生成的答案.
3 模型描述
3.1 數據前處理
TAT數據集是一個基于真實財務報表整理,由金融領域專家進行答案標注的具有代表意義的數據.我們基于TAT數據集進行模型實驗,其中的數據構成如前所述,是由表格和文本以及問題所組成的數據.由于表格是一種結構化的數據,我們對表格進行鋪平處理,以適配我們的預訓練模型.其次,鑒于Roberta模型有輸入的長度限制,我們遵循retrieve-reader的模式在前處理中對數據進行tf-idf檢索處理,抽取與問題最相關的內容.最后,將輸入按照問題、平鋪的表格、文本段落的順序進行排列.標簽包含head的分類標簽、單句的開頭結尾標簽,序列標注標簽,以及真實算式標簽和真實答案標簽.
3.2 模型結構
如圖4所示,我們的模型先將處理后數據經預訓練模型提取語義.由于Roberta預訓練模型的特殊設定,我們用[CLS]表示句首token對應的embedding向量.緊接著加入summary層對問題、表格、文本不同類型輸入提取對應的語義向量(與[CLS]維度相同),對應于hquestion,htable,hpara.對提取出的語義向量經過head predictor層預測出問題對應的類型
Phead=
softmaxFNNCLS,hquestion,htable,hpara (4)
其中FNN為單層前向神經網絡.對于每個數據,根據預測出的head類型進入到不同的頭中.
3.2.1 單句類型 單句類型Span Head對應答案為單個句段的問題.對于這類問題,我們在輸入序列上進行預測答案的開頭和結尾位置
Pbegint=σ(FNN(ht))(5)
pendt=σ(FNN(ht))(6)
其中ht表示對應token位置經過預訓練模型后的語義向量embedding.對于每個位置,我們計算對應的開頭結尾概率值,最終得到最大概率的開頭結尾位置.取出該位置的句段便得到模型的輸出.
3.2.2 多句類型和計數類型 多句類型Spans Head 和 計數類型Count Head 對序列進行標注,對于每個token位置,在標注空間{Cb,Ci,Co}中取值可以視作一個分類問題
Ptagt=σ(FNN(ht))(7)
其中ht表示對應token位置經過預訓練模型后的語義向量embedding.多句類型取出模型標注為相關的句段作為輸出,計算類型取出相關句段后再對句段進行計數得到最終的答案.
3.2.3 數學類型 數學類型Tree Head 用以解決數學類型問題.如2.2節所述,模型在每個樹節點位置預測對應的節點值.預測基于當前節點的目標向量,從目標空間Vtarget=Vop∪Vcon∪Vn (運算符,常數,文中的數)中計算不同結果的分數,取最大分數結果作為預測結果
scorei(ht,vi)=WTtanhFNNht,vi(8)
其中vi表示當前節點對應目標空間Vtarget第i個值時的目標向量,scorei對應目標空間Vtarget第i個值的分數.如2.2節所述,我們采用樹結構建模,根據先序遍歷順序生成整棵樹,最開始根據問題向量得到樹的根節點向量Vgoal,然后由根節點向量Vgoal生成左右兩個子目標[8]
o=σ(Wo[vgoal,vcontext,emb(y︿)])(9)
C=tanh(Wc[vgoal,vcontext,emb(y︿)])(10)
h=o⊙C(11)
g=σ(Wgh)(12)
Qe=tanh(Weh)(13)
vsubgoal=g⊙Qe(14)
其中vgoal表示根節點或根節點與左鄰節點的目標向量,vcontext表示節點相關文本的語義向量,通過3.3.2節的序列標注獲取再加權得到,emb(y︿)為當前節點值下的嵌入向量,表示對應預測符號的向量嵌入,Wo,Wc,Wg,We都是模型參數.
生成的vsubgoal作為左右子樹的目標向量,根據式(8)得到子樹的預測,若預測結果在空間Vop中且小于最大長度則繼續生成,否則停止.最后,依照先序遍歷得到序列結果,再進行計算得到最終答案.
4 數值模擬
我們在TAT數據上進行實驗,用EM和F1指標評估結果,再同其他模型效果進行比較,得到表1中的結果.可以看到,我們的新模型相比于目前表現最優模型仍有較好提升,雖然與人類專家的效果相比仍有距離,但表現出了不錯的潛力.
對不同的問題類型,我們得到表2[14](TAGOP模型)和表3.比較發現,通過對數學問題類型的樹結構建模的改進,在這類問題中我們的模型相較于TAGOP有不錯的提升.
由于計數類型數據量較少,模型在計數類型上表現不夠穩定.數學類型問題的效果提升明顯,但仍有進步空間.
5 結 論
本文提出了一個解決金融領域智能問答問題的模型.對于智能回答所面臨的多種類型數據處理問題,該模型基于Roberta預訓練與muti head機制,在不同head根據問題的類型使用不同的建模方式.即,對單句類型采用傳統的開始結束位置預測方式,對多句類型采用序列標注建模,對數學問題采用基于目標導向機制的樹建模.模型基于head predictor將問題進行分化處理,提高了模型的泛化能力.
對于數學問題的樹建模使得模型效果有較好提升,模型整體效果變好.目標導向機制對模型的提升也表明,對于復雜問題我們可以從人類思維模式中得到啟發.
參考文獻:
[1] Green B F, Wolf A K, Chomsky C L, et al. Baseball: an automatic question-answerer [C]// Proceedings of the Western Joint Computer Conference. New York: ACM, 1961.
[2] 孫存浩, 胡兵, 鄒雨軒. 指數趨勢預測的 bp-lstm模型[J]. 四川大學學報: 自然科學版, 2020, 57: 27.
[3] 晉儒龍, 卿粼波, 文虹茜. 基于注意力機制多尺度網絡的自然場景情緒識別[J]. 四川大學學報: 自然科學版, 2022, 59: 012003.
[4] Seo M, Kembhavi A, Farhadi A, et al. Bidirectional attention flow for machine comprehension [EB/OL].[2022-04-10].https://www.arxiv.org/abs/1611.01603.
[5] Hermann K M, Koisky T, Grefenstette E, et al. Teaching machines to read and comprehend [EB/OL].[2022-04-10].https://www.arxiv.org/abs/1506.03340.
[6] Talmor A, Berant J. The web as a knowledge-base for answering complex questions [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2018.
[7] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: Curran Associates Inc, 2017.
[8] Xie Z, Sun S. A goal-driven tree-structured neural model for math word problems [C]// Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19. Menlo Park: AAAI, 2019.
[9] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space [EB/OL].[2022-04-10].https://www.arxiv.org/abs/1301.3781.
[10] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg: ACL, 2019.
[11] Yang Z, Dai Z, Yang Y, et al. Xlnet: generalized autoregressive pre-training for language understanding [C]// Advances in Neural Information Processing Systems. New York: Curran Associates Inc, 2019.
[12] Liu Y, Ott M, Goyal N, et al. Roberta: a robustly optimized Bert pre-training approach [EB/OL]. [2022-04-10].https://www.arxiv.org/abs/1907.11692.
[13] Baum L E, Petrie T, Soules G, et al. A maximization technique occurring in the statistical analysis of probabilistic functions of Markov chains [J]. Ann Math Stat, 1970, 41: 164.
[14] Zhu F, Lei W, Huang Y, et al. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance [C]// Meeting of the Association for Computational Linguistics. Stroudsburg: ACL, 2021.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
光學精密工程(2016年6期)2016-11-07 09:07:19
