一種基于注意力嵌入對抗網絡的全色銳化方法
2023-04-29 00:44:03張攀李曉華周激流
四川大學學報(自然科學版) 2023年1期
張攀 李曉華 周激流


全色銳化旨在將低空間分辨率的多光譜圖像和高空間分辨率的全色圖像進行融合,生成一幅高空間分辨率的多光譜圖像.伴隨卷積神經網絡的發展,涌現出很多基于CNN的全色銳化方法.這些用于全色銳化的CNN模型大都未考慮不同通道特征和不同空間位置特征對最終銳化結果的影響.并且僅使用基于像素的1-范數或2-范數作為損失函數對銳化結果與參考圖像進行評估,易導致銳化結果過于平滑,空間細節缺失.為了解決上述問題,本文提出一種嵌入注意力機制,并輔以空間結構信息對抗損失的生成對抗網絡模型.該網絡模型由2個部分組成:一個生成器網絡模型和一個判別器網絡模型.嵌入通道注意力機制和空間注意力機制的生成器將低分辨多光譜圖像和全色圖像融合為高質量的高分辨多光譜圖像.判別器以patch-wise判別的方式對銳化結果與參考圖像的梯度進行一致性檢驗,以確保銳化結果的空間細節信息.最后,在3種典型數據集上的對比實驗驗證了所提出方法的有效性.
全色銳化; 深度學習; 注意力機制; 生成對抗網絡
TP751A2023.012001
收稿日期: 2022-03-04
作者簡介: 張攀(1997-), 男, 重慶人, 碩士研究生, 研究方向為遙感圖像處理.E-mail: zhangpan@stu.scu.edu.cn
通訊作者: 李曉華. E-mail: lxhw@scu.edu.cn
AESGGAN: an attention embedded adversarial network for pansharpening
ZHANG Pan, LI Xiao-Hua, ZHOU Ji-Liu
(College of Computer Science, Sichuan University, Chengdu 610065, China)
Pansharpening aims to fuse low-resolution multispectral image with high-resolution panchromatic image to generate a high-resolution multispectral image. With the development of Convolutional Neural Network (CNN), many CNN-based pansharpening methods have appeared and achieved promising performance. However, most of CNN-based pansharpening methods did not consider that the features in different channel dimensions and spatial dimensions have the different importance to generate a good result. In addition, only L1-norm or L2-norm is used as the loss function in the pixel domain to examine the distortion between the pansharpening results and the reference images, which usually cause the pansharpening results appear overly smooth and lack spatial detail information. In order to address the two problems, the authors proposed an attention embedded adversarial network with spatial structure information adversarial loss. This network consists of two parts: the generator and the discriminator. The channel attention and spatial attention embedded generator fuses low-resolution multispectral image and panchromatic image into a high quality high-resolution multispectral image. In order to ensure the spatial information of pansharpening results, the discriminator verifies the consistency of the gradient of pansharpening results and reference image by a patch-wise way. Finally, comparative experiments on three typical datasets verify the effectiveness of the proposed method.
Pansharpening; Deep learning; Attention mechanism; Generative adversarial networks
1 引 言
高分辨率多光譜圖像HRMS(High Resolution Multispectral)廣泛應用于軍事、農業、醫學研究等領域,并且例如Google Earth等商業產品對HRMS圖像的需求量也在持續增長.然而,由于受到衛星傳感器的物理限制,單一傳感器較難獲取兼顧空間分辨率和光譜分辨率的HRMS圖像[1].相應的,一般采用兩個傳感器分別獲取低空間分辨率的多光譜圖像LRMS(Low-Resolution Multispectral)和高空間分辨率的全色圖像PAN(Panchromatic),傳回地面后通過全色銳化方法將它們合成為HRMS圖像.張 攀, 等: 一種基于注意力嵌入對抗網絡的全色銳化方法
隨著卷積神經網絡(Convolutional Neural Network,CNN)在圖像領域的廣泛運用,其在遙感領域多個方向也有著許多實際應用,例如遙感圖像去噪[2]、高光譜圖像分類[3]以及全色銳化.目前全色銳化方法主要分為兩大類[4]:傳統方法和基于CNN的方法.其中傳統方法又可分為基于分量替換(Component Substitution,CS)和基于多分辨率分析(Multiresolution Analysis,MRA)兩大類.CS方法首先對上采樣的LRMS圖像進行某種變換,然后用PAN圖像對變換后的第一分量進行替換,最后通過逆變換得到HRMS圖像[5].根據所采用的變換,CS方法有IHS(Intensity-Hue-Saturation)[6]、PCA(principal Component Analysis)[7]和GS(Gram-Schmidt)[8]等.MRA方法的主要原理是通過多分辨率分析算法從PAN圖像中提取高頻空間信息,并將其注入到上采樣的LRMS圖像中.根據所采用的多分辨率分析方法,MRA方法有DWT(Decimated Wavelet Transform)[9]、ATWT(“à Trous”Wavelet Transform)[10]和LP(Laplacian Pyramid)[11]等.有研究表明[12],幾乎所有的傳統方法都可以用一個通用的細節注入模型來描述,即將PAN圖像中的空間細節信息注入到上采樣的LRMS圖像中得到HRMS圖像.總的來說,CS方法可以保留較多的空間信息,但是光譜失真一般較為嚴重[13],而MRA方法光譜失真較小,但是會面臨不同程度的空間信息丟失問題[14].
近年來,隨著深度學習在圖像領域的廣泛應用,陸續誕生了許多基于CNN的全色銳化方法[15-17].PNN[15]在基于超分辨率的三層CNN架構之上,首次將CNN用于全色銳化,通過將上采樣后的LRMS圖像與PAN圖像進行堆疊作為輸入,生成對應的HRMS圖像.因為利用了有監督的深度學習,PNN的各項指標都顯著優于傳統方法.Yang等[16]受到ResNet中跳躍連接(Skip Connection)和全色銳化先驗知識的啟發,提出基于殘差學習的全色銳化方法PanNet,該方法通過在全色銳化CNN模型中添加跳躍連接來模擬通用的細節注入模型,并且搭建較深的網絡來學習HRMS圖像和LRMS圖像的殘差,獲得了更優的銳化結果.Zhang等[18]認為,基于殘差學習的全色銳化方法學習到的殘差由大部分空間細節信息和少部分光譜信息組成,少部分的光譜信息會對空間信息的注入造成干擾,所以引入圖像的空間梯度來檢驗銳化結果與PAN圖像的空間信息一致性,從而提升合成圖像的空間質量.Liu等[17]首次提出基于生成對抗網絡的全色銳化方法PSGAN,采用一個雙分支結構生成器分別處理LRMS圖像和PAN圖像,再合并處理生成HRMS圖像,同時使用判別器使生成的HRMS圖像盡可能逼近真實的HRMS圖像.Zhang等[19]認為PSGAN架構較為簡單,并未使用全色銳化領域的先驗知識,所以提出一個基于空間特征變換和殘差學習的生成對抗網絡SFTGAN,相較于PSGAN,SFTGAN銳化結果在光譜和空間兩方面都得到了進一步的提升.
通過分析,我們發現目前用于全色銳化的CNN模型存在兩個不足.首先,這些模型只是簡單的將經卷積層處理得到的特征送入下一層,忽略了不同通道特征和不同空間位置特征對最終銳化結果的影響.其次,在訓練階段,只采用基于像素的1-范數或2-范數作為模型的損失函數來評估銳化結果與參考圖像的整體相似程度,這會導致銳化結果過于平滑,空間細節缺失[20].針對以上不足,本文提出一種基于注意力嵌入對抗網絡的全色銳化方法AESGGAN(Attention Embedded Spatial Gradient Generative Adversarial Network).一方面在生成器的設計中引入通道注意力機制和空間注意力機制[21],使生成器從通道和空間兩個維度對能生成更好銳化結果的關鍵特征給予更多的重視.另一方面,我們在損失函數中添加了空間結構信息的對抗損失,對融合結果的梯度進行patch-wise判別,以避免由1-范數損失函數帶來的高頻細節丟失問題.最后,在三種典型數據集上的大量客觀指標和主觀視覺評估表明,與一些典型的方法相比,本文提出的方法具有更好的性能表現.
2 相關背景
2.1 問題描述
全色銳化的目標是,以LRMS圖像M和PAN圖像P為輸入生成HRMS圖像H,期望生成的HRMS圖像同時具有與LRMS圖像相同的光譜分辨率和與PAN圖像相同的空間分辨率.現有的傳統方法[12]都可以用公式的細節注入模型表示.
Hb=M~b+gbD(1)
式中,b∈{1,…,B}表示第b個波段;M~表示r倍上采樣后的LRMS;r為PAN圖像和LRMS圖像的分辨率比;g=g1,…,gb,…,gB是注入增益向量;D是高頻細節.根據高頻細節的獲取方式不同,傳統方法可進一步分為基于CS的方法和基于MRA的方法.
隨著CNN在圖像領域的廣泛運用,陸續誕生了許多基于CNN的全色銳化方法[15-17].比如,PNN[15]直接將全色銳化看做一個盲盒,通過深度學習的方式獲得一個CNN銳化模型,模型以LRMS圖像和PAN圖像作為輸入,以銳化后的結果,即HRMS圖像,作為輸出,如下式所示.
H=Gθ(M,P)(2)
式中,Gθ表示全色銳化CNN模型;θ是模型的參數.
PanNet[16]通過引入跳躍連接來模擬公式描述的細節注入模型,此時深度學習的目標轉化為如式(3)所示的HRMS圖像與LRMS圖像之間的殘差學習.
H=M~+Dθ(M,P)(3)
式中,Dθ表示以LRMS圖像和PAN作為輸入,輸出殘差信息的子模型.
由于結合了傳統全色銳化方法的先驗知識,基于殘差學習的全色銳化CNN模型比基于普通CNN的全色銳化模型的整體銳化效果更好.
2.2 注意力機制
注意力機制是人類視覺系統的一個重要特性,人類的視覺系統可以從復雜的場景中快速且自然的識別出重要場景,并給予更多的注意力.在深度學習中實施注意力機制[22],可以實現與人類視覺系統類似的效果[23],即深度學習模型可以從大量的特征中抽取出更具代表性的特征,對能產生更好輸出的特征賦予更大的注意力權值,從而讓模型更加關注重要的特征,忽略不重要的特征,最終提高模型的性能.基于注意力機制的特征優化模式可用式(4)描述[21].
FA=M(F)F(4)
式中,F∈RC×H×W表示原始輸入特征;M表示以F作為輸入獲取注意力權值的模塊,注意力權值用注意力圖表示;表示element-wise乘法;FA∈RC×H×W表示利用注意力圖加權優化后的特征.
在CNN模型中,特征的具體表現一般為多通道的2D張量,因此注意力機制通常以通道注意力[24]和空間注意力[25]兩種方式來實現.其中,通道注意力依據視覺系統對不同通道的注意力差異,生成1D的注意力圖對原始特征在通道維度進行加權優化.類似的,空間注意力依據視覺系統對2D空間不同位置的注意力差異生成2D的注意力圖,對原始特征在2D空間進行加權優化.
在CNN模型中順序連接通道注意力模塊和空間注意力模塊,可以從通道域和空間域兩方面考慮視覺系統的注意力差異,從而提高模型的性能.并且由于通道注意力模塊和空間注意力模塊的輕量級架構,并不會帶來過多的資源開銷.
2.3 生成對抗網絡
GANs[26]的主要思想是運用對抗策略來訓練一個足以以假亂真的網絡模型.GANs通常由一個生成器G和一個判別器D組成,生成器以噪聲變量作為輸入,以生成樣本為輸出,其目標是生成判別器無法區分的樣本.判別器以生成樣本或真實樣本作為輸入,判定輸出該樣本為真實樣本的概率,其目標是區分生成樣本和真實樣本.它們的目標函數可以用公式表示.GANs的訓練一般通過生成器和判別器的迭代交互訓練完成.
minG maxDVGAN(G,D)=
Ex~Pr[logD(x)]+
Ex~~Pg[1-logD(x~)](5)
式中,pr表示真實樣本分布;pg表示生成樣本分布.盡管原始的GANs能夠在MNIST數據集上生成效果很好的手寫數字圖像,但是原始的GANs存在著兩個主要問題,一個是訓練不穩定,另一個是當GANs用于高分辨率圖像生成時生成圖像的質量不高.學者們在如何提升GANs訓練時的穩定性這一問題進行了更進一步的探索[27-29].Arjovsky等[28]依據Wasserstein距離提出WGAN,并重新設計了如下式所示的目標函數.
minGmaxDVWGAN(G,D)=
Ex~Pr[D(x)]-Ex~~Pg[D(x~)](6)
并且WGAN要求判別器的輸出值足夠平滑,為了達到這個要求,WGAN提出的策略是權重裁剪(Weight Clipping),即按照預先設置的權重范圍硬性的裁剪判別器的參數,從而限制判別器輸出值的范圍.雖然WGAN提高了GANs訓練時的穩定性,但是權重裁剪策略過于簡單,并且使用權重裁剪會面臨權重范圍難以選取的問題.Gulrajani等[29]在WGAN的基礎上提出WGAN-GP,采用梯度懲罰(Gradient Penalty)策略替換權重裁剪策略,實施方法是在判別器的目標函數中添加如下式所示的梯度懲罰項.
LGP=Ex^~Px^‖SymbolQC@x^D(x^)‖2-12(7)
其中,Px^表示符合式(8)的樣本分布;SymbolQC@x^Dx^表示判別器的梯度.
x^=ε·x+1-ε·x~,ε∈0,1(8)
采用梯度懲罰策略可以實現在提升模型訓練穩定性的同時簡化模型超參數的調整步驟.
此外,為了提高GANs生成圖像的質量,學者們進行了進一步的研究[30-32].Isola等[32]認為,對輸入圖像分區域判定能夠豐富生成圖像的細節信息,并據此對判別器進行改進,提出馬爾可夫判別器(PatchGAN),使判別器從只輸出一個判別值改為輸出一個空間尺寸為n×n的矩陣標簽X,X的元素Xi,j代表著馬爾可夫判別器對輸入圖像中相應區域patch的判定結果.由于馬爾可夫判別器是對輸入圖像不同局部區域進行判定,所以能提高生成圖像的局部保真度,即提高生成圖像的質量.
本文受PatchGAN的啟示,將馬爾可夫判別器應用于全色銳化中,以期提高銳化結果的質量.
3 方 法
3.1 網絡整體框架
全色銳化的目標是在保留LRMS圖像中光譜信息的同時盡可能融入PAN圖像中的空間細節信息.對于光譜信息的保留,目前基于CNN的全色銳化方法廣泛使用的策略是在CNN模型中添加跳躍連接,即通過深度學習獲取HRMS圖像和LRMS圖像的殘差信息,然后將上采樣的LRMS圖像與殘差信息相加獲得最終的HRMS圖像.這種基于殘差學習的方式可以較好的保留LRMS圖像中的光譜信息.然而,在空間細節信息的融入方面,仍然有較大的提升空間.在模型訓練中,現有基于CNN的方法通常以模型銳化結果與參考HRMS圖像的1-范數或2-范數作為損失函數.這種基于像素的損失函數注重的是生成圖像與參考圖像的整體相似性,容易導致生成圖像過于平滑,丟失高頻細節信息[20],例如道路和房屋的邊緣.此外,目前大部分基于CNN的全色銳化方法將所有的特征統一對待,使得模型不能高效的學習特征之間的聯系.
為了解決上述問題,本文以GANs為基礎框架,對生成器和判別器分別進行改進,以期銳化結果在保留光譜信息的同時融入盡可能多的空間細節信息.首先,我們在生成器的設計中引入注意力機制,使模型更加關注能產生更好銳化結果的重要特征.其次,本文在采用基于像素的損失函數基礎上,添加了空間結構的對抗損失,具體來說,使用馬爾可夫判別器對銳化結果和參考圖像的梯度進行patch-wise判定,使對抗訓練中的局部細節信息得到更多的重視,從而確保銳化結果的空間細節信息.圖 1給出了AESGGAN的整體框架,該框架主要由兩部分組成:基于注意力機制的生成器負責將LRMS圖像和PAN圖像融合為HRMS圖像;馬爾科夫判別器實現對梯度圖的patch-wise真偽判定.
3.1.1 基于注意力機制的生成器 首先,我們實施了一個單純的基于殘差學習的生成器.考慮到人眼視覺系統對細節信息常常具有更多的關注度,而且具有代表性的特征往往只出現在某些特征通道或某些局部空間位置,我們在單純基于殘差學習的生成器的部分卷積層之后引入通道注意力模塊和空間注意力模塊,對中間特征進行加權優化.此外,受到DenseNet[33]的啟發,我們向模型中添加多個跳躍連接,把從LRMS圖像和PAN圖像中提取到的低級特征多次注入模型,實現對特征的復用.
圖2給出了基于注意力機制的生成器G的網絡架構及空間注意力模塊SABlock和通道注意力模塊CABlock.通道注意力模塊的結構如圖 2d所示.通道注意力模塊接收尺寸為256×N×N的特征作為輸入,然后對輸入特征在空間域上分別求全局平均值和全局最大值,得到通道維度為256的空間平均特征和空間最大特征.接著將兩組特征輸入共享多層感知機(Shared MLP),輸出維度不變的兩組特征.值得說明的是,為減少參數量,共享感知機內部對特征的通道進行了的壓縮和擴充.在這之后,將經共享多層感知機處理后的兩組特征相加并輸入激活函數,得到大小為256×1×1的通道注意力圖.最后,利用通道注意力圖對輸入特征加權,得到在通道域優化后的特征并作為輸出.
空間注意力模塊的結構如圖 3b所示.空間注意力模塊接收尺寸同樣為256×N×N的特征作為輸入,不同的是,空間注意力模塊對輸入特征分別在通道域上求全局平均值和全局最大值,得到尺寸都為1×N×N的通道平均特征和通道最大特征.接著連接兩組特征得到尺寸為2×N×N的復合特征.再將復合特征依次輸入卷積層和激活層,可以得到尺寸為1×N×N的空間注意力圖.最后利用空間注意力圖對輸入特征加權,輸出在空間域優化后的特征.
3.1.2 馬爾可夫梯度判別器 AESGGAN包含兩個結構相同的馬爾可夫判別器,它們分別從水平和垂直方向對銳化結果的梯度和參考圖像的梯度進行patch-wise判定.圖 3展示了判別器的網絡框架.水平梯度判別器DX接收銳化結果或參考圖像的水平梯度,輸出對它們的判定結果.類似的,垂直梯度判別器DY接收銳化結果或參考圖像的垂直梯度,輸出對它們的判定結果.與傳統GANs的判別器僅判別整個輸入的真偽不同,馬爾可夫判別器接收空間尺寸為N×N的輸入,輸出patch-wise的真偽判定結果,即一個空間尺寸為n×n的矩陣標簽,其中n=N/8-2.矩陣元素Xi,j即是判別器對相應patch的判定值.通過patch-wise判別,可提高判別器對圖像局部空間細節的關注,從而促使生成器模型朝著豐富銳化結果的局部空間細節的方向學習.
3.2 損失函數
模型的訓練通過生成器和判別器的迭代交互訓練完成,即先固定判別器學習生成器,然后固定生成器學習判別器,一直重復,直到達到給定結束條件.生成器的損失函數包含1-范數損失項和空間結構信息對抗損失項.其中空間結構信息對抗損失項包含水平梯度判別損失和垂直梯度判別損失兩個子項.生成器的整體損失函數LG如下式.
其中,λ是超參數;LGPX和LGPY表示梯度懲罰項,梯度懲罰的具體計算見式(7)和式(8).
4 實驗及分析
4.1 實驗設置
為了驗證我們方法的有效性,我們在GaoFen-2,WorldView-2和QuickBird 3個數據集上,對7個典型傳統方法:Brovey[34]、SFIM[35]、IHS[6]、GFPCA[36]、GSA[37]、CNMF[38]和MTF_GLP_HPM[39],4個較先進的基于CNN的方法:PanNet[16]、SFTGAN[19]、GPPNN[40]和FGF-GAN[41],以及本文提出方法AESGGAN進行了對比實驗,并從客觀指標和主觀視覺兩方面對實驗結果進行了展示和分析.另外通過消融實驗對所提方法中的創新點進行了有效性驗證.
4.1.1 數據集 我們收集了GaoFen-2,WorldView-2,QuickBird衛星拍攝的原始LRMS圖像和PAN圖像.PAN圖像的空間分辨率分別為0.8、0.5和0.6 m,對應的LRMS圖像包含紅、綠、藍和近紅外4個波段,空間分辨率分別為3.2、2.0和2.4 m.
對于每個數據集,我們都獲得了11 000對尺寸分別為128×128的LRMS圖像塊和512×512的PAN圖像塊.首先,由于無法獲得真實的HRMS參考圖像,我們依據Walds Protocol[42]對LRMS圖像塊和PAN圖像塊進行了降分辨率和下采樣處理.得到的降分辨率LRMS圖像塊和PAN圖像塊用作模型的輸入,原始的LRMS圖像塊將作為銳化結果的參考HRMS圖像.然后,我們通過隨機劃分的方式將10 000對當作訓練集,剩余1000對當作測試集.數據集的詳細信息在表 1中展示.
4.1.2 評價指標 為了評估全色銳化結果,本文采用以下6個廣泛使用的評價指標:Spectral Angle Mapper(SAM)[43],Relative Dimensionless Global Error in Synthesis(ERGAS)[44],Spatial Correlation Coefficient(SCC)[45],Structural Similarity(SSIM)[46],Peak Signal to Noise Ratio(PSNR),Universal Image Quality Index(Q)[47].其中SAM和ERGAS是評價光譜失真的指標,值越小越好,理想值為0.SCC是評價空間相似度的指標,值越大越好,理想值為1.SSIM、PSNR和Q是綜合性指標,值越大越好.
4.1.3 實驗細節 我們在Ubuntu 20.04.1操作系統上使用PyTorch框架實現AESGGAN,并在Intel Xeon E5-2650 v4 CPU和Nvidia GeForce GTX 1080Ti GPU上運行.訓練AESGGAN時epoch設置為200,batch size為16.采用Adam優化器,初始學習率為1e-3,每20個epoch乘以0.5.損失函數中α=1,β=γ=1e-4,λ=100.訓練時對數據進行了歸一化處理.
4.2 實驗結果及分析
4.2.1 GaoFen-2上的實驗結果 在GaoFen-2測試集上,我們對上面提到的12種方法和本文提出的方法進行了測試,表 2給出了實驗結果.可以看出,基于CNN的方法普遍優于傳統方法,他們的SAM、ERGAS、SSIM和PSNR等4項指標明顯好于傳統的全色銳化方法,尤其是表示光譜失真的SAM指標,其中我們提出的AESGGAN的SAM指標比傳統全色銳化方法平均提升了60%.這一方面得益于深度學習的先進理論,另一方面是因為基于CNN的方法是一種有監督學習方法.本文提出的方法和現有的較先進的深度學習方法PanNet、SFTGAN和GPPNN相比,各項指標都達到最優,相較于次優的GPPNN,提出方法的SAM指標提升21%,ERGAS指標則提升16%.
圖4以GaoFen-2數據集中一個圖像塊為例,展示了各種方法的全色銳化視覺效果.由圖 4可以發現,相較于參考圖像,Brovey、IHS、GFPCA、CNMF、MTF_GLP_HPM的銳化結果有較明顯的光譜失真.而在空間細節信息保留方面,除了AESSGAN,所有的全色銳化方法都存在明顯的空間細節丟失,具體表現在圖像框選區域草地上的土路模糊,幾乎無法辨別.相較之下,提出的AESGGAN方法對框選區域的空間細節信息還原最為準確.整體比較發現,在GaoFen-2數據集下,所有參與比較的全色銳化方法中,AESGGAN可以在保證LRMS圖像的光譜信息準確性下,最大程度保留PAN圖像中的空間細節信息.
4.2.2 WorldView-2上的實驗結果 表3展示了WorldView-2測試集上12種方法的評價指標.可以發現,在光譜信息和空間信息保留方面,和在GaoFen-2數據集一樣,基于CNN的方法都優于傳統方法的評價指標,并且GPPNN在WorldView-2上的表現最優,提出的AESGGAN總體與之持平.
圖 5以一幅WorldView-2圖像為例,展示了不同方法的銳化結果.從圖5可以發現,傳統方法獲得的銳化結果在空間細節較為復雜的地方,會存在較嚴重的空間信息丟失現象,如框選區域中的足球場標線,并且SFIM、IHS、GSA、CNMF和MTF_GLP_HPM獲得的銳化結果還會出現較明顯的光譜失真.相比之下,基于CNN方法獲得的銳化結果,光譜失真和空間信息丟失都較小.值得注意的是,雖然GPPNN銳化結果中的“足球場標線”很清晰,但是其整體顏色偏深,存在較為明顯的光譜失真.總的來說,AESGGAN獲得的銳化結果,不論是光譜信息還是和空間信息,都與參考圖像最相似.
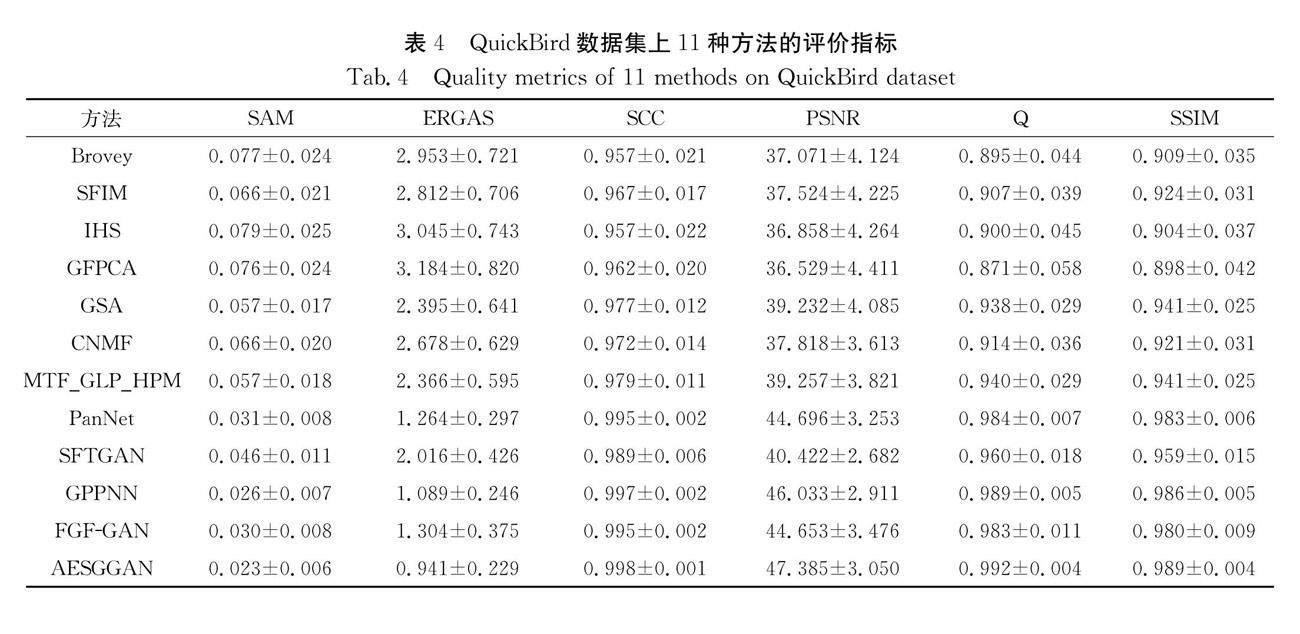
4.2.3 QuickBird上的實驗結果 表4展示了12種方法在QuickBird測試集上的評價指標.表 4表明AESGGAN在所有指標中均能達到最優,尤其是SAM、ERGAS和PSNR指標.相較于傳統方法,AESGGAN的SAM指標平均提升66%,ERGAS指標平均提升60%,PSNR平均提升25%.相較于基于CNN的方法,AESGGAN的SAM指標平均提升33%,ERGAS指標平均提升35%,PSNR指標提升8%.圖6以一張QuickBird圖像為例,展示了不同方法的降銳化結果.從框選區域以及圖像右下部分可以發現,所有傳統方法的銳化結果都存在嚴重的空間信息丟失問題.基于CNN的方法中,PanNet、SFTGAN和GPPNN的銳化結果在圖像右下部分也有較為明顯的空間信息丟失,FGF-GAN雖然空間信息保留較為完整,但是存在較為明顯的光譜失真現象,表現為顏色偏深.相對而言,在QuickBird數據集下,AESGGAN仍然可以保留最多的光譜信息和空間信息.
4.3 消融實驗
為了檢驗通道注意力模塊、空間注意力模塊和空間結構信息判別模塊的有效性,這里以GaoFen-2數據集為例進行消融實驗.具體來說,按照是否包含通道注意力模塊(CA)、空間注意力模塊(SA)和空間結構信息判別模塊(D)構建了如表 5所示的6個模型,不同的模型對應不同的添加模塊.然后用這些模型進行測試并與提出的AESGGAN進行對比.
表6展示了在GaoFen-2數據集上6個模型的降測試結果,圖 7以一個圖像塊為例展示了各模型的視覺效果.
綜合表 6和圖 7可以發現,僅添加空間結構判別模塊的模型,光譜信息保留和空間信息保留能力相較于模型M提升較小.而兩種注意力模塊的嵌入都可以提升銳化效果,相對而言,通道注意力模塊對銳化效果的提升要高于注意力模塊對銳化效果的提升.我們認為,通道注意力模塊比空間注意力模塊的效果更好的原因在于,在生成器中,通道注意力模塊提取的是不同通道特征對最終銳化結果的重要性,在CNN中每個通道都對應原始輸入的一種濾波結果,即常常代表一種具有共性的特征,所以在面對具體的測試樣本時,不僅能關注當前樣本的特點,還能加強共性的特征.而空間注意力模塊提取的是不同空間位置的特征對最終銳化結果的重要性,因為樣本的多樣化,使得不同空間位置的特征個性化較強,因此在測試階段僅能獲取當前樣本的特點.在此基礎上,同時添加通道注意力、空間注意力和空間結構信息判別模塊能夠取得整體最好的全色銳化效果.
5 結 論
本文提出了一種基于注意力機制和空間結構信息判定的多光譜全色銳化對抗網絡AESGGAN,一方面通過在生成器中嵌入通道注意力和空間注意力來提高對能生成更好銳化結果的重要特性的提取能力,另一方面在水平和垂直方向對銳化結果和參考圖像的梯進行patch-wise判別,以保證銳化結果和參考圖像的空間結構信息一致性.三種典型數據集上的對比實驗表明,AESGGAN的銳化效果優于參與比較的所有傳統方法和目前較為先進的深度學習算法.
由于真實的HRMS圖像無法獲得,幾乎所有基于CNN的有監督全色銳化方法都是通過對原始圖像進行降分辨率處理得到有監督學習的訓練集.雖然這種方法在降分辨率的測試中能夠取的很好的效果,但是降辨率圖像和原始分辨率圖像的分布存在差異,在降分辨率下訓練得到的模型在原始分辨率輸入下不一定能取得同樣好的效果.因此,下一步工作我們擬對通過降分辨率數據集下訓練好的全色銳化模型在原始分辨率的數據集下進行無監督的遷移學習,使它更符合原始分辨率下真實HRMS圖像的分布.
參考文獻:
[1] Ye F, Guo Y, Zhuang P. Pan-sharpening via a gradient-based deep network prior [J]. Signal Process: Image, 2019, 74: 322.
[2] 張意, 闞子文, 邵志敏, 等. 基于注意力機制和感知損失的遙感圖像去噪[J]. 四川大學學報:自然科學版, 2021, 58: 042001.
[3] 池濤, 王洋, 陳明. 多層局部感知卷積神經網絡的高光譜圖像分類[J]. 四川大學學報:自然科學版, 2020, 57: 103.
[4] Ghassemian H. A review of remote sensing image fusion methods [J]. Inform? Fusion, 2016, 32: 75.
[5] Zhang L, Shen H, Gong W, et al. Adjustable model-based fusion method for multispectral and panchromatic images [J].IEEE T Syst Man Cybern: B, 2012, 42: 1693.
[6] Haydn R. Application of the IHS color transform to the processing of multisensor data and image enhancement[C]//Proceedings of the International Symposium on Remote Sensing of Arid and Semi-Arid Lands. Egypt: Environ Res Inst of Mich, 1982.
[7] Kwarteng P, Chavez A. Extracting spectral contrast in landsat thematic mapper image data using selective principal component analysis [J]. Photogramm Eng Remote Sens, 1989, 55: 339.
[8] Laben C A, Brower B V. Process for enhancing the spatial resolution of multispectral imagery using pan-sharpening:US06011875A [P]. 2000-01-04.
[9] Mallat S G. A theory for multiresolution signal decomposition: the wavelet representation [J]. IEEE T? Pattern Anal, 1989, 11: 674.
[10] Shensa M J. The discrete wavelet transform: wedding the a trous and Mallat algorithms [J]. IEEE T Signal Process, 1992, 40: 2464.
[11] Burt P J, Adelson E H. The laplacian pyramid as a compact image code [M]//Readings in computer vision. San Francisco: Morgan Kaufmann, 1987.
[12] Vivone G, Alparone L, Chanussot J, et al. A critical comparison among pansharpening algorithms [J]. IEEE T? Geosci Remote Sens, 2014, 53: 2565.
[13] Zhou X, Liu J, Liu S, et al. A GIHS-based spectral preservation fusion method for remote sensing images using edge restored spectral modulation [J]. ISPRSJ Photogramm, 2014, 88: 16.
[14] Aiazzi B , Alparone L , Baronti S, et al. 25 years of pansharpening: a critical review and new developments [M]//Signal and Image Processing for Remote Sensing. Boca Raton: CRC Press, 2012.
[15] Masi G, Cozzolino D, Verdoliva L, et al. Pansharpening by convolutional neural networks [J]. Remote Sens, 2016, 8: 594.
[16] Yang J, Fu X, Hu Y, et al. PanNet: a deep network architecture for pan-sharpening [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017.
[17] Liu Q, Zhou H, Xu Q, et al. PSGAN: a generative adversarial network for remote sensing image pan-sharpening [J]. IEEE T Geosci Remote S, 2020, 59: 10227.
[18] Zhang H, Ma J. GTP-PNet: a residual learning network based on gradient transformation prior for pansharpening [J]. ISPRS J Photogramm, 2021, 172: 223.
[19] Zhang Y, Li X, Zhou J. SFTGAN: a generative adversarial network for pan-sharpening equipped with spatial feature transform layers [J]. J? Appl Remote Sens, 2019, 13: 026507.
[20] Ledig C, Theis L, Huszár F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE, 2017.
[21] Woo S, Park J, Lee J Y, et al. Cbam: convolutional block attention module[C]//Proceedings of the European conference on computer vision (ECCV). Munich: Springer, 2018.
[22] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[C]// International Conference of Legal Regulators. San Diego: arXiv, 2015.
[23] Guo M H, Xu T X, Liu J J, et al. Attention mechanisms in computer vision: a survey[J]. Comput Visual Media, 2022, 8: 331.
[24] Hu J, Shen L, Sun G. Squeeze-and-excitation networks [C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Salt Lake City: IEEE, 2018.
[25] Mnih V, Heess N, Graves A. Recurrent models of visual attention[C]// Proceedings of the Advances in Neural Information Processing Systems(NIPS). Montreal: MIT Press, 2014.
[26] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets [C]. Advances in Neural Information Processing Systems(NIPS). Montreal: MIT Press, 2014.
[27] Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks [C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017.
[28] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks [C]//Proceedings of the International Conference on Machine Learning. Sydney: International Machine Learning Society, 2017.
[29] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans [C]//Advances in Neural Information Processing Systems(NIPS). Long Beach: MIT Press, 2017.
[30] Gregor K, Danihelka I, Graves A, et al. Draw: a recurrent neural network for image generation [C]//Proceedings of the International Conference on Machine Learning. Lille: International Machine Learning Society.[S.l.:S.n.], 2015.
[31] Dosovitskiy A, Brox T. Generating images with perceptual similarity metrics based on deep networks[C]//Advances in Neural Information Processing Systems(NIPS). Barcelona: MIT Press, 2016.
[32] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017.
[33] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017.
[34] Gillespie A R, Kahle A B, Walker R E. Color enhancement of highly correlated images. II. Channel ratio and “chromaticity” transformation techniques[J]. Remote Sens Environ, 1987, 22: 343.
[35] Liu J G. Smoothing filter-based intensity modulation: a spectral preserve image fusion technique for improving spatial details [J]. Int J Remote Sens, 2000, 21: 3461.
[36] Liao W, Huang X, Van Coillie F, et al. Two-stage fusion of thermal hyperspectral and visible RGB image by PCA and guided filter [C]//Proceedings of the 2015 7th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS). [S.l.]: IEEE, 2015.
[37] Aiazzi B, Baronti S, Selva M. Improving component substitution pansharpening through multivariate regression of MS + Pan data [J]. IEEE T Geosci Remote Sens, 2007, 45: 3230.
[38] Yokoya N, Yairi T, Iwasaki A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion[J]. IEEE T Geosci Remote Sens, 2011, 50: 528.
[39] Aiazzi B, Alparone L, Baronti S, et al. MTF-tailored multiscale fusion of high-resolution MS and Pan imagery [J]. Photogramm Eng Rem S, 2006, 72: 591.
[40] Xu S, Zhang J, Zhao Z, et al. Deep gradient projection networks for pansharpening [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]: IEEE, 2021.
[41] Zhao Z, Zhang J, Xu S, et al. FGF-GAN: a lightweight generative adversarial network for pansharpening via fast guided filter [C]//Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME). [S. l.]: IEEE, 2021.
[42] Wald L, Ranchin T, Mangolini M. Fusion of satellite images of different spatial resolutions: assessing the quality of resulting images [J]. Photogramm Eng Rem S, 1997, 63: 691.
[43] Yuhas R H, Goetz A F H, Boardman J W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm[C]// Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop. Pasadena: AVIRIS Workshop, 1992.
[44] Wald L. Data fusion: definitions and architectures: fusion of images of different spatial resolutions [M]. Paris: Presses des MINES, 2002.
[45] Zhou J, Civco D L, Silander J A. A wavelet transform method to merge Landsat TM and SPOT panchromatic data [J]. Int J Remote Sens, 1998, 19: 743.
[46] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEET Image Process, 2004, 13: 600.
[47] Wang Z, Bovik A C. A universal image quality index [J]. IEEE Signal Proc Let, 2002, 9: 81.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
