基于聯邦遷移學習的應用系統日志異常檢測研究
2023-04-29 23:35:58曾閩川方勇許益家
四川大學學報(自然科學版) 2023年3期
曾閩川 方勇 許益家
迄今為止,基于日志的異常檢測研究已經取得了很多進展,然而,在現實條件下仍舊存在兩個挑戰:(1) 是日志數據通常以“數據孤島”形式儲存在不同的服務器上,單一公司或組織的日志數據中異常樣本量不足,且異常模式較為固定,很難通過這些數據訓練出一個準確率高的檢測模型. 為了解決這個問題,將不同來源的日志數據整合成更大的數據集可以提高模型訓練的效果但可能會在數據傳輸過程中產生日志數據泄露問題;(2) 是不同應用系統類型的日志數據通常在結構和語法上存在差異,簡單地整合并用于訓練模型效果不佳. 基于以上原因,本文提出一種基于聯邦遷移學習的日志異常檢測模型訓練框架LogFTL,該框架利用基于匹配平均的聯邦學習算法,在保證客戶端數據隱私安全的前提下于服務器聚合客戶端的模型參數形成全局模型,再將全局模型分發給客戶端并基于客戶端的本地數據進行遷移學習,優化客戶端本地模型針對自身常見異常行為的檢測能力. 經過實驗表明,本文提出的LogFTL框架在聯邦學習場景下效果超過了傳統的日志異常檢測方法,同時也證明了該框架中遷移學習的效果.
日志異常檢測; 聯邦學習; 遷移學習; LSTM;? 數據孤島
TP391.1A2023.033002
收稿日期: 2023-01-04
基金項目: 國家自然科學基金(U20B2045)
作者簡介: 曾閩川(1998-), 男, 四川樂山人, 碩士研究生, 研究方向為網絡信息對抗.E-mail: 2422342691@qq.com
通訊作者: 許益家.E-mail: xuyijia@stu.scu.edu.cn
Research on application system log anomaly detection based on federated transfer learning
ZENG Min-Chuan, FANG Yong, XU Yi-Jia
(School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China)
Significant progress has been made in the research of log anomaly detection. However, two challenges still exist in reality. Firstly, log data is often stored on different servers, creating "data islands", the number of abnormal samples in the log data of a single company or organization is insufficient and the abnormal patterns are relatively limited,? it is a challenge to train a detection model with high accuracy through these data. Integrating log data from different sources can improve the model's performance but may result in log data leakage during transmission; Secondly,the log data of different application system types varies in log structure and syntax, and simple integration for training models is ineffective. To address these issues, this paper proposes a log anomaly detection training framework called? LogFTL based on federated transfer learning, which uses federated learning algorithm based on matching average. On the premise of ensuring the privacy and security of the client's data, LogFTL aggregates the model parameters of the client on the server side to form a global model which is then distributed? to the client side.? Using the client's local data, the LogFTL framework migrates and learns to optimize the clients local model and? the detection effect of local log data is improved.The experiment resluts show that the LogFTL framework proposed in this paper outperforms traditional log anomaly detection methods in federated learning scenarios, and demonstrate the? transfer learning effectiveness of LogFTL.
Log anomaly detection; Federal learning; Transfer learning; LSTM; Data islands
1 引 言
隨著云計算產業的蓬勃發展,眾多應用系統、業務系統依托分布式服務器構建計算集群,導致服務器數量快速增長,同時對服務器的穩定性和可靠性有較高的要求. 系統出現異常可能引發程度較為嚴重的后果,導致直接或間接損失[1]. 如果能夠及時、準確地對系統產生的異常進行檢測,能夠幫助提高運維人員的響應速度,增加解決異常的應急時間,提高各類應用系統的穩定性.
運行日志記錄著應用系統中不同級別的運行信息,是判斷軟件系統運行狀態的重要數據. 通過分析日志數據能夠檢測出應用系統異常并定位問題產生原因[2-5]. 現有的基于日志的應用系統異常檢測存在兩個挑戰:(1)日志數據以“數據孤島”形式存在于不同服務器中且同一應用系統日志數據中的異常模式較為固定. 在實際環境中,不同的組織、機構各自擁有大量的日志,但日志數據中往往包含眾多敏感數據,直接共享這些數據可能會產生隱私泄露問題,因此形成了“數據孤島”問題. 并且日志數據作為運行信息的記錄,正常樣本數量占比遠大于異常樣本數量,這些日志數據中只有一小部分包含有價值的信息. 同時,單一應用系統由于其執行的業務和功能可能觸發的異常行為模型較為固定,通過單一來源的日志數據訓練出來的模型只能學習到一部分異常行為模型.(2)不同類型的日志在結構和語法上存在差異. 例如常見的基于Hadoop的分布式文件系統就存在多種類型的日志結構和語法[5]. 針對每一種日志類型訓練一個檢測模型成本高昂,且對于數據較少的日志類型效果不佳.
針對以上問題,本文設計實現了一種基于聯邦遷移學習的應用系統日志異常檢測框架(Log Anomaly Detection based on Federated Transfer Learning,LogFTL). LogFTL通過基于匹配平均的聯邦學習將不同參與者的本地模型進行聚合以建立檢測能力更加全面的全局模型[7],同時能夠更好地保護用戶的隱私,打消參與機構將自己數據分享給別人會產生隱私泄露問題的顧慮. 然后利用遷移學習方法來實現不同類型應用系統日志數據之間的知識遷移,降低日志結構和語法對模型訓練效果的影響,既能讓本地模型擁有不同類型應用系統日志類型的檢測能力又能提高本地模型對本地日志數據識別的準確度. 本文的主要貢獻如下:(1) 提出并設計了一個基于聯邦遷移學習的應用系統日志異常檢測框架LogFTL,該框架利用了基于匹配平均的聯邦學習方法和基于長短期記憶網絡(Long Short-Term Memory, LSTM)的遷移學習方法,用于解決現實環境中日志數據量不足且不同類型應用系統日志數據結構和語法存在差異的問題;(2) 提出了一種基于長短期記憶網絡的遷移學習方法,能夠基于LSTM模型實現聯邦學習條件下的遷移學習,既能讓本地模型擁有不同類型應用系統日志的檢測能力又能保證本地模型對于本地應用系統日志異常行為的檢測能力; (3) 使用真實的日志數據集對LogFTL進行了充分的評估實驗,實驗結果表明,本文提出的方法在克服“數據孤島”問題后檢測效果優于現有的日志異常檢測方法.
2 相關工作
日志作為系統正常運行狀態的記錄,每一條數據都承載系統的運行信息. 通常而言,日志根據事件類型使用不同的文本用以描述事件,同時根據具體的運行狀態動態生成參數,直觀的如時間. 通過分析日志數據,我們可以知道一個系統的運行是否正常,如果不正常也能通過日志數據定位到問題產生的原因和位置. 但是為了節省服務器存儲空間,提高系統運行效率,大部分應用系統很少以結構化的方式對日志數據進行處理,這提高了研究人員分析日志的難度. 因此當前主流的日志異常檢測方法都需要首先對日志進行解析后再訓練異常檢測模型[8].
日志解析是將日志進行結構化,抽取出日志中的文本信息和參數信息. 一開始,日志事件提取通過正則表達式來提取[9]. 然而這種方式對于正則表達式的設計要求很高,并且十分耗時. 現階段日志解析最常用的方法是日志模板生成. 本文應用Drain這一工具對日志數據進行初步解析[10]. Drain基于一個固定深度的樹,使用節點集合設計的規則來解析日志,是目前性能較好的日志解析方法.
基于日志的異常檢測算法可以分為有監督學習方法和無監督學習方法[11]. 有監督學習包括邏輯回歸、決策樹[12]和SVM[13]. 雖然有監督學習可以在異常檢測中獲得很高的性能,但是它需要大量帶有標簽的訓練數據,在隱私安全的前提下難以獲得足夠的數據進行訓練,也不能同時針對多種應用系統類型日志.典型的無監督學習方法有PCA[3]、LogCluster[14]和DeepLog[4]. PCA基于主成分分析的多元時間序列的降維方法依據累積貢獻率選擇主成分序列;LogCluster通過線性模式對日志異常進行聚類;DeepLog從正常執行中自動學習日志模式,檢測時如果日志模式與正常執行中學習到的模式存在偏離,則報告異常. 實際上,無監督的方法在標記的訓練數據不完全可用的情況下是比較實用的,但它們中大多數的檢測精度較低. 隨著自然語言處理的快速發展,許多基于自然語言處理的方法被提出. 例如LogRobust利用注意力機制的雙向長短期記憶神經網絡來識別異常日志[15]. LogAnomaly根據事件的順序和數量信息發現異常日志[16].
隨著各方對“數據孤島”現象和隱私安全問題愈發重視,基于聯邦學習的日志異常檢測算法也隨之出現. 聯邦學習最早是由谷歌提出來的一種模型訓練框架[17]. 它提出的目的是要解決分布式數據的敏感信息泄露問題,能夠在每個全局迭代中聚合來自各個參與者的本地模型以更新全局模型.FLOGCNN方法設計了一個輕量級的卷積神經網絡在聯邦學習場景下對日志異常行為進行檢測[18].
而LogTransfer則通過遷移學習將源系統的日志數據知識遷移到目標系統的日志檢測模型提高目標系統的檢測能力,但是它只提高目標系統的檢測能力,無法讓所有參與者受益[6].
3 研究方法
3.1 方法概述
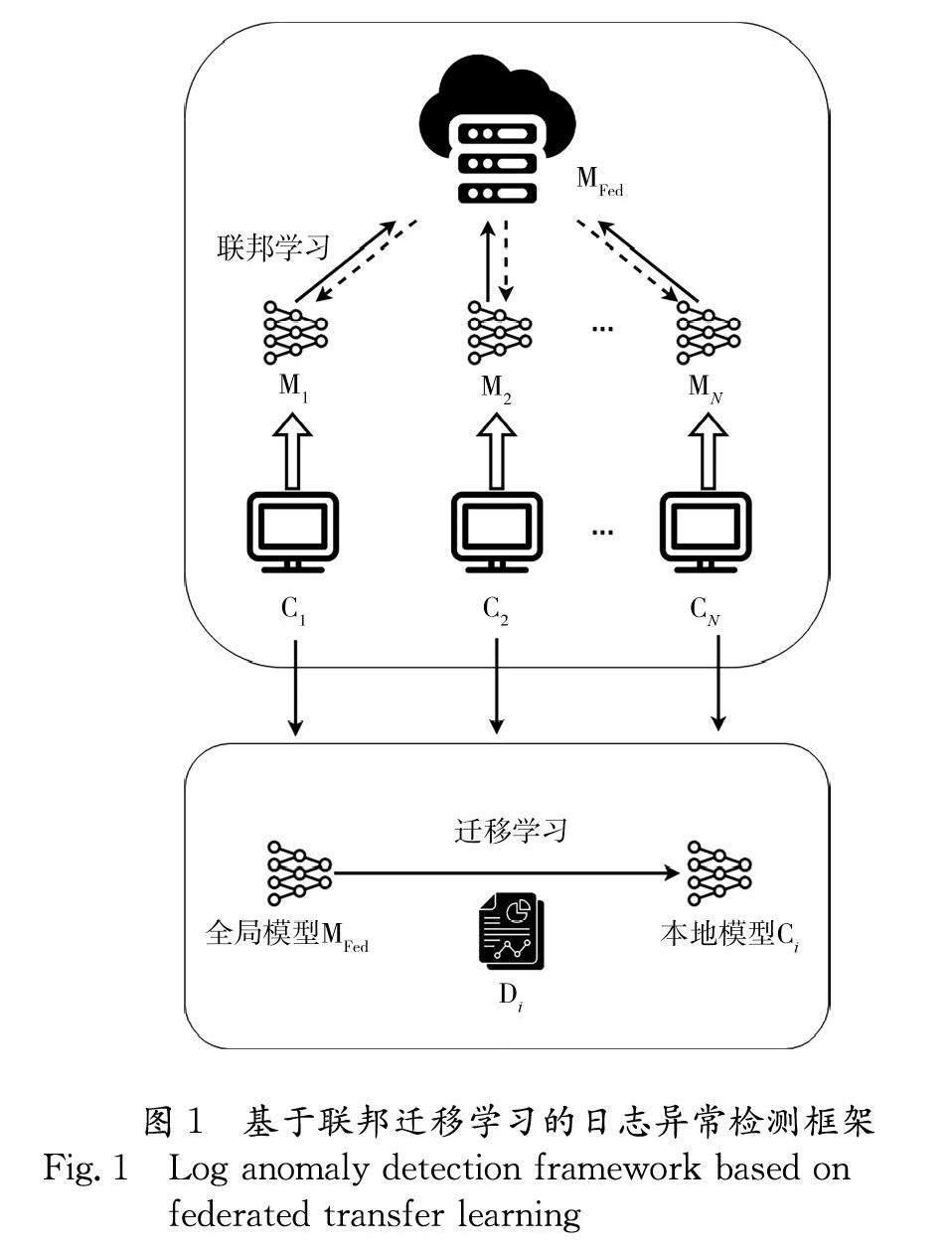
LogFTL的目標是在保障隱私安全的前提下,通過聯邦遷移學習將“數據孤島”場景下的日志數據進行聚合并且實現不同類型應用系統日志數據的知識遷移. LogFTL的架構如圖1所示. 我們假設有N個參與者愿意參與目標模型的訓練,并有一個服務器S負責聚合全局模型,使用{C1,C2,C3,…,CN}來表示參與者,使用{D1,D2,D3,…,DN}表示他們提供的數據. 我們要利用這些分布在不同組織中的數據訓練出各自的本地模型{M1,M2,M3,…,MN},并將這些本地模型的參數上傳到服務器S聚合成全局模型MFED,其中任何用戶Ci不將其數據Di暴露給其他參與者和服務端S. 整個方法包含以下4個步驟.
(1) 日志數據表征構建. LogFTL將所有參與者的日志數據通過Drain進行日志解析,提取日志模板,并且將日志樣本與模板進行匹配后進行標識. 在對日志進行解析后,一條日志樣本被表述為由多條日志數據組成的日志序列,其中每條日志數據有其對應模板的標識. 為了捕捉日志的語義信息,我們利用通過word2vec[20]預訓練單詞向量來替換相應的標識. 通過這種方式,模板的表示方法將語法的影響降到最低,同時保留了日志的語義信息.
(2) 訓練初始模型與分發給用戶. 在服務器端利用初始日志數據訓練初始的全局模型,并將其模型參數分發給所有參與訓練的用戶.
(3) 使用聯邦學習聚合用戶本地模型參數. 每個用戶可以在初始模型上基于各自的數據上訓練本地模型,訓練完成之后將本地模型上傳到服務器端聚合至全局模型.
(4) 使用遷移學習增強本地模型對于本地日志數據的檢測能力. 將全局模型分發給參與者后,讓參與者通過遷移學習在本地數據上對模型進行遷移學習訓練以獲得更適用于當前參與者場景的本地模型.
本文提出方法的總體框架如圖1所示.
3.2 日志數據表征構建
進行日志數據表征構建的目的是為了最大限度地保留日志的語義信息,同時盡量減少語法的影響. 在對原始的日志數據進行表征構建轉化成日志序列向量后,這些向量將被作為本地模型訓練的輸入.我們首先使用Drain對原始日志文本進行解析,輸出解析后的日志模板以及與原日志文本一一對應的日志結構化數據. 將日志按照區塊進行整理后形成日志序列,再將日志序列中的每一個日志事件與其模板進行映射,最終得到一個以日志模板表示的日志序列;之后,通過word2vec對整個日志序列進行詞嵌入,得到該日志序列的向量化表達. 其過程如圖2所示.
3.3 基于匹配平均算法的聯邦學習
LogFTL采用基于匹配平均的聯邦學習算法實現全局模型的聚合[7].基于匹配平均的聯邦學習算法通過對具有相似特征提取標志的隱藏元素進行匹配和均值計算,以分層方式構建共享全局模型. 隱藏元素包括卷積層的通道、長短期記憶神經網絡的隱藏狀態、完全連接層的神經元等. 考慮一個基本的循環神經網絡(Recurrent Neural Network, RNN),ht=σ(ht-1H+xtW),其中H∈瘙綆L×L是隱藏權重到隱藏權重的置換不變量,L是隱藏單元的數量,W是隱藏權重的輸入.為了說明RNN隱藏狀態的置換不變性,我們注意到ht的維數應該以與任何t相同的方式進行置換,因此,有
ht=σht-1ΠTHΠ+xtWΠ(1)
其中,Π是L×L的置換矩陣. 為了匹配循環神經網絡RNN,基本的子問題是將兩個具有歐幾里德相似性的客戶端的隱藏權重對齊. 這就需要在排列Π上對||ΠTHjΠ-HJ′|22進行最小化. 利用置換不變性,聯邦學習全局模型的隱藏權重能夠被計算為H=1j∑jΠjHhΠTj . LSTM具有多個單元狀態,每個單元狀態都具有隱藏到隱藏的單個單元狀態和隱藏權重的輸入. 當計算置換矩陣時,我們將隱藏權重的輸入堆疊成SD×L權重矩陣(S是單元狀態的數量;D是輸入維度;L是隱藏狀態的數量),然后通過式(2)平均所有權重.
minπjli∑Li=1∑j,lminθiπjlicwjl,θis.t.
∑iπjli=1j,l;∑lπjli=1i,j(2)
其中wjl表示在客戶端j上學習的第l個神經元;θi表示全局模型的第i個神經元;c·,·是兩個神經元之間的平方歐式距離相似函數;πjli是客戶端j提供的置換矩陣.
用戶端在本地訓練時根據損失函數計算梯度并更新本地模型參數權重.最后服務器端聚合用戶端上傳的模型參數.我們使用fS表示我們將要訓練的全局模型,訓練目標可以表示為:
argminΘL=∑ni=1lyi,fSxi(3)
其中,l·,·表示全局網絡的損失;例如分類任務的交叉熵損失.{xi,yi}ni=1是所有樣本和他們的標簽.Θ表示所有需要學習的參數,比如權重和偏差.在獲得初始的全局模型后,它將被分發給所有用戶,在我們的框架中,用戶數據的分享和傳輸是被禁止的. 在所有的用戶模型訓練完成后,用戶模型的參數被上傳到服務器上進行聚合對于參與者,其學習目標可以表示為:
argminΘuLu=∑nui=1lyui,fuxui(4)
3.4 基于長短期記憶網絡的遷移學習
聯邦學習能夠打消參與者共享日志數據時發生數據隱私泄露問題的顧慮從而解決“數據孤島”的問題,進而幫助我們使用不同來源不同類型的日志數據對模型進行訓練.通過聯邦訓練得到的全局模型是對所有用戶數據信息的聚合.
全局模型能夠學習到更多不同應用系統類型的日志數據知識,但是不同類型應用系統的日志數據其結構和語法存在差異,反而可能導致本地模型對本地日志數據類型檢測效果變差,因此需要通過遷移學習對本地模型進行重新訓練以獲得一個能夠保證本地異常行為檢測效果的本地模型. 為此我們設計了一個專門用于LogFTL框架的LSTM模型,并基于該模型實現遷移學習. LSTM網絡在日志異常檢測方法中經常被使用. 在LogFTL框架的遷移學習過程中,客戶端在接收到服務端傳輸回來的模型后使用本地日志序列對LSTM網絡的全連接層進行重訓練. 遷移學習的具體過程如圖3所示.
4 實 驗
4.1 基本設置
4.1.1 數據集 為了評估LogFTL的性能,我們使用了兩個公共數據集進行了實驗:(1)從Hadoop應用中收集的Hadoop應用數據集[14];(2)從Hadoop文件系統中收集的HDFS數據集[6]. 我們對上述兩個數據集進行數據預處理及日志表征構建. 使用Drain對日志數據進行模板解析并將其轉化為向量序列,每個序列代表一個樣本. 轉化后Hadoop應用數據集共有193 000條數據,其中正常樣本數120 000條,異常樣本數73 000條;HDFS數據集共有3 833 000條數據,其中正常樣本數3 725 000條,異常樣本數108 000條. 詳細信息如表1.
4.1.2 實驗設置 本文基于聯邦遷移學習方法對應用系統日志進行異常檢測.為模擬聯邦學習場景,將Hadoop應用數據集根據50%,30%,10%的比例隨機劃分為3部分,作為3個客戶端的本地數據,以體現實際環境中各參與者日志樣本量不同的情況,對應的客戶端命名為C1、C2、C3,并將這些數據中的70%用做訓練集,30%用做測試集.將HDFS數據集以相同比例劃分,對應的客戶端命名為C4,C5,C6. 兩個數據集剩下的10%數據混合后用來驗證模型是否能夠檢測不同類型應用系統日志數據的異常樣本,命名為Server.最終獲得對應6個客戶端的子數據集和對應混合類型應用系統日志的子數據集.為方便統計和計算,刪除了極少量的樣本,其數量占總樣本數不到0.1%.實驗數據集的具體劃分情況如表2所示. 在LogFTL框架中,我們將LSTM網絡設定為2層128個記憶單元的LSTM層和1層192個記憶單元的全連接層.
4.2 實驗評估指標
為評估檢測效果,本文使用精度(Precision)、召回率(Recall)、F1分數(F1-Score)和準確率(Accuracy)作為評估指標,其數學定義如下.
(1) 精度:正確判定的惡意樣本數量與所有判定為惡意樣本的數量之比.
Precision=TPTP+FP
(2) 召回率:正確判定的惡意樣本數量與全部真正的惡意樣本數量之比.
Recall=TPTP+FN
(3) F1分數:精度和召回率的加權調和平均值.
F1-Score=2.Precision.RecallPrecision+Recall
(4) 準確率:正確判定良性和惡意樣本的數量與所有樣本數量之比,簡寫為Acc.
Acc=TP+TNTP+TN+FP+FN
4.3 聯邦遷移學習框架效果評估實驗
本文提出的基于聯邦遷移學習的日志異常檢測方法其核心目標是為了在數據獨立存在于不同位置且因為隱私問題無法直接共享的前提下,利用聯邦學習以隱私安全且模型參數加密的方式聚合出一個學習到不同客戶端不同應用系統類型日志數據的全局模型,再將全局模型分發給參與者利用遷移學習強化其針對本地日志數據的檢測能力. 表3表明,所有客戶端在經過聯邦遷移學習之后在本地數據集的檢測結果.
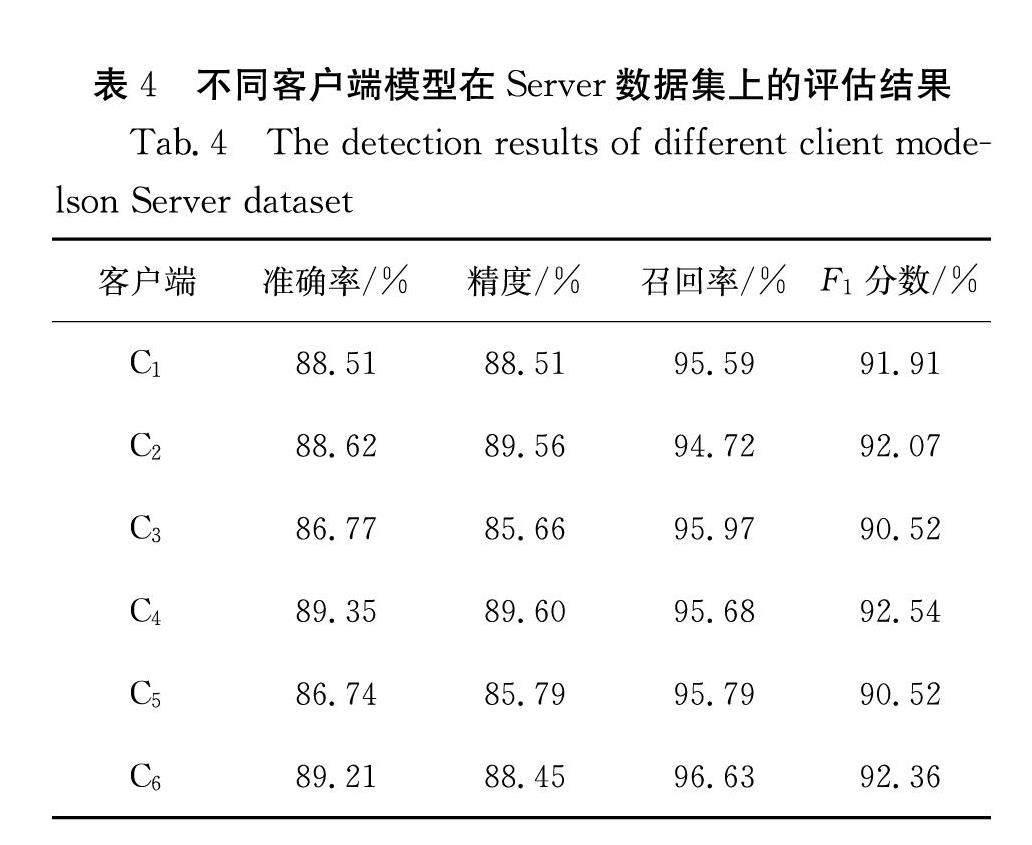
上述實驗表明,本文提出的聯邦遷移學習算法,在檢測客戶端本地應用系統類型的日志數據的異常上有較好的表現,平均達到了90.06%的準確率. 表4表明,所有客戶端在經過聯邦遷移學習之后在Server數據集的檢測結果.
通過對不同類型應用系統日志混合數據集Server的檢測效果實驗,也證明了在沒有與其他客戶端共享日志的條件下,聯邦遷移學習讓本地模型擁有檢測其他類型應用系統日志異常數據異常的能力,平均達到了88.2%的準確率.
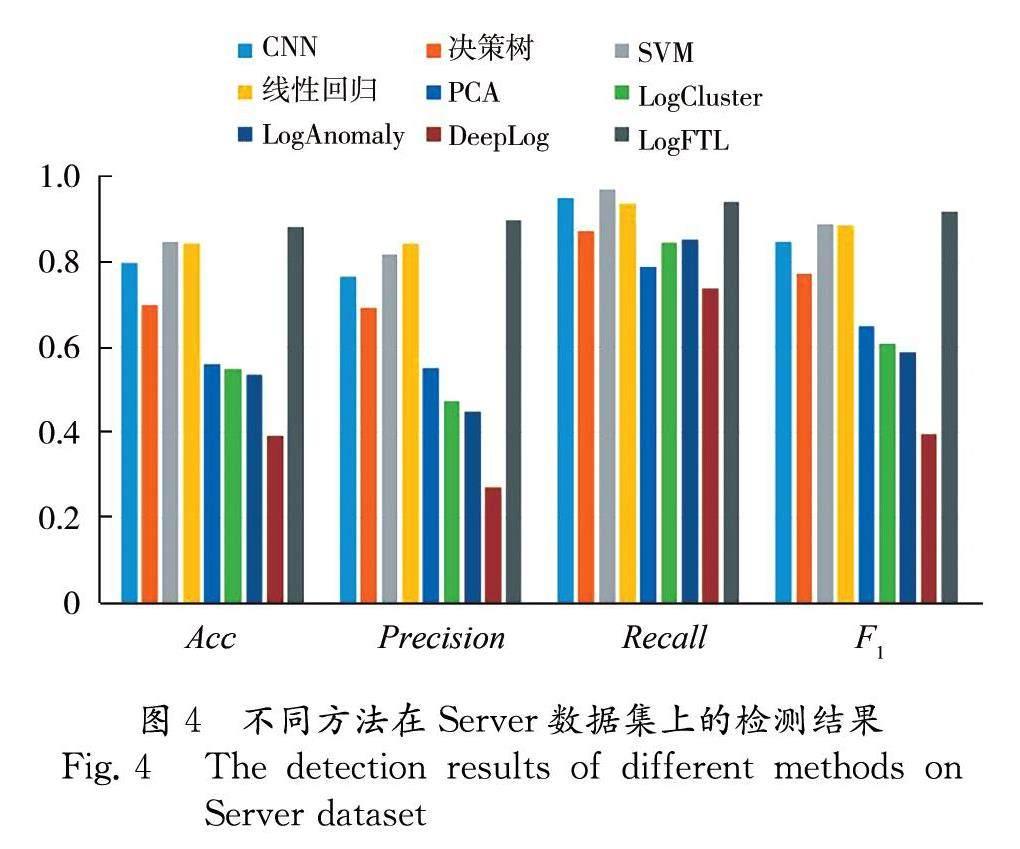
為了進一步評估LogFTL檢測混合類型應用系統日志的效果,我們將其與4種有監督的基于日志的異常檢測方法,包括線性回歸、SVM、決策樹和CNN模型以及4種無監督的方法,包括PCA、LogCluster、LogAnomaly、DeepLog進行對比. 圖4記錄了使用不同方法在Server數據集上的測試結果. 實驗結果表明,我們的方法通過聚合位于不同客戶端的數據,能夠比傳統的有監督學習方法和無監督學習方法學習到更多異常模式.在本地數據樣本不足的情況下,本文方法的準確率要高于其他檢測方法,達到了88.25%,證明了LogFTL能夠在不影響隱私安全的前提下,將處于不同客戶端的數據以聯邦學習的方式進行聚合.
4.4 遷移學習效果評估實驗
為了證明LogFTL框架遷移學習的有效性,我們比較了使用了遷移學習和沒有遷移學習的LogFTL的效果, 其結果如表5所示. 顯然,使用遷移學習確實提高了LogFTL框架檢測異常的準確率.
5 結 論
本文分析了現有日志數據異常檢測中存在的隱私泄露風險,提出了一種基于聯邦遷移學習的應用系統日志的異常檢測方法. 該方法基于長短期記憶網絡構建基礎模型,在保證參與者數據隱私的前提下,通過聯邦學習框架解決了日志數據的“數據孤島”問題和不同應用系統類型日志的結構和語法差異問題,并采用遷移學習的方法解決聯邦學習全局模型本地化后檢測效果降低的情況. 我們在兩種數據集下進行了多場景的實驗,證明了LogFTL方法在聯邦學習的場景下,不僅具有最好的模型性能,還能夠保證隱私和數據的安全.
參考文獻:
[1] Chen J, Zhang S, He X, et al. How incidental are the incidents?:characterizing and prioritizing incidents for largescale online service systems [C]// Proceedings of the? 35 th IEEE/ACM International Conference on Automated Soft-ware Engineering. New York: ACM, 2020: 373.
[2] 張穎君, 劉尚奇, 楊牧, 等. 基于日志的異常檢測技術綜述 [J]. 網絡與信息安全學報, 2020, 6: 1.
[3] 黃緯, 黃曉華, 張源, 等. 基于Git日志的即時軟件質量分析框架[J].吉林大學學報: 理學版,? 2022, 60: 135.
[4] Xu W, Huang L, Fox A,et al. Detecting large-scale system problems by mining console logs [C]//Proceedings of the ACM SIGOPS 22nd Symposium on Operating systems Principles. New York: ACM, 2009: 117.
[5] Du M, Li F, Zheng G, et al. Deeplog: Anomaly detection? and diagnosis from system logs through deep learning [C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 1285.
[6] Karun A K, Chitharanjan K. A review on hadoop——HDFS infrastructure extensions [C]//Proceedings of the 2013 IEEE Conference on Information & Communication Technologies. Thuckalay: IEEE, 2013: 132.
[7] Chen R, Zhang S, Li D, et al. Logtransfer: Cross-system log anomaly detection for software systems with transfer learning [C]//Proceedings of the 2020 IEEE 31st Internation-al Symposium on Software Reliability Engineering. Coimbra: IEEE, 2020: 37.
[8] Wang H, Yurochkin M, Sun Y, et al. Federated learning? with matched averaging [EB/OL]. [2022-02-15]. https://arxiv.org/pdf/2002.06440.pdf.
[9] He S, Zhu J, He P, et al. Experience report: System log analysis for anomaly detection [C]//2016 IEEE 27th International Symposium on Software Reliability Engineering. Ottawa: IEEE, 2016: 207.
[10] Zhu J, He S, Liu J, et al. Tools and benchmarks for autom-ated log parsing [C]//Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice. Montreal: IEEE, 2019: 121.
[11] He P, Zhu J, Zheng Z, et al. Drain: an online log parsing? approach with fixed depth tree [C]//Proceedings of the 2017 IEEE International Conference on Web Services.Montreal: IEEE, 2017: 33.
[12] 閆力, 夏偉.基于機器學習的日志異常檢測綜述[J].計算機系統應用, 2022, 31: 57.
[13] Chen M, Zheng A X, Lloyd J, et al. Failure diagnosis using decision trees [C]//Proceedings of the International Conference on Autonomic Computing. New York: IEEE, 2004: 36.
[14] Liang Y, Zhang Y, Xiong H, et al. Failure prediction in ib-m bluegene/l event logs [C]//Proceedings of the 7 th IEEE International Conference on Data Mining. Omaha: IEEE, 2007: 583.
[15] Lin Q, Zhang H, Lou J G, et al. Log clustering based problem identification for online service systems[C]//Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion. Austin Texas: ACM, 2016: 102.
[16] Zhang X, Xu Y, Lin Q, et al. Robust log-based anomaly detection on unstable log data [C]//Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Tallinn Estonia: ACM, 2019: 807.
[17] Meng W, Liu Y, Zhu Y, et al. LogAnomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs [C]//Proceedings of the 2019 International Joint Conferences on Artificial Intelligence.Macao: IJCAI, 2019: 4739.
[18] Konecny J, McMahan H B, Ramage D, et al. Federated optimization: Distributed machine learning for on-device intelligence [EB/OL].[2016-08-08]. https://arxiv.org/pdf/1610.02527.pdf.
[19] Guo Y, Wu Y, Zhu Y, et al. Anomaly detection using distributed log data: a lightweight federated learning approach [C]//Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN). Shenzhen: IEEE, 2021: 1.
[20] Xu W, Huang L, Fox A, et al. Online system problem detection by mining patterns of console logs[C]//Proceedings of the 9 th IEEE International Conference on Data Mining. [S.l.]:IEEE, 2009: 588.
[21] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space [EB/OL]. [2013-06-16]. https://arxiv.org/pdf/1301.3781.pdf.
[22] Wang J, Tang Y, He S, et al. LogEvent2vec: LogEvent-to-vector based anomaly detection for large-scale logs in internet of things [J]. Sensors, 2020, 20: 2451.
引用本文格式:
中 文: 曾閩川, 方勇, 許益家. 基于聯邦遷移學習的應用系統日志異常檢測研究[J]. 四川大學學報: 自然科學版, 2023, 60: 033002.
英 文: Zeng M C, Fang Y, Xu Y J. Research on application system log anomaly detection based on federated transfer learning [J]. J Sichuan Univ: Nat Sci Ed, 2023, 60: 033002.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
