基于時間演化圖卷積網絡的輿情熱點內容預測
2023-04-29 01:10:43文雅楊頻廖珊代金鞘賈鵬
四川大學學報(自然科學版) 2023年3期
文雅 楊頻 廖珊 代金鞘 賈鵬


有效預測輿情事件的熱點內容有利于提高對輿論導向的把控能力和對公眾訴求的預判能力. 然而,現有的輿情預測工作大多關注事件整體趨勢指標或情感極性的演變預測,鮮有針對輿情事件熱點內容的預測研究. 為解決以上問題,本文提出一種基于時間演化圖卷積網絡的輿情熱點內容預測方法:以輿情事件的熱點詞作為預測對象,首先,通過演化圖卷積網絡學習各時間片詞語的空間關聯關系;然后,使用門控循環單元捕捉各時間片詞語特征的時序變化;最后,通過全連接層進行輸出,實現對輿情事件熱點詞的預測. 以微博上兩個不同的輿情突發事件的相關文本作為數據集,與兩種現有熱點詞預測方法開展對比實驗. 實驗結果表明,該方法在兩個數據集上的精確率分別達到51.21%和50.98%,召回率分別達到50.17%和48.15%,F1值分別達到50.68%和49.52%,均高于兩種對比方法,能夠更好地完成輿情事件中熱點詞的預測.
輿情預測; 熱點詞預測; 時間演化圖卷積網絡
TP391.1A2023.033001
收稿日期: 2022-11-01
基金項目: 四川省科技廳重點研發項目(2021YFG0156)
作者簡介: 文雅(1997-), 女, 碩士研究生, 主要研究領域為輿情分析與預測. E-mail: tanya_scu@163.com
通訊作者: 楊頻. E-mail: yangpin@scu.edu.cn
A temporal evolving graph convolutional network for Public opinion prediction in emergencies
WEN Ya1, YANG Pin1, LIAO Shan2, DAI Jin-Qiao1, JIA Peng1
(1. College of Cybersecurity, Sichuan University, Chengdu 610211, China;
2. The 30th Research Institute of China Electronics Technology Group Corporation, Chengdu 610041, China)
Public opinion prediction is one of the key solutions to improve the ability to guide public opinion in emergencies. However, most of the existing public opinion prediction work focuses on the trend indicator or sentiment polarity of events ,while little attention paid to the prediction of hot words and topics in specific events. In this paper, a temporal evolving graph convolutional network for public opinion prediction in emergencies is proposed, in which the hot words associated with specific events are taken as the object of public opinion prediction. Our approach combines evolving graph convolutional network with gated recurrent unit: the former is used to learn the dynamic spatial correlation between words and the latter is used to capture the temporal changes of words, the hot words of an emergency in the next time period is then predicted through full connection layer output. To validate the proposed method, we selected discussion texts related to two emergencies on Weibo as the dataset, and conducted comparative experiments with two existing hot word prediction methods. The results show that our method achieved higher precision, recall, and F1-score in both emergencies, with precision of 51.21% and 50.98%, recall of 50.17% and 48.15%, and F1-scores of 50.68% and 49.52%, respectively. These results demonstrate that our proposed method is effective in predicting public opinion during emergencies
Public opinion prediction; Hot words prediction; Temporal evolving graph convolutional network
1 引 言
輿情指輿論情況,是指在輿情因變事項(下文簡稱輿情事件)發生、發展和轉變過程中,民眾所持有的看法、觀點和態度等[1]. 隨著互聯網和自媒體的發展,以前只會從事件發源地慢慢擴散流傳的輿情事件,現在則很快通過網絡散播并被全國各地人民知曉[2]. 網絡輿情的傳播速度快,傳播規模大,參與門檻低[3].特別是當惡性事件發生后,如果不能及時了解民眾訴求,盡快進行輿論引導,事件輿論可能會加速發酵升級,給群眾帶來恐慌,甚至影響民眾對政府的信任度[2].因此,有效開展輿論引導工作具有重要意義[4].
及時發現和實時監控輿情可以對輿論引導工作起到幫助[4]. 目前,針對輿情的發現和監控已有廣泛研究,其中Nielsen、Goonie和PALAS等輿情監控系統都可以幫助企業和政府對輿情進行發現和監控[3]. 但是這些系統主要用于發現未知輿情,并對已知輿情的輿論走向進行分析,對輿情輿論的未來發展預測較少. 面對復雜多變的網絡輿情環境,為了更有效地開展輿論引導工作,需要防患于未然,加強對公眾訴求的預判能力,預防突發的輿論危機,那么一個關鍵的解決途徑是對輿情事件下一個階段的發展進行有效預測.
如果能夠在輿情事件發展過程中,對其未來走向進行有效預測,就能夠更加準確地預判群眾對事件的看法,及時調整輿論引導策略[4]. 目前國內外在輿情預測方面已有較多研究,然而,現有的相關研究工作,通常只對輿情事件整體的趨勢指標或者情感極性進行預測. 這類預測對象在一定程度上確實能夠反映大眾對事件的態度,如大眾對事件關注度的高低,對事件的態度是積極還是消極等. 但是這類預測對象難以捕捉輿情事件發展過程中群眾關注點和具體訴求的變化,即輿情熱點內容的變化. 及時了解輿情熱點內容變化的意義主要表現在:有助于提高政府和企業對輿情事件中群眾的關注點和具體訴求的預判能力,能夠在苗頭性傾向性問題上掌握主動權,在群眾的不滿和對立等負面情緒升級之前,進行適當的良性引導,擺脫被動滯后,使輿論引導更加主動和精準[4]. 因此,為了達到更好的輿論引導效果,可以通過預測輿情事件中熱點內容隨時間的發展變化及時獲取群眾的關注點和具體訴求的變化,進而為輿論引導策略的調整提供參考.
基于上述分析,本文提出了一種基于時間演化圖卷積網絡(Temporal Evolving Graph ConvolutionalNetwork,T-EGCN)的輿情熱點內容預測方法. 以輿情事件每個時間片的熱點詞作為內容預測對象,通過預測一個輿情事件發展過程中熱點詞的變化來體現熱點內容的變化. 具體來說,本文首先搜集社交媒體上針對某個輿情事件的討論文本,通過主題模型篩選得到每個時間片的熱點詞,以此代表該輿情事件不同時間片群眾的關注點和具體訴求,即輿情熱點內容. 然后,根據每個時間片的熱點詞的熱度權重為閾值選取每個時間片的候選熱點詞語,以關聯關系為邊轉化為圖結構,形成候選熱點詞空間關聯關系圖. 接著,將詞語特征和圖結構輸入到演化圖卷積網絡(EvolveGCN)[5],通過候選熱點詞的動態空間關聯關系,為下一時間片的熱點詞預測提供豐富的前序時間片詞語關系變化信息. 然后,使用門控循環單元(GRU)學習帶有空間信息的詞語特征,實現對候選熱點詞時序關系的捕捉,使用詞語的時序信息豐富預測特征. 最后,使用全連接層進行熱點詞預測輸出. 實驗表明,本文方法相比已知的兩種熱點詞預測方法,能更準確地預測輿情事件下一時間片的熱點詞,完成輿情熱點內容預測.
本文的主要貢獻有:(1)提出了T-EGCN模型,在EvolveGCN的基礎上融入GRU,通過EvolveGCN捕捉空間特征變化,利用GRU學習時間特征變化,該模型能夠同時捕獲空間動態性和時間動態性,是圖卷積網絡(GCN)在時空預測任務上的一個擴展方案,可以應用于時間和空間信息均存在動態變化的時空預測任務;(2)提出了一種網絡輿情熱點內容預測方法,使用基于數據量的動態時間分片方法、詞語相對熱度計算方法和候選熱點詞篩選方法對數據進行預處理,并使用T-EGCN模型進行預測,實現了一種利用輿情事件前序時間片段的詞語信息,預測后續時間片段該輿情事件熱點詞的方法;(3) 通過實驗驗證了本文所提方法能夠在已知前序多個時間片的事件數據的基礎上,預測下一時間片事件的熱點詞,方法預測效果優于近年的兩種預測未來熱點詞的方法,在本文的兩個輿情事件數據集上,預測精確率分別達到51.21%和50.98%,召回率分別達到50.17%和48.15%,F1值分別達到50.68%和49.52%.
2 相關工作
目前,輿情預測的研究工作中,選取的研究對象主要是趨勢指標[6]或情感極性[7]. 張虹等[8]以熱點事件的網絡論壇點擊率和回復數為預測對象,提出了一種基于小波分析和神經網絡建模的非線性事件序列的預測方法. 杜慧等[9]針對熱度趨勢指標缺乏統一衡量指標的問題,提出了一種基于因果模型的主題熱度算法,以定量評估的主題熱度作為預測對象,實現了一種基于多峰高斯曲線擬合熱度變化進行主題熱度預測的方法. 崔彥琛等[10]針對輿情預測研究中情感分析預測研究不足的問題,提出了一種構建事件專屬情感詞典對情感極性進行定量分析的方法,以定量評估的情感極性值為預測對象,實現了一種基于ARIMA模型的輿情事件情感分析預測方法. 程鐵軍等[11]以百度指數作為熱度趨勢指標,利用模態分解在非線性噪聲序列數據處理方面的優勢,提出了一種結合BP 神經網絡和模態分解對事件百度指數進行預測的方法,增強輿情預測模型的泛化能力和非線性預測能力. 這些針對趨勢指標或情感極性的預測研究,能夠在一定程度上反映輿情變化,但是并不能細粒度地反映輿情中群眾關注點和具體訴求的變化,即輿情熱點內容的變化.
而目前針對熱點內容的預測研究,通常只利用前序一個時間片的詞語空間關聯關系,如語義關系或者共現性關系,對下一時間片的熱點詞進行預測,未考慮前序多個時間片的詞語空間關聯關系對熱點詞預測的影響. 岳麗欣等[12]提出一種基于word2vec語義關系的熱點詞預測方法,將與當前熱點主題詞的word2vec詞語相似度最高的詞語作為預測的未來熱點詞,實現了對美國干細胞研究領域熱門研究方向的未來熱點詞預測. Li等[13]提出了一種基于詞共現概率的關鍵詞信息熵算法,將上一時間片中信息熵高的詞組預測為下一個時間片的熱點詞,最后通過新冠肺炎事件作為例子,說明了該算法在預測流行病事件話題的未來熱點詞上的可行性.
由于輿情熱點內容會隨著輿情事件發展逐漸變化,所以每個時間片中詞語出現的頻率是會不斷變化的,詞語空間關聯關系也會隨之改變. 因此,如果要通過前序多個時間片的詞語空間關聯關系來預測熱點詞,就需要同時捕捉時間和空間特征.
Zhao等[14]提出了一種基于時間圖卷積網絡(Temporal Graph Convolutional Network,T-GCN)的時空預測模型,使用GCN學習節點的空間關聯關系特征,使用GRU學習節點的時間特征,成功將節點的時間依賴性和空間依賴性有機結合在一起. Pareja等[5]針對GCN難以挖掘圖的動態演化特征的問題,提出了演化GCN結構的EvolveGCN模型,使用RNN演化圖節點在圖空間上的時序變化,能夠為不同的時間節點輸入不同的節點空間關聯關系圖結構,并獲取隨著關系圖動態變化的節點嵌入.
3 基于T-EGCN的輿情熱點內容預測方法
本文提出的基于T-EGCN的輿情熱點內容預測方法的框架如圖1所示,方法架構包括數據預處理、候選熱點詞提取、詞語關系圖構建和T-EGCN模型預測等4個部分. 首先,通過關鍵詞搜索從社交媒體上爬取某一輿情事件在演化生命周期內的全部原創發表文本,并對其進行過濾清洗和分片. 接著,對每個時間片的詞語,通過轉贊評計算得到其內容影響力,結合詞頻-逆文檔頻率(TF-IDF)進行熱度量化,得到各個時間片的詞語相對熱度排序,并通過主題模型動態篩選候選主題詞形成候選熱點詞典. 然后,對每個時間片,分析候選熱點詞之間的語義相似度和共現性關系,進而結合內容影響力為每個時間片構造出一個候選熱點詞空間關聯關系圖. 最后,使用EvolveGCN和GRU分析詞語關系共同進行熱點詞預測輸出.
3.1 數據預處理
社交媒體上能夠發表的信息載體有文本、圖片和表情等[15]. 本文主要通過社交媒體上輿情事件的文本數據分析輿情熱點. 考慮到本文研究的重點為熱點詞,所以對數據進行去重后,使用正則表達式過濾掉了tag、表情符號、鏈接和評論的回復前綴. 由于文本中的名詞、動詞等是具有實際意義、能夠更好地反應輿論熱點的詞語[16],所以使用jieba庫(https://pypi.org/project/jieba/) 進行分詞,并做詞性分析,保留名詞、動詞、形容詞等有效詞語,并去除過濾后為空的文本.
在完成數據的清洗和過濾工作后,要對其進行分片. 目前的輿情預測研究使用的時間分片方法通常是均等時長分片,即在輿情事件的整個生命周期內,按均等時間長度切分數據進行分片分析[3, 9-12],如每M分鐘,每H小時,每D天等,該方法的優點是劃分方式簡單,適用于輿情的事后分析工作.
然而,要在輿情事件發展過程中不斷進行熱點內容預測,顯然需要實時性. 但由于輿情事件的文本量在不同時刻變化較大[17],例如當事件出現新發展時,討論量會激增;根據作息規律,人們在凌晨的發帖量總是較少;爆發期博文數平均高于產生期和衰退期等. 這些情況導致均等時長分片的方法存在實時分析時不同時間片的數據量差異較大,而且無法及時感知輿情事件的突發新變化的問題,難以滿足本文輿情預測的實時分析需求.
因此,本文提出了一種基于數據量的動態時間分片方法來實時和均衡地劃分數據,其流程如圖2所示. 首先以小時為單位捕獲數據,設第t個小時獲取的數據量為numt,此時正在劃分第k個時間片的數據,其已獲取的數據量為slicek,每個時間片的最小數據量閾值為MIN,當slicek達到MIN時,將slicek劃分為一個時間片的數據. 本文參考事件輿情產生期的第一個數據量激增周期數據設置閾值MIN.
3.2 候選熱點詞提取
熱點詞是通過算法挑選出的能代表每個時間片中網民觀點的詞語[18,19]. 目前的研究當中,通常使用的選方法有兩種,分別是基于主題模型的提取方法[12, 17, 20]和基于詞頻等權重排序的選取方法[13, 18, 21,22]. 由于目前沒有統一的挑選方法,本文同時考慮主題模型和權重排序,更全面地提取候選熱點詞.
本文結合內容影響力和TF-IDF,獲取詞語的權重排序. 其中,內容影響力代表一條文本對群眾的影響. 一般來說,文本的轉贊評在很大程度上體現了文本的影響力[18]. 不同影響力的文本對包含在其中的詞語的權重貢獻程度應該不同,然而傳統的TF-IDF忽略了這一點[21].
本文在TF-IDF的基礎上加入內容影響力作為TF-IDF的權重. 具體過程如下:對第t個時間片的文本d,其內容影響力P(d)的計算公式為
P(d)=RPd+RTd+Ld+1RPDt+RTDt+LDt+NDt(1)
其中,RPDt、RTDt和LDt分別表示第t個時間片中的所有文本的回復總數、轉發總數和點贊總數;NDt表示第t個時間片中的文本總數;RPd、RTd和Ld表示文本d的回復數、轉發數和點贊數. 該公式可以使轉贊評越多的文本,其P(d)越大.
然后,將P(d)加入到TF-IDF當中. 對文本d中出現的詞j,其權重表示為wj,t,wj,t的計算公式為
wj,t=∑Dtd=1Pd·tf-idfd,j(2)
其中,Dt表示第t個時間片中的所有文本;P(d)表示文本d的內容影響力;tf-idfd,j表示文本d中詞j的TF-IDF值.
通過式(2)得到第t個時間片中所有詞語的權重后,進行降序排列,便得到詞語的權重排序. 接下來即可設置閾值,選取排序靠前的詞語作為候選熱點詞.
本文選取在短文本上表現較佳的GSDMM主題模型[23,24]構建每個時間片的熱點詞集并設置候選熱點詞選取閾值,具體方法如下:對第t個時間片的數據,通過GSDMM主題模型抽取每個主題的前N個主題詞加入熱點詞集,根據式(2)計算得到的詞語權重排序,取熱點詞集中權重最低的詞的權重為閾值,選出該時間片所有權重高于該閾值的詞形成候選熱點詞典.
3.3 詞語關系圖構建
對第t個時間片的所有候選熱點詞,根據詞語的語義和共現性,將它們關聯起來,構建候選熱點詞空間關聯關系圖,其結構參考圖3.
圖3中節點Wi,t和Wj,t表示第t個時間片的第i和j個候選熱點詞,Si=sa,sb,sc,sd代表第t個時間片的文本中出現詞Wi,t的文本集合,Sj=sa,sb,se,sk代表第t個時間片的文本中出現詞Wj,t的文本集合,文本和詞是多對多的關系. 本文提出一種結合內容影響力的候選熱點詞相關性計算方法,來確定圖中詞與詞之間的邊的權值,即相關性ri,j,t. 如圖3所示,詞Wi,t和詞Wj,t的公共文本集合為ssame=sa,sb,其內容影響力權重為hssame,不同文本集合為sdiff=sc,sd∪se,sk,其均值word2vec文本相似度[25]為simsdiff,內容影響力權重為hsdiff,則詞Wi,t和詞Wj,t的相關性ri,j,t的計算公式為
ri,j,t=hssame+hsdiff·simsdiff(3)
內容影響力權重hs的計算公式為
hs=RPs+RTs+Ls+NsRPS+RTS+LS+NS(4)
其中S表示Si和Sj的并集;s代表ssame或者sdiff,NS表示S包含的文本總數;RPS、RTS和LS表示S包含的文本的回復數、轉發數和點贊數; Ns表示s1或者s2包含的文本總數,RPs、RTs和Ls表示ssame或者sdiff包含的文本的回復數、轉發數和點贊數. 轉贊評越多的文本,其內容影響力權重越大,詞語之間的相互影響程度越高.
以式(3)計算得到的相關性特征值作為圖結構中節點之間的邊的權值,可以表現出第t個時間片的候選熱點詞之間的語義相似性和共現性關系,即空間關聯關系.
3.4 T-EGCN模型預測
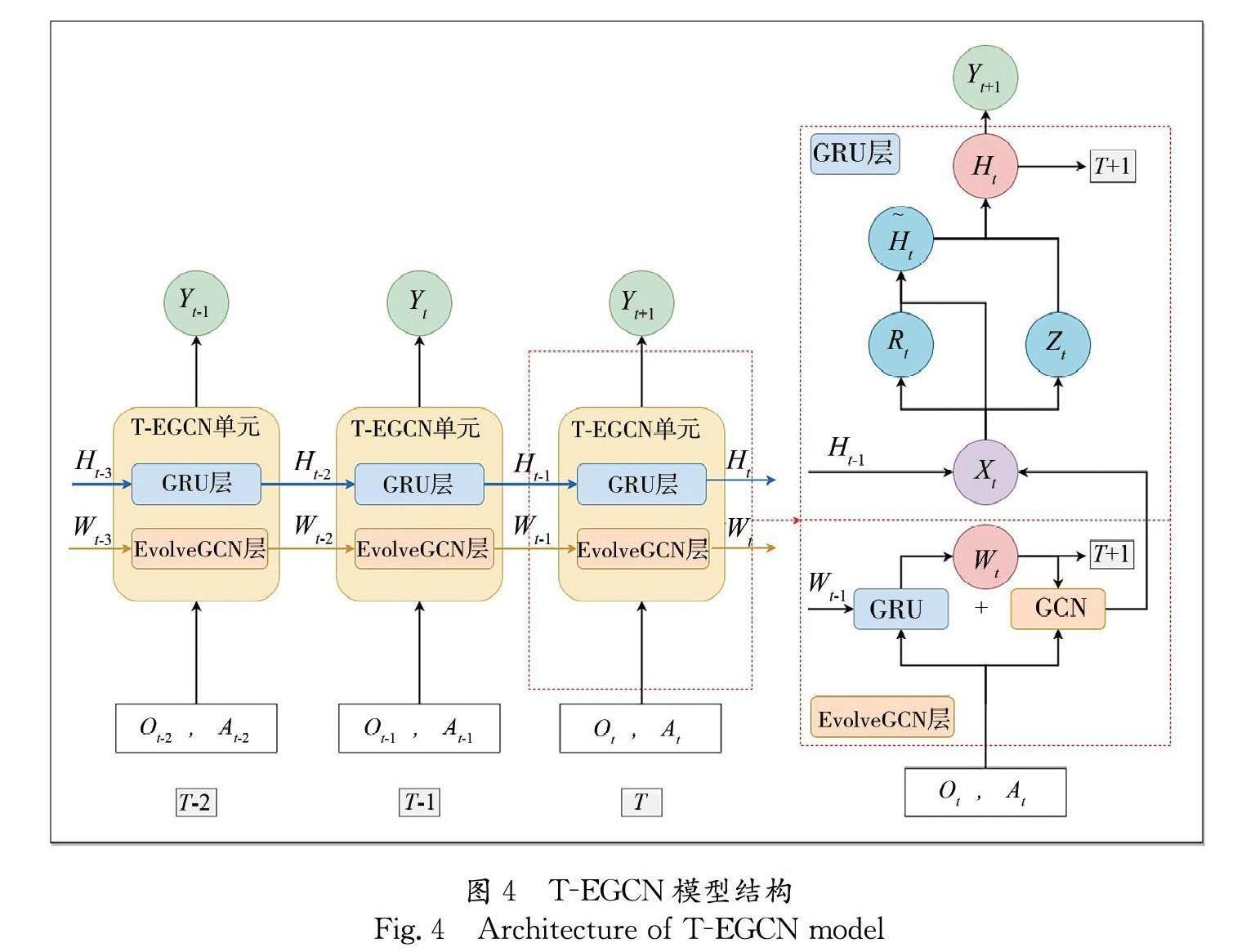
T-EGCN模型利用EvolveGCN學習隨著時間片變化的輿情事件候選熱點詞關聯關系圖的拓撲結構,獲得空間維度特征. 再將帶有空間信息的特征輸入GRU,提取時間維度特征,最后通過全連接層進行預測輸出,模型結構如圖4所示.
圖4的左側部分展示了T-EGCN模型的整體結構,它由前后依次連接的T-EGCN單元組成,每個T-EGCN單元內部包含一個EvolveGCN層以及一個GRU層. 模型的輸入為節點特征矩陣Ot和通過候選熱點詞空間關聯關系圖得到的帶權重的鄰接矩陣At,EvolveGCN層通過圖卷積的過程來學習空間依賴性,GRU層通過重置門Rt和更新門Zt來學習時間依賴性.
圖4的右側部分展示了T-EGCN模型的內部構成. 在EvolveGCN層中,使用基于頻域的GCN來聚合候選熱點詞節點的鄰居信息,加入權重參數矩陣Wt,用于記憶和傳遞圖空間的時序變化,共同計算節點的嵌入矩陣Xt,具體計算過程如下.
At=At+I(5)
Dt=diag(∑jAtij)(6)
A︿t=Dt-12AtDt-12(7)
Xt=σA︿tOtWt(8)
其中,At為帶權重的鄰接矩陣;I為單位矩陣;diag表示加入自環圖的度矩陣計算函數,得到對角線為對應節點度加1,其余數值為0的度矩陣Dt;Ot是節點特征矩陣;Wt為EvolveGCN權重參數矩陣; σ代表ReLU激活函數;卷積得到的節點嵌入矩陣Xt為GRU層的輸入.
如圖4所示,EvolveGCN層中也包含能夠傳遞圖結構時序信息的GRU單元. 但是與GRU層相比,兩者的輸入It不相同:在GRU層中,輸入It是第t個時間片中EvolveGCN層卷積得到的節點嵌入矩陣Xt,學習的是詞語節點特征的時序變化;而在EvolveGCN層的 GRU單元中,輸入It是第t個時間片的候選熱點詞節點特征矩陣Ot,學習的是詞語圖空間的時序變化. 在第t個時間片中,GRU層和EvolveGCN層的GRU單元的重置門Rt、更新門Zt、候選隱藏狀態Ct和最終隱藏狀態Ct的計算公式為
Rt=σUrxIt+UrhCt-1+Br(9)
Zt=σUzxIt+UzhCt-1+Bz(10)
Ct=tanhUcxIt+Uch(Rt.Ct-1)+Bh(11)
Ct=Zt.Ct-1+1-Zt.Ct(12)
其中,U為可學習的權重參數;B為可學習的偏差參數;It為當前時間片t的輸入;Ct-1為上一時間片的隱藏狀態;σ代表sigmoid激活函數;tanh代表tanh激活函數;*代表哈達瑪積.
因此,EvolveGCN層的權重參數Wt和GRU層的隱藏狀態Ht的參數傳遞和計算過程如下.
Wt=GRUIt=Ot,Ct-1=Wt-1(13)
Ht=GRUIt=Xt,Ct-1=Ht-1(14)
可以看到,兩個GRU網絡結構的輸入輸出存在差異,本文利用GRU的特性來捕捉和學習不同維度的時序變化. 最后,將GRU層的Ht作為最終節點特征表示,輸入到全連接層當中,得到下一時間片的熱點詞預測Yt+1.
4 實驗與分析
本節將基于微博輿情事件數據集,展開驗證實驗. 首先,詳細介紹所用的數據集、評價指標和相關實驗設置. 然后,基于對比實驗,深入討論分析本文方法的優點和不足. 其中,為了驗證本文方法在時間分片上的數據均衡性和實時性,基于事件數據集,開展本文分片方法與常規分片方法的對比實驗;為了驗證本文方法在未來熱點詞預測上的有效性,基于事件數據集,開展本文方法與該領域新工作的對比實驗;為了以更直觀的方式展現本文方法在預測熱點詞方面的效果,基于事件數據集,繪制熱點詞云進行對比分析.
4.1 數據集
(1) 數據集A.爬取自新浪微博上關于2018年“女孩乘滴滴遇害”事件發布時間介于2018年 8月25日9時至8月31日24時生命周期內[18]的中文原創微博文本和熱門微博評論文本,共38 668條. 通過過濾清洗,得到結果不為空且不重復的文本29 521條. 按照本文基于數據量的動態時間分片方法,設最小數據量閾值MIN=500,將數據劃分為43個時間片,由于數據向前遞補,所以最后一個時間片數據僅有431條,不足500條,為避免數據量不均衡問題,去掉最后一個時間片的數據,最終數據的時間介于2018年 8月25日9時至8月30日19時,一共有29 090條,分為42個時間片.
(2) 數據集B.爬取自新浪微博上關于2021年“三只松鼠模特妝容爭議”事件發布時間介于2021年 12月25日13時至12月29日24時生命周期內的中文原創微博文本和熱門微博評論文本,一共有22 769條. 通過過濾清洗,得到結果不為空且不重復的文本17 900條. 按照本文基于數據量的動態時間分片方法,設最小數據量閾值MIN=200,將數據劃分為51個時間片,由于數據向前遞補,所以最后一個時間片數據僅有191條,不足200條,為避免數據量不均衡問題,去掉最后一個時間片的數據,最終數據的時間介于2021年 12月25日13時至12月29日21時,一共有17 709條,分為50個時間片.
4.2 評估指標
由于方法的最終目標是預測未來時間片的熱點詞,就實驗結果而言,對詞語的判定為:若在第t個時間片的預測熱點詞集中則“是第t個時間片的熱點詞”,不在詞集中則“不是第t個時間片的熱點詞”. 所以可以看作分類預測,采用分類預測算法常用的評價指標,即精確率(Precision)、召回率(Recall)和兩者的調和平均(F1-score)對算法進行評估,計算公式如下.
Precision=TPTP+FP(15)
Recall=TPTP+FN(16)
F1-score=2·Precision·RecallPrecision+Recall(17)
其中,TP代表真陽性,即預測結果和實際都為熱點詞的詞語數量;FP代表假陽性,即預測結果為熱點詞,但實際不是熱點詞的詞語數量;TN代表真陰性,即預測結果和實際都為非熱點詞的詞語數量;FN代表假陰性,即預測結果為非熱點詞,實際卻是熱點詞的詞語數量.
4.3 實驗設置
本文實驗設置如下:
(1) 將數據集按時序關系切割成7∶3的兩部分,T-EGCN模型每次利用前序三個時間片的圖信息進行學習,預測下一個時間片的熱點詞. 因此,最開始的三個時間片不能作為預測輸出,數據集A構成26個訓練集和12個測試集,數據集B構成31個訓練集和15個測試集.
(2) T-EGCN模型輸入的節點特征值和輸出的節點預測值為詞語在對應時間片的相對權重,優化器為Adam,學習率為0.005,EvolveGCN層和GRU層的隱藏層單元數目均為200.
(3) 將整個數據集中出現的詞語進行匯總,在第t個時間片中,對詞匯表的每個詞,根據真實熱點詞集,出現在熱點詞集中的詞語標記為1,其余詞語標記為0,作為樣本的真實標簽. 以各類算法提取出的預測熱點詞集為預測結果,對詞匯表的每個詞,出現在預測熱點詞集中的詞語標記為1,其余詞語標記為0,作為樣本的預測標簽.
(4) 本實驗所用GPU服務器的顯卡型號為NVIDIA GeForce RTX 3090,顯存為24 G,編程語言為python,深度學習框架為pytorch.
4.4 實驗結果與分析
本小節在GSDMM主題模型提供的對輿情事件的主題提取分析結果的基礎上,開展實驗.
4.5.1 時間分片對比實驗 為了驗證本文所提出的基于數據量的動態時間分片方法比均等時長的時間分片方法更具有數據均衡性和實時性,對清洗后的數據數量進行分片統計. 對照組為每小時分片和每X小時分片,不同數據集選擇的X數值不同的原因是:在對應數據集上選取的X時間長度和本文方法在對應數據集上劃分的總數據片數最相近,在數據集A上X選擇4,劃分結果為39個時間片,在數據集B上X選擇2,劃分結果為52個時間片. 最終在兩個數據集上得到微博條數隨不同時間分片方法變化的規律如圖5和圖6所示.
從數據均衡性上來看,如圖5和圖6所示,當按每小時和每X小時切分文本時,不同時刻的數據量波動較大,特別是按每小時分片,某些凌晨時刻的博文數接近0,導致時間序列分析時會出現信息斷層問題,而本文方法每個分片的數據量分布明顯更加均衡,分片數量也更合理.
從實時性上來看,如圖5和圖6所示,每X小時分片的數據量峰值相較本文基于數據量的動態時間分片,有一定的滯后性. 例如圖5中數據集A的第32個小時,事件數據量激增,討論較為激烈,但是每4個小時分片的方法會在第36個小時后,才將32~36這4個小時的數據劃分為一個時間片進行分析,而本文基于數據量的動態時間分片方法能夠感知數據量的激增,在第32~36小時期間幾乎每個小時就會匯總劃分一個時間片,能夠及時捕捉由于事件出現新進展而出現的討論峰值.
由上述分析可知,均等時長的時間分片方法存在信息量不均等,捕捉數據激增點的滯后性明顯的缺點. 而本文提出的基于數據量的動態時間分片方法能夠使每個時間片數據量相當,信息量均衡,并且能夠及時獲取事件的數據激增點,實時性較好.
4.5.2 輿情熱點詞預測對比實驗 針對上述兩個輿情事件數據集,將本文提出的基于T-EGCN的輿情熱點內容預測方法和兩個近年的未來熱點詞預測方法以及EvolveGCN模型在網絡輿情熱點內容預測上的性能進行對比,相關對比方法描述如下.
(1) 基于word2vec的方法[12]:計算當前時間片詞語與熱點詞典詞語的word2vec詞向量間距,篩選與每個主題詞語義距離最近的前三個詞匯作為下一時間片的預測熱點詞.
(2) 基于信息熵的方法[13]:通過關鍵詞關聯規則挖掘出共現頻率較高的關鍵詞組合,引入信息熵公式計算關鍵詞組合的信息熵,選取信息熵較高的關鍵詞組合,將其作為下一時間片的預測熱點詞.
(3) EvolveGCN[5]:本文提出的T-EGCN模型的EvolveGCN層,EvolveGCN能夠學習隨著時序圖關系變化的節點嵌入,將卷積得到的節點特征輸入到全連接層中,獲得下一時間片的預測熱點詞.
實驗結果如表1所示. 由表1可知,在同一輿情數據集下,本文方法的預測精確率、召回率和F1值均為最高. EvolveGCN模型僅考慮空間拓撲結構,預測效果略低于本文加入GRU后同時考慮時間和空間特征的模型結構. 說明相較其他方法,本文方法能夠更好完成輿情事件中熱點詞的預測.
為了更加直觀地分析不同方法的預測效果,繪制數據集A在第30和40個時間片的詞云進行展示,如圖7和圖8所示. 第30個時間片事件處于爆發期,兇手剛被逮捕,此時群眾憤怒情緒高漲,輿論主要是希望判處兇手死刑、追責滴滴卸載滴滴軟件、希望社會保護女性安全和懷疑警方執法不力;第40個時間片件處于衰退期,因為事件相關人員都被懲處,事件有了交代,群眾的負面情緒得到了平復,和事件相關的微博在慢慢減少,更多的關注重點轉移到了對如何避免此類事件再發生的建議上.
從表1可以看出,基于word2vec的方法的精確率偏低,但是召回率比較高. 這是因為該方法會為第t個時間片的每個熱點詞尋找第t+1個時間片的三個預測熱點詞進行對應,預測中存在很大冗余,所以精確度較低而召回率較高. 這一點也可以從圖7b和圖8b中可以看出,基于word2vec的方法能夠找到較多真實的熱點詞,但是其預測的熱點詞數量遠遠多于真實的熱點詞. 造成該情況的主要原因可能是該方法主要研究科技文獻領域的熱點詞預測,其預測工作通常以年為單位,熱點詞會有長期逐漸替代的過程,通過領域專家進行人工篩選,可以較為準確地去除冗余詞. 而輿情事件變化時間間隔短,隨著事態發展,熱點內容隨時間的波動較大,難以得到領域專家的先驗知識對預測得到的熱點詞進行篩選,所以該方法在輿情熱點詞預測上的性能不佳.
同時,從表1可以看出,基于信息熵的方法的精確率和召回率都較低. 通過分析圖7c和圖8c的熱點詞分布,可以推測出基于信息熵的方法在預測時通常能抓住最可能延續熱度的詞語,即第t個時間片信息熵最高的1~3個詞組實際上確實非常可能是第t+1個時間片的熱點詞,例如長期被提及的“司機”等詞,以及第30個時間片前剛發生的罪犯被逮捕一事. 但是當需要預測的范圍變大時,該方法的性能急劇下降. 造成該情況的主要原因可能是該方法主要研究流行病事件的熱點詞預測,流行病事件的輿情周期較長,相比本文的需求,其分片的時間跨度較大,如10 d為一個時間片,所以該方法并未考慮多個前序時間片信息對熱點詞的影響,僅考慮了前一個時間片詞語之間的關聯關系,導致其在預測短期輿情事件時,對次級重要的詞語的預判能力不足.
而本文方法中,T-EGCN模型會對每個候選熱點詞進行單獨判斷,所以相比基于word2vec的方法,冗余詞較少;同時本文方法使用GRU考慮前序多個時間片的詞語信息,在預測時信息量更加豐富,所以相比基于信息熵的方法,對次級重要的詞語的預判能力更強.
5 結 論
本文提出一種基于T-EGCN的輿情熱點內容預測方法. 根據社交媒體上針對特定突發輿情事件的討論文本,獲得每個時間片中事件的熱點詞,通過熱點詞的變化反映大眾對該事件的關注重心的變化. 該方法將熱點詞作為預測的對象,利用候選熱點詞之間的語義相似性和共現性關系,為每個時間段都構建一個對應的候選熱點詞相關關系圖,再使用EvolveGCN與GRU進行時間維度和空間維度上的聯合分析,預測下一時間片的熱點詞. 實驗結果表明本方法能夠對網絡輿情事件的熱點詞進行有效預測,在輿情時間數據集上,模型預測精度高于近年的熱點詞預測方法,能夠實現在特定輿情事件發展過程中對具體熱點內容進行預判.
參考文獻:
[1] 高承實, 陳越, 榮星, 等. 網絡輿情幾個基本問題的探討[J]. 情報雜志, 2011, 30: 52.
[2] 楊志, 祁凱. 基于 “情景-應對” 的突發網絡輿論事件演化博弈分析[J]. 情報科學, 2018, 36: 30.
[3] 彭思琪, 周安民, 廖珊, 等. 基于圖注意力網絡的輿情演變預測研究[J]. 四川大學學報: 自然科學版, 2022, 59: 013004.
[4] 程新斌. 對重大輿情與突發事件輿論引導研究的分析與對策[J]. 西南民族大學學報: 人文社會科學版, 2022, 43: 235.
[5] Pareja A, Domeniconi G, Chen J, et al. Evolvegcn: Evolving graph convolutional networks for dynamic graphs [C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020.
[6] 游丹丹, 陳福集. 我國網絡輿情預測研究綜述[J]. 情報科學, 2016, 34: 156.
[7] 史偉, 薛廣聰, 何紹義. 情感視角下的網絡輿情研究綜述[J]. 圖書情報知識, 2022, 39: 105.
[8] 張虹, 鐘華, 趙兵. 基于數據挖掘的網絡論壇話題熱度趨勢預報[J]. 計算機工程與應用, 2007, 43: 159.
[9] 杜慧, 郭巖, 范意興, 等. 基于因果模型的主題熱度計算與預測方法[J]. 中文信息學報, 2016, 30: 50.
[10] 崔彥琛, 張鵬, 蘭月新, 等. 面向時間序列的微博突發事件衍生輿情情感分析研究——以“6. 22”杭州保姆縱火案衍生輿情事件為例[J]. 情報科學, 2019, 37: 119.
[11] 程鐵軍, 王曼, 黃寶鳳, 等. 基于CEEMDAN-BP模型的突發事件網絡輿情預測研究[J]. 數據分析與知識發現, 2021, 5: 59.
[12] 岳麗欣, 劉自強, 胡正銀. 面向趨勢預測的熱點主題演化分析方法研究[J]. 數據分析與知識發現, 2020, 4: 22.
[13] Li J, Tang H, Tan H. Research on the evolution and prediction of Internet public opinion of major pandemics-Taking the COVID-19 pandemic as an example [J]. J Phys, 2021, 1774: 012038.
[14] Zhao L, Song Y, Zhang C, et al. T-gcn: A temporal graph convolutional network for traffic prediction [J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21: 3848.
[15] Comito C, Forestiero A, Pizzuti C. Bursty event detection in Twitter streams[J]. ACM T Knowl Discov D, 2019, 13: 1.
[16] 張孝飛, 陳航行, 張春花. 基于語義概念和詞共現的微博主題詞提取研究[J]. 情報科學, 2021, 39: 142.
[17] Huang J, Peng M, Wang H, et al. A probabilistic method for emerging topic tracking in microblog stream [J]. World Wide Web, 2017, 20: 325.
[18] 丁晟春, 劉笑迎, 李真. 融合評論影響力的網絡輿情熱點主題演化研究[J]. 現代情報,? 2021, 41: 87.
[19] 劉定一, 沈陽陽, 詹天明, 等. 融合微博熱點分析和LSTM模型的網絡輿情預測方法[J]. 江蘇大學學報: 自然科學版, 2021, 42: 546.
[20] 曾慶田, 胡曉慧, 李超. 融合主題詞嵌入和網絡結構分析的主題關鍵詞提取方法[J]. 數據分析與知識發現, 2019, 3: 52.
[21] 蘇曉慧, 張曉東, 胡春蕾, 等. 基于改進TF-PDF算法的地震微博熱門主題詞提取研究[J]. 地理與地理信息科學, 2018, 34: 90.
[22] 張孝飛, 陳航行, 張春花. 基于語義概念和詞共現的微博主題詞提取研究[J]. 情報科學, 2021, 39: 142.
[23] Yin J, Wang J. A dirichlet multinomial mixture model-based approach for short text clustering[C]//Proceedings of the 20th ACM SIGKDDInternational Conference on Knowledge Discovery and Data Mining. [S.l:s.n.], 2014: 233.
[24] Mazarura J, De Waal A. A comparison of the performance of latent Dirichlet allocation and the Dirichlet multinomial mixture model on short text[C]//Proceedings of the 2016 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference. [S.l]:IEEE, 2016: 1.
[25] 馬思丹, 劉東蘇. 基于加權 Word2vec 的文本分類方法研究[J]. 情報科學, 2019, 37: 38.
引用本文格式:
中 文: 文雅, 楊頻, 廖珊, 等. 基于時間演化圖卷積網絡的輿情熱點內容預測[J]. 四川大學學報: 自然科學版, 2023, 60: 033001.
英 文: Wen Y, Yang P, Liao S, et al. A temporal evolving graph convolutional network for Public opinion prediction in emergencies [J]. J Sichuan Univ: Nat Sci Ed, 2023, 60: 033001.
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
