面向專利文本的實體識別研究綜述
2023-04-29 15:43:36李嘉茜張麗瑋
信息系統工程 2023年2期
關鍵詞:深度學習
李嘉茜 張麗瑋

摘要:目前,專利數量快速增長,單純依靠人工進行專利查閱,很難及時獲取專利中的創(chuàng)新資源。實體作為知識的一種,是目前最能直接體現專利的知識。實體識別除了專利獨有的技術詞、功效詞抽取,還有在其他領域通用的命名實體等信息的提取。并且隨著計算機技術的創(chuàng)新,大量學者將現代科學技術方法投入到專利文本知識挖掘中。因此,如何從海量專利文本中挖掘有價值的知識成為專利領域研究的新契機。旨在總結專利文本實體種類以及其抽取方法,并從研究對象、技術過程等角度來闡述現狀,探索專利文本實體識別工作的新方向。
關鍵詞:專利文本;實體識別;深度學習
一、前言
隨著知識產權在企業(yè)人心中地位的上升,人人更加注重知識產權保護,所以大量的專利信息充斥著網絡。據知識產權局的統計,2022年上半年我國實用新型專利就達到了147萬。除了數量的龐大,專利數據也因其更易獲取、專業(yè)權威而被選中作為知識庫來源。因此,有關人員需要花費大量時間閱讀和分析專利文獻,獲取專利中蘊藏的知識[1],這與如今快節(jié)奏時代的高效率目標存在矛盾。所以面對大量的專利文本,如何更高效的獲取專利中的知識信息是一個值得關注的問題。
實體識別是知識抽取的一種,也是關系抽取,領域詞典構建的前提。并且專利文本中的實體是專利的顯著標識,可以快速鎖定研究領域。隨著計算機的發(fā)展,實體識別技術也多樣化,目前多數研究都是使用機器自主學習的方法來提取專利實體。專利實體的提取,不僅可以提高閱讀者獲取知識的效率,還可以在當前專業(yè)領域構建知識圖譜。本文將分析、利用現有文章,對現有論文進行梳理與總結,并按照專利實體研究對象和技術實現方法這兩個維度進行分析。
二、實體識別研究對象
專利類的實體知識可以分為通用實體和專業(yè)實體。通用實體是指在專利領域中通用的實體知識,不具備領域特性。比如董文斌[2]在開放領域的實體識別包括公開號、申請人、分類號、發(fā)明人等實體。專業(yè)實體與之相反,包括:術語[3]、關鍵詞[4]、命名實體。其中術語是專利中出現最多的詞語,在不同領域的專利文本中,術語是區(qū)分各個領域的標志。比如孫甜[5]在新能源領域提出的術語“新能源汽車車門、連接板”。除了術語實體,關鍵詞抽取也常常作為知識進行研究。通過關鍵詞可以快速獲取文本主題,方便讀者檢索與理解。文獻[7]利用專利文本構建領域背景,利用計算機去學習背景知識,從而做到可以自動識別關鍵詞的效果。除了上述幾種專業(yè)實體,命名實體類也是重點研究對象。在專利領域中需要考慮所需的處理任務來分析實體種類,比如董文斌[2]專利中將實體分為:零部件名、形狀構造和功效詞。本文將上述實體進行分類,如表1所示。
三、實體識別關鍵技術
但隨著大數據時代的到來,傳統以規(guī)則提取的方法在實際應用中的通用性差,目前只用來輔助主流方法來提高整體的準確率。因此本文將以基于統計學習和機器學習這兩種技術進行分析。
(一)基于統計學習
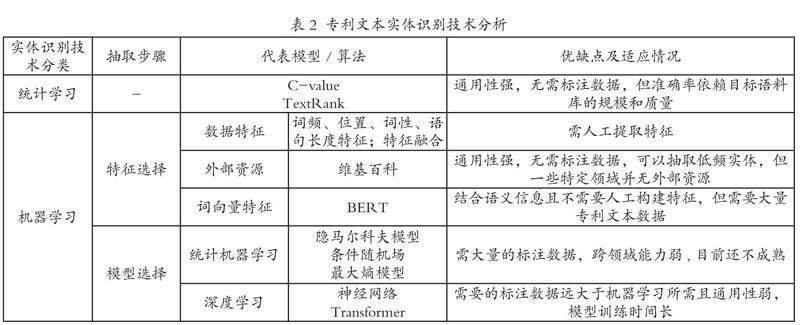
除了最早的人工提取規(guī)則方法,更為先進的是使用統計學方法C-value,該方法主要依靠詞頻特征來選擇專利術語,但是對于詞頻低的專利術語不能做到很好的篩選。俞琰等人[6]在術語抽取的基礎上,還加入了論文關鍵詞知識的特征,將依靠詞頻的C-value方法準確度提高了26%[7]。還有研究者以文本外部的數據作為輔助來自動抽取專利文本中的知識。Yadav[8]利用TextRank算法,學習網站的標注標簽功能,將標簽作為外部知識引入到文本抽取中。此外,比較多的文章是利用維基百科里面的詞條作為獨立概念,再通過統計權重來鏈接各個知識概念,利用知識間的語義抽取關鍵詞[9]。基于統計學習的方法通用性強,無需標注數據,但是準確率依賴目標語料庫的規(guī)模和質量,需要進一步改進。
(二)基于機器學習
針對基于機器學習的實體識別技術,本文將按照特征提取、模型訓練這兩步進行分析。
1.特征抽取
特征抽取是將非結構化文本結構化的重要步驟,在模型訓練前都需要對目標文本進行特征提取。根據文本特征的不同,可以結合詞頻特征、位置特征、詞性特征等。除了按照詞語粒度進行提取,針對于語句等級的特征提取也是很有必要的。如語句長度特征和語義特征:馬建紅[10]將語義角色標注作為一個提取有效特征的工具,借助Chinese PropBank(CPB)標注方式來對專利文本進行句法分析。上述特征的提取方式都是人工抽取,耗時也更依賴人工標注。而使用詞向量不僅可以表示整個句子特征,還省去了人工提取特征的步驟。最初的詞向量是基于計算機的隨機抽取,盡管經模型訓練可以較好地表達詞義,但是不能與其他任務通用。因此,谷歌在2018年發(fā)明了BERT預訓練模型[11]。使用預訓練模型自動創(chuàng)建特征值,很好的保留了語義之間的關系,有更好的泛化能力[12]。由于特征是為了更好的將非結構化文本結構化,所以為了更好的表達專利文本,董文斌[2]提出了特征融合,即將BERT訓練后的特征與句子特征、詞語特征等信息按照對應權重相加,再投入到后續(xù)模型中。使得該方法在在實體識別中準確率提高了8個百分點[5]。雖然詞向量省去人工標注的步驟,但是該特征的提取需要大量數據做準備,對于領域數據量低的文本不友好。
2.模型選擇
在對非結構化的專利文本進行特征提取后,下一步就該應用到模型中進行訓練。下面將模型訓練分為統計機器學習模型和深度學習模型。
(1)統計機器學習模型:在機器學習算法中,賴鴻昌[13]使用了CRF模型(conditional random field,條件隨機場)來識別專利中化合物和生物實體,組合了三種特征:字符特征、例模式特性、上下文特征。這一模型保留了隱馬爾科夫模型的優(yōu)點,也避免了最大熵馬爾科夫模型的基本限制。基于統計機器學習的模型跨領域能力弱,目前還不成熟,需要進一步優(yōu)化。
(2)深度學習模型:在當前知識抽取中,實體識別是使用深度學習最多的方向。它包括在一個詞序列中檢測指向一個預定義實體的詞匯單位,從而確定它所指向的實體的類型。而深度學習方法就是對目標文本中的實體進行分類,并且克服了采用傳統統計機器學習方法提取知識的缺點。在模型訓練過程中,Lstm[14](長短期記憶網絡)是研究者常用的神經網絡模型。Bilstm(雙向長短期記憶網絡)是LSTM的變體,可以從前后兩個方向進行記憶,對長句子有更好的表現。Deng[15]在LSTM基準模型的基礎上,加入了CRF條件隨機場模型,用于解決實體標注順序的問題,取得了不錯的效果。但是原之安等人[16]驗證了BiLSTM對實體識別模型的負向影響:即在同樣的CRF模型基礎上使用Bilstm,會使得F1值降低。由此可見,面對不同的專利文本,應該使用有針對性的方法來提高模型效果,而不是簡單的疊加。除此之外,Transformer模型作為自注意力機制的升級版,也對專利文本的實體識別起到積極作用:如王宇暉[17]在專利數據集上驗證了Transformer模型相比BiLSTM模型準確率提高了4個百分點。基于深度學習的實體識別方法可以無需人工篩選實體特征,不僅降低了人工成本,還有助于將專利實體和上下文相結合。但該方法依賴于復雜的深度學習模型,需要非常大量的標注數據或標注句子以及較長的訓練時間,且模型的跨領域泛化能力較弱。不過,總體而言,基于深度學習的抽取方法仍表現出了不錯的性能,該方法將會成為接下來幾年研究者的熱點研究方向。
綜上,表2 從實體識別技術分類、代表模型/算法、主要優(yōu)缺點及適用情況等宏觀角度對專利實體識別方法進行了對比分析。
四、結語
在技術方面,從特征眾多的統計機器學習方法,再到特征自動抽取的深度學習方法,模型的效率、準確率也在進一步提高。但是目前的技術提升都是在特征提取堆積、模型疊加、規(guī)則糾正這幾方面改進,學者很難跳出這個局限。而尤其針對專利文本,缺少一種針對專利文本特點而創(chuàng)新的方法[18]。畢竟專利文本在數量、格式、內容上與其他文本都有很大的不同,這一點也是本人在今后研究者需要探索的。
在應用方面,從整個數據信息來的角度看,專利文獻作為眾多科學技術文獻類型的一種,擁有眾多的領域分支,盡管實體識別在準確率上進一步提升,但是文本標注是不可避免的,每一個專利領域有不同的特點,所以在通用領域的應用值得進一步挖掘。在后續(xù)應用中,對關系知識的抽取以及如何將各領域等其他來源的知識與知識圖譜融合起來,形成內容更為豐富、內涵更為深入、時效性更強的知識圖譜是值得關注的一個研究方向。H
參考文獻
[1]馬建紅,張明月,趙亞男.面向創(chuàng)新設計的專利知識抽取方法[J].計算機應用,2016,36(02):465-471.
[2]董文斌,戰(zhàn)洪飛,余軍合,等.機械產品專利知識的提取和應用[J].機械制造, 2021,59(08):1-8.
[3]俞琰,陳磊,姜金德,等.融合論文關鍵詞知識的專利術語抽取方法[J].圖書情報工作,2020,64(14):104-111.
[4]俞琰,朱晟忱.融入限定關系的專利關鍵詞抽取方法[J].數據分析與知識發(fā)現,2022,6(10):57-67.
[5]孫甜,陳海濤,呂學強,等.新能源專利文本術語抽取研究[J].小型微型計算機系統,2022,43(05):950-956.
[6]張芳叢,秦秋莉,姜勇,等.基于RoBERTa-WWM-BiLSTM-CRF的中文電子病歷命名實體識別研究[J].數據分析與知識發(fā)現,2022,6(Z1):251-262.
[7]何陽宇,晏雷,易綿竹,李宏欣.融合CRF與規(guī)則的老撾語軍事領域命名實體識別方法[J].計算機工程,2020,46(08):297-304.
[8]Yadav V, Bethard S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models[J].2019.
[9]Grineva M P, Grinev M N, Lizorkin D A. Extracting key terms from noisy and multitheme documents[C]// The Web Conference. ACM,2009.
[10]馬建紅,張明月,趙亞男.面向創(chuàng)新設計的專利知識抽取方法[J].計算機應用,2016,36(02):465-471.
[11]Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J].2018.
[12]李建,靖富營,劉軍.基于改進BERT算法的專利實體抽取研究——以石墨烯為例[J].電子科技大學學報,2020,49(06):883-890.
[13]賴鴻昌,朱禮軍,徐碩.面向專利的化合物和生物實體識別系統[J].情報工程,2015,1(04):95-103.
[14]Hochreiter, S. Schmidhuber, J.Long Short-Term Memory. Neural computation, 1997,9,1735-1780.
[15]Deng Na, Fu Hao, Chen Xu. Named Entity Recognition of Traditional Chinese Medicine Patents Based on BiLSTM-CRF[J].WIRELESS COMMUNICATIONS & MOBILE COMPUTING,2021.
[16]原之安,彭甫镕,谷波,等.面向標注數據稀缺專利文獻的科技實體識別[J].鄭州大學學報(理學版),2021,53(04):61-68.
[17]王宇暉,杜軍平,邵鎣俠.基于Transformer與技術詞信息的知識產權實體識別方法[J].智能系統學報,2023,18(01):186-193.
[18]Puccetti Giovanni, Chiarello Filippo, Fantoni Gualtiero . A simple and fast method for Named Entity context extraction from patents[J]. Expert Systems With Applications,2021,184.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
