多源異構區塊鏈數據質量評估模型*
2023-05-12 02:25:32宋寶燕單曉歡王俊陸
計算機與數字工程 2023年1期
張 冉 宋寶燕 單曉歡 王俊陸
(遼寧大學信息學院 沈陽 110036)
1 引言
區塊鏈[1~3]是一種新型分布式技術,其基于塊鏈式結構、共識算法和智能合約[4~5]實現了數據信息從記錄到傳輸再到存儲的過程,且節點間無需第三方信任機構的約束,實現了無信任關系[6~7]節點之間的價值通信。國內外大型企業單位如谷歌、百度、阿里巴巴等都建立了自己的企業聯盟區塊鏈系統。目前區塊鏈中存儲的企業經營活動信息大多來自于不同的行業和機構,這使得信息質量參差不齊,歧義性較大,同時受公司自身信譽度及環境制約,無法保證區塊中數據的準確性和價值,因此,在創建區塊時,會出現一系列問題。傳統的評估方法沒有利用區塊鏈全程留痕、不可篡改、可追溯的特征,評估效率及準確性均較低,導致企業用戶及相關監管部門無法快速篩選出滿足需求的區塊鏈,也無法建立統一的分析[8~9]模型。因此,評估區塊鏈的質量十分有必要。
針對這些問題,本文提出一種面向企業經營活動的多源異構區塊鏈數據質量評估模型,實現對經營活動信息一致性、可信度以及價值的高效評估。本文主要貢獻如下:
1)針對區塊鏈中企業經營活動異構信息一致性差的問題,提出CEKQRL 模型,用三元組的形式表示企業經營活動信息,并引入注意力機制[10]對三元組和活動類別進行關聯;同時還考慮了實體上下文信息對一致性評估的影響,進而構建上下文結構圖模型,進一步提高區塊鏈的相似度計算效率。
2)在此基礎上,針對區塊鏈中企業經營活動信息的可信度評估困難問題,綜合考慮了信息源、信息評價的可信度,然后將這兩部分的表征結果進行融合[11]。
3)針對區塊鏈中活動信息的價值評估問題,提出了一種信息價值評估方法,通過信息量的大小表述信息的不確定度,進而衡量區塊中企業經營活動的價值量。最后,綜合區塊間語義相似度、區塊鏈內容評估以及價值評估,得出面向企業經營活動的多元異構區塊鏈數據質量評估模型。
2 相關工作
目前,許多學者對數據質量評估方法進行了深入研究,并取得了一定的研究成果。
在區塊鏈信息一致性評估方面,文獻[12]提出一種結構化梯度樹提升(SGTB)算法進行實體消歧,該方法在跨領域的評估中有較好的性能,但它忽略了實體的上下文信息對計算過程的作用;文獻[13]提出一種基于因子圖的不一致記錄對計算方法,該方法對實體進行解析,但未關聯實體表示與其所屬類別;文獻[14]提出具有多視角關注的神經網絡,從而捕捉更多的信息特征,但該方法未關注實體上下文信息。
在區塊鏈信息可信度評估方面,文獻[15]提出一種綜合信譽計算方法,整合了多維度數據,但卻只注重相關評價而未重視信息源這一因素;文獻[16]提出基于多源異構信息融合的數據可信度評估方法,該方法在提高計算收斂性方面效果較好,但忽略了信息內容的可信度;文獻[17]提出一種用于用戶生成內容可信度評估的監督機器學習方法,但該方法只關注相關評論信息,忽略了對信息內容及其來源的關注。
在區塊鏈信息價值評估方面,文獻[18]提出一種基于置信度的可靠性評估方法,該方法能準確地得到數據所屬分布,但忽略了數據本身的價值所在;文獻[19]構建VW&ICM 計算模型進行風險評估,該模型削弱了主觀因素對評估結果的影響,但忽略了數據整體價值信息;文獻[20]從主觀和客觀兩個方面確定總體權重和評估標準,克服了單一模型的限制,但卻只適用于信息不確定性較大的情況。
綜上所述,本文針對區塊鏈質量評估方法的不足之處,基于企業經營活動信息的一致性、可信度及價值三個方面,提出了面向企業經營活動的多源異構區塊鏈質量評估模型。
3 基于上下文信息的區塊間語義相似度計算
由于區塊鏈中企業經營活動信息多來自于不同數據源,導致異構信息表征方式不一致,如數據格式、實體名稱等,這使得區塊鏈中存儲的經營活動信息具有歧義性,數據質量較低。針對該問題,本文通過實體間語義相似度比較來評估區塊鏈數據的一致性。
3.1 基于CEKGRL模型的區塊實體表示
本文提出基于CEKGRL的模型,將區塊實體表示為三元組形式。此外,本文還考慮了三元組信息與其所屬的類別,并使用注意力分數表征其關聯程度。
3.1.1 三元組信息結構
根據CEKGRL模型,本文將企業經營活動信息定義為G=(E,R,S)形式,其中E、R分別代表企業實體集和關系集,三元組集合用S?E×R×E表示,(h,r,t)代表一個由企業名、活動方向以及活動信息構成的三元組,c為類別。CEKGRL 模型的整體架構如圖1所示。

圖1 CEKGRL模型整體架構
圖中的hs、ts代表基于結構的三元組表示,hc、tc代表基于類別的三元組表示,a表示注意力分數,本文將融合兩種表示類型的能量函數定義如式(1)所示:
其中,β表示基于類別表示的權重。
3.1.2 關聯信息類別與活動表示
某企業實體名稱可能屬于不同的類別,基于此,本文通過注意力分數值表明關系與類別之間的相關性。
首先,利用CEKGRL 模型將關系r、類別c視為query向量、key向量和value向量,用矩陣的方式表示注意力。將企業關系與其對應的活動類別以關系矩陣R和類別矩陣C的方式進行拼接。然后,引入權重矩陣WQ、WK和WV,對其進行訓練,并對矩陣進行相乘操作,運算結果和注意力分數如式(2)和(3)所示:
式中,dk為矩陣的維度,att(C,R)值越大,表明與關系r越可能屬于類別c。
3.2 基于上下文信息的相似度計算
在區塊鏈企業經營活動信息中,單一企業實體的名稱指代可能存在“一對多”映射關系,使信息表達具有歧義性,導致相似度計算的準確率較低。本文引入上下文信息,構建上下文結構圖模型進行區塊之間相似度的計算。
3.2.1 上下文信息關聯圖模型構建
本文以企業實體名稱、經營交易活動為例進行實體歧義性計算。把某企業實體的上下文關系描述為實體相關圖模型G=(V,E),V、E分別代表頂點集和邊集。模型的構造分為以下兩步。
1)頂點集合構造
圖模型中的各頂點由企業經營活動信息的上下文構成,其上下文信息ci的可信程度用置信度(Confidence Measure,CM)衡量,置信度的計算如式(4)所示:
其中,ResultScore(ci)是基于知識圖譜得出的匹配分數,值的大小反映了上下文信息的準確程度。
2)邊集合構造
圖模型的邊由該企業活動所對應上下文信息的路徑關聯度組成。本文利用信息A到信息B的前向最短路徑FShortPath和后向最短路徑BShortPath判斷兩個節點之間的最短路徑,并將最短路徑轉化為節點之間的關聯程度,計算如式(5)所示:
節點之間的關聯程度計算如式(6)所示:
從該公式可得,節點間的路徑越短,其關聯程度越高。
3.2.2 塊間相似度計算
本文對企業經營活動信息的實體名稱、具體內容進行語義相似度的計算,SimText(A,B)代表區塊A與B的語義相似度,采用余弦相似度計算如式(7)所示:
歸一化處理如式(8)所示:
最后,取首塊與其他區塊的相似度平均值作為最終的一致性計算結果,計算如式(9)所示:
其中,SimText(A,i)表示首塊與其他區塊的相似度度量結果。
4 區塊鏈質量評估模型構建
評估模型由區塊鏈一致性、信息可信度以及價值綜合衡量,并根據重要程度賦予不同的權重。
4.1 基于可信度理論的區塊鏈內容評估
本文通過綜合表征企業經營活動的信息源和信息評價的可信度來表示區塊鏈內容的可信度。
4.1.1 基于源的信息可信度表征1)信息頁面的可信度
通過企業經營活動信息所處頁面中各鏈接是否可達以及所達頁面是否可用進行信息頁面的可信度度量。計算如式(10)所示:
其中,A、B、C分別表示頁面中可達鏈接、不可達鏈接以及可達不可用鏈接的集合。
2)信息發布者的可信度
本文將網絡中的用戶看為一個整體,用戶總數記為N。用戶的三種狀態如下:
(1)不知者(ignorant)。對于已發布的信息,用戶無法判斷信息真假的用戶。
(2)信息可信用戶(believed)。對于已發布的信息,根據自身的知識積累,認為發布信息是可信的用戶。
(3)信息不可信用戶(unbelieved)。對于已發布的信息,根據自身的知識積累,認為發布信息是不可信的用戶。在進行信息傳播時,各用戶的狀態轉換如圖2所示。

圖2 節點間狀態轉化
對于已發布的信息,首次接觸該信息的用戶被稱為不知者,經過t時間后,該用戶認為信息可信與不可信的概率分別為α和β。
設在t時刻后,認為發布信息是可信的用戶又認為信息不可信的概率為γ,此時用戶的狀態改變;反之為δ。信息交互規則如式(11)所示:
方程組中的I(t),B(t),U(t)表示t時刻各類用戶的比例。該發布者的可信度計算如式(12)所示:
3)源的可信度表征結果融合
將發布平臺、頁面的可信度表征結果進行融合,計算如式(13)所示:
4.1.2 基于評價特征的信息可信度表征
當計算評價表征值時,一般分為兩步:第一步是計算該條評論是否與該信息相關;第二步是進行相關表征傾向值的計算。
1)評價與信息的相關性
評價與信息的相關性具體計算如式(14)所示:
其中,I是某條信息,C為信息中的某條評價,w是評價中的某個詞,用t表示主題詞,即用某信息中出現各詞的概率來衡量評價與信息是否相關。
2)相關評價表征傾向
對信息的評價計算表征傾向值如式(15)所示:
其中,w(R)為評價R的情感傾向得分,p(ai)為句子ai在評價R中所處的位置,count(a|R)為評價中所包含的句子數目。
最后,用信息源的可信度和信息評價的可信度來綜合衡量區塊鏈中存儲的企業經營活動信息的可信度,并賦予不同的權重,計算如式(16)所示:
由于評價具有主觀性,不確定性較大,因此信息源的可信度所占比值最大,信息評價次之。
4.2 基于信息量的區塊鏈價值評估
對區塊鏈價值的評估,本文采用計算其信息量的方法。該方法利用區塊鏈中所包含信息量的多少來評估區塊鏈的價值,其相關性質如下:
性質1信息量的值為非負值,并且值的大小直接反映了信息量的多少。
性質2信息量本身是一個值,可直接進行相加。
區塊鏈中的各個區塊都可視為一種離散信源,某條鏈X的取值集合及其概率空間如式(17)所示:
其中,pi代表區塊xi中活動信息出現的概率,區塊鏈總的信息量Validity計算如式(18)所示:
Validity的最終計算值表明這些企業經營活動信息所在區塊鏈價值量的多少,對于給定的區塊鏈,其價值量的大小可以由信息量的值來反映,值越小,信息量越少,區塊鏈的價值效用越小,反之該區塊鏈的價值效用越大。
4.3 區塊鏈質量評估模型構建
為了評估多源異構區塊鏈的質量,本文用企業經營活動信息的一致性、可信度以及價值三者的加權值來度量區塊鏈的綜合質量。具體的評估模型如式(19)所示:
區塊鏈價值是衡量區塊鏈質量的重要指標,區塊鏈所含價值越大,該區塊鏈的應用價值越大,其次是信息的可信度,最后是信息的一致性,因此權重γ>β>α。
5 實驗結果與分析
實驗平臺為Intel Core i7-12700 處理器,16GB內存和64 位Windows10 操作系統。采用Block?chainSpider 數據收集工具箱中的數據作為本次實驗的數據集,該工具箱旨在收集公鏈數據,包括交易子圖、標簽數據、區塊的內部交易以及轉賬記錄等,本次實驗大約使用了10 萬條數據,區塊中數據的詳細信息如表1 所列。本文從評估模型一致性、準確性、價值以及效率三個方面進行模擬實驗,用本文所建模型(DQAM)與AHP、DSMM 等模型進行對比。

表1 區塊數據
5.1 模型一致性對比
本節在表1 的數據集上評估各模型的一致性,其中橫軸代表數據條數,縱軸代表一致性評估質量,通過結構化梯度樹提升(SGTB)算法、基于因子圖的不一致記錄對消歧(DIBFM)、多視角關注的神經網絡消歧(NDMP)方法和本文所提的基于上下文信息的相似度計算方法(SCBCI)進行對比,實驗結果如圖3所示。

圖3 一致性評估
由圖3 可知,隨著數據量增大,與現有方法相比,本文所提的一致性評估方法的評估質量逐步提高,這是因為該方法對區塊信息采取三元組表示方法,并把這些三元組與某些類別進行關聯,同時又充分考慮了實體的上下文信息,因此能獲得較高的一致性評估質量。
5.2 準確性評估對比
本節驗證基于可信度理論的區塊鏈內容評估(CEBT)方法的效率,各方法在不同數據集上的準確性評估質量對比如圖4所示。

圖4 準確性評估
由圖4 可知,CEBT 方法的平均評估質量高于其他方法。對比方法是多源異構信息的數據可信度評估(MHIF)以及用戶內容可信度評估的(SML)方法。
5.3 價值評估對比
實驗通過模擬采用本文所提的信息量方法(VIS)與基于數據分布的價值評估方法(VADD)、VW&ICM 計算模型的價值評估質量,橫坐標表示數據量多少,縱坐標表示信息價值的評估質量,實驗結果如圖5所示。

圖5 價值評估
由實驗結果可發現,本文所提的基于信息量的方法評估質量較高。其主要原因是該方法關注數據價值本身而非其分布、規律等次要因素,因此該方法直觀、明了、效率較高。
5.4 模型效率對比
本節比較各質量評估模型的運行效率,橫坐標代表區塊鏈中實體數據集,縱坐標表示各模型運行所需時間,實驗結果如圖6所示。
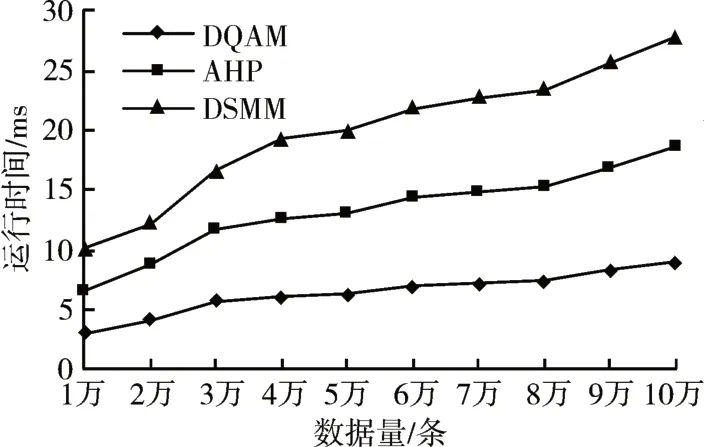
圖6 模型效率對比
由結果可知,AHP、DSMM 方法的平均運行時間在10ms~15ms左右,本文提出的區塊鏈數據質量評估模型(DQAM)評估時間在5ms 左右,并且隨著數據量的增多,DQAM 模型的評估時間基本波動不大。
6 結語
本文提出了一種多源異構區塊鏈質量評估模型,綜合考慮了企業經營活動信息的一致性、可信度以及價值。一致性評估中著重考慮了實體的上下文信息對實體之間相似度比較的影響;信息可信度評估對企業經營活動信息源、信息評價的可信度表征結果進行融合;價值評估采用信息量衡量區塊鏈的總價值。最后,通過實驗驗證了本文所提方法的有效性,為區塊鏈的質量評估提供了一條有效的途徑。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中老年保健(2021年2期)2021-08-22 07:31:10
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
海峽姐妹(2018年3期)2018-05-09 08:20:40
中華手工(2017年2期)2017-06-06 23:00:31
燕山大學學報(2015年4期)2015-12-25 02:19:49
中外會展(2014年4期)2014-11-27 07:46:46
