基于基音周期軌跡的連續漢語語音切分技術研究*
2023-05-12 02:26:16張二華
計算機與數字工程 2023年1期
關鍵詞:信號
高 橋 張二華
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
連續語音切分技術,就是從輸入的語音信號流中,自動找出各種段落的始末點位置。連續語音切分技術不僅對連續語音識別有著至關重要的作用,也能夠應用于語音分離、音頻制作等領域。
語音邊界的標注是語音識別的重要環節。一直以來,隱馬爾科夫模型(HMM)在語音識別領域有著廣泛的應用[1~2]。此類模型通過Viterbi解碼或幀同步算法進行解碼并得到音素邊界[3],是語音識別由孤立詞識別發展為連續語音識別的關鍵里程碑。但HMM 模型沒有利用語音幀的上下文,忽略了語音信號的連續性,實際應用的性能較為有限。
隨著深度學習的不斷發展,端到端語音識別模型拋棄了傳統的HMM 框架,旨在一步實現語音信號的輸入與解碼識別[4]。但端到端語音識別模型需要大量標注的音素進行訓練,訓練成本較高。如果能夠實現準確可靠連續語音切分算法,就可以替代HMM 實現音素邊界的界定,從而提升語音識別系統的性能,也可以應用于語音分離等領域。
傳統的端點檢測技術[5~6]可用于連續語音的初步切分,將語音數據劃分為語音段和非語音段,然而端點檢測難以實現濁音與非濁音的判別,切分精度達不到連續語音識別系統的需求。相關研究通過分析語音信號的語譜圖[7]、共振峰結構[8]、頻譜熵[9]、倒譜特征[10]等,實現連續語音切分,但大多存在穩定性差、調參困難等缺點,同時缺少噪聲環境下的性能測試,難以滿足語音識別系統的應用需求。
為了實現一種低成本、低耗時、高精度,同時具有一定噪聲魯棒性的連續語音切分算法,本文依據漢語的發聲原理,以及語音信號的時域、頻域、倒譜域特征,實現了連續漢語語音切分算法。聽覺實驗與數據對比表明,算法具有較好的準確性,以及較好的噪聲魯棒性,能夠滿足語音識別系統的應用需求。
2 語音信號的特征提取
2.1 語譜圖
語音信號具有短時平穩性,任何語音信號的分析都要基于短時的基礎,因此需要采用交疊分幀的方法[11],將語音信號劃分為多個語音幀,使每一幀語音信號都具有短時平穩的特征。
分幀過程中常用的窗函數有矩形窗、Hanning窗和Hamming窗。矩形窗的頻譜側漏相對較大,因此常用后兩種窗函數進行加窗分幀處理。本文使用窗函數為Hamming窗。
分幀后,可以通過短時傅里葉變換(STFT),得到每一幀語音信號的短時譜[12]。將第n 幀語音信號xn代入式(1),可以得到這一幀信號的短時譜Xn(ω)。
其中N 為幀長。通過短時傅里葉變換得到的短時譜,根據式(2)可以轉化為振幅譜L。
其中,R為Xn(ω)的實部,I為Xn(ω)的虛部。將振幅譜轉化為灰度,振幅越大,灰度值越小,顏色越深(灰度值為0 代表黑色);反之振幅越小,灰度值越大。按照時間順序繪制每一幀的振幅譜,即可得到語譜圖。
圖1 為語音數據“那年正月新春”的語譜圖(上)和對應的時域波形(下)。黑色線段代表人工標記的音節邊界。
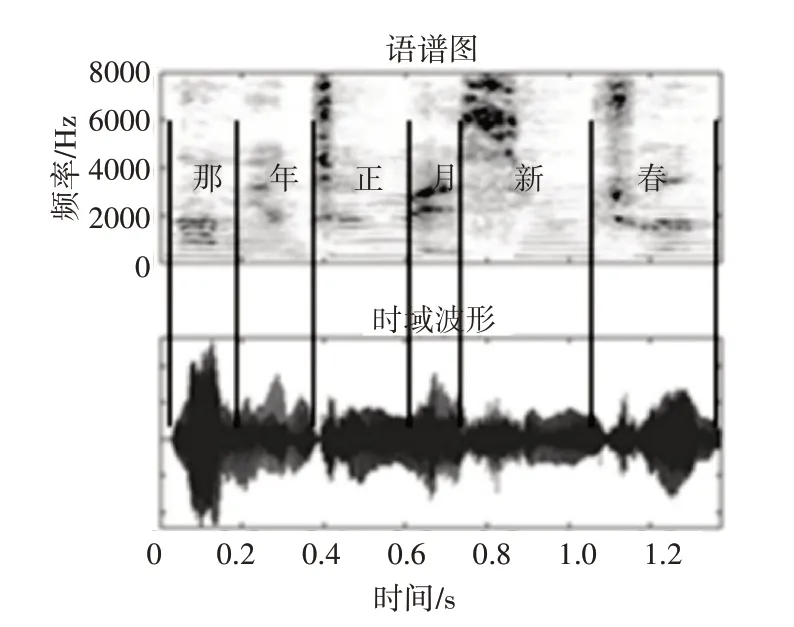
圖1 “那年正月新春”語譜圖(上)與時域波形(下)
語譜圖能夠直觀展現語音信號的頻域特征隨時間的變化,不同音節的頻域能量分布往往也有明顯的區別。
2.2 倒譜與基音周期譜
倒譜的本質是頻譜的頻譜,能夠反映頻域中的變化特性,得到每一幀信號的基音周期與基音峰,是語音信號分析的重要特征[13]。將第n 幀語音信號的短時譜Xn(ω)代入式(3),可以得到這一幀信號的倒譜cn。
式中IFFT代表傅里葉逆變換。為了觀測基音周期隨時間的變化,將每一幀的倒譜幅度轉化為灰度,按照時間順序進行拼接,即可得到基音周期譜,記為T。
圖2 為“那年正月新春”語音數據的基音周期譜圖與對應的時域波形。
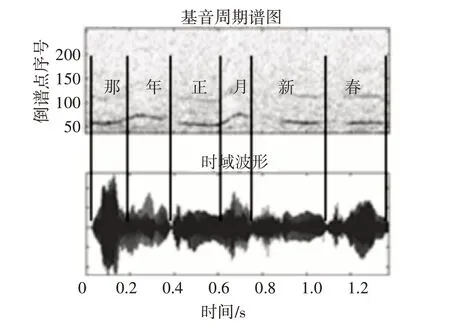
圖2 “那年正月新春”基音周期譜圖(上)與時域波形(下)
濁音段具有諧波結構特征,諧波分布于基音頻率的整數倍附近,使濁音段的頻譜具有一定的周期性,倒譜有明顯的基音周期峰值。相反,清音段、靜音段等非濁音段的倒譜沒有基音峰。
因此,可以依據基音周期軌跡檢測并切分濁音,在無噪環境下使用端點檢測算法檢測有聲段,去除濁音段即可得到清音。噪聲環境下,清音往往會失真,不需要劃分為語音段。
3 多級連續語音切分算法
3.1 基音周期軌跡的提取與濁音檢測
根據基音軌跡曲線的性質可知,只有濁音段能夠形成清晰的連續性強的基音周期軌跡。因此,理論上可以通過提取語音信號的基音周期軌跡曲線,將對應的區間標記為濁音段,實現濁音檢測。
為了證實上述猜想,計算基音周期譜圖中每幀倒譜的灰度最值。因為灰度大小與倒譜幅度成反比,所以計算時取每幀倒譜的灰度最小值點,從而得到倒譜峰值點軌跡曲線。
“那年正月新春”的倒譜峰值點軌跡曲線如圖3(上)所示,圖3(下)為對應的基音周期譜圖。
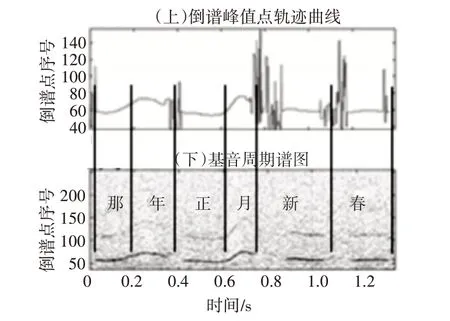
圖3 “那年正月新春”倒譜峰值點軌跡曲線(上)與基音周期譜圖(下)
顯然,濁音段倒譜峰值點軌跡曲線相對平穩,并且與基音周期軌跡相符;非濁音段不存在基音周期軌跡,倒譜峰值點軌跡曲線的變化也沒有規律。
同時不難發現,音節的起始段、截止段與過渡段,基音峰相對模糊,會引起基音周期軌跡的局部波動。為了盡可能提高切分音節的完整性,本文采用多尺度分析的思想,計算局部灰度最小值,降低基音周期譜圖的分辨率,從而平滑基音周期軌跡曲線,提高曲線的連續性,進而提高檢測得到的濁音的完整性。
為保證邊界區域的準確性,同時保證邊緣信息的獲取,在進行多尺度分析時,需要按照神經網絡的思想,將基音周期譜圖的邊緣進行填充(pad?ding),將填充區域賦值為255(灰度最大值),保證輸入輸出數據的維度一致[14]。
圖4 為“那年正月新春”的多尺度分析基音周期譜圖(上)與對應的時域波形(下),上方紅色線段代表檢測到的濁音段。
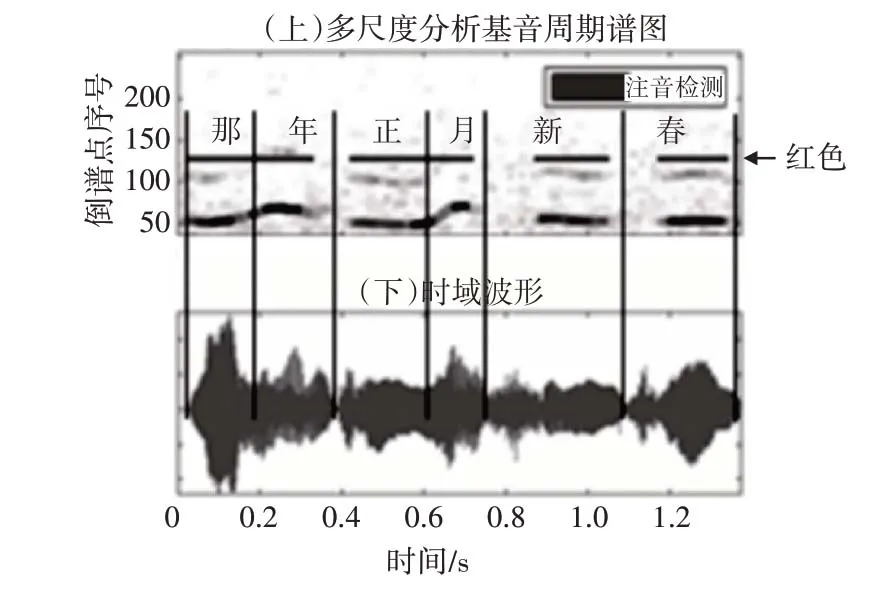
圖4 “那年正月新春”多尺度分析基音周期譜圖與濁音檢測結果
顯然,使用多尺度分析的方法能夠明顯提高基音周期軌跡的連通性,進而提升音節完整性。然而,相鄰音節如果間隔較短,可能無法分開,例如“那年”、“正月”。因此,需要濁音檢測的基礎上,進行更加精確的音節切分。
3.2 基音周期軌跡的斷點切分算法
為了盡可能放大濁音段與非濁音段的灰度差別,實現連續語音的單音節切分,可以按照sigmoid函數的思想,將灰度值進行二分類,并利用符號函數將分類結果兩極化,從而實現基音周期譜的二值化,尋找相鄰音節之間的斷點。
為實現灰度的二分類,需要制定灰度閾值。將所有濁音段內每一幀的基音峰(倒譜峰值)對應的灰度進行正序排序(0為黑色),選取前rate%的灰度分類為黑,另外1-rate%的灰度分類為白,排序位于rate%的灰度即為灰度閾值G0。
將基音周期譜T 代入式(4),得到二值化基音周期譜B_T。
其中,bio為二值化函數,根據輸入數值的正或負返回1 或0。B_T(i,j)=1 代表第i 幀第j 個倒譜點有明顯的峰值,灰度偏黑;反之代表沒有明顯的峰值,灰度偏白。
將每個濁音段內分類結果為0 的點視為斷點,從而將濁音段進行切分。為了保護音節的完整性,同時去除時長過短的濁音段,可以合并相鄰間隔較短的濁音段。在合并結束后,根據人的語速特征[15],設定閾值去除時長小于閾值的濁音段。
如果斷點切分算法能夠尋找到連續基音周期軌跡的斷點,就能夠將多個音節組成的長濁音段切分為單個濁音。但在實際應用中,部分說話人的語速較快,部分音節之間幾乎不存在停頓,斷點切分算法難以應對這類語音數據。
3.3 基音周期軌跡的斜率切分算法
為了應對部分說話人語速較快的難點,需要依據更多特征判斷音節的邊界。漢語音節具有“聲韻調”三要素,聲調不同的音節,基音周期軌跡曲線的變化也不相同。如果能夠捕捉基音周期軌跡的斜率變化,尋找斜率分布的臨界點,就能夠依據聲調的特征實現濁音切分。
例如,“正月”包含的兩個音節聲調不同,反映出的基音周期軌跡斜率分布有著明顯的差異。可以依據這個特征,以貪心算法的思想,選取左右兩側斜率分布差別最大的點作為臨界點。如果臨界點左右側的語音段長度都大于一定時長,可以認為臨界點左右兩側存在聲調不同的兩個音節。將這個臨界點作為切分點,可以實現基音周期軌跡的斜率切分。
使用多級切分算法對“那年正月新春”進行切分,得到結果如圖5 所示。圖中紅色線段代表濁音檢測結果,綠色線段代表多級切分的結果。為了方便觀察,將切分結果交錯繪制。
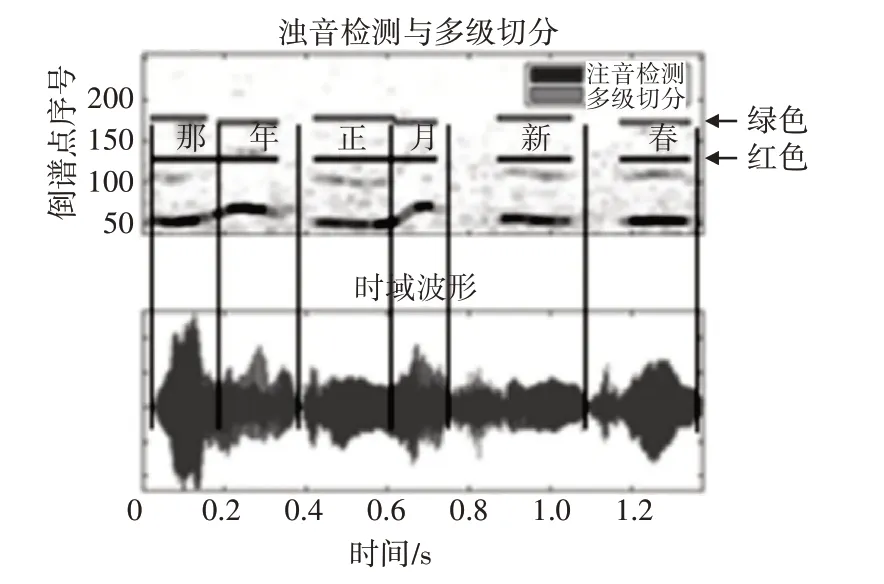
圖5 “那年正月新春”濁音檢測與多級切分結果
從肉眼上能夠直觀地看出,“那年正月新春”被正確地切分為六個音節,并且與人工標記的區間相符。播放切分結果,也能夠證實連續語音切分算法的準確性。
4 切分結果統計與分析
4.1 使用的數據
本文使用的語音數據來源于NJUST603實驗室的語音庫,內容為作家劉紹棠的《師恩難忘》短文,全篇共593 個漢字。語音采樣共計包含男生210人,女生213 人。用于實驗的噪聲數據來源于NoiseX-92噪聲庫,采樣頻率均為16000Hz。
4.2 連續語音切分準確率
隨機選取若干具有正常聽覺認知能力的被試者,同時隨機選取語音庫中一位說話人的語音數據,使用連續語音切分算法切分前38 個音節。切分完成后,將切分結果隨機打亂順序,在安靜環境下以正常音量播放,相鄰音節之間間隔1s,讓被試者復述聽到的音節,與實際音節進行對比,統計準確率,結果如表1所示。
由表1 數據可知,被試者普遍能夠正常識別并復述出正確的音節,證明通過聽覺認知實驗,能夠認為連續語音切分算法得到了正確的切分結果。同時通過數據對比可以發現,多數女性說話人的聲音更容易辨識。
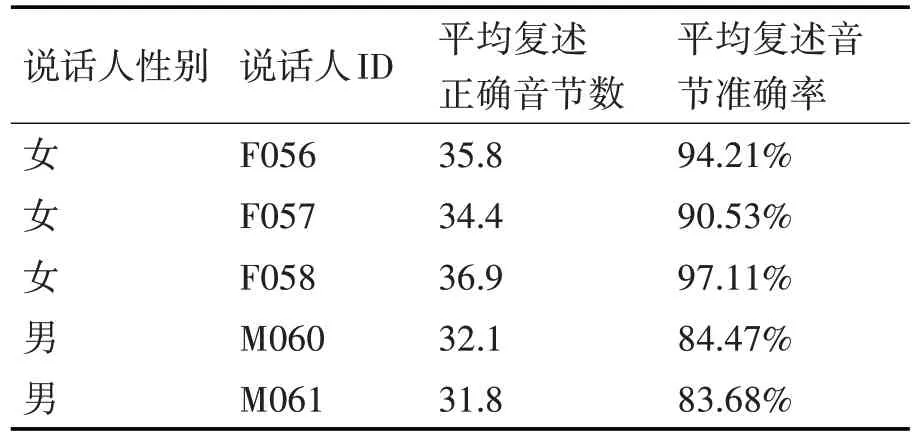
表1 連續語音切分準確率統計結果
4.3 噪聲魯棒性檢驗
絕大多數語音識別系統都要應用于噪聲環境中。因此,需要在噪聲環境下進行連續語音切分算法的性能測試,分析不同信噪比的噪聲對算法性能的影響。
由于低信噪比的噪聲會破壞語音段的共振峰結構,從而導致基音周期軌跡被破壞,使用連續語音切分算法可能會得到不完整的音節和原本不存在的虛假音節。同時,部分音節信息可能會丟失。
選取4.2 節使用的一位說話人的語音段(共38音節),分別加入一定信噪比的白噪聲信號,進行連續語音切分,依據聽感與數據對比,將切分音節分為四類,分類結果如表2所示。
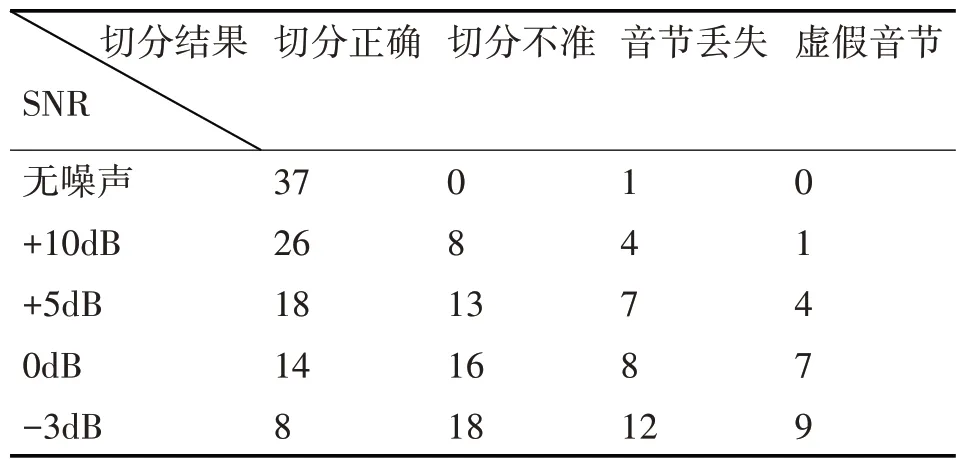
表2 不同信噪比的連續語音信號的切分結果
通過含噪語音切分實驗,證實本文提出的連續語音切分算法具有較好的噪聲魯棒性。低信噪比的噪聲會破壞基音周期軌跡曲線,因此會對算法性能產生較大影響。高信噪比環境下,算法性能較為穩定,實際應用中產生的偏差可以通過語言模型等方式進行修正。
5 結語
本文提出的連續語音切分方法綜合利用了語音信號的時域、頻域和倒譜域特征,以及漢語發聲原理,通過檢測基音周期軌跡區分濁音段與非濁音段,依據基音周期軌跡的斷點與斜率進行多級切分。經過大量被試者的測試,證實了算法具有穩定且較好的性能。不僅如此,加噪實驗表明算法具有較好的噪聲魯棒性。
連續語音切分算法尚有改進空間。濁音檢測與切分算法主要依據基音周期軌跡的特征,噪聲環境下一旦基音周期軌跡被破壞,算法的性能也會受到影響。同時,需要依據不同的應用場景,進行一系列的參數調整。例如應用于脫口秀、RAP等快速講話的字幕生成,需要調整參數,在盡量不破壞完整音節的前提下盡可能提高切分性能。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
