基于ESPnet的中文語音翻譯實現
2023-05-23 10:13:53趙勇
無線互聯科技 2023年6期

作者簡介:趙勇(1974— ),男,陜西高陵人,高級工程師,學士;研究方向:衛星通信。
摘要:當前,很多場合急需實現從語音翻譯為文本的功能,如視頻字幕制作、實時語譯等。文章介紹了一種ESPnet語音識別框架架構,并基于ESPnet框架,訓練得到最優模型,該架構模型能將語音識別過程擴展為網頁在線識別,對目前主流語音識別框架進行對比試驗并總結其優缺點。
關鍵詞:ESPnet;語音識別;CTC
中圖分類號:TP311.5 文獻標志碼:A
0 引言
隨著計算機技術的快速發展,基于深度學習的翻譯軟件應運而生,但這些軟件大多只能實現文本翻譯功能,無法直接對語音進行翻譯、轉錄為文字信息。事實上,在很多場合中急需從語音翻譯為文本的功能,比如視頻字幕制作、實時語譯等。本文基于ESPnet框架,給出了一套網頁端的語音翻譯軟件設計思路[1],該方案能夠實時對上傳到網頁的語音進行翻譯識別。本研究重點介紹了基于ESPnet框架實現語音識別翻譯的原理及框架組成,將結果與其他主流框架進行對比,為后續其他學者研究提供參考方案。
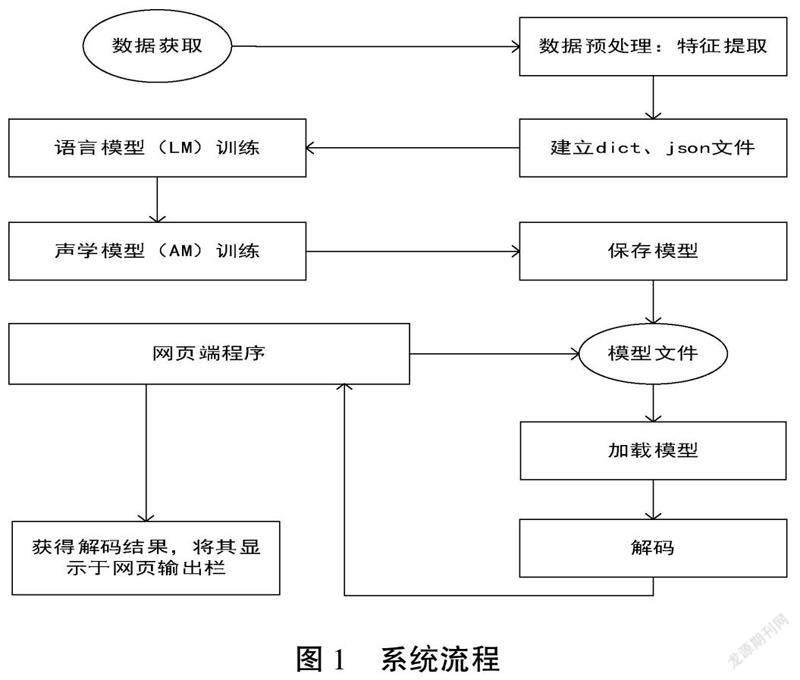
1 系統整體流程
系統整體實現流程如圖1所示,整個系統流程可分為以下步驟。
1.1 特征提取
在數據預處理步驟時,對音頻數據提取80維MFCC特征、三維基音特征歸一化。
1.2 數據準備
在對音頻數據進行特征提取之后,須對整個數據集音頻中所包含的文字內容進行整合,提取數據集對應的轉錄信息,并保存為字典文件dict,后續對新語音翻譯時所輸出的文字內容也基于該字典文件,另外需要將每個訓練語音的文字轉錄內容、發音者ID、音頻編號等信息保存為json文件。
1.3 模型訓練
首先訓練語音模型(RNNLM),其網絡結構能利用文字的上下文序列關系,更好地對語句進行建模,其次訓練聲學模型(AM),訓練出基于CTC和attention混合的語音編解碼器[2]。
1.4 網頁端翻譯服務
網頁部分在接收到語音后,將會調用預設好的語音翻譯程序,在語音翻譯程序中對未知語音進行與模型訓練時同樣的預處理、特征提取過程,然后調用已訓練好的最佳模型,對新的音頻特征進行解碼,得到最終預測結果,網頁端在接收到反饋回來的結果后,將顯示于網頁上的翻譯欄作為最終結果。
通過上述流程,實現數據處理、特征提取、模型訓練、網頁端語音翻譯的整個系統性工作。
2 ESPnet網絡架構
ESPnet的架構核心包括編碼器、CTC機制、注意力機制、解碼器4個部分[3]。
2.1 編碼器
編碼器網絡采用雙向長短時記憶網絡(BLSTM),它能夠更全面、準確地兼容語義信息,由兩層LSTM構成,一個用于正向傳遞語義信息,一個用于反向傳遞語義信息,結構如圖2所示。
2.2 CTC機制
傳統的語音識別在訓練聲學模型時,因為需要每一幀的數據都有其對應的標簽,所以在訓練前需要對語音數據進行語音對齊預處理。語音對齊過程是一個需要反復迭代才能保證其正確性的過程,這一過程十分耗費時間。
CTC的制定遵循貝葉斯決策理論,并加入了空白符號‘來規定字母邊界及替代重復字符。其表示如公式(1):
對于c′,當l為奇數時,其一直為擴展的空白字符‘,當l為偶數時其始終為有效字母。引入CTC機制,可以將語音在時間上的幀序列和相應的轉錄文字序列在模型訓練過程中自動對齊。無須對每個字符或音素出現的起止時間段做標注,以實現直接在時間序列上進行分類,免去了傳統算法較為復雜的對齊操作。CTC模塊占用了大部分的訓練時間,本文采用PyTorch中經過優化的warp-ctc庫,該庫中的CTC模塊較Chainer的CTC模塊可節約5%~10%的訓練時間。
2.3 注意力機制
與HMM / DNN和CTC方法相比,基于注意力的方法根據概率鏈規則直接估算后驗概率P(C|X),如公式(2)所示:
其中patt(C|X)是基于注意力的目標函數。
傳統的注意力機制主要用于改善機器翻譯時輸入輸出位置不一致的問題,但在語音識別過程中,每個詞發音時位置已經固定,不存在位置不一致的問題。本文使用位置感知注意力機制,相較傳統注意力機制來說,位置感知注意力機制無須考慮語音位置關系,更容易訓練,其結構如圖3所示。
2.4 解碼器
在解碼時,系統將參考從CTC、注意力機制的得分,采用集束算法來進行聯合解碼,進一步消除不規則對齊現象。給定歷史輸出y1:n-1和編碼器輸出h1:T′,使yn為n處輸出標簽的假設。在進行集束算法時,將注意力機制得分patt和CTC機制得分Pctc做log加和概率。計算過程如公式(3):
2.5 實現方法
在訓練過程中,首先訓練出編碼器作為共享編碼器,其輸出結果可供CTC、注意力機制使用,在經過CTC和注意力算法后,再將其輸出結果通過集束算法進行聯合解碼得到最終結果。EPSnet整體網絡實現架構如圖4所示。
對于CTC、注意力機制所得結果分別計算其相應的loss值后,需將兩者loss值合并,其表示如公式(4)。
3 對比實驗
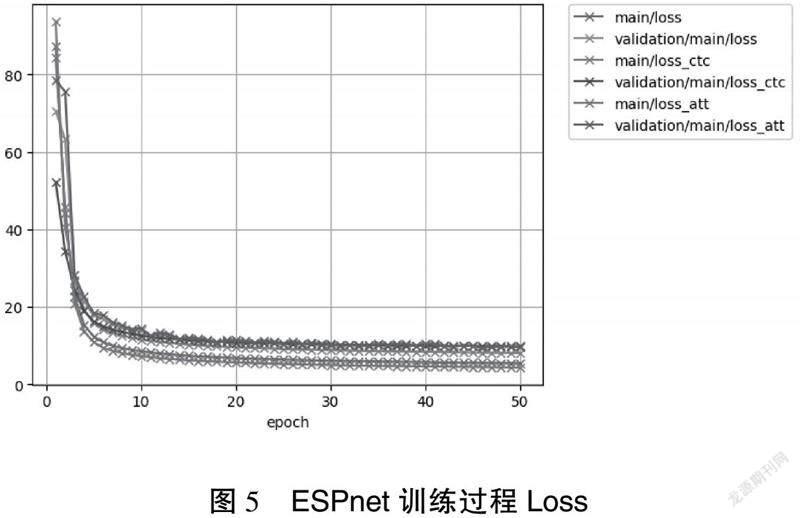
分別采用CTC和注意力機制時,獲得了不同的結果,如圖5所示,可以看出采用注意力方案時,模型在訓練集的損失更小,但在測試集下損失較大,其魯棒性不如CTC機制。本次實驗數據集較小,對于更大的數據集,可以嘗試注意力機制。
本文將ESPnet框架下的模型訓練結果與其他框架、網絡架構所得結果進行同條件下的語音識別正確率對比。這里使用到來自百度的Deepspeech深度學習語音識別框架,Kaldi語音識別框架。測試數據來自aishell數據集,結果如表1所示。從表1中看,采用ESPnet框架所得結果明顯優于Kaldi和Deepspeech模型結果,但模型較大,須經過壓縮、剪枝、稀疏化算法量化后才能具備可移植性。Kaldi模型雖然準確率稍低,模型稍大,但該框架中腳本大部分代碼采用C++編寫,效率更高,產出模型更小,更易于移植擴展。Deepspeech框架結構模型更大,受眾面小。雖然基于百度的大數據優勢,在超大型數據集上可能才會有更優的表現。
4 結語
從上述實驗結果來看,ESPnet的準確性最高,Kaldi居中,但Kaldi的模型最小,易于移植,Deepspeech框架準確率稍低,模型最大。Kaldi的使用者雖眾多,但Kaldi的自行調試較為復雜,其底層語音使用C++語音開發,代碼量繁雜,不易調試;Deepspeech框架的使用者較少,代碼調試過程復雜,其開發社區中可供參考的方案較少,使用起來專業門檻要求高。
ESPnet框架在數據處理時采用Kaldi工具庫,依托于Kaldi活躍的開發社區,在數據處理時遇到問題可以十分快速找到解決方案。深度神經網絡部分采用Pytorch框架進行編寫,Pytorch是目前深度學習工作者都了解的深度學習框架。這些工作者根據自身任務不同對ESPnet的網絡架構和模型參數進行修改,以達到最優結果。
參考文獻
[1]SHINJI A, NANXIN C, ADITHYA R, et al. ESPnet: end-to-end speech processing toolkit[J]. Proc. Interspeech, 2018(18):2207-2211.
[2]GRAVES A, JAITLY N. Towards end-to-end speech recognition with recurrent neural networks[C]. Beijing: International Conference on Machine Learning(ICML), 2014.
[3]DUGGAN J, BROWNE J. Espnet: expert-system-based simulator of petri nets[J].IEE Proceedings D-Control Theory and Applications, 1988(4):239-247.
(編輯 傅金睿)
Abstract: At present, many occasions urgently need to translate from speech to text function, such as video subtitle production, real-time translation, etc.This paper introduces a speech translation based on ESPnet framework. Its optimal training model extends voice recognition to web page online recognition. It compares the current mainstream speech recognition framework and summarizes its advantages and disadvantages.
Key words: ESPnet; speech recognition; CTC
