基于Stacking特征增強多粒度聯(lián)級Logistic的個人信用評估
2023-05-23 08:52:22侯天寶王愛銀
河南師范大學(xué)學(xué)報(自然科學(xué)版) 2023年3期
侯天寶,王愛銀
(新疆財經(jīng)大學(xué) 統(tǒng)計與數(shù)據(jù)科學(xué)學(xué)院,烏魯木齊 830012)
在“互聯(lián)網(wǎng)金融”的快速發(fā)展背景下,P2P網(wǎng)貸近幾年來發(fā)展規(guī)模日益壯大,其業(yè)務(wù)涉及領(lǐng)域也層出不窮.該模式下借貸方式是個人對個人進行信貸,P2P平臺作為中介實現(xiàn)借款人想要借款和貸款人放貸進行投資的需求.其典型的運行模式是借款人和貸款人在平臺上自由競價,每次借貸雙方達成交易,平臺收取相應(yīng)的中介費.P2P網(wǎng)貸平臺具有投資門檻低、成本代價小并且交易更加便捷等優(yōu)勢.但萬物具有兩面性,P2P不斷發(fā)展的同時潛在的信用風(fēng)險問題也日益凸顯,不少借款人因違約未按期還款給平臺以及行業(yè)造成了不利的影響.據(jù)有利網(wǎng)在官方微信公眾號發(fā)布嚴重失信借款人信息,每周都有失信人信息公布,且人數(shù)都在2 000人左右.由此可見,個人信用評估在P2P平臺的重要性.
針對個人信用評估問題,提出一種基于Stacking特征增強多粒度聯(lián)級Logistic模型,該模型的構(gòu)建主要包括兩部分:第一部分,基于Stacking集成的多粒度掃描器的構(gòu)建,利用網(wǎng)格搜索技術(shù)進行調(diào)優(yōu),以準(zhǔn)確率為指標(biāo),選出合適的基評估器作為Stacking框架的初級學(xué)習(xí)器,并用Logistic模型作為次級學(xué)習(xí)器.第二部分,多層聯(lián)級Logistic模型的構(gòu)建,為防止整個模型的過擬合現(xiàn)象,在每一層中的Logistic模型進行交叉檢驗,同時在訓(xùn)練過程中用模型的懲罰系數(shù)去自適應(yīng)調(diào)節(jié)優(yōu)化整個聯(lián)級Logistic模型的預(yù)測性能,以此提升模型準(zhǔn)確率.
1 相關(guān)工作
信用評估是指評估機構(gòu)利用相關(guān)權(quán)威專家的判斷或者數(shù)學(xué)建模方式,結(jié)合融資者所提供的財務(wù)信息、經(jīng)營相關(guān)信息以及歷史還款信息等各類指標(biāo)綜合進行分析,對融資者是否如期按照約定償還債務(wù)本息的能力以及意愿進行評估,并按照其違約概率的不同以劃分等級或分數(shù)的形式給出評估結(jié)論的行為.
在個人信用評估研究領(lǐng)域,評估的方式有三大類:一類是基于統(tǒng)計學(xué)方法,運用統(tǒng)計方面的性質(zhì)來分析數(shù)據(jù)的分布及規(guī)律并進行建模,常見的方法有邏輯回歸(Logistic Regression)和線性判別分析(Linear Discriminant Analysis).如OHLSON[1]首次將邏輯回歸模型應(yīng)用到信用評估問題中,WIGINTON[2]在研究模型信用評估問題上,將邏輯回歸與線性判別分析法加以對比,實驗結(jié)果表明邏輯回歸評估效果優(yōu)于線性判別分析.STEENACKERS等[3]結(jié)合邏輯回歸模型與極大似然估計建立了信用評估模型,將數(shù)據(jù)劃分為好貸款、壞貸款以及拒絕貸款等三大類,用極大似然估計法去迭代邏輯回歸模型,從而找出最接近真實值的最優(yōu)參數(shù).雖然統(tǒng)計學(xué)方法可以建立各種分類問題模型,但由于需要較為嚴格的假設(shè)條件,并且缺少對數(shù)據(jù)特征的學(xué)習(xí),導(dǎo)致預(yù)測準(zhǔn)確率不高.第二類,繼統(tǒng)計學(xué)方法之后,隨著機器學(xué)習(xí)的興起,不少學(xué)者將機器學(xué)習(xí)方法引入到信用評估研究領(lǐng)域,無須刻意找尋數(shù)據(jù)中存在的規(guī)律,重點在于通過對數(shù)據(jù)特征的學(xué)習(xí)來提高預(yù)測精度,打破了統(tǒng)計學(xué)方法中建立模型的局限性.如YEH等[4]建立K近鄰(K-nearest neighbor)、邏輯回歸、神經(jīng)網(wǎng)絡(luò)(Neural networks)、樸素貝葉斯(Naive Bayesian)和判別分析等模型來進行信用評估,發(fā)現(xiàn)K近鄰、神經(jīng)網(wǎng)絡(luò)以及樸素貝葉斯模型都優(yōu)于邏輯回歸與判別分析.隨著研究的不斷深入,影響信用評估的因素不斷被探索出來,數(shù)據(jù)的維度也呈現(xiàn)爆炸式增長,單一的機器學(xué)習(xí)器評估性能受限,HANSEN等[5]研究發(fā)現(xiàn)構(gòu)建多個模型并按一定的規(guī)則結(jié)合起來,能顯著提高整個模型的泛化性能,準(zhǔn)確率有所提高,說明集成模型比單一模型預(yù)測性能更好.TWALA[6]通過實驗發(fā)現(xiàn),集成算法能有效提高信用評估的準(zhǔn)確度.集成學(xué)習(xí)在信用評估中的應(yīng)用主要分為裝袋法(Bagging)、提升法(Boosting)和堆疊法(Stacking),裝袋法的主要思想是從原始數(shù)據(jù)集中抽取訓(xùn)練集,每輪從原始樣本中使用自助采樣法抽取多個訓(xùn)練樣本,并用多個基評估器進行訓(xùn)練,對于分類問題,采取投票的方式獲得最終結(jié)果;對于回歸問題,則以均值的方式獲得最終結(jié)果,如經(jīng)典的隨機森林[7](Random Forest,RF)算法.提升法的主要思想是每次使用全部的樣本,每輪訓(xùn)練減小上一輪的預(yù)測正確的樣本權(quán)重,增大預(yù)測錯誤樣本的權(quán)重,通過自動調(diào)節(jié)權(quán)重來提升模型的預(yù)測性能,如類別型提升[8](Categorical Boosting,CatBoost)、自適應(yīng)提升[9](Adaptive Boosting,AdaBoost)、梯度提升樹[10](Gradient Boosting Decision Tree,GBDT)、極端梯度提升[11](eXtreme Gradient Boosting,XGBoost)、輕量級梯度提升機[12](Light Gradient Boosting Machine,LightGBM),其中XGBoost和LightGBM運算速度快、準(zhǔn)確度高常在Kaggle競賽中被使用,各類集成算法被廣泛應(yīng)用于信用評估研究領(lǐng)域.Stacking的主要思想是通過組合多種評估器來提升模型泛化性,分為初級學(xué)習(xí)器和次級學(xué)習(xí)器兩層,將初級學(xué)習(xí)器的預(yù)測結(jié)果作為元特征來構(gòu)建次級學(xué)習(xí)器模型,以提高預(yù)測性能.丁嵐等[13]以logistic回歸、決策樹(Decision Tree)、支持向量機(SVM)作為初級學(xué)習(xí)器,以SVM作為次級學(xué)習(xí)器來搭建Stacking集成框架違約風(fēng)險評估模型,與單一學(xué)習(xí)器進行比較,發(fā)現(xiàn)集成Stacking框架預(yù)測性能更好.隨著對深度學(xué)習(xí)的不斷深入研究,發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)具有良好的特征學(xué)習(xí)能力以及優(yōu)化性能,如劉偉江等[14]通過數(shù)據(jù)成像技術(shù),將個人違約數(shù)據(jù)轉(zhuǎn)化成圖像,應(yīng)用LeNet-5 模型進行信用評估識別,有著較高的識別精確度;王重仁等[15]將原始數(shù)據(jù)集進行編碼形成包含時間維度和行為維度的灰度圖像,并構(gòu)建具有注意力機制的長短期神經(jīng)網(wǎng)絡(luò)(Long Short-term Memory,LSTM)與卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)融合模型進行信用評估,并與集成模型進行對比,具有較優(yōu)的預(yù)測性能.第三類,近年來不少學(xué)者將機器學(xué)習(xí)方法與統(tǒng)計學(xué)方法相結(jié)合應(yīng)用于信用評估領(lǐng)域,比起單一的學(xué)習(xí)器預(yù)測性能更好,如陳倩等[16]構(gòu)建基于隨機森林的彈性網(wǎng)絡(luò)回歸模型(RF-ElasticNet-Logistic),并與RF-Lasso回歸進行對比,實驗結(jié)果表明RF-ElasticNet-Logistic模型具有較強的預(yù)測性能;李佳欣[17]通過應(yīng)用逐步Logistic回歸依據(jù)AIC準(zhǔn)則對數(shù)據(jù)進行特征選擇,并分別與決策樹、條件推薦樹、隨機森林和支持向量機模型進行對比,發(fā)現(xiàn)選擇較少特征的模型在驗證集上的誤差比全變量模型要低,并且基于逐步Logistic回歸的隨機森林預(yù)測準(zhǔn)確率最優(yōu);曹再輝等[18]以支持向量機、隨機森林、人工神經(jīng)網(wǎng)絡(luò)(ANN)及梯度提升樹作為初級學(xué)習(xí)器,邏輯回歸作為次級學(xué)習(xí)器來搭建Stacking集成框架違約風(fēng)險評估模型,與單一學(xué)習(xí)器、投票集成方法以及人工神經(jīng)網(wǎng)絡(luò)進行對比,預(yù)測性能最優(yōu).
綜上所述,本文提出基于Stacking特征增強多粒度聯(lián)級Logistic模型(Deep_Logistic),該結(jié)構(gòu)類似于深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN),由于Logistic模型缺少對于數(shù)據(jù)的特征學(xué)習(xí),造成預(yù)測準(zhǔn)確度下降,通過用Stacking集成獲取元特征來增強每一級Logistic進行訓(xùn)練前的特征.除此之外,在整個信用評估建模過程中,包括數(shù)據(jù)預(yù)處理、建立模型、調(diào)參、評估.之后,通過AUC、準(zhǔn)確率等評價指標(biāo)對模型進行論證,與此同時與構(gòu)建Stacking集成的基評估器、常見現(xiàn)有的單一集成分類器在3個不同的個人信用評估數(shù)據(jù)集上進行對比分析.
2 模型構(gòu)建理論基礎(chǔ)
2.1 相關(guān)模型的概述
通過對相關(guān)文獻的梳理,發(fā)現(xiàn)集成學(xué)習(xí)的方法可以融合多個單一學(xué)習(xí)器的預(yù)測效果,可提升預(yù)測的準(zhǔn)確度,并且Stacking 集成相對 Bagging和Boosting,往往預(yù)測精度更高,而且過擬合的風(fēng)險會更低[19],據(jù)此選用Stacking作為元特征提取器.為了生成有效的元特征對后續(xù)聯(lián)級Logistic模型進行特征增強,需要建立有效的Stacking集成模型和初級學(xué)習(xí)器.據(jù)此,本文選取信用風(fēng)險預(yù)警問題中應(yīng)用最廣泛且常見集成學(xué)習(xí)方法作為Stacking中的預(yù)選初級學(xué)習(xí)器,包括XGBoost,Catboost,LightGBM,Adaboost以及GBDT模型.
極端梯度提升(XGBoost)是一種改進的梯度提升決策樹模型,僅以決策樹為基分類器,屬于Boosting集成學(xué)習(xí),并且可進行多線程并行運算,故而運算速度較快,在數(shù)據(jù)挖掘領(lǐng)域受到廣泛應(yīng)用.XGBoost的實質(zhì)是由眾多決策樹集成而來,模型:
(1)
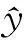
LightGBM與XGBoost的原理相似,該算法由微軟提出,屬于Boosting集成算法的一種.LightGBM是一種基于直方圖算法的決策樹,直方圖將浮點型連續(xù)特征進行離散化,在直方圖遍歷數(shù)據(jù)后,根據(jù)直方圖的離散值,通過累計必要的統(tǒng)計信息,尋找出最優(yōu)分界點.
AdaBoost是Boosting中經(jīng)典算法之一,該算法通過不斷更新迭代正確、錯誤樣本權(quán)重,能降低數(shù)據(jù)隨機性波動導(dǎo)致的泛化錯誤率,使其具有較好的泛化能力[20].AdaBoost首先給樣本(x1,y1),(x2,y2),…,(xn,yn)賦予同等權(quán)重1/n,然后引入分類算法構(gòu)建分類模型,模型在不斷迭代學(xué)習(xí)的過程中,不斷更新樣本的權(quán)重,每輪提高被錯判樣本的權(quán)重,減少正確判斷的權(quán)重,以提升對分類問題中樣本量較少的類別的敏感度.經(jīng)過重復(fù)迭代T次后得到預(yù)測函數(shù)f1,f2,…,fT,最后經(jīng)過加權(quán)投票決定,預(yù)測效果越好權(quán)重越大,反之則越小.在實際分類問題中,這就使得即使在數(shù)據(jù)集不均衡的條件下AdaBoost更偏向錯判的樣本,但由于其優(yōu)點,也容易導(dǎo)致過擬合,不太穩(wěn)定.
GBDT[21-22],又稱MART(Multiple Additive Regression Tree),是一種基于迭代的決策樹算法,屬于Boosting集成的一種,該算法由多個決策樹組成.和AdaBoost類似,GBDT也是重復(fù)選擇一個模型并且每次基于先前的模型表現(xiàn)進行調(diào)整,所不同的是,AdaBoost是通過提升錯分數(shù)點的權(quán)重來定位模型的不足,而GBDT是通過計算梯度來定位模型的不足,這也使得在數(shù)據(jù)集不均衡的條件下更偏向錯判的樣本.GBDT主要思想是通過不斷迭代的方式去減少殘差,并且沿著梯度方向進行不斷優(yōu)化來形成多個分類回歸決策樹,最后將得到的所有決策樹的結(jié)論進行累加起來得到最終的模型,通過這種不斷迭代學(xué)習(xí)的過程,從而得到較為精準(zhǔn)的預(yù)測結(jié)果.
CatBoost,由2017年俄羅斯搜索巨頭Yandex所研究,屬于Boosting集成.CatBoost是基于一種對稱決策樹的GBDT框架,具有支持分類、精度高等優(yōu)點.CatBoost主要的優(yōu)點是合理進行處理類別特征,Categorical和Boosting組成了CatBoost.其次,CatBoost還解決了梯度偏差(Gradient Bias)和預(yù)測偏移(Prediction Shift)的問題,減少了過擬合現(xiàn)象的發(fā)生,同時使用整個數(shù)據(jù)集進行訓(xùn)練,對數(shù)據(jù)信息進行高效提取.
對于二分類問題.首先,CatBoost對數(shù)值特征進行二值化,即通過oblivious樹為基礎(chǔ)預(yù)測器,將浮點特征、統(tǒng)計信息及獨熱編碼進行二值化.其次,將類別型特征轉(zhuǎn)化為數(shù)值型特征,主要是對觀測集進行隨機排序生成多個隨機序列、給定的某個序列利用訓(xùn)練集的平均標(biāo)簽值代替類別(對于出現(xiàn)次數(shù)較少的類別進行平滑處理)、利用先驗的思想將分類數(shù)據(jù)轉(zhuǎn)化為數(shù)值型.之后,采用“貪婪策略”進行特征組合.其中在處理梯度偏差問題方面,在確定樹結(jié)構(gòu)基礎(chǔ)上計算葉子節(jié)點值,根據(jù)不同分割方式下獲得的葉節(jié)點值,對獲得的樹進行評分,從而獲得最佳分割方式,之后采用梯度或牛頓步長來逼近葉子節(jié)點值.
CatBoost實現(xiàn)了訓(xùn)練數(shù)據(jù)集與處理類特征的同步,極大提高了處理特征的效率;通過計算葉節(jié)點的算法來避免“過擬合”,提高模型的泛化性.
2.2 模型的構(gòu)建
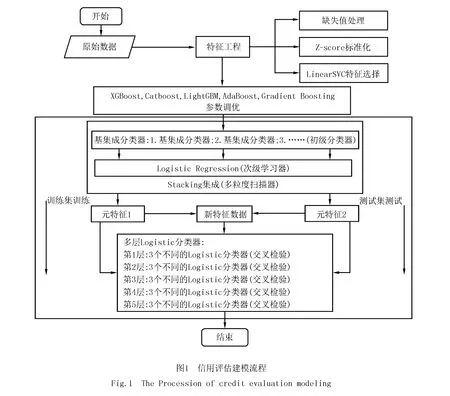
本文提出的個人信用模型構(gòu)建的基本流程圖,如圖1所示.
2.2.1數(shù)據(jù)預(yù)處理概述
為了降低數(shù)據(jù)集本身對于分類器的影響,對原始數(shù)據(jù)集采取預(yù)處理,包括缺失值處理、規(guī)范化處理和特征選擇,其中規(guī)范化處理采用Z分數(shù)標(biāo)準(zhǔn)化(Z-Score Standardization),特征選擇使用線性分類支持向量機[23](LinearSVC)方法.
2.2.2分類器設(shè)計
(1)分類器設(shè)計思路及結(jié)構(gòu)說明
分層訓(xùn)練的訓(xùn)練過程采取逐層訓(xùn)練的方式.聯(lián)級結(jié)構(gòu)屬于一種多層聯(lián)級的訓(xùn)練框架,通過算法將不同層的訓(xùn)練結(jié)果進行結(jié)合.在前向傳播設(shè)計方面,基于聯(lián)級結(jié)構(gòu)中后續(xù)層的分類器通過前一層的反饋進行訓(xùn)練,由于每層的Logistic模型自身缺乏對數(shù)據(jù)特征的學(xué)習(xí),在進行前向傳播訓(xùn)練中需要進行特征增強處理.受深度森林[24]構(gòu)造原理啟發(fā),在聯(lián)級結(jié)構(gòu)外部設(shè)計基于Stacking集成的多粒度掃描器進行訓(xùn)練預(yù)測生成多個元特征,并組合生成新特征向量用于聯(lián)級結(jié)構(gòu)的起始輸入訓(xùn)練以及元特征用于每級訓(xùn)練的特征增強,為避免過擬合現(xiàn)象的發(fā)生,每級Logistic模型均使用交叉檢驗.整體的分類器主要涉及兩方面的結(jié)構(gòu),一是多粒度掃描器的構(gòu)建,二是聯(lián)級Logistic結(jié)構(gòu)的構(gòu)建.
(2)多粒度掃描器的構(gòu)建
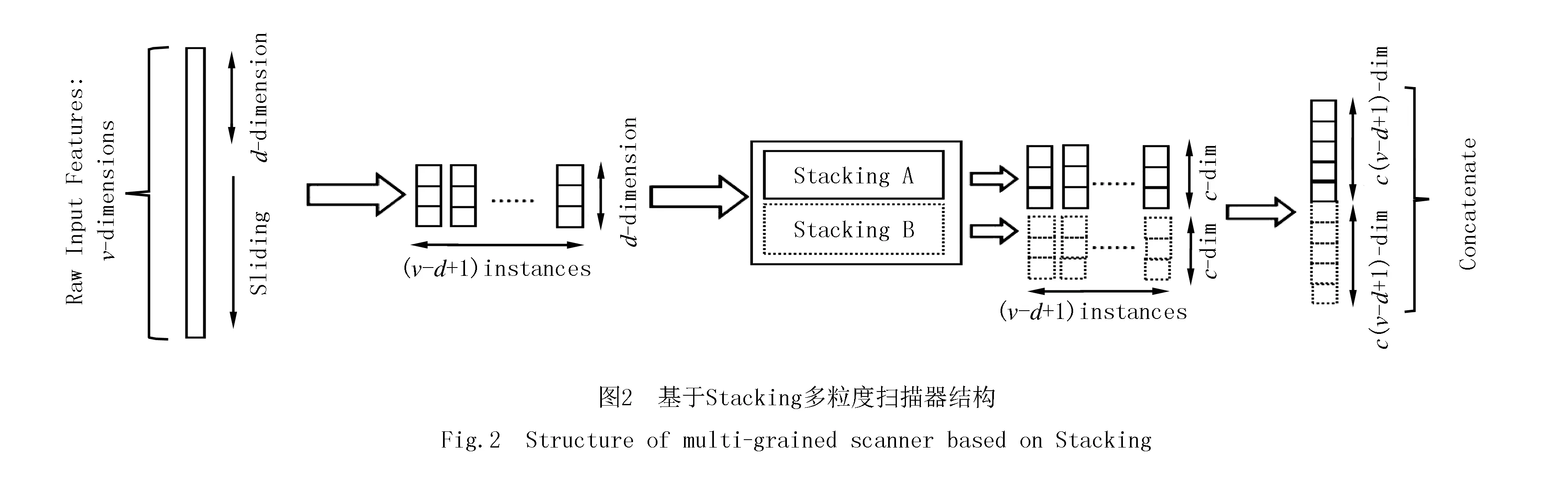
受卷積神經(jīng)網(wǎng)絡(luò)和深度森林[24]構(gòu)造原理的啟發(fā),對原始輸入特征使用基于不同隨機模式Stacking的多粒度掃描方式產(chǎn)生聯(lián)級Logistic的輸入特征向量.其中,Stacking集成中初級基集成學(xué)習(xí)器選用預(yù)測性能較高的學(xué)習(xí)器,即基集成學(xué)習(xí)器作為單一學(xué)習(xí)器經(jīng)過網(wǎng)格搜索調(diào)優(yōu)后,訓(xùn)練預(yù)測正確率之間有著明顯差異中較高得分的學(xué)習(xí)器作為初級學(xué)習(xí)器.
例如圖2中所示,對于維度為的輸入v數(shù)據(jù),若采用d維滑動窗口對輸入的特征進行處理,且分類標(biāo)簽類別數(shù)為c,通過Stacking的訓(xùn)練預(yù)測,最終可以得到c(v-d+1)維度特征向量.在實驗中,通過對滑動窗口維度的設(shè)置,從而最終可以得到不同粒度的特征向量.
(3)聯(lián)級Logistic結(jié)構(gòu)的構(gòu)建
受多層感知器神經(jīng)網(wǎng)絡(luò)[25](MLP)的構(gòu)造原理啟發(fā),類似于神經(jīng)網(wǎng)絡(luò)中對輸入特征經(jīng)過每層以sigmoid激活函數(shù)的多個神經(jīng)元進行訓(xùn)練,從而構(gòu)造聯(lián)級Logistic.在聯(lián)級Logistic中,每一級都包含多個不同隨機模式的Logistic,由多粒度掃描器產(chǎn)生的元特征對每級訓(xùn)練前進行特征增強,使得每經(jīng)過一級的訓(xùn)練,預(yù)測準(zhǔn)確率都有明顯提升.為了防止過擬合現(xiàn)象的發(fā)生,每級中的不同Logistic均進行交叉檢驗.整個構(gòu)造原理如圖3所示,聯(lián)級Logistic的級數(shù)可以進行自定義,每一級Logistic學(xué)習(xí)輸入特征向量的信息,經(jīng)過處理后傳輸?shù)较乱粚?每一級中Logistic均采取自適應(yīng)懲罰系數(shù)進行調(diào)節(jié),同時對于起初某些不太均衡的數(shù)據(jù)集可由Logistic自身class_weight參數(shù)設(shè)置進行微調(diào),并且每級結(jié)束后均進行預(yù)測估計.與此同時,設(shè)定了早停機制,即每級相比上一級預(yù)測效果沒有顯著提升,不必增加層級的深度,終止訓(xùn)練過程.

(4)總體結(jié)構(gòu)
圖4是基于Stacking特征增強多粒度聯(lián)級Logistic的總體框架,若輸入特征為v維,分類標(biāo)簽種數(shù)為c,多粒度掃描器模塊具有2個滑動窗口,經(jīng)過第一個單位滑動維度為d1的多粒度掃描器和第二個單位滑動維度為d2的多粒度掃描器,最終可以得到維度為2c(2v-(d1+d2)+2)的特征向量作為聯(lián)級Logistic的第一級輸入.每一個多粒度掃描器除了生成聯(lián)級Logistic的開始輸入,還交替用于每級Logistic訓(xùn)練前的特征增強,經(jīng)過每級的訓(xùn)練,不斷重復(fù)這一過程,直到預(yù)測性能達到最優(yōu).

3 信用評估實驗
3.1 評價指標(biāo)構(gòu)建
在分類算法中,常見的分類指標(biāo)有準(zhǔn)確率(Accuracy)、精準(zhǔn)率(Precision)、召回率(Recall)、真正例率TPR(True Positive Rate)、假正率FPR(False Positive Rate)、ROC(Receiver Operating Characteristic)曲線和AUC(Area Under Curve)[26-28]等,這些指標(biāo)都是由混淆矩陣(Confuse Matrix)中的真正類TP(True Positive,TP)、假負類FN(False Negative,FN)、假正類FP(False Positive,FP)和真負類TN(True Negative,TN)計算得來.
準(zhǔn)確率(Accuracy,簡稱為A)表示預(yù)測正確的概率:
(2)
精確率(Precision,簡稱為P)表示正確預(yù)測為正樣本(TP)占所有預(yù)測為正樣本(TP+FP)的比重:
(3)
召回率(Recall,簡稱為R),也稱靈敏度(Sensitivity,簡稱為S),表示正確預(yù)測為正樣本(TP)占所有真實正樣本(TP+FN)的比重:
(4)
由式(3)和(4),可以發(fā)現(xiàn)精確率和召回率之間是具有相互的影響,為了同時兼顧二者,并且在盡可能提高精確率和召回率的同時,減少二者之間的差異,故此引入F1-score:
(5)
真正率與召回率公式相同,都表示正確預(yù)測為正樣本占所有預(yù)測為正樣本的比重:
(6)
假正率指的是錯誤預(yù)測為正樣本占所有真實為負樣本的比重:
(7)
ROC曲線是對整個分類器性能測試的一種可視化,通過曲線的形式來描述出真正例率與假正例率之間的變化關(guān)系.一個好的預(yù)測分類器往往盡可能靠近ROC曲線的左上角,越靠近左上角,表示分類器的性能越好.另外,為了更好量化ROC曲線所體現(xiàn)出的測試性能,可用ROC曲線下方的面積即AUC值來表示整個模型的性能表現(xiàn).
3.2 數(shù)據(jù)預(yù)處理
在信用評估模型中,融資者(借款人)的個人信息一般包括貸款金額、期限、年齡、職業(yè)、貸款用途以及還款記錄等數(shù)據(jù).由于數(shù)據(jù)集中包含許多缺失數(shù)據(jù)、類別型數(shù)據(jù)等,同時為降低后期訓(xùn)練預(yù)測模型的復(fù)雜度,提升其正確率,因此需要在建模前進行對數(shù)據(jù)預(yù)處理.在填補缺失值方面,對于連續(xù)性數(shù)據(jù)采取均值進行填補,類別型數(shù)據(jù)用眾數(shù)進行填補,并對其進行編碼轉(zhuǎn)化成數(shù)值型.在特征提取方面,采取線性支持向量機(LinearSVC)進行特征選擇.
實驗中所使用的數(shù)據(jù)集來自機器學(xué)習(xí)開放數(shù)據(jù)集網(wǎng)站[29](UCI Machine Learning Repository)中的德國信用數(shù)據(jù)集,Kaggle網(wǎng)站上的公開P2P平臺Lending Club的貸款數(shù)據(jù)集[30]以及信用卡數(shù)據(jù)集[31](Credit Card Approval Prediction).其中,為了更加符合現(xiàn)實業(yè)務(wù)需要,并且由于數(shù)據(jù)量大,故將Lending Club數(shù)據(jù)類別標(biāo)簽進行規(guī)整分類,對Fully Paid和Current歸結(jié)為正常還款類,對Late(31~120 d),In Grace Period以及Late(16~30 d)歸結(jié)為延期貸款類,對Default和Charged Off歸結(jié)為糟糕貸款類,并對數(shù)據(jù)進行下采樣處理.表1所示為各樣本數(shù)據(jù)分別經(jīng)預(yù)處理后得到的實驗數(shù)據(jù)及其相關(guān)數(shù)據(jù)屬性.
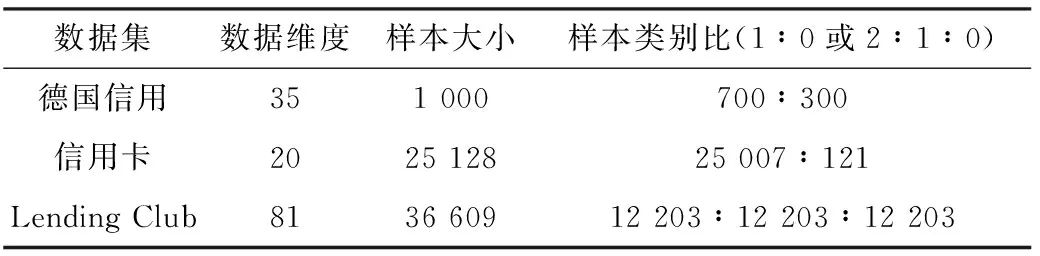
表1 實驗中的樣本數(shù)據(jù)集
3.3 實驗與結(jié)果分析
為了證實所構(gòu)建模型的有效性,本文根據(jù)前期預(yù)選的初級學(xué)習(xí)器,在不同數(shù)據(jù)集上進行信用評估實驗,構(gòu)建基于各預(yù)選初級學(xué)習(xí)器的模型和Deep_Logistic模型.其中,Deep_Logistic模型的構(gòu)建(由圖4知),首先針對每種數(shù)據(jù),Stacking多粒度掃描器滑動窗口均可設(shè)置成原始數(shù)據(jù)特征v維和v-1維,聯(lián)級Logistic級數(shù)可均設(shè)置為5級;其次,根據(jù)基于各預(yù)選初級學(xué)習(xí)器的模型訓(xùn)練預(yù)測情況,確定Stacking多粒度掃描器的基學(xué)習(xí)器,再來構(gòu)建Deep_Logistic模型.最后以Lending Club數(shù)據(jù)集為例,與近幾年文獻中在此數(shù)據(jù)集上所提信用評估模型上的表現(xiàn)進行對比.每個數(shù)據(jù)集上,在進行聯(lián)級Logistic過程中交叉檢驗均采取5折,以確保實驗結(jié)果的穩(wěn)定性、可靠性.
(1)德國信用數(shù)據(jù)集實驗
表2~6所示是各單一集成學(xué)習(xí)器在德國信用數(shù)據(jù)集上的參數(shù)調(diào)優(yōu)結(jié)果.
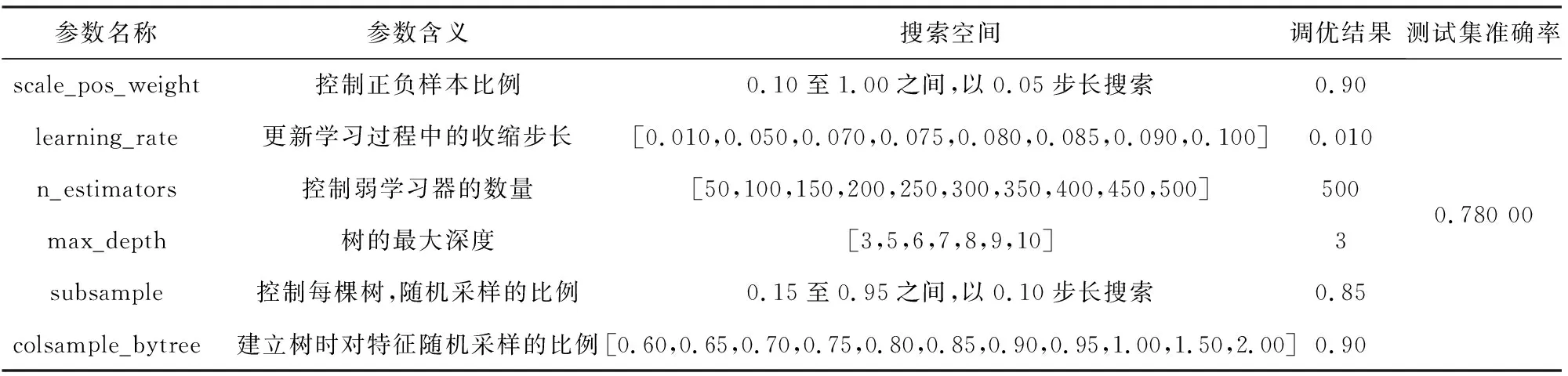
表2 德國信用數(shù)據(jù)集上XGBoost參數(shù)調(diào)優(yōu)結(jié)果

表3 德國信用數(shù)據(jù)集上CatBoost參數(shù)調(diào)優(yōu)結(jié)果
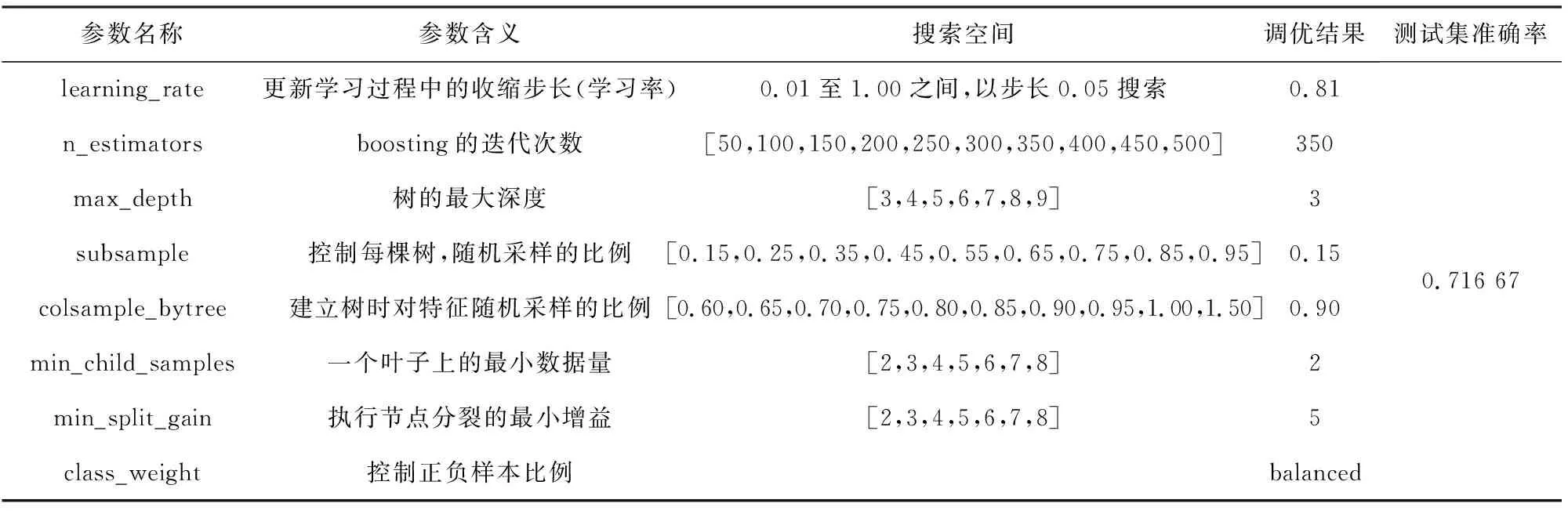
表4 德國信用數(shù)據(jù)集上LightGBM參數(shù)調(diào)優(yōu)結(jié)果
由表2~6可知每一學(xué)習(xí)器在測試集上的預(yù)測準(zhǔn)確率,確定Stacking多粒度掃描器的構(gòu)建,其涉及初級學(xué)習(xí)器有XGBoost,CatBoost.構(gòu)建Stacking,如表7所示.

表5 德國信用數(shù)據(jù)集上AdaBoost參數(shù)調(diào)優(yōu)結(jié)果
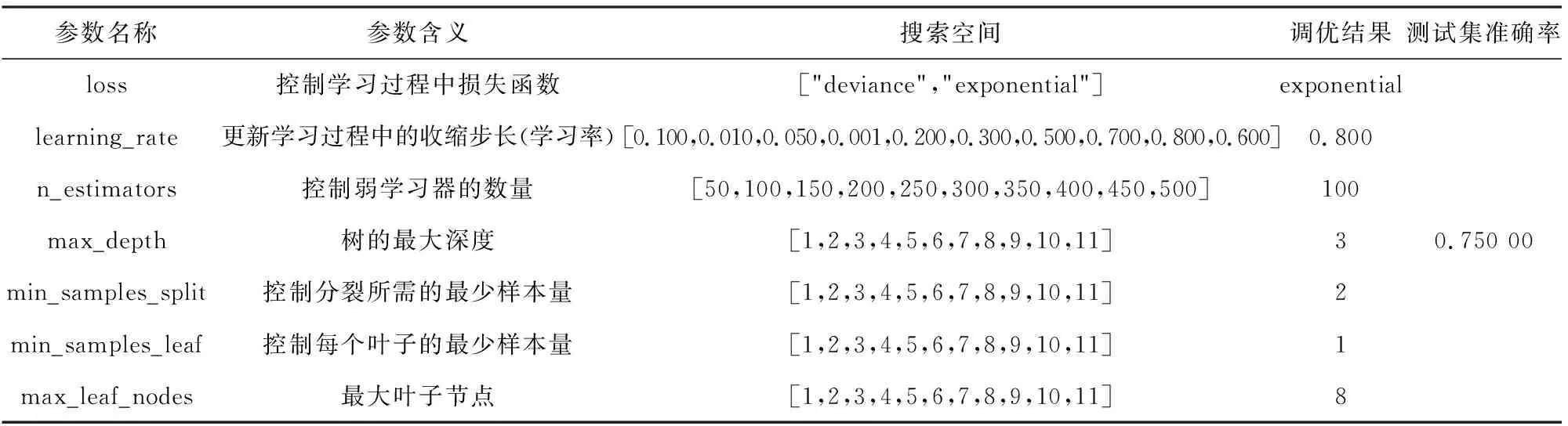
表6 德國信用數(shù)據(jù)集上GBDT參數(shù)調(diào)優(yōu)結(jié)果

表7 德國信用數(shù)據(jù)集上Stacking多粒度掃描器構(gòu)建
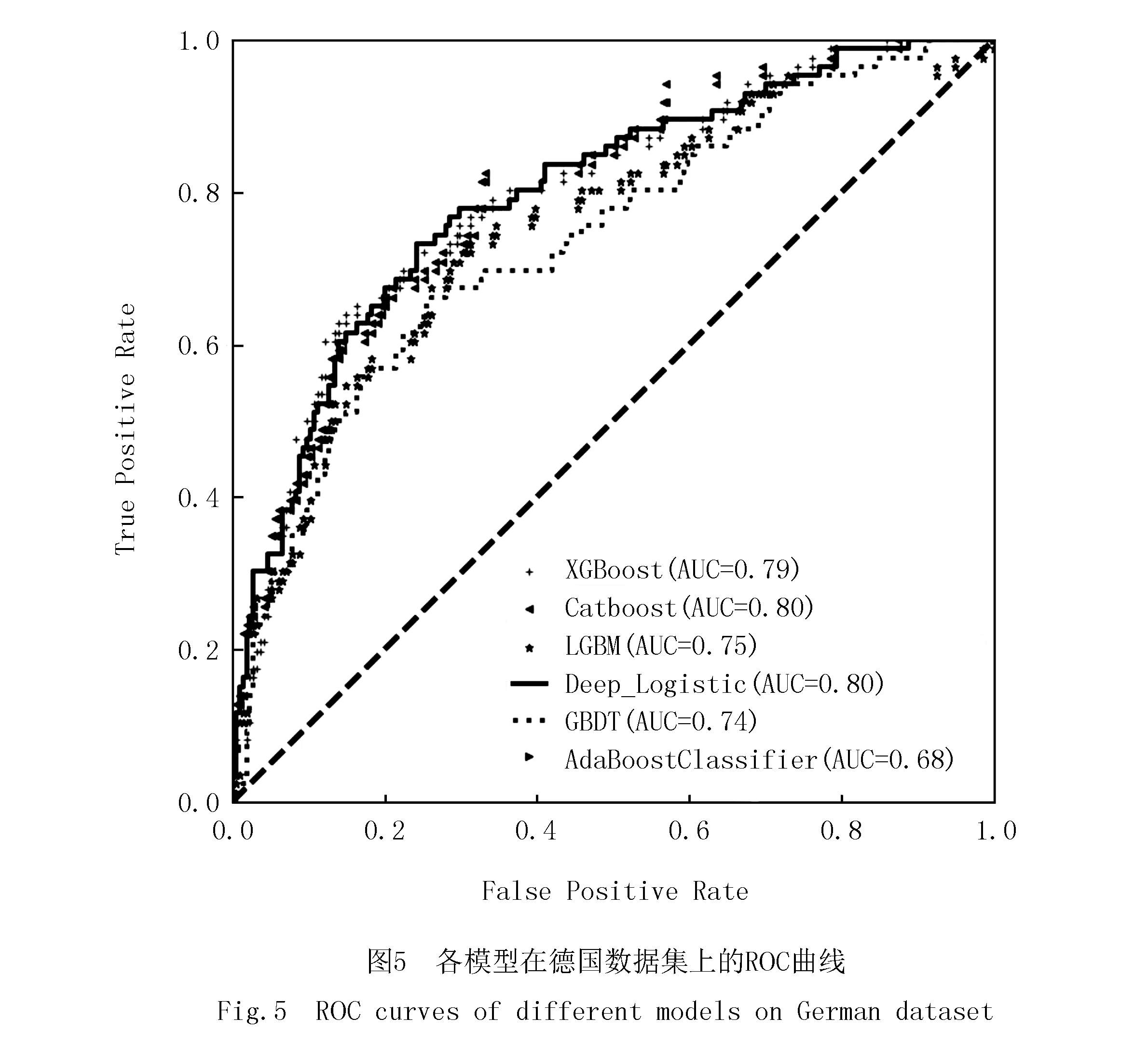
表8和圖5是分別使用預(yù)選初級學(xué)習(xí)器XGBoost,Catboost,LightGBM,Adaboost以及GBDT模型與該文所提Deep_Logistic模型在德國信用數(shù)據(jù)集上的比較,表9是Deep_Logistic模型中聯(lián)級Logistic每級訓(xùn)練最優(yōu)參數(shù)表.

表8 各模型在德國信用數(shù)據(jù)集上的結(jié)果
(2)信用卡數(shù)據(jù)集實驗和Lending Club數(shù)據(jù)集實驗
為了更好地進行有效對比實驗,設(shè)置在信用卡和Lending Club數(shù)據(jù)集上的各分類預(yù)測器參數(shù)配置、尋優(yōu)方法、Deep_Logistic模型構(gòu)建方法均與在德國信用數(shù)據(jù)集上處理方式相同,并且采取一樣的參數(shù)搜索范圍.最終確定信用卡數(shù)據(jù)集上Stacking多粒度掃描器的構(gòu)建,其涉及初級學(xué)習(xí)器有XGBoost,CatBoost,Lending Club數(shù)據(jù)集上Stacking多粒度掃描器的構(gòu)建,其涉及初級學(xué)習(xí)器有XGBoost,LightGBM和CatBoost.由此可得各模型在信用卡、Lending Club數(shù)據(jù)集上的預(yù)測性能對比,如表10所示.表11是在信用卡數(shù)據(jù)集和Lending Club數(shù)據(jù)集上聯(lián)級Logistic每級訓(xùn)練最優(yōu)參數(shù)表.
由表8和圖5可知,在德國信用數(shù)據(jù)集中,Deep_Logistic的AUC值為0.80,與CatBoost同排名第一,比排名第二的XGBoost高出1%,比第三的LightGBM高出5%;Accuracy值為0.79,也為最高,超過排名第二的XGBoost和CatBoost模型1%,比排名第三的AdaBoost高2%;F1-score值為0.62,也為最高,比排名第二模型CatBoost高1%,比排名第三模型LightGBM高5%;相比于構(gòu)建Stacking初級學(xué)習(xí)器中XGBoost和CatBoost模型,靈敏度達到60%,有著明顯提升.因此,在德國信用數(shù)據(jù)集中,Deep_Logistic效果最好.
表9表示的是,在德國信用數(shù)據(jù)集上訓(xùn)練Deep_Logistic模型時,每級Logistic的最優(yōu)參數(shù).根據(jù)早停機制,最優(yōu)級數(shù)為1,并且最優(yōu)參數(shù)自適應(yīng)懲罰系數(shù)C為0.01.

表9 德國信用數(shù)據(jù)集,每級Logistic最優(yōu)參數(shù)

表10 各模型在信用卡、Lending Club數(shù)據(jù)集上的結(jié)果
由表10可知,在信用卡數(shù)據(jù)集中,Deep_Logistic的AUC值為1,處于較好水平;Accuracy值為0.999 735,也為最高,超過排名第二的XGBoost模型0.000 398,比排名第三的CatBoost和GBDT高0.000 531;F1-score值為0.999 867,也為最高,相比排名第二模型XGBoost高0.000 2,比排名第三模型CatBoost和GBDT高0.000 267;相比于構(gòu)建Stacking初級學(xué)習(xí)器中XGBoost和CatBoost模型,靈敏度達到0.999 734,處于最優(yōu);Precision值為1,與CatBoost同排名第一,處于最優(yōu).因此,在信用卡數(shù)據(jù)集上,Deep_Logistic效果最好.由表11可知,訓(xùn)練Deep_Logistic模型,得最優(yōu)級數(shù)為1,最優(yōu)參數(shù)自適應(yīng)懲罰系數(shù)C為0.01.

表11 在信用卡、Lending Club數(shù)據(jù)集上每級Logistic最優(yōu)參數(shù)
Lending Club數(shù)據(jù)集實驗,由上表10可知,在Lending Club數(shù)據(jù)集中.Deep_Logistic的AUC值為0.956 724,排名第一,超過排名第二的CatBoost模型0.063 266,比排名第三的XGBoost模型高0.063 404;Accuracy值為0.861 221,排名第一,超過排名第二的CatBoost模型0.001 583,比排名第三的XGBoost高0.001 6;Precision值為0.860 335,排名第一,超過排名第二的CatBoost模型0.001 784,比排名第三的XGBoost高0.001 963;Recall值為0.860 610,排名第一,超過排名第二的CatBoost模型0.001 938,比排名第三的XGBoost高0.002 034;F1-score值為0.858 873,排名第一,超過排名第二的CatBoost模型0.001 548,比排名第三的XGBoost模型高0.001 73.因此,在Lending Club數(shù)據(jù)集上,Deep_Logistic效果最佳.由表11可知,訓(xùn)練Deep_Logistic模型,得最優(yōu)級數(shù)為2,且每級的最優(yōu)參數(shù)自適應(yīng)懲罰系數(shù)為0.1.
(4)與相關(guān)文獻方法對比實驗
在近兩年信用評估領(lǐng)域中同樣有在基于現(xiàn)有機器學(xué)習(xí)模型進行改進的模型的應(yīng)用研究,在表12中對文獻[14]中引入到信用評估領(lǐng)域的經(jīng)典“手寫數(shù)字”識別模型LeNet-5、文獻[24]中引入到借款人信用評估研究的深度森林模型、本文所提Deep_Logistic模型,使用信用評分模型中常用評價指標(biāo)進行綜合對比分析.由于在兩篇文獻中沒有涉及德國信用數(shù)據(jù)集與信用卡數(shù)據(jù)集上的實驗,因此只在Lending Club數(shù)據(jù)集上進行對比實驗.

表12 Deep_Logistic模型與相關(guān)文獻模型效果對比
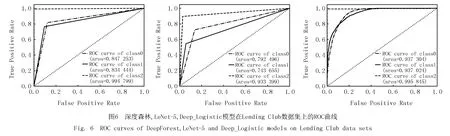
從表12可以看出,Deep_Logistic模型的 AUC 值在Lending Club數(shù)據(jù)集中是最高的,Accuracy值也都表現(xiàn)不錯,明顯優(yōu)于LeNet-5和深度森林模型,在精準(zhǔn)度和敏感度方面也比較突出.圖6是深度森林,LeNet-5,Deep_Logistic模型在Lending Club數(shù)據(jù)集上的ROC曲線,綜合分析可知,明顯可以發(fā)現(xiàn)Deep_Logistic模型下ROC曲線更接近左上角(0,1),一定程度上可說明模型性能較好.
結(jié)合表8、表10中的各項評價指標(biāo)可看出:
(1)在常用信用評估方法中,XGBoost和CatBoost進行信用風(fēng)險評估的效果較好;
(2)在各數(shù)據(jù)集上,Deep_Logistic相比于構(gòu)成其Stacking多粒度掃描器的初級學(xué)習(xí)器中各基評估器,表現(xiàn)更加穩(wěn)定,信用評估效果要更好,可有效地融合各基評估器的預(yù)測性能,提高模型的整體信用評估效果.
4 結(jié)束語
本文的目的在于設(shè)計一種基于集成學(xué)習(xí),擁有聯(lián)級結(jié)構(gòu),能融合多個單一集成學(xué)習(xí)器的分類器,從而有效提出進行貸款和不貸款的策略性建議,輔助P2P平臺及相關(guān)貸款人提供一種解決方案.本文基于Stacking特征增強多粒度聯(lián)級Logistic模型對借款人進行信用風(fēng)險評估,在德國信用數(shù)據(jù)集、信用卡數(shù)據(jù)集和Lending Club數(shù)據(jù)集基礎(chǔ)上進行分類預(yù)測,同時將其與XGBoost,CatBoost,LightGBM,GBDT以及AdaBoost模型分類方法進行對比,并且用該Lending Club數(shù)據(jù)與文獻中LeNet-5,深度森林方法也進行對比.實驗表明,所提方法在3個數(shù)據(jù)集上表現(xiàn)出的性能均優(yōu)于其他對比方法,并且也較優(yōu)于文獻中方法.從以上實驗中可以發(fā)現(xiàn)本文分類器可應(yīng)用于二分類、三分類問題,理論上也可應(yīng)用于多分類任務(wù)中.但是,由于本文方法中聯(lián)級部分僅使用Logistic 模型,同時在構(gòu)建Stacking多粒度掃描器方面,初級學(xué)習(xí)器中的基評估器種類數(shù)量和生成多粒度的滑動窗口維度的增加,會增加模型的整體復(fù)雜性,在之后的研究中可以嘗試使用更多的分類器作為聯(lián)級結(jié)構(gòu)的組成部分,如SVC,KNN等,并且探索出更優(yōu)的方法對于Stacking初級學(xué)習(xí)器中的基評估器種類數(shù)量的選擇,以及對最佳的滑動窗口維度的選擇.為了進一步嘗試使用到其他數(shù)據(jù)集進行實驗應(yīng)用,從而將本文方法應(yīng)用于信用評估領(lǐng)域的相關(guān)其他方面,并嘗試探索聯(lián)級結(jié)構(gòu)中學(xué)習(xí)器的數(shù)量與預(yù)測結(jié)果之間的關(guān)系以及相互影響,以確保整體的預(yù)測模型取得更佳效果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
