基于卷積神經(jīng)網(wǎng)絡(luò)的視頻監(jiān)控異常事件檢測研究
2023-05-30 01:22:32徐曉
電子技術(shù)與軟件工程 2023年6期
徐曉
(濟(jì)南工程職業(yè)技術(shù)學(xué)院工程管理系 山東省濟(jì)南市 250200)
智能視頻監(jiān)控系統(tǒng)憑借其能夠自主理解視頻內(nèi)容并反饋異常情況,在維護(hù)社會公共安全秩序和保障人民生命財產(chǎn)安全方面發(fā)揮重要作用。作為智能監(jiān)控系統(tǒng)的核心功能之一,視頻異常事件檢測技術(shù)旨在采用圖像處理與機(jī)器學(xué)習(xí)相關(guān)方法,自動識別監(jiān)控視頻場景中各類目標(biāo)(行人、汽車等)引發(fā)的各種偏離常規(guī)的事件。該項技術(shù)可以最大程度上協(xié)助工作人員及時發(fā)現(xiàn)并處理異常事件,在降低人力成本同時提高監(jiān)控效率,減少誤報和漏報情況。
近年來,研究人員開始探索基于卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)的視頻異常事件檢測方法,并陸續(xù)發(fā)表了一系列先進(jìn)成果。相較于先前異常檢測領(lǐng)域綜述文獻(xiàn)[1,2],本文根據(jù)不同方法提供的異常檢測結(jié)果的精細(xì)程度與語義水平,創(chuàng)新地將現(xiàn)有基于CNN 的異常檢測方法分為幀級別檢測方法、像素級別檢測方法及目標(biāo)級別檢測方法[3,4]。
其中,幀級別檢測方法判斷每幀圖像內(nèi)是否包含異常事件,僅能提供視頻序列時間維度上異常檢測結(jié)果,無法提供空間維度檢測結(jié)果;像素級別檢測方法在識別異常圖像幀基礎(chǔ)上,能夠判斷視頻幀內(nèi)哪些像素為異常;而目標(biāo)級別檢測方法可以檢測視頻幀內(nèi)由哪些監(jiān)控對象(車輛,行人等)引發(fā)異常事件。因此,相較于幀級別檢測方法,目標(biāo)級別檢測方法能夠提供精細(xì)程度更高異常檢測結(jié)果;而對比像素級別檢測方法,目標(biāo)級別檢測方法可以實(shí)現(xiàn)更高語義水平的異常檢測。由此目標(biāo)級別檢測方法成為視頻異常事件檢測領(lǐng)域主流方法,本文重點(diǎn)關(guān)注該類方法的相關(guān)工作。
目標(biāo)級別異常檢測方法重點(diǎn)針對監(jiān)控場景中各目標(biāo)空間外觀信息與時序運(yùn)動狀態(tài)進(jìn)行聯(lián)合建模,檢測可疑情況、定位并追蹤異常目標(biāo),主要包括場景目標(biāo)感知、檢測模型學(xué)習(xí)以及異常目標(biāo)推斷等步驟,如圖1所示。
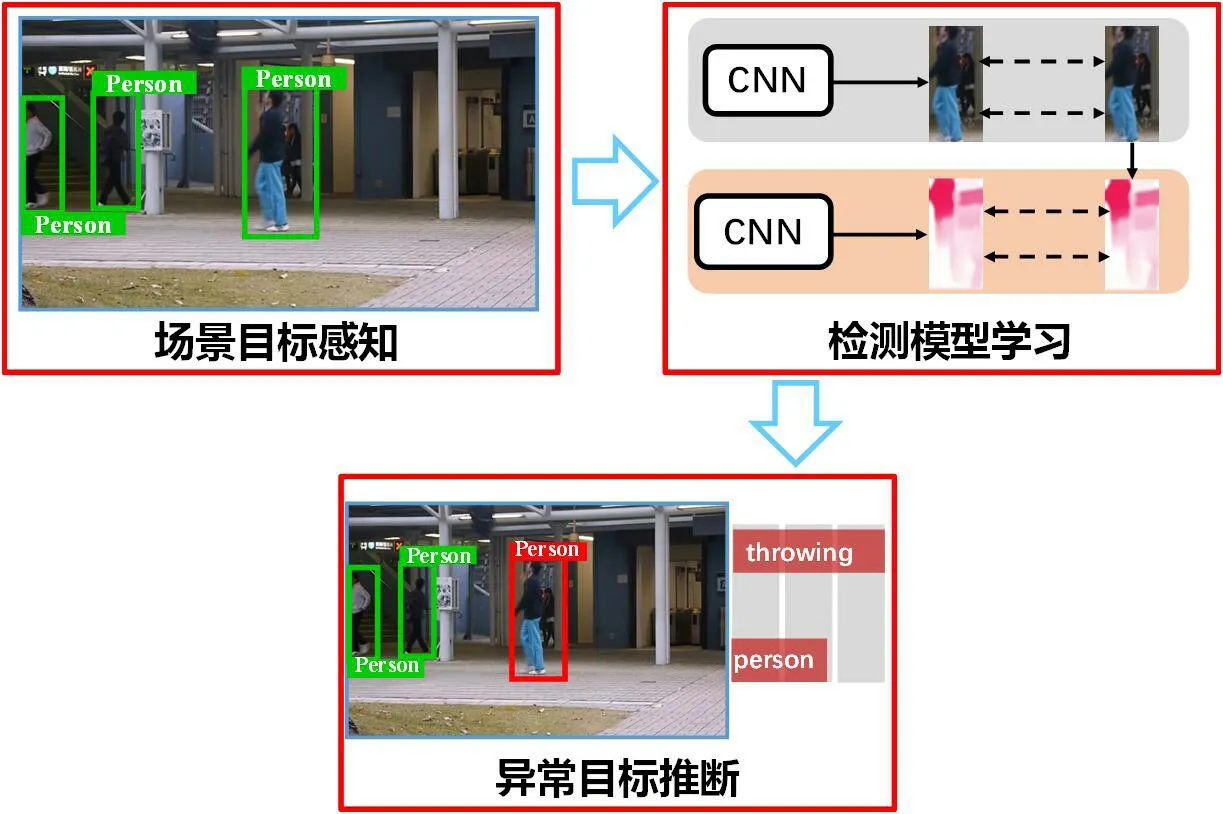
圖1:目標(biāo)級別異常檢測方法基本流程
1 場景目標(biāo)感知
通常情況下,監(jiān)控場景中發(fā)生的事件取決于各類前景目標(biāo)運(yùn)動與行為,受重復(fù)、靜止的背景影響不大。因此,為了避免因考慮背景而引入噪聲和冗余信息進(jìn)而增加運(yùn)算開銷的問題,目標(biāo)級別異常檢測方法首要環(huán)節(jié)是場景目標(biāo)感知,將視頻場景中高語義層次上監(jiān)控對象由背景分割出來,繼而進(jìn)一步提取其位置、尺寸、類別、軌跡、動作、外觀等信息。
1.1 基于目標(biāo)檢測的感知方法
最常用的目標(biāo)感知方法是基于目標(biāo)檢測方法,利用邊界框精準(zhǔn)定位前景目標(biāo)區(qū)域位置,同時提供類別標(biāo)簽。其中,YOLO(You Only Look Once)算法作為一種實(shí)時高幀率的目標(biāo)檢測方法,被廣泛使用[5~7]。此外,Li 等[8]對昏暗監(jiān)控場景的視頻圖像進(jìn)行彩色處理,并利用區(qū)域全卷積網(wǎng)絡(luò)(Region Fully Convolutional Network,RFCN)實(shí)現(xiàn)與場景背景表觀極為相似目標(biāo)的精確檢測,進(jìn)而提取目標(biāo)軌跡特征。在文獻(xiàn)[3]中,Hinami 等采用多任務(wù)快速RFCN 網(wǎng)絡(luò)學(xué)習(xí)場景目標(biāo)的外觀、動作、類別等通用的常識性知識。Yu 等[9]則在利用級聯(lián)RFCN 模型獲取目標(biāo)感興趣區(qū)域基礎(chǔ)上,使用啟發(fā)式濾波算法去除錯誤檢測的目標(biāo)區(qū)域,同時利用輪廓檢測算法基于時序梯度特征定位級聯(lián)RFCN 未能檢測到的目標(biāo)。
1.2 基于人體姿態(tài)估計的感知方法
基于目標(biāo)檢測的感知方法僅能根據(jù)邊界框提供監(jiān)控對象整體剛性運(yùn)動與外觀信息,難以刻畫局部非剛性姿態(tài)變化(重點(diǎn)針對行人)。因此,部分研究工作基于人體姿態(tài)估計方法如AlphaPose 等檢測視頻場景中人體目標(biāo)骨架關(guān)節(jié)點(diǎn),而后設(shè)計骨架特征來刻畫人體動作[4,10,11]。
Morais 等[4]使用骨架關(guān)節(jié)點(diǎn)坐標(biāo)連接成的特征向量作為骨架特征表示,并將其分解為全局特征分量與局部特征分量。全局分量用于提供人體骨架整體剛性運(yùn)動信息,反映人體運(yùn)動;而局部分量負(fù)責(zé)提供骨架內(nèi)部非剛性形變信息,反映人體動作。考慮到基于特征向量的表示方法難以反映骨架關(guān)節(jié)點(diǎn)間空間連接關(guān)系,Markovitz等[10]構(gòu)建時空骨架圖在時間和空間兩個維度上聯(lián)合表示骨架特征。骨架關(guān)節(jié)點(diǎn)作為圖節(jié)點(diǎn),符合人體結(jié)構(gòu)的不同關(guān)節(jié)點(diǎn)間自然連接作為圖空間邊,而不同時刻同一關(guān)節(jié)點(diǎn)間連接作為圖時序邊。
2 檢測模型學(xué)習(xí)
檢測模型學(xué)習(xí)是目標(biāo)級別異常檢測方法至關(guān)重要一步,旨在根據(jù)訓(xùn)練視頻中不同目標(biāo)的運(yùn)動、外觀、動作等特征表示構(gòu)建目標(biāo)模型,該模型能夠精準(zhǔn)建模不同目標(biāo)狀態(tài),并檢測待測視頻中與其他目標(biāo)具有明顯差異的異常目標(biāo)。近年來,各類CNN 如卷積自編碼器CAE 和生成對抗網(wǎng)絡(luò)GAN 被用作異常檢測模型。根據(jù)所用訓(xùn)練數(shù)據(jù)集中樣本標(biāo)簽情況,現(xiàn)有目標(biāo)級別異常檢測方法中檢測模型學(xué)習(xí)過程可分為半監(jiān)督學(xué)習(xí)方法、自監(jiān)督學(xué)習(xí)方法以及無監(jiān)督學(xué)習(xí)方法。
2.1 半監(jiān)督檢測模型學(xué)習(xí)方法
考慮到實(shí)際監(jiān)控場景中正常事件發(fā)生頻率較高,樣本易于獲取。半監(jiān)督檢測模型學(xué)習(xí)方法基于僅包含人工標(biāo)注為正常的事件樣本的訓(xùn)練視頻數(shù)據(jù)集,學(xué)習(xí)表征正常目標(biāo)狀態(tài)檢測模型。
Hinami 等[3]利用核密度估計方法學(xué)習(xí)監(jiān)控場景正常事件中目標(biāo)外觀、動作等特征分布概率模型。Yu 等[9]基于正常目標(biāo)外觀與運(yùn)動信息學(xué)習(xí)一個生成式CNN作為檢測模型,該模型以U-Net 網(wǎng)絡(luò)為基礎(chǔ)架構(gòu),利用U-Net 基于上下采樣特征拼接機(jī)制的生成能力,能夠?qū)φD繕?biāo)連續(xù)運(yùn)動過程中丟失部分進(jìn)行補(bǔ)全。
類似地,Morais 等[4]構(gòu)建消息傳遞編碼器-解碼器循環(huán)神經(jīng)網(wǎng)絡(luò)(Message-Passing Encoder-Decoder Recurrent Neural Network,MPED-RNN)對正常目標(biāo)骨架軌跡特征的全局和局部分量同時進(jìn)行重構(gòu)和預(yù)測,以此建模正常目標(biāo)運(yùn)動和動作模式。MPED-RNN 包含兩個分支,分別處理全局和局部分量。每個分支中的模型均為由三個RNN 模塊組成的單編碼器-雙解碼器結(jié)構(gòu):編碼器、重構(gòu)解碼器及預(yù)測解碼器。兩個分支間通過消息傳遞機(jī)制進(jìn)行交互。
針對人體目標(biāo)骨架特征的時空圖表示,Markovitz等[10]采用時空圖卷積網(wǎng)絡(luò)挖掘骨架時空圖中關(guān)節(jié)點(diǎn)間空間連接信息。
2.2 自監(jiān)督檢測模型學(xué)習(xí)方法
相較于半監(jiān)督學(xué)習(xí)方法,自監(jiān)督檢測模型學(xué)習(xí)方法能夠自動根據(jù)正常目標(biāo)特征樣本構(gòu)造偽異常目標(biāo)特征樣本,共同用于學(xué)習(xí)檢測模型,實(shí)現(xiàn)檢測模型全監(jiān)督式學(xué)習(xí),從而進(jìn)一步提升檢測模型表征能力,進(jìn)而獲得更好異常目標(biāo)檢測效果。
當(dāng)前基于自監(jiān)督檢測模型學(xué)習(xí)方法的相關(guān)研究較少。Georgescu 等[6]率先提出基于自監(jiān)督學(xué)習(xí)策略的異常檢測方法:首先,以t時刻目標(biāo)為中心,由t-T到t+T連續(xù)時刻目標(biāo)按時序維度進(jìn)行連接組成正常目標(biāo)運(yùn)動序列;其次,保留中心時刻目標(biāo),在中心時刻t之前以隨機(jī)時間間隙N跳幀添加T個先前時刻目標(biāo),同時在t之后以隨機(jī)時間間隙N跳幀添加T個后續(xù)時刻目標(biāo),將組成的非連續(xù)的、間歇性的目標(biāo)運(yùn)動序列作為異常樣本;最后,使用3D-CNN 提取正常序列與異常序列時空特征圖,基于二分類交叉熵?fù)p失函數(shù)訓(xùn)練2D-CNN 預(yù)測頭作為目標(biāo)運(yùn)動異常檢測模型。
2.3 無監(jiān)督檢測模型學(xué)習(xí)方法
對比半監(jiān)督與自監(jiān)督學(xué)習(xí)方法,無監(jiān)督檢測模型學(xué)習(xí)方法不依賴任何人工標(biāo)注的訓(xùn)練樣本,換言之,此類學(xué)習(xí)方法不需要獲得任何先驗(yàn)知識,能夠自動根據(jù)對待測視頻中目標(biāo)分析結(jié)果構(gòu)建檢測模型。
由于缺乏人工標(biāo)注的訓(xùn)練數(shù)據(jù)提供監(jiān)督信息,無監(jiān)督檢測模型學(xué)習(xí)方法往往需要依賴于一些假設(shè),其中最為常用的假設(shè)就是認(rèn)為無標(biāo)注數(shù)據(jù)中異常程度較高的樣本往往所占比例較低,而正常樣本所占比例較高;其次,異常樣本通常明顯區(qū)別于正常樣本。遵循該假設(shè),Li 等[8]將待測視頻場景中出現(xiàn)頻率較高的目標(biāo)類別視為正常,并以此構(gòu)建正常類別庫,同時將不屬于此正常類別庫的目標(biāo)類別判為異常。
3 異常目標(biāo)推斷
異常目標(biāo)推斷步驟旨在遷移訓(xùn)練階段學(xué)習(xí)到的檢測模型計算待測視頻場景中目標(biāo)異常得分,用于目標(biāo)異常程度評估,實(shí)現(xiàn)異常目標(biāo)檢測。異常目標(biāo)推斷方法取決于檢測模型類型,大致可分為基于距離的推斷方法、基于概率的推斷方法、基于分類的推斷方法及基于重構(gòu)的推斷方法。
3.1 基于距離的推斷方法
基于距離的推斷方法核心在于訓(xùn)練階段學(xué)習(xí)CNN作為特征提取模型,使正常目標(biāo)對應(yīng)提取到的特征向量分布盡量緊湊,換言之,盡可能縮短正常目標(biāo)特征分布內(nèi)樣本間距離(類內(nèi)距離);在測試階段,通過計算待測目標(biāo)特征與正常目標(biāo)特征間距離作為度量標(biāo)準(zhǔn)進(jìn)行異常檢測,度量距離超過設(shè)定閾值的被判為異常。
Doshi 等[5]首先對目標(biāo)運(yùn)動、位置及外觀特征進(jìn)行拼接融合,并基于小部分正常目標(biāo)特征構(gòu)建正常特征集合Θ;而后,計算Θ 中任意正常特征樣本對間kNN(k-Nearest Neighbor)歐氏距離,形成kNN 距離集合Θ;最后,計算待測目標(biāo)特征與Θ 中任意樣本間kNN 距離,并取最大值與Φ 中距離進(jìn)行對比,若偏差較大,則待測目標(biāo)為異常目標(biāo)。
3.2 基于概率的推斷方法
基于概率的推斷方法依賴概率統(tǒng)計模型實(shí)現(xiàn),訓(xùn)練階段學(xué)習(xí)概率模型描述正常目標(biāo)特征分布情況,主要估計概率模型的各種參數(shù);在測試階段,計算待測目標(biāo)特征在該模型下概率值作為異常得分,由于分布差異,異常目標(biāo)對應(yīng)較低概率值。
部分方法無需對特征概率分布類型做出假設(shè),而是通過大量樣本對模型進(jìn)行擬合。其中核密度估計(Kernel Density Estimation,KDE)方法是最為經(jīng)典的方法。例如,Hinami 等[3]基于高斯核采用KDE 方法學(xué)習(xí)正常目標(biāo)外觀、動作等特征分布概率模型。測試階段,計算待測場景不同目標(biāo)外觀、動作特征在該模型下的概率密度值作為異常得分,用于判別異常目標(biāo)。
3.3 基于分類的推斷方法
基于分類的推斷方法依賴分類模型實(shí)現(xiàn),訓(xùn)練階段由單類正常目標(biāo)特征生成正常及異常等多類樣本,學(xué)習(xí)分類模型區(qū)分正常和異常樣本;在測試階段,利用分類模型對待測目標(biāo)特征進(jìn)行正常/異常二分類。較為常用分類模型有SVM 分類器(傳統(tǒng)機(jī)器學(xué)習(xí)模型)與CNN分類器(先進(jìn)深度學(xué)習(xí)模型)兩種。
Ionescu 等在經(jīng)典二分類SVM 基礎(chǔ)上引入多分類SVM 進(jìn)行異常目標(biāo)推斷,計算待測目標(biāo)特征在k 個正常SVM 分類器下的類別概率,并取最大值作為異常得分。由于異常目標(biāo)特征不屬于先前劃分多類正常特征中任何一種,因此輸出較低類別概率,以此完成異常目標(biāo)檢測。
Georgescu 等[6]通過引入自監(jiān)督學(xué)習(xí)策略獲取正常目標(biāo)運(yùn)動序列與異常目標(biāo)運(yùn)動序列,并以其對應(yīng)高層次特征圖為輸入,基于交叉熵?fù)p失函數(shù)訓(xùn)練2D-CNN 作為分類模型;對于待測目標(biāo)運(yùn)動序列,將其對應(yīng)輸出分類矩陣中屬于異常類別的概率值作為異常得分,很明顯,異常目標(biāo)將獲得更高異常得分。
3.4 基于重構(gòu)的推斷方法
基于重構(gòu)的推斷方法依賴生成式CNN 模型如CAE實(shí)現(xiàn),其核心思想在于訓(xùn)練階段對輸入的正常目標(biāo)特征進(jìn)行編解碼操作,并以較低誤差重構(gòu)正常輸入為目標(biāo)訓(xùn)練網(wǎng)絡(luò)模型;在測試階段,針對訓(xùn)練過程未出現(xiàn)過的異常目標(biāo)特征進(jìn)行重構(gòu)時,將得到較差的重構(gòu)樣本,進(jìn)而獲得較大的重構(gòu)誤差。
由于生成式CNN 具有較強(qiáng)的泛化能力,即使僅基于正常目標(biāo)特征進(jìn)行訓(xùn)練,針對部分異常目標(biāo)特征也可以較好地重構(gòu),從而產(chǎn)生較低重構(gòu)誤差,導(dǎo)致異常漏檢。因此,另一種基于預(yù)測的方法被提出,通常與基于重構(gòu)的方法融合使用,以彌補(bǔ)其不足。
Morais 等[4]訓(xùn)練所設(shè)計的MPED-RNN 網(wǎng)絡(luò)對正常目標(biāo)骨架軌跡特征的全局和局部分量同時進(jìn)行完美重構(gòu)和預(yù)測;針對待測目標(biāo)骨架軌跡,直接對重構(gòu)誤差與預(yù)測誤差進(jìn)行求和融合作為異常目標(biāo)檢測依據(jù)。
Liu 等[12]則構(gòu)建ML-MemAE-SC 網(wǎng)絡(luò)與CVAE 網(wǎng)絡(luò)分別對正常目標(biāo)運(yùn)動狀態(tài)與外觀信息進(jìn)行重構(gòu)及預(yù)測;在測試階段,提出一種加權(quán)融合策略對待測目標(biāo)重構(gòu)誤差與預(yù)測誤差進(jìn)行融合,用于異常目標(biāo)推斷。
4 總結(jié)與展望
本文針對主流的目標(biāo)級別異常事件檢測方法進(jìn)行了回顧,從其3 個關(guān)鍵步驟(場景目標(biāo)感知、檢測模型學(xué)習(xí)集異常目標(biāo)推斷)出發(fā)對相關(guān)前沿工作進(jìn)行了分類與梳理。然而,現(xiàn)有研究仍具有一定局限性與片面性。本文對現(xiàn)有研究不足進(jìn)行了總結(jié),并對未來重點(diǎn)研究方向進(jìn)行了展望:
4.1 面向真實(shí)復(fù)雜場景的異常事件檢測研究
實(shí)際場景中,異常事件通常在城市商業(yè)區(qū)等人員密集區(qū)域出現(xiàn),時常伴隨雨霧和夜景等復(fù)雜氣象、光照條件。面對這類復(fù)雜場景,現(xiàn)有依賴簡單實(shí)驗(yàn)場景視頻數(shù)據(jù)訓(xùn)練的方法性能銳減。因此,未來工作需要考慮將常用可見光數(shù)據(jù)(RGB 圖像)與紅外數(shù)據(jù)、深度數(shù)據(jù)等進(jìn)行多模態(tài)融合實(shí)現(xiàn)真實(shí)復(fù)雜場景全天候的異常事件檢測。
4.2 跨多攝像機(jī)交接的異常事件檢測研究
實(shí)際場景中,異常目標(biāo)運(yùn)動軌跡復(fù)雜多變,常常連續(xù)跨多攝像機(jī)運(yùn)動。面對異常目標(biāo)遠(yuǎn)離當(dāng)前攝像機(jī)監(jiān)控區(qū)域而出現(xiàn)在另一攝像機(jī)監(jiān)控區(qū)域內(nèi)的情況,現(xiàn)有方法難以實(shí)現(xiàn)交接檢測。因此,未來工作需要考慮基于多攝像機(jī)目標(biāo)接力跟蹤算法實(shí)現(xiàn)跨多攝像機(jī)的異常目標(biāo)接力檢測。
4.3 在線自適應(yīng)的異常事件檢測研究
實(shí)際場景中,異常事件種類可能會隨場景變化而變化。面對這種變化,現(xiàn)有基于監(jiān)督式檢測模型學(xué)習(xí)模式的方法難以完成自適應(yīng)檢測。因此,未來工作需要考慮結(jié)合場景信息實(shí)現(xiàn)在線場景自適應(yīng)的異常事件檢測。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
