針對非均衡數據的人臉識別算法*
2023-06-04 06:23:58周輝
計算機與數字工程 2023年2期
周輝
(中國石油大學(華東)計算機與科學技術學院 青島 266580)
1 引言
得益于深度學習[1~3]的發展,人臉識別技術有了突破式發展。由于深度學習是數據驅動的方法,數據集的質量直接影響識別算法的精度。不幸的是,目前幾個比較常用的公共人臉識別數據集(CASIA-WebFace,MS1M,CelebA)都存在著樣本不均衡的問題,一般數目比較少的類稱之為UR數據(Under Represent Data)。幾乎在所有的人臉數據集中都存在UR 數據,這就使得在訓練網絡的過程中,通過網絡得到的數據分布不均衡,從而影響到網絡整體的識別性能。雖然目前人臉識別方向發展已經比較成熟,甚至都投入了商用,但是訓練中遇到的樣本不均衡數據始終制約著人臉識別,無法進一步提高人臉識別精度。早期的解決方法是直接去掉UR 數據類別,只對樣本數據多的類別進行訓練。但是這樣做會造成訓練數據不足,嚴重削弱網絡的泛化能力;另一種常用做法是通過歸一化權重的方式,強行將正常類別和UR 數據類別對應的權重向量歸一到同一均衡數據分布中,但會造成決策邊界傾斜[4],使學習得到的分布與實際的分布差異較大,影響最終識別效果;此外,還可以將UR 數據里的圖片通過旋轉、平移、縮放等仿射變換方式得到新的和原圖相似的圖片,將這些圖片和原圖一起送入網絡訓練:這類方法被稱作顯式數據增強,但是增強得到的數據與真實數據分布存在較大差異,所以這種顯式數據增強對網絡整體效果的提升并大。近年來,隱式數據增強作為一個處理樣本不均衡問題的新方法逐步受到人們關注。FTL[5]提出一種隱式數據增強手段:以類中心向量為基準,在特征空間做數據增強來訓練網絡。具體來說,由于人臉識別是一種細粒度分類問題[8],因此可以假設整個數據集滿足一種高斯分布,在這種高斯分布中,每個類別都有著自己特有的特征向量均值而共享一個協方差,因此,可以在訓練的過程中將普通類的協方差矩陣特征逐步遷移至UR 類,以此解決樣本不均衡問題。
然而,FTL 是基于center-loss 的一種處理不均衡數據集的衍生方法,這類算法只能使類內距離減小而不能使類間距離增大,這就使得數據整體在歐氏空間上不符合正態分布。因為數據符合正態分布是深度學習算法奏效的前提,所以這使得臉識別效果受到不利影響。
本文針對這一問題,將隱式數據增強引入角度量空間。因為通過softmax 損失獲得的特征具有固有的角度分布[7],所以在角空間進行隱式數據增強不會影響數據的整體分布。此外,還對FTL中的協方差矩陣做相關改進,使UR 類別在特征空間中盡可能地產生多樣性特征向量來減輕不均衡數據集對識別算法所造成的負面影響。
在通用數據集上的結果表明,該算法能有效提高最終的人臉識別精度。
2 本文算法
2.1 問題描述
2.2 損失函數
最常用的分類損失函數Softmax損失如下:
由于批正則化(batch normalization)的引入,bj的值已經不起作用,所以之后的論文基本將bj的值設置為0,這樣式(1)中,其中θj為與ai之間的夾角,同時設置及,這么做是為了將特征向量的模歸一到一個常數中,方便向量之間進行公平的比較,至此,特征預測和權重調整的預測就只依賴于θj,原式(1)可改寫為
通過式(2),需學習的特征向量就被分布在一個半徑為s 的超球面上了。Sphereface 很自然地將損失函數從歐式距離判別改寫成了角度距離判別,這種角度距離判別被證明更好地體現特征度量。為了使得特征向量有讓類內距離更小類間距離更大的能力,Sphereface引入變量m對式(2)做改進:
當一個特征向量在極坐標中同時和兩個類中心向量比較時,對于同類別的角度距離乘以m(m>1)。這樣,在有著監督信息的訓練過程中,就越希望同類別的角度距離小。不同類別的角度距離大,以此來抑制來保持損失函數盡量最小化。為了進一步優化這個算法,Sphereface 的衍生方法Arcface對變量m做相關改進,最終得到可以使類內距離更小而類間距離更大的優化式(4):
在式(4)中,m1,m2,m3都是超參用于提升特征向量的表征能力。與Arcface 相同,將三個超參m1,m2,m3分別設置為1,0.3,0.2。
本文使用在特征域對UR類圖像做隱式語義數據增強。為了得到UR 類特征向量的語義方向,這里假定增強后的特征向量滿足正態分布N(ui,λ∑),即,根據Sphereface,每個類別的中心特征向量可以由其網絡最后一層FC對應的相關類別權重向量來表示,即第j 個類別的權重向量可以作為此類的類中心向量表征。為所有普通類中心向量的協方差矩陣,初始的∑并不能完全獲得真實的分布信息,為了解決這個問題,本是使用退火策略,先隨機初始化∑,在訓練過程中∑,將學習得到的∑比重慢慢增加,本文設置,t 為第t 個迭代周期,T 為總迭代周期。為了使UR 類數據得到更好的訓練,本文通過學習普通類協方差矩陣將這種特性引入UR類,從而得到盡可能多的UR類數據滿足訓練。
首先,將普通類圖像以顯式數據增強的方式即旋轉,裁剪等方法送入網絡訓練,得到圖片的特征向量ai,再利用特征向量ai使用式(5)迭代計算協方差矩陣∑:
其中ni為每一類的圖片樣本總數。然后對這個協方差矩陣λ∑,做隨機采樣M 次得到一個新的矩陣,根據矩陣Q對UR 類圖片送入網絡得到的特征向量ui做隱式數據增強,最終得到的隱式數據增強特征向量vi,具體計算過程如式(6)所示:
M為隨機對協方差矩陣∑的抽樣次數,每次得到的隱式數據增強特征向量記為vik,θjk為vik與WTj之間的夾角。
2.3 算法流程
整體網絡框架如圖1 所示,本文算法主要是在網絡中將普通類和UR 類交替訓練,在訓練的過程中慢慢學習得到協方差矩陣∑,以協方差矩陣對UR類在網絡中的特征向量做數據增強。算法流程步驟如下:
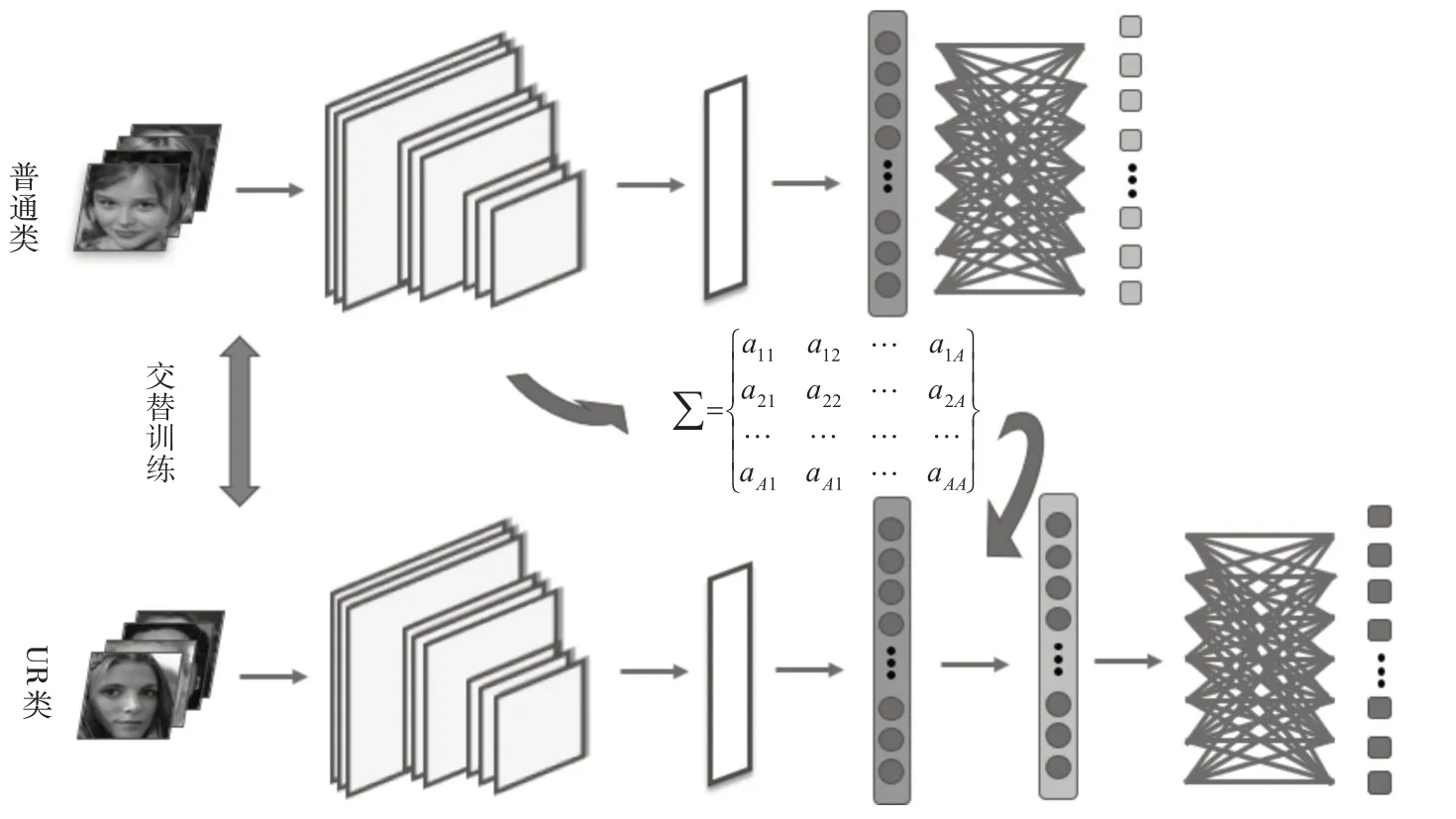
圖1 網絡結構圖
輸入:人臉數據集D,初始超參λ0。
輸出:類中心特征向量矩陣W,深度網絡G 權重參數Θ。
Step1.隨機初始化W、Θ,設置整體迭代周期為T,初始迭代時刻設置為t=0。
Step2.1. 將最小批量樣本送入網絡G 計算出特征向量ai=G(xi,Θ)。
Step2.3. 使用SGD 或者Range 優化器迭代更新W、Θ,并重復Step2過程,直至遍歷完整個人臉數據集的普通類。
Step3.1. 將最小批量樣本送入網絡G 計算出特征向量ui=G(zi,Θ)。
Step3.2. 根據式(6)隨機采樣協方差矩陣λ∑將隱式數據增強M 次,得到特征向量集帶入式(7)計算損失L。
Step3.3. 使用Adam 優化器迭代更新W、Θ ,并重復Step3過程,直至遍歷完整個人臉數據集的UR類。
Step4.迭代時刻t自加1,重復Step2、Step3步驟,直至t=T結束。
3 實驗及結果分析
3.1 數據集及評價標準
本文方法使用CASIA-WebFace 人臉數據集對網絡進行訓練,并在多個公開人臉數據集LFW 、YTF、IJB-A、MegaFace 進行人臉驗證、人臉鑒定實驗評估。
1)CASIA-WebFace:由溫森塞公司的Dong Yi和中國科學院的Zhen Lei 等于2013 年發布。 是一個大規模人臉數據集,主要用于身份鑒定和人臉識別,其包含10,575 個主題和494,414 張圖像,該數據集采用半自動的方式收集互聯網人臉圖像,并以此簡歷大規模數據集。
2)LFW:該數據集是目前人臉識別的常用測試集,其中提供的人臉圖片均來源于生活中的自然場景,因此識別難度會增大,尤其由于多姿態、光照、表情、年齡、遮擋等因素影響導致即使同一人的照片差別也很大。并且有些照片中可能不止一個人臉出現,對這些多人臉圖像僅選擇中心坐標的人臉作為目標,其他區域的視為背景干擾。LFW 數據集共有13233 張人臉圖像,每張圖像均給出對應的人名,共有5749 人,且絕大部分人僅有一張圖片。每張圖片的尺寸為250×250,絕大部分為彩色圖像,但也存在少許黑白人臉圖片。
3)YTF:數據集包含了3425 個視頻,涉及1595個不同的人。所有的視頻都是從YouTube 上下載的,平均每個科目有2.15 個視頻,最短的剪輯長度為48幀,最長的剪輯長度為6070幀,平均一段視頻的長度為181.3幀。
4)IJB-A:一個用于人臉檢測和識別的數據庫,全稱為IARPA Janus Benchmark A,其包含1845 個對象、11754 張圖片、55026 個視頻幀、7011 個視頻和10044 張非人臉圖像,該數據集由美國國家標準化研究院NIST 發布。
5)MegaFace:由華盛頓大學(University of Washington)計算機科學與工程實驗室于2015年針對名為“MegaFace Challenge”的挑戰而發布并維護的公開人臉數據集,是目前最為權威熱門的評價人臉識別性能的指標之一。數據集中的人臉圖像均采集自Flickr creative commons dataset,共包含690,572個身份共1,027,060張圖像。這是第一個在百萬規模級別的人臉識別算法測試標準,本文使用MegaFace Challenge 1做id檢測。
本文對網絡性能的評估分別在人臉驗證和人臉鑒定兩個識別任務中進行,人臉驗證則是根據給定的兩張人臉圖像判斷它們是否是同一個人,而人臉鑒定主要是將給定的面部圖像賦予已知身份的面部鑒定。人臉驗證的評測指標本文使用常用指標FAR(False Accept Rate)即鑒定錯誤接受比例,具體計算公式如下:
T為閾值選取參數,本文閾值選取為0.01,即評價指標為FAR@.01。對于人臉鑒定評價就采用常用的檢索準確度,這里取Rank1測試精度。
3.2 實驗設置
本文方法實驗設計和ArcFace的實驗設置基本一致。本方法采用基本神經網絡框架ResNet50,采用損失函數為式(7),根據上述算法流程展開實驗。經過實驗驗證分析,本文將式(7)中三個超參m1,m2,m3分別設置為1,0.3,0.2。其他方法如Cos-Face參數都選用其論文中的最優結果。
在數據處理部分中,本文將人臉數據按照各類中數量高于20 的歸為普通類,低于或等于20 的歸為UR類。根據文獻[12]提出了標準化的面孔對原始人臉圖片進行裁剪及相關仿射變換,使圖片尺度變為112×112且更易于網絡提取特征的最終圖片。
本文所有實驗代碼實驗都基于Pytorch,使用了兩塊NVIDIA Tesla P40 GPU,在CASIA WebFace人臉數據集中,采用隨機梯度下降Adam優化器,設置batch-size 為64,初始學習率為0.1,在迭代周期10k、20k、28k 時分別將學習率降為原來的10%,總共迭代周期為30k次。
3.3 結果及分析
表1~2 所示為不同方法使用CASIA WebFace人臉數據集上訓練并在多個測試數據庫上分別做人臉驗證和人臉鑒定的結果。通過數據對比,可以看出本文算法在人臉驗證和人臉鑒定的表現均優于所有對比方法。其中實驗的網絡框架都是使用了ResNet50,以保證對比的公平性。從表中信息可以觀測出ArcFace的性能無論是在人臉驗證和人臉鑒定中都優于其他方法,FTL 方法是基于Center-Loss 和隱式數據增強的方法,性能由于Center-Loss,但是在和ArcFace的比較中并沒有很強的優勢,本文將隱式數據增強方法引入角度距離度量損失函數,實驗表明結果良好。

表1 不同方法在LFW和YTF數據集中FAR@.01

表2 不同方法在IJB-A和MegeFace數據集中Rank1
為了更好地驗證本方法隱式增強特性,本文也考慮了對協方差矩陣的抽樣次數做了相關對比實驗,如圖2 所示,從圖中可以看出,人臉驗證和人臉鑒定的精度在開始階段都隨著M的增加而增加,但是在M 到了60 之后就不會再增加了。是由于隨著單個樣本特征向量的隱式擴充,導致該類分布的方差超出了一定界限,最終造成精度的下降,本文根據人臉驗證和鑒定的最優精度取M對應的值。


圖2 協方差矩陣的抽樣次數對實驗精度的影響
此外,還研究了Batch-Size 的大小對結果的影響,如表3、4所示,最終根據結果選取Batch-Size為64。
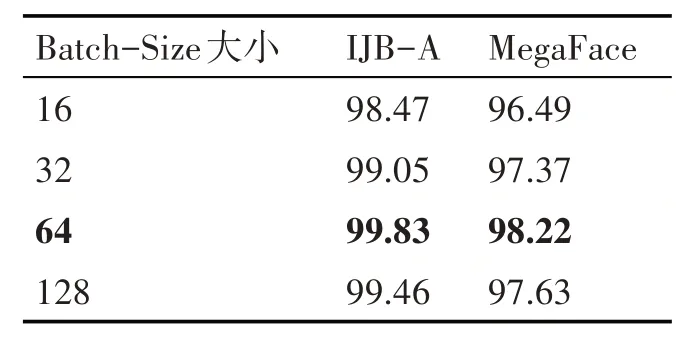
表3 不同Batch Size在兩種人臉鑒定數據集中Rank1

表4 不同Batch Size在兩種人臉驗證數據集中FAR@.01
4 結語
本文提出一種將隱式數據增強引入角度量損失函數的人臉識別算法,有效地緩解了樣本不均衡對識別精度的不利影響。隱式數據增強使深度神經網絡訓練更有針對性,從而使不同數據集的人臉識別性能得到提升,對之后的人臉識別工作有啟發性意義。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2017年17期)2017-12-18 06:40:55
電子制作(2017年1期)2017-05-17 03:54:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
計算機工程(2015年8期)2015-07-03 12:19:07
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
