DeepCA-VO:基于通道域注意力機制的視覺里程計方法*
2023-06-04 06:24:18熊志麗劉華軍
計算機與數字工程 2023年2期
熊志麗 劉華軍
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
同時定位與地圖構建(Simultaneous Localization and Mapping,SLAM)問題一直備受機器人和自動駕駛領域的關注,在經典的視覺SLAM 框架中,視覺里程計(Visual Odometry,VO)扮演著前端的作用,即在讀取傳感器傳來的信息后,通過相鄰兩幀的圖像信息估計出圖像之間的相對運動,運動主要包括旋轉和平移兩個層面。VO的概念最早應用領域為火星探索[1]。傳統的VO 工作流程主要包括:相機校準、對輸入的圖像進行特征的提取和篩選、相鄰幀的特征匹配、異常值剔除、運動估計和比例估計、局部優化、最后輸出位姿。可見傳統VO系統的運行過程比較復雜,分為很多模塊,每個模塊都有各自的算法,將不同模塊耦合在一起也是工作重點。
傳統方法按照是否提取特征可以分為特征點法和直接法。特征點法主要運用在場景紋理豐富、特征明顯的情況下。特征點由關鍵點和描述子組成,在提取關鍵點后再通過計算描述子對關鍵點進行篩選。提取關鍵點是指獲得像素點的位置,而描述子是一個向量,能夠根據人工設計的方法對該關鍵點周圍的像素信息進行描述,減少甚至消除相機視角的變化對圖像尺度和方向的影響,更好地進行幀間匹配。有的特征點還包含朝向、大小等信息。SIFT[2]、SURF[3]、BRIEF[4]是描述子常見的算法。
直接法主要用光流來描述運動信息。光流分為計算所有像素的稠密光流以及計算部分像素的稀疏光流。稀疏光流的代表有Lucas-Kanade(LK)光流[5],可用于SLAM 的特征點位置跟蹤。通常被用來跟蹤角點的運動。稠密光流的代表則有Horn-Schunck[6]光流。
目前像ORB-SLAM2[7]這樣的特征點法在精度上已經能夠達到工業界的要求,但特征點的篩選和匹配算法計算復雜耗時較大,而且受環境影響嚴重。當處于光線暗以及紋理弱的環境下,能檢測到的特征點數量會大大下降,從而對結果產生很大影響。而基于光流的直接法雖然運行速度快,但由于該方法依賴于像素的運動,因此受光照強度變化的影響很大。而隨著深度學習的興起及其在圖像特征檢測方面的卓越優勢,學者們看到了用深度學習解決視覺里程計問題的潛力。另外,基于深度學習的方法不需要人工設計特征,這也是此類方法的一大優勢。
在特征提取,特征匹配及位姿估計這些環節都可以引入深度學習。LIFT(Learned Invariant Feature Transform)[8]就采用深度學習的框架實現了特征提取的功能,其性能甚至優于傳統的SIFT 算法。D2-Net((A Trainable CNN for Joint Description and Detection of Local Features)算法是由Mihan 等人[9]提出的,該方法對光照的魯棒性較好。而在位姿估計環節,因為CNN 在對序列關系進行建模方面表現不盡如人意,此環節引入了循環神經網絡(RNN),后來由于RNN 不適合用于長時序列的估計,而LSTM(Long Short-Term Memory)[10]能很好地解決這個問題,逐漸用LSTM替代了原始的RNN。
2 相關原理
2.1 CNN用于特征提取
卷積神經網絡(Convolutional Neural Network,CNN)的研究自21世紀80年代開始,在經歷少有人問津的幾十年后,隨著深度學習理論的提出重現于人們的視野中。為了適應不同的學習任務,各種各樣的CNN結構層出不窮。著名的結構有AlexNet[11],VGG,GoogleNet,ResNet等。
對于視覺里程計問題,因為視覺里程計和圖像分類,目標跟蹤這類問題有很大區別,我們不能簡單地采用這些流行結構來解決問題。這里我們采用2015 年Dosovitskiy 等[12]提出的卷積神經網絡FlowNet-S。這是一種用于估計幀間光流的卷積神經網絡,可以學習圖片間的幾何特征。但我們只關注FlowNet-S 網絡前面的卷積部分,丟掉了后面的反卷積部分。
2.2 LSTM解決時序性問題
循環神經網絡(RNN)主要用于處理時序輸出信號。RNN 的網絡深度的增加有助于網絡在更加抽象的特性上的表達,將上一層RNN 的輸出作為下一層RNN 的時序信號輸入,依次往上疊加,最后一層RNN 的輸出作為整個網絡的輸出,深度RNN網絡由此形成。RNN 的狀態更新方程。以及輸出方程為
梯度消失問題產生的原因是當前時刻的梯度往前傳播時,梯度會隨著時間間隔變長而變小。采用LSTM 可以很好地解決這個問題,其內部結構如圖1。LSTM 采用三個門來處理輸入信號、內部狀態以及輸出信號,其中輸入門對輸入信號進行過濾,遺忘門對上一時刻狀態進行過濾,輸出門對輸出信號進行過濾。幾何法求解VO 問題時,經常會考慮集束約束(Bundle Adjustment,BA)問題,其實就是把多幀圖片之間的約束關系考慮進來,從而提高VO估計的精度。

圖1 LSTM內部結構
2.3 注意力機制
近兩年,注意力模型在自然語言處理、圖像識別及語音識別等各種不同類型的深度學習任務中有著廣泛使用。人們對他們注意到的目標內部以及該場景內每一處空間位置上的注意力分布是有區別的。注意力機制是一種能讓模型對重要信息重點關注并充分學習吸收的技術。計算機視覺中的注意力機制分為通道域注意力機制,空間域注意力機制,混合域注意力機制。本文采用的是通道域的注意力機制[13]。
對于通道域注意力機制的原理,聯系傅里葉變換我們可以從信號變換的角度理解。時頻變換可以將正弦波信號轉換成頻率信號,而所有的信號都可以看成是正弦波的線性組合。在卷積神經網絡中,每張RGB 圖片都由三個通道表示,在經過不同的卷積核卷積之后,每一個通道又會生成新的信號,比如對圖片特征的每個通道用64 個卷積核進行卷積操作,就會產生64 個新通道的矩陣(H,W,64)。可將這64 個新通道的特征視為圖片在不同卷積核上的分量表示。產生的新的64 個通道對于關鍵信息的貢獻理論上來說不盡相同,那么每個通道對關鍵信息貢獻度可以用權重來代表,權重越大,則表示相關度越高,說明此通道需要被注意。
3 融合了注意力機制的VO方法
本文所提出的網絡結構可以端到端地輸出相機位姿,主要由基于卷積神經網絡的特征提取器和基于LSTM 的位姿回歸器組成。通過對特征提取模塊添加注意力機制子網絡使得卷積神經網絡能提取到更多利于位姿估計的特征。本文的網絡結構參考DeepVO[14],但在此基礎上做了以下改進:
1)卷積神經網絡最后加了一層池化層,使得特征圖維度進一步降低。
2)DeepVO中隨機產生長度不同的序列作為網絡的輸入,而本文采取固定長度輸入,序列長度為超參數,可以根據需要進行調整。
3)DeepVO 中采用了兩層LSTM,本文只有一層。
4)本文的方法添加了通道域注意力模塊。
3.1 基于卷積神經網絡的特征提取器設計
該網絡一共包含十層卷積,每層卷積后面都接一個非線性激活函數ReLU(Rectified linear unit)。本文在最后一層卷積層后加一個池化層,起到降低特征圖維度,減少網絡參數的作用,將經過CNN 處理得到的多個10×3×1024 大小的張量拉伸為一維向量后再輸入給LSTM。所有的圖像在輸入前統一將尺度調整為1280×384,因為輸入的是圖像對,且都為RGB圖像,所以通道數為6。
LSTM層的主要作用是讓網絡自動學習連續多個姿態時序上的內在關系,因為LSTM 能記住前面多幀圖片之間的幾何關系,然后再對當前時刻的姿態進行估計,達到多幀圖片之間幾何約束的效果。因為Sigmoid 激活函數會將數據限定在(-1,1)之間,完整的網絡結構如圖2所示。

圖2 CNN-LSTM網絡結構圖
3.2 基于卷積神經網絡的特征提取器設計
卷積神經網絡在提取特征時對每個通道一視同仁,這顯然是不合理的。基于通道域的注意力機制[13]通過對通道之間的相互依賴關系進行建模,能夠自動改變通道對特征的響應,選擇性地關注有用的特征并抑制不太有用的特征。這種子網絡的計算成本很低,但能給性能帶來明顯的提升。具體操作是將特征圖放到一個向量上去操作,給響應最大的位置更多的權重。將基于通道域注意力模塊集成到本文提出的深度學習網絡框架中進行端到端的訓練。其基本結構如圖3 所示,集成到深度學習網絡框架后的網絡結構如圖4所示。

圖3 通道域注意力機制子網

圖4 添加注意力模塊的網絡框架
3.3 用于數據增強的網絡結構設計
在之前的基礎上設計了一種網絡結構,通過添加約束使網絡更準確地估計相對位姿。如圖5 所示,網絡結構是左右對稱的,左邊和上文提到的網絡結構一樣,而右邊結構為左邊結構翻轉得到,各個部分的參數共享。左右兩邊同時輸入,但右邊的輸入序列為左邊輸入序列的逆序。最后對輸出的兩個姿態一起計算誤差并優化。

圖5 數據增強后的網絡結構

圖6 注意力機制對性能的影響
3.4 損失函數及優化
可以把VO 估計問題看成一個條件概率問題:給定一個序列的圖片(I1,I2,I3…,In),計算得到這串序列中兩兩相鄰的圖片之間的相對位姿的概率:
求解最優的網絡參數w使得上述概率最大化:
對于N 個序列,采用MSE(Mean Squared Error)作為誤差評價函數,可以得到最終需要優化的函數:
β為尺度因子,用于保持位移誤差和轉角誤差的平衡性。
4 實驗結果與分析
本節通過3 組實驗驗證了本文設計的基于通道域注意力機制的視覺里程計網絡的有效性,第1組實驗致力于比較添加注意力模型對網絡性能的影響。第2 組實驗對不同方法性能進行了比較,包括傳統方法VISO2_M 和VISO2_S,以及基于深度學習的方法DeepVO。第3 組實驗致力于驗證本文方法在不同數據集上的有效性。
4.1 數據集
4.1.1 KITTI數據集
KITTI Visual Odometry[15]是目前自動駕駛領域最重要的測試集之一,該數據集提供了很多基準如立體評估、光流估計、深度估計等。KITTI數據集還可以廣泛用于評估各種VO 或者視覺SLAM 算法。KITTI VO benchmark 共包含22 個場景序列。其中前11 個場景還包含汽車行駛軌跡的真值,本文方法只需用到雙目圖像中的單目圖像。
和DeepVO 一樣,將序列00,01,02,08,09 作為訓練集,序列03,04,05,06,07,10作為測試集。
4.1.2 Microsoft 7-Scenes數據集
Microsoft 7-Scenes[16]是一個由手持Kinect RGB-D 相機在7 個不同的室內辦公場景中采集的RGB-D 圖像組成的數據集。并使用KinectFusion獲取真實位姿。每個場景包含若干運動方式不同的序列,在室內存在運動模糊、感知混疊以及無紋理的情況。
4.2 實驗環境及參數配置
本實驗采用一塊英偉達泰坦顯卡(NVIDIA TITAN X Pascal GPU)來訓練和測試網絡。通過深度學習框架Pytorch 進行相關算法的設計。優化方法為批量梯度下降法(Batch Gradient Descent),其它參數詳情見表1。

表1 網絡超參數設置
4.3 實驗結果與分析
目前在KITTI VO/SLAM 數據集上最常用的評價指標有四種:不同長度子序列的平均旋轉誤差(Translation errors for subsequences)和平均平移誤差(Rotation errors for subsequences),以及不同時速下的平均平移誤差(Translation errors for different speeds)和平均旋轉誤差(Rotation errors for different speeds)。
4.3.1 注意力模型對性能的影響
本文測試的網絡分別為基于深度學習的視覺里程計方法CNN-LSTM-VO 和在此基礎上添加了通道域注意力模型的視覺里程計方法Deep-CA-VO,以及經過數據增強后的網絡Deep-CA-VO-cons。不同網絡測試后的軌跡對比圖如6所示,其中gt表示位姿標簽。
針對常用的前兩種評價指標,在不同長度序列(100m,200m,…,800m)上計算平移矢量和旋轉量的均方誤差,計算其均值并以此作為視覺里程計方法的精度指標。具體數值如表2 所示。從表中可以看到添加了注意力機制后,網絡對旋轉的估計精度提高較對平移估計精度提高更顯著。

表2 注意力機制有無在04,07,10序列上的誤差
4.3.2 與其它方法的性能比較
本節選擇主流的三種方法VISO2-M,VISO2-S,DeepVO 與添加了注意力模塊且經過數據增強網絡DeepCA-VO-cons 進行對比。前兩種是主流的傳統方法,區別在于VISO2-M 是單目視覺里程計方法,而VISO2-S 是雙目視覺里程計方法。而DeepVO 是近期提出解決視覺里程計問題主流的深度學習框架。如表3 所示,顯示了不同方法在不同序列下平均平移和旋轉誤差的RMSE。圖7是不同方法在序列07 上的軌跡圖。在不同路徑長度下,本文提出的方法優于VISO2-M,與DeepVO 性能接近,分析原因是DeepVO 使用了兩層LSTM,因此對序列依賴關系的學習能力更強。而VISO2-S用到了雙目圖像,性能普遍比單目視覺里程計方法要好。

表3 不同方法性能對比
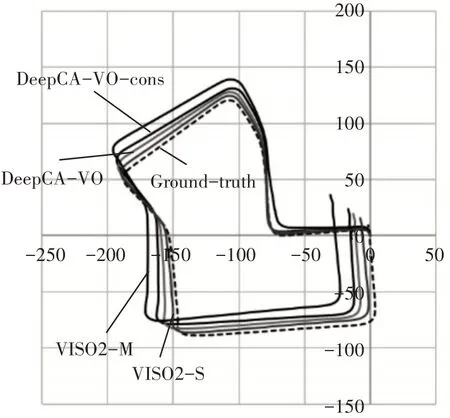
圖7 與其它方法的性能比較
4.3.3 在Microsoft 7-Scenes數據集上的結果分析
本節選擇用Fire,Office,RedKitchen 以及Stairs場景下的序列作為訓練集,其余Chess,Heads,Pumpkin 場景下的序列作為測試集。由于室內數據集上的平移分量較室外數據集上的小,因此在訓練過程中降低了損失函數中旋轉與平移分量權重因子β的值。圖8顯示了Chess場景下seq-02上估計的軌跡結果。結果表明本文提出的方法在不同場景下也具有可用性。

圖8 在chess場景seq-02上的軌跡估計結果
5 結語
本文提出了一種新的端到端的基于深度學習并融入通道域注意力機制視覺里程計算法。通過融合基于通道域的注意力機制,使得網絡模型能夠學到更多有用的特征,相比于傳統算法,具有更準確的結果,同時摒棄了相機標定,特征提取等復雜過程。在不同場景下具有實用性,且具有較高的穩定性。相比于其它的基于深度學習的網絡,其復雜度低,對硬件要求相對較低。下一步的工作將考慮增加樣本空間,提高位姿估計效果,更好地應對測試集中樣本多樣性增多的情況。考慮采用輕量化網絡,減少網絡參數,加快網絡訓練速度,拓展其應用前景。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
