融合相似度算法與預(yù)訓(xùn)練模型的中文電子病歷實(shí)體映射方法研究*
2023-06-30 02:27:24馮鳳翔任慧玲李曉瑛王巍潔
醫(yī)學(xué)信息學(xué)雜志 2023年5期
馮鳳翔 任慧玲 李曉瑛 王巍潔 王 勖 張 穎
(中國醫(yī)學(xué)科學(xué)院/北京協(xié)和醫(yī)學(xué)院醫(yī)學(xué)信息研究所/圖書館 北京 100020)
1 引言
隨著計(jì)算機(jī)技術(shù)和生物技術(shù)的飛速發(fā)展,電子病歷(electronic medical record,EMR)、醫(yī)學(xué)報(bào)告、醫(yī)學(xué)文獻(xiàn)等生物醫(yī)學(xué)文本的數(shù)量迅速增長(zhǎng),積累了海量有價(jià)值的醫(yī)學(xué)數(shù)據(jù)[1],如EMR記錄患者全部診療過程,包括所患疾病、藥物、檢查和治療結(jié)果等[2]。隨著命名實(shí)體識(shí)別技術(shù)成熟,可實(shí)現(xiàn)從中抽取疾病、藥物、手術(shù)操作等特定實(shí)體[3],但實(shí)體存在表述口語化、多樣化等問題,如“狼瘡腦炎”可能被表述為“狼瘡腦病”,“氯硝柳胺”可能被寫作“滅絳靈”等。如果未經(jīng)處理就加以利用或者儲(chǔ)存入庫可能導(dǎo)致各醫(yī)療信息系統(tǒng)標(biāo)準(zhǔn)不一,難以實(shí)現(xiàn)醫(yī)院間資源互聯(lián)互通[2]。因而需要根據(jù)實(shí)體在文中語義表達(dá)將其映射到知識(shí)庫中對(duì)應(yīng)的標(biāo)準(zhǔn)實(shí)體上,以解決概念內(nèi)涵不清、語義表達(dá)和邏輯不一致等問題,促進(jìn)獨(dú)立醫(yī)療信息系統(tǒng)間的互操作,實(shí)現(xiàn)醫(yī)療信息和數(shù)據(jù)共享[4]。
目前中文電子病歷實(shí)體映射研究主要由中國健康信息處理會(huì)議(China Health Information Processing Conference,CHIP)中的臨床術(shù)語標(biāo)準(zhǔn)化評(píng)測(cè)任務(wù)推動(dòng),該任務(wù)使用來自真實(shí)醫(yī)療數(shù)據(jù)中的手術(shù)原詞,由專業(yè)人員依據(jù)《ICD 9—2017協(xié)和臨床版》手術(shù)詞表進(jìn)行訓(xùn)練數(shù)據(jù)標(biāo)注。目前已有多支隊(duì)伍完成手術(shù)實(shí)體映射任務(wù),CHIP 2019任務(wù)最佳結(jié)果F1值為94.83%,由Dolphin-ICI團(tuán)隊(duì)取得[5]。實(shí)體映射作為一項(xiàng)重要的生物醫(yī)學(xué)技術(shù),近年來取得較大進(jìn)步。但由于生物醫(yī)學(xué)領(lǐng)域本身的復(fù)雜性以及真實(shí)醫(yī)療應(yīng)用場(chǎng)景的高標(biāo)準(zhǔn)、嚴(yán)要求,該領(lǐng)域研究還存在一些提升空間,如現(xiàn)有研究大都以預(yù)訓(xùn)練語言模型BERT為基礎(chǔ)進(jìn)行任務(wù)構(gòu)造,相關(guān)研究主要圍繞CHIP任務(wù)中標(biāo)注的手術(shù)實(shí)體進(jìn)行[6],還需增加基于多類型實(shí)體的映射方法研究、改進(jìn)方法模型以提升實(shí)體映射效果。
本文依靠專家知識(shí)與標(biāo)準(zhǔn)詞表,標(biāo)注涵蓋多種類型實(shí)體的自標(biāo)注標(biāo)準(zhǔn)數(shù)據(jù)集。結(jié)合傳統(tǒng)文本匹配方法與深度學(xué)習(xí)的優(yōu)勢(shì),提出融合傳統(tǒng)相似度算法與深度學(xué)習(xí)模型的聯(lián)合模型改進(jìn)實(shí)體映射效果。并在此基礎(chǔ)上提出基于別名間相似性映射標(biāo)準(zhǔn)實(shí)體的方法,為提升較短字符類實(shí)體映射效果提供思路。本文提出的方法在自標(biāo)注數(shù)據(jù)集中F1值達(dá)到94.87%,可幫助抽取和規(guī)范化醫(yī)療數(shù)據(jù)以擴(kuò)充中文臨床醫(yī)學(xué)術(shù)語體系的實(shí)體覆蓋度,更好地支持臨床輔助診療系統(tǒng)、精準(zhǔn)醫(yī)學(xué)研究和疾病監(jiān)控等應(yīng)用。
2 研究?jī)?nèi)容
2.1 數(shù)據(jù)來源
從“愛愛醫(yī)” “眾意好醫(yī)師”“病歷網(wǎng)”中抽取20 000余條中文電子病歷,采用命名實(shí)體識(shí)別模型對(duì)疾病診斷、解剖部位、臨床檢查、手術(shù)操作和藥物5類實(shí)體進(jìn)行識(shí)別[7]。每類實(shí)體分別抽取約500個(gè)樣例,邀請(qǐng)3位臨床專家根據(jù)《國際疾病分類第10次修訂本》(International Classification of Disease V 10,ICD 10)和《常用臨床醫(yī)學(xué)名詞(2019年版)》,人工標(biāo)注標(biāo)準(zhǔn)實(shí)體,數(shù)據(jù)清洗后,形成共包含2 390對(duì)數(shù)據(jù)的自標(biāo)注標(biāo)準(zhǔn)數(shù)據(jù)集,訓(xùn)練集與測(cè)試集數(shù)據(jù)按照7∶3的比例進(jìn)行分配,見表1。
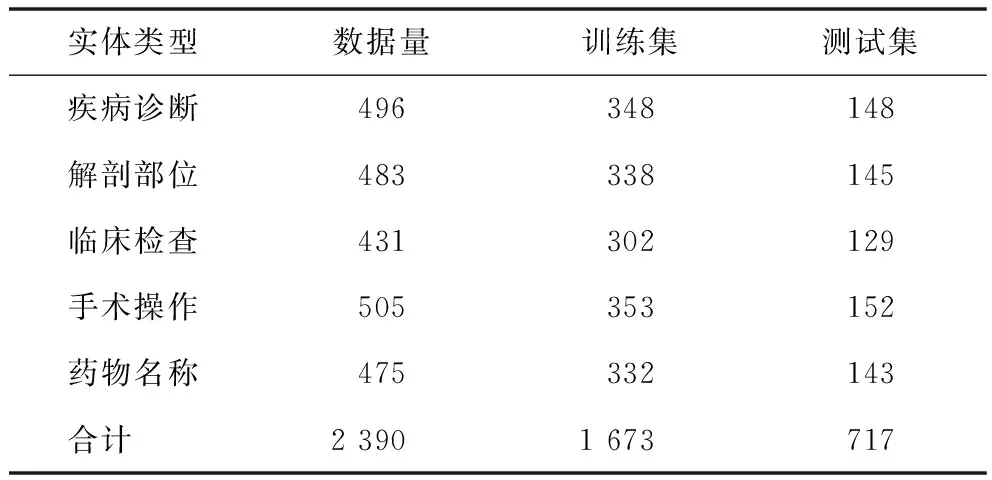
表1 自標(biāo)注標(biāo)準(zhǔn)數(shù)據(jù)集內(nèi)容統(tǒng)計(jì)
2.2 實(shí)驗(yàn)設(shè)計(jì)
實(shí)體映射任務(wù)可分成候選實(shí)體生成(candidate entity generation,CEG)和實(shí)體消歧(entity disambiguation,ED)兩個(gè)階段,為此設(shè)計(jì)兩個(gè)實(shí)驗(yàn)。
實(shí)驗(yàn)1為候選實(shí)體生成實(shí)驗(yàn),即為待標(biāo)準(zhǔn)實(shí)體找到標(biāo)準(zhǔn)詞表中所有可能與之對(duì)應(yīng)的實(shí)體,生成候選標(biāo)準(zhǔn)實(shí)體集合,高效簡(jiǎn)便的相似度算法可以較好地完成這一任務(wù)。具體而言,針對(duì)每個(gè)待標(biāo)準(zhǔn)實(shí)體,計(jì)算其與標(biāo)準(zhǔn)詞表中每個(gè)標(biāo)準(zhǔn)實(shí)體的文本相似度并排序,選取結(jié)果中前15位作為候選標(biāo)準(zhǔn)實(shí)體集合。采用目前應(yīng)用較廣泛的中文短文本相似度算法進(jìn)行實(shí)驗(yàn),對(duì)召回率進(jìn)行比較以選取最佳算法,包括Cosine余弦相似度、BM 25(best match,BM)相關(guān)性評(píng)分、Jaccard相似系數(shù)、編輯距離(minimum edit distance,MED)與Dice系數(shù)。
實(shí)驗(yàn)2為實(shí)體消歧實(shí)驗(yàn),生成候選標(biāo)準(zhǔn)實(shí)體集后,需要從中預(yù)測(cè)最可能與待標(biāo)準(zhǔn)實(shí)體相對(duì)應(yīng)的實(shí)體作為映射結(jié)果,這一過程便是實(shí)體消歧。將該任務(wù)視為一個(gè)二分類任務(wù),采用深度學(xué)習(xí)模型進(jìn)行預(yù)訓(xùn)練,學(xué)習(xí)實(shí)體間語義關(guān)系并輸出預(yù)測(cè)結(jié)果。谷歌推出的BERT模型能結(jié)合文本上下文信息并從中提取豐富全面的語義特征,出色完成二分類任務(wù),在其基礎(chǔ)上還衍生出如RoBERTa、ALBERT、RoBERTa-wwm等在各項(xiàng)自然語言處理任務(wù)中取得較好效果的模型。采用以上4種模型進(jìn)行實(shí)體消歧,并比較模型性能,得到表現(xiàn)最好的算法模型組合,見圖1。
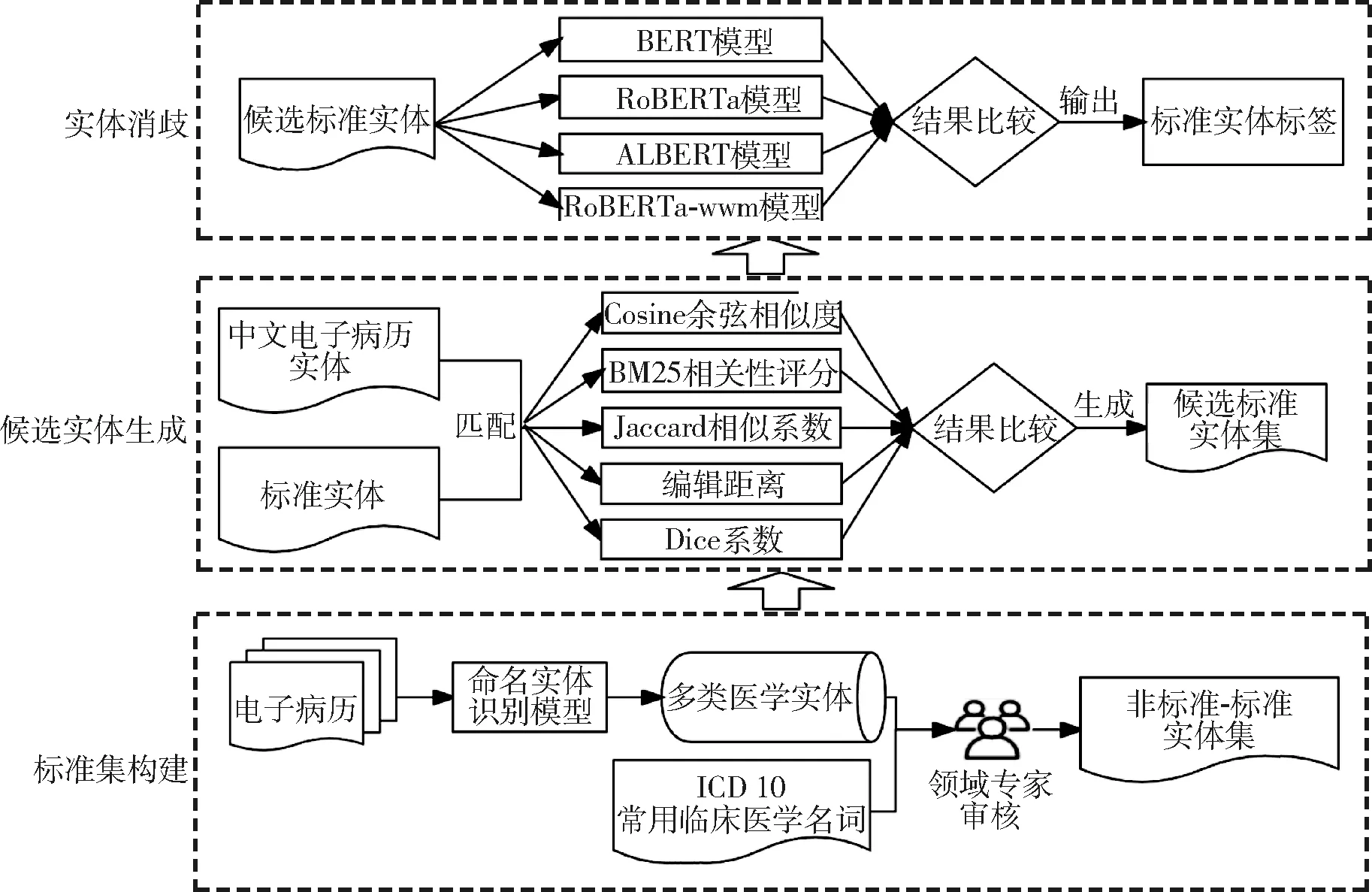
圖1 本文技術(shù)路線
2.3 評(píng)價(jià)指標(biāo)
采用準(zhǔn)確率(accuracy,A)、精確率(precision,P)、召回率(recall,R)和F1值(F1 score)作為評(píng)價(jià)指標(biāo)。準(zhǔn)確率指所有預(yù)測(cè)正確的結(jié)果所占比例,精確率指預(yù)測(cè)正確的正例占所有被預(yù)測(cè)為正例的比例,召回率指所有正例樣本中預(yù)測(cè)正確的樣本所占比例。F1值用來衡量二分類模型精確度,可以看作是模型精準(zhǔn)率和召回率的調(diào)和平均,其最大值是1,最小值是0。預(yù)測(cè)結(jié)果有真陽性(true positive,TP),假陽性(false positive,F(xiàn)P),真陰性(true negative,TN),假陰性(false negative,F(xiàn)N)4種類型。其中,真陽性指預(yù)測(cè)結(jié)果為正,實(shí)際亦為正,其他同理。各指標(biāo)計(jì)算方式如下:
(1)
(2)
(3)
(4)
3 相關(guān)算法與模型
3.1 相似度算法
3.1.1 Cosine余弦相似度 通過將文本矢量化,計(jì)算同個(gè)向量空間中兩個(gè)向量夾角間的余弦值Cos(θ)來衡量相似度大小,夾角越小則相似度越高。在生成每個(gè)文本矢量時(shí)根據(jù)詞頻-逆向文件頻率(term frequency-inverse document frequency,TF-IDF)原理,用詞頻向量V代替文本矢量每個(gè)維度的值[8]:
(5)
3.1.2 BM 25相關(guān)性評(píng)分 主要原理是先對(duì)句子q分詞,生成若干特征詞qi。Wi為每個(gè)qi的權(quán)重。之后對(duì)要與句子q進(jìn)行比較的句子D計(jì)算每個(gè)qi與D的相關(guān)性得分,最后將qi相對(duì)于D的相關(guān)性得分進(jìn)行加權(quán)求和,得到q與D的相關(guān)性得分[9]:
(6)
3.1.3 Jaccard相似系數(shù) 用于比較兩個(gè)有限樣本集之間的相似性,兩個(gè)集合A和B交集元素的個(gè)數(shù)在A、B并集中所占比例稱為這兩個(gè)集合的Jaccard系數(shù),Jaccard系數(shù)值越大則相似度越高[10]:
(7)
3.1.4 編輯距離 是對(duì)兩個(gè)字符串差異程度的測(cè)量,其原理是計(jì)算一個(gè)字符串S1經(jīng)過多少次處理才能變成另一個(gè)字符串S2,允許的編輯操作有替換一個(gè)字符、插入一個(gè)字符、刪除一個(gè)字符3種[11]:
(8)
其中l(wèi)en代表字符串的字符個(gè)數(shù),d(S1,S2)為字符串S1和S2的編輯距離。
3.1.5 Dice系數(shù) 是一種集合相似度度量指標(biāo),可將字符串理解為集合,因此Dice系數(shù)也可用于計(jì)算兩個(gè)字符串的相似度,其范圍為0~1,值越大表示相似度越高[12]。對(duì)于給定字符串S1和S2,其Dice系數(shù)算法如下:
(9)
3.2 深度學(xué)習(xí)模型
3.2.1 BERT 是一個(gè)無監(jiān)督雙向模型,可以使用純文本語料庫進(jìn)行訓(xùn)練,并預(yù)測(cè)受左右上下文制約的單詞。BERT能夠在各種自然語言處理任務(wù)中表現(xiàn)出優(yōu)異的性能[13]。經(jīng)過調(diào)整,BERT可用于進(jìn)行二分類任務(wù),其模型原理,見圖2。其中[CLS]位于開頭,用于預(yù)測(cè)文本類別,[SEP]用于分割兩個(gè)句子,ClassLabel為模型輸出的類別標(biāo)簽。
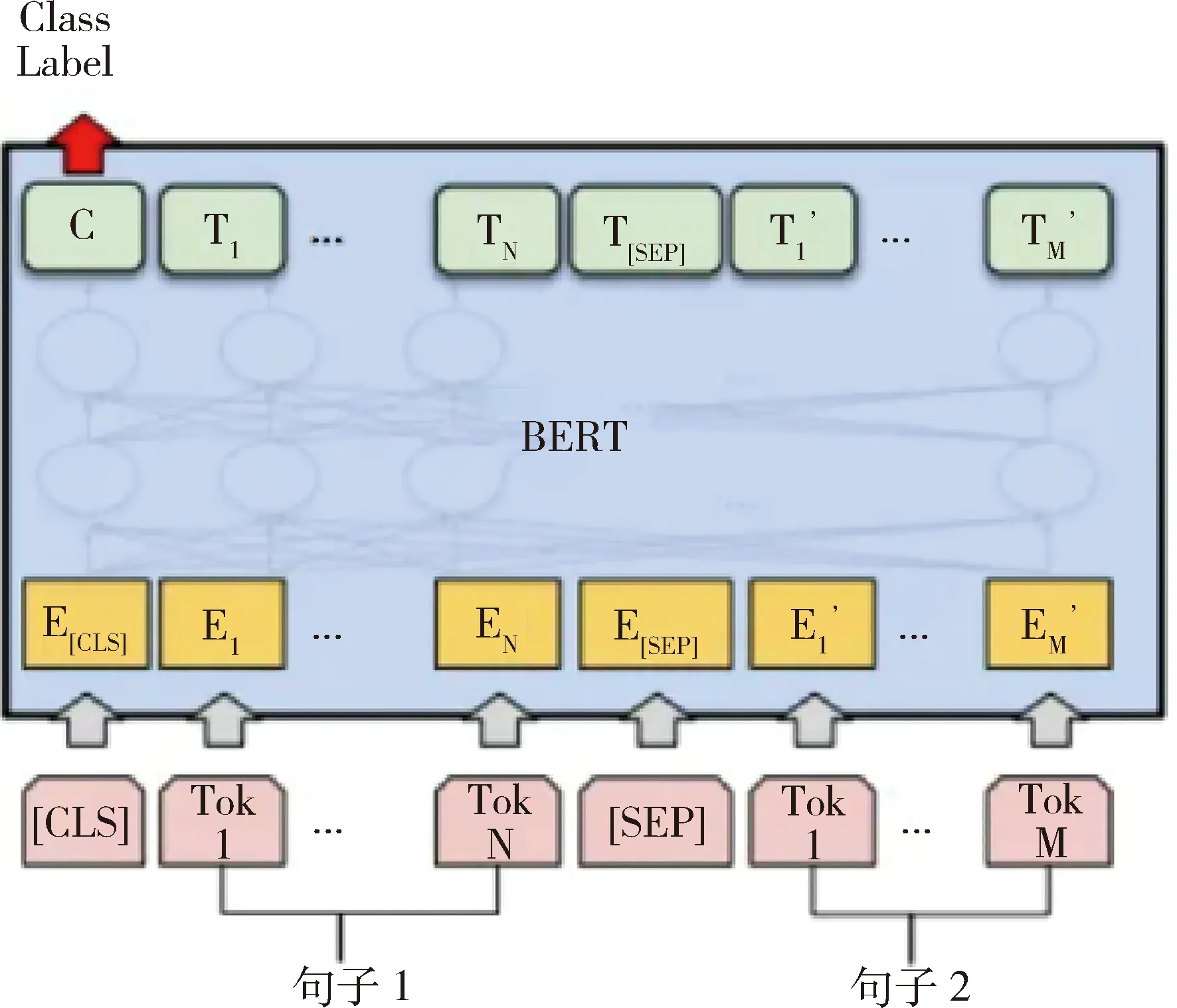
圖2 BERT模型二分類任務(wù)原理
3.2.2 RoBERTa 是在BERT預(yù)訓(xùn)練模型基礎(chǔ)上進(jìn)行改進(jìn)的復(fù)制研究,其中包括對(duì)超參數(shù)調(diào)整和對(duì)訓(xùn)練集大小的影響進(jìn)行仔細(xì)評(píng)估。同時(shí)該任務(wù)使用新數(shù)據(jù)集CCNEWS,并使用更多數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,進(jìn)一步提高下游任務(wù)性能[14]。
3.2.3 ALBERT 采用因子嵌入?yún)?shù)化和跨層參數(shù)共享兩種參數(shù)簡(jiǎn)化技術(shù)解決BERT內(nèi)存消耗高和訓(xùn)練速度慢的問題。此外,模型還提出句子順序預(yù)測(cè)(sentence order prediction,SOP)任務(wù)來代替?zhèn)鹘y(tǒng)的下一句預(yù)測(cè)(next sentence prediction,NSP)預(yù)訓(xùn)練任務(wù),從而獲得更好的性能[15]。
3.2.4 RoBERTa-wwm 由哈工大訊飛聯(lián)合實(shí)驗(yàn)室發(fā)布,結(jié)合中文全詞掩碼(whole word masking,wwm)技術(shù)與RoBERTa模型的優(yōu)勢(shì),在RoBERTa模型基礎(chǔ)上采用全詞掩碼來屏蔽漢語單詞進(jìn)行預(yù)訓(xùn)練。由于這些模型將應(yīng)用于中文文本分類,全詞掩碼將允許這些模型結(jié)合中文場(chǎng)景,以提供更多有關(guān)中文語義的信息[16]。
4 實(shí)驗(yàn)結(jié)果及分析
4.1 候選實(shí)體生成實(shí)驗(yàn)
為對(duì)比分析不同相似度算法對(duì)候選實(shí)體生成效果的影響,基于5種相似度算法進(jìn)行候選實(shí)體生成,選取相似度概率值前15位作為候選實(shí)體,并計(jì)算其召回率,見表2。為方便理解,下文待標(biāo)準(zhǔn)實(shí)體稱為原始詞,標(biāo)準(zhǔn)實(shí)體稱為標(biāo)準(zhǔn)詞。從結(jié)果中可以看出,基于Jaccard相似度算法匹配的效果優(yōu)于其他4種算法,因此選擇Jaccard算法進(jìn)行候選實(shí)體生成能較好地保證候選標(biāo)準(zhǔn)實(shí)體集質(zhì)量,有利于進(jìn)行后續(xù)實(shí)體消歧工作。Cosine余弦相似度算法和BM25算法的生成效果明顯低于其他相似度算法,是因?yàn)橛嘞蚁嗨贫人惴ㄒ蕾嚫哔|(zhì)量的詞向量,BM25算法需要精準(zhǔn)分詞,本文并未人工進(jìn)行特征構(gòu)建,因此二者效果較差。

表2 候選實(shí)體生成實(shí)驗(yàn)召回率統(tǒng)計(jì)結(jié)果
從本實(shí)驗(yàn)中Jaccard算法未召回準(zhǔn)確標(biāo)準(zhǔn)詞的樣例中可以看出,對(duì)字?jǐn)?shù)過短或者原始詞與標(biāo)準(zhǔn)詞之間差異較大的實(shí)體,單純使用相似度算法無法獲取詞中的語義信息,會(huì)導(dǎo)致召回失敗,見表3。

表3 Jaccard算法未召回標(biāo)準(zhǔn)詞樣例
4.2 實(shí)體消歧實(shí)驗(yàn)
4.2.1 模型訓(xùn)練集構(gòu)建 基于預(yù)訓(xùn)練模型的實(shí)體消歧需要構(gòu)建包含正負(fù)例的訓(xùn)練集用于訓(xùn)練模型。根據(jù)相似度算法性能對(duì)比實(shí)驗(yàn),基于Jaccard相似度算法,計(jì)算原詞i與標(biāo)準(zhǔn)詞詞表中的每個(gè)標(biāo)準(zhǔn)詞的Jaccard相似度系數(shù),取相似度值前15位作為候選詞表,將標(biāo)準(zhǔn)詞i從候選詞表中去除后剩下的候選標(biāo)準(zhǔn)詞j用于構(gòu)建負(fù)例[17]。訓(xùn)練集正例為:<原詞i,標(biāo)準(zhǔn)詞i,1>。負(fù)例為:<原詞i,標(biāo)準(zhǔn)詞j,0>。由于正樣本數(shù)較少,與負(fù)樣本數(shù)相差較大,為了擴(kuò)充正樣本,構(gòu)建10*(標(biāo)準(zhǔn)-原始+原始-標(biāo)準(zhǔn))共33 460條正樣本。
4.2.2 實(shí)驗(yàn)環(huán)境及參數(shù) 本實(shí)驗(yàn)代碼使用Python 3.6和Tensorflow 1.8編寫,模型詳細(xì)訓(xùn)練參數(shù)包括學(xué)習(xí)率(learning_rate)、每個(gè)樣本處理成的長(zhǎng)度(pad_size)、隱藏層中節(jié)點(diǎn)個(gè)數(shù)(hidden_size)、單次訓(xùn)練選取樣本數(shù)(batch_size)、樣本訓(xùn)練輪次(num_epochs),見表4。

表4 預(yù)訓(xùn)練模型參數(shù)設(shè)置
4.2.3 實(shí)體消歧實(shí)驗(yàn)結(jié)果 在基于Jaccard算法生成候選實(shí)體集的基礎(chǔ)上,選取4種在二分類任務(wù)中表現(xiàn)較好的深度學(xué)習(xí)預(yù)訓(xùn)練模型作為基準(zhǔn)進(jìn)行實(shí)驗(yàn),以對(duì)比分析不同模型的性能,見表5。從結(jié)果可知,采用RoBERTa-wwm模型的準(zhǔn)確率最高,ALBERT模型的精確率和F1值最高,BERT模型的召回率最高,RoBERTa模型的各項(xiàng)指標(biāo)效果都接近理想,因此難以確定最佳模型。同時(shí)還注意到,4個(gè)模型整體的準(zhǔn)確率、精確率和F1值仍不太理想。對(duì)輸出結(jié)果文檔進(jìn)行分析后發(fā)現(xiàn)除藥物分類之外的其他分類各項(xiàng)指標(biāo)均已大于86%,但是藥物分類的原始詞和標(biāo)準(zhǔn)詞之間差異性過大,導(dǎo)致召回率較低,還需對(duì)此問題進(jìn)行解決。
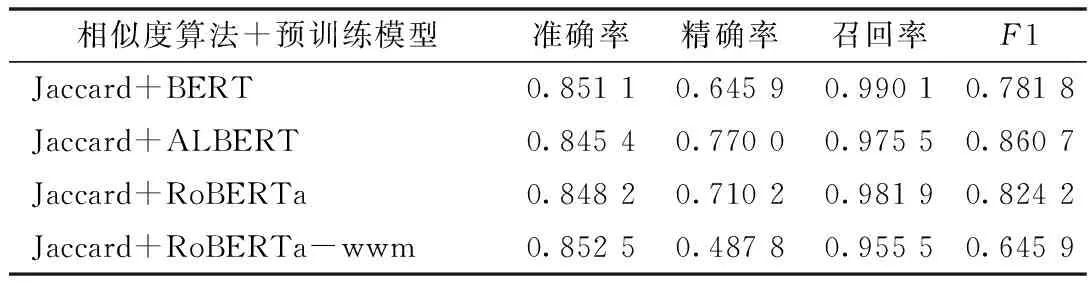
表5 實(shí)體消歧實(shí)驗(yàn)結(jié)果指標(biāo)統(tǒng)計(jì)
4.2.4 優(yōu)化后實(shí)體消歧實(shí)驗(yàn)結(jié)果 針對(duì)藥物原始詞和標(biāo)準(zhǔn)詞差異過大問題,提出通過別名間相似性來進(jìn)行知識(shí)補(bǔ)全從而提高實(shí)體映射效果的方法。標(biāo)準(zhǔn)詞的別名間大多存在字符相似關(guān)系,如“甲硝唑”的別名有“滅滴靈”和“滅滴唑”,“布地奈德”的別名有“普米克”和“普米克令舒”。因此,本文針對(duì)藥物實(shí)體采集第2批共9 481條標(biāo)準(zhǔn)實(shí)體-別名語料,構(gòu)建藥品別名映射庫,增加藥品原始詞與藥品標(biāo)準(zhǔn)詞別名的匹配,若匹配到藥品別名,將其鏈接至標(biāo)準(zhǔn)詞。從結(jié)果可知,方法優(yōu)化后,4個(gè)模型組合的實(shí)驗(yàn)結(jié)果均有較大提升,召回率均超過98%。采用Jaccard+BERT方法進(jìn)行實(shí)體映射的各項(xiàng)指標(biāo)均優(yōu)于其他模型,F(xiàn)1值達(dá)到94.87%,見表6。
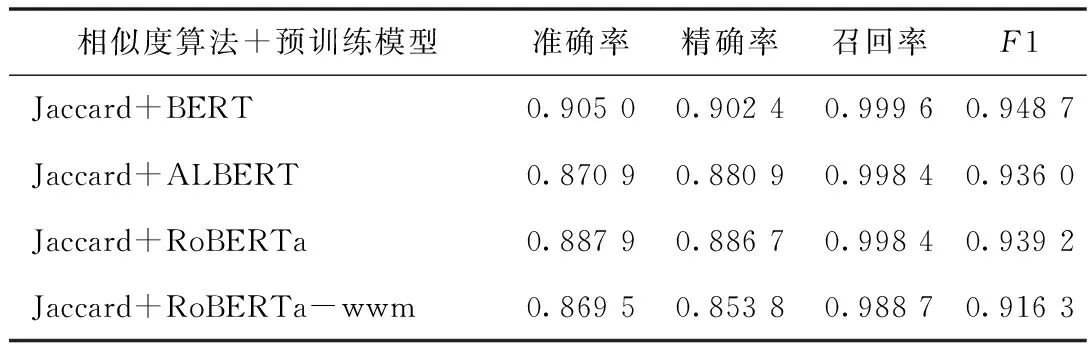
表6 優(yōu)化后實(shí)體消歧實(shí)驗(yàn)結(jié)果指標(biāo)統(tǒng)計(jì)
5 結(jié)語
本文標(biāo)注了一個(gè)中文電子病歷實(shí)體映射數(shù)據(jù)集,結(jié)合相似度算法與深度學(xué)習(xí)預(yù)訓(xùn)練模型,探究進(jìn)行海量實(shí)體映射的最佳算法與模型組合。采用相似度算法進(jìn)行候選實(shí)體生成,采用預(yù)訓(xùn)練模型進(jìn)行實(shí)體消歧,并比較不同算法模型效果。結(jié)果顯示采用Jaccard相似度算法與BERT模型的組合能夠達(dá)到最優(yōu)效果。同時(shí)本文提出通過別名間相似性改進(jìn)實(shí)體映射效果的方法,各組合模型較改進(jìn)前的F1值平均提高15.69%,達(dá)到較理想的實(shí)體映射效果,為未來相關(guān)研究提供思路。但是本文標(biāo)注樣本量較少,缺乏對(duì)不同類型實(shí)體映射效果的分別比較,未詳細(xì)探究術(shù)語構(gòu)成特點(diǎn),未來可增加對(duì)不同類型實(shí)體的對(duì)照研究,針對(duì)性探究改進(jìn)方案,以提升中文電子病歷實(shí)體映射效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
中老年保健(2021年12期)2021-11-30 02:58:01
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年8期)2019-05-09 02:22:48
動(dòng)漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52

- 醫(yī)學(xué)信息學(xué)雜志的其它文章
- 基于學(xué)位論文主題挖掘的醫(yī)學(xué)信息專業(yè)跨學(xué)科研究特征分析*
- 英國NHS醫(yī)學(xué)知識(shí)服務(wù)戰(zhàn)略框架及對(duì)我國醫(yī)學(xué)圖書館的啟示*
- 基于深度學(xué)習(xí)的醫(yī)學(xué)影像問答模型*
- 手機(jī)自媒體健康傳播研究*
- 摘要語言視角下醫(yī)學(xué)突破性論文識(shí)別研究*
- “中心+節(jié)點(diǎn)”分布式生命科學(xué)數(shù)據(jù)平臺(tái)構(gòu)建模式研究
——基于歐洲ELIXIR的案例分析*