伴隨壓制干擾與組網雷達功率分配的深度博弈研究
2023-07-04 09:51:58王躍東顧以靜王增福張會霞
雷達學報 2023年3期
王躍東 顧以靜 梁 彥* 王增福 張會霞
①(西北工業大學自動化學院 西安 710072)
②(信息融合技術教育部重點實驗室 西安 710072)
1 引言
組網雷達(Networked Radar,NR)因具有資源共享、協同探測、空間覆蓋范圍大和抗干擾等優勢,已經受到廣大學者和機構的關注[1–8]。組網雷達資源管理在提升信息融合系統的探測、跟蹤性能中扮演著至關重要的角色。然而,干擾技術向智能化方向發展[9–13],給雷達系統資源管理帶來新的挑戰和任務需求。如何在時間、能量和計算等軟硬件資源限制下,降低干擾帶來的不利影響,是實現組網雷達探測性能提升的關鍵。
現有的組網雷達資源分配方法主要分為3類:基于啟發式優化方法、基于博弈論方法和基于強化學習方法。基于啟發式優化方法通常利用最優化方法或者群智能優化方法求解某一探測性能指標下的最優解。文獻[6]以最小化多輸入多輸出雷達的發射功率為目標,通過推導了各個目標定位誤差的克拉美羅界建立機會約束模型,并通過等效變換將機會約束問題變為非線性方程求解問題。文獻[14]將目標的后驗克拉美羅下界作為優化目標函數,提出一種同時優化雷達功率和帶寬的改進型麻雀搜索算法對目標函數進行求解。啟發式優化方法是資源優化的有效手段,然而最優化方法需要在每一個資源分配時刻沿著目標函數的負梯度方向尋找最優值,這個過程耗費大量時間且要求目標函數具有可導性。群體智能體方法在高維場景下其性能受到嚴重影響,導致算法搜索能力下降。
博弈論方法將組網雷達中的雷達節點視為博弈參與者,利用決策理論進行雷達資源分配。文獻[15]將雷達功率分配問題建立為合作博弈模型,提出一種基于合作博弈的分布式功率分配算法,利用一種基于shapley值的求解算法得到功率分配結果。文獻[16]針對組網雷達的抗截獲問題,將信干噪比(Signal to Interference plus Noise Ratio,SINR)和各雷達的發射功率作為約束條件,提出了一種基于非合作博弈的迭代功率控制方法,該方法可以快速收斂至納什均衡解。文獻[17]提出基于納什均衡的彈載雷達波形設計方法,根據最大化SINR準則分別設計了雷達和干擾的波形策略。博弈論方法無法提供資源分配的唯一解,而且需要每一時刻計算博弈雙方的收益矩陣,具有較大的計算復雜度。
近年來,隨著深度強化學習(Deep Reinforcement Learning,DRL)在資源分配和控制決策方面的成功應用,已經有基于DRL的雷達資源優化技術被提出。DRL具有利用智能體與環境交互來學習狀態到動作最優映射策略的能力。將組網雷達作為智能體,文獻[3]提出基于領域知識輔助強化學習的多輸入多輸出雷達功率方法,其利用領域知識來設計導向獎勵,從而增加策略網絡收斂性和收斂速度。文獻[18]考慮目標信息感知和平臺安全的情況下獲得傳感器目標探測分配序列,提出一種基于DRL的機載傳感器任務分配方法。文獻[19]考慮無線通信系統中的功率分配問題,提出一種近似SARSA[20]功率分配算法,其通過線性近似避免了SARSA功率分配策略中可能出現的“維數災難”問題。毫無疑問DRL已經成功的運用于組網雷達資源分配問題。
然而,上述組網雷達資源分配方法都是建立在沒有干擾或者干擾模型已知的基礎上,缺少干擾機和雷達的博弈與交互。隨著干擾技術的發展,干擾機在干擾時間、干擾功率控制方面具有更強的對抗能力。在干擾機資源調度方面,文獻[21]提出一種魯棒的干擾波束選擇和功率調度策略來協同壓制NR系統,其中多個目標的后驗克拉美羅下界之和用來評估干擾性能。文獻[22]考慮在干擾資源有限的情況下的干擾波束和功率的分配問題,建立了一種基于改進遺傳算法的干擾資源分配模型,推導了壓制干擾下NR系統的探測概率,并將其作為評價干擾性能指標,提出一種基于粒子群算法的兩步求解方法。文獻[23]采用模糊綜合評價方法對影響輻射源威脅水平和干擾效率的綜合因素進行量化,提出了一種基于改進螢火蟲算法的干擾資源分配方法。文獻[11]提出一種基于雙Q學習算法的干擾資源分配策略。文獻[24]提出基于DRL的智能頻譜干擾方法,其對不同種類的跳頻通信信號具有很好的干擾效果。
綜上所述,DRL已經被用于組網雷達或者干擾機的資源分配任務,但是同時考慮伴隨壓制干擾與組網雷達功率分配的深度博弈仍然是一個開放性問題。由于以下因素,應用DRL解決上述問題頗具挑戰:組網雷達功率分配動作屬于連續動作,因此智能體探索空間很大,導致策略難以收斂;組網雷達和干擾機博弈過程中環境動態性增強,進一步增加智能體的策略學習難度。
考慮DRL在處理動態環境下的資源分配的優勢,本文首先將干擾機和組網雷達映射為智能體,根據雷達目標檢測模型和干擾模型建立了壓制干擾下組網雷達目標檢測模型和檢測概率最大化優化目標函數。然后,采用PPO策略網絡生成組網雷達功率分配動作;引入目標檢測模型和等功率分配策略兩類領域知識構建導向獎勵以輔助智能體探索。其次,設計混合策略網絡生成干擾機智能體的波束選擇和功率分配動作;同樣引入領域知識(貪婪干擾資源分配策略)生成干擾機智能體的導向獎勵。最后,通過交替訓練更新兩種智能體的策略網絡參數。實驗結果表明:當干擾機采用基于DRL的資源分配策略時,采用基于DRL的組網雷達功率分配在目標檢測概率和運行速度兩種指標上明顯優于基于粒子群的組網雷達功率分配和基于人工魚群的組網雷達功率分配。
2 問題描述
本文目的是在智能化壓制干擾下通過調度組網雷達的功率資源以提升雷達的探測性能。為此,首先提出干擾機掩護目標穿越組網雷達探測區域的任務想定。其次,根據干擾模型和雷達檢測模型建立壓制干擾下的組網雷達目標檢測模型,進而提出最大化目標檢測概率優化目標函數。
2.1 任務想定
圖1給出干擾機掩護目標穿越組網雷達防區的資源分配任務的示例。由一架干擾機伴隨一架飛機(目標)試圖穿越由N部雷達組成的組網雷達探測區域。在此過程中,干擾機生成電磁噪聲干擾雷達的探測信號來掩護目標,這種噪聲干擾被稱為壓制式干擾。在該任務想定中,干擾方希望盡可能地使組網雷達探測不到目標,而我方組網雷達則期望最大化目標的檢測性能。

圖1 壓制干擾機掩護目標穿越組網雷達防區的示例Fig.1 An example of a suppression jammer protecting a target through the networked radar defense area
如圖2所示,上述干擾機和組網雷達的博弈過程被進一步細化為干擾機智能體和組網雷達智能體資源分配策略的博弈。
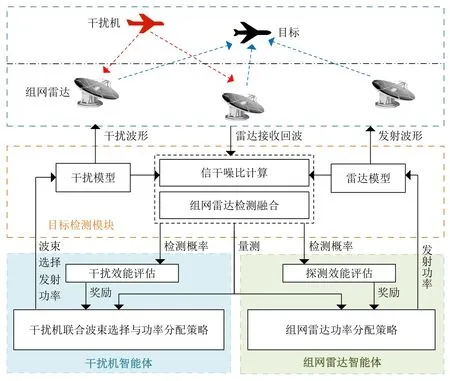
圖2 干擾機智能體和組網雷達智能體的博弈流程圖Fig.2 The game closed-loop process of the jammer agent and the networked radar agent
(1) 假設干擾機在k時刻能夠發射L <N個干擾波束。干擾機智能體需要完成以下任務,即:在k時刻選擇干擾哪幾部雷達?被選中的雷達的干擾功率分配多少才能使組網雷達探測目標的概率最小?
(2) 假設組網雷達每個節點都工作單波束模式,在各個探測時刻,所有雷達節點均發射波束,即每個探測時刻有N個雷達波束探測目標。組網雷達智能體需要怎么為每個雷達-目標分配合理的發射功率使得目標檢測概率最大化?
與無干擾情況下的組網雷達功率分配不同,在干擾機干擾下,組網雷達需要考慮干擾機對資源分配和目標檢測的影響,因此需要引入干擾機的干擾特性和模型來優化組網雷達功率分配。同時,由于干擾機的干擾波束和功率分配具有不確定性和動態性,因此需要動態地調整組網雷達功率分配策略,以實現最優的干擾抑制和探測性能的平衡。在組網雷達功率分配策略求解方面,傳統的方法通常采用全局優化算法對問題求解,如遺傳算法、粒子群算法等,這些方法都需要較高的計算成本,難以在大規模優化問題中保證優化的時效性和可靠性,因此需要探測探索具有大規模優化空間搜索能力的DRL分配策略。
2.2 目標檢測模塊
2.2.1 干擾模型
壓制干擾是一種噪聲干擾手段,干擾機發射強干擾信號進入雷達接收機,進而形成對雷達的回波的掩蓋和壓制,使雷達對目標的檢測性能下降。本文采用噪聲調頻干擾信號進行干擾信號建模,假設干擾機向敵方雷達n施加噪聲調頻干擾信號[10,21,23],即
2.2.2 壓制干擾下單雷達目標檢測模型
在無干擾情況下,目標的檢測概率與雷達接收天線處的信噪比(Signal Noise Ratio,SNR)相關。SNR的大小由目標回波功率ysignal和接收機輸入噪聲Pn共同決定[10,21,23]。
雷達n接收到的目標回波信號功率ysignal可表示為
其中,Pr,k為雷達的發射功率,Gr為雷達天線主瓣方向上的增益,σ為目標有效反射面積,λ為雷達的工作波長,為k時刻目標與探測雷達n之間的距離。
雷達接收機的內部噪聲Pn可表示為
其中,k=1.38×10-23J/K為玻爾茲曼常數,Bn為接收機帶寬,T0為接收機內部有效熱噪聲溫度,Fn為接收機噪聲系數。
因此,雷達n接收端的SNR表示為
在噪聲壓制干擾下,雷達接收端的信號由目標回波功率ysignal、內部噪聲Pn以及干擾信號功率yinterf3部分組成。根據干擾方程[10,21,23],雷達n接收到來自干擾機發射的干擾信號功率為
其中,θ0.5為雷達天線波瓣寬度;β為常數。
如圖3所示,θk取決于干擾機、目標機和雷達三者之間的相對位置關系。根據干擾信號進入雷達的角度,壓制干擾劃分為伴隨干擾和支援干擾兩種類型。當干擾信號從雷達天線主瓣進入接收機時為伴隨干擾;當θk>θ0.5/2時干擾信號主要從雷達天線旁瓣進入,干擾方式為支援干擾。

圖3 干擾機、雷達和目標的相對空間位置Fig.3 The relative spatial position of the jammer,radar and target
壓制干擾下,雷達n接收機接收到關于目標的SINR為[10,23]
假設目標的起伏特性為Swerling I型,雷達累積脈沖數為1,則雷達n對目標的檢測概率可表示為[10,23,25]
其中,VT為檢測門限。將式(7)代入式(8)可得
由式(9)可以發現雷達對目標的檢測概率與干擾資源分配變量以及干擾機、目標機和雷達間的空間位置有關。
2.2.3 組網雷達檢測融合
組網雷達采用K-N融合規則來實現信息融合[10,23,26]。假設雷達n的局部判決為dn∈{0,1},其中dn=1或0表示發現目標與否。融合中心根據這些局部判據產生全局判決向量D=[d1d2...dN],共有 2N種可能。定義全局判決規則為R(D),當組網雷達中發現目標的雷達數超過檢測門限K(1≤K≤N)時,判定發現目標,否則判定為未發現目標,即
根據秩K融合準則可以得到k時刻組網雷達對目標的檢測概率Pd,k為
2.3 優化函數設計
組網雷達探測任務的要求是在統計意義下探測到目標的次數越多越好。該指標可進一步量化為組網雷達對目標的檢測概率Pd,k,其值越大說明目標越容易被發現。根據任務需求,本文的優化目標函數為
傳統的組網雷達功率方法一般先通過干擾性能評估建立優化目標函數,然后利用啟發式搜索算法進行策略求解。這些方法通常是在假定探測環境沒有干擾或者干擾模型給定的情況下進行方案設計,缺少干擾機和組網雷達相互博弈,不符合實際作戰需求。同時啟發式搜索方法存在計算成本高、搜索速度慢的缺點,難以保證優化的有效性。與這些方法不同,本文考慮到體系協同作戰下干擾機與組網雷達的博弈,提出基于DRL的干擾機波束和功率分配條件下的組網雷達功率分配問題。在策略求解方面,結合了人工智能方法,干擾機和組網雷達被映射為智能體,利用DRL的交互試錯學習機制生成從環境狀態到組網雷達功率分配向量的映射。由于采用離線訓練的方式進行策略探索,因此DRL相較于一般方法具有更快的在線運行速度。
3 組網雷達智能體的MDP建模
本節首先將組網雷達智能體功率分配模型化為馬爾可夫決策過程(Markov Decision Process,MDP)[27]。一個MDP通常采用元組(S,A,P,r)表示,其中S為環境狀態,它是智能體的環境觀測;A為動作,它是執行器的輸出;P為狀態的轉移概率。值得注意的是,在無模型強化學習中P是未知的。r是由環境產生的單步獎勵。
圖4顯示組網雷達策略網絡同干擾機與雷達博弈環境的交互過程。首先組網雷達智能體的策略網絡根據環境狀態生成一個功率分配動作,并將該動作傳遞給組網雷達。然后雷達執行探測動作獲取目標量測,并提取下一時刻的環境狀態。智能體的狀態、動作和獎勵被存入經驗池用于組網雷達智能體的策略網絡參數更新。
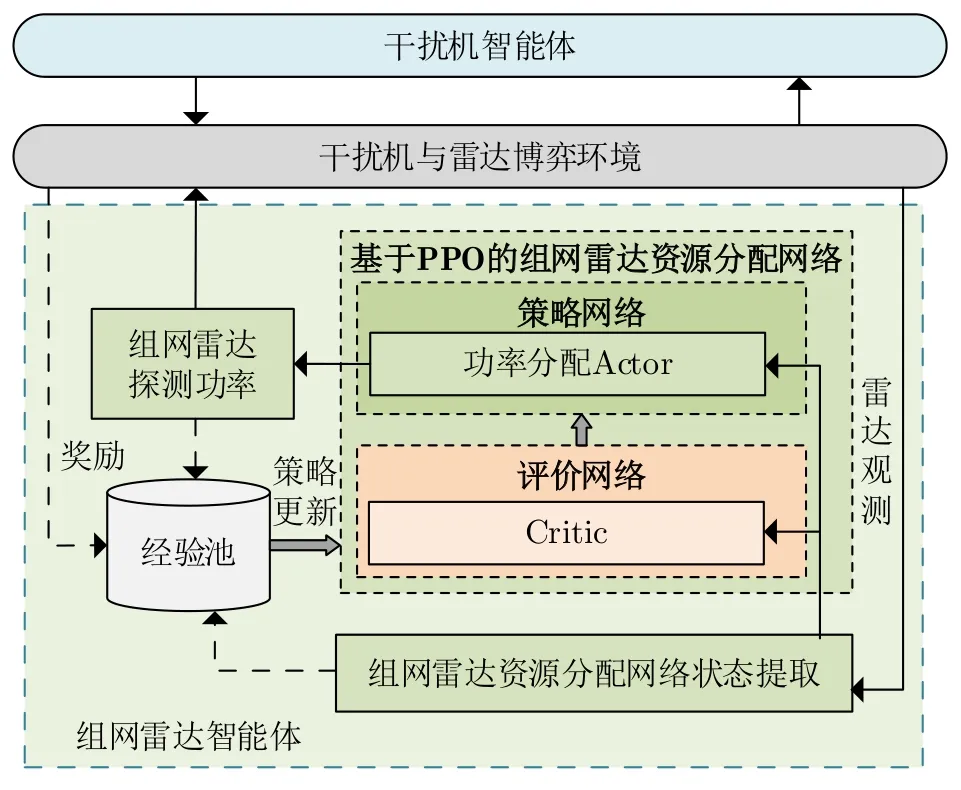
圖4 組網雷達智能體與環境交互圖Fig.4 The networked radar agent and environment interaction diagram
(1) 組網雷達智能體的狀態
組網雷達能夠獲取的環境信息包括k時刻雷達n與目標的距離和雷達被干擾指示。通過對組網雷達的觀測進行預處理生成策略網絡的輸入狀態。預處理過程包括標準化和連接操作。標準化是為了將不同量綱的雷達觀測統一到[0,1]。定義距離標準化函數為
其中,Rmin,Rmax分別表示雷達的最小和最大觀測距離。
連接操作是在數據標準化后將不同類型的雷達觀測組合成策略網絡的輸入狀態。首先將任意雷達的觀測按照被干擾指示和雷達與目標的距離組合,即。然后將所有雷達的觀測按照雷達編號組合,即
(2) 組網雷達智能體的動作
組網雷達智能體的動作定義為ar,k=(n=1,2,...,N),其中表示k時刻雷達節點n的發射功率。
(3) 知識輔助的組網雷達智能體獎勵函數設計
強化學習模擬人類獎懲機制,利用智能體與環境交互試錯改進策略,本質上是選擇獎勵大的動作。然而,強化學習的試錯過程仍然是隨機探索,對于壓制干擾下組網雷達功率分配任務,干擾機和組網雷達的博弈與目標運動使得探測環境的動態性顯著增加,進而導致智能體策略學習困難。為了輔助智能體的探索,有必要引入人的認知模型和知識,提出知識輔助下的獎勵設計。通過專家知識和模型知識設計導向獎勵,以引導智能體向人類認知方向探索,最終生成符合任務想定的資源分配策略。如圖5所示,本文給出知識輔助的組網雷達智能體獎勵函數設計框圖。

圖5 知識輔助的組網雷達智能體獎勵模塊Fig.5 The knowledge-assisted reward module for the networked radar agent
根據壓制干擾下組網雷達目標探測模型(模型知識)可知,雷達發現目標的概率和雷達與目標的距離以及雷達的發射功率相關。對于使用相同發射功率的雷達,目標距離雷達越近,雷達接收端獲得的SINR越大,意味著發現目標的概率越大。因此定義評價函數為
在組網雷達功率分配任務中等功率分配策略(專家知識)被用來作為判斷智能體分配動作好壞的基準策略。如果k時刻智能體的探測收益大于基準策略的探測收益,那么給予智能體正的導向獎勵,否則做出適當的懲罰。具體的規則定義如下:
其中,rrg,k表示組網雷達智能體的導向獎勵;b1和b2是正實數;為等功率分配動作。
組網雷達智能體的環境獎勵是根據優化目標給出的。組網雷達期望發現目標的概率越大越好,即目標的檢測概率越接近1給予的獎勵越大。因此,組網雷達的環境獎勵定義為
組網雷達智能體的導向獎勵和環境獎勵共同用于改進組網雷達智能體的策略。考慮到隨著訓練次數的增加智能體的策略將超越基準策略,此時導向獎勵起到促進策略探索作用,相反會影響智能體向最優策略探索。因此,本文設計導向獎勵衰減獎勵融合模塊,由知識產生的導向獎勵隨著訓練幕數的增加逐漸減小,即
其中,rr,k為融合后組網雷達智能體的獎勵;β為衰減因子;t為訓練幕數。
注意,上述設計過程中使用等功率分配策略作為專家知識來生成導向獎勵,事實上可以引入更加先進的分配策略輔助智能體探索。
(4) 組網雷達智能體的策略網絡
如圖6,組網雷達智能體的策略網絡采用演員-評論家(Actor-Critic,AC)框架,由一個Actor和一個Critic組成,其中Actor策略網絡用于產生功率分配動作,Critic策略網絡用來評估動作的好壞。Actor策略網絡采用3層全連接神經網絡(Neural Network,NN)搭建,中間層采用ReLU激活函數激活,輸出層采用Tanh激活函數激活。Critic策略網絡同樣采用3層全連接NN搭建并使用Tanh激活。采用PPO算法進行策略學習[28]。

圖6 組網雷達智能體的策略網絡Fig.6 The policy network of the networked radar agent
4 干擾機智能體的MDP建模
圖7顯示了干擾機策略網絡同干擾機與雷達博弈環境的交互過程。首先由基于混合強化學習的干擾資源分配策略網絡生成干擾機智能體的波束選擇動作和波束功率分配動作。然后,干擾機執行該動作對被選中雷達發射干擾波束。干擾機獲取環境觀察并提取下一時刻狀態。干擾機智能體的狀態、動作和獎勵被存入經驗池,這些樣本用于混合策略網絡的參數更新。

圖7 干擾機智能體與環境交互圖Fig.7 The jammer agent and environment interaction diagram
(1) 干擾機智能體的狀態
(2) 干擾機智能體的動作
(3) 干擾機智能體的獎勵
干擾機的波束和功率聯合分配具有由離散動作和連續動作組成的混合動作空間,這比其他的資源分配任務更加復雜。其中,混合動作空間增加了智能體的探索難度,更少的最優動作被遍歷,這意味著最優動作下的環境獎勵是稀疏的,這導致DRL的策略難以改進。因此引入模型知識和專家知識設計導向獎勵輔助智能體探索,如圖8所示。

圖8 知識輔助的干擾機智能體獎勵函數模塊Fig.8 The knowledge-assisted reward function module for the jammer agent
將貪婪干擾資源分配策略視作評價干擾機智能體的資源分配動作的基準。當采用干擾機智能體的波束選擇和功率分配動作下組網雷達發現目標的概率小于使用基準干擾資源分配策略時,給予正的導向獎勵,否則懲罰,即
其中,rjg,k為干擾機智能體的導向獎勵;表示基準干擾資源分配策略下組網雷達發現目標的概率。
干擾機的優化目標與組網雷達的優化目標相反,目標的發現概率越小越好。因此干擾機智能體的環境獎勵表示為
與組網雷達的導向獎勵和環境獎勵融合的方法相同,干擾機智能體的獎勵融合模塊定義為
其中,rj,k表示融合后干擾機智能體的獎勵。
(4) 干擾機智能體的混合策略網絡
干擾機智能體需要同時產生兩種不同質的混合動作,即離散的干擾波束選擇動作和連續的波束功率分配動作。因此本文設計一種混合策略網絡,如圖9所示,用來表示兩種分配動作,其中利用具有分類分布輸出的離散Actor來表示干擾波束選擇動作,采用具有高斯分布的連續Actor來表示干擾波束功率分配動作。

圖9 干擾機智能體的混合策略網絡Fig.9 The hybrid policy network of the jammer agent
5 基于交替訓練的干擾機與組網雷達資源分配策略學習
如圖2所示,由組網雷達和干擾機組成的資源對抗優化問題由于以下困難使得資源分配策略很難收斂:(1)組網雷達和干擾的功率分配都是連續變量,因此策略學習的狀態-動作空間維度很大,難以收斂;(2)干擾機波束分配為非凸優化并與功率分配耦合,這進一步增加策略搜索空間;(3)組網雷達和干擾機博弈過程中資源分配環境動態性增加。
為此本文提出基于交替訓練的多步求解方法,設置最大迭代次數為M。具體步驟為:
步驟1 固定組網雷達的功率分配策略,訓練干擾機的聯合波束與功率分配策略。
步驟2 固定干擾機的資源分配策略,訓練組網雷達的功率分配策略。
進行下一次迭代m←m+1,重復執行步驟1和步驟2,直到迭代訓練次數m>M。此時得到訓練后的組網雷達功率分配策略。
6 仿真實驗
6.1 場景描述與參數設置
6.1.1 任務場景描述
如圖10所示,代表一種典型的部署方式,各部雷達以扇形方式部署到作戰區域,探測范圍相互重疊,這種部署有效地增加了雷達發現目標的能力。目標由西北方向朝向東南方向勻速運動,并且逐漸靠近雷達4和雷達5所在區域。

圖10 組網雷達部署和目標編隊軌跡Fig.10 The deployment of the networked radar and the trajectory of the target formation
值得注意的是,在測試場景干擾機和目標飛行軌跡的趨勢與訓練場景中軌跡的飛行樣式相同,但每一次運行目標和干擾機的位置與速度都在一個區間內隨機生成。在實際作戰過程中,如果測試場景與訓練場景的匹配度很低,訓練好的參數可能不再有效。因為DRL是通過訓練階段不斷地與環境交互學習最優策略。如果測試環境改變較大,可能會導致性能下降。此時,需要通過在線訓練方式對模型進行微調,以適應新的環境。同時,本文通過對訓練數據進行隨機擾動,即每一個訓練幕干擾機和目標的位置和速度隨機產生,來增加模型對新情況的魯棒性。
6.1.2 仿真參數設置
仿真實驗在10 km×10 km的二維作戰平面進行。組網雷達由N=5部廣泛分布的單站雷達組成,融合中心采用K-N準則(K=2)。假設組網雷達和干擾機的工作頻率相等,基于文獻[9,10,23,29,30]提供的數據,每部雷達的工作參數設置如表1所示,干擾機的工作參數設置如表2所示。雷達的工作帶寬為300 MHz,干擾機帶寬為雷達帶寬的2倍,各場景中目標的有效反射面積均設置為5 m2。

表1 雷達工作參數Tab.1 The working parameters of the radars

表2 干擾機工作參數Tab.2 The working parameters of the jammer
本文算法的參數設置如表3所示,其中組網雷達智能體中Actor網絡的層數和節點數與干擾機智能體中連續Actor的參數設置相同。仿真所使用的計算機硬件參數為:Intel i5-10400F CPU,8 GB RAM,NVIDIA GTX 1650顯示適配器,python版本為3.6,tensorflow版本為1.14.1。
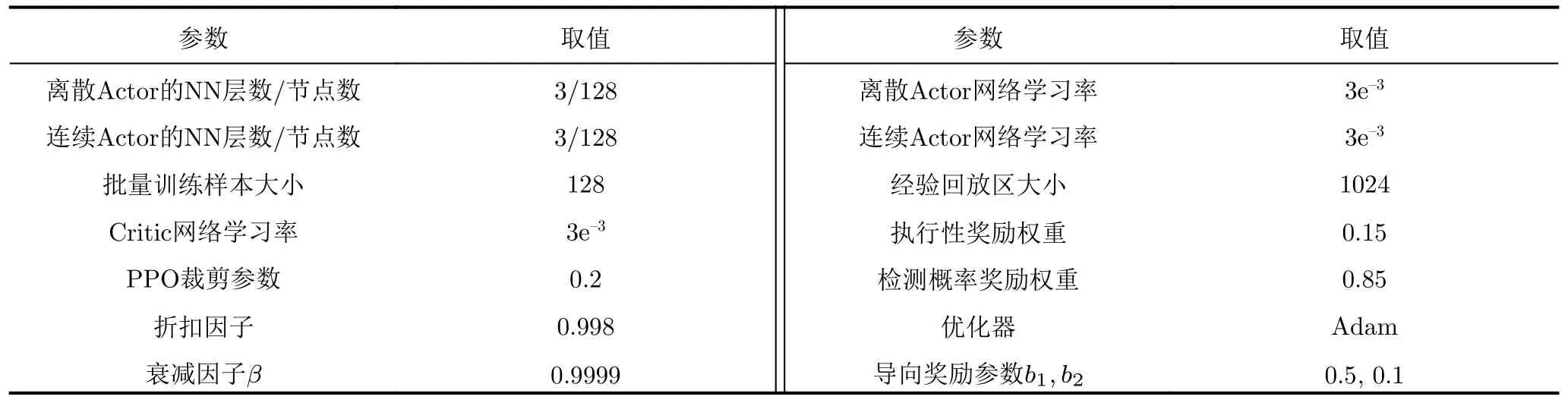
表3 算法參數設置Tab.3 The algorithm parameters setting
算法的計算復雜度分析:算法的計算復雜度包含時間復雜度和空間復雜度[3]。前者由NN中乘法和加法的數量來衡量,后者由NN中帶優化的參數數量決定,即
其中,M是NN的層數(隱藏層數+1),m表示NN層編號,FCin(m)和 FCout(m)分別表示第m層NN的輸入節點數和輸出節點數。根據表3所示的Actor網絡的參數設置,本文算法干擾機策略網絡中離散Actor的時間復雜度是17792,空間復雜度是18049,連續Actor的時間復雜度是18048,空間復雜度是18307。組網雷達智能體策略網絡的時間復雜度為18304,空間復雜度為18565。
6.2 對比策略和評價指標
為驗證所提方法的有效性,在干擾機使用基于DRL的干擾策略時,將基于DRL的組網雷達功率分配算法與如下2種組網雷達功率分配策略進行對比:
基于粒子群(Particle Swarm Optimization,PSO)算法的組網雷達分配策略:該方法采用粒子群算法作為雷達功率資源分配策略,在使用時設計參數較少、粒子群規模較小,所以收斂速度相對較快。
基于人工魚群算法(Artificial Fish Swarms Algorithm,AFSA)的組網雷達分配策略:應用人工魚群算法進行功率資源的分配,該方法通過模擬魚群的覓食行為進行策略尋優,具有較好的全局最優解的求解能力,對初始值和參數要求較低、魯棒性強。
組網雷達功率資源分配的目的是最大化目標的檢測概率,因此選取目標檢測概率以及資源調度運行時間(Scheduling Run Time,SRT)作為性能評估指標。
6.3 訓練過程
根據6.1.2節設置的參數和第5節的訓練方法學習組網雷達功率分配策略。每隔50步對目標運動狀態進行初始化,稱為一幕。干擾機策略訓練的總幕數設置為3000幕,組網雷達智能體的訓練總幕數設置為10000幕。圖11顯示了不同訓練幕下獎勵收斂情況。從圖11(a)可以看出,隨著訓練幕數的增加組網雷達智能體的獎勵逐漸收斂,表明訓練是有效的。由圖11(b)可以發現,隨著訓練幕數的增加干擾機智能體的獎勵也逐漸收斂,表明干擾機的策略訓練是有效的。
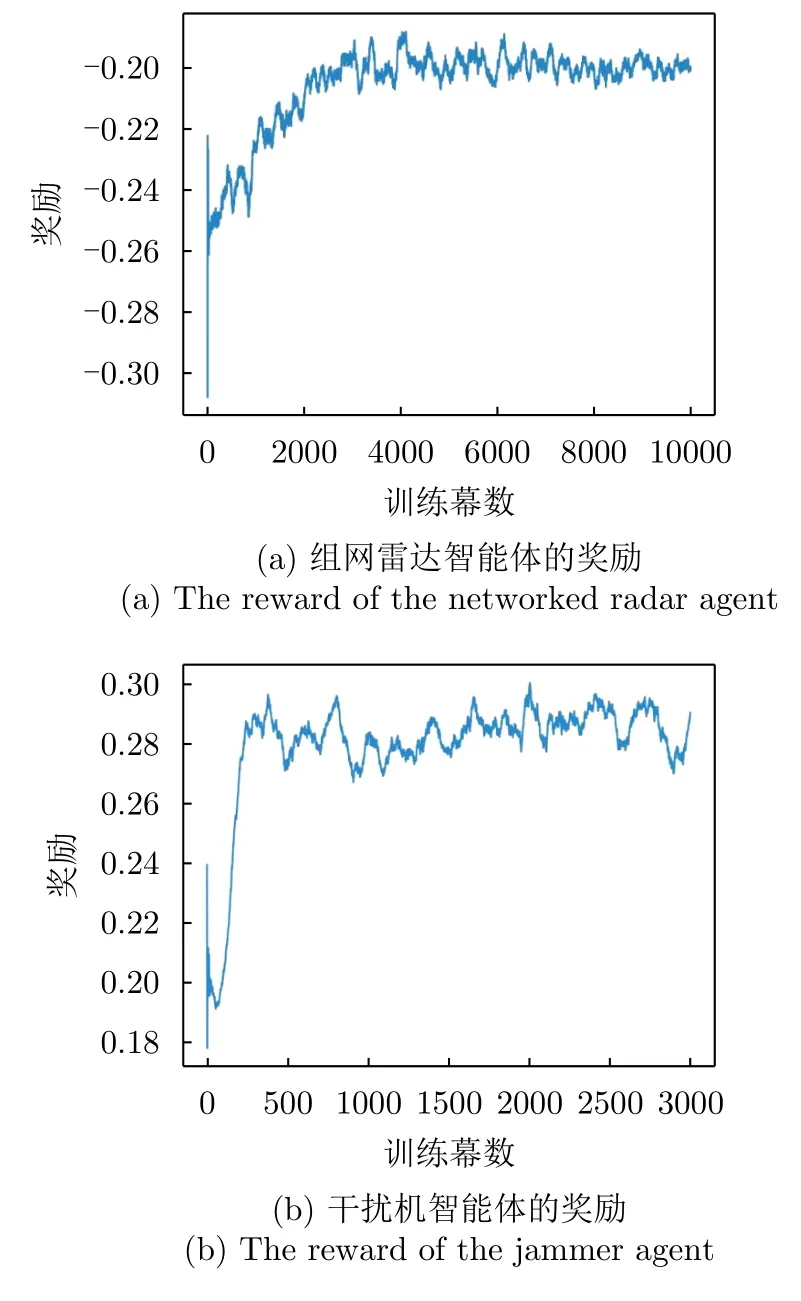
圖11 獎勵變化曲線Fig.11 The rewards convergence curve
6.4 測試結果
將訓練好的組網雷達功率分配策略參數和干擾機資源分配策略參數加載到測試環境。圖12顯示了單次運行下的干擾資源分配結果。可以發現,在初始階段距離干擾機較近的雷達1、雷達2和雷達3受到的干擾較大;在運行到中間時刻時干擾機分配更多的干擾功率給雷達2;隨著目標編隊逐漸靠近雷達,干擾機選擇對距離近的雷達4和雷達5施加干擾。
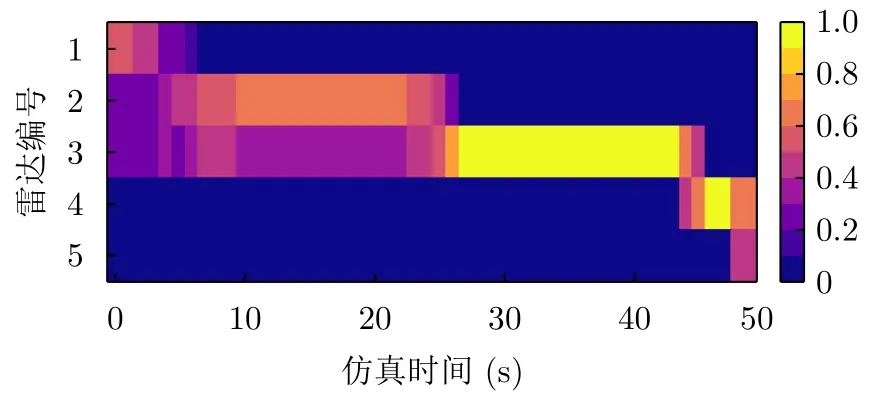
圖12 干擾資源分配結果Fig.12 The interference resource allocation result
通過50次蒙特卡羅仿真測試了3種組網雷達功率分配策略在干擾機采用基于DRL的壓制干擾下的目標檢測性能。圖13顯示了幾種組網雷達功率分配策略在基于DRL干擾下的目標檢測概率,可以發現基于DRL的組網雷達功率分配方法可以有效地提升壓制干擾下的目標檢測性能,相較于其他兩種策略,目標檢測概率最多提升了大約11%,這是由于DRL通過智能體與環境交互學習,因此DRL分配策略考慮了干擾機帶來的不確定性。

圖13 3種組網雷達功率分配策略的目標檢測概率Fig.13 The target detection probability of three networked radar power allocation strategies
為了驗證本文算法在時變干擾條件下的優勢,本文分別采用3種不同的策略進行測試,包括基于DRL干擾下訓練的組網雷達功率分配策略(DRL-TI)、在無干擾下訓練的組網雷達分配策略(DRL-NI)以及固定干擾情況下訓練的組網雷達功率分配策略(DRL-FI)。其中,固定干擾設置為干擾機在所有時刻采用均等功率干擾雷達3、雷達4和雷達5。本文測試了這3種策略的目標檢測性能,結果如圖14所示。從圖14可以看出,DRL-TI組網雷達功率分配策略的目標檢測概率要比DRL-NI和DRL-FI策略的目標檢測概率高,最多提升了約15%。這是因為,DRL-TI分配策略在訓練過程中考慮了干擾機與組網雷達的資源博弈,能夠適應時變干擾帶來的不確定性,從而具有更好的目標檢測性能。
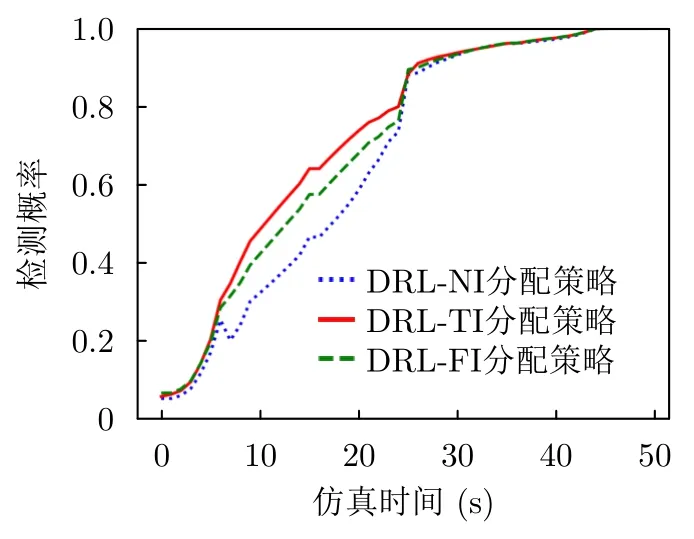
圖14 不同干擾模式下基于DRL組網雷達功率分配策略的目標檢測概率Fig.14 The target detection probability of the DRL-based networked radar power allocation strategy under different interference models
圖15對比了單次仿真測試下3種組網雷達功率分配策略雷達功率分配結果。圖16顯示了各雷達節點受干擾壓制干擾情況。圖17顯示了干擾機和組網雷達的距離變化。由圖15(a)—圖17可以發現基于DRL的組網雷達功率分配方法具有以下現象:

圖15 組網雷達功率分配結果Fig.15 The networked radar power allocation results

圖16 各雷達節點受壓制干擾情況Fig.16 The indication that each radar node is interfered

圖17 干擾機和組網雷達的距離變化Fig.17 The distance variation of the jammer and the networked radar
在1~25步,干擾機與雷達1、雷達2和雷達3的距離最近,因此干擾資源偏向于分配給這3部雷達,以達到最佳的干擾效果。為了對抗上述干擾策略,組網雷達分配資源大部分資源給雷達1、雷達4和雷達5,其能夠提升未被干擾且距離較遠的雷達4和雷達5檢測概率,同時能夠提升受干擾最嚴重的雷達1的檢測概率。采用該策略保證在K-N融合準則下對的檢測概率最大。在26~38步,干擾機所有的功率都用于干擾雷達3。在這種情況下組網雷達3的探測性能受到極大限制,所以在系統資源有限的情況下,幾乎不分配資源于此節點,以保證對突防目標的及時探測。總體來看,基于DRL的組網雷達功率分配方法能夠隨著壓制干擾強度以及目標運動實時動態調整每個雷達節點的功率,從而提高資源的利用率,進而提高壓制干擾下目標的發現概率。
從圖15(b)可以發現,基于PSO的組網雷達功率分配在整個仿真時刻呈現出交替分配較大功率給部分雷達,這種各個分配時刻交替分配功率的分配策略與雷達受干擾情況和雷達-目標的距離曲線的變化不符。原因在于基于PSO的組網雷達功率分配不能保證各個時刻的分配結果都是最優。
從圖15(c)可以發現,基于AFSA的組網雷達功率分配在1~10步的功率分配結果變化較大,選擇為部分雷達分配均等的發射功率;在6~25步組網雷達的能量主要分配給雷達1、雷達4和雷達5,而此時雷達2和雷達3受到干擾,可以發現AFSA將組網雷達功率分配給未受干擾的雷達,這種分配結果使雷達2和雷達3對目標的檢測概率較低,進而導致K-N融合準則下目標的檢測性能降低。在26~45步具有類似的結果,但是僅雷達3被干擾,因此融合后的目標檢測性能下降小。總體來看,AFSA將組網雷達功率均勻地分配給未受到干擾的雷達節點,這種分配方式是一種保守的分配策略,在被干擾雷達節點較少時有較好的目標檢測性能。
表4對比了50次蒙特卡羅仿真下各分配策略的資源調度運行時間。其中PSO算法和AFSA算法的種群規模數和最大迭代次數均相同,所有算法均在相同的仿真平臺上運行。從運行時間來看,所提方法的資源調度運行時間能夠達到0.01 s以下,相對于PSO優化方法和AFSA優化方法有顯著提升,完全能夠滿足高動態博弈場景下雷達功率資源調度的實時性要求。

表4 各策略的資源調度運行時間Tab.4 The resource scheduling running time of each strategy
7 結語
考慮到干擾機與雷達相互博弈作戰場景,本文提出了一種基于DRL的伴隨壓制干擾下組網雷達功率分配問題的解決方案。在該問題中,干擾機和組網雷達被映射為智能體。基于DRL的策略網絡被用來訓練組網雷達的功率分配策略,同時采用DRL生成干擾機智能體的波束選擇和功率分配動作。此外,引入模型知識和專家知識,以協助兩類智能體的策略探索。在仿真測試中,干擾機采用了基于DRL的干擾策略,而組網雷達分別采用了基于DRL的功率分配以及其他兩種啟發式組網雷達功率分配方法。比較了3種組網雷達功率分配方法在目標檢測概率和運行時間兩個指標下的表現。結果表明,當干擾機采用DRL資源分配策略時,組網雷達采用基于DRL的功率分配策略在兩個指標上都優于其他方法。這是因為DRL采用離線訓練生成策略模型,因此在線功率分配的運行時間相比PSO和AFSA更快。其次由于干擾機的干擾波束和功率具有不確定性和動態性,基于啟發式搜索的組網雷達功率分配策略難以在這種環境下求得最優解,而DRL的分配策略是從智能體與環境交互的訓練樣本得到的,這些樣本中包含了干擾機帶來的不確定性,因此基于DRL組網雷達功率分配具有更好的目標檢測性能。
在未來的工作中,我們將探究在多干擾機協同干擾下的組網雷達資源分配,并且拓展當前的組網雷達資源分配算法,使其能夠適應分布式學習結構,以應對集群體系的對抗場景。同時,我們也會考慮其他針對雷達的抗干擾措施,如波束置零和干擾濾除等。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
鐵道通信信號(2020年9期)2020-02-06 09:15:22
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
文苑(2018年23期)2018-12-14 01:06:06
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
