融合數據分析算法的臨床科研平臺研究
2023-07-06 06:18:09林志剛
中國信息化 2023年6期
林志剛
一、引言
在各級各類醫療機構中,科研水平已成為衡量其發展程度的重要依據。近年來,人工智能、大數據等信息技術的蓬勃發展對醫療領域的科研模式產生了深遠影響。國家先后出臺了《“健康中國2030”規劃綱要》《關于促進和規范健康醫療大數據應用發展的指導意見》《關于印發國家健康醫療大數據標準、安全和服務管理辦法(試行)的通知》等政策文件,鼓勵推進醫療大數據的開放共享、深度挖掘和醫學科研應用,造福于民。醫療領域的科研需要精確的實驗方法設計,更需要大量的實驗樣本、高質量的實驗數據、及時的數據分析結果。人工智能、大數據等信息技術為醫療領域的科研注入了新的技術活力,使實驗設計更具有針對性和前瞻性,樣本收集更快捷高效,數據分析結果更準確直觀。
從學科建設和醫院的長期發展來看,基于臨床大數據的專科、專病科研是未來的發展趨勢。許多醫院已在這些方面進行了有益的嘗試,例如,上海市兒童醫院以兒童專科為特色,搭建了醫療大數據平臺。首都醫科大學附屬北京天壇醫院立足醫院特色,建設了神經腦血管病專科大數據科研平臺,自2017年部署實施后,應用效果良好。廈門大學附屬第一醫院建立了專科臨床科研管理平臺,提高了臨床數據的科研利用率。
借鑒相關醫院的成功經驗,我院基于已有的臨床信息系統,建設了大數據智能平臺,在科研平臺上融入高效的數據分析算法和工具,進一步增強了臨床科研平臺的功能。本文重點介紹臨床科研平臺的架構、科研平臺的數據采集和數據分析功能,并以“2型糖尿病人頸動脈斑塊形成的危險因素”的臨床科研案例進行說明,而科研項目的全過程管理不在本文進行討論。
二、臨床科研平臺的架構
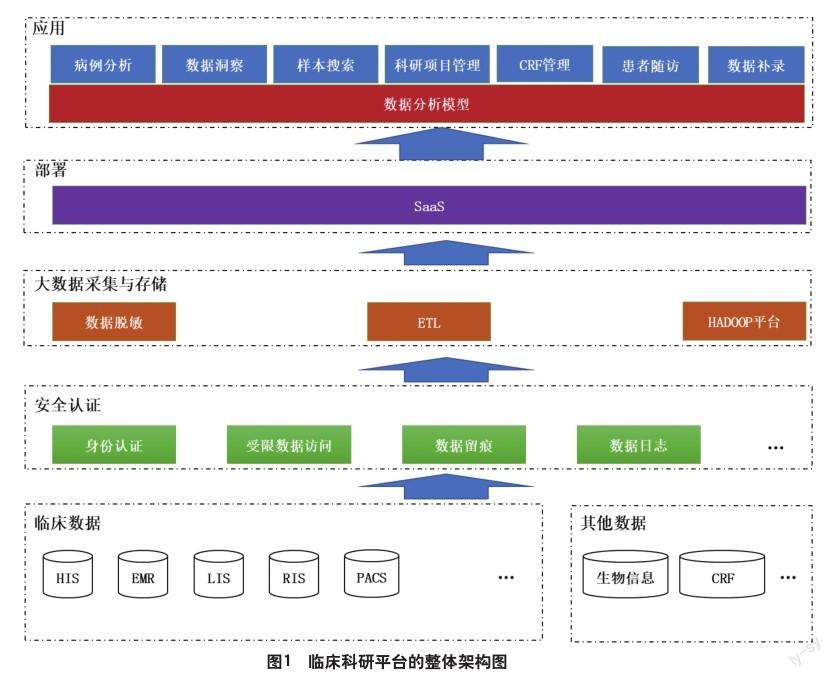
打通各個信息子系統的障礙,構建共享的數據平臺是我院構建臨床科研平臺的重要任務。我院構建的臨床科研平臺整體架構如圖1所示,根據實際的業務分布,整體平臺由5個層次構成,各層的內容如下:
(1)數據層主要由臨床信息子系統及其他信息系統構成。臨床數據囊括了醫院信息系統(Hospital Information System, HIS)、病案系統(Electronic Medical Record, EMR)、實驗室(檢驗科)信息系統(Laboratory Information System, LIS)、放射信息管理系統(Radiology Information System, R I S )、醫學影像存檔與通訊系統(Picture Archiving and Communication Systems, PACS)等的數據;其他數據包括生物信息、病例報告表單(Case Report Form)等信息系統的數據。
(2)安全認證層利用技術手段來保障數據的安全,主要采用了諸如身份認證、受限數據訪問、數據留痕、數據日志技術。
(3)大數據采集與存儲采用Hadoop平臺技術,經過對初始數據層的數據脫敏和預處理后,進行醫院全維度數據采集。
(4)部署層主要采用SaaS(Software as a Service,SaaS,軟件即服務)架構,實現數據統計、報表、評價模型等業務邏輯的處理,將主要應用以WEB的方式提供給應用層的用戶。
(5)應用層根據臨床科研的實際需求,重點實現了病例分析、數據洞察、樣本搜索、CRF管理、患者隨訪、科研項目管理、數據補錄等功能。
三、科研平臺的臨床病例采集功能
傳統的臨床科研往往需要從各個子系統中逐個抽取病例樣本進行手動管理,效率較低且出錯率高,臨床醫生可以直接獲得的臨床數據質量普遍較低,這直接影響醫院臨床科研人員產出的水平;同時,由于臨床病例數量大、噪聲多,這些問題集中到基于臨床病例的科研中,導致廣大科研人員對第一手病例的分布特征缺乏直觀認識,科學假設從提出到驗證周期長。
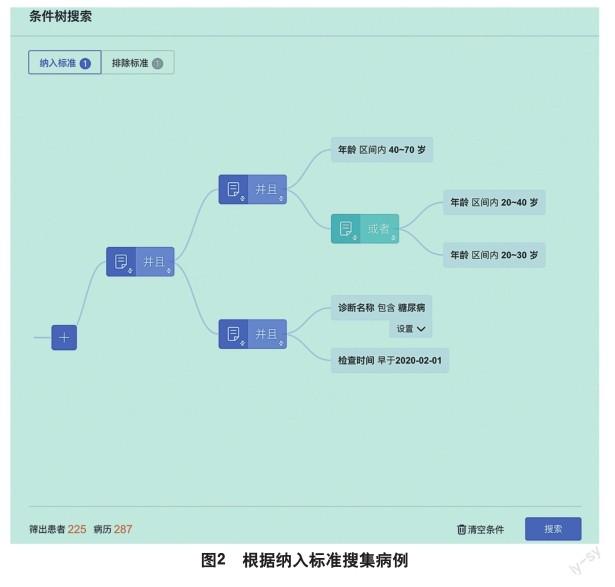
本平臺利用高效的數據采集算法,能極大地降低假設到實驗驗證的困難,滿足人工智能和數據挖掘技術應用于臨床科研的需求,有效提高科研效率。以臨床科研中分析“2型糖尿病人頸動脈斑塊形成的危險因素”為例,在納排研究對象時,如圖2所示,采用的納入標準為:年齡介于40到70歲,體質指數(BMI)介于20到28,診斷名稱包含“2型糖尿病”,設置時限后,科研平臺自動采集到1351名患者,1475例病例。同時,如圖3所示,設置排除標準為:患有患有腫瘤、糖尿病急性代謝紊亂綜合征、肝臟疾病、資料不完整的病人,進行病例篩除。
在搜集到科研病例后,科研人員可以預覽或導出病例數據。在本平臺中,可以利用納排的病例創建單獨的“2型糖尿病人頸動脈斑塊形成的危險因素”科研項目,設置病例與科研項目的對應關系,設置團隊成員后可以共享科研項目數據,展開研究。
根據搜集到的科研病例,可以根據需求設置指標,從病例中抽取相關數據,例如,可以在“2型糖尿病人頸動脈斑塊形成的危險因素”的科研項目中收集病人的年齡、性別、身高、體重、血壓、丙氨酸氨基轉移酶、同型半胱氨酸、尿酸、糖化血紅蛋白等指標,進行研究。
四、科研平臺的數據分析功能
基于收集的科研病例和數據指標,在本平臺可以進行數據分析,初步驗證科學假設。本平臺的數據分析算法主要包括特征描述、類別分析、回歸分析、知識圖譜分析等。
(一)數據特征描述
在特征描述中,本平臺提供了數據分析的平均性指標,包括算術平均數、中位數、眾數、四分位數,還包括簡單調和平均數、加權調和平均數、幾何平均數等指標。特征描述也包括諸如極差、平均差、標準差、四分位間距、標準差系數等離散性指標,還包括數據形態分布的指標,如原始數據服從正態分布情況下的偏度系數、峰度系數等。在用戶選定需要計算的數據屬性或特征指標后,本平臺可以直接利用平臺算法按用戶要求計算指定的數據特征。
基于平均性指標和離散性指標還可以進行數據標準化,本平臺提供了極差標準化、Z-Score標準化、歸一化等算法。
在特征描述中,基于本平臺的數據分析算法還可以利用可視化工具,繪制不同特征值的散點圖、折線圖、面積圖,演示數據特征;或利用異質性指標、集中性指標等進行探索性的復雜數據分析,其中的異質性指標包括Gini指標、熵指標等。在特征描述中,還包括二元數據的協方差、 Pearson系數、Spearman系數、多元數據的方差-協方差矩陣等測定指標。
(二)類別分析
類別分析包括聚類算法和分類算法,聚類算法主要根據病例樣本的選定屬性或特征,將病例樣本劃分為有意義的類或簇。本平臺集成了K均值聚類算法、層次聚類算法、密度聚類算法等。科研人員根據選定的屬性或特征,可以選用不同的聚類算法對病例進行劃分,并用圖示方法展示,方便科研人員反復調整參數取得滿意結果。聚類算法不必要使用樣本病例的標記,是根據選定屬性或特征的自然聚集。而分類算法則要根據已有樣本病例所屬不同類別的標記結果,預測未知病例樣本的所屬類別或標記。本平臺的分類算法包括決策樹算法、貝葉斯算法、SVM算法、KNN算法等。
(三)回歸分析
本平臺主要利用回歸分析算法幫助科研人員在臨床數據用一個或多個屬性值(自變量)去解釋另一個屬性值(因變量)。一般來說,臨床病例的樣本具有多維特征,本平臺的回歸分析主要提供單因素和多因素回歸分析算法,在多因素回歸分析算法中,進一步包括多因素線性回歸算法、多因素Logistic回歸算法等。以“2型糖尿病人頸動脈斑塊形成的危險因素”科研項目為例,在本平臺的單因素邏輯回歸和多因素邏輯回歸方法中,能提供詳細的結果說明,并提供回歸模型診斷和可視化結果。
(四)知識圖譜分析

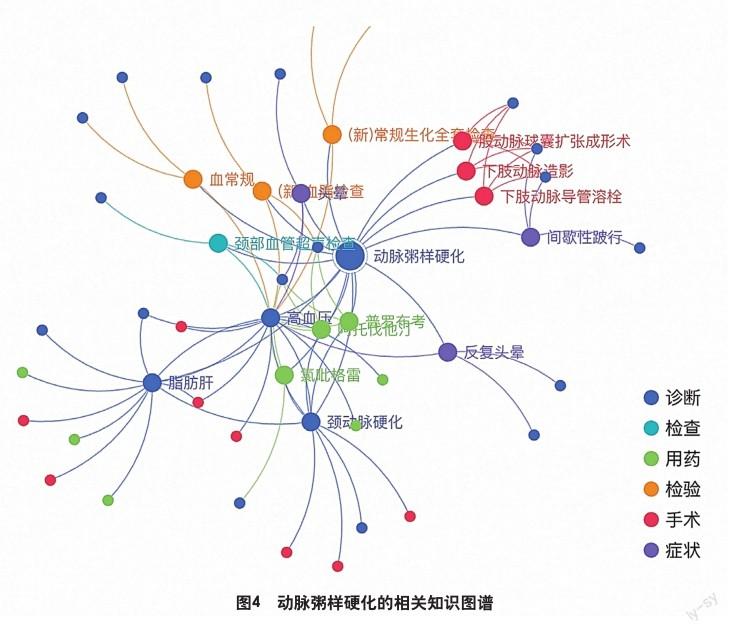
知識圖譜能對領域知識進行顯性化的沉淀和關聯,在搜索到的科研病例中,本平臺通過自然語言切分技術處理歷史診斷數據中的專業術語,并利用深度學習技術構建領域本體;關聯病歷記錄中的結構化數據,利用共現分析技術、模式匹配技術、統計機器學習技術進行屬性抽取;通過相似度挖掘、聚類等方法進行知識整合和關系屬性鏈接。通過知識圖譜的可視化展示,能給科研人員更清晰的關聯知識表達,為后續的研究方向和數據分析角度提供有力工具。圖4展示了動脈粥樣硬化在ICD10詞表中利用多個下位詞構建的知識圖譜。
五、科研平臺的其他特點與優勢
(一)標準化程度高
我院的臨床科研平臺基于醫療行業標準,采用的行業標準既考慮國際標準的領先性,也與醫院實際數據情況相結合,確立了醫院標準化的數據管理規范,并提供相應的標準化組件功能實現標準化管理服務(比如數據標準化、術語服務標準化)。這些都節約了醫院持續發展的成本,簡化了持續發展的復雜性,使復雜的醫療數據管理和整合成本有效降低、改善了數據整體的利用效率。
(二)平臺支持了既有業務的需求,也兼顧了未來的增長性需求
在我院臨床科研平臺的建設中,充分發揮已有系統的功能,利用現有的數據庫,通過平臺提供數據集成和業務價值的增值,不僅保存了業務系統的原有歷史數據,而且滿足了接入和管理未來數據增長的需求。平臺采用了模塊化的設計,便于醫療服務業務的變化和擴展,提供了豐富的開發環境,支持多種應用的開發,能夠實現跨平臺數據庫間的數據管理,提供了用戶應用層的組件支持。
(三)注重頂層設計,強化安全設計
我院臨床科研平臺的建設從醫院的現實需求出發,統一規劃、統一設計。平臺架構采用了整體化的設計理念,可以覆蓋業務系統數據的完整接入,并可進行逐一的數據校驗服務以及對歷史數據的關聯性存儲,還可以按需擴展并支撐第三方系統的數據利用。平臺也進行了全面的安全性設計,防止對數據的非法訪問、破壞和泄露。由于平臺將管理醫院全部數據,平臺架構提供了嚴謹和完善的安全和隱私管理策略及服務。
六、結語
我院通過對接臨床信息子系統,建成了融合數據分析算法的臨床科研平臺。依據醫院實際的業務需求,平臺提取了臨床信息子系統數據和生物樣本數據(脫敏后的數據),實現了病例分析、樣本搜索、CRF管理等功能;并提供了特征描述、類別分析、回歸分析、主成分分析、知識圖譜分析等數據分析算法和工具;由此,實現了臨床信息子系統和生物樣本庫的數據共享,集成了數據分析算法,滿足了臨床科研的數據處理需求。
作者單位:福建醫科大學附屬第一醫院信息中心
