金融時間序列數據可視化框架研究
2023-07-07 03:10:04許紅星
計算機應用與軟件 2023年6期
羅 超 許紅星 段 然
(云南大學軟件學院 云南 昆明 650504)
0 引 言
經濟市場快速發展,帶來資本市場的快速發展。傳統的手工交易方式存在著效率低、盲目投資、實效性差等問題,導致手工交易越來越無法滿足人們的需求。在手動交易的基礎上,人們開發出了量化交易的方式,以先進的數學模型替代人為的主觀判斷,利用數據挖掘、機器學習、深度學習等計算機技術從龐大的歷史數據中海選能帶來超額收益的多種“大概率”事件以制定策略[1-4],極大地減少了投資者情緒波動的影響,避免在市場極度狂熱或悲觀的情況下做出非理性的投資決策。
在研究量化模型和交易策略的過程中,使用的數據主要是時間序列數據。這種數據如果直接以數字方式呈現,會導致難以分析數據的特點,難以直觀看出變化規律,對策略的制定會有很大的限制。如果只涉及一般大盤和股票數據,研究者可以選擇市面上成熟的股票行情軟件作為輔助參考,但這難以滿足研究者的個性化需求。例如在研究中自定義了新指標的計算模型、自合成了新板塊數據時,不僅要求能靜態地顯示數據,還要能在策略回測、實盤交易時動態地更新并顯示數據,但是常見的量化平臺并不提供此類個性化的可視化接口,這給研究工作造成了阻礙。
對于上述個性化的需求,研究者通常采用兩種方法解決:股票公司訂制數據、自己編程實現。第一種方法最為直接,但是在研究過程中模型和策略的變動比較頻繁,訂制的內容可能跟不上需求的變更,而且如果是小型研究團隊或個人研究者,這也增加了研究成本。第二種方法對編程能力提出了要求,可以使用可視化工具包做出圖形[5-6],但一般復用性較差、容錯率較低,只能依托固定的平臺或程序,不能適應數據的高速變化,甚至沒有考慮數據的動態更新,且市面上缺乏完整的可供調用的可視化模型或框架,也缺少對圖形繪制的詳細描述,這無形中降低了研究效率。
因此,我們從實際出發,針對存在問題和市場需求,建立了一套金融時間序列數據可視化框架,兼容大部分圖形和金融指標的顯示,也允許用戶添加自定義指標,支持數據動態更新的同時,還考慮到了回測和實盤過程中該類數據具有高實時性、高并發性、瞬時數據量大的特點,改進了數據刷新方式,為下游用戶做數據分析與量化交易策略研究提供了可靠且高效的上游數據可視化支持。且框架本身也可作為同類型軟件UI設計部分的參考,可以在不同平臺用不同編程語言實現。最后以實際工作為參考,將框架與各類常見的量化交易平臺相結合,驗證了框架的實用性、高效性和跨平臺性。
1 數據結構
1.1 Tick數據
Tick是交易數據流的一種快照,是金融時間序列數據的基本單位。以期貨市場為例,交易系統會實時收到交易所每秒2次的Tick行情推送,其行情信息有最新價、成交量、成交額等,不同市場或不同量化平臺提供的Tick數據,在數據結構和推送頻率上都有所不同。我們將一個Tick數據定義為一個基本單位t,t的數據結構設計意在滿足所有信息能完整獲得的情況下,做到每次傳輸的數據量最小化。作為一種需要高頻刷新的數據,其本身的信息攜帶量過大,會導致傳輸性能的降低和傳輸成本的增加。因此,Tick數據的結構設計,只保留交易中的基本數據,其他關鍵數據,可由基本數據計算出來。綜上所述,t被設計為一個四元組:
t=[′price′,′datetime′,′volume′,′amount′]
(1)
式中:price為最新價;datetime為Tick的創建時間;volume為瞬時成交量;amount為瞬時成交額。
1.2 K線數據
K線模型是最常用的數據可視化模型,其數據由單位時間內的Tick數據生成。K線的數據結構設計為一個多元組:
bar=[′datetime′,′open′,′high′,′low′,
′close′,′volume′,′amount′]
(2)
式中:datetime為K線數據的起始時間(或結束時間);open為單位時間內的開盤價;high為單位時間內的最高交易價格;low為單位時間內的最低交易價格;close為單位時間內的收盤價;volume和amount分別為單位時間內的成交量和成交額的總和。
定義T=[t1,t2,…,tN]為Tick數據的集合,間隔頻率為x。設K線的單位時間為y,N為單位時間內Tick數據的個數,若xN=y,則K線數據可以由集合T通過以下公式合成:
bar[′datetime′]=t1[′datetime′]
(3)
bar[′open′]=t1[′price′]
(4)
bar[′close′]=tN[′price′]
(5)
bar[′high′]=Max(T[′price′])
(6)
bar[′low′]=Min(T[′price′])
(7)
bar[′volume′]=∑T[′volume′]
(8)
bar[′amount′]=∑T[′amount′]
(9)
2 框架設計
2.1 總體設計
可視化框架的架構分為3層,分別是底層接口、中層引擎和上層應用,如圖1所示。

圖1 可視化框架架構
中層引擎的設計參考了vn.py框架的設計思路[7],包括數據引擎和事件引擎,往下對接各種數據輸入接口,往上服務于各種應用模塊。
底層接口負責對接輸入數據,主要是時間序列數據、金融技術指標和計算模型。上層應用包括可視化模塊和功能模塊、可視化模塊負責圖形的繪制、功能模塊涉及與用戶的動態交互。
2.2 上層應用
2.2.1 可視化模塊計算模型
根據大多數交易員的使用習慣,可視化部分依然采用主流的設計,即1個主圖、2個副圖的形式。主圖用來顯示K線圖與均線圖,副圖根據需要可切換顯示各種指標。我們以顯示區域的左上角為坐標(0,0),右下角坐標為(x,y)建立一個矩形顯示區域并劃分3個子圖區,如圖2所示。3個子圖區有各自的縱坐標和比例,但是3個圖區的橫坐標是同步的。

圖2 可視化模塊
設有一組金融時間序列數據B=[bar1,bar2,…,barN],若此時模塊可顯示的K線個數為N,即將B全部繪制到顯示區域,需要以下幾個步驟:
(1) 確立子圖的坐標系。計算橫縱坐標軸的上下界、比例和顯示間隔。
橫坐標:將子圖的橫坐標等分N+1份,可得到N條刻度,刻度的值由此位置所在K線的datetime確定。
主圖縱坐標:首先將輸入數據中四個維度[′open′,′high′,′low′,′close′]的所有數據看作一個集合,獲取集合中的最大值和最小值作為主圖縱坐標的上下界,并計算兩者差值d。模塊中預先設定了15個檔位的坐標軸間隔,以及每個檔位對應的數據取舍精度,如表1所示。
計算d與各間隔的比值,選擇比值最接近10的一檔作為主圖縱坐標的間隔,表2使用5組具體數據以說明整個計算過程。

表2 坐標軸間隔及上下界計算示例
副圖縱坐標:常見的副圖圖形主要有柱狀圖和折線圖兩種,在確立副圖縱坐標時需要考慮輸入數據的分布。一種情況是數據只分布在X軸一側,即全為正數數據或全為負數數據,此時取數據絕對值的最大值計算比例即可。另一種情況是數據分布在X軸兩側,此時X軸需要繪制到區域中心,兩側比例取數據絕對值的最大值計算。
(2) 計算圖形坐標。將之前確立的坐標系與顯示區域(屏幕)的坐標系作轉換,主要繪制的圖形有K線圖、柱狀圖和折線圖。

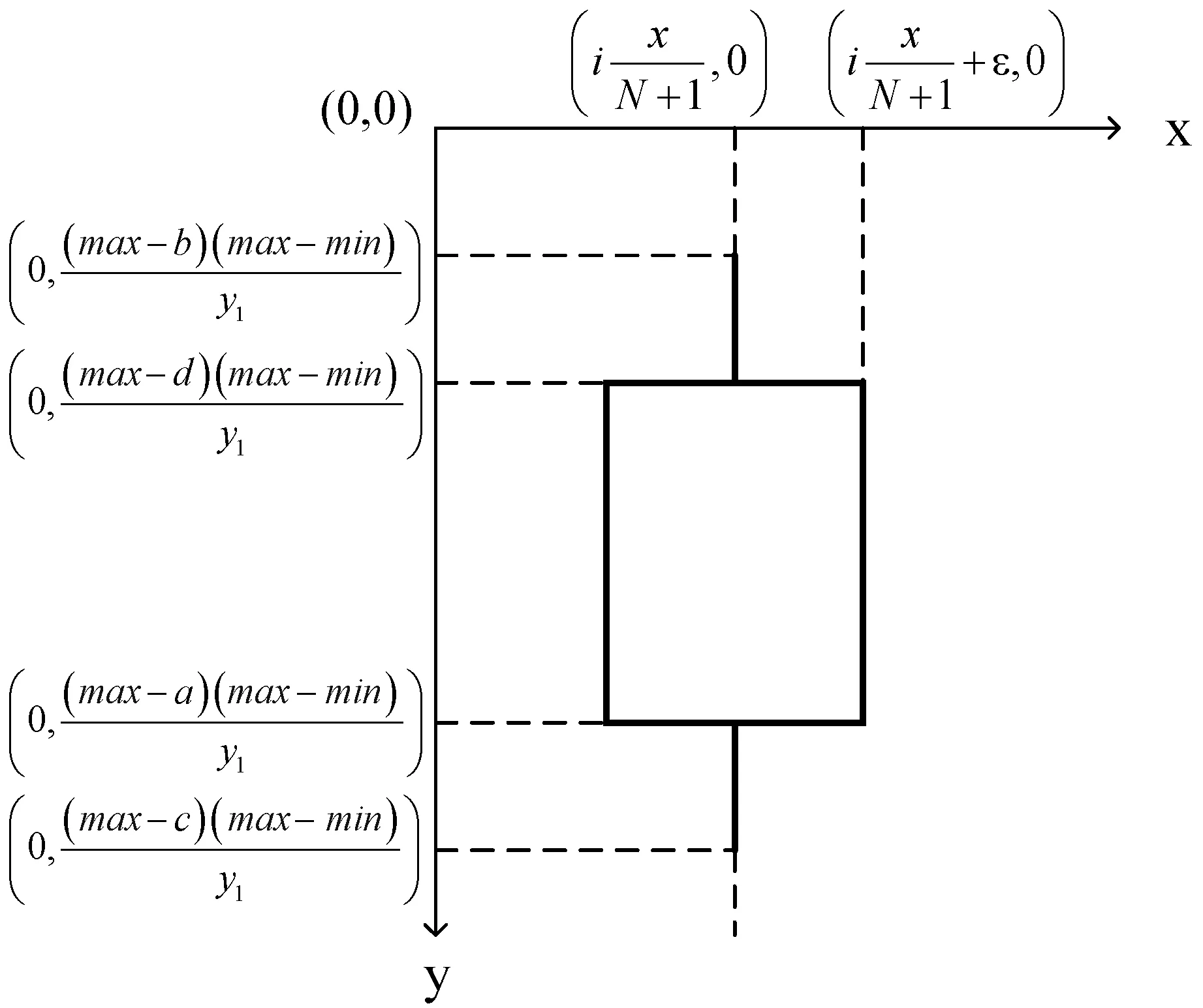
圖3 K線圖形坐標計算
2.2.2 功能模塊計算模型
功能模塊要實現的是數據圖形在顯示區域內的縮放、左右移動以及光標十字線等內容,本質上是接受操作輸入,觸發可視化模塊的重繪機制,實現與用戶交互的過程。
(1) 縮放與平移功能。框架內置兩個參數,count用于控制顯示區域可繪制圖形的個數,start用于記錄顯示區域第一個繪制的圖形的下標,2.2.1節中所描述的“設有一組金融時間序列數據B=[bar1,bar2,…,barN],將B全部繪制到顯示區域”,就是對應于count=N,start=1的情況。數據B傳入框架時不是直接通過可視化模塊繪制,而是以參數count和start構成的“滑動窗口”在輸入數據B上進行截取,然后再傳入可視化模塊進行繪制,過程如圖4所示。改變count值就可以實現動態放大縮小的可視化效果,同理固定count值并改變start值就可以實現平移效果。
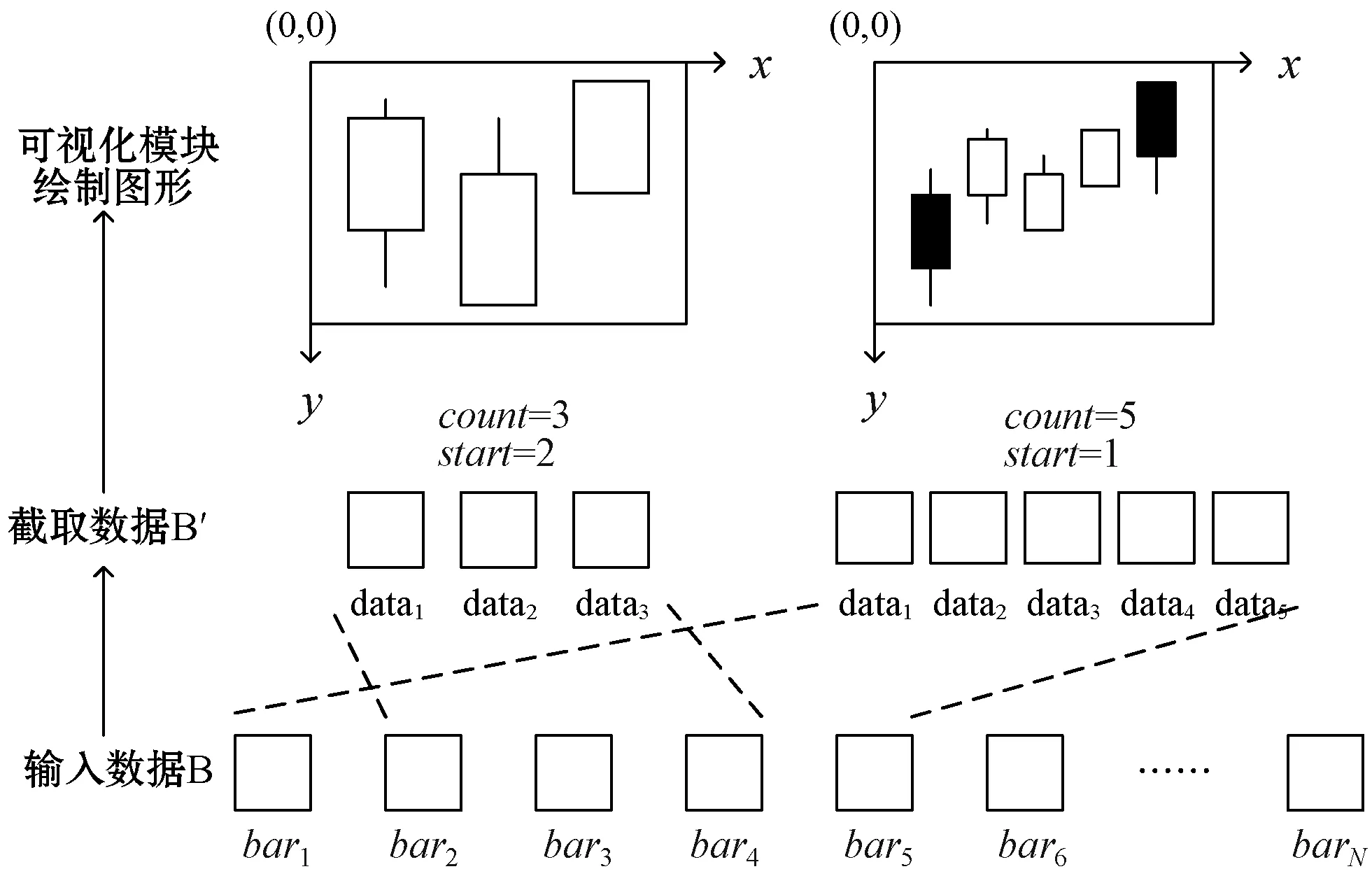
圖4 縮放及平移功能
(2) 光標十字線功能。隨著光標在顯示區域中的移動,實時地以光標為中心繪制水平與垂直兩條直線,并有一個浮動窗口顯示光標所指處圖形數據信息的功能。此功能有助于用戶更精準快速地查看數據,核心在于通過光標的顯示區域坐標計算出圖形數據在“滑動窗口”中的下標,進而獲取到數據,過程如圖5所示。
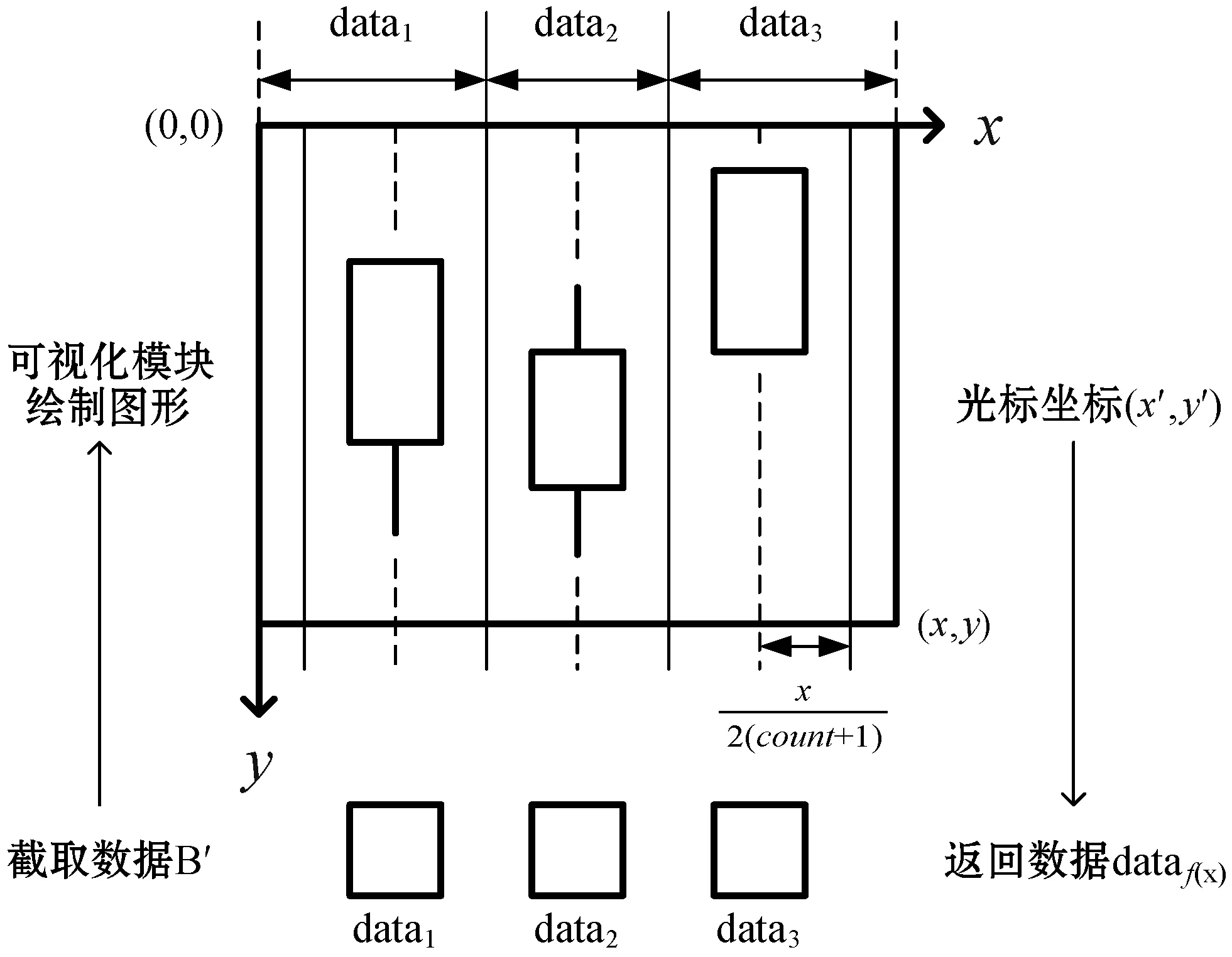
圖5 光標獲取數據
圖中設光標的坐標值為(x′,y′),通過式(10)和式(11)可計算出截取數據的下標f(x′),進而獲取數據。
(10)
(11)
2.3 中層引擎
中層引擎的功能是將程序中的各個組件,例如數據庫接口、多線程等整合到一個對象中,便于上層應用的調用。下面對事件引擎和數據引擎的工作原理及流程做介紹。
2.3.1 事件引擎
事件引擎工作流程如圖6所示。

圖6 事件引擎工作流程
事件引擎是整個框架的核心組件,也是大多數交易系統或回測引擎,甚至大多數交互程序的設計基礎。事件引擎的設計基于事件驅動,事件驅動簡單來說就是用戶點什么按鈕(即產生什么事件),計算機就執行什么操作(即調用什么函數)[9]。事件引擎主要完成的功能是收集事件對象(底層接口數據推送、用戶輸入)存入事件隊列,并依次傳入數據引擎作出相應處理。目前本框架中數據引擎承擔了所有事件的處理工作,但仍把事件引擎和數據引擎的設計分隔開,是為以后框架更新、加入更多處理引擎做準備。
2.3.2 數據引擎
數據引擎主要負責維護數據在整個框架中的讀寫、傳遞與計算,包括計算模塊、緩存模塊、數據庫接口模塊三個子模塊。主要完成以下兩個工作:
(1) 底層接口數據推送的處理。底層接口以某個頻率不斷向中層引擎推送tick數據,由事件引擎傳入數據引擎后,將tick數據保存到數據庫并計數,直到tick數據的個數滿足合成bar數據的要求,則計算模塊將這一段tick數據取出合成bar數據。如底層接口以3秒的頻率推送tick數據,顯示模塊使用1分鐘級別的bar數據,則每20個tick數據為一組合成bar數據,合成方法如式(3)-式(9)所示。合成新的bar數據后,添加到緩存模塊,以內置參數count和start重新截取顯示數據傳入顯示模塊并執行重繪、內置參數及截取方法如式(10)和式(11)所示。如底層接口傳入了bar數據,則直接添加到緩存模塊。
(2) 用戶輸入的處理。用戶輸入是指用戶調用了功能模塊,或改變內置參數count和start以放大、縮小、平移圖形,或移動光標以獲取光標所指處圖形所包含的數據信息。如是前者,數據引擎將重新截取顯示數據傳入顯示模塊并執行重繪,如是后者,數據引擎將根據式(10)和式(11)計算出光標所指處對應的顯示數據的下標,然后將數據傳入可視化模塊并執行重繪。
2.4 底層接口
底層接口是可視化框架的輸入通道,金融時間序列數據由此傳入中層引擎,且自定義指標和自定義計算模型通過配置文件的形式保存,并由數據引擎中的計算模塊調用。
本框架的跨平臺性也由底層接口體現。用戶通過量化交易平臺訂閱數據,在平臺的回調推送端調用底層接口,即可實現數據的持續可視化及交互,使用效果將在下一節與不同平臺對接測試中展示。
3 量化交易平臺對接測試
本節以實際工作為例,選取兩個代表性的量化交易平臺進行對接測試,以說明本框架的主要功能及用途。
3.1 自定義股票板塊結構并對接商用平臺
現有以下需求:取若干股票,自定義“煤炭”板塊,根據所取股票數據合成新板塊數據,并對接國內某量化交易平臺,使新板塊數據在回測時能實時更新顯示。板塊的計算模型如表3所示。

表3 自定義板塊計算模型
第一步,訂閱這若干只股票的行情數據,訂閱后量化平臺將在回調推送端自動傳回行情數據。第二步,分析平臺傳回行情數據的結構及字段信息,編寫計算模型,將平臺數據轉換成式(1)的形式。第三步,在平臺的回調推送端直接調用數據傳入接口。之后每當平臺推送數據,就會觸發事件引擎,通知數據引擎根據自定義的計算模型轉換數據并存入數據庫,并根據顯示模塊的參數,合成相應的bar數據及其他金融指標,最后由上層應用繪制圖形,實現新版塊數據的持續可視化與交互。
在測試中,同時定義了多個板塊,涉及不同數量的股票數據,添加了鍵盤事件實現板塊切換,并使用多個時間段回測觀察性能表現,如表4所示。測試環境:Intel i7-8750H,內存16 GB,以下測試中框架均能正常工作,響應時間小于1秒,能夠滿足日常研究需要。自定義“煤炭”板塊的效果圖如圖7所示。

表4 平臺對接測試

圖7 自定義“煤炭”板塊效果圖
3.2 基于開源平臺的二次開發
vn.py是基于Python語言的開源的量化交易系統,基于vn.py二次開發說明了可視化框架可以作為同類型軟件UI設計的一部分,不局限于電腦端或手機端。在開發時,由于可視化框架的中層引擎部分就取自于vn.py,所以框架的上層應用可以很好地移植到vn.py中。軟件界面如圖8所示。

圖8 基于vn.py二次開發的軟件界面
4 結 語
本框架設計是為了滿足量化交易研究過程中個性化定制數據的可視化需求,使用戶可以更加注重策略和模型研究本身,直接調用接口,方便快捷,優勢在于兼容目前市場上絕大多數的量化交易平臺。
此次工作的不足之處:(1) 測試時板塊數量與包含股票數量代入不夠,未能測試框架所能承受數據量的上限。(2) 回測周期較短,不能說明框架在長時間運行時的穩定性。(3) 沒有具體性能指標,只通過主觀判斷系統運行效果,不具有說服力。針對以上問題將在后期的研發工作中加大測試力度,完善框架的整體性能評價。
最后框架本身還有很多值得改進與擴充的部分,將在今后的工作研究中不斷完善和更新。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
數學物理學報(2020年2期)2020-06-02 11:29:24
傳媒評論(2019年4期)2019-07-13 05:49:14
商周刊(2017年22期)2017-11-09 05:08:31
光學精密工程(2016年6期)2016-11-07 09:07:19
河南電力(2015年5期)2015-06-08 06:01:46
