基于BERT-WWM預訓練的跨文檔三元組提取
2023-07-07 03:10:18章振增
計算機應用與軟件 2023年6期
章 振 增
(南威軟件股份有限公司 福建 泉州 362000)
0 引 言
三元組信息抽取是知識圖譜構建的關鍵問題之一。該任務的輸入是篇章內容,輸出是三元組(SPO)集合。SPO中的S、O可以視為實體抽取任務,P可以視為關系抽取任務,因此SPO三元組抽取可以視為對實體與關系抽取任務。
當前實體與關系抽取任務的主要技術思路有兩種:流水線模型(Pipeline)和聯(lián)合模型。流水線模型把實體與關系抽取分成兩個子任務:實體識別和關系分類,兩個子任務依次執(zhí)行且二者之間沒有交互。而聯(lián)合抽取則把整個當成一個整體任務,目前針對實體與關系抽取任務的研究大多基于聯(lián)合模型。聯(lián)合模型主要是基于自然語言處理的深度學習方法,例如流行的Transfomer網(wǎng)絡,包括BERT[1]、TransformerXL[2]、RoBERTa[3]、GPT[4]、MASS[5]和ELECTRA[6]等。這些模型使用多頭注意力機制來捕獲上下文關系,由于上下文信息的引入可以幫助這些模型消除歧義和加強分布式表示的內涵。此外遷移學習方法的引入,使得深度學習可以在現(xiàn)有模型基礎上進行微調學習,增強了模型整體的收斂速度和準確度。
然而目前大多數(shù)實體關系抽取方法都是基于句子級處理,在實踐中有大量的實體關系事實是以多個句子表達的,文檔中的多個實體之間往往需要通過整篇文章才可能得以確定。也就是說模型不僅需要理解句子的信息,更需要綜合整篇文章的信息才能準確推斷實體類型以及實體間的關系。
目前在文檔級的公開語料上,有國內研究機構發(fā)布了DocRED(Document-level Relation Extraction Dataset)[7]大規(guī)模文檔級別信息抽取的數(shù)據(jù)集,該數(shù)據(jù)集結合Wikipedia的文章和Wikidata的結構化數(shù)據(jù)生成的,包含了5 053篇人工標注的文章,覆蓋了132 375個實體、56 354種關系。然而該數(shù)據(jù)集是英文數(shù)據(jù)集,不是本文所研究范疇。為了獲取中文跨文檔三元組語料,本文嘗試通過對Doc2EDAG[8]論文數(shù)據(jù)集(簡稱Doc2EDAG數(shù)據(jù)集)進行預處理,將其轉化成本文實驗所需的中文實體與關系抽取訓練數(shù)據(jù)集進行實驗分析。
1 相關工作
目前針對三元組SPO抽取任務的研究大多采用聯(lián)合模型。而聯(lián)合模型可分為基于參數(shù)共享和基于聯(lián)合解碼的聯(lián)合模型。另外,解碼方式對實體關系抽取性能的影響也很大,主要的解碼方式有三種:基于序列標注、基于指針網(wǎng)絡(PointerNet)和基于片段(Span)分類的方法。
聯(lián)合解碼的基于序列標注的經(jīng)典模型有文獻[9],通過{B,I,E,S,O}序列編碼,把實體以及實體關系直接通過語料序列標注時就進行表示,然后使用RNN序列模型進行編碼和解碼。這種模型簡單明了,也由此衍生出了許多變種的模型[10-11]。此外為解決實體重疊問題,有研究者提出了基于指針網(wǎng)絡的編碼模型[12],通過使用多個標簽序列(多層label網(wǎng)絡)來表示一個句子。基于片段(Span)分類的編碼模型SpERT[13]通過找出所有可能的片段組合,然后針對每一個片段進行分類。
SpERT模型通過遍歷生成所有可能片段進行訓練導致其計算復雜度極高,此外它也無法解決跨文檔實體與關系抽取問題。因此本文在SpERT模型基礎之上,通過引入SPAN規(guī)則模型來生成片段減少復雜度,width embeddings更改為Rule Index Embedding以及引入上下文信息等來解決跨文檔實體與關系抽取任務。
2 語料處理
Doc2EDAG數(shù)據(jù)集是金融領域事件抽取訓練數(shù)據(jù)集,其中事件的論元分散于不同句子(Sentence)中。因此只需對數(shù)據(jù)集中標注的事件論元等進行相應的轉換,即可得到本文所需的跨文檔實體關系抽取語料數(shù)據(jù)集。
Doc2EDAG數(shù)據(jù)集的文本存儲格式如圖1所示,每個字段域的具體含義如下:sentences域存儲原始文本數(shù)據(jù),按句子分隔存儲為數(shù)組;ann_valid_mspans域存儲實體信息;ann_valid_dranges域存儲實體位置信息;ann_mspan2dranges域存儲實體位置信息;ann_mspan2guess_field域存儲實體類別信息;recguid_eventname_eventdict_list域存儲事件類型、事件元素信息。

圖1 金融領域事件數(shù)據(jù)集實例
從上述信息格式分析可以看出,Doc2EDAG數(shù)據(jù)集中的實體已經(jīng)有規(guī)范的邊界定義,至于具體如何把語料中定義的事件信息轉化為三元組SPO信息,首先得考慮知識圖譜的最終應用上來定義和考慮。
三元組SPO抽取從知識圖譜最終應用于邏輯推理角度上解釋,這里S表示主體、O表示客體、P表示謂詞。本文訓練所構建的SPO數(shù)據(jù)集以篇章作為單位,實體為主體S與客體O,而P則是S與O之間的邏輯關系,它描述S與O之間的關系或屬性不需要從語料中抽取。基于此分析可以將實體識別問題表述為實體e邊界Ce=[estart,eend]檢測與實體e類別Ce={None,S,O,SO}的分類問題,其中類別SO表示該實體ei在三元組中既可能充當S也可能充當O,類別None表示ei非三元組中的實體。
下面通過選取Doc2EDAG數(shù)據(jù)集中的EquityPledge事件來說明事件元素信息如何轉換為對應SPO三元組信息。
如表1所示,EquityPledge事件規(guī)范元素有9項,部分元素的值為null。值為null部分也就是說實體不存在,轉換時可以直接跳過。EquityPledge事件中Pledger元素項的值映射為SPO三元組中的類別為CPledger=S實體,PledgedShares元素項的值映射為SPO三元組中類別為CPledgerShares=SO實體,事件中其余元素的值分別映射為SPO三元組中的類別為Ce=O實體。其中EquityPledge事件謂詞P的值為以下集合:

表1 EquityPledge事件
P={EquityPledge,Pledgee,…,TotalHoldingShares}
(1)
由以上映射關系定義可以最終得到如表2所示SPO三元組集合。
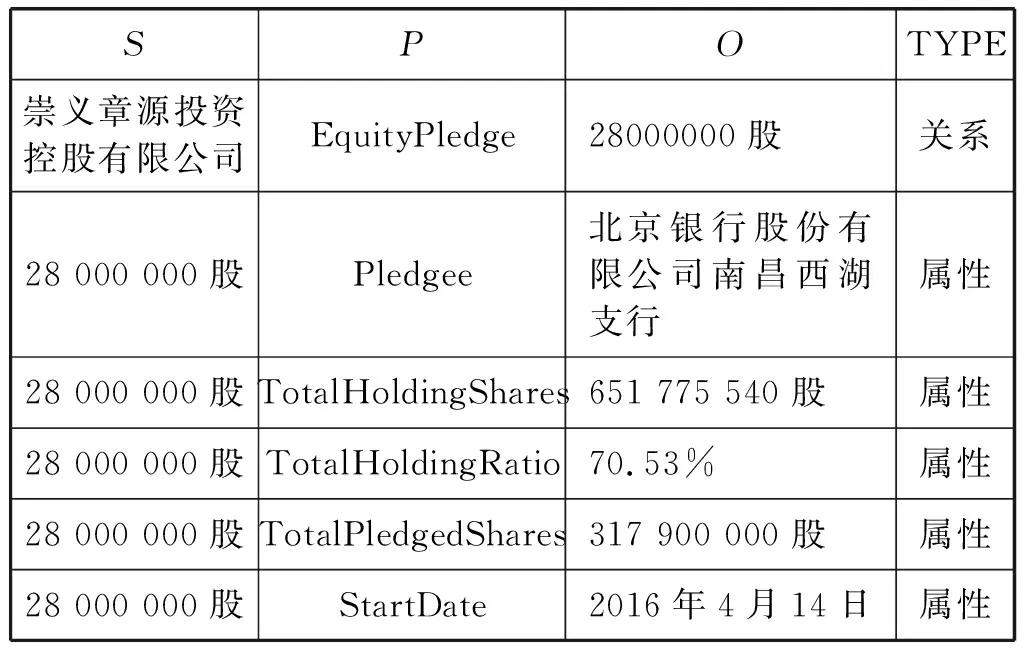
表2 SPO三元組數(shù)據(jù)
結合表1和表2可以看出PledgedShares項的值“28 000 000股”應標注為CPledgerShares=SO類別的實體,也就是說在三元組中既可能充當S也可能充當O。
同理,其他類型事件的元素也可以按照以上相似的方法進行映射,最終把Doc2EDAG數(shù)據(jù)集轉換為跨文檔三元組標注數(shù)據(jù)集。
3 模型結構
跨文檔SPO三元組任務的抽取過程不僅需要考慮當前S、O實體所在句子上下文信息,同時也需要考慮文檔的上下文。例如文檔語料中的某段含有實體內容的句子“……將其持有的本公司限售流通股32 000 000股(占本公司總股份的6.43%)質押給……。……占公司總股本32.97%;累計質押本公司股份164 000 000股……”,從該文檔中可看出其中的“1 640 000 00股”與“32 000 000股”為實體信息,但是哪個實體應該標注為“S”,哪個標注為“O”,需要將S、O實體所在句子以及文檔上下文一起考慮,才能得出正確的結論。
因此只考慮句子級的三元組抽取無法滿足實際需求,本文在借鑒SpERT網(wǎng)絡思想基礎上,構造了跨文檔的三元組抽取模型。模型的整體架構如圖2所示。

圖2 實體分類與關系抽取模型
模型的整體結構可以分為四個部分:
(1) BERT-WWM預訓練模型部分,該部分主要使用預訓練模型來得到token以及句子的Embedding表示。
(2) Stacked Span Rule Detect模型部分,該部分主要用于Span候選集生成。它通過語料學習來生成Span規(guī)則,為后面的Span候選集生成提供規(guī)則模型。
(3) Span Classification模型部分,該部分主要完成對生成的Span候選集進行Ce={None,S,O,SO}分類的任務。
(4) P Classification模型部分,主要通過對Span Classification模型得到的標簽為{S、SO、O}的Span進行排列組合得到候選集SOcandidate={(S1,O1),(S1,O2),…,(Si,Oj)},再對SOcandidate中每個元素進行謂詞P的多分類任務。
3.1 Span候選集
深度學習中的文本標注語料,通過基于BIO/BILOU的標注模式來實現(xiàn)。該標注模式只為每個字符分配一個類別標注,導致對于實體堆疊的情況就無法標記而完成學習。為此當前研究者提出了多種學習方式來解決該問題,如指針網(wǎng)絡、Span分類等技術。而SpERT模型是其中的代表模型之一,通過在模型中引入Span來聯(lián)合學習。但是由于SpERT模型的Span生成方式導致Span候選集過于龐大使得后期計算極為復雜,雖然模型也引入了Span最大長度來合理削減負樣本規(guī)模來解決部分問題,可是該方式對于長文本來說復雜度也極為復雜。
因此本文提出通過對語料的Span規(guī)則自動學習,實現(xiàn)Span候選集生成,而不需要去排列所有可能的token組合,使得Span候選集規(guī)模與句子的token長度比維持在接近1∶1的范圍之內,極大減小候選集規(guī)模加快訓練速度。接下來我們從Doc2EDAG數(shù)據(jù)集中抽取一篇文檔來分析Span規(guī)則與候選集生成過程,具體如圖3所示。

圖3 Span候選集生成處理流程
假設從語料的sentences字段域中抽取出一句文本如下:
“截至2018年12月28日,中國寶安持有本公司股份126 163 313股,占本公司總股本的29.27%。”
從以上文本中可知它含有的實體信息有兩項:實體1“126 163 313股”與實體2“29.27%”。如果單純從實體所含字符長度分析,二者差異較大無法形成有效規(guī)則,因此需要通過其他方式來得到一個較穩(wěn)定的符號特征模式來大體識別它們,這里通過采用詞性特征分析來加以實現(xiàn)。首先使用Hanlp[14]中文分詞工具對上文進行分詞和詞性標注,可得到如下內容:
“[截至/v, 2018/m, 年/qt, 12月/t, 28/m, 日/b, ,/w, 中國/ns, 寶安/ns, 持有/v, 本/rz, 公司/nis, 股份/n, 126163313/m, 股/q, ,/w, 占本/nr, 公司/nis, 總股本/nz, 的/ude1, 29.27/m, %/nx, 。/w]”
通過對比分詞前后以及實體1和實體2,可以發(fā)現(xiàn)實體1由分詞后的(126 163 313/m, 股/q)構成,實體2由分詞后的(29.27/m, %/nx)構成,可發(fā)現(xiàn)這其中已經(jīng)去除了實體長度因素的影響,并且由于分詞器本身就隱式地引入了通用先驗語言知識到本文模型之中。為了得到實體大范圍的規(guī)則覆蓋,本文通過把語料中只要出現(xiàn)的實體都形成規(guī)則,如(m,q)與(m,nx)詞性的組合規(guī)則直接加入規(guī)則庫,不考慮詞性的組合頻率等其他因素,具體的生成方式如下。
假設句子集S={s1,s2,…,sn},句子s1分詞后得到的詞集s1={w1,w2,…,wn}和對應的詞性集POS1={pos1,pos2,…,posn},通過對比語料中每個實體e所對應的詞wi對應詞性posi,可得到如下規(guī)則集:
Rm={(pos1,pos2),(pos5,pos6),…,(pos7,pos8,…)}
(2)
根據(jù)規(guī)則集Rm,Span候選集生成偽代碼如下:
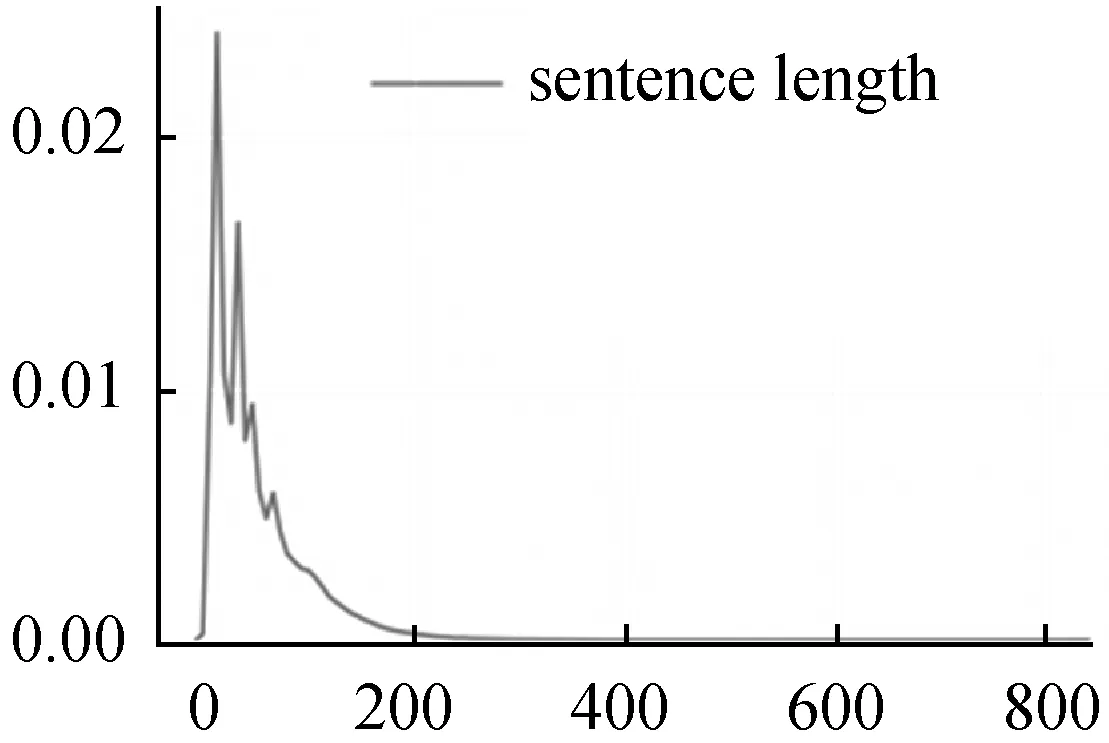
for n=0 and n for j=max_Length(Rm) and j>1: if [posn:posn+j]in R: SP.add([wn:wn+j]) j+=1 n+=1 for w in wi: SP.add(w) Span會跨過多個token,假設訓練最大字符長度為256,則每個token在經(jīng)過Bert層后可以得到Embedding是{e0,e1,e2,…,e255},Span的Embedding特征可以通過它所含的多個token的Embedding進行Maxpooling計算f(ei,ei+1,…,ei+k)得到相同大小的Embedding表示。假設Span生成時使用規(guī)則編號為k,可以通過查詢隨機嵌入矩陣來得到它的Rule Index Embedding表示wk。Span的Embeddinge(s)可以表示如下: (3) Span所在的句子上下文特征Csent使用BERT-WWM層CLS標簽所在token的Embedding表示,對于整篇文檔的上下文特征Cdoc,通過對每一句的上下文特征Csent_n,使用Maxpooling算子得到。 最后用于Span分類層的輸入特征,可以表示如下: (4) Span的輸入向量xs,進分類層: (5) Span經(jīng)過分類后,可以對Span進行過濾,篩選出分類屬于集合Cspan={S,O,SO}內的Span。對過濾后的Span類別為Cspan=(S,SO)的Span放入三元組SPO的Sspo,Cspan=(O,SO)放入三元組SPO的Ospo中。對Sspo與Ospo有序組合形成待分類SOij候選集。 SOij={(si,oj)|1≤i≤size(Sspo),1≤j≤size(Ospo)} (6) (7) (8) L=Ls+Lp (9) 式中:Ls和Lp分別表示Span分類的損失函數(shù)與(S,O)組合對的P分類損失函數(shù)。 本文使用BERT-WWM[15]作為預訓練模型,模型接收的最大字符序列長度max_seq_length設置為256,整體的學習率設置為0.001。 實體關系抽取子任務訓練上,由于受Span分類任務的精確率、召回率影響,可能無法得到有效的(S,O)組合對數(shù)據(jù)進行實體關系抽取的訓練任務,因此需要擴展關系抽取訓練任務的數(shù)據(jù)。本文對(S,O)候選分類組合的訓練數(shù)據(jù)主要通過如下三種方式生成: 1) 從Span分類正確且分類屬于{S,O,SO}結果進行(S,O)全組合生成正樣本數(shù)據(jù)。 2) 使用語料中標注為{S,O,SO}的Span數(shù)據(jù)進行(S,O)全組合,組合存在部分標注為P標簽正樣本,否則為負樣本標注為None標簽。 3) 使用Span分類錯誤的結果進行全匹配,生成標注None標簽的負樣本。 綜上即可得到充分的用于關系抽取訓練的數(shù)據(jù)。 本文是跨文檔中文三元組信息抽取,當前還未有公開的基線模型,文本采用SO實體識別部分使用BERT+CRF模型,SO的P分類模型使用BERT得到S、O的字向量分別進行maxpool計算后等到Es、Eo,以及SO分別所在句的[CLS]標簽作為句向量maxpool計算得到Econtext,再與Es、Eo拼接進入Softmax分類層進行分類。 模型的評價指標上,對于Span候選集生成只需要考慮覆蓋率cov即可,cov計算公式如下: cov=correctnum/entitynum (10) {S,O,SO}實體識別的評價指標使用精確率、召回率、F1值。其中精確率為預測準確實體個數(shù)與預測出的實體總數(shù)的比值: precision=correctnum/predictnum (11) 實體識別召回率為預測準確實體個數(shù)與樣本總的實體總數(shù)的比值: recall=correctnum/totalnum (12) (13) (S,O)組合的謂詞P分類部分只計算準確率: SOAcc=CorrectLabelnum/TotalLabelnum (14) 將Doc2EDAG數(shù)據(jù)集轉化為三元組數(shù)據(jù)集后,進行數(shù)據(jù)分析統(tǒng)計得到P謂詞有20種(即實體關系有20種類別),測試集與訓練集的數(shù)據(jù)量進行隨機拆分,分別為3 204和2 5632篇文檔。 其中數(shù)據(jù)集的句子長度分布,最大值832、最小值1、均值46個字符,核密度估計如圖4所示。 圖4 句子長度分布核密度估計 可以看出句子長度分布主要在0到200長度之間,max_seq_length設置為256是較為合適的,下文在針對不同max_seq_length模型實驗中將詳細分析。 訓練集中所有的三元組S與O實體的長度分布、核密度估計如圖5所示。 圖5 實體長度分布核密度估計 實體長度分布最大41,最小2,平均7.8,中位數(shù)9.0,也就是說token之間有著較長的上下文依賴關系。 由于本文模型的實驗指標有三項,其中Span候選集規(guī)則抽取部分基線模型不需要用到或者其他對比實驗對模型該部分沒有影響,因此后文主要對實體與關系識別進行對比分析。其中本文模型Span候選集規(guī)則抽取部分實驗結果覆蓋率cov為0.978,基本上可以滿足模型后續(xù)候選實體的覆蓋率訓練要求。 針對不同的max_seq_length配置對于模型的影響實驗結果如表3所示。 表3 不同max_seq_length三元組識別實驗結果 可以看出max_seq_length越長模型識別效果越好,這主要是因為max_seq_length越長可以捕捉到更多的語義信息。但是對比長度128、256兩個實驗,可看出模型優(yōu)化效果大幅降低,再結合圖4分析max_seq_length設置為256是比較合適的超參設置。 接下來對不同預訓練模型對整體模型性能的影響進行對比實驗,實驗結果如表4所示。 表4 不同預訓練模型三元組識別實驗結果 可以看出,BERT-WWM相比其他模型有著更好的效果,因此本文模型更適合使用BERT-WWM作為預訓練模型。 最后對本文模型與基線模型進行對比實驗,結果如表5所示。 表5 Doc2EDAG數(shù)據(jù)集三元組識別實驗結果 可以看出本文模型相比BERT-CRF不論在實體識別還是關系抽取上都有顯著的優(yōu)勢。 本文提出的基于Bert-WWM預訓練的跨文檔三元組提取模型,通過將SPO三元組抽取任務轉化為SO的Span生成、Span分類、P分類任務來實現(xiàn)三元組抽取目標。本文模型在Doc2EDAG的語料實體關系識別部分明顯優(yōu)于基線模型,且支持跨文檔的中文SPO抽取任務。 當然本文模型在召回率上有所欠缺,這與Span規(guī)則學習方式有關,后期可以通過引入通用實體標注語料進行規(guī)則的預學習,同時也可以引入特定領域詞匯改進基礎分詞器的分詞效果。這些可以一定程度上在不需要擴大Span候選集規(guī)模基礎上,提高Span候選集的覆蓋率。其次在模型的訓練上,未來可以嘗試引入其他更優(yōu)秀的預訓練模型。3.2 Span的編碼與分類

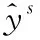
3.3 SPO分類層
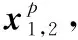


3.4 損失函數(shù)
4 實驗與結果分析
4.1 實驗設置
4.2 基線模型和評價指標
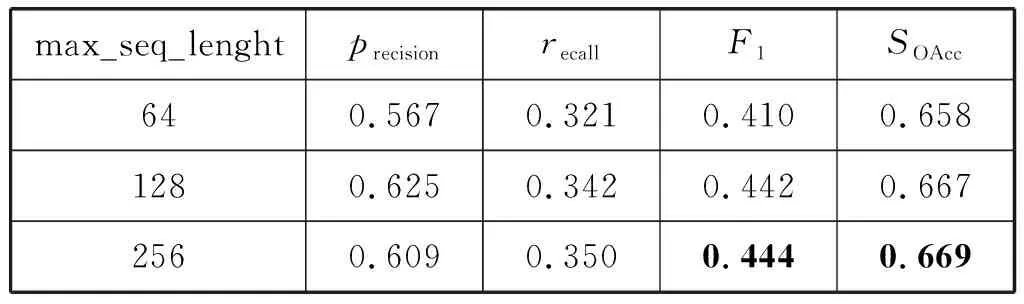
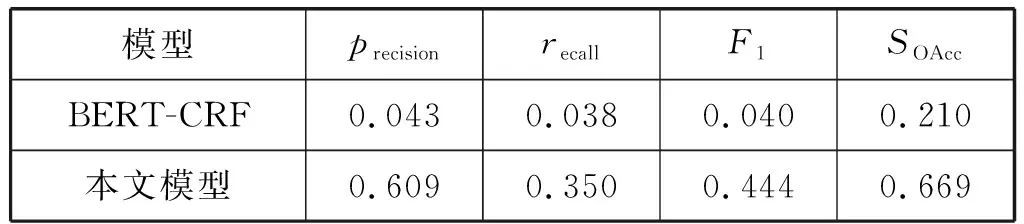
4.3 實驗結果


5 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
